Este artigo descreve uma solução para exportar métricas do Cloud Monitoring para análise a longo prazo. O Cloud Monitoring oferece uma solução de monitorização para o Google Cloud e os Amazon Web Services (AWS). O Cloud Monitoring mantém as métricas durante seis semanas porque o valor das métricas de monitorização está frequentemente limitado no tempo. Por conseguinte, o valor das métricas do histórico diminui ao longo do tempo. Após o período de seis semanas, as métricas agregadas podem continuar a ter valor para a análise a longo prazo de tendências que podem não ser evidentes com a análise a curto prazo.
Esta solução fornece um guia para compreender os detalhes das métricas para exportação e uma implementação de referência sem servidor para exportação de métricas para o BigQuery.
Os relatórios State of DevOps identificaram capacidades que impulsionam o desempenho da entrega de software. Esta solução ajuda com as seguintes capacidades:
- Monitorização e observabilidade
- Monitorizar sistemas para orientar as decisões empresariais
- Capacidades de gestão visual
Exemplos de utilização de exportação de métricas
O Cloud Monitoring recolhe métricas e metadados da Google Cloud, da AWS e da instrumentação de apps. As métricas de monitorização oferecem uma observabilidade detalhada do desempenho, do tempo de atividade e do estado geral das apps na nuvem através de uma API, de painéis de controlo e de um explorador de métricas. Estas ferramentas oferecem uma forma de rever os valores das métricas das 6 semanas anteriores para análise. Se tiver requisitos de análise de métricas a longo prazo, use a API Cloud Monitoring para exportar as métricas para armazenamento a longo prazo.
O Cloud Monitoring mantém as métricas das últimas 6 semanas. É frequentemente usado para fins operacionais, como a monitorização da infraestrutura de máquinas virtuais (CPU, memória, métricas de rede) e métricas de desempenho da aplicação (latência de pedidos ou respostas). Quando estas métricas excedem os limites predefinidos, é acionado um processo operacional através de alertas.
As métricas capturadas também podem ser úteis para a análise a longo prazo. Por exemplo, pode querer comparar as métricas de desempenho da app da Cyber Monday ou de outros eventos de tráfego elevado com as métricas do ano anterior para planear o próximo evento de tráfego elevado. Outro exemplo de utilização é analisar a utilização dos serviços durante um trimestre ou um ano para prever melhor os custos. Google Cloud Também podem existir métricas de desempenho da app que queira ver ao longo de meses ou anos.
Nestes exemplos, é necessário manter as métricas para análise durante um período prolongado. A exportação destas métricas para o BigQuery oferece as capacidades de análise necessárias para abordar estes exemplos.
Requisitos
Para realizar uma análise a longo prazo dos dados das métricas de monitorização, existem 3 requisitos principais:
- Exporte os dados do Cloud Monitoring. Tem de exportar os dados de métricas do Cloud Monitoring como um valor de métrica agregado.
A agregação de métricas é necessária porque o armazenamento de pontos de dados
timeseriesbrutos, embora tecnicamente viável, não acrescenta valor. A maioria das análises a longo prazo é realizada ao nível agregado durante um período mais longo. A granularidade da agregação é exclusiva do seu exemplo de utilização, mas recomendamos uma agregação mínima de 1 hora. - Carregue os dados para análise. Tem de importar as métricas do Cloud Monitoring exportadas para um motor de estatísticas para análise.
- Escrever consultas e criar painéis de controlo com base nos dados. Precisa de painéis de controlo e acesso SQL padrão para consultar, analisar e visualizar os dados.
Passos funcionais
- Crie uma lista de métricas a incluir na exportação.
- Ler métricas da API Monitoring.
- Mapeie as métricas da saída JSON exportada da API Monitoring para o formato de tabela do BigQuery.
- Escrever as métricas no BigQuery.
- Crie uma agenda programática para exportar regularmente as métricas.
Arquitetura
A conceção desta arquitetura tira partido dos serviços geridos para simplificar as suas operações e o esforço de gestão, reduzir os custos e oferecer a capacidade de escalar conforme necessário.
