In diesem Dokument wird eine Referenzarchitektur beschrieben, mit der Sie einen produktionsfertigen, skalierbaren, fehlertoleranten Logexport-Mechanismus erstellen können, der Logs und Ereignisse von Ihren Ressourcen in Google Cloud in Splunk streamt. Splunk ist ein beliebtes Analysetool, das eine einheitliche Plattform für Sicherheit und Beobachtbarkeit bietet. Tatsächlich können Sie die Logging-Daten entweder nach Splunk Enterprise oder Splunk Cloud Platform exportieren. Wenn Sie Administrator sind, können Sie diese Architektur auch für IT-Vorgänge oder Sicherheitsanwendungsfälle verwenden. Informationen zum Bereitstellen dieser Referenzarchitektur finden Sie unter Log-Streaming von Google Cloud zu Splunk bereitstellen.
Diese Referenzarchitektur setzt eine Ressourcenhierarchie voraus, die dem folgenden Diagramm ähnelt. Alle Google Cloud-Ressourcenlogs auf Organisations-, Ordner- und Projektebene werden in einer aggregierten Senke zusammengefasst. Anschließend sendet die aggregierte Senke diese Logs an eine Logexport-Pipeline, die die Logs verarbeitet und in Splunk exportiert.

Architektur
Das folgende Diagramm zeigt die Referenzarchitektur, die Sie beim Bereitstellen dieser Lösung verwenden. Dieses Diagramm zeigt, wie Logdaten von Google Cloud zu Splunk fließen.

Diese Architektur umfasst die folgenden Komponenten:
- Cloud Logging:Zu Beginn des Vorgangs erfasst Cloud Logging die Logs in einer aggregierten Log-Senke auf Organisationsebene und sendet die Logs an Pub/Sub.
- Pub/Sub: Der Pub/Sub-Dienst erstellt dann ein einzelnes Thema und ein Abo für die Logs und leitet die Logs an die Dataflow-Hauptpipeline weiter.
- Dataflow:In dieser Referenzarchitektur gibt es zwei Dataflow-Pipelines:
- Primary Dataflow pipeline: Im Zentrum des Prozesses befindet sich die Dataflow-Hauptpipeline, eine Pub/Sub to Splunk-Streamingpipeline, die Logs aus dem Pub/Sub-Abo abruft und an Splunk übermittelt.
- Sekundäre Dataflow-Pipeline: Parallel zur primären Dataflow-Pipeline ist die sekundäre Dataflow-Pipeline eine Pub/Sub-zu-Pub/Sub-Streaming-Pipeline, um Nachrichten wiederzugeben, wenn eine Übermittlung fehlschlägt.
- Splunk: Am Ende des Vorgangs dient Splunk Enterprise oder Splunk Cloud Platform als HTTP Event Collector (HEC) und empfängt die Logs zur weiteren Analyse. Sie können Splunk lokal, in Google Cloud als SaaS oder über einen hybriden Ansatz bereitstellen.
Anwendungsfall
Diese Referenzarchitektur verwendet einen cloudbasierten, Push-basierten Ansatz. Bei dieser Push-basierten Methode verwenden Sie die Dataflow-Vorlage „Pub/Sub für Splunk“ um Logs an einen Splunk HTTP-Ereignis-Collector (HEC) Diese Referenzarchitektur behandelt auch die Kapazitätsplanung für die Dataflow-Pipeline und die Behandlung potenzieller Bereitstellungsfehler bei vorübergehenden Server- oder Netzwerkproblemen.
Während sich diese Referenzarchitektur auf Google Cloud-Logs konzentriert, kann dieselbe Architektur zum Exportieren anderer Google Cloud-Daten wie Echtzeit-Asset-Änderungen und Sicherheitsergebnisse verwendet werden. Durch das Einbinden von Logs aus Cloud Logging können Sie weiterhin vorhandene Partnerdienste wie Splunk als einheitliche Loganalyselösung verwenden.
Die Push-basierte Methode zum Streamen von Google Cloud-Daten in Splunk bietet folgende Vorteile:
- Verwalteter Dienst Als verwalteter Dienst verwaltet Dataflow die erforderlichen Ressourcen in Google Cloud für Datenverarbeitungsaufgaben wie den Log-Export.
- Verteilte Arbeitslast: Mit dieser Methode können Sie Arbeitslasten zur Parallelverarbeitung auf mehrere Worker verteilen, sodass es keinen Single Point Of Failure gibt.
- Sicherheit. Da Google Cloud Ihre Daten per Push an Splunk HEC überträgt, sind die mit dem Erstellen und Verwalten von Dienstkontoschlüsseln verbundenen Wartungs- und Sicherheitsaufwand nicht verbunden.
