In Looker, a derived table is a query whose results are used as if the query were an actual table in the database.
For example, you might have a database table called orders that has many columns. You want to compute some customer-level aggregate metrics, such as how many orders each customer has placed or when each customer placed their first order. Using either a native derived table or a SQL-based derived table, you can create a new database table named customer_order_summary that includes these metrics.
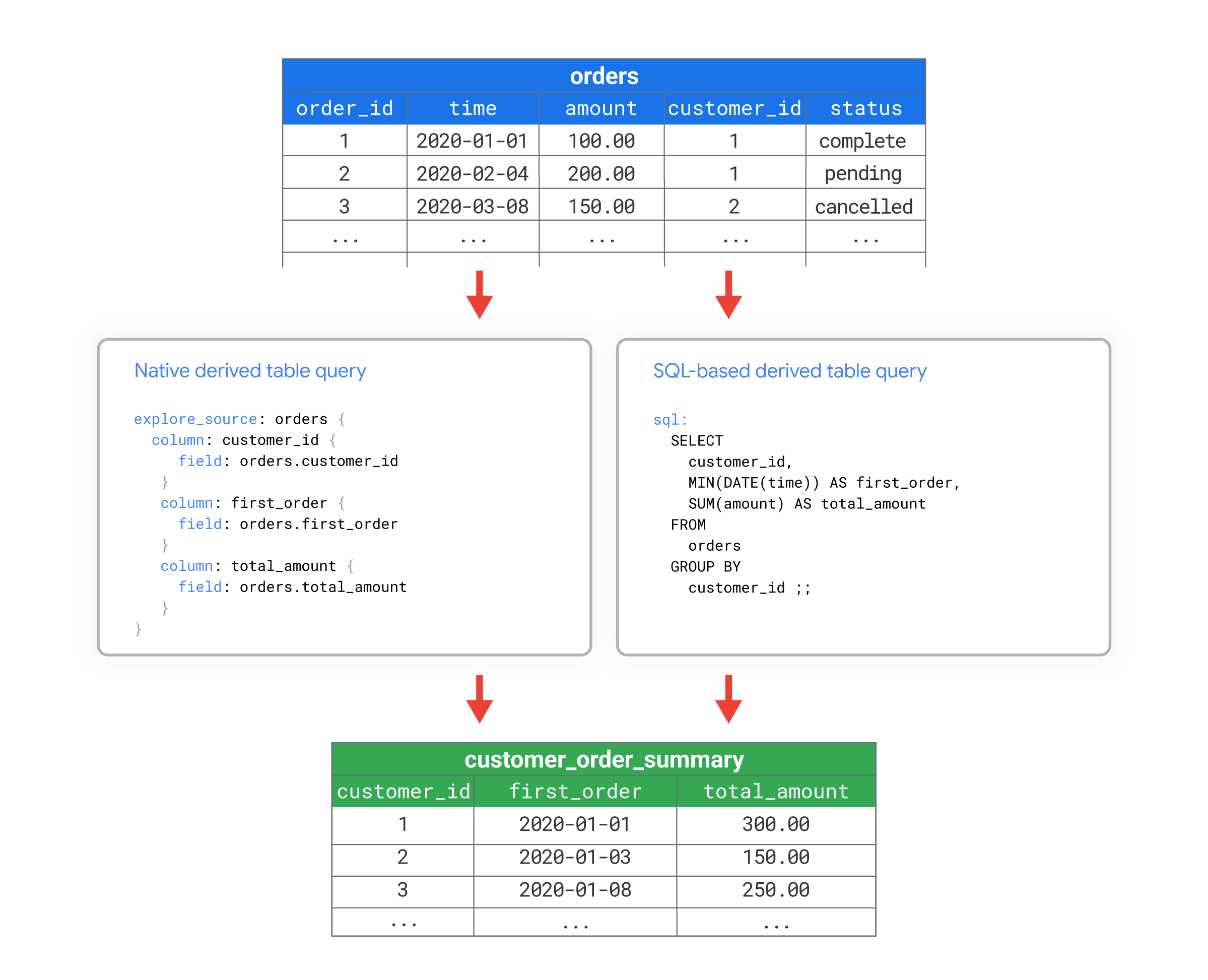
You can then work with the customer_order_summary derived table as if it were any other table in the database.
For popular use cases of derived tables, visit Looker cookbooks: Getting the most out of derived tables in Looker.
Native derived tables and SQL-based derived tables
To create a derived table in your Looker project, use the derived_table parameter under a view parameter. Inside the derived_table parameter, you can define the query for the derived table in one of two ways:
- For a native derived table, you define the derived table with a LookML-based query.
- For a SQL-based derived table, you define the derived table with a SQL query.
For example, the following view files show how you could use LookML to create a view from a customer_order_summary derived table. The two versions of the LookML illustrate how you can create equivalent derived tables using either LookML or SQL to define the query for the derived table:
- The native derived table defines the query with LookML in the
explore_sourceparameter. In this example, the query is based on an existingordersview, which is defined in a separate file that is not shown in this example. Theexplore_sourcequery in the native derived table brings in thecustomer_id,first_order, andtotal_amountfields from theordersview file. - The SQL-based derived table defines the query using SQL in the
sqlparameter. In this example, the SQL query is a direct query of theorderstable in the database.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
Both versions create a view called customer_order_summary that is based on the orders table, with the columns customer_id, first_order, and total_amount.
Other than the derived_table parameter and its subparameters, this customer_order_summary view works just like any other view file. Whether you define the derived table's query with LookML or with SQL, you can create LookML measures and dimensions that are based on the columns of the derived table.
Once you define your derived table, you can use it like any other table in your database.
Native derived tables
Native derived tables are based on queries that you define using LookML terms. To create a native derived table, you use the explore_source parameter inside the derived_table parameter of a view parameter. You create the columns of your native derived table by referring to the LookML dimensions or measures in your model. See the native derived table view file in the previous example.
Compared to SQL-based derived tables, native derived tables are much easier to read and understand as you model your data.
See the Creating native derived tables documentation page for details on creating native derived tables.
SQL-based derived tables
To create a SQL-based derived table, you define a query in SQL terms, creating columns in the table using a SQL query. You cannot refer to LookML dimensions and measures in a SQL-based derived table. See the SQL-based derived table view file in the previous example.
Most commonly, you define the SQL query using the sql parameter inside the derived_table parameter of a view parameter.
A helpful shortcut for creating SQL-based queries in Looker is to use SQL Runner to create the SQL query and turn it into a derived table definition.
Certain edge cases won't permit the use of the sql parameter. In such cases, Looker supports the following parameters for defining a SQL query for persistent derived tables (PDTs):
create_process: When you use thesqlparameter for a PDT, in the background Looker wraps the dialect'sCREATE TABLEData Definition Language (DDL) statement around your query to create the PDT from your SQL query. Some dialects don't support a SQLCREATE TABLEstatement in a single step. For these dialects, you cannot create a PDT with thesqlparameter. Instead, you can use thecreate_processparameter to create a PDT in multiple steps. See thecreate_processparameter documentation page for information and examples.sql_create: If your use case requires custom DDL commands and your dialect supports DDL (for example, the Google predictive BigQuery ML), you can use thesql_createparameter to create a PDT instead of using thesqlparameter. See thesql_createdocumentation page for information and examples.
Whether you are using the sql, create_process, or sql_create parameter, in all these cases you are defining the derived table with a SQL query, so these are all considered SQL-based derived tables.
