このドキュメントでは、研究者、データ サイエンティスト、ビジネス アナリストを対象に、BigQuery を使用した Fast Healthcare Interoperability Resources(FHIR)データの分析に関するプロセスと考慮事項について説明します。
具体的には、Cloud Healthcare API で FHIR ストアからエクスポートされた患者リソースデータを中心に説明します。また、一連のクエリを使用して、FHIR スキーマデータがリレーショナル形式でどのように機能するのかを説明します。ビューを通じて再利用するために、これらのクエリにアクセスする方法についても説明します。
BigQuery を使用した FHIR データの分析
Cloud Healthcare API の FHIR 固有の API は、単一の FHIR リソースレベルまたは FHIR リソースのコレクション レベルで FHIR データをリアルタイムで処理するトランザクション向けに設計されています。ただし、FHIR API は分析ユースケース向けには設計されていません。このようなユースケースでは、FHIR API から BigQuery にデータをエクスポートすることをおすすめします。BigQuery はサーバーレスでスケーラブルなデータ ウェアハウスであり、大量のデータを遡及的または予測的に分析できます。
さらに、BigQuery は ANSI:2011 SQL に準拠しています。これにより、データ サイエンティストやビジネス アナリストが通常使用する Tableau、Looker、または Vertex AI Workbench などのツールでデータにアクセスできます。
Vertex AI Workbench などの一部のアプリケーションでは、BigQuery 用 Python クライアント ライブラリなどの組み込みクライアントを通じてアクセスします。この場合、アプリケーションに返されるデータは組み込みの言語データ構造を通じて利用できます。
BigQuery へのアクセス
BigQuery には、Google Cloud コンソールの BigQuery ウェブ UI または次のツールからアクセスできます。
- BigQuery コマンドライン ツール
- BigQuery REST API またはクライアント ライブラリ
- ODBC ドライバと JDBC ドライバ
これらのツールを使用することにより、ほぼすべてのアプリケーションに BigQuery を統合できます。
FHIR データ構造の操作
