For many customers, the first step in adopting a Google Cloud product is getting their data into Google Cloud. This document explores that process, from planning a data transfer to using best practices in implementing a plan.
Transferring large datasets involves building the right team, planning early, and testing your transfer plan before implementing it in a production environment. Although these steps can take as much time as the transfer itself, such preparations can help minimize disruption to your business operations during the transfer.
This document is part of the following multi-part series about migrating to Google Cloud:
- Migrate to Google Cloud: Get started
- Migrate to Google Cloud: Assess and discover your workloads
- Migrate to Google Cloud: Plan and build your foundation
- Migrate to Google Cloud: Transfer your large datasets (this document)
- Migrate to Google Cloud: Deploy your workloads
- Migrate to Google Cloud: Migrate from manual deployments to automated, containerized deployments
- Migrate to Google Cloud: Optimize your environment
- Migrate to Google Cloud: Best practices for validating a migration plan
- Migrate to Google Cloud: Minimize costs
What is data transfer?
For the purposes of this document, data transfer is the process of moving data without transforming it, for example, moving files as they are into objects.
Data transfer isn't as simple as it sounds
It's tempting to think of data transfer as one giant FTP session, where you put your files in one side and wait for them to come out the other side. However, in most enterprise environments, the transfer process involves many factors such as the following:
- Devising a transfer plan that accounts for administrative time, including time to decide on a transfer option, get approvals, and deal with unanticipated issues.
- Coordinating people in your organization, such as the team that executes the transfer, personnel who approve the tools and architecture, and business stakeholders who are concerned with the value and disruptions that moving data can bring.
- Choosing the right transfer tool based on your resources, cost, time, and other project considerations.
- Overcoming data transfer challenges, including "speed of light" issues (insufficient bandwidth), moving datasets that are in active use, protecting and monitoring the data while it's in flight, and ensuring the data is transferred successfully.
This document aims to help you get started on a successful transfer initiative.
Other projects related to data transfer
The following list includes resources for other types of data transfer projects not covered in this document:
- If you need to transform your data (such as combining rows, joining datasets, or filtering out personal identifiable information), you should consider an extract, transform, and load (ETL) solution that can deposit data into a Google Cloud data warehouse.
- If you need to migrate a database and related apps (for example, to migrate a database app), see Database migration: Concepts and principles.
Step 1: Assembling your team
Planning a transfer typically requires personnel with the following roles and responsibilities:
- Enabling resources needed for a transfer: Storage, IT, and network admins, an executive sponsor, and other advisors (for example, a Google Account team or integration partners)
- Approving the transfer decision: Data owners or governors (for internal policies on who is allowed to transfer what data), legal advisors (for data-related regulations), and a security administrator (for internal policies on how data access is protected)
- Executing the transfer: A team lead, a project manager (for executing and tracking the project), an engineering team, and on-site receiving and shipping (to receive appliance hardware)
It's crucial to identify who owns the preceding responsibilities for your transfer project and to include them in planning and decision meetings when appropriate. Poor organizational planning is often the cause of failed transfer initiatives.
Gathering project requirements and input from these stakeholders can be challenging, but making a plan and establishing clear roles and responsibilities pays off. You can't be expected to know all the details of your data. Assembling a team gives you greater insight into the needs of the business. It's a best practice to identify potential issues before you invest time, money, and resources to complete the transfers.
Step 2: Collecting requirements and available resources
When you design a transfer plan, we recommend that you first collect requirements for your data transfer and then decide on a transfer option. To collect requirements, you can use the following process:
- Identify what datasets you need to move.
- Select tools like Data Catalog to organize your data into logical groupings that are moved and used together.
- Work with teams within your organization to validate or update these groupings.
- Identify what datasets you can move.
- Consider whether regulatory, security, or other factors prohibit some datasets from being transferred.
- If you need to transform some of your data before you move it (for example, to remove sensitive data or reorganize your data), consider using a data integration product like Dataflow or Cloud Data Fusion, or a workflow orchestration product like Cloud Composer.
- For datasets that are movable, determine where to transfer each dataset.
- Record which storage option you select to store your data. Typically, the target storage system on Google Cloud is Cloud Storage. Even if you need more complex solutions after your applications are up and running, Cloud Storage is a scalable and durable storage option.
- Understand what data access policies must be maintained after migration.