When you define a SQL-based derived table, make sure to give each column a clean alias by using AS. This is because you will need to reference the column names of your result set in your dimensions, such as ${TABLE}.first_order. This is why the previous example uses MIN(DATE(time)) AS first_order instead of just MIN(DATE(time)).
Temporary and persistent derived tables
In addition to the distinction between native derived tables and SQL-based derived tables, there is also a distinction between a temporary derived table — which is not written to the database — and a persistent derived table (PDT) — which is written to a schema on your database.
Native derived tables and SQL-based derived tables can be either temporary or persistent.
Temporary derived tables
The derived tables shown previously are examples of temporary derived tables. They are temporary because there is no persistence strategy defined in the derived_table parameter.
Temporary derived tables are not written to the database. When a user runs an Explore query that involves one or more derived tables, Looker constructs a SQL query by using a dialect-specific combination of the SQL for the derived table(s) plus the requested fields, joins, and filter values. If the combination has been run before and the results are still valid in the cache, Looker uses the cached results. See the Caching queries documentation page for more information on query caching in Looker.
Otherwise, if Looker can't use cached results, Looker must run a new query on your database every time a user requests data from a temporary derived table. Because of this, you should be sure that your temporary derived tables are performant and won't put excessive strain on your database. In cases where the query will take some time to run, a PDT is often a better option.
Supported database dialects for temporary derived tables
For Looker to support derived tables in your Looker project, your database dialect must also support them. The following table shows which dialects support derived tables in the latest release of Looker:
Click here to display the table.
| Dialect | Supported? |
|---|---|
| Actian Avalanche | Yes |
| Amazon Athena | Yes |
| Amazon Aurora MySQL | Yes |
| Amazon Redshift | Yes |
| Amazon Redshift 2.1+ | Yes |
| Amazon Redshift Serverless 2.1+ | Yes |
| Apache Druid | Yes |
| Apache Druid 0.13+ | Yes |
| Apache Druid 0.18+ | Yes |
| Apache Hive 2.3+ | Yes |
| Apache Hive 3.1.2+ | Yes |
| Apache Spark 3+ | Yes |
| ClickHouse | Yes |
| Cloudera Impala 3.1+ | Yes |
| Cloudera Impala 3.1+ with Native Driver | Yes |
| Cloudera Impala with Native Driver | Yes |
| DataVirtuality | Yes |
| Databricks | Yes |
| Denodo 7 | Yes |
| Denodo 8 & 9 | Yes |
| Dremio | Yes |
| Dremio 11+ | Yes |
| Exasol | Yes |
| Google BigQuery Legacy SQL | Yes |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | Yes |
| Google Spanner | Yes |
| Greenplum | Yes |
| HyperSQL | Yes |
| IBM Netezza | Yes |
| MariaDB | Yes |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | Yes |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | Yes |
| Microsoft SQL Server 2012+ | Yes |
| Microsoft SQL Server 2016 | Yes |
| Microsoft SQL Server 2017+ | Yes |
| MongoBI | Yes |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | Yes |
| Oracle ADWC | Yes |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | Yes |
| PrestoSQL | Yes |
| SAP HANA | Yes |
| SAP HANA 2+ | Yes |
| SingleStore | Yes |
| SingleStore 7+ | Yes |
| Snowflake | Yes |
| Teradata | Yes |
| Trino | Yes |
| Vector | Yes |
| Vertica | Yes |
Persistent derived tables
A persistent derived table (PDT) is a derived table that is written into a scratch schema on your database and regenerated on the schedule that you specify with a persistence strategy.
A PDT can be either a native derived table or a SQL-based derived table.
Requirements for PDTs
To use persistent derived tables (PDTs) in your Looker project, you need the following:
- A database dialect that supports PDTs. See the Supported database dialects for PDTs section later on this page for the lists of dialects that support persistent SQL-based derived tables and persistent native derived tables.
A scratch schema on your database. This can be any schema on your database, but we recommend creating a new schema that will be used only for this purpose. Your database administrator must configure the schema with write permission for the Looker database user.
A Looker connection that is configured with the Enable PDTs toggle turned on. This Enable PDTs setting is usually configured when you initially set up your Looker connection (see the Looker dialects documentation page for instructions for your database dialect), but you can also enable PDTs for your connection after the initial setup.
Supported database dialects for PDTs
For Looker to support PDTs in your Looker project, your database dialect must also support them.
To support any type of PDTs (either LookML-based or SQL-based), the dialect must support writes to the database, among other requirements. There are some read-only database configurations that don't allow persistence to work (most commonly Postgres hot-swap replica databases). In these cases, you can use temporary derived tables instead.
The following table shows the dialects that support persistent SQL-based derived tables in the latest release of Looker:
Click here to display the table.
| Dialect | Supported? |
|---|---|
| Actian Avalanche | Yes |
| Amazon Athena | Yes |
| Amazon Aurora MySQL | Yes |
| Amazon Redshift | Yes |
| Amazon Redshift 2.1+ | Yes |
| Amazon Redshift Serverless 2.1+ | Yes |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Yes |
| Apache Hive 3.1.2+ | Yes |
| Apache Spark 3+ | Yes |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Yes |
| Cloudera Impala 3.1+ with Native Driver | Yes |
| Cloudera Impala with Native Driver | Yes |
| DataVirtuality | No |
| Databricks | Yes |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Yes |
| Google BigQuery Legacy SQL | Yes |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | Yes |
| Google Spanner | No |
| Greenplum | Yes |
| HyperSQL | No |
| IBM Netezza | Yes |
| MariaDB | Yes |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | Yes |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | Yes |
| Microsoft SQL Server 2012+ | Yes |
| Microsoft SQL Server 2016 | Yes |
| Microsoft SQL Server 2017+ | Yes |
| MongoBI | No |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | Yes |
| Oracle ADWC | Yes |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | Yes |
| PrestoSQL | Yes |
| SAP HANA | Yes |
| SAP HANA 2+ | Yes |
| SingleStore | Yes |
| SingleStore 7+ | Yes |
| Snowflake | Yes |
| Teradata | Yes |
| Trino | Yes |
| Vector | Yes |
| Vertica | Yes |
To support persistent native derived tables (which have LookML-based queries), the dialect must also support a CREATE TABLE DDL function. Here is a list of the dialects that support persistent native (LookML-based) derived tables in the latest release of Looker:
Click here to display the table.
| Dialect | Supported? |
|---|---|
| Actian Avalanche | Yes |
| Amazon Athena | Yes |
| Amazon Aurora MySQL | Yes |
| Amazon Redshift | Yes |
| Amazon Redshift 2.1+ | Yes |
| Amazon Redshift Serverless 2.1+ | Yes |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Yes |
| Apache Hive 3.1.2+ | Yes |
| Apache Spark 3+ | Yes |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Yes |
| Cloudera Impala 3.1+ with Native Driver | Yes |
| Cloudera Impala with Native Driver | Yes |
| DataVirtuality | No |
| Databricks | Yes |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Yes |
| Google BigQuery Legacy SQL | Yes |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Yes |
| HyperSQL | No |
| IBM Netezza | Yes |
| MariaDB | Yes |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | Yes |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | Yes |
| Microsoft SQL Server 2012+ | Yes |
| Microsoft SQL Server 2016 | Yes |
| Microsoft SQL Server 2017+ | Yes |
| MongoBI | No |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | Yes |
| Oracle ADWC | Yes |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | Yes |
| PrestoSQL | Yes |
| SAP HANA | Yes |
| SAP HANA 2+ | Yes |
| SingleStore | Yes |
| SingleStore 7+ | Yes |
| Snowflake | Yes |
| Teradata | Yes |
| Trino | Yes |
| Vector | Yes |
| Vertica | Yes |
Incrementally building PDTs
An incremental PDT is a persistent derived table that Looker builds by appending fresh data to the table instead of rebuilding it in its entirety.
