집계 인지도 구현에 대한 가이드는 집계 인지도 튜토리얼 고객센터 도움말도 참고하세요.
개요
Looker는 집계 인식 로직을 사용하여 데이터베이스에서 가장 작고 효율적인 테이블을 찾아 정확성을 유지하면서 쿼리를 실행합니다.
데이터베이스에 크기가 매우 큰 테이블의 경우 Looker 개발자는 다양한 속성 조합으로 그룹화하여 더 작은 총 데이터 테이블을 만들 수 있습니다. 집계 테이블은 가능하면 항상 원본의 큰 테이블 대신 Looker에서 쿼리에 사용할 수 있는 롤업 또는 요약 테이블 역할을 합니다. 전략적으로 구현하면 인지도가 엄청나게 증가하여 평균 쿼리 속도가 크게 향상될 수 있습니다.
예를 들어 웹사이트에서 발생한 모든 주문에 대해 하나의 행이 있는 페타바이트급 데이터 테이블이 있을 수 있습니다. 이 데이터베이스에서 일일 총 판매액이 포함된 집계 테이블을 만들 수 있습니다. 웹사이트에서 매일 1,000건의 주문을 받는 경우 일일 집계 표는 기존 테이블보다 999개 적은 행에 매일 표시됩니다. 월간 총 판매액을 포함하여 다른 통합 표를 만들면 훨씬 더 효율적일 수 있습니다. 따라서 사용자가 일일 또는 주간 판매 쿼리를 실행하는 경우 Looker에서 일일 판매 합계 표를 사용합니다. 사용자가 연간 판매에 관한 쿼리를 실행하고 있지만 연간 집계 테이블이 없는 경우 Looker에서 차선책인 이 예시의 월간 판매 집계 표를 사용합니다.
이 이미지는 Looker가 사용자 질문에 어떻게 답변하는지 보여줍니다(가능한 경우).
- 월간 총 판매에 대한 쿼리와 함께 Looker는 월별 매출(
sales_monthly_aggregate_table)을 기준으로 집계 표를 사용합니다. - 일일 각 판매 합계에 대한 쿼리의 경우 이 세분화를 포함한 집계 테이블이 없으므로 Looker가 원래 데이터베이스 테이블(
orders_database)에서 쿼리 결과를 가져옵니다. 하지만 사용자가 이러한 유형의 쿼리를 자주 실행하는 경우 집계 테이블을 쉽게 만들 수 있습니다. - 주간 판매에 관한 쿼리에는 주간 집계 테이블이 없으므로 Looker가 차선책인 일일 판매량(
sales_daily_aggregate_table)을 기반으로 하는 집계표를 사용합니다.

집계 인식 로직을 사용하여 Looker는 사용자 질문에 답할 수 있는 가장 작은 집계 테이블을 쿼리합니다. 원본 테이블은 집계 테이블이 제공할 수 있는 것보다 더 세분화된 쿼리가 필요한 쿼리에만 사용됩니다.
집계 표는 별도의 탐색 분석에 조인하거나 추가할 필요가 없습니다. 대신 Looker는 쿼리에 가장 적합한 집계 테이블에 액세스하도록 탐색 쿼리의 FROM 절을 동적으로 조정합니다. 즉, 드릴은 유지되고 탐색 분석은 통합될 수 있습니다. 집계 인식을 사용하면 탐색 한 번으로 집계 표를 자동으로 활용할 수 있지만 필요한 경우 세분화된 데이터를 자세히 살펴볼 수 있습니다.
또한 특히 대규모 데이터 세트를 쿼리하는 타일의 경우 집계 테이블을 활용하여 대시보드의 성능을 대폭 개선할 수 있습니다. 자세한 내용은 aggregate_table 매개변수 문서 페이지의 대시보드에서 집계 테이블 LookML 가져오기 섹션을 참조하세요.
프로젝트에 집계 테이블 추가
집계 인식을 위해 액세스할 수 있으려면 데이터베이스에 집계 테이블이 유지되어야 합니다. 집계 테이블은 영구 파생 테이블 (PDT) 유형이므로 집계 테이블에는 PDT와 동일한 요구사항이 적용됩니다. 자세한 내용은 Looker의 파생 테이블 문서 페이지를 참조하세요.
Looker 개발자는 데이터베이스의 큰 테이블에 필요한 쿼리 수를 최소화하는 전략적 집계 테이블을 만들 수 있습니다. 집계 테이블은 집계 인식에 액세스할 수 있도록 데이터베이스에 지속되어야 합니다. 따라서 집계 테이블은 영구 파생 테이블 (PDT) 유형입니다.
집계 테이블은 LookML 프로젝트의 explore 매개변수 아래에 aggregate_table 매개변수를 사용하여 정의됩니다.
다음은 LookML에서 집계 테이블이 있는 explore의 예입니다.
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
집계 테이블을 만들려면 처음부터 LookML을 작성하거나 탐색에서 또는 대시보드에서 LookTable을 가져오면 됩니다. aggregate_table 매개변수 및 하위 매개변수의 세부사항은 aggregate_table 매개변수 문서 페이지를 참고하세요.
집계 테이블 설계
탐색 쿼리가 집계 테이블을 사용하려면 집계 테이블이 탐색 쿼리에 대한 정확한 데이터를 제공할 수 있어야 합니다. 다음 사항이 모두 참인 경우 Looker에서 탐색 쿼리에 집계 테이블을 사용할 수 있습니다.