組み込みの FHIR 標準データ構造は複雑で、FHIR リソース全体にネストした FHIR データ型が埋め込まれています。こうした埋め込み可能な FHIR データ型は、複合データ型と呼ばれます。また、リレーショナル データベースでは、配列と構造型も複合データ型と呼ばれます。組み込みの FHIR 標準データ構造は、ドキュメント指向システムでは XML または JSON ファイルとして適切にシリアル化されますが、リレーショナル データベースに変換する際は、その構造の操作は容易ではありません。
次のスクリーンショットは、FHIR patient resource データ型の一部を表示したもので、FHIR の標準データ構造の複雑さが示されています。
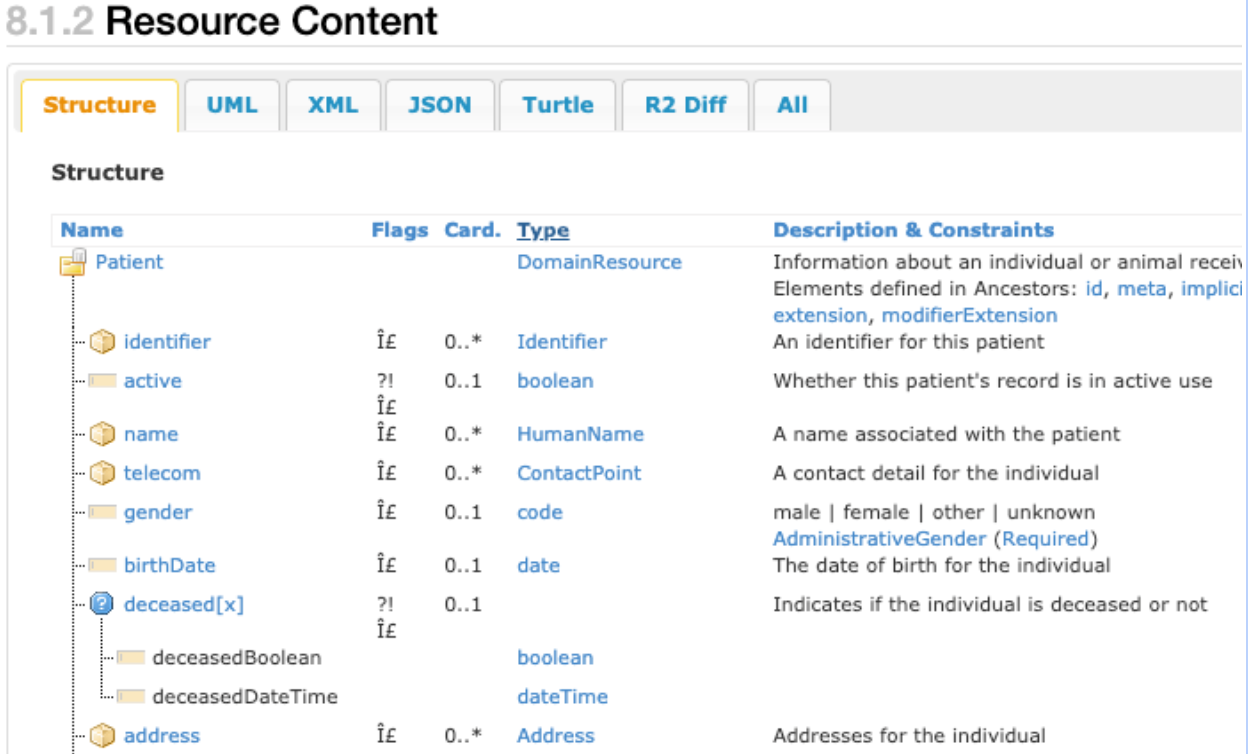
上のスクリーンショットは、FHIR データ型 patient
resource の主な構成要素を示しています。たとえば、テーブルの Cardinality 列(テーブル内では Card.)には、0 個、1 個または複数のエントリを持つことができます。Type 列は、Identifier、HumanName、Address のデータ型を表しています。これは patient
resource データ型を構成する複合データ型の例です。これらの各行は構造体の配列として複数回記録できます。
配列と構造体の使用
BigQuery は配列と STRUCT データ型(ネストされた繰り返しのデータ構造)をサポートしています。これらは、FHIR リソースで表現されるため、FHIR から BigQuery へのデータ変換が可能です。
BigQuery でいう配列とは、ゼロ個以上の同じデータ型の値で構成された順序付きリストのことです。INT64 データ型のような簡単なデータ型と、STRUCT データ型のような複雑なデータ型の配列を作成できます。ただし、配列の配列は現在サポートされていないため、ARRAY データ型は例外です。BigQuery では、構造の配列は再現可能なレコードとして表示されます。
BigQuery UI または JSON スキーマ ファイルで、ネストされたデータ、またはネストされたデータと繰り返しデータを指定できます。ネストされた列、またはネストされた列と繰り返し列を指定するには、RECORD (STRUCT) データ型を使用します。
Cloud Healthcare API は、BigQuery の FHIR スキーマの SQL をサポートします。この分析スキーマは ExportResources() メソッドのデフォルトのスキーマで、FHIR コミュニティでサポートされています。
BigQuery は非正規化データをサポートします。つまり、スタースキーマやスノーフレーク スキーマなどのリレーショナル スキーマを作成せずにデータを保存する場合、データを非正規化して、ネストされた繰り返し列を使用できます。ネストされた列と繰り返し列は、リレーショナル(正規化)スキーマの維持でパフォーマンスに影響を及ぼすことなく、データ要素間の関係を維持します。
