For additional details, see the Aggregate awareness documentation page.
Introduction
This page is a guide for implementing aggregate awareness in a practical scenario, including identifying opportunities for implementation, the value aggregate awareness drives, and a simple workflow for implementing it in a real model. This page is not a deep explanation of all aggregate awareness features or edge cases, nor is it an exhaustive catalogue of all its features.
What is aggregate awareness?
In Looker, you mostly query against raw tables or views in your database. Sometimes these are Looker persistent derived tables (PDTs).
You may often encounter very large datasets or tables that, in order to be performant, require aggregation tables or roll-ups.
Commonly, you may create aggregation tables like an orders_daily table that contains limited dimensionality. These need to be treated separately and modeled separately in the Explore, and they do not sit in the model neatly. These limitations lead to poor user experiences when the user has to choose between multiple Explores for the same data.
Now, with Looker's aggregate awareness, you can pre-construct aggregate tables to various levels of granularity, dimensionality, and aggregation; and you can inform Looker of how to use them within existing Explores. Queries will then leverage these roll-up tables where Looker deems appropriate, without any user input. This will cut down query size, reduce wait times, and enhance user experience.
NOTE: Looker's aggregate tables are a type of persistent derived table (PDT). This means that aggregate tables have the same database and connection requirements as PDTs.To see if your database dialect and Looker connection can support PDTs, see the requirements listed on the Derived tables in Looker documentation page.
To see if your database dialect supports aggregate awareness, see the Aggregate awareness documentation page.
The value of aggregate awareness
There are a number of significant value propositions aggregate awareness offers to drive extra value from your existing Looker model:
- Performance improvement: Implementing aggregate awareness will make user queries faster. Looker will use a smaller table if it contains data needed to complete the user's query.
- Cost savings: Certain dialects charge by the size of query on a consumption model. By having Looker query smaller tables, you will have a reduced cost per user query.
- User experience enhancement: Along with an improved experience that retrieves answers faster, consolidation eliminates redundant Explore creation.
- Reduced LookML footprint: Replacing existing, Liquid-based aggregate awareness strategies with flexible, native implementation leads to increased resilience and fewer errors.
- Ability to leverage existing LookML: Aggregate tables use the
queryobject, which reuses existing modeled logic rather than duplicating logic with explicit custom SQL.
Basic example
Here is a very simple implementation in a Looker model to demonstrate how lightweight aggregate awareness can be. Given a hypothetical flights table in the database with a row for every flight recorded through the FAA, we can model this table in Looker with its own view and Explore. Here is the LookML for an aggregate table we can define for the Explore:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
With this aggregate table, a user can query the flights Explore and Looker will automatically leverage the aggregate table that is defined in the LookML and use the aggregate table to answer queries. The user won't have to inform Looker of any special conditions: If the table is a fit for the fields that the user selects, Looker will use that table.
Users with see_sql permissions can use the comments in the SQL tab of an Explore to see which aggregate table will be used for a query. Here is an example Looker SQL tab for a query that uses the aggregate table flights:flights_by_week_and_carrier in teach_scratch:
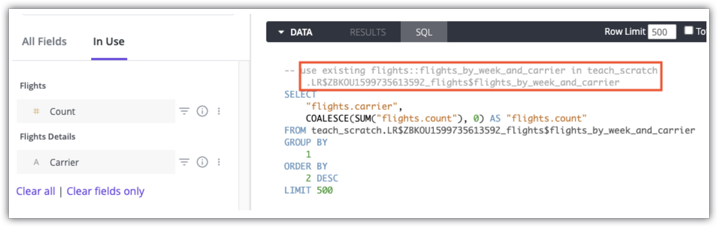
See the Aggregate awareness documentation page for details on determining if aggregate tables are used for a query.
Identifying opportunities
To maximize the benefits of aggregate awareness, you should identify where aggregate awareness can play a role in optimization or in driving the value of aggregate awareness.
