Questo documento descrive come eseguire il deployment dell'architettura in Utilizza una pipeline CI/CD per i flussi di lavoro di elaborazione dati.
Questo deployment è destinato a data scientist e analisti che creano in esecuzione di job di elaborazione dati per strutturare le attività di ricerca e sviluppo di ricerca e sviluppo, per gestire in modo sistematico e automatico i carichi di lavoro di elaborazione dei dati.
I data scientist e gli analisti possono adattare le metodologie dalle pratiche CI/CD a contribuiscono a garantire l'alta qualità, la manutenibilità e l'adattabilità dei dati processi e flussi di lavoro. I metodi che puoi applicare sono i seguenti:
- Controllo della versione del codice sorgente.
- Creazione, test e deployment automatici delle app.
- Isolamento e separazione dell'ambiente dalla produzione.
- Procedure replicabili per la configurazione dell'ambiente.
Architettura
Il seguente diagramma mostra una vista dettagliata dei passaggi della pipeline CI/CD per entrambi la pipeline di test e la pipeline di produzione.

Nel diagramma precedente, la pipeline di test inizia quando uno sviluppatore esegue il commit del codice modifiche a Cloud Source Repositories e termina quando il flusso di lavoro di elaborazione dati ha superato il test di integrazione. A quel punto, la pipeline pubblica un messaggio Pub/Sub che contiene un riferimento all'ultima esecuzione automatica Java Archive (JAR) (ottenuto dalle variabili Airflow) nel codice .
Nel diagramma precedente, la pipeline di produzione inizia quando viene generato un messaggio pubblicata in un argomento Pub/Sub e termina quando il flusso di lavoro di produzione Viene eseguito il deployment del file DAG in Cloud Composer.
In questa guida al deployment, utilizzi i seguenti prodotti Google Cloud:
- Cloud Build per creare una pipeline CI/CD per la creazione, il deployment e il test di una flusso di lavoro di elaborazione dei dati e l'elaborazione stessa dei dati. Cloud Build è un servizio gestito che esegue la tua build in Google Cloud. Una build è una serie di passaggi di build in cui ogni passaggio viene eseguito in un container Docker.
- Cloud Composer per definire ed eseguire i passaggi del flusso di lavoro, come l'avvio dei dati l'elaborazione, i test e la verifica dei risultati. Cloud Composer è un servizio gestito Apache Airflow che offre un ambiente in cui è possibile creare, pianificare, monitorare e gestire flussi di lavoro complessi, come quello di elaborazione e deployment continuo.
- Dataflow per eseguire Apache Beam WordCount come esempio di processo dati.
Obiettivi
- Configurare l'ambiente Cloud Composer.
- Crea bucket Cloud Storage per i tuoi dati.
- Creare le pipeline di build, test e produzione.
- Configura il trigger di build.
Ottimizzazione dei costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Prima di iniziare
Nella pagina del selettore progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
Verifica che la fatturazione sia attivata per il tuo progetto Google Cloud. Scopri come fare a verifica se la fatturazione è abilitata su un progetto.
Codice di esempio
Il codice campione per questo deployment si trova in due cartelle:
- La cartella
env-setupcontiene script shell per la configurazione iniziale di dell'ambiente Google Cloud. La cartella
source-codecontiene codice sviluppato nel tempo, deve essere controllato dal codice sorgente e attiva build e test automatici i processi di machine learning. Questa cartella contiene le seguenti sottocartelle:- La cartella
data-processing-codecontiene il file Apache Beam del codice sorgente dell'elaborazione. - La cartella
workflow-dagcontiene le definizioni del DAG del compositore per i flussi di lavoro di elaborazione dati con le fasi di progettazione, implementazione e testare il processo Dataflow. - La cartella
build-pipelinecontiene due file Cloud Build diverse, una per la pipeline di test e l'altra per pipeline di produzione. Questa cartella contiene anche uno script di supporto pipeline di dati.
