자세한 내용은 집계 인식 문서 페이지를 참조하세요.
소개
이 페이지에서는 구현 기회 파악, 가치 집계 인식 제고, 실제 모델에 구현하기 위한 간단한 워크플로 등 실제 시나리오에서 집계 인식을 구현하기 위한 가이드입니다. 이 페이지는 모든 집계 인식 기능 또는 특이 사례에 대한 자세한 설명이나 모든 기능을 포괄적으로 다루지 않습니다.
집계 인식이란 무엇인가요?
Looker에서는 데이터베이스의 원시 테이블이나 뷰를 대부분 쿼리합니다. Looker 영구 파생 테이블(PDT)인 경우도 있습니다.
성능을 높이기 위해 집계 테이블이나 롤업이 필요한 대규모 데이터 세트나 테이블이 있는 경우가 많습니다.
일반적으로 제한된 차원을 포함하는 orders_daily 테이블과 같은 집계 테이블을 만들 수 있습니다. 이들은 Explore에서 별도로 취급하고 모델링해야 하며 모델에 깔끔하게 배치되어 있지 않습니다. 이러한 제한사항은 사용자가 동일한 데이터에 대해 여러 Explore 중에서 선택해야 할 때 사용자 경험을 저하시킵니다.
이제 Looker의 집계 인식을 사용하여 다양한 수준의 세부사항, 차원, 집계에 대해 집계 테이블을 사전 구성할 수 있으며, 기존 Explore 내에서 이를 사용하는 방법을 Looker에 알릴 수 있습니다. 그러면 쿼리는 사용자 입력 없이 Looker가 적절하다고 판단한 롤업 테이블을 활용합니다. 이렇게 하면 쿼리 크기가 줄어들고 대기 시간이 단축되며 사용자 환경이 향상됩니다.
참고: Looker의 집계 테이블은 영구 파생 테이블(PDT) 유형입니다. 즉, 집계 테이블은 데이터베이스 및 연결 요구사항이 PDT와 동일합니다.데이터베이스 언어 및 Looker 연결이 PDT를 지원하는지 알아보려면 Looker의 파생 테이블 문서 페이지에 나열된 요구사항을 참조하세요.
데이터베이스 언어가 집계 인식을 지원하는지 알아보려면 집계 인식 문서 페이지를 참조하세요.
집계 인식의 가치
기존 Looker 모델에서 더 많은 가치를 창출하기 위한 여러 가지 중요한 가치 제안 집계 인식 제안이 있습니다.
- 성능 개선: 집계 인식을 구현하면 사용자 쿼리가 더 빨라집니다. Looker에서 사용자 쿼리를 완료하는 데 필요한 데이터가 포함된 작은 테이블을 사용합니다.
- 비용 절감: 특정 언어는 소비 모델에 따라 쿼리 크기로 비용이 청구됩니다. Looker에서 더 작은 테이블을 쿼리하면 사용자 쿼리당 비용이 감소하게 됩니다.
- 사용자 환경 개선: 답변을 더 빠르게 가져오는 개선된 환경과 함께 통합으로 인해 중복 Explore가 생성되지 않습니다.
- LookML 사용 공간 축소: 기존의 Liquid 기반 집계 인식 전략을 유연한 기본 구현으로 대체하면 복원력이 높아지고 오류가 줄어듭니다.
- 기존 LookML 활용: 집계 테이블은 명시적인 커스텀 SQL로 로직을 복제하는 대신 기존 모델링된 로직을 재사용하는
query객체를 사용합니다.
기본 예시
다음은 Looker 모델에서 아주 간단한 구현 방식으로 가볍게 집계된 인식의 정도를 보여줍니다. FAA를 통해 기록된 모든 항공편에 대한 행이 있는 데이터베이스의 가상의 flights 테이블이 있다면 Looker에서 이 테이블을 자체 뷰 및 Explore로 모델링할 수 있습니다. 다음은 Explore 분석에 대해 정의할 수 있는 집계 테이블의 LookML입니다.