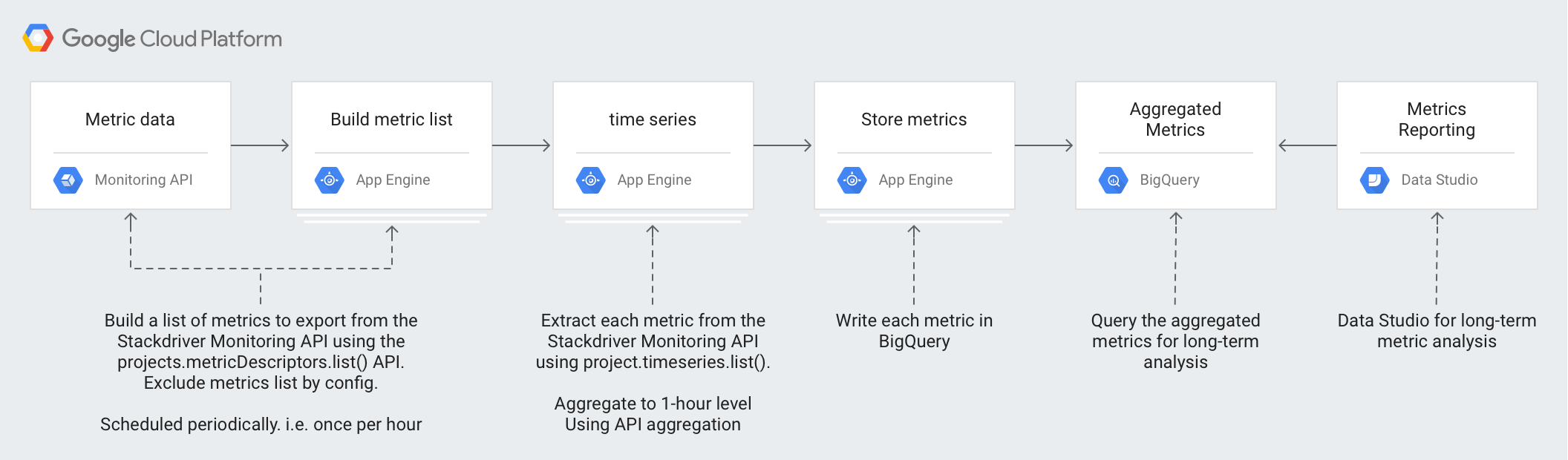
As seguintes tecnologias são usadas na arquitetura:
- App Engine: solução de plataforma como serviço (PaaS) escalável usada para chamar a API Monitoring e escrever no BigQuery.
- BigQuery: um motor de estatísticas totalmente gerido usado para carregar e analisar os dados do
timeseries. - Pub/Sub: um serviço de mensagens em tempo real totalmente gerido usado para fornecer processamento assíncrono escalável.
- Cloud Storage: um armazenamento de objetos unificado para programadores e empresas usado para armazenar os metadados sobre o estado da exportação.
- Cloud Scheduler: um programador de estilo cron usado para executar o processo de exportação.
Compreender os detalhes das métricas do Cloud Monitoring
Para compreender a melhor forma de exportar métricas do Cloud Monitoring, é importante saber como armazena as métricas.
Tipos de métricas
Existem 4 tipos principais de métricas no Cloud Monitoring que pode exportar.
- A Google Cloud lista de métricas contém métricas de Google Cloud serviços, como o Compute Engine e o BigQuery.
- A lista de métricas do agente contém métricas de instâncias de VM que executam os agentes do Cloud Monitoring.
- A lista de métricas da AWS inclui métricas de serviços da AWS, como o Amazon Redshift e o Amazon CloudFront.
- As métricas de origens externas são métricas de aplicações de terceiros e métricas definidas pelo utilizador, incluindo métricas personalizadas.
Cada um destes tipos de métricas tem um
descritor de métricas,
que inclui o tipo de métrica, bem como outros metadados de métricas. A métrica seguinte é um exemplo de uma lista de descritores de métricas do método
projects.metricDescriptors.list
da API Monitoring.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
Os valores importantes a compreender a partir do descritor de métricas são os campos type, valueType e metricKind. Estes campos identificam a métrica e
afetam a agregação possível para um descritor de métricas.
Tipos de métricas
Cada métrica tem um tipo de métrica e um tipo de valor. Para mais informações, leia o artigo Tipos de valores e tipos de métricas. O tipo de métrica e o tipo de valor associado são importantes porque a respetiva combinação afeta a forma como as métricas são agregadas.
No exemplo anterior, o tipo de métrica pubsub.googleapis.com/subscription/push_request_count metric tem um tipo de métrica DELTA e um tipo de valor INT64.

No Cloud Monitoring, o tipo de métrica e os tipos de valores são armazenados em
metricsDescriptors, que estão disponíveis na API Monitoring.
Séries cronológicas
timeseries são medições normais para cada tipo de métrica armazenado ao longo do tempo que contêm o tipo de métrica, os metadados, as etiquetas e os pontos de dados medidos individuais. As métricas recolhidas automaticamente pela monitorização, como as métricas do Google Cloud e da AWS, são recolhidas regularmente.Google Cloud Por exemplo, a métrica
appengine.googleapis.com/http/server/response_latencies
é recolhida a cada 60 segundos.