- La cartella
Per questo deployment, i file di codice sorgente per l'elaborazione dei dati del flusso di lavoro dei DAG si trovano in cartelle diverse nello stesso repository di codice sorgente. In un ambiente di produzione, i file di codice sorgente si trovano solitamente nel proprio repository di codice sorgente e sono gestiti da team diversi.
Test di integrazione e delle unità
Oltre al test di integrazione che verifica il flusso di lavoro di elaborazione dati da un lato all'altro, ci sono due test delle unità in questo deployment. I test delle unità Test automatici sul codice di elaborazione dei dati e sul flusso di lavoro di elaborazione dei dati le API nel tuo codice. Il test sul codice di elaborazione dei dati è scritto in Java ed esegue automaticamente durante il processo di compilazione Maven. Il test sull'elaborazione dei dati il codice del flusso di lavoro è scritto in Python e viene eseguito come passo di build indipendente.
Configura l'ambiente
In questo deployment, eseguirai tutti i comandi Cloud Shell. Cloud Shell viene visualizzato come finestra nella parte inferiore della console Google Cloud.
Nella console Google Cloud, apri Cloud Shell:
Clona il repository di codice campione:
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.gitEsegui uno script per impostare le variabili di ambiente:
cd ~/ci-cd-for-data-processing-workflow/env-setup source set_env.shLo script imposta le seguenti variabili di ambiente:
- L'ID del tuo progetto Google Cloud
- Regione e zona
- Il nome dei tuoi bucket Cloud Storage utilizzati dalla la pipeline di build e il flusso di lavoro di elaborazione dei dati.
Poiché le variabili di ambiente non vengono conservate tra una sessione e l'altra, se la sessione di Cloud Shell viene chiusa si disconnette durante l'esecuzione del deployment, devi reimpostare le variabili di ambiente.
crea l'ambiente Cloud Composer
In questo deployment, configurerai un ambiente Cloud Composer.
In Cloud Shell, aggiungi il ruolo Estensione agente di servizio API Cloud Composer v2 (
roles/composer.ServiceAgentV2Ext) all'account dell'agente di servizio di Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member serviceAccount:service-$PROJECT_NUMBER@cloudcomposer-accounts.iam.gserviceaccount.com \ --role roles/composer.ServiceAgentV2ExtIn Cloud Shell, crea l'ambiente Cloud Composer:
gcloud composer environments create $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --image-version composer-2.0.14-airflow-2.2.5Esegui uno script per impostare le variabili in Cloud Composer completamente gestito di Google Cloud. Le variabili sono necessarie per i DAG di elaborazione dati.
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x set_composer_variables.sh ./set_composer_variables.shLo script imposta le seguenti variabili di ambiente:
- L'ID del tuo progetto Google Cloud
- Regione e zona
- Il nome dei tuoi bucket Cloud Storage utilizzati dalla la pipeline di build e il flusso di lavoro di elaborazione dei dati.
Estrarre le proprietà dell'ambiente Cloud Composer
Cloud Composer utilizza un bucket Cloud Storage per archiviare i DAG. Lo spostamento di un file di definizione DAG nel bucket attiva Cloud Composer per legge automaticamente i file. Hai creato il bucket Cloud Storage per Cloud Composer, quando hai creato Cloud Composer. completamente gestito di Google Cloud. Nella procedura seguente, estrai l'URL per i bucket e quindi configura la tua pipeline CI/CD per eseguire automaticamente il deployment delle definizioni DAG nel bucket Cloud Storage.
In Cloud Shell, esporta l'URL per il bucket come ambiente variabile:
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.dagGcsPrefix)")Esporta il nome dell'account di servizio utilizzato da Cloud Composer per avere accesso ai bucket Cloud Storage:
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.nodeConfig.serviceAccount)")
crea i bucket Cloud Storage
In questa sezione creerai un insieme di bucket Cloud Storage per archiviare seguenti:
- Artefatti dei passaggi intermedi del processo di compilazione.
- I file di input e di output per il flusso di lavoro di elaborazione dati.
- La posizione temporanea in cui i job Dataflow possono archiviare i loro file binari.