- 쿼리 필드는 필드 집계의 하위 집합입니다. 이 페이지의 필드 요소 섹션을 참조하세요. 또는 기간의 경우 탐색 쿼리 기간은 집계 테이블의 기간에서 파생될 수 있습니다 (이 페이지의 기간 요소 섹션 참조).
- 탐색 쿼리에는 집계 인식에서 지원하는 측정 유형이 포함되어 있거나 (이 페이지의 유형 유형 측정 섹션 참조) 완전하게 일치하는 집계 테이블이 있는 탐색 쿼리 (이 페이지의 탐색 쿼리와 정확하게 일치하는 집계 테이블 만들기 섹션 참고)
- 쿼리 탐색 시간대는 집계 표에서 사용되는 시간대와 일치합니다 (이 페이지의 시간대 요소 섹션 참고).
- 탐색 쿼리 필터는 집계 테이블에서 측정기준으로 사용할 수 있는 참조 필드 또는 각 탐색 분석 필터가 집계 테이블의 필터와 일치합니다 (이 페이지의 필터 요소 섹션 참고).
집계 테이블이 탐색 쿼리에 대한 정확한 데이터를 제공할 수 있도록 하는 한 가지 방법은 단순히 탐색 쿼리와 정확히 일치하는 집계 테이블을 만드는 것입니다. 자세한 내용은 이 페이지의 쿼리와 정확하게 일치하는 집계 테이블 만들기 섹션을 참조하세요.
필드 요소
집계 쿼리에 탐색 쿼리에 사용하려면 집계 쿼리에 해당 탐색 쿼리에 필요한 모든 측정기준과 측정항목이 있어야 합니다. 여기에는 탐색 쿼리의 필터에 사용되는 필드가 포함됩니다. 집계 쿼리에 없는 측정기준 또는 측정값을 탐색 쿼리에 포함하는 경우, Looker는 집계 테이블을 사용할 수 없으며 대신 기본 테이블을 사용합니다.
예를 들어 검색어가 측정기준 A와 B로 그룹화되고, 측정 C에 의해 집계되며, 측정기준 D에 대해 필터링되는 경우, 집계 테이블에는 최소한 A, B, D가 측정기준에 있고 C가 측정값이어야 합니다.
집계 테이블에는 다른 필드도 있을 수 있지만 최적화할 수 있으려면 적어도 탐색 쿼리 필드가 있어야 합니다. 한 가지 예외는 기간 차원입니다. 세밀한 세분화 기간을 보다 세분화할 수 있기 때문입니다.
이러한 필드 고려사항으로 인해 집계 테이블은 정의된 탐색에 따라 달라집니다. 한 탐색 분석에 정의된 집계 테이블은 다른 탐색의 쿼리에 사용할 수 없습니다.
시간대 요인
Looker의 집계 인식 로직은 다른 시간대에서 한 기간을 도출할 수 있습니다. 집계 테이블의 기간이 탐색 쿼리보다 더 상세하거나 같다면 쿼리에 집계 테이블을 사용할 수 있습니다. 예를 들어 일일 데이터를 기반으로 한 집계 표는 일간, 월간, 연간 데이터 또는 월, 일, 연중 데이터와 같은 다른 기간을 호출하는 탐색 쿼리에 사용될 수 있습니다. 하지만 시간별 데이터를 호출하는 탐색 쿼리에 연간 집계 테이블을 사용할 수 없습니다. 집계 테이블의 데이터는 탐색 쿼리에 대한 세분화된 데이터가 많지 않기 때문입니다.
이는 기간 하위 집합에도 적용됩니다. 예를 들어 지난 3개월에 대해 필터링된 집계 테이블이 있고 사용자가 지난 2개월에 대한 필터를 사용하여 데이터를 쿼리하면 Looker에서 해당 쿼리에 집계 테이블을 사용할 수 있습니다.
또한 기간 필터가 있는 쿼리에도 동일한 로직이 적용됩니다. 기간 필터를 사용하면 집계 테이블의 기간이 탐색 쿼리에 사용되는 기간 필터보다 세부적이거나 같다면 쿼리에 필터를 사용할 수 있습니다. 예를 들어 기간 측정기준이 있는 집계 표는 일, 주 또는 월을 필터링하는 탐색 쿼리에 사용할 수 있습니다.
유형 요소 측정
탐색 쿼리가 집계 테이블을 사용하려면 집계 테이블의 측정값으로 탐색 쿼리에 대한 정확한 데이터를 제공할 수 있어야 합니다.
따라서 다음 섹션에 설명된 대로 특정 유형의 측정만 지원됩니다.
탐색 쿼리가 다른 유형의 측정을 사용하는 경우 Looker에서 집계 테이블이 아닌 원래 테이블을 사용하여 결과를 반환합니다. 유일한 예외는 쿼리가 탐색 쿼리와 정확하게 일치하는 집계 테이블 만들기 섹션에 설명된 대로 탐색 쿼리가 집계 테이블 쿼리와 정확히 일치하는 경우입니다.
그렇지 않으면 Looker에서 집계 테이블이 아닌 원래 테이블을 사용하여 결과를 반환합니다.