Identify dashboards with a high runtime
One great opportunity for aggregate awareness is to create aggregate tables for heavily used dashboards with a very high runtime. You may hear from your users about slow dashboards, but if you have see_system_activity, you can also use Looker's System Activity History Explore to find dashboards with slower than average runtime. As a shortcut, you can use the following URL in a browser, replacing the HOSTNAME with your Looker instance's name (such as example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
You'll see an Explore visualization with data about your instance's dashboards, including Title, History, Count of Explores, Ration from Cache vs. Database, and Is Performing Worse than Mean:
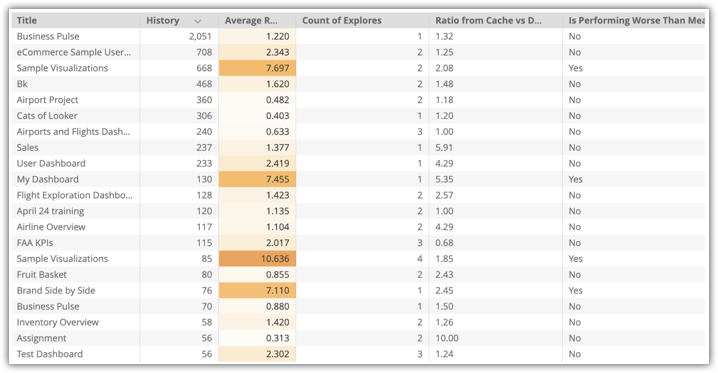
In this example, there are a number of dashboards with high utilization that perform worse than the mean, such as the Sample Visualizations dashboard. The Sample Visualizations dashboard uses two Explores, so a good strategy would be to create aggregate tables for both of these Explores.
Identify Explores that are slow and heavily queried by users
Another opportunity for aggregate awareness is with Explores that are heavily queried by users and have lower-than-average query response.
You can use the System Activity History Explore as a starting point for identifying opportunities for optimizing Explores. As a shortcut, you can use the following URL in a browser, replacing the HOSTNAME with your Looker instance's name (such as example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
You'll see an Explore visualization with data about your instance's Explores, including Explore, Model, Query Run Count, User Count, and Average Runtime in Seconds:

In the History Explore, you can identify the following types of Explores on your instance:
- Explores that are queried by users (as opposed to queries from the API or queries from scheduled deliveries)
- Explores that are queried often
- Explores that are performing poorly (relative to other Explores)
In the previous System Activity History Explore example, the flights and order_items Explores are probable candidates for aggregate awareness implementation.
Identify fields that are heavily used in queries
Finally, you can identify other opportunities at the data level by understanding fields that users commonly include in queries and filters.
As a shortcut, you can use the following URL in a browser, replacing the HOSTNAME with your Looker instance's name (such as example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Replace filters accordingly. You'll see an Explore with a bar graph visualization that indicates the number of times that a field has been used in a query:
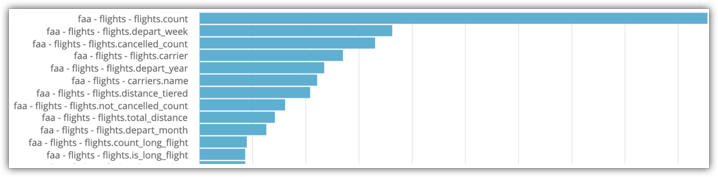
In the example System Activity Explore shown in the image, you can see that flights.count and flights.depart_week are the two most commonly selected fields for the Explore. Therefore, those fields are good candidates for fields to include in aggregate tables.
Concrete data like this is helpful, but there are subjective elements that will guide your selection criteria. For example, by looking at the previous four fields, you can safely assume that users commonly look at the number of scheduled flights and the number of flights that were canceled and that they want to break that data down both by week and by carrier. This is an example of a clear, logical, real-world combination of fields and metrics.
Summary
The steps on this documentation page should serve as a guide for finding dashboards, Explores, and fields that need to be considered for optimization. It's also worth understanding that all three may be mutually exclusive: the problematic dashboards may not be powered by the problematic Explores, and building aggregate tables with the commonly used fields may not help those dashboards at all. It is possible these are three discrete aggregate awareness implementations.
Designing aggregate tables
After you identify opportunities for aggregate awareness, you can design aggregate tables that will best address these opportunities. See the Aggregate awareness documentation page for information on the fields, measures, and timeframes supported in aggregate tables, as well as other guidelines for designing aggregate tables.
NOTE: Aggregate tables do not need to be an exact match for your query to be used. If your query is at the week granularity and you have a daily roll-up table, Looker will use your aggregate table instead of your raw, timestamp-level table. Similarly, if you have an aggregate table rolled up to thebrandanddatelevel and a user queries at thebrandlevel only, that table is still a candidate to be used by Looker for aggregate awareness.