- Determine if you need to store this data in specific regions.
- Plan how to structure this data at the destination. For example, will it be the same as the source or different?
- Determine if you need to transfer data on an ongoing basis.
- For datasets that are movable, determine what resources are available
to move them.
- Time: When does the transfer need to be completed?
- Cost: What is the budget available for the team and transfer costs?
- People: Who is available to execute the transfer?
- Bandwidth (for online transfers): How much of your available bandwidth for Google Cloud can be allocated for a transfer, and for what period of time?
Before you evaluate and select transfer options in the next phase of planning, we recommend that you assess whether any part of your IT model can be improved, such as data governance, organization, and security.
Your security model
Many members of the transfer team might be granted new roles in your Google Cloud organization as part of your data transfer project. Data transfer planning is a great time to review your Identity and Access Management (IAM) permissions and best practices for using IAM securely. These issues can affect how you grant access to your storage. For example, you might place strict limits on write access to data that has been archived for regulatory reasons, but you might allow many users and applications to write data to your test environment.
Your Google Cloud organization
How you structure your data on Google Cloud depends on how you plan to use Google Cloud. Storing your data in the same Google Cloud project where you run your application may work, but it might not be optimal from a management perspective. Some of your developers might not have privilege to view the production data. In that case, a developer could develop code on sample data, while a privileged service account could access production data. Thus, you might want to keep your entire production dataset in a separate Google Cloud project, and then use a service account to allow access to the data from each application project.
Google Cloud is organized around projects. Projects can be grouped into folders, and folders can be grouped under your organization. Roles are established at the project level and the access permissions are added to these roles at the Cloud Storage bucket levels. This structure aligns with the permissions structure of other object store providers.
For best practices to structure a Google Cloud organization, see Decide a resource hierarchy for your Google Cloud landing zone.
Step 3: Evaluating your transfer options
To evaluate your data transfer options, the transfer team needs to consider several factors, including the following:
- Cost
- Transfer time
- Offline versus online transfer options
- Transfer tools and technologies
- Security
Cost
Most of the costs associated with transferring data include the following:
- Networking costs
- Ingress to Cloud Storage is free. However, if you're hosting your data on a public cloud provider, you can expect to pay an egress charge and potentially storage costs (for example, read operations) for transferring your data. This charge applies for data coming from Google or another cloud provider.
- If your data is hosted in a private data center that you operate, you might also incur added costs for setting up more bandwidth to Google Cloud.
- Storage and operation costs for Cloud Storage during and after the transfer of data
- Product costs (for example, a Transfer Appliance)
- Personnel costs for assembling your team and acquiring logistical support
Transfer time
Few things in computing highlight the hardware limitations of networks as transferring large amounts of data. Ideally, you can transfer 1 GB in eight seconds over a 1 Gbps network. If you scale that up to a huge dataset (for example, 100 TB), the transfer time is 12 days. Transferring huge datasets can test the limits of your infrastructure and potentially cause problems for your business.
When you estimate how much time a transfer might take, include the following factors in your calculations:
- The size of the dataset you're moving.
- The bandwidth available for the transfer.
- A certain percentage of management time.
- The bandwidth efficiency, which can also have an impact on transfer time.
You might not want to transfer large datasets out of your company network during peak work hours. If the transfer overloads the network, nobody else will be able to get necessary or mission-critical work completed. For this reason, the transfer team needs to consider the factor of time.
After the data is transferred to Cloud Storage, you can use a number of technologies to process the new files as they arrive, such as Dataflow.
Increasing network bandwidth
How you increase network bandwidth depends on how you connect to Google Cloud.
In a cloud-to-cloud transfer between Google Cloud and other cloud providers, Google provisions the connection between cloud vendor data centers, requiring no setup from you.
If you're transferring data between your private data center and Google Cloud, there are several approaches, such as:
- A public internet connection by using a public API
- Direct Peering by using a public API
- Cloud Interconnect by using a private API
When evaluating these approaches, it's helpful to consider your long-term connectivity needs. You might conclude that it's cost prohibitive to acquire bandwidth solely for transfer purposes, but when factoring in long-term use of Google Cloud and the network needs across your organization, the investment might be worthwhile. For more information about how to connect your networks to Google Cloud, see Choose a Network Connectivity product.
