In diesem Dokument werden zwei Referenzarchitekturen beschrieben, mit denen Sie mit Google Kubernetes Engine (GKE) eine Plattform für föderiertes Lernen in Google Cloud erstellen können. Die in diesem Dokument beschriebenen Referenzarchitekturen und die zugehörigen Ressourcen unterstützen Folgendes:
- Siloübergreifendes föderiertes Lernen
- Geräteübergreifendes föderiertes Lernen, das auf der siloübergreifenden Architektur basiert
Dieses Dokument richtet sich an Cloud-Architekten sowie KI- und ML-Entwickler, die Anwendungsfälle für föderiertes Lernen in Google Cloud implementieren möchten. Es richtet sich auch an Entscheidungsträger, die prüfen, ob föderiertes Lernen in Google Cloud implementiert werden soll.
Architektur
Die Diagramme in diesem Abschnitt zeigen eine siloübergreifende und eine geräteübergreifende Architektur für föderiertes Lernen. Informationen zu den verschiedenen Anwendungen dieser Architekturen finden Sie unter Anwendungsfälle.
Siloübergreifende Architektur
Das folgende Diagramm zeigt eine Architektur, die das siloübergreifende föderierte Lernen unterstützt:

Das obige Diagramm zeigt ein vereinfachtes Beispiel für eine siloübergreifende Architektur. Im Diagramm befinden sich alle Ressourcen im selben Projekt in einer Google Cloud-Organisation. Diese Ressourcen umfassen das lokale Clientmodell, das globale Clientmodell und die zugehörigen Arbeitslasten für föderiertes Lernen.
Diese Referenzarchitektur kann so geändert werden, dass sie mehrere Konfigurationen für Datensilos unterstützt. Mitglieder des Konsortiums können ihre Datensilos auf folgende Arten hosten:
- In Google Cloud, in derselben Google Cloud-Organisation und im selben Google Cloud-Projekt.
- In Google Cloud, in derselben Google Cloud-Organisation, in verschiedenen Google Cloud-Projekten.
- In Google Cloud, in verschiedenen Google Cloud-Organisationen.
- In privaten, lokalen Umgebungen oder in anderen öffentlichen Clouds
Damit die teilnehmenden Mitglieder zusammenarbeiten können, müssen sie sichere Kommunikationskanäle zwischen ihren Umgebungen einrichten. Weitere Informationen zur Rolle der teilnehmenden Mitglieder bei der föderierten Lerntechnologie, zur Zusammenarbeit und zum Datenaustausch finden Sie unter Anwendungsfälle.
Die Architektur umfasst die folgenden Komponenten:
- Ein VPC-Netzwerk (Virtual Private Cloud) und ein Subnetz.
- Ein privater GKE-Cluster, mit dem Sie Folgendes tun können:
- Clusterknoten vom Internet isolieren.
- Die Sichtbarkeit Ihrer Clusterknoten und Steuerungsebene auf das Internet beschränken. Dazu erstellen Sie einen privaten GKE-Cluster mit autorisierten Netzwerken.
- Verwenden Sie gehärtete Clusterknoten mit einem gehärteten Betriebssystem-Image.
- Dataplane V2 für ein optimiertes Kubernetes-Netzwerk aktivieren.
- Dedizierte GKE-Knotenpools: Sie erstellen einen dedizierten Knotenpool, um ausschließlich Mandantenanwendungen und -ressourcen zu hosten. Die Knoten haben Markierungen, damit nur Mandantenarbeitslasten auf den Mandantenknoten geplant werden. Andere Clusterressourcen werden im Hauptknotenpool gehostet.
Datenverschlüsselung (standardmäßig aktiviert):
- Ruhende Daten
- Daten bei der Übertragung
- Cluster-Secrets auf Anwendungsebene.
Verschlüsselung von aktiven Daten, indem optional Confidential Google Kubernetes Engine-Knoten aktiviert werden.
VPC-Firewallregeln, die Folgendes anwenden:
- Referenzregeln, die für alle Knoten im Cluster gelten.
- Zusätzliche Regeln, die nur für Knoten im Mandantenknotenpool gelten. Diese Firewallregeln begrenzen den Traffic, der zu den Mandantenknoten und von ihnen ausgeht.
Cloud NAT, um ausgehenden Traffic zum Internet zuzulassen.
Cloud DNS-Einträge zur Aktivierung des privaten Google-Zugriffs, sodass Anwendungen innerhalb des Clusters auf Google APIs zugreifen können, ohne das Internet zu durchlaufen.
-
- Ein dediziertes Dienstkonto für die Knoten im Mandantenknotenpool.
- Ein spezielles Dienstkonto für Mieteranwendungen, das mit der Workload Identity-Föderation verwendet wird.
Unterstützung für die Verwendung von Rollenbasierter Zugriffssteuerung (Role-Based Access Control, RBAC) von Kubernetes in Google Groups
Ein Git-Repository zum Speichern von Konfigurationsdeskriptoren.
Ein Artifact Registry-Repository zum Speichern von Container-Images.
Config Sync und Policy Controller zum Bereitstellen der Konfiguration und von Richtlinien.
Cloud Service Mesh-Gateways, um selektiv eingehenden und ausgehenden Cluster-Traffic zuzulassen.
Cloud Storage-Buckets zum Speichern globaler und lokaler Modellgewichtungen.
Zugriff auf andere Google und Google Cloud APIs. Beispielsweise kann eine Trainingsarbeitslast auf Trainingsdaten zugreifen, die in Cloud Storage, BigQuery oder Cloud SQL gespeichert sind.
Geräteübergreifende Architektur
Das folgende Diagramm zeigt eine Architektur, die das geräteübergreifende föderierte Lernen unterstützt:
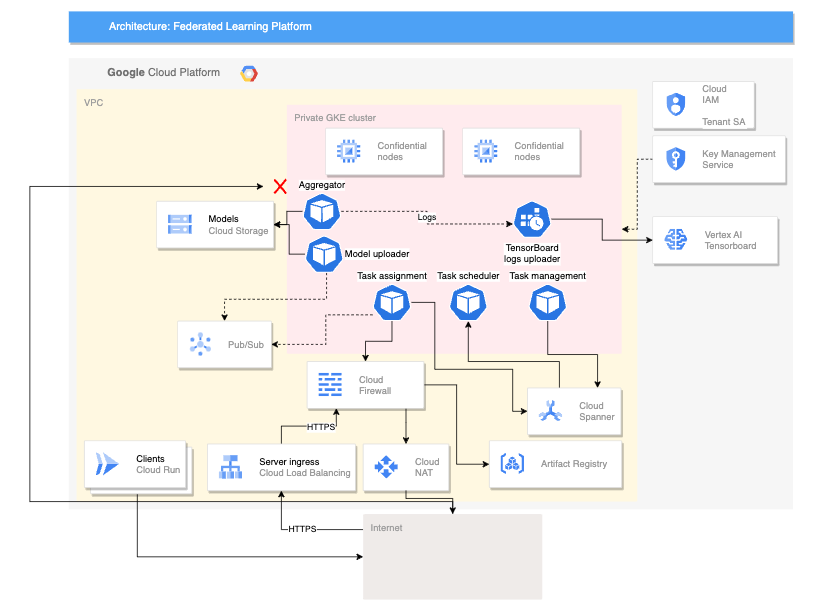
Die obige geräteübergreifende Architektur baut auf der siloübergreifenden Architektur mit den folgenden Komponenten auf:
- Einen Cloud Run-Dienst, der Geräte simuliert, die eine Verbindung zum Server herstellen
- Ein Certificate Authority Service, der private Zertifikate für den Server und die Clients erstellt
- Ein Vertex AI TensorBoard zum Visualisieren des Trainingsergebnisses
- Einen Cloud Storage-Bucket zum Speichern des konsolidierten Modells
- Der private GKE-Cluster, der Confidential Nodes als primären Pool verwendet, um die aktiven Daten zu schützen
Die geräteübergreifende Architektur verwendet Komponenten aus dem Open-Source-Projekt Federated Compute Platform (FCP). Dieses Projekt umfasst Folgendes:
- Clientcode für die Kommunikation mit einem Server und die Ausführung von Aufgaben auf den Geräten
- Ein Protokoll für die Client-Server-Kommunikation
- Verbindungspunkte mit TensorFlow Federated, um die Definition Ihrer föderierten Berechnungen zu vereinfachen
Die im vorherigen Diagramm dargestellten FCP-Komponenten können als Gruppe von Mikrodiensten bereitgestellt werden. Diese Komponenten haben folgende Funktionen:
- Aggregator: Bei diesem Job werden Gerätegradienten gelesen und das aggregierte Ergebnis mithilfe des Differential Privacy-Algorithmus berechnet.