Per creare i bucket Cloud Storage, completa questo passaggio:
In Cloud Shell, crea bucket Cloud Storage e assegna l'autorizzazione dell'account di servizio Cloud Composer per eseguire flussi di lavoro di elaborazione dati:
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x create_buckets.sh ./create_buckets.sh
crea l'argomento Pub/Sub
In questa sezione creerai un argomento Pub/Sub per ricevere messaggi. inviati dal test di integrazione del flusso di lavoro di elaborazione dati per attiva automaticamente la pipeline di build di produzione.
Nella console Google Cloud, vai agli argomenti Pub/Sub .
Fai clic su Crea argomento.
Per configurare l'argomento, completa i seguenti passaggi:
- Per ID argomento, inserisci
integration-test-complete-topic. - Verifica che l'opzione Aggiungi un abbonamento predefinito sia selezionata.
- Lascia vuote le opzioni rimanenti.
- Per Crittografia, seleziona Chiave di crittografia gestita da Google.
- Fai clic su Crea argomento.
- Per ID argomento, inserisci
esegui il push del codice sorgente in Cloud Source Repositories
In questo deployment, hai un codebase sorgente che devi inserire controllo della versione. Il passaggio seguente mostra come viene sviluppato un codebase cambiamenti nel tempo. Ogni volta che viene eseguito il push delle modifiche nel repository, la pipeline di creazione, deployment e test.
In Cloud Shell, esegui il push della cartella
source-codeCloud Source Repositories:gcloud source repos create $SOURCE_CODE_REPO cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO cd ~/$SOURCE_CODE_REPO git init git remote add google \ https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO git add . git commit -m 'initial commit' git push google masterQuesti sono comandi standard per inizializzare Git in una nuova directory del contenuto in un repository remoto.
Creazione di pipeline di Cloud Build
In questa sezione creerai le pipeline di build che consentono di creare, eseguire il deployment e testare il flusso di lavoro di elaborazione dei dati.
Concedi l'accesso all'account di servizio Cloud Build
Cloud Build esegue il deployment dei DAG di Cloud Composer attiva flussi di lavoro, che vengono abilitati quando aggiungi un ulteriore accesso Account di servizio Cloud Build. Per ulteriori informazioni sui diversi ruoli disponibili quando si lavora con Cloud Composer, documentazione sul controllo dell'accesso.
In Cloud Shell, aggiungi il ruolo
composer.adminal l'account di servizio Cloud Build per fare in modo che il job puoi impostare le variabili Airflow in Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.adminAggiungi il ruolo
composer.workera Cloud Build account di servizio in modo che il job Cloud Build possa attivare i dati del flusso di lavoro in Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.worker
Crea la pipeline di build e di test
I passaggi di creazione e test della pipeline sono configurati
File di configurazione YAML.
In questo deployment, utilizzerai modelli
immagini del builder
per git, maven e gcloud per eseguire le attività in ogni passaggio di creazione.
Utilizzi la variabile di configurazione
sostituzioni
per definire le impostazioni dell'ambiente al momento della creazione. Il repository di codice sorgente
la località è definita da sostituzioni di variabili e le posizioni
di archiviazione dei bucket Cloud Storage. La build ha bisogno di queste informazioni per eseguire il deployment
file JAR, file di test e definizione del DAG.
In Cloud Shell, invia il file di configurazione della pipeline di compilazione a crea la pipeline in Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=build_deploy_test.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\ _COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TESTQuesto comando indica a Cloud Build di eseguire una build con seguenti passaggi:
Crea ed esegui il deployment del file JAR a esecuzione automatica WordCount.
- Controlla il codice sorgente.
- Compila il codice sorgente Beam WordCount in un JAR a esecuzione automatica .
- Archiviare il file JAR in Cloud Storage, dove può essere scelto da Cloud Composer per eseguire l'elaborazione WordCount un lavoro.
Eseguire il deployment e configurare il flusso di lavoro di elaborazione dati con Cloud Composer.
- Esegui il test delle unità sul codice dell'operatore personalizzato utilizzato dal flusso di lavoro con il DAG.