If you opt for an approach that involves transferring data over the public internet, we recommend that you check with your security administrator on whether your company policy forbids such transfers. Also, check whether the public internet connection is used for your production traffic. Finally, consider that large-scale data transfers might negatively impact the performance of your production network.
Online versus offline transfer
A critical decision is whether to use an offline or online process for your data transfer. That is, you must choose between transferring over a network, whether it's a Cloud Interconnect or the public internet, or transferring by using storage hardware.
To help with this decision, the following chart also shows some transfer speeds for various dataset sizes and bandwidths. A certain amount of management overhead is built into these calculations.
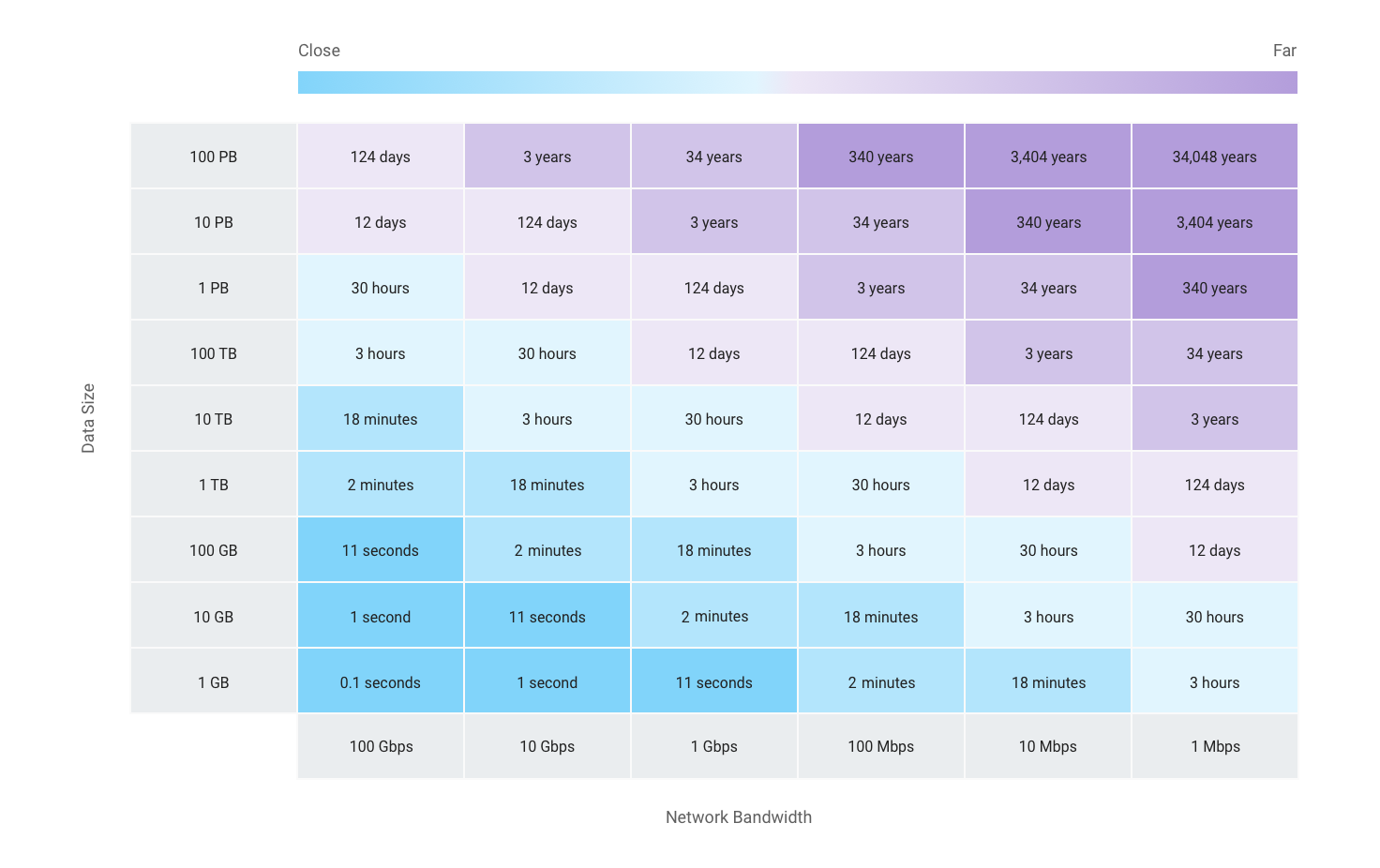
As noted earlier, you might need to consider whether the cost to achieve lower latencies for your data transfer (such as acquiring network bandwidth) is offset by the value of that investment to your organization.