UNNEST 演算子によるデータへのアクセス
FHIR API のすべての FHIR リソースは 1 行のデータとして BigQuery にエクスポートされます。行内の配列または構造体は埋め込みテーブルとして考えることができます。クエリの SELECT 句または WHERE 句の「テーブル」内のデータには、UNNEST 演算子を使用して配列または構造体をフラット化することでアクセスできます。UNNEST 演算子は配列を受け取り、配列内の各要素を 1 行にしたテーブルを返します。詳細については、標準 SQL での配列の操作をご覧ください。
UNNEST 演算は、配列要素の順序を保持しませんが、オプションの WITH OFFSET 句を使用することでテーブルの順序を変更できます。これにより、配列要素ごとに OFFSET 句を含む追加の列が返されます。その後、ORDER BY 句を使用して、それぞれのオフセットで行を並べ替えることができます。
ネストされていないデータを結合する際、BigQuery は相関 CROSS JOIN オペレーションを使用します。これは、配列内の各アイテムから配列の列をソーステーブルで参照します。このソーステーブルは FROM 句の UNNEST 呼び出しの直前にあるテーブルです。ソーステーブルの行ごとに、UNNEST オペレーションはその行の配列をフラット化し、配列要素を含む一連の行にします。相関 CROSS JOIN オペレーションは、この新しい一連の行をソーステーブルの単一の行に結合します。
クエリによるスキーマの調査
BigQuery で FHIR データをクエリするには、エクスポート プロセスで作成されたスキーマを理解することが重要です。BigQuery では、メタデータを表示する一連のビューである INFORMATION_SCHEMA 機能を使用して、データセット内のすべてのテーブルの列構造を検査できます。このドキュメントの残りの部分では、FHIR スキーマの SQL について説明します。このスキーマは、データを取得するために使用できます。
次のサンプルクエリは、SQL on FHIR スキーマの患者テーブルの列の詳細を調べます。このクエリは、FHIR での Synthea Generated Synthetic Data 一般公開データセットを参照しています。このデータセットには、Synthea と FHIR 形式で生成された 100 万を超える合成患者レコードがホストされています。
INFORMATION_SCHEMA.COLUMNS ビューにクエリを実行すると、クエリ結果として、テーブル内の列(フィールド)ごとに 1 行が表示されます。次のクエリは、患者テーブルのすべての列を返します。
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