- Collector: Dieser Job wird regelmäßig ausgeführt, um aktive Aufgaben und verschlüsselte Gradienten abzufragen. Anhand dieser Informationen wird festgelegt, wann die Aggregation beginnt.
- Modell-Uploader: Dieser Job überwacht Ereignisse und veröffentlicht Ergebnisse, damit Geräte aktualisierte Modelle herunterladen können.
- Aufgabenzuweisung: Dieser Frontend-Dienst verteilt Trainingsaufgaben auf Geräte.
- Aufgabenverwaltung: Dieser Job verwaltet Aufgaben.
- Task-Scheduler: Dieser Job wird entweder regelmäßig ausgeführt oder durch bestimmte Ereignisse ausgelöst.
Verwendete Produkte
In den Referenzarchitekturen für beide Anwendungsfälle für föderiertes Lernen werden die folgenden Google Cloud-Komponenten verwendet:
- Google Cloud Kubernetes Engine (GKE): GKE ist die grundlegende Plattform für föderiertes Lernen.
- TensorFlow Federated (TFF): TFF ist ein Open-Source-Framework für maschinelles Lernen und andere Berechnungen auf dezentralen Daten.
GKE bietet Ihrer Plattform für föderiertes Lernen außerdem die folgenden Funktionen:
- Hosting des Koordinators für föderiertes Lernen: Der Koordinator für föderiertes Lernen ist für die Verwaltung des föderierten Lernprozesses verantwortlich. Dazu gehören Aufgaben wie die Verteilung des globalen Modells an die Teilnehmer, das Aggregieren von Updates von Teilnehmern und die Aktualisierung des globalen Modells. Mit GKE können Sie den Koordinator für föderiertes Lernen hochverfügbar und skalierbar hosten.
- Teilnehmer am föderierten Lernen hosten: Teilnehmer am föderierten Lernen sind dafür verantwortlich, das globale Modell mit ihren lokalen Daten zu trainieren. Mit GKE können Teilnehmer an föderiertem Lernen sicher und isoliert gehostet werden. So können die Daten der Teilnehmer lokal gespeichert werden.
- Sicheren und skalierbaren Kommunikationskanal bereitstellen: Teilnehmer des föderierten Lernens müssen auf sichere und skalierbare Weise mit dem Koordinator für föderiertes Lernen kommunizieren können. GKE kann verwendet werden, um einen sicheren und skalierbaren Kommunikationskanal zwischen den Teilnehmern und dem Koordinator bereitzustellen.
- Lebenszyklus von Bereitstellungen für föderiertes Lernen verwalten: Mit GKE können Sie den Lebenszyklus von Bereitstellungen für föderiertes Lernen verwalten. Dazu gehören Aufgaben wie die Bereitstellung von Ressourcen, die Bereitstellung der Plattform für föderiertes Lernen und die Überwachung der Leistung der Plattform für föderiertes Lernen.
Neben diesen Vorteilen bietet GKE auch eine Reihe von Funktionen, die für Bereitstellungen mit föderierter Lernen nützlich sein können, z. B.:
- Regionale Cluster: Mit GKE können Sie regionale Cluster erstellen und so die Leistung von Bereitstellungen für föderiertes Lernen verbessern, indem Sie die Latenz zwischen Teilnehmern und dem Koordinator reduzieren.
- Netzwerkrichtlinien: Mit GKE können Sie Netzwerkrichtlinien erstellen und so die Sicherheit von Bereitstellungen für föderiertes Lernen verbessern. Dazu steuern Sie den Trafficfluss zwischen Teilnehmern und dem Koordinator.
- Load-Balancing: GKE bietet eine Reihe von Load-Balancing-Optionen, mit denen die Skalierbarkeit von Bereitstellungen für föderiertes Lernen verbessert wird, indem der Traffic zwischen den Teilnehmern und dem Koordinator verteilt wird.
TFF bietet die folgenden Funktionen, um die Implementierung von Anwendungsfällen für föderiertes Lernen zu erleichtern:
- Die Möglichkeit, föderierte Berechnungen deklarativ auszudrücken, d. h. eine Reihe von Verarbeitungsschritten, die auf einem Server und einer Reihe von Clients ausgeführt werden. Diese Berechnungen können in verschiedenen Laufzeitumgebungen bereitgestellt werden.
- Benutzerdefinierte Aggregatoren können mit TFF Open Source erstellt werden.
- Unterstützung einer Vielzahl von Algorithmen für föderiertes Lernen, einschließlich der folgenden Algorithmen:
- Föderierte Mittelung: Ein Algorithmus, der den Durchschnitt der Modellparameter der teilnehmenden Clients ermittelt. Diese Architektur eignet sich besonders für Anwendungsfälle, bei denen die Daten relativ homogen sind und das Modell nicht zu komplex ist. Typische Anwendungsfälle:
- Personalisierte Empfehlungen: Ein Unternehmen kann föderierte Mittelung verwenden, um ein Modell zu trainieren, das Nutzern Produkte basierend auf deren bisherigen Käufen empfiehlt.
- Betrugserkennung: Ein Bankenkonsortium kann die föderierte Aggregation verwenden, um ein Modell zu trainieren, das betrügerische Transaktionen erkennt.
- Medizinische Diagnose: Eine Gruppe von Krankenhäusern kann die föderierte Aggregation verwenden, um ein Modell zu trainieren, mit dem Krebs diagnostiziert wird.
- Föderierter stochastischer Gradientenabfall (FedSGD): Ein Algorithmus, der den stochastischen Gradientenabstieg zur Aktualisierung der Modellparameter verwendet. Er eignet sich gut für Anwendungsfälle, bei denen die Daten heterogen sind und das Modell komplex ist. Typische Anwendungsfälle:
- Verarbeitung natürlicher Sprache: Ein Unternehmen kann FedSGD verwenden, um ein Modell zu trainieren, das die Genauigkeit der Spracherkennung verbessert.
- Bilderkennung: Ein Unternehmen kann FedSGD verwenden, um ein Modell zu trainieren, das Objekte in Bildern erkennen kann.
- Vorhersagende Wartung: Ein Unternehmen kann FedSGD verwenden, um ein Modell zu trainieren, das vorhersagt, wann ein Gerät wahrscheinlich ausfällt.
- Föderierter Adam: Ein Algorithmus, der das Adam-Optimierungstool zum Aktualisieren der Modellparameter verwendet.
Typische Anwendungsfälle:
- Recommender-Systeme: Ein Unternehmen kann föderierten Adam verwenden, um ein Modell zu trainieren, das Nutzern Produkte basierend auf deren bisherigen Käufen empfiehlt.
- Ranking: Ein Unternehmen kann föderierten Adam verwenden, um ein Modell zu trainieren, das Suchergebnisse bewertet.
- Vorhersage der Klickrate: Ein Unternehmen kann föderierten Adam verwenden, um ein Modell zu trainieren, das die Wahrscheinlichkeit vorhersagt, dass ein Nutzer auf eine Anzeige klickt.
- Föderierte Mittelung: Ein Algorithmus, der den Durchschnitt der Modellparameter der teilnehmenden Clients ermittelt. Diese Architektur eignet sich besonders für Anwendungsfälle, bei denen die Daten relativ homogen sind und das Modell nicht zu komplex ist. Typische Anwendungsfälle:
Anwendungsfälle
In diesem Abschnitt werden Anwendungsfälle beschrieben, in denen die silo- und geräteübergreifenden Architekturen für Ihre Plattform für föderiertes Lernen geeignet sind.
Föderiertes Lernen ist eine Umgebung für maschinelles Lernen, in der viele Clients gemeinsam ein Modell trainieren. Dieser Prozess wird von einem zentralen Koordinator geleitet und die Trainingsdaten bleiben dezentral.
Beim föderierten Lernen laden Clients ein globales Modell herunter und verbessern das Modell, indem sie lokal mit ihren Daten trainieren. Anschließend sendet jeder Client seine berechneten Modellaktualisierungen zurück an den zentralen Server, wo die Modellaktualisierungen zusammengefasst und eine neue Iteration des globalen Modells generiert wird. In diesen Referenzarchitekturen werden die Arbeitslasten für das Modelltraining in GKE ausgeführt.