지원되는 측정 유형이 있는 측정
집계 인지도는 다음 측정 유형의 측정값을 사용하는 탐색 쿼리에 사용할 수 있습니다.
탐색이 여러 데이터베이스 테이블에 조인되는 경우 Looker는
SUM,COUNT,AVERAGE,SUM DISTINCT,COUNT DISTINCT,AVERAGE DISTINCT, 이 작업은 이 페이지의 조인을 사용한 탐색의 대칭 집계 섹션에 설명된 대로 팬아웃 계산 오차를 방지하기 위해 이렇게 합니다.
탐색 쿼리에 집계 테이블을 사용하려면 Looker가 집계 테이블에서 작업을 수행하여 탐색 쿼리에 정확한 데이터를 제공할 수 있어야 합니다. 예를 들어 type: sum를 사용한 측정은 여러 합계를 합산할 수 있으므로 집계 인식에 사용할 수 있습니다. 주간 총합계 표를 함께 추가하여 정확한 월별 합계를 얻을 수 있습니다. 마찬가지로 type: max를 사용한 측정은 일일 최댓값 집계표를 사용하여 정확한 주간 최댓값을 찾을 수 있습니다.
type: average를 사용한 측정의 경우 Looker가 합계 및 집계 데이터를 사용하여 집계 테이블에서 평균 값을 정확하게 도출하므로 집계 인식이 지원됩니다.
SQL 표현식으로 정의된 측정
집계 인식은 sql 매개변수의 표현식을 사용하여 정의된 측정값과 함께 사용할 수도 있습니다. SQL 표현식으로 정의하면 다음 측정 유형도 지원됩니다.
집계 인식은 다음 예와 같이 다른 측정의 조합으로 정의된 측정에 지원됩니다.
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
집계 인식은 다음과 같이 sql 매개변수에 계산이 정의된 측정에도 지원됩니다.
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
집계 인식은 다음과 같이 sql 매개변수에 MIN, MAX, COUNT 작업이 정의되어 있는 경우에 지원됩니다.
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
집계 인식은
MIN(),MAX(),COUNT()작업에만 지원됩니다. 집계 테이블에서 평균 또는 합계 측정을 사용하려면 집계 인식이 지원되는type: average또는type: sum의 측정값을 만들면 됩니다.
LookML 필드를 참조하는 측정
sql 표현식이 측정에 사용되는 경우 집계 인식은 다음 유형의 필드 참조를 지원합니다.
- 다른 뷰의 필드를 나타내는
${view_name.field_name}형식을 사용하는 참조 - 동일한 뷰의 필드를 나타내는
${field_name}형식을 사용하는 참조
집계 인식은 테이블의 열을 나타내는 ${TABLE}.column_name 형식을 사용하여 정의된 측정에는 지원되지 않습니다. LookML에서 참조를 사용하는 방법에 대한 개요는 SQL 통합 및 LookML 객체 참조 문서 페이지를 참조하세요.
예를 들어 이 sql 매개변수로 정의된 측정은 집계 형식을 지원하지 않습니다. ${TABLE}.column_name 형식을 사용하기 때문입니다.
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
집계 테이블에 이 측정값을 포함하려면 대신 ${TABLE}.column_name 형식으로 정의된 측정기준을 만든 후 이 측정기준을 참조하는 측정값을 만들면 됩니다.
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
이제 집계 테이블에서 wholesale_value 측정을 사용할 수 있습니다.
대략적인 근사치 측정
일반적으로 고유한 개수는 집계를 지원하려고 할 때 정확한 데이터를 얻을 수 없기 때문에 집계 인지도에서 지원되지 않습니다. 예를 들어, 웹사이트에서 순 사용자 수를 집계하는 경우 3주 간격에 2번 웹사이트를 방문한 사용자가 있을 수 있습니다. 주간 집계 표를 적용하여 웹사이트의 월간 순 사용자 수를 가져오면 이 사용자는 월간 고유 사용자 수 쿼리에 두 번 집계되며 데이터가 정확하지 않습니다.
이 문제를 해결하는 방법 중 하나는 이 페이지의 탐색 쿼리와 정확하게 일치하는 집계 테이블 만들기 섹션에 설명된 대로 탐색 쿼리와 정확하게 일치하는 집계 테이블을 만드는 것입니다. 탐색 쿼리와 집계 테이블 쿼리가 같은 경우 고유한 집계 방법이 정확한 데이터를 제공하므로 집계 인식에 사용할 수 있습니다.
또 다른 옵션은 고유한 수에 근사치를 사용하는 것입니다. HyperLogLog 스케치를 지원하는 언어의 경우 Looker는 HyperLogLog 알고리즘을 활용하여 집계 테이블의 고유한 개수를 추정할 수 있습니다.
HyperLogLog 알고리즘은 약 2% 의 오류가 있는 것으로 알려져 있습니다. allow_approximate_optimization: yes 매개변수를 사용하면 Looker 개발자가 대략적인 집계 데이터를 사용하여 측정이 대략적으로 총 표 수로 계산될 수 있음을 확인해야 합니다.
자세한 내용 및 HyperLogLog를 사용한 개수 구분을 지원하는 언어 목록은 allow_approximate_optimization 매개변수 문서 페이지를 참고하세요.