- Autoscaling Der Dataflow-Dienst skaliert die Anzahl der Worker als Reaktion auf Variationen des eingehenden Logvolumens und des Rückstands automatisch.
- Fehlertoleranz Bei vorübergehenden Server- oder Netzwerkproblemen versucht die Push-basierte Methode automatisch, die Daten an den Splunk HEC noch einmal zu senden. Diese Methode unterstützt auch unverarbeitete Themen (auch als betrügerische Themen bezeichnet) für nicht zustellbare Lognachrichten, um Datenverluste zu vermeiden.
- Einfachheit: Sie vermeiden den Verwaltungsaufwand und die Kosten für die Ausführung eines oder mehrerer intensiver Forwarder in Splunk.
Diese Referenzarchitektur gilt für Unternehmen in vielen verschiedenen Branchen, einschließlich regulierter Unternehmen, wie z. B. Pharma- und Finanzdienstleistungen. Wenn Sie Ihre Google Cloud-Daten in Splunk exportieren möchten, kann das folgende Gründe haben:
- Geschäftsanalysen
- IT-Operationen
- Monitoring der Anwendungsleistung
- Sicherheitsabläufe
- Compliance
Designalternativen
Eine alternative Methode für den Logexport nach Splunk ist die Abfrage von Logs aus Google Cloud. Bei dieser Pull-basierten Methode verwenden Sie Google Cloud APIs, um die Daten über das Splunk Add-on für Google Cloud abzurufen. Sie können die Pull-basierte Methode in folgenden Situationen verwenden:
- Ihr Splunk-Deployment bietet keinen Splunk-HEC-Endpunkt.
- Ihr Logvolumen ist niedrig.
- Sie möchten Cloud Monitoring-Messwerte, Cloud Storage-Objekte, Cloud Resource Manager API-Metadaten oder Logs mit geringem Volumen analysieren.
- Sie verwalten bereits einen oder mehrere schwere Forwarder in Splunk.
- Sie verwenden den gehosteten Inputs Data Manager für Splunk Cloud.
Beachten Sie auch die zusätzlichen Überlegungen, die bei der Verwendung dieser Pull-basierten Methode auftreten:
- Ein einzelner Worker verarbeitet die Arbeitslast der Datenaufnahme, die keine Autoscaling-Funktionen bietet.
- In Splunk kann die Verwendung eines starken Forwarders zum Abrufen von Daten zu einem Single Point of Failure führen.
- Für die pullbasierte Methode müssen Sie die Dienstkontoschlüssel erstellen und verwalten, mit denen Sie das Splunk Add-on für Google Cloud konfigurieren.
Zum Aktivieren des Splunk Add-ons führen Sie die folgenden Schritte aus:
- Folgen Sie in Splunk der Anleitung für Splunk, um das Splunk-Add-on für Google Cloud zu installieren.
- Erstellen Sie in Google Cloud ein Pub/Sub-Thema zum Exportieren Ihrer Logging-Daten.
- Erstellen Sie ein Pub/Sub-Pull-Abo für dieses Thema.
- Erstellen Sie ein Dienstkonto.
- Erstellen Sie einen Dienstkontoschlüssel für das gerade erstellte Dienstkonto.
- Weisen Sie dem Dienstkonto die Rollen Pub/Sub-Betrachter (
roles/pubsub.viewer) und Pub/Sub-Abonnent (roles/pubsub.subscriber) zu, damit das Konto Nachrichten aus dem Pub/Sub-Abo empfangen kann. Folgen Sie in Splunk der Anleitung von Splunk, um eine neue Pub/Sub-Eingabe im Splunk Add-on für Google Cloud zu konfigurieren.
Die Pub/Sub-Nachrichten aus dem Logexport werden in Splunk angezeigt.
So können Sie prüfen, ob das Add-on funktioniert:
- Öffnen Sie in Cloud Monitoring den Metrics Explorer.
- Wählen Sie im Menü Ressourcen die Option
pubsub_subscriptionaus. - Wählen Sie in den Kategorien Messwert
pubsub/subscription/pull_message_operation_countaus. - Überwachen Sie die Anzahl der Abrufvorgänge für ein bis zwei Minuten.
Überlegungen zum Design
Die folgenden Richtlinien können Ihnen bei der Entwicklung einer Architektur helfen, die den Anforderungen Ihrer Organisation für Sicherheit, Datenschutz, Compliance, betriebliche Effizienz, Zuverlässigkeit, Fehlertoleranz, Leistung und Kostenoptimierung entspricht.
