데이터베이스를 보안하고 구성한 후 데이터베이스를 Looker에 연결할 수 있습니다.
새 데이터베이스 연결 만들기
관리자 패널의 데이터베이스 섹션에서 연결을 선택합니다. 연결 페이지에서 연결 추가 버튼을 클릭합니다. Looker에서 연결 설정 페이지를 표시합니다. 연결 설정 페이지에 표시되는 필드는 언어 설정에 따라 다릅니다.
연결 설정에 사용자 속성을 적용하는 방법에 대한 자세한 내용은 사용자 속성 문서 페이지의 연결 섹션을 참고하세요.
PDT 재정의 열을 사용하여 PDT 프로세스에 별도의 로그인 사용자 인증 정보를 구성하는 방법에 대한 자세한 내용은 PDT 프로세스에 별도의 로그인 사용자 인증 정보 구성 섹션을 참조하세요.
예를 들어 Looker와 Amazon Redshift를 다시 연결할 때 다음 옵션을 구성할 수 있습니다.
이름
참조하려는 연결의 이름입니다. 폴더의 이름을 사용하면 안 됩니다. 이 값은 데이터베이스의 어떤 항목과도 일치하지 않아도 되며, 할당한 라벨일 뿐입니다. LookML 모델의 connection 매개변수에서 사용합니다.
언어
연결과 일치하는 SQL 언어 적절한 연결 옵션을 제시하고 Looker에서 LookML을 SQL로 적절하게 변환할 수 있도록 올바른 값을 선택하는 것이 중요합니다.
SSH 서버
SSH 서버 옵션은 인스턴스가 Kubernetes 인프라에 배포되고 SSH 서버 구성 정보를 Looker 인스턴스에 추가하는 기능이 사용 설정된 경우에만 사용할 수 있습니다. 이 옵션이 Looker 인스턴스에 사용 설정되지 않은 상태에서 사용 설정하려면 Looker 계정 관리자에게 문의하거나 Looker 고객센터에서 지원 요청을 여세요.
SSH 서버가 자동으로 localhost 포트를 선택하지만 현재 localhost 포트를 지정할 수 없습니다. localhost 포트를 지정해야 하는 SSH 연결을 만들어야 하는 경우 Looker 계정 관리자에게 문의하거나 Looker 고객센터에서 지원 요청을 여세요.
SSH 터널을 사용하여 데이터베이스에 연결하려면 전환 버튼을 사용 설정하고 드롭다운 목록에서 SSH 서버 구성을 선택합니다.
원격 호스트:포트
Looker에서 데이터베이스 호스트에 연결하는 데 사용할 데이터베이스 호스트 이름과 포트입니다.
Looker 분석가와 협력하여 데이터베이스에 SSH 터널을 구성한 경우 호스트 필드에 "localhost"을 입력하고 포트 필드에 데이터베이스로 리디렉션되는 포트 번호를 입력합니다. 이 포트는 Looker 분석가가 제공해야 합니다.
사용자 속성을 호스트 입력란에 적용하는 경우 사용자 속성의 사용자 액세스 수준을 수정 가능으로 설정하면 안 됩니다.
데이터베이스에 연결하도록 SSH 터널을 구성한 경우 Remote Host:Port 입력란에 사용자 속성을 적용할 수 없습니다.
데이터베이스
호스트에 있는 데이터베이스의 이름입니다. 예를 들어 호스트 이름이 my-instance.us-east-1.redshift.amazonaws.com이고 데이터베이스에 sales_info라는 데이터베이스가 있을 수 있습니다. 이 입력란에 sales_info를 입력합니다. 동일한 호스트에 데이터베이스가 여러 개 있는 경우 데이터베이스를 사용하려면 연결을 여러 개 만들어야 할 수 있습니다 (단, Database라는 단어는 대다수 SQL 언어와 약간 다른 것을 의미함).