시간대 요인
대부분의 경우 데이터베이스 관리자는 UTC를 데이터베이스의 시간대로 사용합니다. 하지만 많은 사용자가 UTC 시간대를 사용하지 않을 수 있습니다. 사용자가 자신의 시간대로 쿼리 결과를 얻을 수 있도록 Looker에는 시간대를 변환하는 여러 옵션이 있습니다.
- 쿼리 시간대: 데이터베이스 연결의 모든 쿼리에 적용되는 설정입니다. 모든 사용자가 동일한 시간대에 있다면 단일 쿼리를 설정하여 모든 쿼리가 데이터베이스 시간대에서 쿼리 시간대로 변환되도록 할 수 있습니다.
- 사용자별 시간대: 사용자에게 개별적으로 시간대를 할당하고 선택할 수 있습니다. 이 경우 쿼리는 데이터베이스 시간대에서 개별 사용자의 시간대로 변환됩니다.
이 옵션에 대한 자세한 내용은 시간대 설정 사용 문서 페이지를 참조하세요.
집계 개념은 날짜 측정기준 또는 날짜 필터가 있는 쿼리에 집계 표가 사용되려면 집계 테이블의 시간대가 원래 검색어에 사용된 시간대 설정과 일치해야 하므로 집계 인식을 이해하는 데 중요합니다.
timezone 값을 지정하지 않으면 집계 테이블에 데이터베이스 시간대가 사용됩니다. 다음 중 하나라도 해당하는 경우 데이터베이스 연결에서 데이터베이스 시간대를 사용합니다.
- 데이터베이스가 시간대를 지원하지 않습니다.
- 데이터베이스 연결의 쿼리 시간대가 데이터베이스 시간대와 동일한 시간대로 설정됩니다.
- 데이터베이스 연결에 지정된 쿼리 시간대 또는 사용자별 시간대가 없습니다. 이 경우 데이터베이스 연결이 데이터베이스 시간대를 사용합니다.
다음 중 하나라도 해당하는 경우 집계 테이블의 timezone 매개변수를 생략할 수 있습니다.
그렇지 않으면 집계 테이블의 시간대가 가능한 쿼리와 일치하도록 정의하여 집계 테이블의 사용 가능성이 더 높아야 합니다.
- 데이터베이스 연결이 단일 쿼리 시간대를 사용하는 경우 집계 테이블의
timezone값을 쿼리 시간대 값과 일치시켜야 합니다. - 데이터베이스 연결이 사용자별 시간대를 사용하는 경우 사용자의 가능한 시간대와 일치하도록 각각 다른
timezone값을 가진 동일한 집계 테이블을 만들어야 합니다.
집계 테이블의 시간대가 탐색 쿼리의 시간대와 일치하지 않으면 Looker에서 탐색 쿼리에 집계 테이블을 사용할 수 없습니다. 데이터베이스 연결에 사용자별 시간대가 있는 경우 각 사용자 시간대마다 별도의 집계 테이블이 필요합니다.
요소 필터링
집계 테이블에 필터를 포함할 때는 주의해야 합니다. 집계 테이블의 필터는 집계 테이블을 사용할 수 없는 지점으로 범위를 좁힐 수 있습니다. 예를 들어 일일 주문 수에 대한 집계 테이블을 만들고 오스트레일리아에서 발생하는 선글라스 주문만을 위한 집계 테이블을 필터링한다고 가정해 보겠습니다. 사용자가 전 세계 선글라스의 일일 주문 수에 대해 살펴보기 쿼리를 실행하는 경우, Looker에서 해당 탐색 쿼리에 집계 테이블을 사용할 수 없습니다. 집계 테이블에는 오스트레일리아의 데이터만 있기 때문입니다. 집계 테이블은 데이터를 너무 좁혀서 탐색 쿼리에 사용할 수 없도록 필터링합니다.
또한 다음과 같이 Looker 개발자가 Explore에 빌드할 수 있는 필터를 염두에 두세요.
access_filters: 사용자별 데이터 제한을 적용합니다.always_filter: 사용자가 탐색 쿼리에 특정 필터 세트를 포함하도록 요구합니다. 사용자가 검색어의 기본 필터 값을 변경할 수 있지만 필터를 완전히 삭제할 수는 없습니다.conditionally_filter: 사용자가 탐색에 정의된 두 번째 목록에서 필터를 하나 이상 적용할 때 사용자가 재정의할 수 있는 기본 필터 집합을 정의합니다.
이러한 필터 유형은 특정 필드를 기반으로 합니다. 탐색에 이러한 필터가 있으면 aggregate_table의 dimensions 매개변수에 이러한 필드를 포함해야 합니다.
예를 들어 다음은 orders.region 필드를 기반으로 하는 액세스 필터가 있는 Explore입니다.
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
이 탐색 분석에 사용할 집계 테이블을 만들려면 집계 테이블에 액세스 필터의 기반이 포함된 필드가 있어야 합니다. 다음 예에서는 액세스 필터가 orders.region 필드를 기반으로 하며, 동일한 필드가 집계 테이블의 측정기준으로 포함됩니다.
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
집계 테이블 쿼리에는 orders.region 측정기준이 포함되므로 Looker는 집계 테이블의 데이터를 동적으로 필터링하여 탐색 쿼리와 일치시킬 수 있습니다. 따라서 탐색에는 액세스 필터가 있더라도 Looker는 계속 탐색 쿼리에 집계 테이블을 사용할 수 있습니다.