Sicherheit, Datenschutz und Compliance
In den folgenden Abschnitten werden die Sicherheitsaspekte für diese Referenzarchitektur beschrieben:
- Private IP-Adressen verwenden, um die VMs zu sichern, die die Dataflow-Pipeline unterstützen
- Privaten Google-Zugriff aktivieren
- Splunk HEC-Traffic auf bekannte IP-Adressen beschränken, die von Cloud NAT verwendet werden
- Splunk-HEC-Token in Secret Manager speichern
- Benutzerdefiniertes Dataflow-Worker-Dienstkonto erstellen, um die Best Practices für die geringsten Berechtigungen zu befolgen
- SSL-Validierung für ein internes Stamm-CA-Zertifikat konfigurieren, wenn Sie eine private Zertifizierungsstelle verwenden
Private IP-Adressen verwenden, um die VMs zu sichern, die die Dataflow-Pipeline unterstützen
Sie sollten den Zugriff auf die Worker-VMs einschränken, die in der Dataflow-Pipeline verwendet werden. Wenn Sie den Zugriff einschränken möchten, stellen Sie diese VMs mit privaten IP-Adressen bereit. Diese VMs müssen jedoch auch HTTPS verwenden können, um die exportierten Logs in Splunk zu streamen und auf das Internet zuzugreifen. Für diesen HTTPS-Zugriff benötigen Sie ein Cloud NAT-Gateway, das den VMs, die sie benötigen, automatisch Cloud NAT-IP-Adressen zuweist. Ordnen Sie das Subnetz, das die VMs enthält, dem Cloud NAT-Gateway zu.
Privaten Google-Zugriff aktivieren
Wenn Sie ein Cloud NAT-Gateway erstellen, wird der private Google-Zugriff automatisch aktiviert. Damit Dataflow-Worker mit privaten IP-Adressen Zugriff auf die externen IP-Adressen erhalten, die Google Cloud APIs und Dienste verwenden, müssen Sie außerdem den privaten Google-Zugriff für das Subnetz manuell aktivieren.
Splunk HEC-Traffic auf bekannte IP-Adressen beschränken, die von Cloud NAT verwendet werden
Wenn Sie den Traffic auf Splunk HEC auf eine Teilmenge von bekannten IP-Adressen beschränken möchten, können Sie statische IP-Adressen reservieren und diese manuell dem Cloud NAT-Gateway zuweisen. Abhängig von Ihrer Splunk-Bereitstellung können Sie dann die Splunk HEC-Firewallregeln für eingehenden Traffic mit diesen statischen IP-Adressen konfigurieren. Weitere Informationen zu Cloud NAT finden Sie unter Netzwerkadressübersetzung mit Cloud NAT einrichten und verwalten.
Splunk-HEC-Token in Secret Manager speichern
Wenn Sie die Dataflow-Pipeline bereitstellen, können Sie den Tokenwert auf eine der folgenden Arten übergeben:
- Klartext
- Mit einem Cloud Key Management Service-Schlüssel verschlüsselter Geheimtext
- Secret-Version, die von Secret Manager verschlüsselt und verwaltet wird
In dieser Referenzarchitektur verwenden Sie die Option Secret Manager, da diese Option die am wenigsten komplexe und effizienteste Methode zum Schutz Ihres Splunk HEC-Tokens bietet. Diese Option verhindert außerdem Datenlecks aus dem Splunk HEC-Token aus der Dataflow-Konsole oder den Jobdetails.
Ein Secret in Secret Manager enthält eine Sammlung von Secret-Versionen. Jede Secret-Version speichert die tatsächlichen Secret-Daten, z. B. das Splunk HEC-Token. Wenn Sie später Ihr Splunk HEC-Token als zusätzliche Sicherheitsmaßnahme rotieren, können Sie das neue Token als neue Secret-Version zu diesem Secret hinzufügen. Allgemeine Informationen zur Rotation von Secrets finden Sie unter Rotationspläne.
Benutzerdefiniertes Dataflow-Worker-Dienstkonto erstellen, um die Best Practices für die geringsten Berechtigungen zu befolgen
Worker in der Dataflow-Pipeline verwenden das Dataflow-Worker-Dienstkonto, um auf Ressourcen zuzugreifen und Vorgänge auszuführen. Die Worker verwenden standardmäßig das Compute Engine-Standarddienstkonto Ihres Projekts als Worker-Dienstkonto, das ihnen umfassende Berechtigungen für alle Ressourcen in Ihrem Projekt gewährt. Zum Ausführen von Dataflow-Jobs in der Produktion empfehlen wir jedoch, ein benutzerdefiniertes Dienstkonto mit einem Mindestsatz an Rollen und Berechtigungen zu erstellen. Dieses benutzerdefinierte Dienstkonto können Sie dann Ihren Dataflow-Pipeline-Workern zuweisen.