OAuth 사용
Snowflake 및 Google BigQuery 연결의 경우 OAuth를 사용할 수 있습니다. 즉, 사용자가 Looker에서 쿼리를 실행하려면 각각 Snowflake 또는 Google에 로그인해야 합니다.
OAuth 사용을 선택하면 OAuth 클라이언트 ID 및 OAuth 클라이언트 보안 비밀번호 입력란이 표시됩니다.
이 값은 Snowflake 데이터베이스 또는 Google에서 생성됩니다. 전체 절차는 Snowflake OAuth 구성 또는 Google BigQuery OAuth 구성을 설명하는 문서를 참조하세요.
사용자 이름
Looker에서 데이터베이스에 연결하는 데 사용할 사용자 이름입니다. 데이터베이스 구성 안내에 따라 미리 사용자를 구성해야 합니다.
비밀번호
Looker에서 데이터베이스에 연결하는 데 사용할 비밀번호입니다. 데이터베이스 구성 안내에 따라 미리 비밀번호를 구성해야 합니다.
스키마
스키마가 지정되지 않은 경우 Looker가 사용하는 기본 스키마입니다. 이는 SQL Runner를 사용하는 경우, LookML 프로젝트를 생성하는 동안, 테이블을 쿼리하는 경우에 적용됩니다.
영구 파생 테이블
이 체크박스를 선택하면 영구 파생 테이블이 사용 설정됩니다. 그러면 추가 PDT 필드와 PDT 재정의 열이 표시됩니다. Looker는 데이터베이스 언어에서 PDT 사용을 지원하는 경우에만 이 옵션을 표시합니다.
PDT에 관한 다음 사항에 유의하세요.
- PDT는 OAuth를 사용하는 Snowflake 연결에서 지원되지 않습니다.
- 연결에서 PDT를 사용 중지해도 PDT와 연결된 데이터 그룹은 사용 중지되지 않습니다. PDT를 사용 중지해도 기존 데이터 그룹은 데이터베이스에 대해
sql_trigger쿼리를 계속 실행합니다. 데이터 그룹에서 데이터베이스에 대한sql_trigger쿼리를 실행하지 않도록 하려면 LookML 프로젝트에서datagroup매개변수를 삭제하거나 주석 처리하거나, Looker에서 PDT 및 데이터 그룹을 매우 드물게 또는 전혀 확인하지 않도록 연결에 대한 PDT 및 Datagroup 유지보수 일정 설정을 업데이트할 수 있습니다. - Snowflake 연결의 경우 Looker는
AUTOCOMMIT매개변수의 값을TRUE(Snowflake'의 기본값)로 설정합니다. Looker가 PDT 등록 시스템을 유지관리하기 위해 실행하는 SQL 명령어에AUTOCOMMIT가 필요합니다.
임시 데이터베이스
임시 데이터베이스로 라벨이 지정되었지만 Looker에서 영구 파생 테이블을 만들 때 사용해야 하는 데이터베이스 이름 또는 스키마 이름을 입력합니다. 적절한 쓰기 권한으로 이 데이터베이스나 스키마를 미리 구성해야 합니다. 데이터베이스 구성 안내 문서 페이지에서 데이터베이스 언어를 선택하여 해당 언어에 대한 안내를 확인하세요.
각 연결에는 자체 임시 데이터베이스 또는 스키마가 있어야 하며 연결 간에 공유할 수 없습니다.
최대 PDT 빌더 연결
최대 PDT 빌더 연결 설정을 사용하면 Looker 재생기가 데이터베이스 연결에서 시작할 수 있는 동시 테이블 빌드 수를 지정할 수 있습니다. 최대 PDT 빌더 연결 설정은 Looker 재생기가 재빌드를 시작하는 테이블 유형에만 적용됩니다.