- Esegui il deployment del file di input di test e del file di riferimento del test su di archiviazione ideale in Cloud Storage. Il file di input di test è l'input per Job di elaborazione Conteggio parole. Il file di riferimento del test viene utilizzato come per verificare l'output del job di elaborazione WordCount.
- Imposta le variabili Cloud Composer in modo che puntino al nuovo appena creato.
- Esegui il deployment della definizione di DAG del flusso di lavoro nell'ambiente Cloud Composer.
Per attivare il flusso di lavoro di elaborazione dei test, esegui flusso di lavoro nell'ambiente di test.
Verificare la build e la pipeline di test
Dopo aver inviato il file di build, verifica i relativi passaggi.
Nella console Google Cloud, vai alla pagina Cronologia build per visualizzare un elenco di tutte le build passate e attualmente in esecuzione.
Fai clic sulla build in esecuzione.
Nella pagina Dettagli build, verifica che i passaggi di build corrispondano descritti in precedenza.
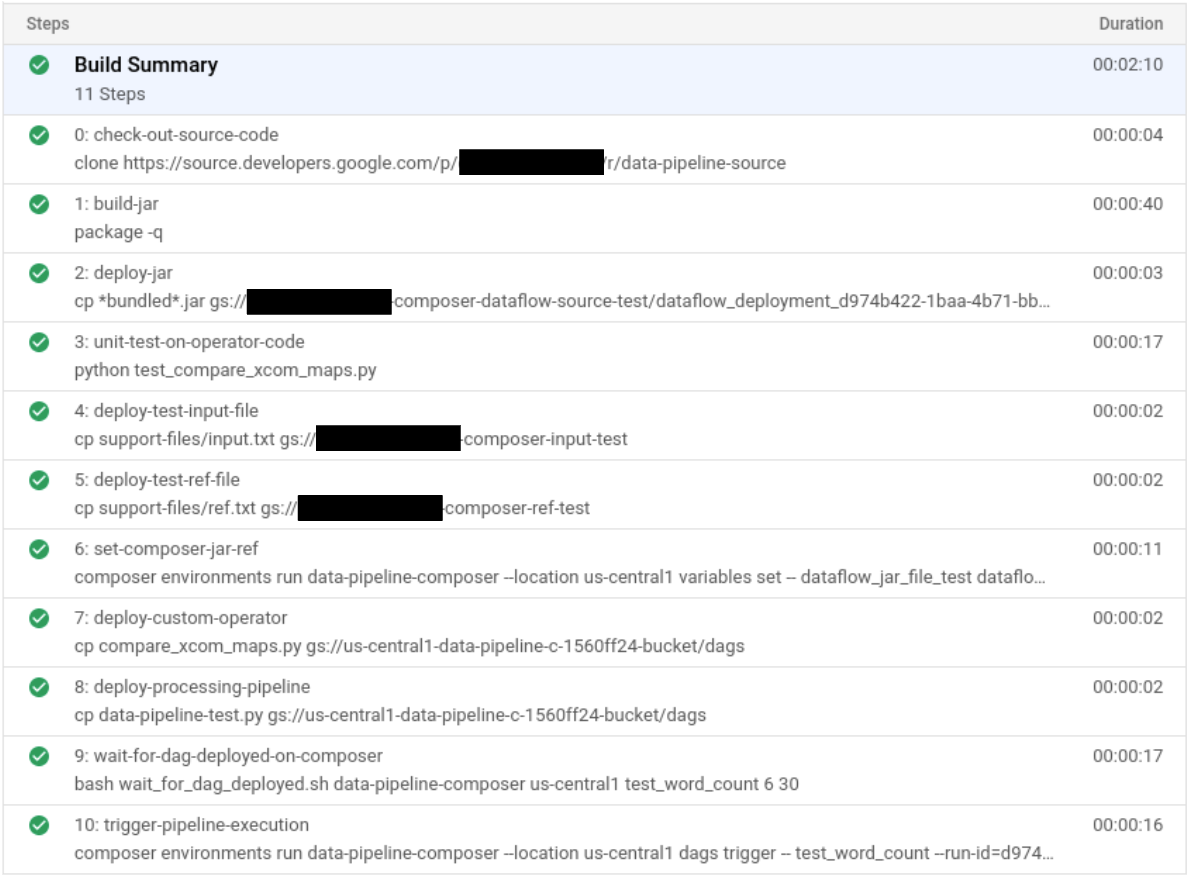
Nella pagina Dettagli build, il campo Stato della build dice
Build successfulal termine della compilazione.In Cloud Shell, verifica che il file JAR di esempio WordCount sia stato nel bucket corretto:
gcloud storage ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jarL'output è simile al seguente:
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
Recupera l'URL all'interfaccia web di Cloud Composer. Scrivi una nota dell'URL perché verrà usato nel passaggio successivo.