Das folgende Diagramm zeigt die erforderlichen Rollen, die Sie einem Dienstkonto zuweisen müssen, damit Dataflow-Worker einen Dataflow-Job erfolgreich ausführen können.
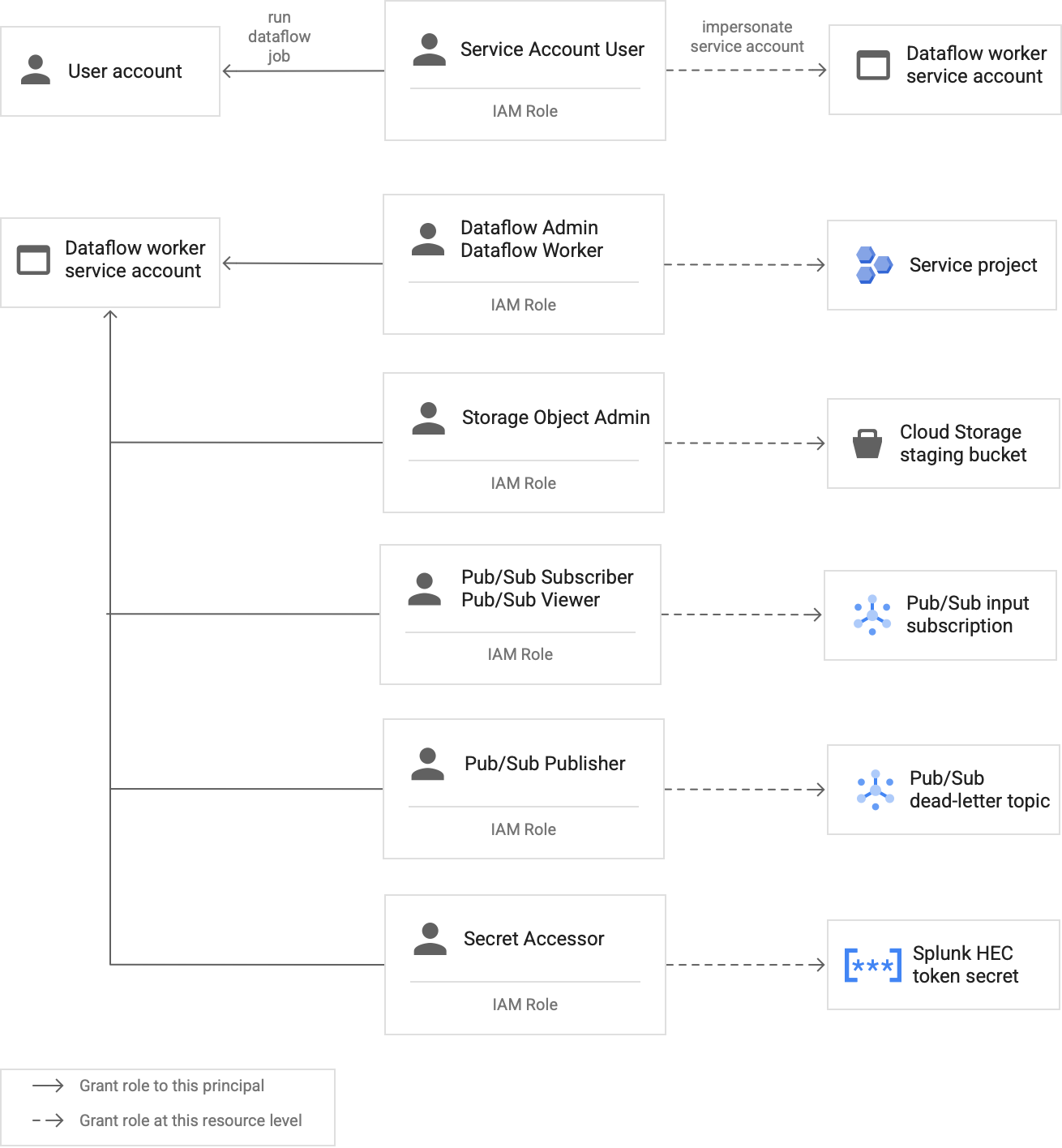
Wie im Diagramm dargestellt, müssen Sie dem Dienstkonto für Ihren Dataflow-Worker die folgenden Rollen zuweisen:
- Dataflow-Administrator
- Dataflow-Worker
- Storage-Objekt-Administrator
- Pub/Sub-Abonnent
- Pub/Sub-Betrachter
- Pub/Sub-Publisher
- Secret Accessor
Weitere Informationen zu den Rollen, die Sie dem Dataflow-Worker-Dienstkonto zuweisen müssen, finden Sie im Abschnitt Rollen und Zugriff auf das Dataflow-Worker-Dienstkonto gewähren des Bereitstellungsleitfadens.