- 트리거 지속성 테이블(
datagroup_trigger또는sql_trigger_value지속성 전략을 사용하는 영구 파생 테이블 및 집계 테이블) persist_for전략을 사용하지만 영구 테이블이datagroup_trigger또는sql_trigger_value지속성 전략을 사용하는 테이블에 종속되는 파생된 테이블의 계단식의 일부인 경우에만 지속되는 테이블 이 경우 Looker 재생기가persist_for테이블을 다시 빌드합니다. 테이블이 캐스케이드에서 다른 테이블을 다시 빌드하는 데 필요하기 때문입니다. 그렇지 않으면 재생성 프로그램은persist_for테이블의 빌드를 시작하지 않습니다.
최대 PDT 빌더 연결 설정은 기본적으로 1이지만 최대 10으로 설정될 수도 있습니다. 그러나 이 값은 최대 연결 필드 또는 Looker의 시작 옵션에 설정된 per-user-query-limit에 설정된 값보다 클 수 없습니다.
이 값은 신중하게 설정합니다. 값이 너무 높으면 데이터베이스에 과부하가 발생할 수 있습니다. 이 값이 작으면 장기 실행 PDT 또는 집계 테이블이 다른 영구 테이블 생성을 지연시키거나 연결 시 다른 쿼리의 속도를 저하시킬 수 있습니다. 멀티테넌시를 지원하는 데이터베이스(예: BigQuery, Snowflake, Redshift)는 병렬 쿼리 빌드를 처리하는 데 성능이 더 뛰어날 수 있습니다.
최대 PDT 빌더 연결 설정을 늘리려면 1씩 늘리는 것이 좋습니다. 예상치 못한 동작이 발생하면 기본값으로 1로 다시 설정하세요. 그렇지 않고 쿼리 성능에 영향을 미치지 않는 경우, 1씩 늘려서 각 증분마다 성능을 확인한 후 설정을 더 늘릴 수 있습니다.
최대 PDT 빌더 연결 설정에 관한 다음 사항에 유의하세요.
- 최대 PDT 빌더 연결 설정은 트리거 검사에 필요한 연결이 아니라 테이블의 재빌드에 필요한 연결에만 적용됩니다. 트리거 확인은 테이블의 지속성 전략이 트리거되는지 확인하는 쿼리입니다. 트리거 검사 쿼리는 항상 순차적으로 실행되므로 최대 PDT 빌더 연결 설정은 적용되지 않습니다.
- 클러스터링된 Looker 인스턴스에서는 재생성기가 기본 노드에서만 실행됩니다. 최대 PDT 빌더 연결 설정은 기본 노드에만 적용되므로 전체 클러스터에 한도를 설정합니다.
- 최대 PDT 빌더 연결 설정은 다음 유형의 표에는 적용되지 않습니다. 이러한 유형의 테이블은 연속적으로 빌드됩니다.
persist_for매개변수를 통해 지속된 테이블 (테이블이datagroup_trigger또는sql_trigger_value전략을 사용하여 종속되지 않는 경우)- 개발 모드의 테이블.
- Rebuild Derived Tables & Run 옵션을 사용하여 다시 빌드된 테이블
- 테이블은 종속 항목 cascade에서 다른 종속 항목에 종속됩니다. 테이블은 종속되는 테이블과 동시에 빌드할 수 없습니다. 예를 들어
table_B가table_A에 종속되는 경우에는table_A가 재빌드를 완료해야table_B가 재빌드를 시작할 수 있습니다.
실패한 PDT 빌드 항상 재시도
항상 실패한 PDT 빌드 다시 시도 설정은 Looker 재생 생성기가 이전 재생기 주기에서 실패한 트리거 지속성 테이블을 다시 빌드하려고 시도하는 방법을 구성합니다. Looker 재생성 도구는 PDT 및 데이터 그룹 유지보수 일정 연결 설정에 구성된 간격에 따라 트리거 영구 테이블 (PDT 및 집계 테이블)을 다시 빌드하는 프로세스입니다. 항상 실패한 PDT 빌드 재시도 설정을 사용 설정하면 PDT의 트리거 조건이 충족되지 않더라도 Looker 재생기가 이전 재생성 주기에서 실패한 PDT를 다시 빌드하려고 시도합니다. 이 설정을 사용 중지하면 PDT의 트리거 조건이 충족될 때만 Looker 재생기가 이전에 실패한 PDT를 다시 빌드하려고 시도합니다. 항상 실패한 PDT 빌드 다시 시도는 기본적으로 사용 중지되어 있습니다.