Aggregate awareness is supported for the following measures:
- Standard measures: Measures of type SUM, COUNT, AVERAGE, MIN, and MAX
- Composite measures: Measures of type NUMBER, STRING, YESNO, and DATE
- Approximate distinct measures: Dialects that can use HyperLogLog functionality
Aggregate awareness is not supported for the following measures:
- Distinct measures: Because distinctness can be calculated only on atomic, non-aggregated data,
*_DISTINCTmeasures are not supported outside of these approximates that use HyperLogLog. - Cardinality-based measures: As with distinct measures, medians and percentiles cannot be pre-aggregated and are not supported.
NOTE: If you know of a potential user query with measure types that are not supported by aggregate awareness, this is a case where you may want to create an aggregate table that is an exact match of a query. An aggregate table that is an exact match of the query can be used to answer a query with measure types that would otherwise be unsupported for aggregate awareness.
Aggregate table granularity
Before building tables for combinations of dimensions and measures, you should determine common patterns of usage and field selection to make aggregate tables that will be used as often as possible with the biggest impact. Note that all fields used in the query (whether selected or filtered) must be in the aggregate table in order for the table to be used for the query. But, as noted previously, the aggregate table does not have to be an exact match for a query to by used for the query. You can address many potential user queries within a single aggregate table and still see large performance gains.
From the example of identifying fields that are heavily used in queries, there are two dimensions, (flights.depart_week and flights.carrier), that are selected very frequently, as well as two measures, (flights.count and flights.cancelled_count). Therefore, it would be logical to build an aggregate table that uses all four of these fields. In addition, creating a single aggregate table for flights_by_week_and_carrier will result in more frequent aggregate table usage than two different aggregate tables for flights_by_week and flights_by_carrier tables.
Here is an example aggregate table we might create for queries on the common fields:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Your business users and anecdotal evidence as well as data from Looker's System Activity can help guide your decision-making process.
Balancing applicability and performance
The following example shows an Explore query of the fields Flights Depart Week, Flights Details Carrier, Flights Count, and Flights Detailed Cancelled Count from the flights_by_week_and_carrier aggregate table:
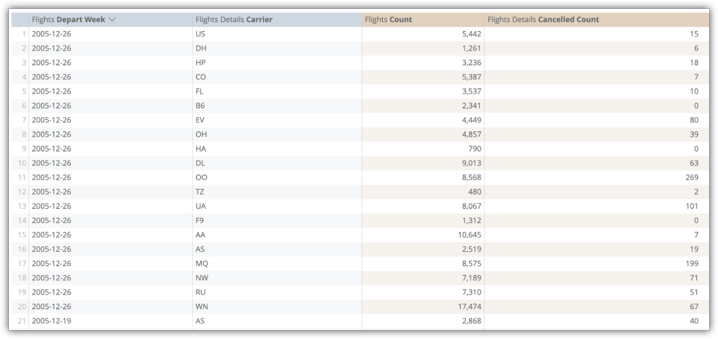
Running this query from the original database table took 15.8 seconds and scanned 38 million rows without any joins using Amazon Redshift. Pivoting the query, which would be a normal user operation, took 29.5 seconds.
After implementing the flights_by_week_and_carrier aggregate table, the subsequent query took 7.2 seconds and scanned 4592 rows . This is a 99.98% reduction in table size. Pivoting the query took 9.8 seconds.
From the System Activity Field Usage Explore, we can see how often our users include these fields in queries. In this example, flights.count was used 47,848 times, flights.depart_week was used 18,169 times, flights.cancelled_count was used 16,570 times, and flights.carrier was used 13,517 times.

Even if we very modestly estimated that 25% of these queries used all 4 fields in the simplest fashion (simple select, no pivot), 3379 x 8.6 seconds = 8 hours, 4 minutes in aggregate user wait time eliminated.
NOTE: The example model used here is very basic. These results should not be used as a benchmark or frame of reference for your model.
After applying the exact same flow to our ecommerce model order_items — the most frequently used Explore on the instance ‐ the results are as follows:
| Source | Query Time | Rows Scanned |
|---|---|---|
| Base Table | 13.1 seconds | 285,000 |
| Aggregate Table | 5.1 seconds | 138,000 |
| Delta | 8 seconds | 147,000 |
The fields used in the query and subsequent aggregate table were brand, created_date, orders_count, and total_revenue, using two joins. The fields had been used a total of 11,000 times. Estimating the same combined usage of ~25%, the aggregate saving for users would be 6 hours, 6 minutes (8s * 2750 = 22000s). The aggregate table took 17.9 seconds to build.