SSL-Validierung mit einem internen Stamm-CA-Zertifikat konfigurieren, wenn Sie eine private Zertifizierungsstelle verwenden
Standardmäßig verwendet die Dataflow-Pipeline den Standard-Trust Store des Dataflow-Workers, um das SSL-Zertifikat für Ihren Splunk HEC-Endpunkt zu validieren. Wenn Sie eine private Zertifizierungsstelle (CA) verwenden, um ein SSL-Zertifikat zu signieren, das vom Splunk HEC-Endpunkt verwendet wird, können Sie Ihr internes Stamm-CA-Zertifikat in den Trust Store importieren. Die Dataflow-Worker können dann das importierte Zertifikat zur Validierung des SSL-Zertifikats verwenden.
Sie können Ihr eigenes internes Stamm-CA-Zertifikat für Splunk-Bereitstellungen mit selbst signierten oder privat signierten Zertifikaten verwenden und importieren. Sie können die SSL-Validierung auch nur für interne Entwicklungs- und Testzwecke deaktivieren. Diese interne Stamm-CA-Methode funktioniert am besten für nicht Internet-interne, interne Splunk-Bereitstellungen.
Weitere Informationen finden Sie unter Dataflow-Vorlagenparameter „Pub/Sub to Splunk“
rootCaCertificatePath und disableCertificateValidation.
Operative Effizienz
In den folgenden Abschnitten werden die Aspekte der betrieblichen Effizienz für diese Referenzarchitektur beschrieben:
- UDF zum Transformieren von Logs oder Ereignissen während der Übertragung verwenden
- Unverarbeitete Nachrichten wiedergeben
UDF zum Transformieren von Logs oder Ereignissen während der Übertragung verwenden
Die Dataflow-Vorlage Pub/Sub zu Splunk unterstützt benutzerdefinierte Funktionen (User-Defined Functions, benutzerdefinierte Funktionen) für die benutzerdefinierte Ereignistransformation. Beispiele für Anwendungsfälle sind das Anreichern von Datensätzen mit zusätzlichen Feldern, das Entfernen einiger vertraulicher Felder oder das Filtern unerwünschter Datensätze. Mit UDF können Sie das Ausgabeformat der Dataflow-Pipeline ändern, ohne den Vorlagencode selbst neu kompilieren oder verwalten zu müssen. In dieser Referenzarchitektur werden UDF zur Verarbeitung von Nachrichten verwendet, die nicht von der Pipeline an Splunk übermittelt werden können.
Unverarbeitete Nachrichten wiedergeben
Manchmal erhält die Pipeline Übermittlungsfehler und versucht nicht, die Nachricht noch einmal zu senden. In diesem Fall sendet Dataflow diese nicht verarbeiteten Nachrichten an ein nicht verarbeitetes Thema, wie im folgenden Diagramm dargestellt. Nachdem Sie die Ursache des Übermittlungsfehlers behoben haben, können Sie die nicht verarbeiteten Nachrichten wiedergeben.
Mit den folgenden Schritten können Sie die im vorherigen Diagramm dargestellte Vorgehensweise umgehen:
- Die Hauptübermittlungspipeline von Pub/Sub to Splunk leitet unzustellbare Nachrichten automatisch an das unverarbeitete Thema zur Nutzereinstufung weiter.
Der Operator oder Site Reliability Engineer (SRE) untersucht die fehlgeschlagenen Nachrichten im unverarbeiteten Abo. Der Operator behebt die Ursache des Zustellungsfehlers und behebt sie. Beispielsweise kann die Behebung einer Fehlkonfiguration des HEC-Tokens dazu führen, dass die Nachrichten zugestellt werden.
Der Operator löst die Pipeline für fehlgeschlagene Nachrichten aus. Diese Pub/Sub-zu-Pub/Sub-Pipeline (im markierten Abschnitt des vorhergehenden Diagramms hervorgehoben) ist eine temporäre Pipeline, die fehlgeschlagene Nachrichten aus dem nicht verarbeiteten Abo wieder in das ursprüngliche Logsenkenthema verschiebt.