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Usa l'URL del passaggio precedente per andare a Cloud Composer UI per verificare la riuscita dell'esecuzione di un DAG. Se la colonna Esecuzioni non mostra informazioni, attendi qualche minuto e ricarica la pagina.
per verificare che il DAG del flusso di lavoro di elaborazione dati Il deployment di
test_word_countè stato eseguito ed è in modalità di esecuzione: tieni premuto il puntatore sopra il cerchio verde chiaro tramite Esecuzioni e verifica che indica In esecuzione.Per visualizzare il flusso di lavoro di elaborazione dati in esecuzione sotto forma di grafico, fai clic su il cerchio verde chiaro e poi nella pagina Esecuzioni DAG fare clic su Dag ID:
test_word_countRicarica la pagina Visualizzazione grafico per aggiornare lo stato del dell'esecuzione attuale del DAG. Di solito ci vogliono dai 3 ai 5 minuti flusso di lavoro per completare l'operazione. Per verificare che l'esecuzione del DAG venga completata correttamente, tieni il puntatore sopra ogni attività per verificare che la descrizione comando Stato: operazione completata. La penultima attività,
do_comparison, è la test di integrazione che verifica l'output del processo rispetto al riferimento .
Una volta completato il test di integrazione, l'ultima attività,
publish_test_completepubblica un messaggio inintegration-test-complete-topicargomento Pub/Sub che verrà utilizzata per attivare la pipeline della build di produzione.Per verificare che il messaggio pubblicato contenga il riferimento corretto a il file JAR più recente, possiamo eseguire il pull del messaggio dall'elenco Sottoscrizione Pub/Sub
integration-test-complete-topic-sub.Nella console Google Cloud, vai alla pagina Abbonamenti.
Fai clic su integration-test-complete-topic-sub e seleziona Messaggio. e fai clic su Pull.
L'output dovrebbe essere simile al seguente:

Crea la pipeline di produzione
Quando il flusso di lavoro di elaborazione dei test viene eseguito correttamente, puoi promuovere dalla versione corrente del flusso di lavoro in produzione. Esistono diversi modi per eseguire il deployment dal flusso di lavoro alla produzione:
- Manualmente.
- Viene attivato automaticamente quando tutti i test superano il test o la gestione temporanea ambienti cloud-native.
- Viene attivato automaticamente da un job pianificato.
In questo deployment, attiverai automaticamente la build di produzione quando vengono superati nell'ambiente di test. Per maggiori informazioni informazioni sugli approcci automatici, vedi Progettazione dei rilasci.
Prima di implementare l'approccio automatizzato, verifichi l'ambiente eseguendo un deployment manuale in produzione. Il deployment di produzione la build segue questi passaggi:
- Copia il file JAR WordCount dal bucket di test al bucket di produzione.
- Imposta le variabili Cloud Composer per il flusso di lavoro di produzione su al file JAR appena promosso.
- Esegui il deployment della definizione di DAG del flusso di lavoro di produzione dell'ambiente Cloud Composer ed esecuzione del flusso di lavoro.