Föderiertes Lernen verbindet das Datenschutzprinzip der Datenminimierung. Dabei wird festgelegt, welche Daten in jeder Berechnungsphase erfasst werden, der Zugriff auf Daten beschränkt und die Daten werden verarbeitet und dann so früh wie möglich verworfen. Darüber hinaus ist die Problemeinstellung des föderierten Lernens mit zusätzlichen Datenschutztechniken kompatibel, z. B. der Verwendung von Differential Privacy (DP), um die Modellanonymisierung zu verbessern, damit das endgültige Modell nicht die Daten einzelner Nutzer speichert.
Je nach Anwendungsfall kann das Training von Modellen mit föderiertem Lernen zusätzliche Vorteile haben:
- Compliance: In einigen Fällen können Vorschriften einschränken, wie Daten verwendet oder weitergegeben werden dürfen. Föderiertes Lernen kann zur Einhaltung dieser Bestimmungen verwendet werden.
- Kommunikationseffizienz: In einigen Fällen ist es effizienter, ein Modell mit verteilten Daten zu trainieren, als die Daten zu zentralisieren. Beispielsweise sind die Datensätze, mit denen das Modell trainiert werden muss, zu groß, um zentral verschoben zu werden.
- Daten zugänglich machen: Mit föderiertem Lernen können Organisationen die Trainingsdaten dezentral in Datensilos pro Nutzer oder pro Organisation aufbewahren.
- Höhere Modellgenauigkeit: Durch das Training mit realen Nutzerdaten (unter Sicherstellung des Datenschutzes) anstelle von synthetischen Daten (manchmal auch als Proxydaten bezeichnet) führt dies häufig zu einer höheren Modellgenauigkeit.
Es gibt verschiedene Arten von föderiertem Lernen, die sich dadurch unterscheiden, woher die Daten stammen und wo die lokalen Berechnungen stattfinden. Die Architekturen in diesem Dokument konzentrieren sich auf zwei Arten des föderierten Lernens: silo- und geräteübergreifend. Andere Arten der föderierten Lerntechnologie werden in diesem Dokument nicht behandelt.
Die föderierte Lernmethode wird weiter nach der Partitionierung der Datasets kategorisiert. Dabei sind folgende Möglichkeiten verfügbar:
- Horizontales föderiertes Lernen (HFL): Datasets mit denselben Features (Spalten), aber unterschiedlichen Samples (Zeilen). So können beispielsweise mehrere Krankenhäuser Patientenakten mit denselben medizinischen Parametern, aber unterschiedlichen Patientengruppen haben.
- Vertikales föderiertes Lernen (VFL): Datasets mit denselben Beispielen (Zeilen), aber unterschiedlichen Features (Spalten). Beispielsweise haben eine Bank und ein E-Commerce-Unternehmen möglicherweise Kundendaten mit übereinstimmenden Personen, aber unterschiedlichen Finanz- und Kaufinformationen.
- Föderiertes Transfer-Lernen (FTL): Teilweise Überschneidung sowohl bei den Beispielen als auch bei den Features der Datasets. Beispiel: Zwei Krankenhäuser haben Patientenakten mit einigen überlappenden Personen und einigen gemeinsamen medizinischen Parametern, aber auch einzigartige Merkmale in jedem Datensatz.
Bei der siloübergreifenden föderierten Berechnung sind die teilnehmenden Mitglieder Organisationen oder Unternehmen. In der Praxis ist die Anzahl der Mitglieder normalerweise klein (z. B. bis zu 100 Mitglieder). Die siloübergreifende Berechnung wird in der Regel verwendet, wenn die beteiligten Organisationen verschiedene Datasets haben, aber ein gemeinsames Modell trainieren oder aggregierte Ergebnisse analysieren möchten, ohne ihre Rohdaten miteinander zu teilen. Teilnehmende Mitglieder können beispielsweise ihre Umgebungen in verschiedenen Google Cloud-Organisationen haben, z. B. wenn sie verschiedene Rechtspersönlichkeiten repräsentieren, oder in derselben Google Cloud-Organisation, z. B. wenn sie verschiedene Abteilungen derselben juristischen Person.
Teilnehmende Mitglieder können die Arbeitslasten anderer Mitglieder möglicherweise nicht als vertrauenswürdige Entitäten betrachten. Ein teilnehmendes Mitglied hat beispielsweise möglicherweise keinen Zugriff auf den Quellcode einer Trainingslast, die es von einem Drittanbieter wie dem Koordinator erhält. Da es nicht auf diesen Quellcode zugreifen kann, kann das teilnehmende Mitglied nicht sicher sein, dass die Arbeitslast vollständig vertrauenswürdig ist.
Um zu verhindern, dass eine nicht vertrauenswürdige Arbeitslast ohne Autorisierung auf Ihre Daten oder Ressourcen zugreift, empfehlen wir Folgendes:
- Stellen Sie nicht vertrauenswürdige Arbeitslasten in einer isolierten Umgebung bereit.
- Gewähren Sie nicht vertrauenswürdigen Arbeitslasten nur die unbedingt erforderlichen Zugriffsrechte und Berechtigungen, um die der Arbeitslast zugewiesenen Trainingsrunden abzuschließen.
Damit Sie potenziell nicht vertrauenswürdige Arbeitslasten isolieren können, implementieren diese Referenzarchitekturen Sicherheitskontrollen, z. B. die Konfiguration isolierter Kubernetes-Namespaces, wobei jeder Namespace einen dedizierten GKE-Knotenpool hat. Die netzwerkübergreifende Kommunikation sowie ein- und ausgehender Traffic im Cluster sind standardmäßig verboten, es sei denn, Sie überschreiben diese Einstellung ausdrücklich.
Beispielanwendungsfälle für das siloübergreifende föderierte Lernen:
- Betrugserkennung: Mit föderiertem Lernen kann ein Betrugserkennungsmodell anhand von Daten trainiert werden, die auf mehrere Organisationen verteilt sind. Ein Bankenkonsortium könnte beispielsweise mithilfe von föderiertem Lernen ein Modell trainieren, das betrügerische Transaktionen erkennt.
- Medizinische Diagnose: Mit föderiertem Lernen kann ein Modell für die medizinische Diagnose anhand von Daten trainiert werden, die auf mehrere Krankenhäuser verteilt sind. So könnte eine Gruppe von Krankenhäusern beispielsweise mithilfe von föderiertem Lernen ein Modell trainieren, das Krebs diagnostiziert.
Geräteübergreifendes föderiertes Lernen ist eine Art föderierter Datenverarbeitung, bei der die teilnehmenden Mitglieder Endnutzergeräte wie Smartphones, Fahrzeuge oder IoT-Geräte sind. Die Anzahl der Mitglieder kann Millionen oder sogar Dutzende von Millionen erreichen.
Der Vorgang für geräteübergreifendes föderiertes Lernen ähnelt dem Verfahren für siloübergreifendes föderiertes Lernen. Er erfordert jedoch auch die Anpassung der Referenzarchitektur, um einige der zusätzlichen Faktoren zu berücksichtigen, die Sie berücksichtigen müssen, wenn Sie mit Tausenden bis Millionen Geräten zu tun haben. Sie müssen administrative Arbeitslasten bereitstellen, um Szenarien zu bewältigen, die in Anwendungsfällen für geräteübergreifendes föderiertes Lernen auftreten. Beispielsweise müssen Sie eine Teilmenge der Kunden koordinieren, die am Training teilnehmen. Die geräteübergreifende Architektur bietet diese Möglichkeit, da Sie die FCP-Dienste bereitstellen können. Diese Dienste haben Arbeitslasten mit Verbindungspunkten zu TFF. TFF wird verwendet, um den Code zu schreiben, der diese Koordination verwaltet.
Beispielanwendungsfälle für das geräteübergreifende föderierte Lernen:
- Personalisierte Empfehlungen: Mithilfe geräteübergreifender föderierter Lernmethoden können Sie ein personalisiertes Empfehlungsmodell mit Daten trainieren, die auf mehreren Geräten verteilt sind. So kann ein Unternehmen beispielsweise föderiertes Lernen verwenden, um ein Modell zu trainieren, das Nutzern Produkte basierend auf ihrem bisherigen Kaufverlauf empfiehlt.
- Verarbeitung natürlicher Sprache: Mit föderiertem Lernen kann ein Modell für die Verarbeitung natürlicher Sprache anhand von Daten trainiert werden, die auf mehreren Geräten verteilt sind. Ein Unternehmen könnte beispielsweise mithilfe von föderiertem Lernen ein Modell trainieren, das die Genauigkeit der Spracherkennung verbessert.