Options available from Google
Google offers several tools and technologies to help you perform a data transfer.
Deciding among Google's transfer options
Choosing a transfer option depends on your use case, as the following table shows.
| Where you're moving data from | Scenario | Suggested products |
|---|---|---|
| Another cloud provider (for example, Amazon Web Services or Microsoft Azure) to Google Cloud | — | Storage Transfer Service |
| Cloud Storage to Cloud Storage (two different buckets) | — | Storage Transfer Service |
| Your private data center to Google Cloud | Enough bandwidth to meet your project deadline | gcloud storage command
|
| Your private data center to Google Cloud | Enough bandwidth to meet your project deadline | Storage Transfer Service for on-premises data |
| Your private data center to Google Cloud | Not enough bandwidth to meet your project deadline | Transfer Appliance |
gcloud storage command for smaller transfers of on-premises data
The gcloud storage command
is the standard tool for small- to medium-sized transfers over a typical
enterprise-scale network, from a private data center or from another cloud
provider to Google Cloud. While gcloud storage supports uploading objects up
to the
maximum Cloud Storage object size,
transfers of large objects are more likely to experience failures than short-running transfers.
For more information about transferring large objects to Cloud Storage,
see Storage Transfer Service for large transfers of on-premises data.
The gcloud storage command is especially useful in the following scenarios:
- Your transfers need to be executed on an as-needed basis, or during command-line sessions by your users.
- You're transferring only a few files or very large files, or both.
- You're consuming the output of a program (streaming output to Cloud Storage).
- You need to watch a directory with a moderate number of files and sync any updates with very low latencies.
Storage Transfer Service for large transfers of on-premises data
Like the gcloud storage command,
Storage Transfer Service for on-premises data
enables transfers from network file system (NFS) storage to
Cloud Storage. Storage Transfer Service for on-premises data is designed
for large-scale transfers (up to petabytes of data, billions of files). It
supports full copies or incremental copies, and it works on all transfer options
listed earlier in
Deciding among Google's transfer options. It
also has a managed graphical user interface; even non-technically savvy
users (after setup) can use it to move data.
Storage Transfer Service for on-premises data is especially useful in the following scenarios:
- You have sufficient available bandwidth to move the data volumes.
- You support a large base of internal users who might find a command-line tool challenging to use.
- You need robust error-reporting and a record of all files and objects that are moved.
- You need to limit the impact of transfers on other workloads in your data center (this product can stay under a user-specified bandwidth limit).
- You want to run recurring transfers on a schedule.
You set up Storage Transfer Service for on-premises data by installing on-premises software (known as agents) onto computers in your data center.
After setting up Storage Transfer Service, you can initiate transfers in the
Google Cloud console by providing a source directory, destination bucket, and time
or schedule.
Storage Transfer Service recursively crawls subdirectories and files in the
source directory and creates objects with a corresponding name in
Cloud Storage (the object /dir/foo/file.txt becomes an object in the
destination bucket named /dir/foo/file.txt). Storage Transfer Service
automatically re-attempts a transfer when it encounters any transient errors.
While the transfers are running, you can monitor how many files are moved and
the overall transfer speed, and you can view error samples.
When Storage Transfer Service completes a transfer, it generates a tab-delimited file (TSV) with a full record of all files touched and any error messages received. Agents are fault tolerant, so if an agent goes down, the transfer continues with the remaining agents. Agents are also self-updating and self-healing, so you don't have to worry about patching the latest versions or restarting the process if it goes down because of an unanticipated issue.
Things to consider when using Storage Transfer Service:
- Use an identical agent setup on every machine. All agents should see the same Network File System (NFS) mounts in the same way (same relative paths). This setup is a requirement for the product to function.
- More agents results in more speed. Because transfers are automatically parallelized across all agents, we recommend that you deploy many agents so that you use your available bandwidth.
- Bandwidth caps can protect your workloads. Your other workloads might be using your data center bandwidth, so set a bandwidth cap to prevent transfers from impacting your SLAs.