Looker 재생기에 대한 자세한 내용은 Looker의 파생 테이블 문서 페이지를 참조하세요.
PDT API 제어 사용 설정
PDT API 제어 사용 설정 설정에 따라 이 연결에 start_pdt_build, check_pdt_build, stop_pdt_build API 호출을 사용할 수 있는지 여부가 결정됩니다. 설정을 사용 중지하면 이 연결에서 PDT를 참조할 때 이러한 API 호출이 실패합니다. PDT API 제어 사용 설정은 기본적으로 사용 중지되어 있습니다.
추가 매개변수
필요한 경우 쿼리에 추가로 Java Database Connectivity (JDBC) 매개변수를 포함할 수 있습니다.
JDBC 매개변수에서 사용자 속성을 참조하려면 액체 템플릿 구문인 _user_attributes['name_of_attribute']를 사용합니다. 예를 들면 다음과 같습니다.
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Looker의 추가 매개변수 필드에는 다음과 같이 표시될 수 있습니다.

추가 JDBC 매개변수는 Looker에서 테스트하지 않으므로 의도하지 않은 동작이 발생할 수 있습니다.
PDT 및 데이터 그룹 유지보수 일정
이 설정은 Looker 재생성이 sql_trigger_value에 기반한 데이터 그룹 및 영구 테이블 (집계 테이블 및 영구 파생 테이블)을 확인해야 함을 나타내는 cron 표현식을 허용하며, 어떤 테이블을 다시 생성하거나 삭제해야 하는지 확인합니다.
기본값 */5 * * * *은 '5분마다 확인'을 의미하며 최대 확인 빈도입니다. 검사 빈도가 더 높은 cron 표현식을 사용하면 5분마다 검사가 수행됩니다.
PDT가 빌드되는 동안에는 Looker가 추가 트리거 검사를 실행하지 않습니다. 마지막 트리거 검사의 모든 PDT가 빌드되면 Looker가 PDT 및 데이터 그룹 유지보수 일정에 따라 데이터 그룹 및 PDT 트리거 검사를 다시 시작합니다.
데이터베이스가 연중무휴 운영되지 않는 경우에는 데이터베이스가 가동되는 시간으로 검사를 제한하는 것이 좋습니다. 다음은 추가 cron 표현식입니다.
cron 표현식 |
정의 |
|---|---|
*/5 8-17 * * MON-FRI |
월요일부터 금요일까지 영업시간 동안 5분마다 데이터 그룹 및 PDT 확인 |
*/5 8-17 * * * |
매일 영업시간에 5분마다 데이터 그룹 및 PDT 확인 |
0 8-17 * * MON-FRI |
월요일부터 금요일까지 영업시간 동안 매시간 데이터 그룹 및 PDT 확인 |
1 3 * * * |
매일 오전 3시 1분에 데이터 그룹 및 PDT 확인 |
cron 표현식을 만들 때 다음 사항에 유의하세요.
- Looker는
cron표현식에서?를 지원하지 않는 parse-cron v0.1.3을 사용합니다. cron표현식은 Looker 애플리케이션 시간대를 사용하여 검사가 이루어지는 시점을 결정합니다.- PDT가 빌드되지 않는 경우 크론 문자열을 기본값인
*/5 * * * *로 재설정합니다.
다음은 cron 문자열을 만드는 데 도움이 되는 리소스입니다.