Le sostituzioni delle variabili definiscono il nome dell'ultimo file JAR, il deployment in produzione con i bucket Cloud Storage utilizzati flusso di lavoro per l'elaborazione della produzione. Per creare la pipeline di Cloud Build che esegue il deployment del flusso di lavoro del flusso di aria di produzione, completa i seguenti passaggi:
In Cloud Shell, leggi il nome del file JAR più recente stampando la variabile Cloud Composer per il nome file JAR:
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION variables get -- \ dataflow_jar_file_test 2>&1 | grep -i '.jar')Usa il file di configurazione della pipeline di build
deploy_prod.yaml,per crea la pipeline in Cloud Build:cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=deploy_prod.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\ _DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\ _DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Verificare il flusso di lavoro di elaborazione dei dati creato dalla pipeline di produzione
Recupera l'URL per la UI di Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Per verificare che sia stato eseguito il deployment del DAG del flusso di lavoro di elaborazione dei dati di produzione, vai all'URL recuperato nel passaggio precedente e verifica che
prod_word_countIl DAG è nell'elenco dei DAG.- Nella pagina DAG, nella riga
prod_word_count, fai clic su Attiva il DAG.
- Nella pagina DAG, nella riga
Per aggiornare lo stato dell'esecuzione del DAG, fai clic sul logo Airflow o ricarica la pagina. R cerchio verde chiaro nella colonna Esecuzioni indica che il DAG è in esecuzione.
Una volta eseguita correttamente l'esecuzione, tieni il puntatore sul cerchio verde scuro vicino al Esecuzioni DAG e verifica che sia indicato Operazione riuscita.
In Cloud Shell, elenca i file di risultati nella directory Cloud Storage del bucket:
gcloud storage ls gs://$RESULT_BUCKET_PRODL'output è simile al seguente:
gs://…-composer-result-prod/output-00000-of-00003 gs://…-composer-result-prod/output-00001-of-00003 gs://…-composer-result-prod/output-00002-of-00003
crea trigger Cloud Build
In questa sezione creerai i trigger di Cloud Build che collegano le modifiche al codice sorgente al processo di compilazione di test e tra la pipeline di test e la pipeline della build di produzione.
Configura il trigger della pipeline di build di test
Hai configurato Trigger di Cloud Build che attiva una nuova build quando viene eseguito il push delle modifiche al ramo master repository di codice sorgente.
Nella console Google Cloud, vai alla pagina Trigger di build.
Fai clic su Crea trigger.
Per configurare le impostazioni del trigger, completa i seguenti passaggi:
- Nel campo Nome, inserisci
trigger-build-in-test-environment. - Nel menu a discesa Regione, seleziona globale (non a livello di regione).
- Per Evento, fai clic su Invia a un ramo.
- In Origine, seleziona
data-pipeline-source. - Nel campo Nome filiale, inserisci
master. - Per Configurazione, fai clic su Configurazione Cloud Build (yaml o json).
- In Località, fai clic su Repository.
- Nel campo Posizione file di configurazione Cloud Build, inserisci
build-pipeline/build_deploy_test.yaml.
- Nel campo Nome, inserisci
In Cloud Shell, esegui questo comando per ottenere tutte le di sostituzione necessarie per la build. Prendi nota di questi valori perché sono necessarie in un passaggio successivo.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST} _COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}"Nella pagina Impostazioni trigger, in Avanzate, Variabili di sostituzione, sostituisci le variabili con i valori del tuo ambiente al passaggio precedente. Aggiungi quanto segue alla volta e fai clic su + Aggiungi elemento per ciascuna delle coppie nome-valore.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_TEST_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REF_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET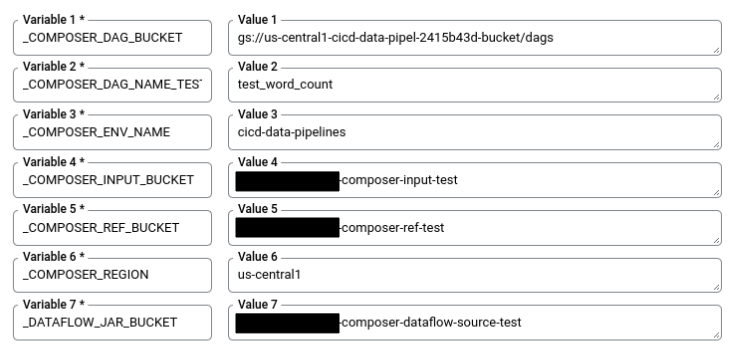
Fai clic su Crea.