- Vorhersage der Wartungsanforderungen von Fahrzeugen: Mithilfe von föderiertem Lernen kann ein Modell trainiert werden, das vorhersagt, wann ein Fahrzeug wahrscheinlich gewartet werden muss. Dieses Modell kann mit Daten trainiert werden, die von mehreren Fahrzeugen erfasst werden. So kann das Modell aus den Erfahrungen aller Fahrzeuge lernen, ohne die Privatsphäre einzelner Fahrzeuge zu gefährden.
In der folgenden Tabelle sind die Funktionen der silo- und geräteübergreifenden Architekturen zusammengefasst. Außerdem erfahren Sie, wie Sie das für Ihren Anwendungsfall geeignete Szenario für föderiertes Lernen kategorisieren.
| Funktion | Siloübergreifende föderierte Berechnungen | Geräteübergreifende föderierte Berechnungen |
|---|---|---|
| Bestandsgröße | In der Regel klein (z. B. bis zu 100 Geräte) | Skalierbar auf Tausende, Millionen oder Hunderte von Millionen von Geräten |
| Teilnehmende Mitglieder | Organisationen oder Unternehmen | Mobilgeräte, Edge-Geräte, Fahrzeuge |
| Häufigste Datenpartitionierung | HFL, VFL, FTL | HFL |
| Vertraulichkeit der Daten | Vertrauliche Daten, die die Teilnehmer nicht im Rohformat miteinander teilen möchten. | Daten, die zu sensibel sind, um mit einem zentralen Server geteilt zu werden |
| Datenverfügbarkeit | Die Teilnehmer sind fast immer verfügbar. | Es ist immer nur ein Bruchteil der Teilnehmer verfügbar. |
| Beispielanwendungsfälle | Betrugserkennung, medizinische Diagnose, Finanzprognosen | Fitness-Tracking, Spracherkennung, Bildklassifizierung |
Designaspekte
Dieser Abschnitt enthält eine Anleitung zur Verwendung dieser Referenzarchitektur, um eine oder mehrere Architekturen zu entwickeln, die Ihren spezifischen Anforderungen an Sicherheit, Zuverlässigkeit, operativer Effizienz, Kosten und Leistung entsprechen.
Designüberlegungen für eine siloübergreifende Architektur
Wenn Sie eine siloübergreifende Architektur für föderiertes Lernen in Google Cloud implementieren möchten, müssen Sie die folgenden Mindestvoraussetzungen implementieren, die in den folgenden Abschnitten ausführlicher erläutert werden:
- Konsortium des föderierten Lernens einrichten
- Legen Sie das Zusammenarbeitsmodell fest, das für das Konsortium des föderierten Lernens implementiert werden soll.
- Die Verantwortlichkeiten der teilnehmenden Organisationen festlegen
Zusätzlich zu diesen Voraussetzungen gibt es weitere Aktionen, die der Föderationsinhaber ausführen muss, die in diesem Dokument nicht behandelt werden. Dazu gehören z. B.:
- Konsortium des föderierten Lernens verwalten.
- Modell zur Zusammenarbeit entwerfen und implementieren.
- Modelltrainingsdaten sowie das Modell, das der Föderationsinhaber trainieren möchte, vorbereiten, verwalten und betreiben.
- Föderierte Lern-Workflows erstellen, containerisieren und orchestrieren.
- Workloads zum föderierten Lernen bereitstellen und verwalten.
- Einrichten der Kommunikationskanäle für die Teilnehmerorganisationen, um Daten sicher zu übertragen.
Föderiertes Lernen-konsortium einrichten
Ein Konsortium für föderiertes Lernen ist die Gruppe von Organisationen, die an Bemühungen zum siloübergreifenden föderierten Lernen beteiligt sind. Organisationen im Konsortium geben nur die Parameter der ML-Modelle weiter. Sie können diese Parameter verschlüsseln, um den Datenschutz zu verbessern. Wenn das Konsortium für föderiertes Lernen es zulässt, können Organisationen auch Daten zusammenfassen, die keine personenbezogenen Daten enthalten.
Zusammenarbeitsmodell für das föderierte Lernen-konsortium festlegen
Das Konsortium für föderiertes Lernen kann verschiedene Zusammenarbeitsmodelle implementieren, z. B.:
- Ein zentralisiertes Modell, das aus einer einzelnen koordinierenden Organisation besteht, die als Föderationsinhaber oder Orchestrator bezeichnet wird, und eine Reihe von Teilnehmerorganisationen oder Dateninhaber.
- Ein dezentralisiertes Modell, das aus Organisationen besteht, die als Gruppe koordinieren.
- Ein heterogenes Modell, das aus einem Konsortium verschiedener beteiligter Organisationen besteht, die verschiedene Ressourcen in das Konsortium einbringen.
In diesem Dokument wird davon ausgegangen, dass das Zusammenarbeitsmodell ein zentralisiertes Modell ist.
Die Verantwortlichkeiten der Teilnehmenden Organisationen festlegen
Nachdem Sie ein Zusammenarbeitsmodell für das Konsortium für föderiertes Lernen ausgewählt haben, muss der Föderationsinhaber die Verantwortlichkeiten für die Teilnehmerorganisationen festlegen.
Der Föderationsinhaber muss außerdem Folgendes tun, wenn er mit der Erstellung eines Konsortiums für föderiertes Lernen beginnt:
- Koordinieren der föderierten Lernbemühungen.
- Entwerfen und implementieren Sie das globale ML-Modell und die ML-Modelle, die Sie mit den Teilnehmerorganisationen teilen werden.
- Runden föderierten Lernens definieren – der Ansatz für die Iteration des ML-Trainingsprozesses.
- Auswählen der Teilnehmerorganisationen, die an der jeweiligen Runde föderierten Lernens beteiligt sind. Diese Auswahl wird als Kohorte bezeichnet.
- Entwerfen und Implementieren eines Überprüfungsverfahrens in Bezug auf die Konsortiumsmitgliedschaft für die Teilnehmerorganisationen.
- Aktualisieren Sie das globale ML-Modell und die ML-Modelle, die sie mit den Teilnehmerorganisationen teilen werden.
- Geben Sie den Teilnehmerorganisationen die Tools, um zu prüfen, ob das föderierte Lernkonsortium ihre Datenschutz-, Sicherheits- und behördlichen Anforderungen erfüllt.
- Bereitstellen sicherer und verschlüsselter Kommunikationskanäle für die Teilnehmerorganisationen.
- Bereitstellen aller erforderlichen nicht vertraulichen, aggregierten Daten, die die Teilnehmerorganisationen benötigen, um die einzelnen Runden föderierten Lernens durchzuführen.
Die Teilnehmerorganisationen sind für Folgendes verantwortlich:
- Eine sichere, isolierte Umgebung (ein Silo) bereitstellen und pflegen. Der Silo ist der Ort, an dem Teilnehmerorganisationen ihre eigenen Daten speichern und wo das ML-Modelltraining implementiert wird. Die teilnehmenden Organisationen geben ihre eigenen Daten nicht an andere Organisationen weiter.
- Trainieren der vom Föderationsinhaber bereitgestellten Modelle mit ihrer eigenen Recheninfrastruktur und ihren eigenen lokalen Daten.
- Freigeben der Ergebnisse des Modelltrainings für den Föderations-inhaber in Form von aggregierten Daten, nachdem die personenbezogene Daten entfernt wurden.
Der Inhaber der Föderation und die teilnehmenden Organisationen können über Cloud Storage aktualisierte Modelle und Trainingsergebnisse freigeben.
Der Föderationsinhaber und die Teilnehmerorganisationen optimieren das ML-Modelltraining, bis es ihre Anforderungen erfüllt.
Föderiertes Lernen in Google Cloud implementieren
Nachdem Sie das Konsortium für föderiertes Lernen eingerichtet und festgelegt haben, wie die Zusammenarbeit funktioniert, sollten die Teilnehmerorganisationen Folgendes tun:
- Notwendige Infrastruktur für das Konsortium für föderiertes Lernen bereitstellen und konfigurieren
- Das Zusammenarbeitsmodell Implementieren
- Maßnahmen für föderiertes Lernen starten
Infrastruktur für das föderierte Lernen-konsortium bereitstellen und konfigurieren
Bei der Bereitstellung und Konfiguration der Infrastruktur für das föderierte Lernkonsortium ist es die Aufgabe des Föderationseigentümers, die Arbeitslasten zu erstellen und zu verteilen an die Teilnehmerorganisationen, die die föderierten ML-Modelle trainieren. Da ein Drittanbieter (der Föderationsinhaber) die Arbeitslasten erstellt und bereitgestellt hat, müssen die Teilnehmerorganisationen bei der Bereitstellung dieser Arbeitslasten in ihren Laufzeitumgebungen gewisse Vorkehrungen treffen.