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
이 집계 테이블을 사용하면 사용자가 flights Explore를 쿼리할 수 있으며 Looker에서 LookML에 정의된 집계 테이블을 자동으로 활용하고 집계 테이블을 사용하여 쿼리에 답변합니다. 사용자가 Looker에 특별한 조건을 알릴 필요가 없습니다. 테이블이 사용자가 선택한 필드에 적합하면 Looker가 이 테이블을 사용합니다.
see_sql 권한이 있는 사용자는 탐색의 SQL 탭에 있는 주석을 사용하여 쿼리에 사용할 집계 테이블을 확인할 수 있습니다. 다음은 flights:flights_by_week_and_carrier in teach_scratch 집계 테이블을 사용하는 쿼리에 대한 Looker SQL 탭의 예시입니다.
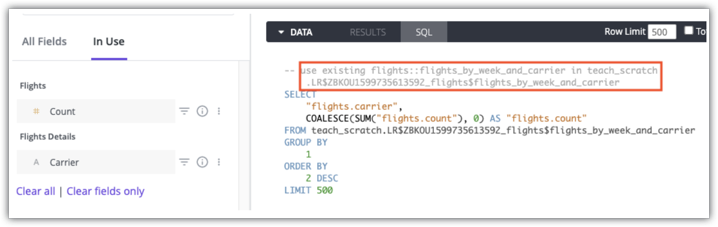
쿼리에 집계 테이블이 사용되는지 확인하는 방법은 집계 인식 문서 페이지를 참조하세요.
기회 식별
집계 인식의 이점을 극대화하려면 최적화 또는 집계 인식 값을 촉진하는 데 집계 인식이 특정 역할을 담당할 수 있는 분야를 파악해야 합니다.
높은 런타임으로 대시보드 식별
집계 인식의 한 가지 기회는 런타임이 매우 높고 사용량이 많은 대시보드를 위한 집계 테이블을 만드는 것입니다. 사용자는 대시보드가 느리다는 이야기를 들으실 수 있지만, see_system_activity를 사용하고 있다면 Looker의 시스템 활동 기록 Explore를 사용하여 런타임이 평균보다 느린 대시보드를 찾을 수도 있습니다. 단축키로 브라우저에서 다음 URL을 사용하고 HOSTNAME를 Looker 인스턴스의 이름 (예: example.cloud.looker.com)으로 바꿀 수 있습니다.
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
제목, 기록, Explore 개수, 캐시와 데이터베이스 비교, 평균보다 성능이 낮은 경우 등 인스턴스의 대시보드에 대한 데이터가 포함된 Explore 분석 시각화가 표시됩니다.
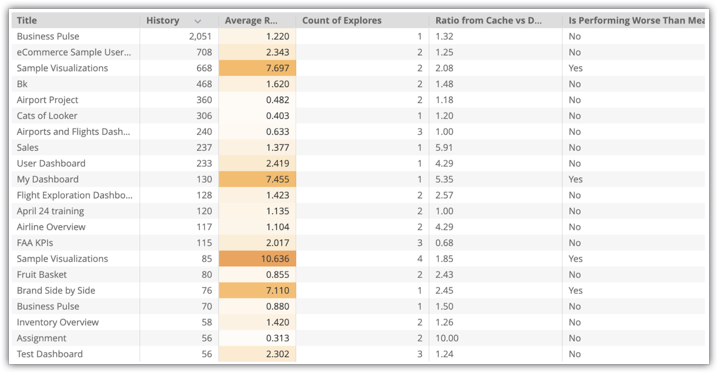
이 예에는 샘플 시각화 대시보드처럼 사용률이 평균보다 낮은 대시보드가 많습니다. 샘플 시각화 대시보드에서는 두 개의 Explore를 사용하므로 이 두 Explore 모두에 대한 집계 테이블을 만드는 것이 좋습니다.
속도가 느리고 사용자가 자주 쿼리하는 Explore 식별
집계 인식을 높일 수 있는 또 다른 기회는 사용자가 자주 쿼리하고 평균 미만의 쿼리 응답을 갖는 Explore입니다.
시스템 활동 기록 Explore를 Explore 최적화 기회를 파악할 때 출발점으로 사용할 수 있습니다. 단축키로 브라우저에서 다음 URL을 사용하고 HOSTNAME를 Looker 인스턴스의 이름 (예: example.cloud.looker.com)으로 바꿀 수 있습니다.
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Explore, 모델, 쿼리 실행 횟수, 사용자 수, 평균 런타임(초) 등 인스턴스의 Explore에 대한 데이터가 포함된 Explore 시각화가 표시됩니다.

기록 Explore에서 인스턴스의 다음 Explore 유형을 식별할 수 있습니다.