Configura il trigger della pipeline di build di produzione
Configuri un trigger di Cloud Build che attiva una build di produzione
quando i test sono stati superati nell'ambiente di test e viene pubblicato un messaggio
nell'argomento Pub/Sub tests-complete. Questo attivatore include un
passaggio di approvazione in cui la build deve essere approvata manualmente prima
viene eseguita la pipeline di produzione.
Nella console Google Cloud, vai alla pagina Trigger di build.
Fai clic su Crea trigger.
Per configurare le impostazioni del trigger, completa i seguenti passaggi:
- Nel campo Nome, inserisci
trigger-build-in-prod-environment. - Nel menu a discesa Regione, seleziona globale (non a livello di regione).
- In Evento, fai clic su Messaggio Pub/Sub.
- In Abbonamento, seleziona integration-test-complete-topic.
- In Origine, seleziona
data-pipeline-source. - In Revisione, seleziona Ramo.
- Nel campo Nome filiale, inserisci
master. - Per Configurazione, fai clic su Configurazione Cloud Build (yaml o json).
- In Località, fai clic su Repository.
- Nel campo Posizione file di configurazione Cloud Build, inserisci
build-pipeline/deploy_prod.yaml.
- Nel campo Nome, inserisci
In Cloud Shell, esegui questo comando per ottenere tutte le di sostituzione necessarie per la build. Prendi nota di questi valori perché sono necessarie in un passaggio successivo.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_PROD : ${COMPOSER_DAG_NAME_PROD} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_PROD} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET_PROD : ${DATAFLOW_JAR_BUCKET_PROD} _DATAFLOW_JAR_BUCKET_TEST : ${DATAFLOW_JAR_BUCKET_TEST}"Nella pagina Impostazioni trigger, in Avanzate, Variabili di sostituzione, sostituisci le variabili con i valori del tuo ambiente al passaggio precedente. Aggiungi quanto segue alla volta e fai clic su + Aggiungi elemento per ciascuna delle coppie nome-valore.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_PROD_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET_PROD_DATAFLOW_JAR_BUCKET_TEST_DATAFLOW_JAR_FILE_LATEST = $(body.message.data)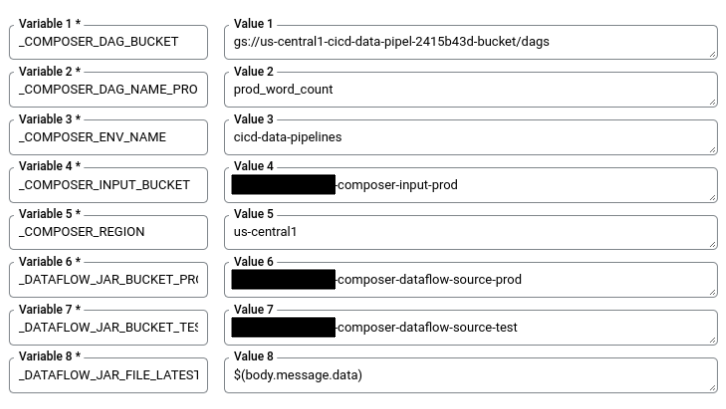
Per Approvazione, seleziona Richiedi l'approvazione prima dell'esecuzione della build.
Fai clic su Crea.
Testa i trigger
Per testare il trigger, aggiungi una nuova parola al file di input di test e aggiungi la l'aggiustamento corrispondente al file di riferimento del test. Verifichi che la build viene attivata tramite push di commit in Cloud Source Repositories e il flusso di lavoro di elaborazione dei dati viene eseguito correttamente con i file di test aggiornati.
In Cloud Shell, aggiungi una parola di test alla fine del file di test:
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txtAggiorna il file di riferimento dei risultati del test,
ref.txt, in modo che corrisponda alle modifiche nel file di input di test:echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txtEsegui il commit e il push delle modifiche in Cloud Source Repositories:
cd ~/$SOURCE_CODE_REPO git add . git commit -m 'change in test files' git push google masterNella console Google Cloud, vai alla pagina Cronologia.