- https://crontab.guru —
cron문자열 수정 및 테스트 지원 - http://www.crontab-generator.org — 시간 설정을 선택하면 생성기에서 해당하는
cron문자열이 생성됩니다.
SSL
Looker와 데이터베이스 간에 전송되는 데이터를 보호하기 위해 SSL 암호화를 사용할지 여부를 선택합니다. SSL은 데이터 보호에 사용할 수 있는 하나의 옵션일 뿐입니다. 다른 보안 옵션은 보안 데이터베이스 액세스 사용 설정 문서 페이지에 설명되어 있습니다.
SSL 인증서 확인
연결에 사용되는 SSL 인증서 확인을 요청할지 선택합니다. 확인이 필요한 경우 SSL 인증서에 서명한 SSL 인증 기관 (CA)은 클라이언트의 신뢰할 수 있는 소스 목록에서 가져와야 합니다. CA가 신뢰할 수 있는 소스가 아니면 데이터베이스 연결이 설정되지 않습니다.
이 체크박스를 선택하지 않으면 연결에 SSL 암호화가 계속 사용되지만 SSL 연결 확인이 필요하지 않으므로 CA가 클라이언트의 신뢰할 수 있는 소스 목록에 없을 때 연결을 설정할 수 있습니다.
최대 연결 수
여기에서 Looker가 데이터베이스에 설정할 수 있는 최대 연결 수를 설정할 수 있습니다. 대부분의 경우 Looker가 데이터베이스에 대해 실행할 수 있는 동시 쿼리 수를 설정합니다. 또한 Looker는 쿼리 종료를 위해 최대 3개의 연결을 예약합니다. 연결 풀이 너무 작으면 Looker에서 더 적은 수의 연결을 예약합니다.
이 값은 신중하게 설정합니다. 값이 너무 높으면 데이터베이스에 과부하가 발생할 수 있습니다. 값이 너무 작으면 쿼리가 적은 수의 연결을 공유해야 합니다. 따라서 쿼리가 이전의 다른 쿼리가 반환될 때까지 기다려야 하므로 많은 쿼리가 사용자에게 느리게 보일 수 있습니다.
기본값 (SQL 언어에 따라 다름)이 일반적으로 적합한 시작점입니다. 또한 대부분의 데이터베이스에는 수락할 수 있는 최대 연결 수에 대한 자체 설정이 있습니다. 데이터베이스 구성이 연결을 제한하는 경우 최대 연결 수 값이 데이터베이스 한도와 같거나 이보다 작아야 합니다.
연결 풀 제한 시간
사용자가 최대 연결 설정보다 더 많은 연결을 요청하면 요청은 다른 사용자가 완료될 때까지 기다린 후에 실행됩니다. 여기에서 요청이 대기하는 최대 시간이 여기에 구성됩니다. 이 값은 신중하게 설정해야 합니다. 값이 너무 낮다면 다른 사용자의 쿼리가 완료될 시간이 충분하지 않아 사용자의 쿼리가 취소되는 것일 수 있습니다. 너무 높으면 쿼리가 너무 많아 사용자가 매우 오래 기다려야 할 수 있습니다. 기본값은 일반적으로 적절한 시작점입니다.
예상 비용
비용 예상치 체크박스는 다음 데이터베이스 연결에만 적용됩니다.
비용 예측 체크박스를 선택하면 연결에서 다음 기능이 사용 설정됩니다.
BigQuery 및 MySQL 연결도 비용 예측 기능을 지원하지만, 이 기능이 항상 사용 설정되어 있으므로 BigQuery 및 MySQL 연결에 대한 비용 추정 체크박스가 없습니다.
자세한 내용은 Looker의 데이터 탐색 문서 페이지를 참조하세요.