Die Hauptübermittlungspipeline verarbeitet die zuvor fehlgeschlagenen Nachrichten noch einmal. Bei diesem Schritt muss die Pipeline die Beispiel-UDF verwenden, um die Nutzlasten fehlgeschlagener Nachrichten korrekt zu erkennen und zu decodieren. Der folgende Code zeigt den Teil der Funktion, der diese bedingte Decodierungslogik implementiert, einschließlich einer Liste von Übermittlungsversuchen zu Verfolgungszwecken:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Zuverlässigkeit und Fehlertoleranz
In Bezug auf Zuverlässigkeit und Fehlertoleranz werden in der folgenden Tabelle, Tabelle 1, einige mögliche Fehler bei der Splunk-Übermittlung aufgeführt. In der Tabelle werden auch die entsprechenden errorMessage-Attribute aufgeführt, die die Pipeline mit jeder Nachricht aufzeichnet, bevor diese Nachrichten an das nicht verarbeitete Thema weitergeleitet werden.
Tabelle 1: Fehlertypen der Splunk-Übermittlung
| Zustellungsfehlertyp | Automatisch von Pipeline wiederholen? | Beispielattribut errorMessage |
|---|---|---|
Vorübergehender Netzwerkfehler |
Ja |
oder
|
5xx-Fehler des Splunk-Servers |
Ja |
|
4xx-Fehler des Splunk-Servers |
Nein |
|
Splunk-Server ausgefallen |
Nein |
|
Splunk-SSL-Zertifikat ungültig |
Nein |
|
JavaScript-Syntaxfehler in einer benutzerdefinierten Funktion (UDF) |
Nein |
|
In einigen Fällen wendet die Pipeline den exponentiellen Backoff an und versucht automatisch, die Nachricht noch einmal zu senden. Wenn der Splunk-Server beispielsweise den Fehlercode 5xx generiert, muss die Pipeline die Nachricht noch einmal senden. Diese Fehlercodes treten auf, wenn der Splunk-HEC-Endpunkt überlastet ist.
Alternativ kann es zu einem persistenten Problem kommen, das die Übermittlung einer Nachricht an den HEC-Endpunkt verhindert. Bei solchen dauerhaften Problemen versucht die Pipeline nicht, die Nachricht noch einmal zu senden. Beispiele für dauerhafte Probleme:
- Syntaxfehler in der UDF-Funktion.
- Ungültiges HEC-Token, das dazu führt, dass der Splunk-Server die Serverantwort
4xx„Forbidden“ generiert.
Leistungs- und Kostenoptimierung
Im Hinblick auf Leistungs- und Kostenoptimierung müssen Sie die maximale Größe und den Durchsatz für Ihre Dataflow-Pipeline festlegen. Sie müssen die richtigen Größen- und Durchsatzwerte berechnen, damit Ihre Pipeline das maximale tägliche Logvolumen (GB/Tag) und die Lognachrichtenrate (Ereignisse pro Sekunde oder EPS) aus dem vorgelagerten Pub/Sub-Abo verarbeiten kann.
Sie müssen die Größe und den Durchsatzwert auswählen, damit das System keines der folgenden Probleme verursacht:
- Verzögerungen durch Nachrichtenrückstände oder Nachrichtendrosselung
- Zusätzliche Kosten durch Überdimensionierung einer Pipeline
Nachdem Sie die Größen- und Durchsatzberechnungen durchgeführt haben, können Sie die Ergebnisse verwenden, um eine optimale Pipeline zu konfigurieren, die Leistung und Kosten ausgleicht. Mit den folgenden Einstellungen konfigurieren Sie die Pipelinekapazität:
- Die Seite Maschinentyp und Anzahl der Maschinen Flags sind Teil der gcloud-Befehl der den Dataflow-Job bereitstellt. Mit diesen Flags können Sie den Typ und die Anzahl der zu verwendenden VMs definieren.
- Die Seite Parallelismus undAnzahl der Batches Parameter sind Teil der Dataflow-Vorlage "Pub/Sub to Splunk". Diese Parameter sind wichtig, um die EPS zu erhöhen und zu vermeiden, dass der Splunk HEC-Endpunkt überlastet wird.
In den folgenden Abschnitten werden diese Einstellungen erläutert. Gegebenenfalls enthalten diese Abschnitte auch Formeln und Beispielberechnungen, die jede Formel verwenden. Bei diesen Beispielberechnungen und den resultierenden Werten wird von einer Organisation mit folgenden Merkmalen ausgegangen:
- Es werden täglich 1 TB Logs erstellt.
- Die durchschnittliche Nachrichtengröße beträgt 1 KB.