Per verificare che una nuova build di test venga attivata dal push precedente al master. ramo, sulla build attualmente in esecuzione, la colonna Ref indica principale.
In Cloud Shell, ottieni l'URL per il tuo sito web di Cloud Composer dell'interfaccia:
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION --format="get(config.airflowUri)"Al termine della build, vai all'URL dal comando precedente e verifica che il DAG
test_word_countsia in esecuzione.Attendi il termine dell'esecuzione del DAG, che viene indicato quando la spia il cerchio verde nella colonna Esecuzioni DAG scompare. Di solito ci vogliono 3-5 minuti per il completamento del processo.
In Cloud Shell, scarica i file dei risultati del test:
mkdir ~/result-download cd ~/result-download gcloud storage cp gs://$RESULT_BUCKET_TEST/output* .Verifica che la parola appena aggiunta si trovi in uno dei file dei risultati:
grep testword output*L'output è simile al seguente:
output-00000-of-00003:testword: 1
Nella console Google Cloud, vai alla pagina Cronologia.
Verifica che sia stata attivata una nuova build di produzione dopo il completamento di il test di integrazione e che la build sia in attesa di approvazione.
Per eseguire la pipeline di build di produzione, seleziona la casella di controllo accanto alla build Fai clic su Approva, poi su Approva nella casella di conferma.
Al termine della build, vai all'URL del comando precedente e attivare manualmente il DAG
prod_word_countper eseguire la pipeline di produzione.
Esegui la pulizia
Le seguenti sezioni spiegano come evitare addebiti futuri per il progetto Google Cloud e le risorse Apache Hive e Dataproc utilizzate in questo deployment.
Elimina il progetto Google Cloud
Per evitare che al tuo account Google Cloud vengano addebitati costi per utilizzate in questo deployment, puoi eliminare il progetto Google Cloud.
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Elimina le singole risorse
Se vuoi mantenere il progetto utilizzato per questo deployment, esegui questo comando: passaggi per eliminare le risorse che hai creato.
Per eliminare il trigger di Cloud Build, completa questi passaggi:
Nella console Google Cloud, vai alla pagina Trigger.
Accanto agli attivatori che hai creato, fai clic su Altromore_vert e poi su Elimina.
In Cloud Shell, elimina l'ambiente Cloud Composer:
gcloud -q composer environments delete $COMPOSER_ENV_NAME \ --location $COMPOSER_REGIONElimina i bucket Cloud Storage e i relativi file:
gcloud storage rm gs://$DATAFLOW_JAR_BUCKET_TEST \ gs://$INPUT_BUCKET_TEST \ gs://$REF_BUCKET_TEST \ gs://$RESULT_BUCKET_TEST \ gs://$DATAFLOW_STAGING_BUCKET_TEST \ gs://$DATAFLOW_JAR_BUCKET_PROD \ gs://$INPUT_BUCKET_PROD \ gs://$RESULT_BUCKET_PROD \ gs://$DATAFLOW_STAGING_BUCKET_PROD \ --recursivePer eliminare l'argomento Pub/Sub e la sottoscrizione predefinita: esegui questi comandi in Cloud Shell:
gcloud pubsub topics delete integration-test-complete-topic gcloud pubsub subscriptions delete integration-test-complete-topic-subElimina il repository:
gcloud -q source repos delete $SOURCE_CODE_REPOElimina i file e le cartelle che hai creato:
rm -rf ~/ci-cd-for-data-processing-workflow rm -rf ~/$SOURCE_CODE_REPO rm -rf ~/result-downloadPassaggi successivi
- Scopri di più su Distribuzione continua in stile GitHub con Cloud Build.
- Scopri come Utilizza una pipeline CI/CD per i flussi di lavoro di elaborazione dati.
- Scopri di più su Pattern comuni di casi d'uso di Dataflow.
- Scopri di più su Progettazione dei rilasci.
- Per altre architetture di riferimento, diagrammi e best practice, esplora il Centro architetture cloud.