이는 bind_filters로 구성된 네이티브 파생 테이블을 사용하는 탐색 쿼리에도 적용됩니다. bind_filters 매개변수는 탐색 쿼리에서 지정된 필터를 네이티브 파생 테이블 서브 쿼리로 전달합니다. 집계 인식의 경우 탐색 쿼리에 bind_filters을 사용하는 네이티브 파생 테이블이 필요한 경우 탐색 쿼리는 네이티브 파생 테이블의 bind_filters 필드에 사용된 모든 필드가 집계 테이블에서와 정확히 동일한 필터 값을 가진 경우에만 집계 테이블을 사용할 수 있습니다.
탐색 쿼리와 정확히 일치하는 집계 테이블 만들기
집계 쿼리가 탐색 쿼리에 사용될 수 있는지 확인하는 한 가지 방법은 단순히 탐색 쿼리와 정확하게 일치하는 집계 테이블을 만드는 것입니다. 탐색 쿼리와 집계 테이블이 모두 동일한 측정값, 측정기준, 필터, 시간대, 기타 매개변수를 사용하는 경우 정의에 따라 집계 테이블의 결과가 탐색 쿼리에 적용됩니다. 집계 테이블이 탐색 쿼리와 정확하게 일치하는 경우 Looker는 모든 유형의 측정값을 포함하는 집계 테이블을 사용할 수 있습니다.
탐색의 톱니바퀴 메뉴에서 LookML 가져오기 옵션을 사용하여 탐색에서 집계 테이블을 만들 수 있습니다. 또한 대시보드의 톱니바퀴 메뉴에서 LookLook 가져오기 옵션을 사용하여 모든 타일에 대해 일치검색을 만들 수 있습니다.
쿼리에 사용되는 집계 테이블 확인
see_sql 권한이 있는 사용자는 탐색의 SQL 탭에 있는 주석을 사용하여 쿼리에 사용할 집계 테이블을 확인할 수 있습니다. SQL 탭 주석도 개발 모드에도 표시되므로, 개발자는 새로운 집계 테이블을 테스트하여 사용자가 새 테이블을 프로덕션에 푸시하기 전에 Looker에서 이를 어떻게 사용하는지 확인할 수 있습니다.
예를 들어 앞서 살펴본 월별 집계 표 예를 바탕으로 살펴보기로 이동하여 연간 총 매출에 대한 쿼리를 실행할 수 있습니다. 그런 다음 SQL 탭을 클릭하여 Looker에서 만든 쿼리의 세부정보를 볼 수 있습니다. 개발 모드인 경우 Looker는 쿼리에 사용된 집계 테이블을 나타내는 주석을 표시합니다.

SQL 탭의 설명에서 Looker가 이 쿼리에 sales_monthly 집계 테이블을 사용하고 있는 경우와 이 쿼리에 다른 집계 테이블이 사용되지 않은 이유를 확인할 수 있습니다.
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
이 페이지의 문제 해결 섹션에서 SQL 탭에 표시될 수 있는 의견과 해결 방법에 대한 제안사항을 확인하세요.
집계 인지도 관련 예상 절감액
데이터베이스 연결이 예상 비용을 지원하고 쿼리에 집계 테이블을 사용할 수 있는 경우 데이터베이스를 직접 쿼리하는 대신 집계 테이블을 사용하여 컴퓨팅 비용을 절약할 수 있습니다. 집계된 인지도 절감은 쿼리가 실행되기 전에 탐색 분석의 실행 버튼 왼쪽에 표시됩니다.

쿼리를 실행하기 전에 이 문서 페이지에서 쿼리에 사용되는 집계 테이블 확인 섹션에 설명된 대로 쿼리에 사용할 집계 테이블을 확인하려면 SQL 탭을 클릭하면 됩니다.
쿼리가 실행되면 탐색창에 쿼리에 답하는 데 사용된 집계 테이블이 표시됩니다.

비용 견적이 사용 설정된 데이터베이스 연결에 집계 절감액이 표시됩니다. 자세한 내용은 Looker의 데이터 탐색 문서 페이지를 참고하세요.
Looker가 새 데이터를 집계 테이블에 조인
시간 필터가 있는 집계 테이블의 경우 Looker가 새 데이터를 집계 테이블에 통합할 수 있습니다. 지난 3일 동안의 데이터가 포함된 집계 테이블이 있지만 해당 집계 표는 어제 빌드되었을 수 있습니다. 집계 테이블에 오늘 정보가 누락될 수 있으므로 가장 최근의 일일 정보에 대한 탐색 쿼리에 사용할 수 있을 것입니다.
그러나 Looker는 여전히 해당 집계 테이블의 데이터를 쿼리에 사용할 수 있습니다. Looker가 최신 데이터에 쿼리를 실행한 후 결과를 집계 테이블의 결과에 통합하기 때문입니다.
Looker는 다음과 같은 경우에 최신 데이터를 집계 테이블과 조인할 수 있습니다.
- 집계 테이블에는 시간 필터가 있습니다.
- 집계 테이블에는 시간 필터와 동일한 시간 필드를 기반으로 하는 측정기준이 포함됩니다.