Teilnehmerorganisationen müssen ihre Umgebungen entsprechend ihren individuellen Best Practices für die Sicherheit konfigurieren und Kontrollen anwenden, die den Umfang und die Berechtigungen der einzelnen Arbeitslasten einschränken. Neben dem Beachten der individuellen Best Practices für die Sicherheit empfehlen wir, dass der Föderationsinhaber und die Teilnehmerorganisationen Bedrohungsvektoren berücksichtigen, die für das föderierte Lernen spezifisch sind.
Zusammenarbeitsmodell Implementieren
Nachdem die Infrastruktur des Konsortiums für föderiertes Lernen erstellt wurde, entwickelt und implementiert der Föderationsinhaber die Mechanismen, die die Interaktion zwischen den Teilnehmerorganisationen ermöglichen. Der Ansatz folgt dem Zusammenarbeitsmodell, das der Föderationsinhaber für das Konsortium für föderiertes Lernen ausgewählt hat.
Föderiertes Lernen starten
Nach der Implementierung des Zusammenarbeitsmodells implementiert der Föderationsinhaber das globale ML-Modell zum Trainieren und die ML-Modelle zur Freigabe für die Teilnehmerorganisation. Sobald diese ML-Modelle bereit sind, startet der Föderationsinhaber die erste Runde des föderierten Lernens.
Der Föderationsinhaber tut in jeder Runde des föderierten Lernens Folgendes:
- Er verteilt die ML-Modelle, die mit den Teilnehmerorganisationen geteilt werden sollen.
- Er wartet, bis die Teilnehmerorganisationen die Ergebnisse des Trainings der ML-Modelle geliefert haben, die der Föderationsinhaber mit ihnen geteilt hat.
- Er erfasst und verarbeitet die Trainingsergebnisse, die die Teilnehmerorganisationen erstellt haben.
- Er aktualisiert das globale ML-Modell, wenn er angemessene Trainingsergebnisse von beteiligten Organisationen erhält.
- Er aktualisiert die ML-Modelle, die mit den anderen Mitglieder des Konsortiums geteilt werden sollen, falls zutreffend.
- Er bereitet die Trainingsdaten für die nächste föderierte Lernrunde vor.
- Er startet die nächste Runde des föderierten Lernens.
Sicherheit, Datenschutz und Compliance
In diesem Abschnitt werden Faktoren beschrieben, die Sie bei der Verwendung dieser Referenzarchitektur zum Entwerfen und Erstellen einer Plattform für föderiertes Lernen in Google Cloud berücksichtigen sollten. Diese Empfehlungen gelten für beide Architekturen, die in diesem Dokument beschrieben werden.
Durch die Arbeitslasten für föderiertes Lernen, die Sie in Ihren Umgebungen bereitstellen, können Sie, Ihre Daten, Ihre Modelle für föderiertes Lernen und Ihre Infrastruktur Bedrohungen ausgesetzt sein, die sich auf Ihr Unternehmen auswirken könnten.
Damit Sie die Sicherheit Ihrer Umgebungen für föderiertes Lernen erhöhen können, konfigurieren diese Referenzarchitekturen GKE-Sicherheitskontrollen, die sich auf die Infrastruktur Ihrer Umgebungen konzentrieren. Diese Kontrollen sind möglicherweise nicht ausreichend, um Sie vor Bedrohungen zu schützen, die für Ihre Workloads und Anwendungsfälle für föderiertes Lernen spezifisch sind. Angesichts der Genauigkeit der einzelnen Arbeitslasten und Anwendungsfälle für föderiertes Lernen werden Sicherheitskontrollen, die zum Schutz Ihrer Implementierung für föderiertes Lernen dienen, in diesem Dokument nicht behandelt. Weitere Informationen und Beispiele zu diesen Bedrohungen finden Sie unter Sicherheitsaspekte für föderiertes Lernen.
GKE-Sicherheitskontrollen
In diesem Abschnitt werden die Steuerelemente erläutert, die Sie mit diesen Architekturen anwenden, um Ihren GKE-Cluster zu sichern.
Verbesserte Sicherheit von GKE-Clustern
Diese Referenzarchitekturen unterstützen Sie beim Erstellen eines GKE-Cluster mit den folgenden Sicherheitseinstellungen:
- Die Sichtbarkeit Ihrer Clusterknoten und Steuerungsebene auf das Internet beschränken. Dazu erstellen Sie einen privaten GKE-Cluster mit autorisierten Netzwerken.
- Shielded-Knoten verwenden, die ein gehärtetes Knoten-Image mit der Laufzeit
containerdnutzen. - Verbesserte Isolation von Mandantenarbeitslasten mithilfe von GKE Sandbox.
- Ruhende Daten standardmäßig verschlüsseln
- Daten bei der Übertragung standardmäßig verschlüsseln
- Secrets auf der Anwendungsebene verschlüsseln.
- Optional können Sie aktive Daten verschlüsseln, indem Sie Confidential Google Kubernetes Engine-Knoten aktivieren.
Weitere Informationen zu GKE-Sicherheitseinstellungen finden Sie unter Sicherheit Ihres Clusters erhöhen und Informationen zum Sicherheitsstatus-Dashboard.
VPC-Firewallregeln
VPC-Firewallregeln steuern, welcher Traffic zu oder von Compute Engine-VMs zugelassen wird. Mit den Regeln können Sie Traffic auf VM-Ebene in Abhängigkeit von Layer-4-Attributen filtern.
Sie erstellen einen GKE-Cluster mit den Standard-Firewallregeln für GKE-Cluster. Diese Firewallregeln ermöglichen die Kommunikation zwischen den Clusterknoten und der GKE-Steuerungsebene sowie zwischen Knoten und Pods im Cluster.
Sie wenden zusätzliche Firewallregeln auf die Knoten im Mandantenknotenpool an. Diese Firewallregeln beschränken den ausgehenden Traffic von den Mandantenknoten. Mit diesem Ansatz kann die Isolation von Mandantenknoten erhöht werden. Standardmäßig wird der gesamte ausgehende Traffic von den Mandantenknoten abgelehnt. Jeder erforderliche ausgehende Traffic muss explizit konfiguriert werden. Beispielsweise können Sie Firewallregeln erstellen, um ausgehenden Traffic von den Mandantenknoten zur GKE-Steuerungsebene und zu Google APIs mithilfe von privatem Google-Zugriff zuzulassen. Die Firewallregeln werden mithilfe des Dienstkontos für den Mandantenknotenpool auf die Mandantenknoten ausgerichtet.
Namespaces
Mit Namespaces können Sie einen Bereich für zusammengehörige Ressourcen innerhalb eines Clusters angeben, z. B. Pods, Dienste und Replikationscontroller. Durch die Verwendung von Namespaces können Sie die Verwaltungsverantwortung für die zugehörigen Ressourcen als Einheit delegieren. Daher sind Namespaces ein wichtiger Bestandteil der meisten Sicherheitsmuster.
Namespaces sind ein wichtiges Feature zur Isolierung von Steuerungsebenen. Sie bieten jedoch keine Isolation von Knoten, Datenebenen oder Netzwerken.
Ein gängiger Ansatz besteht darin, Namespaces für einzelne Anwendungen zu erstellen. Sie können beispielsweise den Namespace myapp-frontend für die UI-Komponente einer Anwendung erstellen.
Diese Referenzarchitekturen helfen Ihnen, einen speziellen Namespace zum Hosten der Drittanbieter-Apps zu erstellen. Der Namespace und seine Ressourcen werden innerhalb Ihres Clusters als Mandanten behandelt. Sie wenden Richtlinien und Steuerelemente auf den Namespace an, um den Umfang der Ressourcen im Namespace einzuschränken.
Netzwerkrichtlinien
Netzwerkrichtlinien erzwingen Layer-4-Netzwerk-Trafficflüsse mithilfe von Firewallregeln auf Pod-Ebene. Netzwerkrichtlinien sind auf einen Namespace beschränkt.
In den Referenzarchitekturen, die in diesem Dokument beschrieben werden, wenden Sie Netzwerkrichtlinien auf den Mandanten-Namespace an, in dem die Anwendungen von Drittanbietern gehostet werden. Standardmäßig lehnt die Netzwerkrichtlinie den gesamten Traffic zu und von Pods im Namespace ab. Jeder erforderliche Traffic muss explizit einer Zulassungsliste hinzugefügt werden. Beispielsweise lassen die Netzwerkrichtlinien in diesen Referenzarchitekturen explizit Traffic zu den erforderlichen Clusterdiensten wie dem internen Cluster-DNS und der Steuerungsebene von Cloud Service Mesh zu.