If your dialect supports incremental PDTs, and your PDT uses a trigger-based persistence strategy (datagroup_trigger, sql_trigger_value, or interval_trigger), you can define the PDT as an incremental PDT.
See the Incremental PDTs documentation page for more information.
Supported database dialects for incremental PDTs
For Looker to support incremental PDTs in your Looker project, your database dialect must also support them. The following table shows which dialects support incremental PDTs in the latest release of Looker:
Click here to display the table.
| Dialect | Supported? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Yes |
| Amazon Redshift 2.1+ | Yes |
| Amazon Redshift Serverless 2.1+ | Yes |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Yes |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Yes |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Yes |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Yes |
Creating PDTs
To make a derived table into a persistent derived table (PDT), you define a persistence strategy for the table. To optimize performance, you should also add an optimization strategy.
Persistence strategies
The persistence of a derived table can be managed by Looker or, for dialects that support materialized views, by your database using materialized views.
To make a derived table persistent, add one of the following parameters to the derived_table definition:
- Looker-managed persistence parameters:
- Database-managed persistence parameters:
With trigger-based persistence strategies (datagroup_trigger, sql_trigger_value, and interval_trigger), Looker maintains the PDT in the database until the PDT is triggered for rebuild. When the PDT is triggered, Looker rebuilds the PDT to replace the previous version. This means that, with trigger-based PDTs, your users won't have to wait for the PDT to be built in order to get answers for Explore queries from the PDT.
datagroup_trigger
Datagroups are the most flexible method of creating persistence. If you have defined a datagroup with sql_trigger or interval_trigger, you can use the datagroup_trigger parameter to initiate the rebuilding of your persistent derived tables (PDTs).
Looker maintains the PDT in the database until its datagroup is triggered. When the datagroup is triggered, Looker rebuilds the PDT to replace the previous version. This means that, in most cases, your users won't have to wait for the PDT to be built. If a user requests data from the PDT while it is being built and the query results aren't in the cache, Looker will return data from the existing PDT until the new PDT is built. See Caching queries for an overview of datagroups.
See the section on The Looker regenerator for more information on how the regenerator builds PDTs.
sql_trigger_value
The sql_trigger_value parameter triggers the regeneration of a persistent derived table (PDT) that is based on a SQL statement that you provide. If the result of the SQL statement is different from the previous value, the PDT is regenerated. Otherwise, the existing PDT is maintained in the database. This means that, in most cases, your users won't have to wait for the PDT to be built. If a user requests data from the PDT while it is being built, and the query results aren't in the cache, Looker will return data from the existing PDT until the new PDT is built.
See the section on The Looker regenerator for more information on how the regenerator builds PDTs.
interval_trigger
The interval_trigger parameter triggers the regeneration of a persistent derived table (PDT) based on a time interval that you provide, such as "24 hours" or "60 minutes". Similar to the sql_trigger parameter, this means that usually the PDT will be prebuilt when your users query it. If a user requests data from the PDT while it is being built, and the query results aren't in the cache, Looker will return data from the existing PDT until the new PDT is built.
persist_for
Yet another option is to use the persist_for parameter to set the length of time the derived table should be stored before it is marked as expired, so that it is no longer used for queries and will be dropped from the database.
A persist_for persistent derived table (PDT) is built when a user first runs a query on it. Looker then maintains the PDT in the database for the length of time that is specified in the PDT's persist_for parameter. If a user queries the PDT within the persist_for time, Looker uses cached results if possible or else runs the query on the PDT.
After the persist_for time, Looker clears the PDT from your database, and the PDT will be rebuilt the next time a user queries it, which means that the query will need to wait for the rebuild.
PDTs that use persist_for aren't automatically rebuilt by the Looker regenerator, except in the case of a dependency cascade of PDTs. When a persist_for table is part of a dependency cascade with trigger-based PDTs (PDTs that use the datagroup_trigger, interval_trigger, or sql_trigger_value persistence strategy), the regenerator will monitor and rebuild the persist_for table in order to rebuild other tables in the cascade. See the How Looker builds cascading derived tables section on this page.
materialized_view: yes
Materialized views allow you to use your database's functionality to persist derived tables in your Looker project. If your database dialect supports materialized views and your Looker connection is configured with the Enable PDTs toggle turned on, you can create a materialized view by specifying materialized_view: yes for a derived table. Materialized views are supported for both native derived tables and SQL-based derived tables.
Similar to a persistent derived table (PDT), a materialized view is a query result that is stored as a table in the scratch schema of your database. The key difference between a PDT and a materialized view is in how tables are refreshed:
- For PDTs, the persistence strategy is defined in Looker, and the persistence is managed by Looker.
- For materialized views, the database is responsible for maintaining and refreshing the data in the table.
For this reason, the materialized view functionality requires advanced knowledge of your dialect and its features. In most cases, your database will refresh the materialized view any time the database detects new data in the tables that are queried by the materialized view. Materialized views are optimal for scenarios that require real-time data.
See the materialized_view parameter documentation page for information on dialect support, requirements, and important considerations.
Optimization strategies
Because persistent derived tables (PDTs) are stored in your database, you should optimize your PDTs using the following strategies, as supported by your dialect:
For example, to add persistence to the derived table example, you could set it to rebuild when the datagroup orders_datagroup triggers, and add indexes on both customer_id and first_order, like this:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
If you don't add an index (or an equivalent for your dialect), Looker will warn you that you should do so to improve query performance.
Use cases for PDTs
Persistent derived tables (PDTs) are useful because they can improve performance of a query by persisting the results of the query in a table.
As a general best practice, developers should try to model data without using PDTs until absolutely necessary.
In some cases data can be optimized through other means. For example, adding an index or changing a column's data type might resolve an issue without the need to create a PDT. Make sure to analyze the execution plans of slow queries using the Explain from SQL Runner tool.
In addition to reducing query time and database load on frequently run queries, there are several other use cases for PDTs including:
You can also use a PDT to define a primary key in cases where there is no reasonable way to identify a unique row in a table as a primary key.
Using PDTs to test optimizations
You can use PDTs to test different indexing, distributions, and other optimization options without needing a large amount of support from your DBA or ETL developers.
Consider a case where you have a table but want to test different indexes. Your initial LookML for the view may look like the following:
view: customer {
sql_table_name: warehouse.customer ;;
}
To test optimization strategies, you can use the indexes parameter to add indexes to the LookML like this:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Query the view once to generate the PDT. Then run your test queries and compare your results. If your results are favorable, you can ask your DBA or ETL team to add the indexes to the original table.
Remember to change your view code back to remove the PDT.
Using PDTs to pre-join or aggregate data
It can be useful to pre-join or pre-aggregate data to adjust query optimization for high volumes or multiple types of data.