- Die Zahl der Nachrichten mit kontinuierlicher Spitzenrate ist doppelt so hoch wie die durchschnittliche Rate.
Da Ihre Dataflow-Umgebung eindeutig ist, ersetzen Sie die Beispielwerte durch Werte aus Ihrer eigenen Organisation, wenn Sie die Schritte durcharbeiten.
Maschinentyp
Best Practice: Setzen Sie das Flag --worker-machine-type auf n1-standard-4, um eine Maschinengröße auszuwählen, die das beste Leistungs-/Kostenverhältnis bietet.
Da der Maschinentyp n1-standard-4 12.000 EPS verarbeiten kann, empfehlen wir, diesen Maschinentyp als Referenz für alle Dataflow-Worker zu verwenden.
Legen Sie für diese Referenzarchitektur das Flag --worker-machine-type auf den Wert n1-standard-4 fest.
Maschinenanzahl
Best Practice: Legen Sie das Flag --max-workers fest, um die maximale Anzahl von Workern zu steuern, die für den Umgang mit dem erwarteten Spitzen-EPS-Wert erforderlich ist.
Mit Dataflow-Autoscaling kann der Dienst die Anzahl der Worker, die zum Ausführen der Streamingpipeline verwendet werden, dynamisch ändern, wenn es Änderungen an der Ressourcennutzung und -last gibt. Um eine Überdimensionierung beim Autoscaling zu vermeiden, empfehlen wir Ihnen, immer die maximale Anzahl virtueller Maschinen zu definieren, die als Dataflow-Worker verwendet werden. Sie definieren die maximale Anzahl virtueller Maschinen mit dem Flag --max-workers, wenn Sie die Dataflow-Pipeline bereitstellen.
Dataflow stellt die Speicherkomponente statisch so bereit:
Eine Autoscaling-Pipeline stellt für jeden potenziellen Streaming-Worker einen nichtflüchtigen Datenspeicher bereit. Die Standardgröße des nichtflüchtigen Speichers beträgt 400 GB. Sie legen mit dem Flag
--max-workersdie maximale Anzahl der Worker fest. Die Laufwerke werden jederzeit für die aktiven Worker bereitgestellt, einschließlich des Starts.Da jede Worker-Instanz auf 15 nichtflüchtige Speicher beschränkt ist, beträgt die Mindestanzahl von Worker-Starts
⌈--max-workers/15⌉. Wenn der Standardwert also--max-workers=20ist, sind die Pipelinenutzung (und die Kosten) so:- Speicher: statisch mit 20 nichtflüchtigen Speichern
- Computing: dynamisch mit mindestens zwei Worker-Instanzen (⌈20 / 15⌉ = 2) und maximal 20.
Dieser Wert entspricht 8 TB einer Persistent Disk. Diese Größe von Persistent Disk kann unnötige Kosten verursachen, wenn die Laufwerke nicht vollständig genutzt werden, insbesondere wenn nur ein oder zwei Worker die meiste Zeit ausführen.
Verwenden Sie die folgenden Formeln nacheinander, um die maximale Anzahl von Workern zu ermitteln, die Sie für Ihre Pipeline benötigen:
Ermitteln Sie die durchschnittlichen Ereignisse pro Sekunde (EPS) mit der folgenden Formel:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Beispielberechnung: Bei den Beispielwerten von 1 TB Logs pro Tag mit einer durchschnittlichen Nachrichtengröße von 1 KB generiert diese Formel einen durchschnittlichen EPS-Wert von 11.500 EPS.
Ermitteln Sie den kontinuierlichen maximalen EPS-Wert mithilfe der folgenden Formel, wobei der Multiplikator N die sporadischen Zustandsspitzen des Loggings darstellt:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Beispielberechnung: Bei einem Beispielwert von N=2 und dem durchschnittlichen EPS-Wert von 11.500, den Sie im vorherigen Schritt berechnet haben, generiert diese Formel ein kontinuierlicher EPS-Wert von 23.000 EPS
Ermitteln Sie die maximal erforderliche Anzahl von vCPUs mit der folgenden Formel:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Beispielberechnung: Unter Verwendung des kontinuierlichen EPS-Werts von 23.000, den Sie im vorherigen Schritt berechnet haben, generiert diese Formel maximal ⌈23 / 3⌉ = 8 vCPU-Kerne.
Ermitteln Sie die maximale Anzahl von Dataflow-Workern mit der folgenden Formel:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Beispielrechnung: Unter Verwendung der im letzten Schritt berechneten maximalen vCPU-Wert von 8 generiert diese Formel [8/4] eine maximale Anzahl von 2 für eine
n1-standard-4Maschinentyp.