- API에서 쿼리하거나 예약된 전송에서 쿼리하는 것이 아니라 사용자가 쿼리하는 Explore
- 자주 쿼리되는 Explore
- 다른 Explore와 비교했을 때 성능이 낮은 Explore
이전 시스템 활동 기록 Explore 예시에서 flights 및 order_items Explore는 집계 인식을 구현하기에 적합한 후보입니다.
쿼리에 많이 사용되는 필드 식별
마지막으로 사용자가 쿼리 및 필터에 일반적으로 포함하는 필드를 이해하여 데이터 수준에서 다른 기회를 식별할 수 있습니다.
단축키로 브라우저에서 다음 URL을 사용하고 HOSTNAME를 Looker 인스턴스의 이름 (예: example.cloud.looker.com)으로 바꿀 수 있습니다.
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
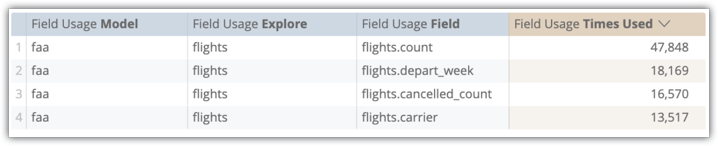
필터를 적절히 교체하세요. 쿼리에서 필드가 사용된 횟수를 나타내는 막대 그래프 시각화를 통한 Explore가 표시됩니다.
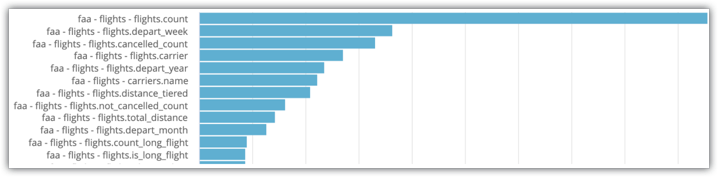
이미지에 표시된 시스템 활동 Explore 예시에서는 flights.count 및 flights.depart_week가 Explore에 대해 가장 일반적으로 선택되는 두 개의 필드라는 것을 알 수 있습니다. 따라서 이러한 필드는 집계 테이블에 포함하기에 적합한 필드 후보입니다.
이와 같은 구체적인 데이터는 유용하지만 선택 기준을 안내하는 주관적 요소가 있습니다. 예를 들어 위의 4개 필드를 살펴보면 사용자가 일반적으로 예약된 항공편 수와 취소된 항공편 수를 보고 이 데이터를 주 및 항공사별로 세분화하려고 한다고 안전하게 추측할 수 있습니다. 이는 필드와 측정항목의 명확하고 논리적인 실제 조합의 예입니다.
요약
이 문서 페이지의 단계는 최적화 대상으로 고려할 수 있는 대시보드, Explore, 필드를 찾기 위한 가이드로 사용해야 합니다. 세 가지 모두 상호 배타적일 수 있다는 점을 이해하는 것도 좋습니다. 문제가 있는 대시보드는 문제가 있는 Explore에 의해 구동되지 않을 수 있으며, 일반적으로 사용되는 필드로 집계 테이블을 빌드하면 이러한 대시보드가 전혀 도움이 되지 않을 수 있습니다. 이것들은 세 가지 고유한 집계 인식으로 구현될 수 있습니다.
집계 테이블 설계
집계 인식을 위한 기회를 식별한 후에는 이러한 기회를 가장 효과적으로 반영할 수 있는 집계 테이블을 설계할 수 있습니다. 집계 테이블에서 지원되는 필드, 측정값, 기간과 집계 테이블 설계에 관한 기타 가이드라인은 집계 인식 문서 페이지를 참조하세요.
참고: 집계 테이블은 사용할 쿼리와 정확하게 일치할 필요가 없습니다. 쿼리가 주 단위이고 일일 롤업 테이블이 있는 경우 Looker에서 원시 타임스탬프 수준 테이블 대신 집계 테이블을 사용합니다. 마찬가지로brand및date수준으로 롤업된 집계 테이블이 있고 사용자가brand수준에서만 쿼리하는 경우에도 이 테이블은 Looker에서 집계 인식에 사용할 수 있는 후보입니다.
집계 인식은 다음 측정값을 지원합니다.