For example, suppose you want to create a query for customers by cohort based on when they made their first order. This query might be expensive to run multiple times whenever the data is needed in real time; however, you can calculate the query only once and then reuse the results with a PDT:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Cascading derived tables
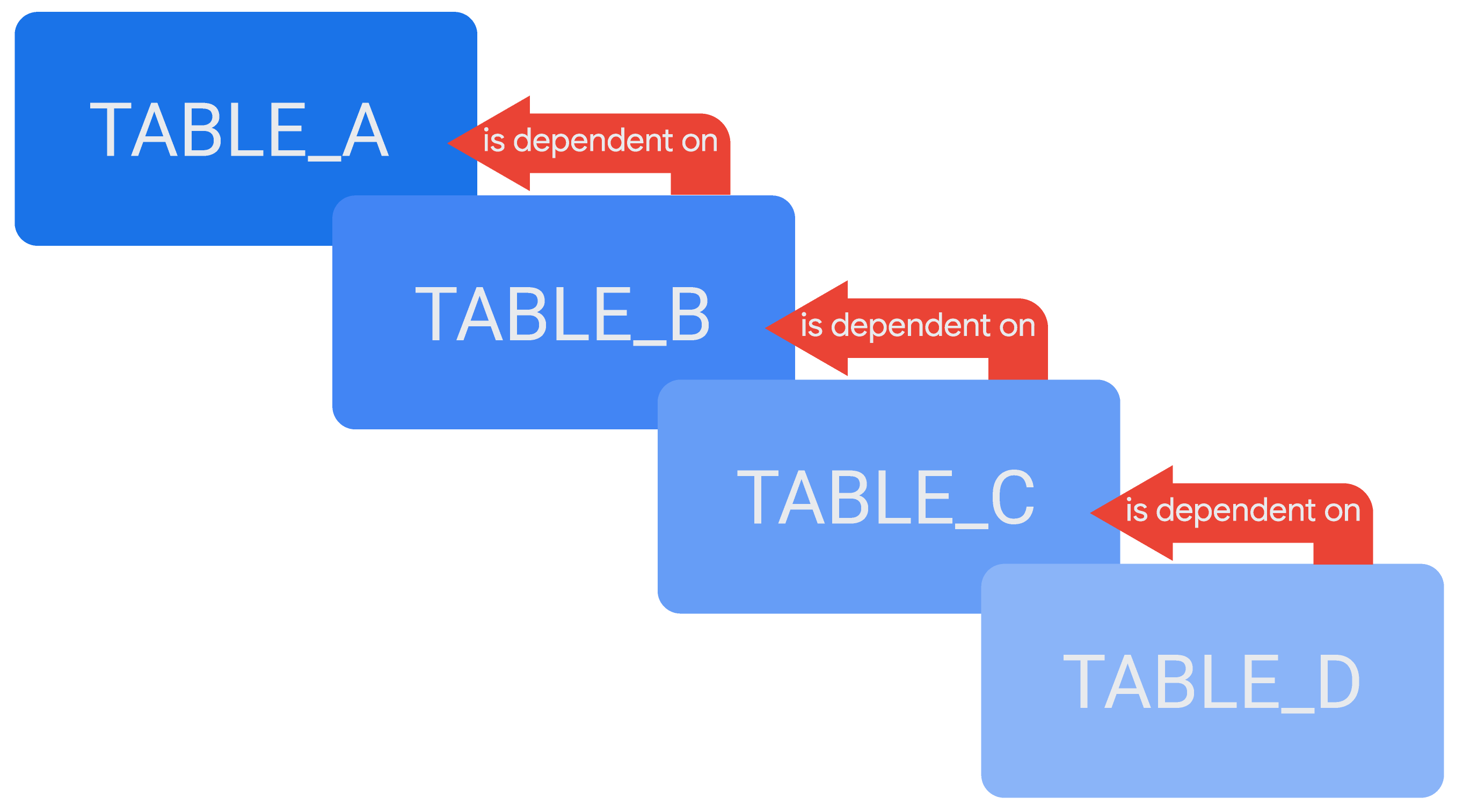
It is possible to reference one derived table in the definition of another, creating a chain of cascading derived tables, or cascading persistent derived tables (PDTs), as the case may be. An example of cascading derived tables would be a table, TABLE_D, which depends on another table, TABLE_C, while TABLE_C depends on TABLE_B, and TABLE_B depends on TABLE_A.
Syntax for referencing a derived table
To reference a derived table in another derived table, use this syntax:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
In this format, SQL_TABLE_NAME is a literal string. For example, you can reference the clean_events derived table with this syntax:
`${clean_events.SQL_TABLE_NAME}`
You can use this same syntax to refer to a LookML view. Again, in this case, the SQL_TABLE_NAME is a literal string.
In the next example, the clean_events PDT is created from the events table in the database. The clean_events PDT leaves out unwanted rows from the events database table. Then a second PDT is shown; the event_summary PDT is a summary of the clean_events PDT. The event_summary table regenerates whenever new rows are added to clean_events.
The event_summary PDT and the clean_events PDT are cascading PDTs, where event_summary is dependent on clean_events (since event_summary is defined using the clean_events PDT). This particular example could be done more efficiently in a single PDT, but it's useful for demonstrating derived table references.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Although it's not always required, when you're referring to a derived table in this manner, it's often useful to create an alias for the table by using this format:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
The previous example does this:
${clean_events.SQL_TABLE_NAME} AS clean_events
It is helpful to use an alias because, behind the scenes, PDTs are named with lengthy codes in your database. In some cases (especially with ON clauses) it's possible to forget that you need to use the ${derived_table_or_view_name.SQL_TABLE_NAME} syntax to retrieve this lengthy name. An alias can help to prevent this type of mistake.
How Looker builds cascading derived tables
In the case of cascading temporary derived tables, if a user's query results aren't in the cache, Looker will build all the derived tables that are needed for the query. If you have a TABLE_D whose definition contains a reference to TABLE_C, then TABLE_D is dependent on TABLE_C. This means that if you query TABLE_D and the query is not in Looker's cache, Looker will rebuild TABLE_D. But first, it must rebuild TABLE_C.