Config Sync
Config Sync synchronisiert Ihre GKE-Cluster mit Konfigurationen, die in einem Git-Repository gespeichert sind. Das Git-Repository fungiert als zentrale Informationsquelle für Ihre Clusterkonfiguration und -richtlinien. Config Sync ist deklarativ. Der Dienst prüft kontinuierlich den Clusterstatus und wendet den in der Konfigurationsdatei deklarierten Status zur Erzwingung von Richtlinien an. Dadurch werden Abweichungen von der Konfiguration verhindert.
Sie installieren Config Sync in Ihrem GKE-Cluster. Sie konfigurieren Config Sync so, dass Clusterkonfigurationen und -richtlinien aus einem Cloud Source-Repository synchronisiert werden. Die synchronisierten Ressourcen umfassen Folgendes:
- Cloud Service Mesh-Konfiguration auf Clusterebene
- Sicherheitsrichtlinien auf Clusterebene
- Konfiguration und Richtlinie auf Mandantenebene, darunter Netzwerkrichtlinien, Dienstkonten, RBAC-Regeln und die Cloud Service Mesh-Konfiguration
Policy Controller
Policy Controller von Google Kubernetes Engine (GKE) Enterprise ist ein dynamischer Admission-Controller für Kubernetes, der CRD-basierte Richtlinien (CustomResourceDefinition) erzwingt, die durch den Open Policy Agent (OPA) ausgeführt werden.
Zugangssteuerungen sind Kubernetes-Plug-ins, die Anfragen an den Kubernetes API-Server abfangen, bevor ein Objekt beibehalten wird, aber nachdem die Anfrage authentifiziert und autorisiert wurde. Sie können die Verwendung von Clustern mithilfe von Zugangssteuerungen einschränken.
Sie installieren Policy Controller in Ihrem GKE-Cluster. Diese Referenzarchitekturen enthalten Beispielrichtlinien, um Ihren Cluster zu schützen. Sie wenden die Richtlinien automatisch mit Config Sync auf Ihren Cluster an. Sie wenden die folgenden Richtlinien an:
- Ausgewählte Richtlinien zur Durchsetzung der Pod-Sicherheit. Beispiel: Sie wenden Richtlinien an, die verhindern, dass Pods privilegierte Container ausführen, die ein schreibgeschütztes Root-Dateisystem benötigen.
- Richtlinien aus der Vorlagenbibliothek von Policy Controller. Sie wenden beispielsweise eine Richtlinie an, die keine Dienste vom Typ NodePort zulässt.
Cloud Service Mesh
Cloud Service Mesh ist ein Service Mesh, mit dem Sie die Verwaltung sicherer Kommunikation zwischen Diensten vereinfachen können. Mit diesen Referenzarchitekturen wird Cloud Service Mesh so konfiguriert, dass die Lösung Folgendes tut:
- Sidecar-Proxys werden automatisch eingefügt.
- mTLS-Kommunikation zwischen Diensten im Mesh-Netzwerk erzwingen.
- Ausgehenden Mesh-Traffic auf bekannte Hosts beschränken.
- Eingehenden Traffic auf bestimmte Clients beschränken.
- Hiermit können Sie Netzwerksicherheitsrichtlinien konfigurieren, die auf der Dienstidentität basieren und nicht auf der IP-Adresse von Peers im Netzwerk.
- Autorisierte Kommunikation zwischen Diensten im Mesh-Netzwerk beschränken. Anwendungen im Mandanten-Namespace können beispielsweise nur mit Anwendungen im selben Namespace oder mit einer Reihe bekannter externer Hosts kommunizieren.
- Leitet den gesamten ein- und ausgehenden Traffic über Mesh-Gateways weiter, auf denen Sie weitere Trafficsteuerungen anwenden können.
- Unterstützt die sichere Kommunikation zwischen Clustern.
Knotenmarkierungen und -affinitäten
Knotenmarkierungen und Knotenaffinität sind Kubernetes-Mechanismen, mit denen Sie die Planung von Pods auf Clusterknoten beeinflussen können.
Markierungsknoten verwerfen Pods. Kubernetes plant einen Pod nicht auf einem markierten Knoten, es sei denn, der Pod hat eine Toleranz für die Markierung. Sie können mit Knotenmarkierungen Knoten für bestimmte Arbeitslasten oder Mandanten reservieren. Markierungen und Toleranzen werden häufig in mehrmandantenfähigen Clustern verwendet. Weitere Informationen finden Sie in der Dokumentation zu dedizierten Knoten mit Markierungen und Toleranzen.
Mit der Knotenaffinität können Sie Pods auf Knoten mit bestimmten Labels beschränken. Wenn ein Pod eine Knotenaffinitätsanforderung hat, plant Kubernetes den Pod nur dann auf einem Knoten, wenn dieser ein der Affinitätsanforderung entsprechendes Label hat. Mit der Knotenaffinität können Sie dafür sorgen, dass Pods auf geeigneten Knoten geplant werden.
Sie können Knotenmarkierungen und Knotenaffinität zusammen verwenden, um dafür zu sorgen, dass Pods von Mandanten-Arbeitslasten ausschließlich auf Knoten geplant werden, die für den Mandanten reserviert sind.
Mit diesen Referenzarchitekturen können Sie die Planung der Mandantenanwendungen so steuern:
- GKE-Knotenpool für den Mandanten erstellen. Jeder Knoten im Pool hat eine Markierung für den Mandantennamen.
- Die entsprechende Toleranz und Knotenaffinität wird automatisch auf jeden Pod angewendet, der auf den Mandanten-Namespace ausgerichtet ist. Sie wenden Toleranz und Affinität mit PolicyController-Mutationen an.
Geringste Berechtigung
Es ist eine bewährte Sicherheitsmethode, das Prinzip der geringsten Berechtigung für Ihre Google Cloud-Projekte und -Ressourcen wie GKE-Cluster anzuwenden. Auf diese Weise haben die Anwendungen, die in Ihrem Cluster ausgeführt werden, und die Entwickler und Operatoren, die den Cluster verwenden, nur die erforderlichen Mindestberechtigungen.
Diese Referenzarchitekturen unterstützen Sie auf folgende Weise bei der Verwendung von Dienstkonten mit minimalen Berechtigungen:
- Jeder GKE-Knotenpool erhält ein eigenes Dienstkonto. Beispielsweise verwenden die Knoten im Mandantenknotenpool ein Dienstkonto, das diesen Knoten zugeordnet ist. Die Knoten-Dienstkonten werden mit den erforderlichen Mindestberechtigungen konfiguriert.
- Der Cluster verwendet Workload Identity Federation for GKE, um Kubernetes-Dienstkonten mit Google-Dienstkonten zu verknüpfen. Auf diese Weise können die Mandantenanwendungen eingeschränkten Zugriff auf alle erforderlichen Google APIs erhalten, ohne einen Dienstkontoschlüssel herunterladen und speichern zu müssen. Beispielsweise können Sie dem Dienstkonto Berechtigungen zum Lesen von Daten aus einem Cloud Storage-Bucket erteilen.
Mit diesen Referenzarchitekturen können Sie den Zugriff auf Clusterressourcen auf folgende Weise einschränken:
- Sie erstellen eine Kubernetes-RBAC-Beispielrolle mit eingeschränkten Berechtigungen zum Verwalten von Anwendungen. Sie können diese Rolle den Nutzern und Gruppen zuweisen, die die Anwendungen im Mandanten-Namespace ausführen. Durch Anwenden dieser eingeschränkten Rolle von Nutzern und Gruppen sind diese Nutzer nur berechtigt, Anwendungsressourcen im Mandanten-Namespace zu ändern. Sie sind nicht berechtigt, Ressourcen auf Clusterebene oder sensible Sicherheitseinstellungen wie Cloud Service Mesh-Richtlinien zu ändern.
Binärautorisierung
Mit der Binärautorisierung können Sie Richtlinien erzwingen, die Sie für die Container-Images definieren, die in Ihrer GKE-Umgebung bereitgestellt werden. Mit der Binärautorisierung können nur Container-Images bereitgestellt werden, die Ihren definierten Richtlinien entsprechen. Das Bereitstellen anderer Container-Images ist nicht zulässig.
In dieser Referenzarchitektur ist die Binärautorisierung mit der Standardkonfiguration aktiviert. Informationen zur Standardkonfiguration der Binärautorisierung finden Sie unter YAML-Richtliniendatei exportieren.