- 표준 측정값: SUM, COUNT, AVERAGE, MIN, MAX 유형의 측정값
- 복합 측정값: NUMBER, STRING, YESNO, DATE 유형의 측정값
- 대략적인 고유 측정값: HyperLogLog 기능을 사용할 수 있는 언어
집계 인식은 다음 측정값을 지원하지 않습니다.
- 고유 측정값: 고유성은 집계되지 않은 원자적 데이터에 대해서만 계산할 수 있으므로
*_DISTINCT측정값은 HyperLogLog를 사용하는 이러한 근사치 외부에서 지원되지 않습니다. - 카디널리티 기반 측정값: 다른 측정값과 마찬가지로 중앙값과 백분위수는 사전 집계할 수 없으며 지원되지 않습니다.
참고: 집계 인식에서 지원하지 않는 측정 유형을 사용하는 잠재적 사용자 쿼리를 알고 있으면 쿼리와 정확하게 일치하는 집계 테이블을 생성해야 할 수 있습니다. 쿼리와 정확하게 일치하는 집계 테이블을 사용하면 집계 인식에서 지원되지 않는 측정 유형을 사용하여 쿼리에 답할 수 있습니다.
집계 테이블 세분성
측정기준과 측정의 조합을 위한 테이블을 만들기 전에 사용 및 필드 선택의 공통 패턴을 결정하여 가장 큰 영향을 미치면서 가장 많이 사용되는 집계 테이블을 만들어야 합니다. 쿼리에 테이블을 사용하려면 쿼리에 사용된 모든 필드(선택한 필드 또는 필터링된 필드)가 집계 테이블에 있어야 합니다. 하지만 앞에서 설명한 것처럼 집계 테이블은 쿼리에 사용할 쿼리와 정확히 일치할 필요는 없습니다. 단일 집계 테이블 내에서 다양한 사용자 쿼리를 처리할 수 있으며 여전히 상당한 성능 이점을 얻을 수 있습니다.
쿼리에서 많이 사용되는 필드 식별 예시에는 매우 자주 선택되는 2개의 측정기준(flights.depart_week 및 flights.carrier)과 2개의 측정값(flights.count 및 flights.cancelled_count)이 있습니다. 따라서 이러한 4개의 필드를 모두 사용하는 집계 테이블을 빌드하는 것이 논리적입니다. 또한 flights_by_week_and_carrier에 대한 단일 집계 테이블을 만들면 flights_by_week 및 flights_by_carrier 테이블에 대한 서로 다른 두 집계 테이블보다 사용량이 더 많아집니다.
다음은 공통 필드의 쿼리에 대해 만들 수 있는 집계 테이블 예시입니다.
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
비즈니스 사용자와 일화 증거 및 Looker의 시스템 활동 데이터를 토대로 의사 결정을 내릴 수 있습니다.
적용 가능성과 성능 간 균형 유지
다음 예시는 flights_by_week_and_carrier 집계 테이블의 항공편 출발 주, 항공편 세부정보 항공사, 항공편 수, 항공편 상세 취소 수 필드의 Explore 쿼리를 보여줍니다.
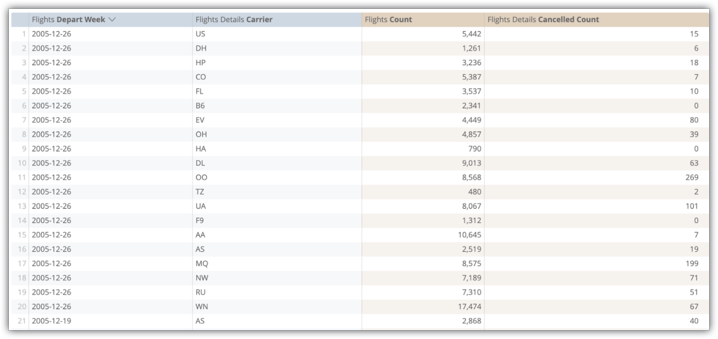
원본 데이터베이스 테이블에서 이 쿼리를 실행하는 데는 15.8초가 소요되었으며 Amazon Redshift를 사용한 조인 없이 3,800만 개의 행을 스캔했습니다. 일반적인 사용자 작업인 쿼리 피벗에는 29.5초가 걸렸습니다.
flights_by_week_and_carrier 집계 테이블을 구현한 후 후속 쿼리에는 7.2초가 걸리고 4,592개 행을 스캔했습니다. 이렇게 하면 테이블 크기가 99.98% 감소합니다. 쿼리 피벗에는 9.8초가 걸렸습니다.