Consider a scenario with cascading temporary derived tables, where TABLE_D is dependent on TABLE_C, which is dependent on TABLE_B, which is dependent on TABLE_A. If Looker doesn't have valid results for a query on TABLE_C in the cache, Looker will build all the tables it needs for the query. So Looker will build TABLE_A, and then TABLE_B, and then TABLE_C:
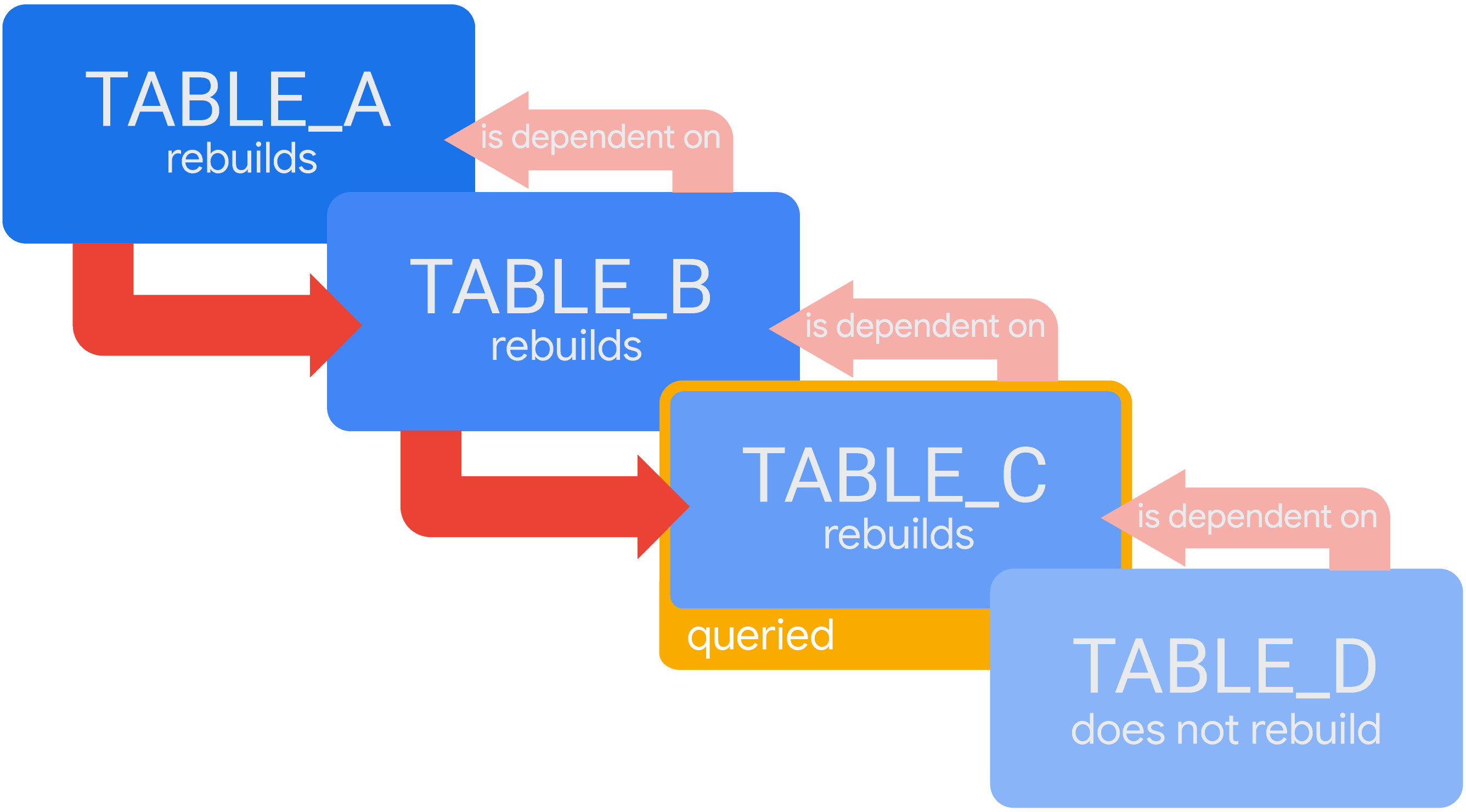
In this scenario, TABLE_A must finish generating before Looker can start generating TABLE_B, and TABLE_B must finish generating before Looker can start generating TABLE_C. When TABLE_C is finished, Looker will provide the query results. (Since TABLE_D isn't needed to answer this query, Looker won't rebuild TABLE_D at this time.)
See the datagroup parameter documentation page for an example scenario of cascading PDTs that use the same datagroup.
The same basic logic applies for PDTs: Looker will build any table that is required to answer a query, all the way up the chain of dependencies. But with PDTs, it is often the case that the tables already exist and don't need to be rebuilt. With standard user queries on cascading PDTs, Looker rebuilds the PDTs in the cascade only if there's no valid version of the PDTs in the database. If you want to force a rebuild for all PDTs in a cascade, you can manually rebuild the tables for a query through an Explore.
An important logical point to understand is that in the case of a PDT cascade, a dependent PDT is essentially querying the PDT it depends on. This is significant especially for PDTs that use the persist_for strategy. Typically, persist_for PDTs are built when a user queries them, remain in the database until their persist_for interval is up, and then are not rebuilt until they are next queried by a user. However, if a persist_for PDT is part of a cascade with trigger-based PDTs (PDTs that use the datagroup_trigger, interval_trigger, or sql_trigger_value persistence strategy), the persist_for PDT is essentially being queried whenever its dependent PDTs are rebuilt. So, in this case, the persist_for PDT will be rebuilt on the schedule of its dependent PDTs. This means that persist_for PDTs can be affected by the persistence strategy of their dependents.
Manually rebuilding persistent tables for a query
Users can select the Rebuild Derived Tables & Run option from an Explore's menu to override the persistence settings and rebuild all the persistent derived tables (PDTs) and aggregate tables required for the current query in the Explore:
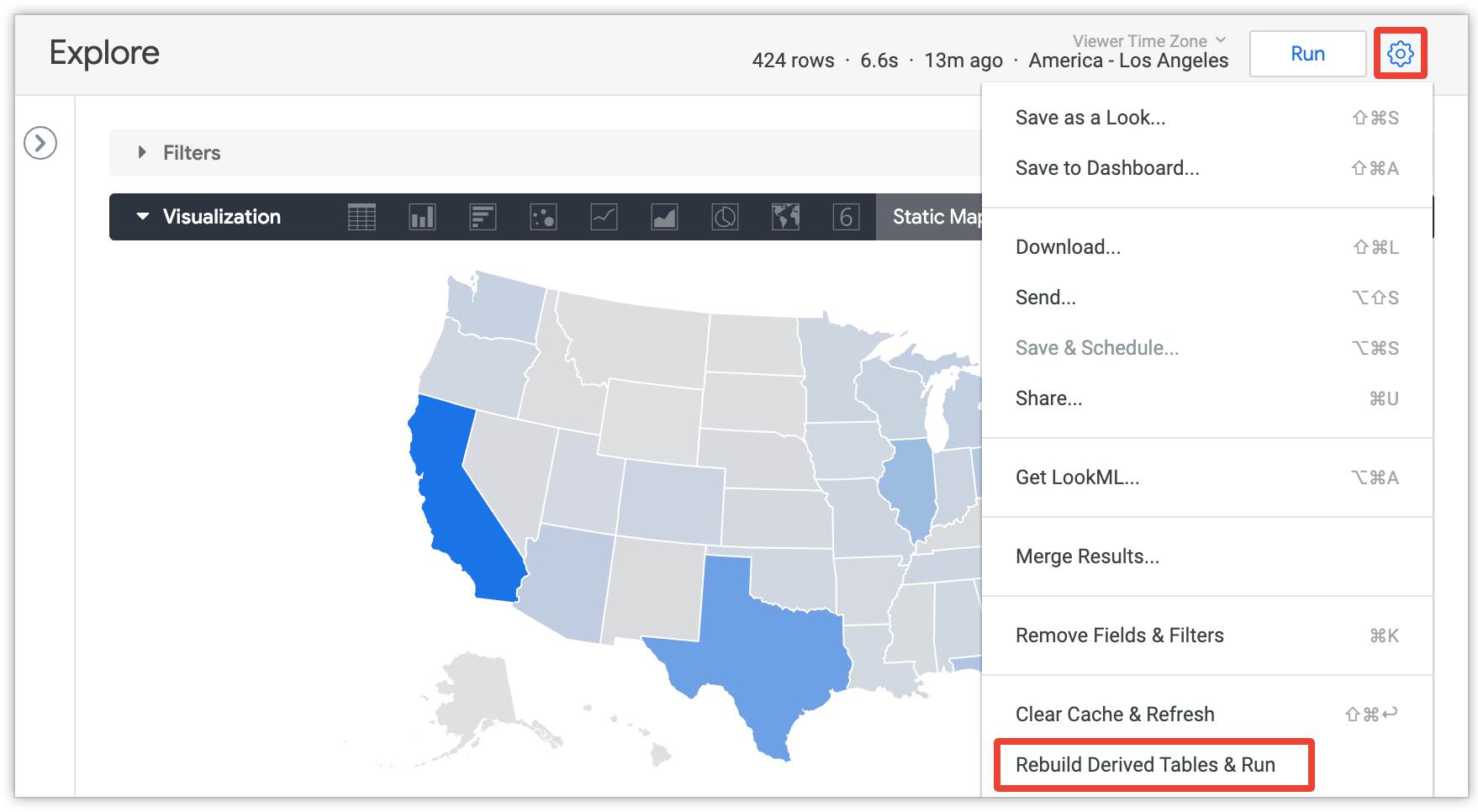
This option is visible only to users with develop permission, and only after the Explore query has loaded.