예를 들어 다음 집계 테이블에는 orders.created_date 필드를 기반으로 하는 측정기준이 있고, 동일한 필드를 기반으로 하는 시간 필터("3 days")가 있습니다.
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
이 집계 테이블이 어제 빌드된 경우 Looker는 아직 집계 테이블에 포함되지 않은 최신 데이터를 검색한 다음 최신 결과를 집계 테이블의 결과와 결합합니다. 즉, 사용자는 최신 데이터를 제공받아도 계속해서 집계 실적을 사용하여 실적을 최적화할 수 있습니다.
개발 모드에 있는 경우 탐색의 SQL 탭을 클릭하여 Looker가 쿼리에 사용한 집계 테이블 및 Looker가 집계 테이블에 포함되지 않은 최신 데이터를 가져오는 데 사용한 UNION 문을 볼 수 있습니다.
현재 Looker가 새 데이터를 총괄 테이블과 연결할 수 없는 경우 Looker는 집계 테이블의 기존 데이터를 사용합니다.
집계 테이블은 지속되어야 합니다.
집계 인식을 위해 액세스할 수 있으려면 집계 테이블이 데이터베이스에 지속되어야 합니다. 지속성 전략은 집계 테이블의 materialization 매개변수에 지정됩니다. 집계 테이블은 영구 파생 테이블 (PDT) 유형이므로 집계 테이블에는 PDT와 동일한 요구사항이 적용됩니다. 자세한 내용은 Looker의 파생 테이블 문서 페이지를 참조하세요.
언어가 PDT를 지원하는 경우 프로젝트에 증분 PDT를 만들 수 있습니다. Looker는 테이블을 완전히 다시 빌드하는 대신 테이블에 최신 데이터를 추가하여 증분 PDT를 빌드합니다. 집계 테이블은 그 자체로 PDT의 한 유형이므로 증분 집계 테이블도 만들 수 있습니다. 증분 PDT에 대한 자세한 내용은 증분 PDT 문서 페이지를 참조하세요. 증분 집계 테이블의 예는 increment_key 매개변수 문서 페이지를 참조하세요.
develop 권한이 있는 사용자는 지속성 설정을 재정의하고 쿼리의 모든 집계 테이블을 다시 빌드하여 최신 데이터를 가져올 수 있습니다. 쿼리의 테이블을 다시 빌드하려면 탐색 메뉴에서 파생 테이블 다시 빌드 및 실행 옵션을 사용하세요.
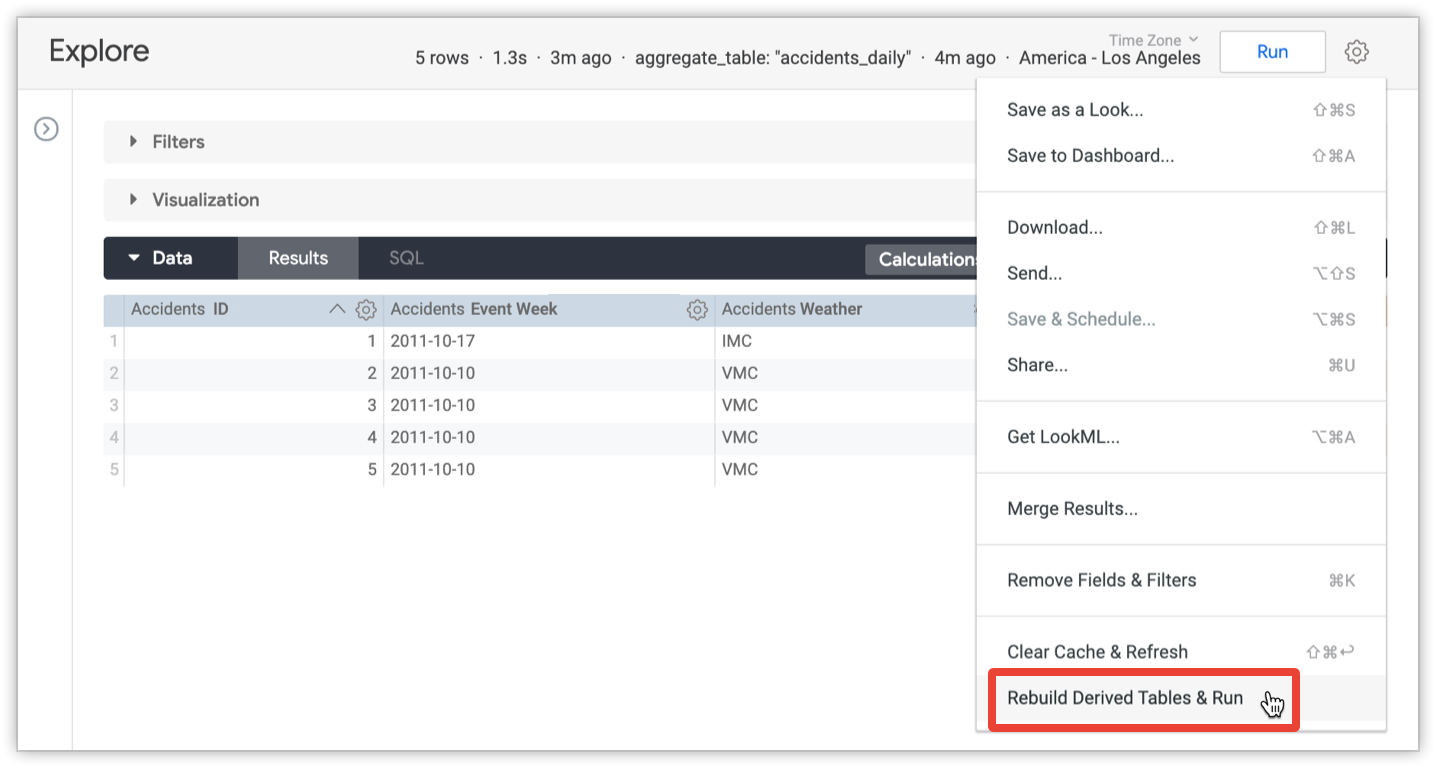
이 옵션을 사용하려면 탐색 쿼리가 로드될 때까지 기다려야 합니다.