- Plan time for reviewing errors. Large transfers can often result in errors requiring review. Storage Transfer Service lets you see a sample of the errors encountered directly in the Google Cloud console. If needed, you can load the full record of all transfer errors to BigQuery to check on files or evaluate errors that remained even after retries. These errors might be caused by running apps that were writing to the source while the transfer occurred, or the errors might reveal an issue that requires troubleshooting (for example, permissions error).
- Set up Cloud Monitoring for long-running transfers. Storage Transfer Service lets Monitoring monitor agent health and throughput, so you can set alerts that notify you when agents are down or need attention. Acting on agent failures is important for transfers that take several days or weeks, so that you avoid significant slowdowns or interruptions that can delay your project timeline.
Transfer Appliance for larger transfers
For large-scale transfers (especially transfers with limited network bandwidth), Transfer Appliance is an excellent option, especially when a fast network connection is unavailable and it's too costly to acquire more bandwidth.
Transfer Appliance is especially useful in the following scenarios:
- Your data center is in a remote location with limited or no access to bandwidth.
- Bandwidth is available, but cannot be acquired in time to meet your deadline.
- You have access to logistical resources to receive and connect appliances to your network.
With this option, consider the following:
- Transfer Appliance requires that you're able to receive and ship back the Google-owned hardware.
- Depending on your internet connection, the latency for transferring data into Google Cloud is typically higher with Transfer Appliance than online.
- Transfer Appliance is available only in certain countries.
The two main criteria to consider with Transfer Appliance are cost and speed. With reasonable network connectivity (for example, 1 Gbps), transferring 100 TB of data online takes over 10 days to complete. If this rate is acceptable, an online transfer is likely a good solution for your needs. If you only have a 100 Mbps connection (or worse from a remote location), the same transfer takes over 100 days. At this point, it's worth considering an offline-transfer option such as Transfer Appliance.
Acquiring a Transfer Appliance is straightforward. In the Google Cloud console, you request a Transfer Appliance, indicate how much data you have, and then Google ships one or more appliances to your requested location. You're given a number of days to transfer your data to the appliance ("data capture") and ship it back to Google.
Storage Transfer Service for cloud-to-cloud transfers
Storage Transfer Service is a fully managed, highly scalable service to automate transfers from other public clouds into Cloud Storage. For example, you can use Storage Transfer Service to transfer data from Amazon S3 to Cloud Storage.
For HTTP, you can give Storage Transfer Service a list of public URLs in
a specified format.
This approach requires that you write a script providing the size of each
file in bytes, along with a Base64-encoded MD5 hash of the file contents.
Sometimes the file size and hash are available from the source website. If
not, you need local access to the files, in which case, it might be easier to
use the gcloud storage command, as described earlier.
If you have a transfer in place, Storage Transfer Service is a great way to get data and keep it, particularly when transferring from another public cloud.
If you would like to move data from another cloud not supported by
Storage Transfer Service, you can use the gcloud storage command from a
cloud-hosted virtual machine instance.
Security
For many Google Cloud users, security is their primary focus, and there are different levels of security available. A few aspects of security to consider include protecting data at rest (authorization and access to the source and destination storage system), protecting data while in transit, and protecting access to the transfer product. The following table outlines these aspects of security by product.
| Product | Data at rest | Data in transit | Access to transfer product |
|---|---|---|---|
| Transfer Appliance | All data is encrypted at rest. | Data is protected with keys managed by the customer. | Anyone can order an appliance, but to use it they need access to the data source. |
gcloud storage command |
Access keys required to access Cloud Storage, which is encrypted at rest. | Data is sent over HTTPS and encrypted in transit. | Anyone can download and run the Google Cloud CLI. They must have permissions to buckets and local files in order to move data. |
| Storage Transfer Service for on-premises data | Access keys required to access Cloud Storage, which is encrypted at rest. The agent process can access local files as OS permissions allow. | Data is sent over HTTPS and encrypted in transit. | You must have object editor permissions to access Cloud Storage buckets. |
| Storage Transfer Service | Access keys required for non-Google Cloud resources (for example, Amazon S3). Access keys are required to access Cloud Storage, which is encrypted at rest. | Data is sent over HTTPS and encrypted in transit. | You must have IAM permissions for the service account to access the source and object editor permissions for any Cloud Storage buckets. |
To achieve baseline security enhancements, online transfers to
Google Cloud using the gcloud storage command
are accomplished over HTTPS, data is encrypted in transit, and all data in
Cloud Storage is, by default, encrypted at rest.