The Rebuild Derived Tables & Run option rebuilds all the persistent tables (all the PDTs and aggregate tables) that are required to answer the query, regardless of their persistence strategy. This includes any aggregate tables and PDTs in the current query, and it also includes any aggregate tables and PDTs that are referenced by the aggregate tables and PDTs in the current query.
In the case of incremental PDTs, the Rebuild Derived Tables & Run option triggers the build of a new increment. With incremental PDTs, an increment includes the time period specified in the increment_key parameter, and also the number of previous time periods specified in the increment_offset parameter, if any. See the Incremental PDTs documentation page for some example scenarios that show how incremental PDTs build, depending on their configuration.
In the case of cascading PDTs, this means rebuilding all the derived tables in the cascade, starting at the top. This is the same behavior as when you query a table in a cascade of temporary derived tables:
Note the following about manually rebuilding derived tables:
- For the user who initiates the Rebuild Derived Tables & Run operation, the query will wait for the tables to rebuild before loading results. Other users' queries will still use the existing tables. Once the persistent tables are rebuilt, then all users will use the rebuilt tables. Although this process is designed to avoid interrupting other users' queries while the tables are rebuilding, those users could still be affected by the additional load on your database. If you are in a situation where triggering a rebuild during business hours could put an unacceptable strain on your database, you may need to communicate to your users that they should never rebuild certain PDTs or aggregate tables during those hours.
If a user is in Development Mode and the Explore is based on a development table, the Rebuild Derived Tables & Run operation will rebuild the development table, not the production table, for the Explore. But if the Explore in Development Mode is using the production version of a derived table, the production table will be rebuilt. See Persisted tables in Development Mode for information on development tables and production tables.
For Looker-hosted instances, if the derived table takes longer than one hour to rebuild, the table won't rebuild successfully and the browser session will time out. See the Query timeouts and queueing section on the Admin settings - Queries documentation page for more information about timeouts that may affect Looker processes.
Persisted tables in Development Mode
Looker has some special behaviors for managing persisted tables in Development Mode.
If you query a persisted table in Development Mode without making any changes to its definition, Looker will query the production version of that table. If you do make a change to the table definition that affects the data in the table or the way that the table is queried, a new development version of the table will be created the next time you query the table in Development Mode. Having such a development table lets you test changes without disturbing users.
What prompts Looker to create a development table
When possible, Looker uses the existing production table to answer queries, whether or not you are in Development Mode. But there are certain cases where Looker cannot use the production table for queries in Development Mode:
- If your persisted table has a parameter that narrows its dataset to work faster in Development Mode
- If you have made changes to the definition of your persisted table that affect the data in the table
Looker will build a development table if you are in Development Mode and you query a SQL-based derived table that is defined using a conditional WHERE clause with if prod and if dev statements.
For persisted tables that don't have a parameter to narrow the dataset in Development Mode, Looker uses the production version of the table to answer queries in Development Mode, unless you change the definition of the table and then query the table in Development Mode. This goes for any changes to the table that affect the data in the table or the way that the table is queried.
Here are some examples of the types of changes that will prompt Looker to create a development version of a persistent table (Looker will create the table only if you subsequently query the table after making these changes):
- Changing the query that the persistent table is based on, such as modifying the
explore_source,sql,query,sql_create, orcreate_processparameter in the persistent table itself, or in any required table (in the case of cascading derived tables) - Changing the persistence strategy of the table, such as modifying the table's
datagroup_trigger,sql_trigger_value,interval_trigger, orpersist_forparameter - Changing the name of a derived table's
view - Changing the
increment_keyorincrement_offsetof an incremental PDT - Changing the
connectionthat is used by the associated model
For changes that don't modify the table's data or affect the way that Looker queries the table, Looker won't create a development table. The publish_as_db_view parameter is a good example: In Development Mode, if you change only the publish_as_db_view setting for a derived table, Looker doesn't need to rebuild the derived table so won't create a development table.
How long Looker persists development tables
Regardless of the table's actual persistence strategy, Looker treats development persisted tables as if they had a persistence strategy of persist_for: "24 hours". Looker does this to ensure that development tables aren't persisted for more than a day, since a Looker developer may query many iterations of a table during development, and each time a new development table is built. To prevent the development tables from cluttering the database, Looker applies the persist_for: "24 hours" strategy to be sure that the tables are frequently cleaned from the database.
Otherwise, Looker builds persistent derived tables (PDTs) and aggregate tables in Development Mode the same way it builds persisted tables in Production Mode.
If a development table is persisted on your database when you deploy changes to a PDT or an aggregate table, Looker can often use the development table as the production table so that your users don't have to wait for the table to build when they query the table.
Note that when you deploy your changes, the table may still need to be rebuilt to be queried in production, depending on the situation:
- If it has been over 24 hours since you queried the table in Development Mode, the development version of the table is tagged as expired and won't be used for queries. You can check for unbuilt PDTs by using the Looker IDE or by using the Development tab of the Persistent Derived Tables page. If you have unbuilt PDTs, you can query them in Development Mode right before you make your changes so that the development table is available to be used in production.
- If a persisted table has the
dev_filtersparameter (for native derived tables) or the conditionalWHEREclause that is using theif prodandif devstatements (for SQL-based derived tables), the development table cannot be used as the production version, since the development version has an abbreviated dataset. If this is the case, after you've finished developing the table and before you deploy your changes, you can comment out thedev_filtersparameter or the conditionalWHEREclause and then query the table in Development Mode. Looker will then build a full version of the table that can be used for production when you deploy your changes.
Otherwise, if you deploy your changes when there is no valid development table that can be used as the production table, Looker will rebuild the table the next time the table is queried in Production Mode (for persisted tables that use the persist_for strategy), or the next time the regenerator runs (for persisted tables that use datagroup_trigger, interval_trigger, or sql_trigger_value).
Checking for unbuilt PDTs in Development Mode
If a development table is persisted on your database when you deploy changes to a persistent derived table (PDT) or an aggregate table, Looker can often use the development table as the production table so that your users don't have to wait for the table to build when they query the table. See the How long Looker persists development tables and What prompts Looker to create a development table sections on this page for more details.
Therefore, it is optimal that all your PDTs are built when you deploy to production so that the tables can be used immediately as the production versions.
You can check your project for unbuilt PDTs in the Project Health panel. Click the Project Health icon in the Looker IDE to open the Project Health panel. Then click the Validate PDT Status button.