Weitere Informationen zum Konfigurieren von Richtlinien finden Sie in den folgenden Anleitungen:
- Google Cloud CLI
- Google Cloud Console
- REST API
- Die Terraform-Ressource
google_binary_authorization_policy
Organisationsübergreifende Attestierungsprüfung
Mit der Binärautorisierung können Sie Attestierungen prüfen, die von einem Drittanbietersignaturgeber generiert wurden. In einem siloübergreifenden Anwendungsfall für föderiertes Lernen können Sie beispielsweise Attestierungen prüfen, die von einer anderen teilnehmenden Organisation erstellt wurden.
So überprüfen Sie die von einem Drittanbieter erstellten Attestierungen:
- Sie erhalten die öffentlichen Schlüssel, mit denen der Drittanbieter die Attestationen erstellt hat, die Sie überprüfen müssen.
- Erstellen Sie die Attestierer, um die Attestierungen zu bestätigen.
- Fügen Sie den von Ihnen erstellten Attestierern die öffentlichen Schlüssel hinzu, die Sie vom Drittanbieter erhalten haben.
Weitere Informationen zum Erstellen von Attestierern finden Sie in den folgenden Anleitungen:
- Google Cloud CLI
- Google Cloud Console
- REST API
- die Terraform-Ressource
google_binary_authorization_attestor
GKE-Compliance-Dashboard
Das GKE-Compliance-Dashboard bietet umsetzbare Informationen zur Verbesserung Ihres Sicherheitsstatus und hilft Ihnen, die Compliance-Berichterstellung für Branchenstandards und -standards zu automatisieren. Sie können GKE-Cluster registrieren, um automatisierte Compliance-Berichte zu aktivieren.
Weitere Informationen finden Sie unter GKE-Compliance-Dashboard.
Sicherheitsaspekte für föderiertes Lernen
Trotz des strengen Datenfreigabemodells ist das föderierte Lernen nicht von Natur aus sicher vor allen gezielten Angriffen. Sie sollten diese Risiken berücksichtigen, wenn Sie eine der in diesem Dokument beschriebenen Architekturen bereitstellen. Es besteht auch das Risiko unbeabsichtigter Informationslecks zu ML-Modellen oder Modelltrainingsdaten. Ein Angreifer könnte beispielsweise absichtlich das globale ML-Modell oder die Runden des föderierten Lernverfahrens manipulieren oder einen Zeitangriff (eine Art von Nebenkanalangriff) ausführen. um Informationen über die Größe der Trainings-Datasets zu sammeln.
Im Folgenden sind die häufigsten Bedrohungen für eine Implementierung föderierten Lernens aufgeführt:
- Absichtliche oder unabsichtliche Speicherung von Trainingsdaten. Ihre Implementierung föderierten Lernens oder ein Angreifer speichert Daten möglicherweise absichtlich oder unabsichtlich auf eine Weise, die es schwierig macht, damit zu arbeiten. Ein Angreifer kann möglicherweise durch Reverse Engineering der gespeicherten Daten Informationen zum globalen ML-Modell oder zu früheren Runden des föderierten Lernens erfassen ermitteln.
- Informationen aus Aktualisierungen des globalen ML-Modells extrahieren. Während des föderierten Lernens kann ein Angreifer Reverse Engineering auf die Aktualisierungen des globalen ML-Modells anwenden, die der Föderationsinhaber von Teilnehmerorganisationen und -geräten erfasst.
- Der Föderationsinhaber kann Runden manipulieren. Ein manipulierter Föderationsinhaber kann einen böswilligen Silo steuern und eine föderierte Lernrunde starten. Am Ende der Runde kann der manipulierte Föderationsinhaber möglicherweise Informationen zu den Aktualisierungen erfassen, die er von legitimen Teilnehmerorganisationen und Geräten erfasst, indem er diese Aktualisierungen mit denen vergleicht, die der schädliche Silo erstellt hat.
- Teilnehmerorganisationen und ‑geräte können das globale ML-Modell manipulieren. Während des föderierten Lernens kann ein Angreifer versuchen, die Leistung, die Qualität oder die Integrität des globalen ML-Modells nachteilig zu beeinflussen, indem er schädliche oder belanglose Aktualisierungen erzeugt.
Um die Auswirkungen der in diesem Abschnitt beschriebenen Bedrohungen zu mindern, empfehlen wir die folgenden Best Practices:
- Passen Sie das Modell so an, dass die Speicherung von Trainingsdaten auf ein Minimum reduziert wird.
- Implementieren von Datenschutzmechanismen.
- Prüfen Sie regelmäßig das globale ML-Modell, die ML-Modelle, die Sie freigeben möchten, die Trainingsdaten und die Infrastruktur, die Sie implementiert haben, um Ihre Ziele für föderiertes Lernen zu erreichen.
- Implementieren eines sicheren Aggregationsalgorithmus, um die Trainingsergebnisse zu verarbeiten, die von den Teilnehmerorganisationen erstellt werden.
- Datenverschlüsselungsschlüssel mit einer Public-Key-Infrastruktur sicher generieren und verteilen.
- Infrastruktur auf einer Confidential Computing-Plattform bereitstellen.
Föderationsinhaber müssen außerdem die folgenden zusätzlichen Schritte ausführen:
- Identität jeder Teilnehmerorganisation und die Integrität jedes Silos bei siloübergreifenden Architekturen sowie die Identität und Integrität jedes Geräts bei geräteübergreifenden Architekturen prüfen.
- Umfang der Updates für das globale ML-Modell beschränken, die Teilnehmerorganisationen und Geräte erstellen können.
Zuverlässigkeit
In diesem Abschnitt werden Designfaktoren beschrieben, die Sie berücksichtigen sollten, wenn Sie eine der Referenzarchitekturen in diesem Dokument verwenden, um eine Plattform zum föderierten Lernen in Google Cloud zu entwerfen und zu erstellen.
Wenn Sie Ihre Architektur für das föderierte Lernen in Google Cloud entwerfen, sollten Sie der Anleitung in diesem Abschnitt folgen, um die Verfügbarkeit und Skalierbarkeit der Arbeitslast zu verbessern und Ihre Architektur widerstandsfähig gegen Ausfälle und Katastrophen zu machen.
GKE: GKE unterstützt mehrere verschiedene Clustertypen, die Sie an die Verfügbarkeitsanforderungen Ihrer Arbeitslasten und Ihr Budget anpassen können. Sie können beispielsweise regionale Cluster erstellen, bei denen die Steuerungsebene und die Knoten auf mehrere Zonen innerhalb einer Region verteilt werden, oder zonale Cluster, bei denen die Steuerungsebene und die Knoten in einer einzelnen Zone liegen. Sowohl silo- als auch geräteübergreifende Referenzarchitekturen basieren auf regionalen GKE-Clustern. Weitere Informationen zu den Aspekten, die beim Erstellen von GKE-Clustern zu berücksichtigen sind, finden Sie unter Auswahlmöglichkeiten für die Clusterkonfiguration.
Je nach Clustertyp und Verteilung der Steuerungsebene und der Clusterknoten auf Regionen und Zonen bietet GKE verschiedene Funktionen zur Notfallwiederherstellung, um Ihre Arbeitslasten vor zonalen und regionalen Ausfällen zu schützen. Weitere Informationen zu den Notfallwiederherstellungsfunktionen von GKE finden Sie unter Architektur der Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur: Google Kubernetes Engine.
Google Cloud Load Balancing: GKE unterstützt mehrere Möglichkeiten zum Load Balancing von Traffic für Ihre Arbeitslasten. Mit den GKE-Implementierungen der Kubernetes Gateway und Kubernetes Service APIs können Sie Cloud Load Balancing automatisch bereitstellen und konfigurieren, um die in Ihren GKE-Clustern ausgeführten Arbeitslasten sicher und zuverlässig verfügbar zu machen.
In diesen Referenzarchitekturen wird der gesamte eingehende und ausgehende Traffic über Cloud Service Mesh-Gateways geleitet. Mit diesen Gateways können Sie den Traffic innerhalb und außerhalb Ihrer GKE-Cluster genau steuern.