시스템 활동 필드 사용 Explore에서 사용자가 쿼리에 이러한 필드를 포함하는 빈도를 확인할 수 있습니다. 이 예시에서는 flights.count가 47,848회 사용되었고 flights.depart_week는 18,169회, flights.cancelled_count는 16,570회, flights.carrier는 13,517회 사용되었습니다.
이 쿼리 중 25%가 4개 필드를 모두 가장 간단한 방식(단순 선택, 피벗 없음)으로 사용한다고 단순하게 예상하더라도 3379 x 8.6초 = 8시간, 총 사용자 대기 시간 4분을 없앱니다.
참고: 여기에 사용된 예시 모델은 매우 기본적인 모델입니다. 이러한 결과를 모델의 벤치마크 또는 참조 프레임으로 사용해서는 안 됩니다.
전자상거래 모델인 order_items와 동일한 흐름을 인스턴스에서 가장 자주 사용되는 Explore로 적용한 후의 결과는 다음과 같습니다.
| 소스 | 쿼리 시간 | 스캔된 행 |
|---|---|---|
| 기본 테이블 | 13.1초 | 285,000개 |
| 집계 테이블 | 5.1초 | 138,000개 |
| 델타 | 8초 | 147,000개 |
쿼리와 후속 집계 테이블에 사용된 필드는 2개의 조인을 사용하는 brand, created_date, orders_count, total_revenue입니다. 이 필드는 총 11,000회 사용되었습니다. 최대 25%의 동일한 총 사용량을 추정할 경우 사용자의 총 절약 시간은 6시간 6분(8초 * 2750 = 22,000초)이 됩니다. 집계 테이블을 만드는 데 17.9초가 걸렸습니다.
이러한 결과를 살펴보면 잠시 시간을 내어 다음에서 얻은 결과를 평가하는 것이 좋습니다.
- '허용 가능한' 성능을 가지고 있으며 더 나은 모델링 방식을 통해 성능이 개선될 가능성이 있는 더 크고 복잡한 모델/Explore 최적화
vs.
- 집계 인식을 사용하여 더 자주 사용되고 성능이 저조한 간단한 모델 최적화
Looker와 데이터베이스에서 마지막 성능을 가져오려고 하면 노력한 결과에 따른 수익이 감소하게 됩니다. 특히 비즈니스 사용자로부터 기대하는 기준 성능 기대치와 데이터베이스에서 부과하는 제한사항(예: 동시 실행, 쿼리 기준점, 비용 등)에 대해 항상 잘 알고 있어야 합니다. 이러한 한계를 극복하기 위한 집계 인식을 기대해서는 안 됩니다.
또한 집계 테이블을 설계할 때 필드가 많아질수록 집계 테이블이 커지고 속도가 느려집니다. 테이블이 클수록 더 많은 쿼리를 최적화할 수 있으므로 더 많은 상황에서 사용할 수 있습니다. 하지만 큰 테이블은 작고 간단한 테이블만큼 빠르지 않습니다.
예를 들면 다음과 같습니다.
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}이렇게 하면 표시된 측정기준의 조합과 포함된 모든 측정값에 집계 테이블이 사용되므로, 이 테이블을 여러 다른 사용자 쿼리에 답하는 데 사용할 수 있습니다. 하지만 간단한 carrier 및 count SELECT 쿼리에 이 테이블을 사용하려면 885,000개 행을 스캔해야 합니다. 반대로 테이블이 2개의 측정기준을 기반으로 하는 경우 같은 쿼리에서는 행 4,592개만 스캔해야 합니다. 885,000개 행 테이블을 사용하면 테이블 크기가 이전 행 3,800만 개에서 97% 줄어듭니다. 하지만 측정기준을 하나 더 추가하면 테이블 크기가 2천만 개 행으로 늘어납니다. 따라서 더 많은 쿼리에 대한 적용 가능성을 높이기 위해 집계 테이블에 더 많은 필드를 포함하면 수익 감소가 발생합니다.
집계 테이블 빌드
최적화 기회로 식별된 항공편 Explore의 예를 생각해 볼 때 가장 좋은 전략은 이를 위한 3가지 집계 테이블을 만드는 것입니다.
