このドキュメントでは、Google Cloud でマネージド プロダクトを使用して CI / CD メソッドを実装し、データ処理用の継続的インテグレーション / 継続的デプロイ(CI / CD)パイプラインを設定する方法について説明します。データ サイエンティストやアナリストは CI / CD の方法論を応用して、品質、保守性、適応性に優れたデータ処理とワークフローを実現できます。適用できる手法は次のとおりです。
- ソースコードのバージョン管理
- アプリの自動的なビルド、テスト、デプロイ
- 本番環境からの環境分離
- 環境設定のための複製可能な手順
このドキュメントは、繰り返し実行されるデータ処理ジョブを構築するデータ サイエンティストやアナリストを対象としており、研究開発(R&D)を構造化してデータ処理ワークロードを体系的かつ自動的に維持するのに役立ちます。
アーキテクチャ
次の図に、CI / CD パイプライン ステップの詳細を示します。

テスト環境と本番環境へのデプロイが 2 つの異なる Cloud Build パイプライン(テスト パイプラインと本番環境パイプライン)に分かれています。
上の図では、テスト パイプラインは以下のステップで構成されています。
- デベロッパーがコードの変更を Cloud Source Repositories に commit します。
- コードの変更によって Cloud Build でテストビルドがトリガーされます。
- Cloud Build が自己実行型 JAR ファイルをビルドし、それを Cloud Storage のテスト用 JAR バケットにデプロイします。
- Cloud Build がテストファイルを Cloud Storage のテストファイル バケットにデプロイします。
- Cloud Build が、新しくデプロイされた JAR ファイルを参照するように Cloud Composer の変数を設定します。
- Cloud Build が、データ処理ワークフローの有向非巡回グラフ(DAG)をテストし、Cloud Storage の Cloud Composer バケットにデプロイします。
- このワークフローの DAG ファイルが Cloud Composer にデプロイされます。
- Cloud Build が、新しくデプロイされたデータ処理ワークフローの実行をトリガーします。
- データ処理ワークフローの統合テストに合格すると、メッセージが Pub/Sub に公開されます。ここには、メッセージのデータ フィールド内の最新の自己実行型 JAR(Airflow 変数から取得)への参照が含まれます。
上の図では、本番環境パイプラインは以下のステップで構成されています。
- Pub/Sub トピックにメッセージが公開されると、本番環境のデプロイ パイプラインがトリガーされます。
- デベロッパーが本番環境デプロイ パイプラインを手動で承認し、ビルドが実行されます。
- Cloud Build が、最新の自己実行型 JAR ファイルを Cloud Storage のテスト用 JAR バケットから本番環境用 JAR バケットにコピーします。
- Cloud Build が、本番環境用データ処理ワークフロー DAG をテストし、Cloud Storage の Cloud Composer バケットにデプロイします。
- 本番環境用のワークフロー DAG ファイルが Cloud Composer にデプロイされます。
このリファレンス アーキテクチャのドキュメントでは、本番環境用データ処理ワークフローをテスト用ワークフローと同じ Cloud Composer 環境にデプロイして、すべてのデータ処理ワークフローを一元的に確認できるようにします。このリファレンス アーキテクチャでは、異なる Cloud Storage バケットに入出力データを保持することで、環境を分離しています。
環境を完全に分離するには、異なるプロジェクト内に作成された複数の Cloud Composer 環境が必要です。このようにして作成された環境はデフォルトで分離され、本番環境を保護するのに役立ちます。ただし、このアプローチは本チュートリアルの対象範囲外です。複数の Google Cloud プロジェクトのリソースにアクセスする方法の詳細については、サービス アカウント権限の設定をご覧ください。
データ処理ワークフロー
Cloud Composer がデータ処理ワークフローを実行する手順は、Python で書かれた DAG で定義されます。DAG では、データ処理ワークフローのすべてのステップが、それぞれの依存関係とともに定義されます。
CI / CD パイプラインは毎回のビルドの中で、DAG 定義を Cloud Source Repositories から Cloud Composer に自動的にデプロイします。このプロセスにより、Cloud Composer のワークフロー定義は人の手を介さなくても常に最新の状態に保たれます。
テスト環境用の DAG 定義では、データ処理ワークフローに加えてエンドツーエンドのテストステップが定義されています。テストステップは、データ処理ワークフローが正しく実行されることを確認するのに役立ちます。
次の図に、データ処理ワークフローを示します。
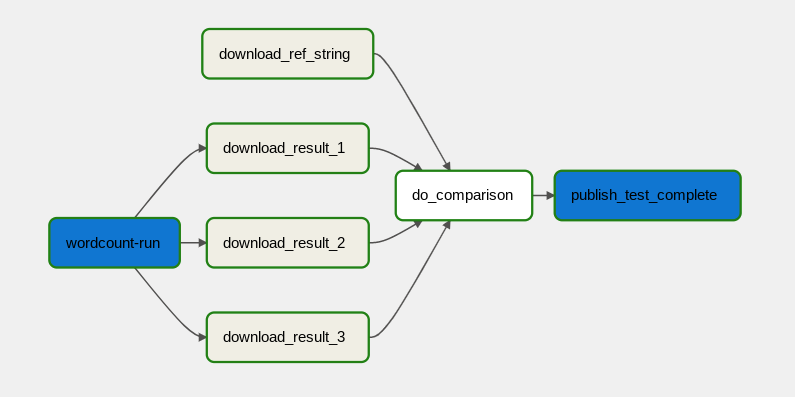
データ処理ワークフローは次のステップで構成されます。
- Dataflow で WordCount データ処理を実行します。
WordCount プロセスの出力ファイルをダウンロードします。WordCount プロセスは次の 3 つのファイルを出力します。
download_result_1download_result_2download_result_3
download_ref_stringという名前の参照ファイルをダウンロードします。この参照ファイルと照らし合わせて結果を検証します。この統合テストでは、3 つの結果すべてを集計して、集計結果を参照ファイルと比較します。
統合テストに合格したら、メッセージを Pub/Sub に公開します。
Cloud Composer などのタスク オーケストレーション フレームワークを使用してデータ処理ワークフローを管理すると、ワークフローのコードの複雑さを軽減できます。
費用の最適化
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
次のステップ
- Cloud Build を使用した GitOps スタイルの継続的デリバリーの詳細を見る。
- 一般的な Dataflow のユースケース パターンの詳細を確認する。
- リリース エンジニアリングの詳細を見る。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。