Um conjunto de pontos recolhidos para um determinado timeseries pode aumentar ao longo do tempo, com base na frequência dos dados comunicados e em quaisquer etiquetas associadas ao tipo de métrica. Se exportar os pontos de dados timeseries não processados, isto pode resultar numa exportação grande. Para reduzir o número de pontos de dados devolvidos, pode agregar as métricas num determinado período de alinhamento.timeseries Por exemplo, através da agregação, pode devolver um ponto de dados por hora para uma determinada métrica timeseries que tenha um ponto de dados por minuto. Isto reduz o número de pontos de dados exportados e o processamento analítico necessário no motor de estatísticas. Neste artigo, são devolvidos timeseries para cada tipo de métrica selecionado.
Agregação de métricas
Pode usar a agregação para combinar dados de vários timeseries num único timeseries. A API Monitoring oferece funções de alinhamento e agregação avançadas para que não tenha de realizar a agregação, transmitindo os parâmetros de alinhamento e agregação para a chamada API. Para
mais detalhes sobre o funcionamento da agregação para a API Monitoring,
leia
Filtragem e agregação
e esta
publicação no blogue.
Mapeia metric typepara aggregation type para garantir que as métricas estão alinhadas e que o timeseries é reduzido para satisfazer as suas necessidades de análise.
Existem listas de
alinhadores
e
redutores,
que pode usar para agregar o timeseries. Os alinhadores e os redutores têm um conjunto de métricas que pode usar para alinhar ou reduzir com base nos tipos de métricas e nos tipos de valores. Por exemplo, se agregar durante 1 hora, o resultado da agregação é 1 ponto devolvido por hora para o timeseries.
Outra forma de ajustar a agregação é usar a função Group By, que lhe permite agrupar os valores agregados em listas de timeseries agregados. Por exemplo, pode optar por agrupar as métricas do App Engine com base no módulo do App Engine. O agrupamento pelo módulo do App Engine, em combinação com os alinhadores e os redutores que agregam a 1 hora, produz 1 ponto de dados por módulo do App Engine por hora.
A agregação de métricas equilibra o aumento do custo do registo de pontos de dados individuais com a necessidade de reter dados suficientes para uma análise detalhada a longo prazo.
Detalhes da implementação de referência
A implementação de referência contém os mesmos componentes descritos no diagrama de design da arquitetura. Os detalhes de implementação funcionais e relevantes em cada passo são descritos abaixo.
Crie uma lista de métricas
O Cloud Monitoring define mais de mil tipos de métricas para ajudar a
monitorizar Google Cloudo AWS e o software de terceiros. A API Monitoring fornece o método projects.metricDescriptors.list, que devolve uma lista de métricas disponíveis para um projeto Google Cloud. A API Monitoring oferece um mecanismo de filtragem para que possa filtrar uma lista de métricas que quer exportar para armazenamento e análise a longo prazo.
A implementação de referência no GitHub usa uma app do App Engine em Python para obter uma lista de métricas e, em seguida, escreve cada mensagem num tópico do Pub/Sub separadamente. A exportação é iniciada por um Cloud Scheduler que gera uma notificação do Pub/Sub para executar a app.
Existem muitas formas de chamar a API Monitoring e, neste caso, as APIs Cloud Monitoring e Pub/Sub são chamadas através da biblioteca cliente de APIs Google para Python devido ao seu acesso flexível às APIs Google.
Get timeseries
Extrai o timeseries para a métrica e, em seguida, escreve cada timeseries no Pub/Sub. Com a API Monitoring, pode agregar os valores das métricas num determinado período de alinhamento através do método project.timeseries.list. A agregação de dados reduz a carga de processamento, os requisitos de armazenamento, os tempos de consulta e os custos de análise. A agregação de dados é uma prática recomendada para realizar de forma eficiente a análise de métricas a longo prazo.
A implementação de referência no GitHub usa uma app do App Engine em Python para subscrever o tópico, onde cada métrica para exportação é enviada como uma mensagem separada. Para cada mensagem recebida, o Pub/Sub envia a mensagem para a app do App Engine. A app recebe o timeseries para uma determinada métrica agregada com base na configuração de entrada. Neste caso, as APIs Cloud Monitoring e Pub/Sub são chamadas através da biblioteca cliente de APIs Google.