Rebuild Derived Tables & Run 옵션은 쿼리에 참조된 모든 파생 테이블 및 쿼리의 테이블에 종속된 모든 파생 테이블을 다시 빌드합니다. 여기에는 영구 파생 테이블의 한 유형인 집계 테이블이 포함됩니다.
Rebuild Derived Tables & Run 옵션을 시작하는 사용자의 경우 쿼리가 테이블이 다시 빌드될 때까지 기다린 후 결과를 로드합니다. 다른 사용자는 기존 테이블을 계속 사용합니다. 영구 테이블이 다시 빌드되면 모든 사용자가 다시 빌드된 테이블을 사용합니다.
Looker 파생 테이블 및 실행 옵션에 대한 자세한 내용은 Looker의 파생 테이블 문서 페이지를 참조하세요.
문제 해결
쿼리에 사용되는 집계 테이블 확인 섹션에 설명된 대로 개발 모드인 경우 탐색에서 쿼리를 실행하고 SQL 탭을 클릭하여 쿼리에 사용되는 집계 테이블에 대한 주석을 볼 수 있습니다(있는 경우).
SQL 탭에는 쿼리에 집계 테이블이 사용되지 않은 이유에 대한 주석도 있습니다. 사용되지 않는 집계 테이블의 경우 주석은 다음과 같이 시작합니다.
Did not use [explore name]::[aggregate table name];
예를 들어 다음은 order_items 탐색에 정의된 sales_daily 집계 테이블이 쿼리에 사용되지 않은 이유에 대한 주석입니다.
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
이 경우 쿼리의 필터로 인해 집계 테이블을 사용할 수 없습니다.
다음 표에는 집계 테이블을 사용할 수 없는 몇 가지 가능한 이유와 집계 테이블의 사용성을 높이기 위해 취할 수 있는 단계가 나와 있습니다.
| 집계 테이블을 사용하지 않는 이유 |
설명 및 가능한 단계 |
|---|---|
| 탐색에 해당 필드가 없습니다. | LookML 검증 유형 오류가 있습니다. 대부분 집계 테이블이 올바르게 정의되지 않았거나 LookML에서 집계 테이블의 오타가 있었기 때문일 수 있습니다. 문제의 원인으로는 잘못된 필드 이름 등이 있습니다. 이 문제를 해결하려면 집계 표의 측정기준과 측정항목이 탐색의 필드 이름과 일치하는지 확인하세요. 집계 테이블을 정의하는 방법에 대한 자세한 내용은 aggregate_table 매개변수 문서 페이지를 참조하세요. |
| 집계 테이블은 쿼리에 다음 필드를 포함하지 않습니다. | 집계 쿼리에 탐색 쿼리에 사용하려면 집계 쿼리에 해당 탐색 쿼리에 필요한 모든 측정기준과 측정항목이 있어야 합니다. 여기에는 탐색 쿼리의 필터에 사용되는 필드가 포함됩니다. 집계 쿼리에 없는 측정기준 또는 측정값을 탐색 쿼리에 포함하는 경우, Looker는 집계 테이블을 사용할 수 없으며 대신 기본 테이블을 사용합니다. 자세한 내용은 이 페이지의 필드 요소 섹션을 참고하세요. 한 가지 예외는 기간 차원입니다. 세밀한 세분화 기간을 보다 세분화할 수 있기 때문입니다. 이 문제를 해결하려면 탐색 쿼리 필드가 집계 테이블 정의에 포함되어 있는지 확인하세요. |
| 쿼리에 다음 필드가 포함되어 있지 않습니다. 이러한 필터는 필드로 포함되지 않았거나 총괄 테이블의 필터와 정확히 일치하지 않습니다. | 탐색 쿼리의 필터로 인해 Looker에서 집계 테이블을 사용할 수 없습니다. 이 문제를 해결하려면 다음 중 하나를 실행하세요.
|
| 쿼리에 롤업할 수 없는 다음 조치가 포함되어 있습니다. | 이 쿼리에는 집계 값에서 지원되지 않는 측정 유형(예: 고유 개수, 중앙값, 백분위수)이 하나 이상 포함되어 있습니다. 이 문제를 해결하려면 쿼리의 각 측정 유형 유형을 확인하고 지원되는 측정 유형 중 하나인지 확인하세요. 또한 탐색에 조인이 있는 경우 측정값이 팬아웃된 조인을 통해 고유한 측정값 (대칭 집계)으로 변환되지 않는지 확인합니다. 자세한 내용은 이 페이지의 조인을 사용한 탐색의 대칭 집계 섹션을 참조하세요. |
| 다른 집계 표는 최적화에 더 적합했습니다. | 쿼리에 사용할 수 있는 집계 테이블이 여러 개 있었으며 Looker는 대신 사용하기에 더 적합한 집계 테이블을 찾았습니다. 이 경우 별도의 조치를 취할 필요가 없습니다. |
Looker에서 그룹화를 수행하지 않았으므로 (primary_key 또는 cancel_grouping_fields 매개변수로 인해) 쿼리가 롤업될 수 없습니다. |
이 쿼리는 GROUP BY 절이 없는 측정기준을 참조하므로 Looker에서 쿼리에 집계 테이블을 사용할 수 없습니다.