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
이러한 집계 테이블을 빌드하는 가장 쉬운 방법은 Explore 쿼리 또는 대시보드에서 집계 테이블 LookML을 가져와 Looker 프로젝트 파일에 LookML 추가하는 것입니다.
LookML 프로젝트에 집계 테이블을 추가하고 업데이트를 프로덕션에 배포하면 Explore에서 사용자 쿼리에 집계 테이블을 활용합니다.
지속성
집계 인식에 액세스하려면 데이터베이스에 집계 테이블이 유지되어야 합니다. 이러한 집계 테이블의 자동 재생성을 데이터 그룹을 활용해서 캐싱 정책에 맞게 조정하는 것이 가장 좋습니다. 연결된 Explore에 사용되는 집계 테이블에는 동일한 데이터 그룹을 사용해야 합니다. 데이터 그룹을 사용할 수 없을 때 대체 가능한 옵션은 sql_trigger_value 파라미터를 대신 사용하는 것입니다. 다음은 sql_trigger_value의 일반적인 날짜 기반 값을 보여줍니다.
sql_trigger_value: SELECT CURRENT_DATE() ;;
이렇게 하면 매일 자정에 집계 테이블이 자동으로 빌드됩니다.
기간 논리
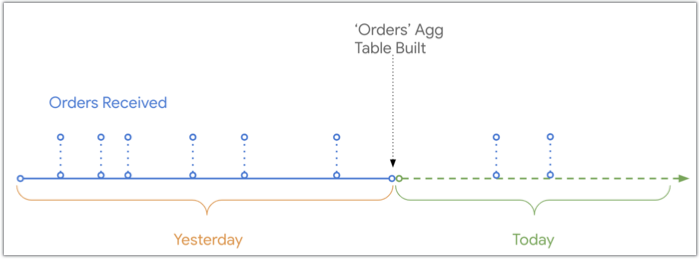
Looker에서 집계 테이블을 빌드하면 집계 테이블이 빌드된 시점까지의 데이터가 포함됩니다. 이후에 데이터베이스의 기본 테이블에 추가된 모든 데이터는 해당 집계 테이블을 사용하는 쿼리 결과에서 제외됩니다.
이 다이어그램은 주문 집계 테이블이 빌드된 시점과 비교하여 주문이 접수되고 데이터베이스에 기록된 시점의 타임라인을 보여줍니다. 집계 테이블이 빌드된 후에 주문이 접수되었기 때문에 오늘 접수된 주문 2건은 주문 집계 테이블에 표시되지 않습니다.
그러나 동일한 타임라인 다이어그램에 나와 있는 것처럼 사용자가 집계 테이블과 겹치는 기간을 쿼리하면 Looker에서 집계 테이블에 새 데이터를 UNION할 수 있습니다.
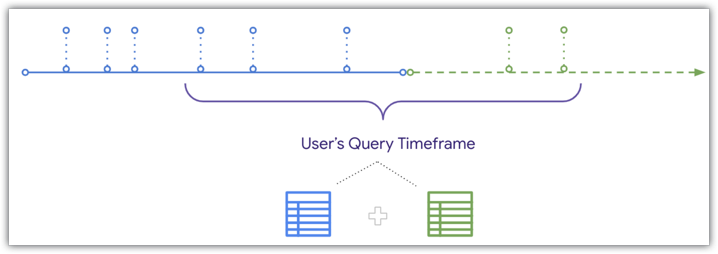
Looker에서 최신 데이터를 집계 테이블에 UNION할 수 있으므로, 사용자가 집계 테이블 및 기본 테이블의 끝 부분과 겹치는 기간을 필터링하면 집계 테이블이 빌드된 후 접수된 주문이 사용자 결과에 포함됩니다. 집계 테이블 쿼리에 새 데이터를 결합하기 위해 충족해야 하는 조건과 자세한 내용은 집계 인식 문서 페이지를 참조하세요.
요약
요약하면 집계 인식 구현을 빌드하기 위한 3가지 기본 단계가 있습니다.
- 집계 테이블을 사용한 최적화가 적절하고 효과적인 기회를 식별합니다.
- 일반 사용자 쿼리에 대한 적용 범위가 가장 넓고 쿼리 크기를 충분히 줄일 수 있을 정도로 작게 만드는 집계 테이블을 설계합니다.
- Looker 모델에서 집계 테이블을 빌드하고 테이블의 지속성을 Explore 캐시의 지속성과 연결합니다.