Zuverlässigkeitsprobleme beim geräteübergreifenden föderierten Lernen
Beim geräteübergreifenden föderierten Lernen gibt es eine Reihe von Zuverlässigkeitsherausforderungen, die bei siloübergreifenden Szenarien nicht auftreten. Dazu gehören die folgenden:
- Unzuverlässige oder unterbrochene Geräteverbindung
- Begrenzter Gerätespeicher
- Begrenzte Rechen- und Arbeitsspeicherressourcen
Eine unsichere Verbindung kann zu folgenden Problemen führen:
- Veraltete Updates und Modellabweichungen: Wenn die Verbindung zu Geräten unterbrochen wird, sind die lokalen Modellupdates möglicherweise veraltet und enthalten im Vergleich zum aktuellen Zustand des globalen Modells veraltete Informationen. Das Aggregieren veralteter Updates kann zu Modellabweichungen führen, bei denen das globale Modell aufgrund von Inkonsistenzen im Trainingsablauf von der optimalen Lösung abweicht.
- Ungleichmäßige Beiträge und verzerrte Modelle: Eine unterbrochene Kommunikation kann zu einer ungleichmäßigen Verteilung der Beiträge der teilnehmenden Geräte führen. Geräte mit schlechter Konnektivität tragen möglicherweise weniger Updates bei, was zu einer ungleichmäßigen Darstellung der zugrunde liegenden Datenverteilung führt. Dieses Ungleichgewicht kann das globale Modell in Richtung der Daten von Geräten mit zuverlässigeren Verbindungen verzerren.
- Erhöhter Kommunikationsoverhead und höherer Energieverbrauch: Eine unterbrochene Kommunikation kann zu einem erhöhten Kommunikationsoverhead führen, da verlorene oder beschädigte Updates möglicherweise noch einmal gesendet werden müssen. Dieses Problem kann auch den Energieverbrauch von Geräten erhöhen, insbesondere bei Geräten mit begrenzter Akkulaufzeit, da möglicherweise längere Zeit aktive Verbindungen aufrechterhalten werden müssen, um eine erfolgreiche Übertragung von Updates zu ermöglichen.
Um einige der Auswirkungen zu minimieren, die durch unterbrochene Kommunikation verursacht werden, können die Referenzarchitekturen in diesem Dokument mit dem FCP verwendet werden.
Eine Systemarchitektur, die das FCP-Protokoll ausführt, kann so konzipiert werden, dass sie die folgenden Anforderungen erfüllt:
- Runden mit langer Ausführungszeit verarbeiten
- Spekulative Ausführung aktivieren. Runden können gestartet werden, bevor die erforderliche Anzahl von Clients zusammengestellt wird, in der Erwartung, dass mehr Prüfungen bald eingehen.
- Geräten erlauben, auszuwählen, an welchen Aufgaben sie teilnehmen möchten Dieser Ansatz ermöglicht Funktionen wie die Stichprobenerhebung ohne Zurücklegen, bei der jede Stichprobeneinheit einer Population nur einmal ausgewählt werden kann. Dieser Ansatz hilft, ungleichmäßige Beiträge und verzerrte Modelle zu vermeiden.
- Erweiterbar für Anonymisierungstechniken wie Differential Privacy (DP) und Trusted Aggregation (TAG).
Die folgenden Methoden können helfen, die begrenzten Speicher- und Rechenkapazitäten von Geräten zu kompensieren:
- Maximale Kapazität für die Ausführung der Berechnung für die föderierte Lerntechnologie ermitteln
- Informationen dazu, wie viele Daten zu einem bestimmten Zeitpunkt gespeichert werden können
- Entwerfen Sie den clientseitigen Code für föderiertes Lernen so, dass er innerhalb der auf den Clients verfügbaren Rechenleistung und des verfügbaren RAM ausgeführt werden kann.
- Auswirkungen von Speicherplatzmangel verstehen und einen Prozess zur Verwaltung dieser Auswirkungen implementieren
Kostenoptimierung
In diesem Abschnitt finden Sie eine Anleitung zum Optimieren der Kosten für das Erstellen und Ausführen der Plattform für föderiertes Lernen in Google Cloud, die Sie mithilfe dieser Referenzarchitektur einrichten. Diese Empfehlungen gelten für beide Architekturen, die in diesem Dokument beschrieben werden.
Wenn Sie Arbeitslasten in GKE ausführen, können Sie Ihre Umgebung kostenoptimieren, indem Sie Ihre Cluster entsprechend den Ressourcenanforderungen Ihrer Arbeitslasten bereitstellen und konfigurieren. Außerdem werden Funktionen aktiviert, mit denen Ihre Cluster und Clusterknoten dynamisch neu konfiguriert werden können, z. B. die automatische Skalierung von Clusterknoten und Pods sowie die richtige Größe Ihrer Cluster.
Weitere Informationen zur Kostenoptimierung Ihrer GKE-Umgebungen finden Sie unter Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE.
Operative Effizienz
In diesem Abschnitt werden die Faktoren beschrieben, die Sie zur Optimierung der Effizienz berücksichtigen sollten, wenn Sie diese Referenzarchitektur zum Erstellen und Ausführen einer Plattform zum föderierten Lernen in Google Cloud verwenden. Diese Hinweise gelten für beide in diesem Dokument beschriebenen Architekturen.
Um die Automatisierung und Überwachung Ihrer föderierten Lernarchitektur zu verbessern, empfehlen wir die Anwendung von MLOps-Prinzipien, also DevOps-Prinzipien im Kontext von Systemen für maschinelles Lernen. MLOps zu praktizieren bedeutet, auf Automatisierung und Überwachung zu setzen, und zwar in allen Phasen der ML-Systemkonfiguration wie Integration, Testen, Freigabe, Bereitstellung und Infrastrukturverwaltung. Weitere Informationen zu MLOps finden Sie unter MLOps: Continuous Delivery und Pipelines zur Automatisierung im maschinellen Lernen.
Leistungsoptimierung
In diesem Abschnitt werden die Faktoren beschrieben, die Sie zur Optimierung der Leistung Ihrer Arbeitslasten berücksichtigen sollten, wenn Sie diese Referenzarchitektur zum Erstellen und Ausführen einer Plattform zum föderierten Lernen in Google Cloud verwenden. Diese Hinweise gelten für beide Architekturen, die in diesem Dokument beschrieben werden.
GKE unterstützt mehrere Funktionen, mit denen Sie Ihre GKE-Umgebung automatisch und manuell anpassen und skalieren können, um die Anforderungen Ihrer Arbeitslasten zu erfüllen und eine Überdimensionierung von Ressourcen zu vermeiden. So können Sie beispielsweise Recommender verwenden, um Statistiken und Empfehlungen zur Optimierung der GKE-Ressourcennutzung zu generieren.
Wenn Sie darüber nachdenken, wie Sie Ihre GKE-Umgebung skalieren möchten, empfehlen wir Ihnen, kurzfristige, mittelfristige und langfristige Pläne für die Skalierung Ihrer Umgebungen und Arbeitslasten zu entwerfen. Wie möchten Sie beispielsweise Ihre GKE-Nutzung in einigen Wochen, Monaten und Jahren ausweiten? Mit einem Plan können Sie die Skalierungsfunktionen von GKE optimal nutzen, Ihre GKE-Umgebungen optimieren und Kosten senken. Weitere Informationen zur Planung der Cluster- und Arbeitslastskalierung finden Sie unter Skalierbarkeit von GKE.
Um die Leistung Ihrer ML-Arbeitslasten zu erhöhen, können Sie Cloud Tensor Processing Units (Cloud TPUs) verwenden. Dies sind von Google entwickelte KI-Beschleuniger, die für Training und Inferenz von großen KI-Modellen optimiert sind.
Bereitstellung
Informationen zum Bereitstellen der in diesem Dokument beschriebenen silo- und geräteübergreifenden Referenzarchitekturen finden Sie im GitHub-Repository Federated Learning on Google Cloud.
Nächste Schritte
- Erfahren Sie, wie Sie Ihre Algorithmen für föderiertes Lernen auf der TensorFlow Federated-Platform implementieren.
- Weitere Informationen zu Fortschritten und ungelösten Problemen im föderierten Lernen
- Mehr über föderiertes Lernen im Google AI-Blog erfahren
- Video: Google schützt die Privatsphäre, wenn es föderiertes Lernen mit de-identifizierten, aggregierten Informationen verwendet, um ML-Modelle zu verbessern
- Lesen Sie Towards Federated learning at scale.
- Hier erfahren Sie, wie Sie eine MLOps-Pipeline implementieren können, um den Lebenszyklus der Modelle für maschinelles Lernen zu verwalten.
- Einen Überblick über die Prinzipien und Empfehlungen, die speziell für KI- und ML-Arbeitslasten in Google Cloud gelten, finden Sie im Architektur-Framework unter KI und ML.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autoren:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect
Weitere Beitragende:
- Chloé Kiddon | Staff Software Engineer und Manager
- Laurent Grangeau | Solutions Architect
- Lilian Felix | Cloud Engineer