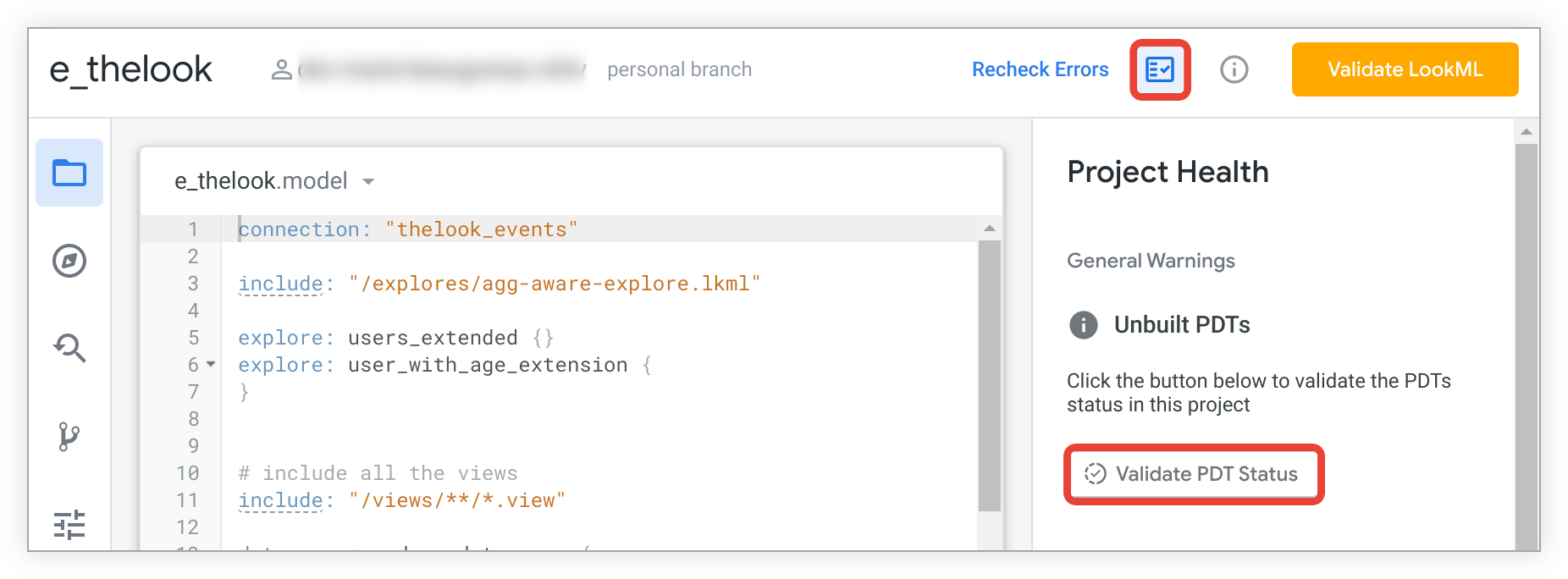
If there are unbuilt PDTs, the Project Health panel will list them:
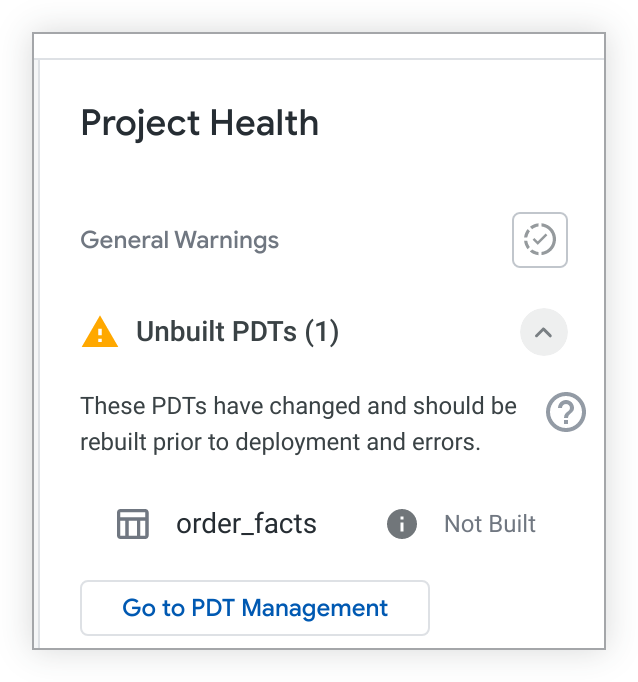
If you have see_pdts permission, you can click the Go to PDT Management button. Looker will open the Development tab of the Persistent Derived Tables page and filter the results to your specific LookML project. From there, you can see which development PDTs are built and unbuilt, as well as access other troubleshooting information. See the Admin settings - Persistent Derived Tables documentation page for more information.
Once you identify an unbuilt PDT in your project, you can build a development version it by opening an Explore that queries the table, then using the Rebuild Derived Tables & Run option from the Explore menu. See the Manually rebuilding persistent tables for a query section on this page.
Table sharing and cleanup
Within any given Looker instance, Looker will share persisted tables between users if the tables have the same definition and the same persistence method setting. Additionally, if a table's definition ever ceases to exist, Looker marks the table as expired.
This has several benefits:
- If you haven't made any changes to a table in Development Mode, your queries will use the existing production tables. This is the case unless your table is a SQL-based derived table that is defined using a conditional
WHEREclause withif prodandif devstatements. If the table is defined with a conditionalWHEREclause, Looker will build a development table if you query the table in Development Mode. (For native derived tables with thedev_filtersparameter, Looker has the logic to use the production table to answer queries in Development Mode, unless you change the definition of the table and then query the table in Development Mode.) - If two developers happen to make the same change to a table while in Development Mode, they will share the same development table.
- Once you push your changes from Development Mode to Production Mode, the old production definition does not exist anymore, so the old production table is marked as expired and will be dropped.
- If you decide to throw away your Development Mode changes, that table definition does not exist anymore, so the unneeded development tables are marked as expired and will be dropped.
Working faster in Development Mode
There are situations when the persistent derived table (PDT) that you're creating takes a long time to generate, which can be time-consuming if you are testing lots of changes in Development Mode. For these cases, you can prompt Looker to create smaller versions of a derived table when you're in Development Mode.
For native derived tables, you can use the dev_filters subparameter of explore_source to specify filters that are only applied to development versions of the derived table:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
This example includes a dev_filters parameter that filters the data to the last 90 days and a filters parameter that filters the data to the last 2 years and to the Yucca Valley Airport.
The dev_filters parameter acts in conjunction with the filters parameter so that all filters are applied to the development version of the table. If both dev_filters and filters specify filters for the same column, dev_filters takes precedence for the development version of the table. In this example, the development version of the table will filter the data to the last 90 days for the Yucca Valley Airport.
For SQL-based derived tables, Looker supports a conditional WHERE clause with different options for production (if prod) and development (if dev) versions of the table:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
In this example, the query will include all data from 2000 onward when in Production Mode but only the data from 2020 onward when in Development Mode. Using this feature strategically to limit your result set, and increase query speed, can make Development Mode changes much easier to validate.
How Looker builds PDTs
After a persistent derived table (PDT) has been defined and is either run for the first time or triggered by the regenerator for rebuilding according to its persistence strategy, Looker will go through the following steps:
- Use the derived table SQL to fashion a CREATE TABLE AS SELECT (or CTAS) statement and execute it. For example, to rebuild a PDT called
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Issue the statements to create the indexes when the table is built
- Rename the table from LC$.. ("Looker Create") to LR$.. ("Looker Read"), to indicate the table is ready to use
- Drop any older version of the table that should no longer be in use
There are a few important implications:
- The SQL that forms the derived table must be valid inside a CTAS statement.
- The column aliases on the result set of the SELECT statement must be valid column names.
- The names used when specifying distribution, sortkeys, and indexes must be the column names that are listed in the SQL definition of the derived table, not the field names that are defined in the LookML.
The Looker regenerator
The Looker regenerator checks the status and initiates rebuilds for trigger-persisted tables. A trigger-persisted table is a persistent derived table (PDT) or an aggregate table that uses a trigger as a persistence strategy:
- For tables that use
sql_trigger_value, the trigger is a query that is specified in the table'ssql_trigger_valueparameter. The Looker regenerator triggers a rebuild of the table when the result of the latest trigger query check is different from the result of the previous trigger query check. For example, if your derived table is persisted with the SQL querySELECT CURDATE(), the Looker regenerator will rebuild the table the next time the regenerator checks the trigger after the date changes. - For tables that use
interval_trigger, the trigger is a time duration that is specified in the table'sinterval_triggerparameter. The Looker regenerator triggers a rebuild of the table when the specified time has passed. - For tables that use
datagroup_trigger, the trigger can be a query specified in the associated datagroup'ssql_triggerparameter, or the trigger can be a time duration that is specified in the datagroup'sinterval_triggerparameter.