Cada métrica pode devolver 1 ou mais timeseries. Cada métrica é enviada por uma mensagem Pub/Sub separada para inserção no BigQuery. O mapeamento da métrica type-to-aligner e da métrica type-to-reducer está integrado na implementação de referência. A tabela seguinte capta o mapeamento usado na implementação de referência com base nas classes de tipos de métricas e tipos de valores suportados pelos alinhadores e redutores.
| Tipo de valor | GAUGE |
Alinhador | Redutor | DELTA |
Alinhador | Redutor | CUMULATIVE2 |
Alinhador | Redutor |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
sim |
ALIGN_FRACTION_TRUE
|
nenhum | não | N/A | N/A | não | N/A | N/A |
INT64 |
sim |
ALIGN_SUM
|
nenhum | sim |
ALIGN_SUM
|
nenhum | sim | nenhum | nenhum |
DOUBLE |
sim |
ALIGN_SUM
|
nenhum | sim |
ALIGN_SUM
|
nenhum | sim | nenhum | nenhum |
STRING |
sim | excluído | excluído | não | N/A | N/A | não | N/A | N/A |
DISTRIBUTION |
sim |
ALIGN_SUM
|
nenhum | sim |
ALIGN_SUM
|
nenhum | sim | nenhum | nenhum |
MONEY |
não | N/A | N/A | não | N/A | N/A | não | N/A | N/A |
É importante considerar o mapeamento de valueType para alinhadores e redutores, uma vez que a agregação só é possível para valueTypes e metricKinds específicos para cada alinhador e redutor.
Por exemplo, considere o tipo
pubsub.googleapis.com/subscription/push_request_count metric. Com base no DELTA tipo de métrica e no INT64 tipo de valor, uma forma de agregar a métrica é:
- Período de alinhamento: 3600 s (1 hora)
Aligner = ALIGN_SUM– O ponto de dados resultante no período de alinhamento é a soma de todos os pontos de dados no período de alinhamento.Reducer = REDUCE_SUM– Reduza calculando a soma detimeseriespara cada período de alinhamento.
Juntamente com o período de alinhamento, o alinhador e os valores do redutor, o método project.timeseries.list requer várias outras entradas:
filter: selecione a métrica a devolver.startTime- Selecione o ponto de partida no tempo para o qual pretende obter resultadostimeseries.endTime- Selecione o último ponto no tempo para o qual deve ser devolvido o valortimeseries.groupBy- Introduza os campos nos quais agrupar a respostatimeseries.alignmentPeriod- Introduza os períodos nos quais quer alinhar as métricas.perSeriesAligner- Alinhe os pontos em intervalos de tempo uniformes definidos por umalignmentPeriod.crossSeriesReducer- Combine vários pontos com diferentes valores de etiquetas num único ponto por intervalo de tempo.
O pedido GET à API inclui todos os parâmetros descritos na lista anterior.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
O exemplo seguinte HTTP GET fornece uma chamada de exemplo ao método da API projects.timeseries.list através dos parâmetros de entrada:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
A chamada API Monitoring anterior inclui um
crossSeriesReducer=REDUCE_SUM, o que significa que as métricas são reduzidas e
agrupadas numa única soma, conforme mostrado no exemplo seguinte.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
Este nível de agregação agrega dados num único ponto de dados, o que a torna uma métrica ideal para o seu Google Cloud projeto geral. No entanto, não permite analisar em detalhe os recursos que contribuíram para a métrica. No exemplo anterior, não é possível saber que subscrição do Pub/Sub contribuiu mais para a contagem de pedidos.
Se quiser rever os detalhes dos componentes individuais que geram o
timeseries, pode remover o parâmetro crossSeriesReducer.
Sem o crossSeriesReducer, a API Monitoring não combina os vários timeseries para criar um único valor.
O exemplo seguinte HTTP GET fornece uma chamada de exemplo ao método da API projects.timeseries.list através dos parâmetros de entrada. O
crossSeriesReducer não está incluído.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
Na seguinte resposta JSON, os metric.labels.keys são iguais em ambos os resultados porque o timeseries está agrupado. São devolvidos pontos separados para cada um dos valores resource.labels.subscription_ids. Reveja os valores metric_export_init_pub e metrics_list no seguinte JSON. Este nível de agregação é recomendado porque permite usar
Google Cloud produtos, incluídos como etiquetas de recursos, nas suas
consultas do BigQuery.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Cada métrica na saída JSON da chamada da API projects.timeseries.list é escrita diretamente no Pub/Sub como uma mensagem separada. Existe uma potencial expansão em que 1 métrica de entrada gera 1 ou mais timeseries.
O Pub/Sub oferece a capacidade de absorver um potencial fan-out grande sem exceder os limites de tempo.