SQL 러너 사전 캐시
SQL Runner에서는 연결과 스키마를 선택하는 즉시 모든 테이블 정보가 미리 로드됩니다. 이렇게 하면 테이블 이름을 클릭하는 즉시 SQL Runner가 테이블 열을 빠르게 표시할 수 있습니다. 그러나 테이블이 많거나 테이블이 매우 큰 연결과 스키마의 경우 SQL Runner가 모든 정보를 미리 로드하지 않는 것이 좋습니다.
테이블이 선택되었을 때만 SQL Runner가 테이블 정보를 로드하도록 하려면 SQL Runner Precache 옵션을 선택 해제하여 연결에 대한 SQL Runner 사전 로드를 사용 중지할 수 있습니다.
SQL 쓰기를 위한 정보 스키마 가져오기
집계 인식과 같은 일부 SQL 작성 기능의 경우 Looker는 데이터베이스 정보 스키마를 사용하여 SQL 쓰기를 최적화합니다. 정보 스키마가 캐시되지 않으면 Looker에서 정보 스키마를 가져오기 위해 가끔 데이터베이스에 SQL을 작성하는 것을 차단해야 할 수도 있습니다. Hadoop 분산 파일 시스템 (HDFS)을 사용하는 경우 정보 스키마를 가져오는 데 Looker 쿼리의 성능에 상당한 영향을 미칠 수 있습니다. 정보 스키마가 느리다는 것을 알고 있다면 연결에 대한 SQL 쓰기를 위한 정보 스키마 가져오기 옵션을 사용 중지할 수 있습니다. 이 기능을 사용 중지하면 특정 기능에 대한 Looker의 SQL 최적화가 차단되므로 연결 정보 스키마가 특히 느리다는 것을 알고 있지 않은 경우 SQL 쓰기를 위한 정보 스키마 가져오기 옵션을 사용 설정해야 합니다.
컨텍스트 설명 사용 중지
컨텍스트 댓글 사용 중지 옵션은 BigQuery 연결에만 적용됩니다. 컨텍스트 주석은 Google BigQuery의 캐시 기능을 무효화하며 캐시 성능에 부정적인 영향을 줄 수 있으므로 Google BigQuery 연결에 대한 컨텍스트 댓글은 기본적으로 사용 중지되어 있습니다. 연결의 연결 설정 페이지에서 컨텍스트 댓글 사용 중지 설정을 선택 해제하여 BigQuery 연결에 대한 컨텍스트 댓글을 사용 설정할 수 있습니다. 자세한 내용은 Google BigQuery 문서 페이지를 참고하세요.
데이터베이스 시간대
데이터베이스에 시간 기반 정보를 저장하는 시간대입니다. Looker에서 이를 통해 사용자의 시간 값을 변환하여 시간 기반 데이터를 더 쉽게 이해하고 사용할 수 있도록 해야 합니다. 자세한 내용은 시간대 설정 사용하기 문서 페이지를 참고하세요.
쿼리 시간대
쿼리 시간대 옵션은 사용자별 시간대를 사용 중지한 경우에만 표시됩니다.
사용자 시간대를 사용 중지하면 쿼리 시간대는 사용자가 시간 기반 데이터를 쿼리할 때 사용자에게 표시되는 시간대와 Looker가 데이터베이스 시간대에서 시간 기반 데이터를 변환하는 시간대입니다.
자세한 내용은 시간대 설정 사용하기 문서 페이지를 참고하세요.
PDT 프로세스에 별도의 로그인 사용자 인증 정보 구성
데이터베이스가 영구 파생 테이블을 지원하고 연결 설정에서 영구 파생 테이블 체크박스를 선택하면 Looker에 PDT 재정의 열이 표시됩니다. PDT 재정의 열에 PDT 프로세스 전용의 개별 JDBC 매개변수 (호스트, 포트, 데이터베이스, 사용자 이름, 비밀번호, 스키마, 추가 매개변수)를 입력할 수 있습니다. 이 측정항목이 도움이 되는 이유는 다음과 같습니다.