이 문제를 해결하려면 뷰의 primary_key 매개변수와 탐색의 cancel_grouping_fields 매개변수가 올바르게 설정되어 있는지 확인하세요. |
| 집계 테이블에는 쿼리에 없는 필터가 포함되어 있습니다. | 집계 테이블에 시간이 아닌 필터가 쿼리에 없습니다. 이 문제를 해결하려면 집계 테이블에서 필터를 삭제하면 됩니다. 자세한 내용은 이 페이지의 필터 요소 섹션을 참조하세요. |
필드는 탐색 쿼리에서 필터 전용 필드로 정의되지만 집계 테이블의 dimensions 매개변수에 나열됩니다. |
집계 테이블의 dimensions 매개변수는 탐색 쿼리에 filter 필드로만 정의된 필드를 나열합니다.이 문제를 해결하려면 집계 테이블의 dimensions 목록에서 필드를 삭제하세요. 이 필드가 집계 테이블에 필요한 경우 집계 테이블의 쿼리의 filters 목록에 추가합니다. |
| 옵티마이저는 집계 테이블이 사용되지 않은 이유를 확인할 수 없습니다. | 이 케이스는 특수한 경우를 위한 것입니다. 자주 사용되는 탐색 쿼리에 이 메시지가 표시되면 탐색 쿼리와 정확하게 일치하는 집계 테이블을 만들 수 있습니다. aggregate_table 매개변수 페이지에 설명된 대로 탐색에서 집계 테이블 LookML을 쉽게 가져올 수 있습니다. |
고려사항
조인을 사용한 탐색의 대칭 집계
한 가지 유의할 점은 Looker가 여러 데이터베이스 테이블을 조인하는 탐색에서 SUM, COUNT, AVERAGE 유형의 측정값을 각각 SUM DISTINCT, COUNT DISTINCT, AVERAGE DISTINCT로 렌더링할 수 있다는 것입니다. Looker는 팬아웃 계산이 발생하지 않도록 하기 위해 사용합니다. 예를 들어 count 측정값은 count_distinct 측정 유형으로 렌더링됩니다. 이는 조인에 대해 팬아웃 계산이 계산되는 것을 방지하기 위한 것으로, Looker의 대칭 집계 기능에 포함되어 있습니다. Looker의 이 기능에 대한 설명은 대칭 집계에 대한 고객센터 도움말을 참조하세요.
대칭 집계 기능은 계산 오류를 방지하지만 특정 경우에 집계 테이블이 사용되지 않도록 할 수 있으므로 이해하는 것이 중요합니다.
집계 인식에서 지원하는 측정 유형의 경우 sum, count, average에 적용됩니다. Looker는 다음과 같은 경우 이러한 유형의 측정을 DISTINCT로 렌더링합니다.
이러한 유형의 조인에 대한 설명은 relationship 매개변수 문서 페이지를 참조하세요.
이러한 이유로 집계 테이블이 사용되지 않는 경우 탐색 쿼리와 정확하게 일치하는 집계 테이블을 만들어 조인을 통한 탐색에 이러한 측정 유형을 사용할 수 있습니다. 자세한 내용은 이 페이지의 쿼리와 정확하게 일치하는 집계 테이블 만들기 섹션을 참조하세요.
또한 HyperLogLog 스케치를 지원하는 SQL 언어를 사용하는 경우 측정값에 allow_approximate_optimization: yes 매개변수를 추가할 수 있습니다. 카운트 측정이 allow_approximate_optimization: yes로 정의되면 Looker가 카운트를 고유 집계로 렌더링하더라도 집계 인식에 사용할 수 있습니다.
자세한 내용과 HyperLogLog 스케치 지원 SQL 언어 목록은 allow_approximate_optimization 매개변수 문서 페이지를 참고하세요.
집계 인지도에 대한 방언 지원
집계 인식 사용 가능 여부는 Looker 연결에서 사용하는 데이터베이스 언어에 따라 다릅니다. Looker 최신 출시 버전에서는 다음 언어를 사용해 집계 인식이 지원됩니다.
Google BigQuery Legacy SQL은 집계 인식을 지원하지만 집계 데이터를 새 데이터와 결합하는 것은 지원하지 않습니다.
점진적 집계 테이블 빌드를 위한 언어 지원
Looker 프로젝트에서 증분 집계 테이블을 지원하려면 데이터베이스 언어에서도 Looker를 지원해야 합니다. 다음 표는 최신 Looker 버전에서 집계 테이블과 PDT 증분 빌드를 모두 지원하는 언어를 보여줍니다.