O período de alinhamento fornecido como entrada significa que os valores ao longo desse período são agregados num único valor, conforme mostrado na resposta de exemplo anterior. O período de alinhamento também define a frequência de execução da exportação. Por exemplo, se o período de alinhamento for de 3600 segundos, ou 1 hora, a exportação é executada a cada hora para exportar regularmente o timeseries.
Métricas de lojas
A implementação de referência no GitHub usa uma app do App Engine em Python para
ler cada timeseries e, em seguida, inserir os registos na tabela do
BigQuery. Para cada mensagem recebida, o Pub/Sub envia a mensagem para a app do App Engine. A mensagem do Pub/Sub contém dados de métricas exportados da API Monitoring num formato JSON e tem de ser mapeada para uma estrutura de tabela no BigQuery. Neste caso, as APIs BigQuery são chamadas através da biblioteca cliente de APIs Google.
O esquema do BigQuery foi concebido para ser mapeado de perto para o JSON exportado da API Monitoring. Ao criar o esquema da tabela do BigQuery, uma consideração é a escala dos tamanhos dos dados à medida que aumentam ao longo do tempo.
No BigQuery, recomendamos que particione a tabela com base num campo de data, uma vez que pode tornar as consultas mais eficientes selecionando intervalos de datas sem incorrer numa análise completa da tabela. Se planeia executar a exportação regularmente, pode usar com segurança a partição predefinida com base na data de carregamento.
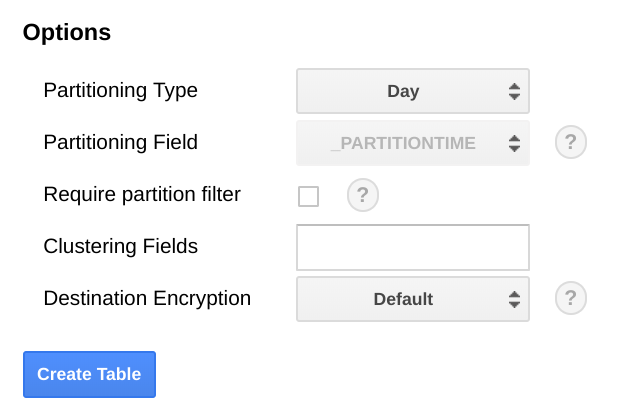
Se planeia carregar métricas em massa ou não executar a exportação periodicamente, faça a partição na end_time,, o que requer alterações ao esquema do BigQuery. Pode mover o elemento end_time para um campo de nível superior no esquema, onde o pode usar para a partição, ou adicionar um novo campo ao esquema. A movimentação do campo end_time é necessária porque o campo está contido num registo do BigQuery e a partição tem de ser feita num campo de nível superior. Para mais informações, leia a
documentação de partição do BigQuery.
O BigQuery também oferece a capacidade de fazer expirar conjuntos de dados, tabelas e partições de tabelas após um determinado período.
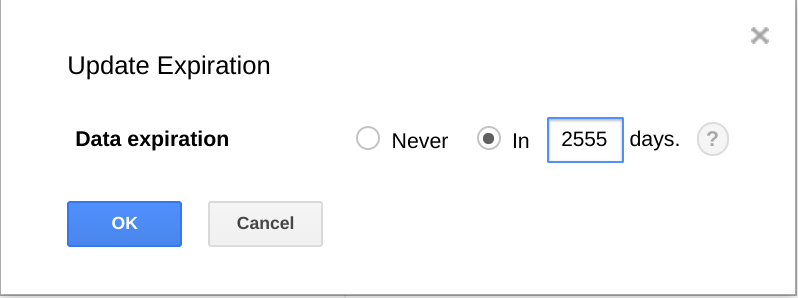
A utilização desta funcionalidade é uma forma útil de limpar dados mais antigos quando estes já não são úteis. Por exemplo, se a sua análise abranger um período de 3 anos, pode adicionar uma política para eliminar dados com mais de 3 anos.
Agende a exportação
O Cloud Scheduler é um agendador de tarefas cronológicas totalmente gerido. O Cloud Scheduler permite-lhe usar o formato de agendamento cron padrão para acionar uma app do App Engine, enviar uma mensagem através do Pub/Sub ou enviar uma mensagem para um ponto final HTTP arbitrário.
Na implementação de referência no GitHub, o Cloud Scheduler aciona a app do App Engine a cada hora enviando uma mensagem do Pub/Sub com um token que corresponde à configuração do App Engine.list-metrics O período de agregação predefinido na configuração da app é de 3600 segundos ou 1 hora, o que está relacionado com a frequência com que a app é acionada. Recomendamos uma agregação mínima de 1 hora, uma vez que oferece um equilíbrio entre a redução dos volumes de dados e a retenção de dados de alta fidelidade. Se usar um período de alinhamento diferente, altere a frequência da exportação para corresponder ao período de alinhamento. A implementação de referência armazena o último valor de end_time no armazenamento na nuvem e usa esse valor como o start_time subsequente, a menos que um start_time seja transmitido como um parâmetro.