次のスクリーンショットはクエリ結果を表しています。identifier データ型と、STRUCT データ型を含むデータ型内の配列を示しています。

BigQuery での FHIR 患者リソースの使用
患者カルテ番号(MRN)は、FHIR データに保存される最も重要な情報であり、組織のすべての患者の臨床データシステムおよび運用データシステム全体で使用されます。個々の患者または一連の患者のデータにアクセスする方法として MRN をフィルタするか、返す必要があります。または、その両方を行います。
次のサンプルクエリは、内部 FHIR サーバー ID を、MRN とすべての患者の生年月日を含む患者リソース自体に返します。特定の MRN をクエリするフィルタも含まれますが、この例ではコメントアウトされています。
このクエリでは、identifier の複雑なデータ型を 2 回ネスト解除します。ネストされていないデータをソーステーブルと結合するには、相関 CROSS JOIN オペレーションも使用します。クエリの bigquery-public-data.fhir_synthea.patient テーブルは、SQL on FHIR スキーマ バージョンの FHIR から BigQuery へのエクスポートを使用して作成されました。
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
出力は次のようになります。
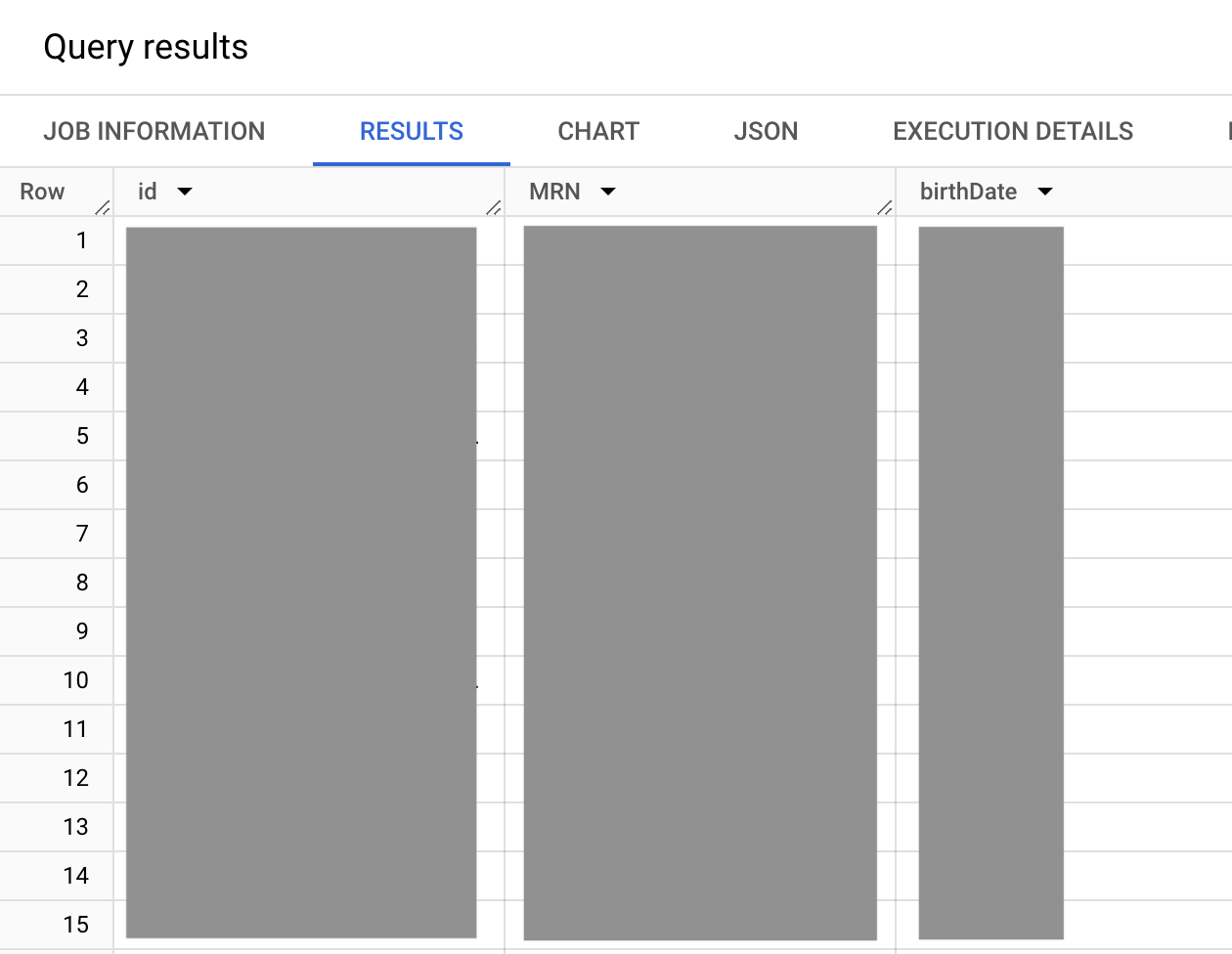
前述のクエリでは、identifier.type.coding.code 値セットが、MRN(MR ID データ型)、運転免許証(DL ID データ型)、パスポート番号(PPN ID データ型)などの利用可能な ID データ型を列挙する FHIR identifier 値セットです。identifier.type.coding 値セットは配列であるため、任意の数の患者 ID をリストできます。ただし、この場合は MRN(MR ID データ型)が必要です。
患者テーブルと他のテーブルの結合
患者テーブルクエリを利用して、患者テーブルをこのデータセット内の他のテーブル(疾患テーブルなど)と結合できます。疾患テーブルには患者の診断情報が記録されています。
次のサンプルクエリでは、高血圧の病状のすべてのエントリを取得します。
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
出力は次のようになります。
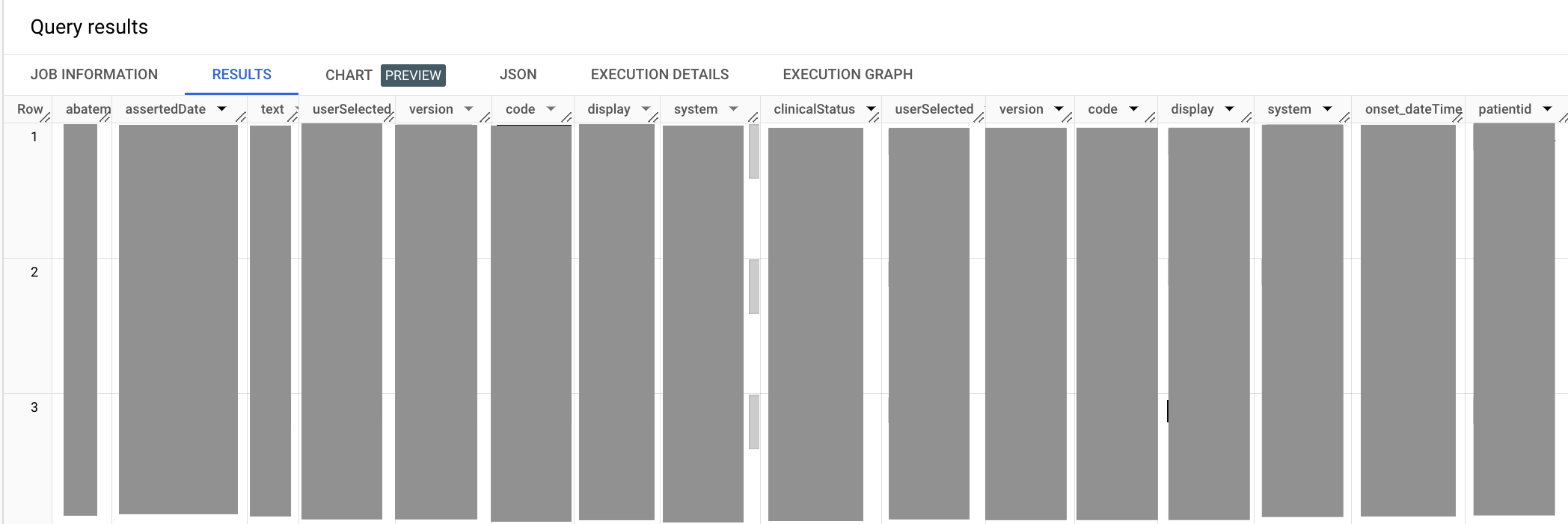