- PDT 프로세스에 별도의 데이터베이스 사용자를 만들면 데이터베이스 로그인 사용자 인증 정보에 사용자 속성을 할당하는 경우에도 모델에 PDT를 사용할 수 있습니다.
- PDT 프로세스는 우선순위가 더 높은 별도의 데이터베이스 사용자를 통해 인증할 수 있습니다. 이렇게 하면 데이터베이스가 덜 중요한 사용자 쿼리보다 PDT 작업의 우선순위를 정할 수 있습니다.
- 표준 Looker 데이터베이스 연결의 쓰기 액세스 권한을 취소할 수 있으며 PDT 프로세스에서 인증에 사용하는 특수 사용자에게만 권한을 부여합니다. 이는 대부분의 조직에 더 나은 보안 전략입니다.
- Snowflake와 같은 데이터베이스의 경우 PDT 프로세스를 나머지 Looker 사용자와 공유하지 않는 더 강력한 하드웨어로 라우팅할 수 있습니다. 이런 방식으로 PDT는 값비싼 하드웨어를 상시 실행하느라 비용을 들이지 않고도 신속하게 빌드할 수 있습니다.
예를 들어 다음 구성은 사용자 이름과 비밀번호 필드가 사용자 속성으로 설정된 연결을 보여줍니다. 이렇게 하면 각 사용자가 개별 사용자 인증 정보를 사용하여 데이터베이스에 액세스할 수 있습니다. PDT 재정의 열에서 자체 비밀번호를 가진 별도의 사용자(pdt_user)를 만듭니다. pdt_user 계정이 모든 PDT 프로세스에 사용되며 PDT 생성 및 업데이트에 적절한 액세스 수준이 사용됩니다.
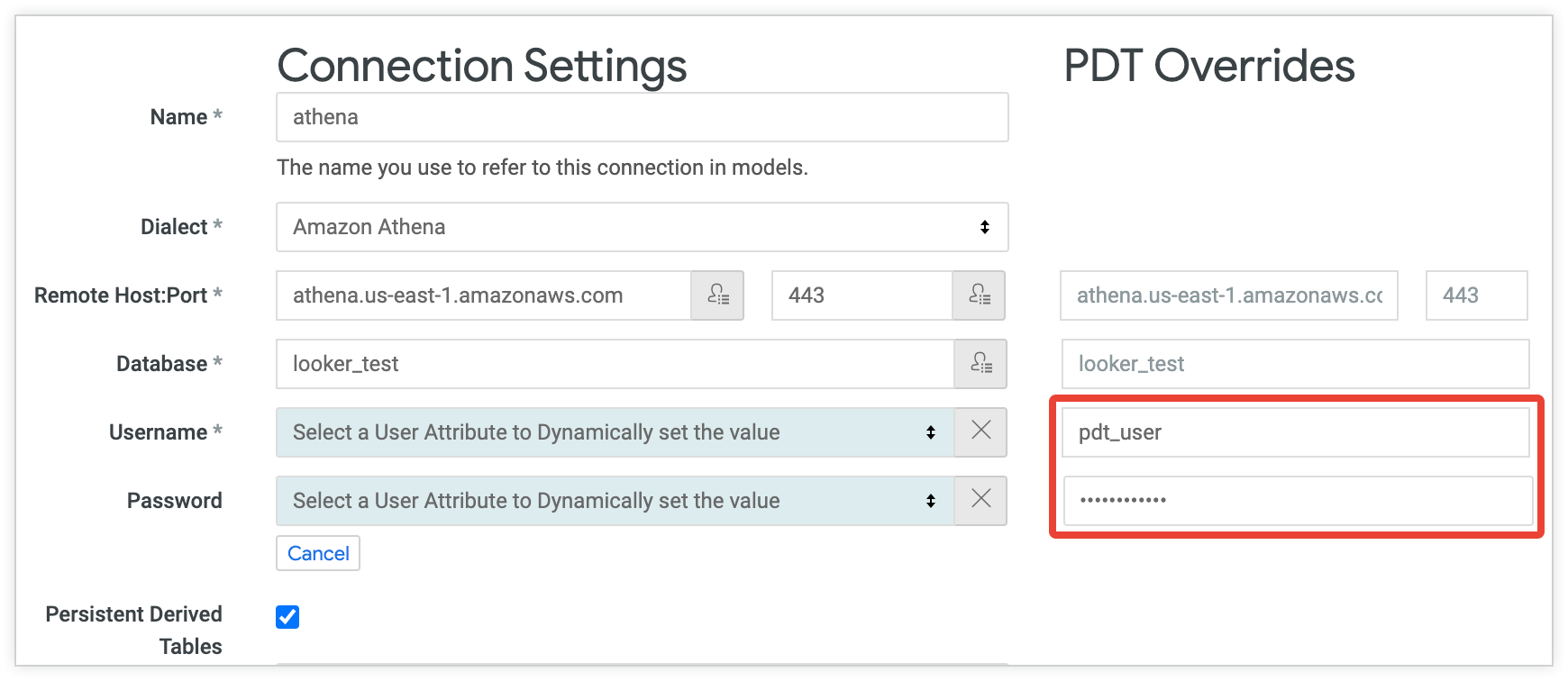
PDT 재정의 열을 사용하면 데이터베이스 사용자 및 기타 연결 속성을 변경할 수 있지만, PDT 재정의는 기본 연결과 동일한 데이터를 읽어야 하며, 같은 위치에 데이터를 써야 합니다. Looker는 한 위치에서 데이터를 읽고 다른 위치에 쓸 수 없습니다.
연결 설정 테스트