A captura de ecrã seguinte do Cloud Scheduler demonstra como pode usar a consola para configurar o Cloud Scheduler de modo a invocar a app do App Engine a cada hora. Google Cloud list-metrics
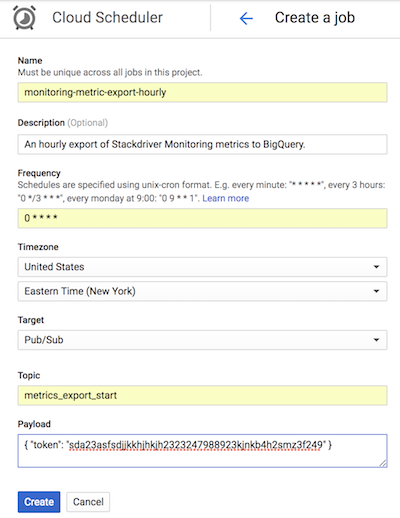
O campo Frequência usa a sintaxe de estilo cron para indicar ao Cloud Scheduler a frequência com que a app deve ser executada. O campo Destino especifica uma mensagem do Pub/Sub que é gerada, e o campo Payload contém os dados incluídos na mensagem do Pub/Sub.
Usar as métricas exportadas
Com os dados exportados no BigQuery, pode agora usar o SQL padrão para consultar os dados ou criar painéis de controlo para visualizar as tendências nas suas métricas ao longo do tempo.
Exemplo de consulta: latências do App Engine
A seguinte consulta encontra o mínimo, o máximo e a média dos valores das métricas de latência média para uma app do App Engine. O metric.type identifica a métrica do App Engine e as etiquetas identificam a app do App Engine com base no valor da etiqueta project_id. O point.value.distribution_value.meané usado porque esta métrica é um valor DISTRIBUTION na API Monitoring, que é mapeado para o objeto de campo distribution_value no BigQuery. O campoend_time analisa os valores dos últimos 30 dias.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Consulta de exemplo: contagens de consultas do BigQuery
A seguinte consulta devolve o número de consultas em relação ao
BigQuery por dia num projeto. O campo int64_value é usado porque esta métrica é um valor INT64 na API Monitoring, que é mapeado para o campo int64_value no BigQuery. O elemento
metric.typeidentifica a métrica do BigQuery e as etiquetas
identificam o projeto com base no valor da etiqueta project_id. O campo end_time analisa os valores dos últimos 30 dias.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
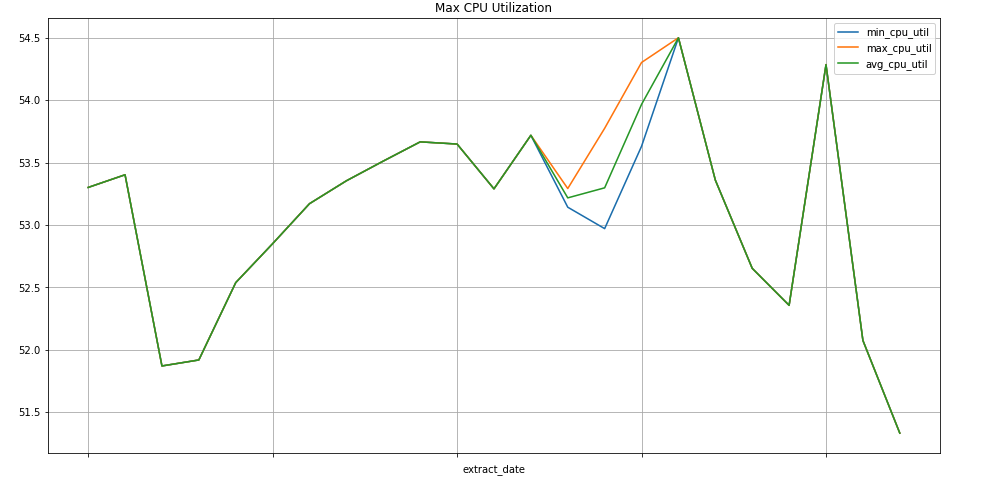
Exemplo de consulta: instâncias do Compute Engine
A consulta seguinte encontra o mínimo, o máximo e a média semanais dos valores da métrica de utilização da CPU para instâncias do Compute Engine de um projeto. O elemento
metric.type identifica a métrica do Compute Engine e as etiquetas
identificam as instâncias com base no valor da etiqueta project_id. O campo end_time
analisa os valores dos últimos 30 dias.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Visualização de dados
O BigQuery está integrado com muitas ferramentas que pode usar para a visualização de dados.