Looking at these results, it's worth taking a moment to step back and assess the returns potentially gained from:
- Optimizing larger, more complex models/Explores that have "acceptable" performance and may see performance improvements from better modeling practices
versus
- Using aggregate awareness to optimize simpler models that are used more frequently and are performing poorly
You will see diminishing returns for your efforts as you try to get the last bit of performance from Looker and your database. You should always be cognizant of the baseline performance expectations, particularly from business users, and the limitations imposed by your database (such as concurrency, query thresholds, cost, and so on). You shouldn't expect aggregate awareness to overcome these limitations.
Also, when designing an aggregate table, remember that having more fields will result in a bigger, slower aggregate table. Bigger tables can optimize more queries and therefore be used in more situations, but large tables won't be as fast as smaller, more simple tables.
For example:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}This will result in the aggregate table being used for any combination of dimension shown and for any of the measures included, so this table can be used to answer many different user queries. But to use this table for a simple SELECT of carrier and count query would require a scan of an 885,000-row table. In contrast, the same query would only require a scan of 4,592 rows if the table was based on two dimensions. The 885K-row table is still a 97% reduction in table size (from the previous 38M rows); but adding one more dimension increases the table size to 20M rows. As such, there are diminishing returns as you include more fields in your aggregate table to increase its applicability to more queries.
Building aggregate tables
Taking our example Flights Explore that we identified as an opportunity to optimize, the best strategy would be to build three different aggregate tables for it:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
The easiest way to build these aggregate tables is to get the aggregate table LookML from an Explore query or from a dashboard and add the LookML to your Looker project files.
Once you add the aggregate tables to your LookML project and deploy the updates to production, your Explores will leverage the aggregate tables for your users' queries.
Persistence
To be accessible for aggregate awareness, aggregate tables must be persisted in your database. It is best practice to align the automatic regeneration of these aggregate tables with your caching policy by leveraging datagroups. You should use the same datagroup for an aggregate table that is used for the associated Explore. If you can't use datagroups, an alternative option is to use the sql_trigger_value parameter instead. The following shows a generic, date-based value for sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
This will build your aggregate tables automatically at midnight every day.
Timeframe logic
When Looker builds an aggregate table, it will include data up to the point in time the aggregate table was built. Any data that has been subsequently appended to the base table in the database would normally be excluded from the results of a query using that aggregate table.
This diagram shows the timeline of when orders were received and logged in the database compared to the the point in time that the Orders aggregate table was built. There are two orders received today that will not be present in the Orders aggregate table, since the orders were received after the aggregate table was built:
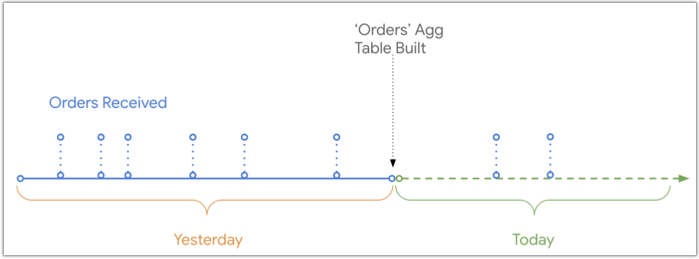
But Looker can UNION fresh data to the aggregate table when a user queries for a timeframe that overlaps with the aggregate table, as depicted in the same timeline diagram:
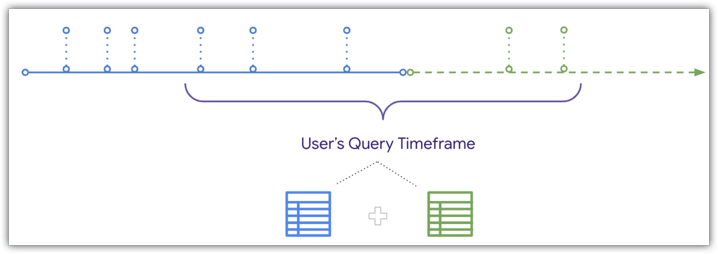
Because Looker can UNION fresh data to an aggregate table, if a user filters for a timeframe that overlaps with the end of both the aggregate and the base table, the orders received after the aggregate table was built will be included in the user's results. See the Aggregate awareness documentation page for details and the conditions that need to be met to union fresh data to aggregate table queries.
Summary
To recap, to build an aggregate awareness implementation, there are three fundamental steps:
- Identify opportunities where optimization using aggregate tables is appropriate and impactful.
- Design aggregate tables that will provide the most coverage for common user queries while still remaining small enough to reduce the size of those queries sufficiently.
- Build the aggregate tables in the Looker model, pairing the persistence of the table with the persistence of the Explore cache.