사용자 인증 정보를 입력한 후 테스트 이러한 설정을 클릭하여 정보가 올바르고 데이터베이스를 연결할 수 있는지 확인합니다.
연결에서 하나 이상의 테스트를 통과하지 못하면 다음을 수행합니다.
- 데이터베이스 연결 테스트 문서 페이지의 일부 문제 해결 단계를 시도해 보세요.
- Atlas에서 Mongo 버전 3.6 이하를 실행 중인데 통신 링크 오류가 발생하면 Mongo Connector 문서 페이지를 참고하세요.
- 임시 스키마 및 PDT와 관련된 연결 메시지를 수신하려면 Looker 데이터베이스를 설정할 때 해당 기능을 허용해야 합니다. 방법은 데이터베이스 구성 안내 문서 페이지에서 확인할 수 있습니다.
Snowflake 및 Google BigQuery와 같이 OAuth를 사용하는 데이터베이스 연결에는 사용자 로그인이 필요합니다. 이러한 연결 중 하나를 테스트할 때 OAuth 사용자 계정에 로그인하지 않은 경우 Looker에서 로그인 링크와 함께 경고를 표시합니다. 링크를 클릭하여 OAuth 사용자 인증 정보를 입력하거나 Looker에서 OAuth 계정 정보에 액세스하도록 허용합니다.
문제가 계속되면 Looker 지원팀에 문의하여 도움을 받으세요.
사용자로 테스트
연결 매개변수 값을 사용자 속성에 설정한 경우 사용자로 테스트 옵션이 이 설정 테스트 버튼 위에 표시됩니다. 사용자를 선택한 다음 테스트 이러한 설정을 클릭하여 데이터베이스가 이 사용자로 연결되고 쿼리를 실행할 수 있는지 확인합니다.
데이터베이스 연결 추가
데이터베이스 연결 설정을 구성하고 테스트한 후 연결 추가를 클릭합니다. 이제 데이터베이스 연결이 연결 페이지의 목록에 추가됩니다.
다음 단계
데이터베이스를 Looker에 연결하고 나면 사용자를 위해 로그인 옵션을 구성할 수 있습니다.