前述のクエリでは、UNNEST メソッドを再利用して code.coding フィールドをフラット化しています。SELECT ステートメントの abatement.dateTime と onset.dateTime のコード要素は、どちらも dateTime で終わり、SELECT ステートメントの出力があいまいな列名になるため、別名が付けられます。Hypertension コードを選択する際は、コードの送信元となる用語システム(この場合は SNOMED CT 臨床用語システム)も宣言する必要があります。
最後に、subject.patientid キーを使用して、疾患テーブルと患者テーブルを結合します。この鍵は、FHIR サーバー内の患者リソース自体の ID を指します。
クエリを結合する
次のサンプルクエリでは前の 2 つのセクションのクエリを使用して、単純な計算を行いながら、WITH 句で結合します。
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
出力は次のようになります。
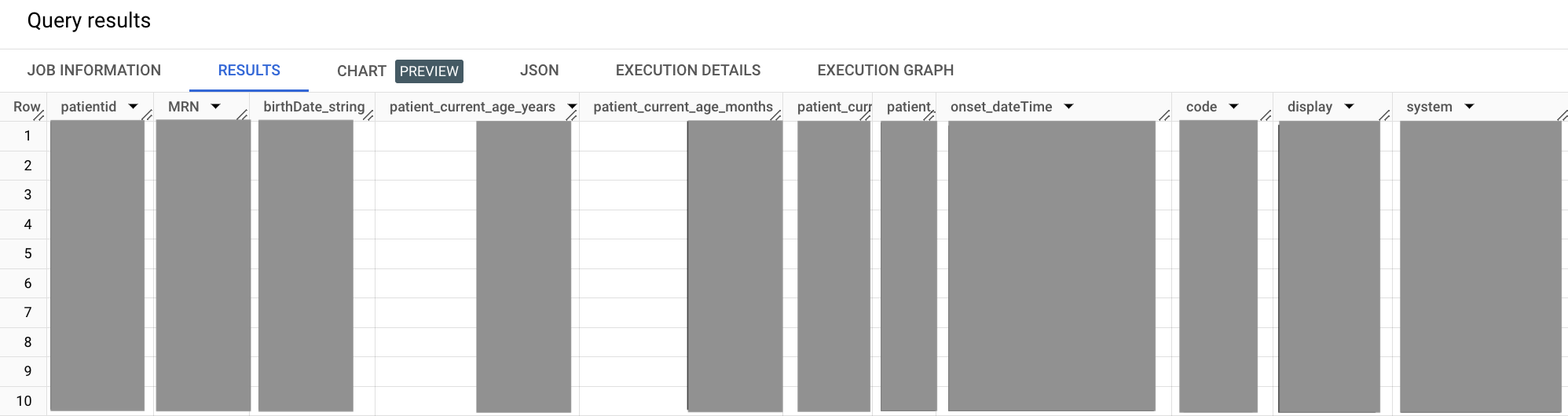
前述のサンプルクエリでは、WITH 句を使用して、サブクエリを独自に定義したセグメントに分離しています。この方法でクエリを読みやすくしています。この作業は、クエリの規模が大きくなるほど重要になります。このクエリでは、患者と条件のサブクエリを独自の WITH セグメントに分離し、それをメインの SELECT セグメントに結合します。
元データにも計算を適用できます。次のサンプルコードの SELECT ステートメントは、患者の発病年齢を計算する方法を示しています。
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
上記のコードサンプルのように、指定された dateTime 文字列 condition.onset_dateTime に対してさまざまなオペレーションを実行できます。まず、SUBSTR 値を持つ文字列の日付コンポーネントを選択します。次に、CAST 構文を使用して文字列を DATE データ型に変換します。また、patient.birthDate フィールドを DATE フィールドに変換します。最後に、DATE_DIFF 関数を使用して 2 つの日付の差を計算します。
次のステップ
- BigQuery と AI Platform Notebooks を使用して臨床データを分析する。
- Jupyter ノートブックで BigQuery データを可視化する。
- Cloud Healthcare API のセキュリティ。
- BigQuery アクセス制御。
- Google Cloud Marketplace のヘルスケアとライフ サイエンス ソリューション。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。