In diesem Beispiel würden Sie das Flag --max-workers auf der Grundlage des vorherigen Satzes von Beispielberechnungen auf den Wert 2 festlegen. Denken Sie jedoch daran, Ihre eigenen eindeutigen Werte und Berechnungen zu verwenden, wenn Sie diese Referenzarchitektur in Ihrer Umgebung bereitstellen.
Parallelität
Best Practice: Legen Sie den Parameter parallelism in der Dataflow-Vorlage "Pub/Sub to Splunk Dataflow" auf die doppelte Anzahl der vCPUs fest, die von der maximalen Anzahl von Dataflow-Workern verwendet werden.
Der Parameter parallelism trägt dazu bei, die Anzahl der parallelen Splunk-HEC-Verbindungen zu maximieren, die wiederum die EPS-Rate für Ihre Pipeline maximieren.
Der Standardwert parallelism von 1 deaktiviert Parallelität und begrenzt die Ausgaberate. Sie müssen diese Standardeinstellung überschreiben, um zwei bis vier parallele Verbindungen pro vCPU zu berücksichtigen. Dabei werden die maximale Anzahl von Workern bereitgestellt. In der Regel berechnen Sie den Überschreibungswert für diese Einstellung, indem Sie die maximale Anzahl von Dataflow-Workern mit der Anzahl der vCPUs pro Worker multiplizieren und diesen Wert dann verdoppeln.
Verwenden Sie die folgende Formel, um die Gesamtzahl der parallelen Verbindungen zum Splunk HEC für alle Dataflow-Worker zu ermitteln:
Beispielberechnung: Bei dieser Formel für die maximale Anzahl von 8 vCPUs, die zuvor für die Maschinenanzahl berechnet wurden, wird die Anzahl der parallelen Verbindungen auf 8 x 2 = 16 erzeugt.
Für dieses Beispiel würden Sie den Parameter parallelism auf der Grundlage des vorherigen Beispiels auf den Wert 16 festlegen. Denken Sie jedoch daran, Ihre eigenen eindeutigen Werte und Berechnungen zu verwenden, wenn Sie diese Referenzarchitektur in Ihrer Umgebung bereitstellen.
Anzahl der Batches
Best Practice: Damit der Splunk HEC Ereignisse in Batches verarbeiten kann, anstatt jeweils einzeln, setzen Sie den Parameter batchCount auf einen Wert. zwischen 10 und 50 Ereignissen/Anfrage für Logs.
Durch das Konfigurieren der Batchanzahl können Sie die EPS erhöhen und die Last auf dem Splunk HEC-Endpunkt reduzieren. Diese Einstellung kombiniert mehrere Ereignisse zu einem einzigen Batch, um die Verarbeitung effizienter zu gestalten. Wir empfehlen, den Parameter batchCount auf einen Wert zwischen 10 und 50 Ereignissen/Anfrage für Logs zu setzen, sofern die maximale Pufferverzögerung von zwei Sekunden akzeptabel ist.
Da die durchschnittliche Größe der Lognachrichten 1 KB in diesem Beispiel beträgt, empfehlen wir, mindestens 10 Ereignisse pro Anfrage im Batch zu verarbeiten. In diesem Beispiel würden Sie für den Parameter batchCount den Wert 10 festlegen. Denken Sie jedoch daran, Ihre eigenen eindeutigen Werte und Berechnungen zu verwenden, wenn Sie diese Referenzarchitektur in Ihrer Umgebung bereitstellen.
Weitere Informationen zu diesen Empfehlungen für Leistungs- und Kostenoptimierung finden Sie unter Dataflow-Pipeline planen.
Bereitstellung
Informationen zum Bereitstellen dieser Referenzarchitektur finden Sie unter Log-Streaming von Google Cloud zu Splunk bereitstellen.
Nächste Schritte
- Eine vollständige Liste der Parameter der Dataflow-Vorlage "Pub/Sub to Splunk" finden Sie in der Dokumentation „Pub/Sub to Splunk Dataflow“.
- Die entsprechenden Terraform-Vorlagen zur Bereitstellung dieser Referenzarchitektur finden Sie im GitHub-Repository
terraform-splunk-log-export. Es enthält ein vordefiniertes Cloud Monitoring-Dashboard für das Monitoring Ihrer Splunk Dataflow-Pipeline. - Weitere Informationen zu benutzerdefinierten Messwerten und Logging von Splunk Dataflow finden Sie in diesem Blog: Neue Beobachtbarkeitsfeatures für Ihre Splunk Dataflow-Streamingpipelines.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center