O Looker Studio
é uma ferramenta gratuita criada pela Google onde pode criar gráficos de dados e painéis de controlo para
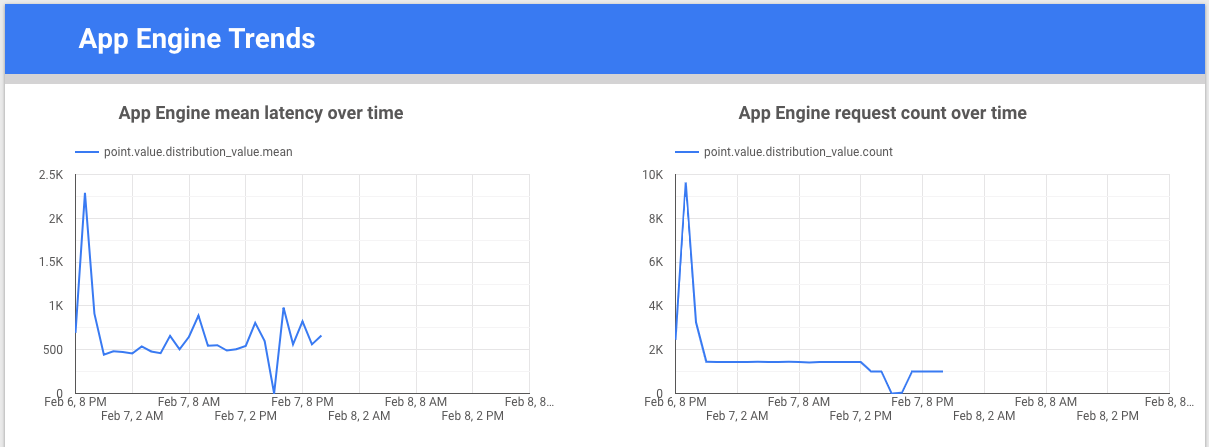
visualizar os dados das métricas e, em seguida, partilhá-los com a sua equipa. O exemplo
seguinte mostra um gráfico de linhas de tendência da latência e da contagem para a métrica
appengine.googleapis.com/http/server/response_latencies ao longo do tempo.
O Colaboratory é uma ferramenta de investigação para a educação e a investigação em aprendizagem automática. É um ambiente de bloco de notas do Jupyter alojado que não requer configuração para usar e aceder aos dados no BigQuery. Usando um bloco de notas do Colab, comandos Python e consultas SQL, pode desenvolver análises e visualizações detalhadas.
Monitorizar a implementação de referência da exportação
Quando a exportação estiver em curso, tem de a monitorizar. Uma forma de decidir que métricas monitorizar é definir um objetivo ao nível do serviço (SLO). Um SLO é um valor ou um intervalo de valores de destino para um nível de serviço que é medido por uma métrica. O livro Site reliability engineering descreve 4 áreas principais para os SLOs: disponibilidade, taxa de transferência, taxa de erro e latência. Para uma exportação de dados, a taxa de transferência e a taxa de erro são duas considerações importantes, e pode monitorizá-las através das seguintes métricas:
- Tráfego transmitido –
appengine.googleapis.com/http/server/response_count - Taxa de erros –
logging.googleapis.com/log_entry_count
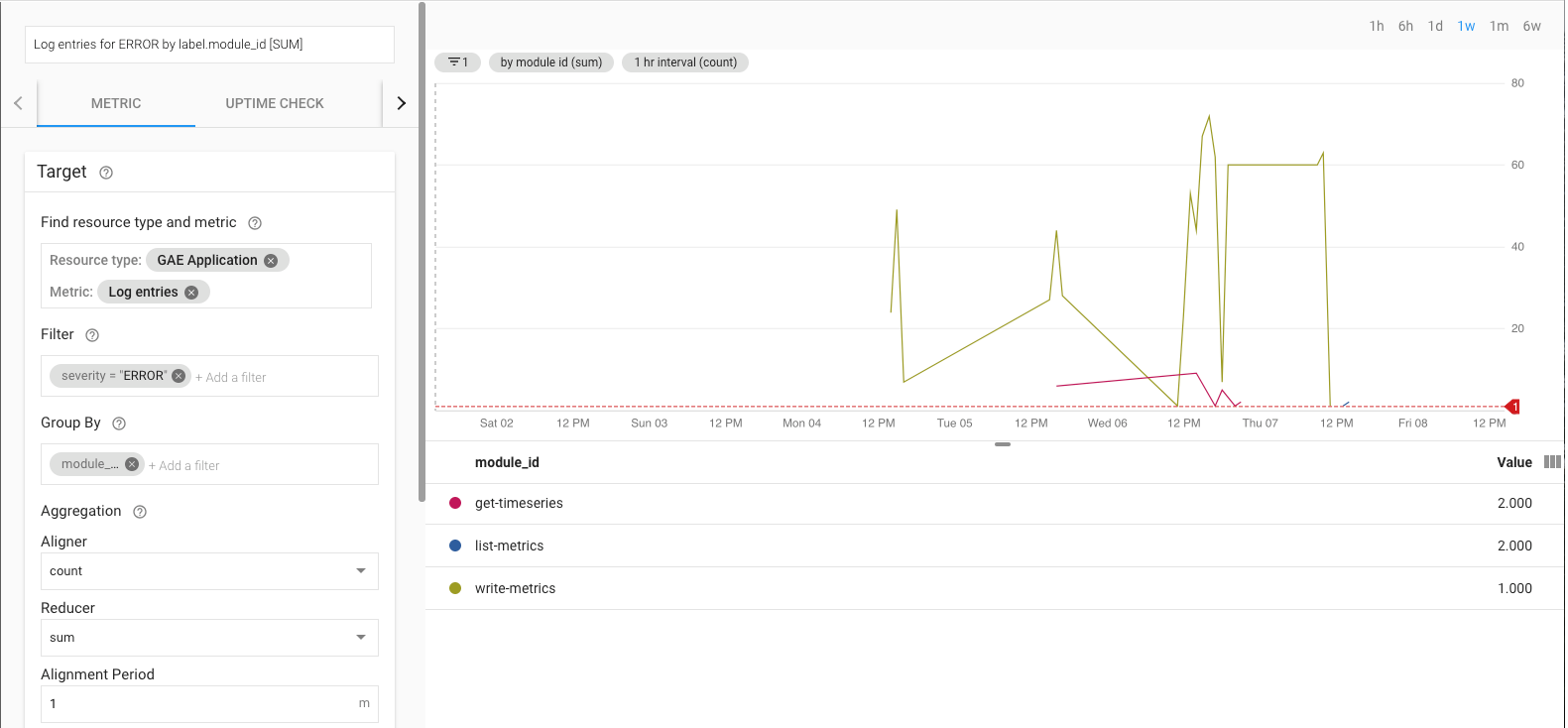
Por exemplo, pode monitorizar a taxa de erros através da métrica log_entry_count
e filtrá-la para as apps do App Engine (list-metrics, get-timeseries e write-metrics) com uma gravidade de ERROR. Em seguida, pode usar as
políticas de alerta
no Cloud Monitoring para receber alertas sobre erros encontrados na app de exportação.
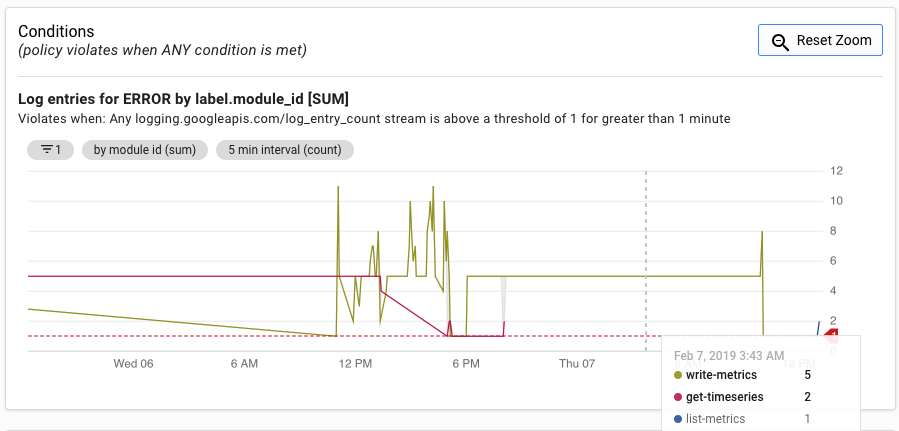
A IU de alertas apresenta um gráfico da métrica log_entry_count em comparação com o limite para gerar o alerta.
O que se segue?
- Veja a implementação de referência no GitHub.
- Leia a documentação do Cloud Monitoring.
- Explore a documentação da API Cloud Monitoring v3.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
- Leia os nossos recursos sobre DevOps.
Saiba mais sobre as capacidades de DevOps relacionadas com esta solução:
Faça a verificação rápida de DevOps para saber a sua posição em comparação com o resto da indústria.