If you use
Transfer Appliance,
security keys that you control can help protect your data. Generally, we
recommend that you engage your security team to ensure that your transfer plan
meets your company and regulatory requirements.
Third-party transfer products
For advanced network-level optimization or ongoing data transfer workflows, you might want to use more advanced tools. For information about more advanced tools, see Google Cloud partners.
Step 4: Evaluating data migration approaches
When migrating data, you can follow these general steps:
- Transfer data from the legacy site to the new site.
- Resolve any data integration issues that arise—for example, synchronizing the same data from multiple sources.
- Validate the data migration.
- Promote the new site to be the primary copy.
- When you no longer need the legacy site as a fallback option, retire it.
You should base your data migration approach on the following questions:
- How much data do you need to migrate?
- How often does this data change?
- Can you afford the downtime represented by a cut-over window while migrating data?
- What is your current data consistency model?
There is no best approach; choosing one depends on the environment and on your requirements.
The following sections present four data migration approaches:
- Scheduled maintenance
- Continuous replication
- Y (writing and reading)
- Data-access microservice
Each approach tackles different issues, depending on the scale and the requirements of the data migration.
The data-access microservice approach is the preferred option in a microservices architecture. However, the other approaches are useful for data migration. They're also useful during the transition period that's necessary in order to modernize your infrastructure to use the data-access microservice approach.
The following graph outlines the respective cut-over windows sizes, refactoring effort, and flexibility properties of each of these approaches.

Before following any of these approaches, make sure that you've set up the required infrastructure in the new environment.
Scheduled maintenance
The scheduled maintenance approach (also called one-time migration or big bang migration) is ideal if your workloads can afford a cut-over window. It's scheduled in the sense that you can plan when your cut-over window occurs.
In this approach, your migration consists of these steps:
- Copy data that's in the legacy site to the new site. This initial copy minimizes the cut-over window; after this initial copy, you need to copy only the data that has changed during this window.
- Perform data validation and consistency checks to compare data in the legacy site against the copied data in the new site.
- Stop the workloads and services that have write access to the copied data, so that no further changes occur.
- Synchronize changes that occurred after the initial copy.
- Refactor workloads and services to use the new site.
- Start your workloads and services.
- When you no longer need the legacy site as a fallback option anymore, retire it.
The scheduled maintenance approach places most of the burden on the operations side, because minimal refactoring of workload and services is needed.
Continuous replication
Because not all workloads can afford a long cut-over window, you can build on the scheduled maintenance approach by providing a continuous replication mechanism after the initial copy and validation steps. When you design a mechanism like this, you should also take into account the rate at which changes are applied to your data; it might be challenging to keep two systems synchronized.
The continuous replication approach (also called online migration or trickle migration) is more complex than the scheduled maintenance approach. However, the continuous replication approach minimizes the time for the required cut-over window, because it minimizes the amount of data that you need to synchronize.The sequence for a continuous replication migration is as follows:
- Copy data that's in the legacy site to the new site. This initial copy minimizes the cut-over window; after the initial copy, you need to copy only the data that changed during this window.
- Perform data validation and consistency checks to compare data in the legacy site against the copied data in the new site.
- Set up a continuous replication mechanism from the legacy site to the new site.
- Stop the workloads and services that have access to the data to migrate (that is, to the data involved in the previous step).
- Refactor workloads and services to use the new site.
- Wait for the replication to fully synchronize the new site with the legacy site.
- Start your workloads and services.
- When you no longer need the legacy site as a fallback option anymore, retire it.
As with the scheduled maintenance approach, the continuous replication approach places most of the burden on the operations side.
Y (writing and reading)
If your workloads have hard high-availability requirements and you cannot afford the downtime represented by a cut-over window, you need to take a different approach. For this scenario, you can use an approach that in this document is referred to as Y (writing and reading), which is a form of parallel migration. With this approach, the workload is writing and reading data in both the legacy site and the new site during the migration. (The letter Y is used here as a graphic representation of the data flow during the migration period.)
This approach is summarized as follows:
- Refactor workloads and services to write data both to the legacy site and to the new site and to read from the legacy site.
- Identify the data that was written before you enabled writes in the new site and copy it from the legacy site to the new site. Along with the preceding refactoring, this ensures that the data stores are aligned.
- Perform data validation and consistency checks that compare data in the legacy site against data in the new site.
- Switch read operations from the legacy site to the new site.
- Perform another round of data validation and consistency checks to compare data in the legacy site against the new site.
- Disable writing in the legacy site.
- When you no longer need the legacy site as a fallback option anymore, retire it.
Unlike the scheduled maintenance and continuous replication approaches, the Y (writing and reading) approach shifts most of the efforts from the operations side to the development side due to the multiple refactorings.
Data-access microservice
If you want to reduce the refactoring effort necessary to follow the Y (writing and reading) approach, you can centralize data read and write operations by refactoring workloads and services to use a data-access microservice. This scalable microservice becomes the only entry point to your data storage layer, and it acts as a proxy for that layer. Of the approaches discussed here, this gives you the maximum flexibility, because you can refactor this component without impacting other components of the architecture and without requiring a cut-over window.
Using a data-access microservice is much like the Y (writing and reading) approach. The difference is that the refactoring efforts focus on the data-access microservice alone, instead of having to refactor all the workloads and services that access the data storage layer. This approach is summarized as follows:
- Refactor the data-access microservice to write data both in the legacy site and the new site. Reads are performed against the legacy site.
- Identify the data that was written before you enabled writes in the new site and copy it from the legacy site to the new site. Along with the preceding refactoring, this ensures that the data stores are aligned.
- Perform data validation and consistency checks comparing data in the legacy site against data in the new site.
- Refactor the data-access microservice to read from the new site.
- Perform another round of data validation and consistency checks comparing data in the legacy site against data in the new site.
- Refactor the data-access microservice to write only in the new site.
- When you no longer need the legacy site as a fallback option anymore, retire it.
Like the Y (writing and reading) approach, the data-access microservice approach places most of the burden on the development side. However, it's significantly lighter compared to the Y (writing and reading) approach, because the refactoring efforts are focused on the data-access microservice.
Step 5: Preparing for your transfer
For a large transfer, or a transfer with significant dependencies, it's important to understand how to operate your transfer product. Customers typically go through the following steps:
- Pricing and ROI estimation. This step provides many options to aid in decision making.
Functional testing. In this step, you confirm that the product can be successfully set up and that network connectivity (where applicable) is working. You also test that you can move a representative sample of your data (including accompanying non-transfer steps, like moving a VM instance) to the destination.
You can usually do this step before allocating all resources such as transfer machines or bandwidth. The goals of this step include the following:
- Confirm that you can install and operate the transfer.
- Surface potential project-stopping issues that block data movement (for example, network routes) or your operations (for example, training needed on a non-transfer step).
Performance testing. In this step, you run a transfer on a large sample of your data (typically 3–5%) after production resources are allocated to do the following:
- Confirm that you can consume all allocated resources and can achieve getting the speeds you expect.
- Surface and fix bottlenecks (for example, slow source storage system).
Step 6: Ensuring the integrity of your transfer
To help ensure the integrity of your data during a transfer, we recommend taking the following precautions:
- Enable versioning and backup on your destination to limit the damage of accidental deletes.
- Validate your data before removing the source data.
For large-scale data transfers (with petabytes of data and billions of files), a baseline latent error rate of the underlying source storage system as low as 0.0001% still results in a data loss of thousands of files and gigabytes. Typically, applications running at the source are already tolerant of these errors, in which case, extra validation isn't necessary. In some exceptional scenarios (for example, long-term archive), more validation is necessary before it's considered safe to delete data from the source.
Depending on the requirements of your application, we recommend that you run some data integrity tests after the transfer is complete to ensure that the application continues to work as intended. Many transfer products have built-in data integrity checks. However, depending on your risk profile, you might want to do an extra set of checks on the data and the apps reading that data before you delete data from the source. For example, you might want to confirm whether a checksum that you recorded and computed independently matches the data written at the destination, or confirm that a dataset used by the application transferred successfully.
What's next
- Learn when to find help for your migrations.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
Contributors
Authors:
- Marco Ferrari | Cloud Solutions Architect
- Ross Thomson | Cloud Solutions Architect