The Looker regenerator also initiates rebuilds for persisted tables that use the persist_for parameter, but only when the persist_for table is a dependency cascade of a trigger-persisted table. In this case, the Looker regenerator will initiate rebuilds for a persist_for table, since the table is needed to rebuild the other tables in the cascade. Otherwise, the regenerator doesn't monitor persisted tables that use the persist_for strategy.
The Looker regenerator cycle begins at a regular interval that is configured by your Looker admin in the Maintenance Schedule setting on your database connection (the default is a five-minute interval). However, the Looker regenerator does not start a new cycle until it has completed all the checks and PDT rebuilds from the last cycle. This means if you have long-running PDT builds, the Looker regenerator cycle may not run as often as defined in the Maintenance Schedule setting. Other factors can affect the time that is required to rebuild your tables, as described in the Important considerations for implementing persisted tables section on this page.
In cases where a PDT fails to build, the regenerator may attempt to rebuild the table in the next regenerator cycle:
- If the Retry Failed PDT Builds setting is enabled on your database connection, the Looker regenerator will attempt to rebuild the table during the next regenerator cycle, even if the table's trigger condition is not met.
- If the Retry Failed PDT Builds setting is disabled, the Looker regenerator won't attempt to rebuild the table until the PDT's trigger condition is met.
If a user requests data from the persisted table while it is being built and the query results aren't in the cache, Looker checks to see if the existing table is still valid. (The previous table may not be valid if it is not compatible with the new version of the table, which can happen if the new table has a different definition, the new table uses a different database connection, or the new table was created with a different version of Looker.) If the existing table is still valid, Looker will return data from the existing table until the new table is built. Otherwise, if the existing table is not valid, Looker will provide query results once the new table is rebuilt.
Important considerations for implementing persisted tables
Considering the usefulness of persisted tables (PDTs and aggregate tables), it is possible to accumulate many of them on your Looker instance. It is possible to create a scenario in which the Looker regenerator needs to build many tables at the same time. Especially with cascading tables, or long-running tables, you can create a scenario where tables have a long delay before rebuilding, or where users experience a delay in getting query results from a table while the database is working hard to generate the table.
The Looker regenerator checks PDT triggers to see if it should rebuild trigger-persisted tables. The regenerator cycle is set at a regular interval that is configured by your Looker admin in the Maintenance Schedule setting on your database connection (the default is a five-minute interval).
Several factors can affect the time that is required to rebuild your tables:
- Your Looker admin may have changed the interval of the regenerator trigger checks by using the Maintenance Schedule setting on your database connection.
- The Looker regenerator does not start a new cycle until it has completed all of the checks and PDT rebuilds from the last cycle. So if you have long-running PDT builds, the Looker regenerator cycle may not be as frequent as the Maintenance Schedule setting.
- By default, the regenerator can initiate the rebuilding of one PDT or aggregate table at a time over a connection. A Looker admin can adjust the regenerator's allowed number of concurrent rebuilds by using the Max number of PDT builder connections field in a connection's settings.
- All PDTs and aggregate tables triggered by the same
datagroupwill rebuild during the same regeneration process. This can be a heavy load if you have many tables using the datagroup, either directly or as a result of cascading dependencies.
In addition to the previous considerations, there are also some situations in which you should avoid adding persistence to a derived table:
- When derived tables will be extended — Each extension of a PDT will create a new copy of the table in your database.
- When derived tables use templated filters or Liquid parameters — Persistence is not supported for derived tables that use templated filters or Liquid parameters.
- When native derived tables are built from Explores that use user attributes with
access_filters, or withsql_always_where— Copies of the table will be built in your database for each possible user attribute value specified. - When the underlying data changes frequently and your database dialect does not support incremental PDTs.
- When the cost and time involved in creating PDTs is too high.
Depending on the number and complexity of persisted tables on your Looker connection, the queue might contain many persisted tables that need to be checked and rebuilt at each cycle, so it is important to keep these factors in mind when implementing derived tables on your Looker instance.
Managing PDTs at scale using API
Monitoring and managing persistent derived tables (PDTs) that refresh on varying schedules becomes increasingly complex as you create more PDTs on your instance. Consider using the Looker Apache Airflow integration to manage your PDT schedules alongside your other ETL and ELT processes.
Monitoring and troubleshooting PDTs
If you use persistent derived tables (PDTs), and especially cascading PDTs, it is helpful to see the status of your PDTs. You can use the Looker Persistent Derived Tables admin page to see the status of your PDTs. You can also check the PDT troubleshooting tree for step-by-step debugging.
When attempting to troubleshoot PDTs:
- Pay special attention to the distinction between development tables and production tables when investigating the PDT Event Log.
- Verify that the Temp Database setting on your Looker connection matches your actual scratch schema or database. If the Temp Database setting on the connection doesn't match the scratch schema on your database, update the Temp Database setting so that Looker can store persistent derived tables on your database.
- Determine if there are problems with all PDTs, or just one. If there is a problem with one, then the issue is likely caused by a LookML or SQL error.
- Determine if problems with the PDT correspond with the times when it is scheduled to rebuild.
- Make sure that all
sql_trigger_valuequeries evaluate successfully and that they return only one row and column. For SQL-based PDTs, you can do this by running them in SQL Runner. (Applying aLIMITprotects from runaway queries.) For more information on using SQL Runner to debug derived tables, see the Using sql runner to test derived tables Community post. - For SQL-based PDTs, use SQL Runner to verify that the SQL of the PDT executes without error. (Be sure to apply a
LIMITin SQL Runner to keep query times reasonable.) - For SQL-based derived tables, avoid using common table expressions (CTEs). Using CTEs with DTs creates nested
WITHstatements that can cause PDTs to fail without warning. Instead, use the SQL for your CTE to create a secondary DT and reference that DT from your first DT using the${derived_table_or_view_name.SQL_TABLE_NAME}syntax. - Check that any tables on which the problem PDT depends — whether normal tables or PDTs themselves — exist and can be queried.
- Ensure that any tables on which the problem PDT depends don't have any shared or exclusive locks. For Looker to successfully build a PDT, it needs to acquire an exclusive lock on the table that needs to be updated. This will conflict with other shared or exclusive locks that are on the table. Looker will be unable to update the PDT until all other locks have cleared. The same is true for any exclusive locks on the table that Looker is building a PDT from; if there is an exclusive lock on a table, Looker won't be able to acquire a shared lock to run queries until the exclusive lock clears.
- Use the Show Processes button in SQL Runner. If there are a large number of processes active, this could slow down query times.
- Monitor comments in the query. See the Query comments for PDTs section on this page.
Query comments for PDTs
Database administrators can differentiate normal queries from those that generate persistent derived tables (PDTs). Looker adds comments to the CREATE TABLE ... AS SELECT ... statement that includes the PDT's LookML model and view, plus a unique identifier (slug) for the Looker instance. If the PDT is being generated on behalf of a user in Development Mode, the comments will indicate the user's ID. The PDT generation comments follow this pattern:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
The PDT generation comment will appear in an Explore's SQL tab if Looker has had to generate a PDT for the Explore's query. The comment will appear at the top of the SQL statement.
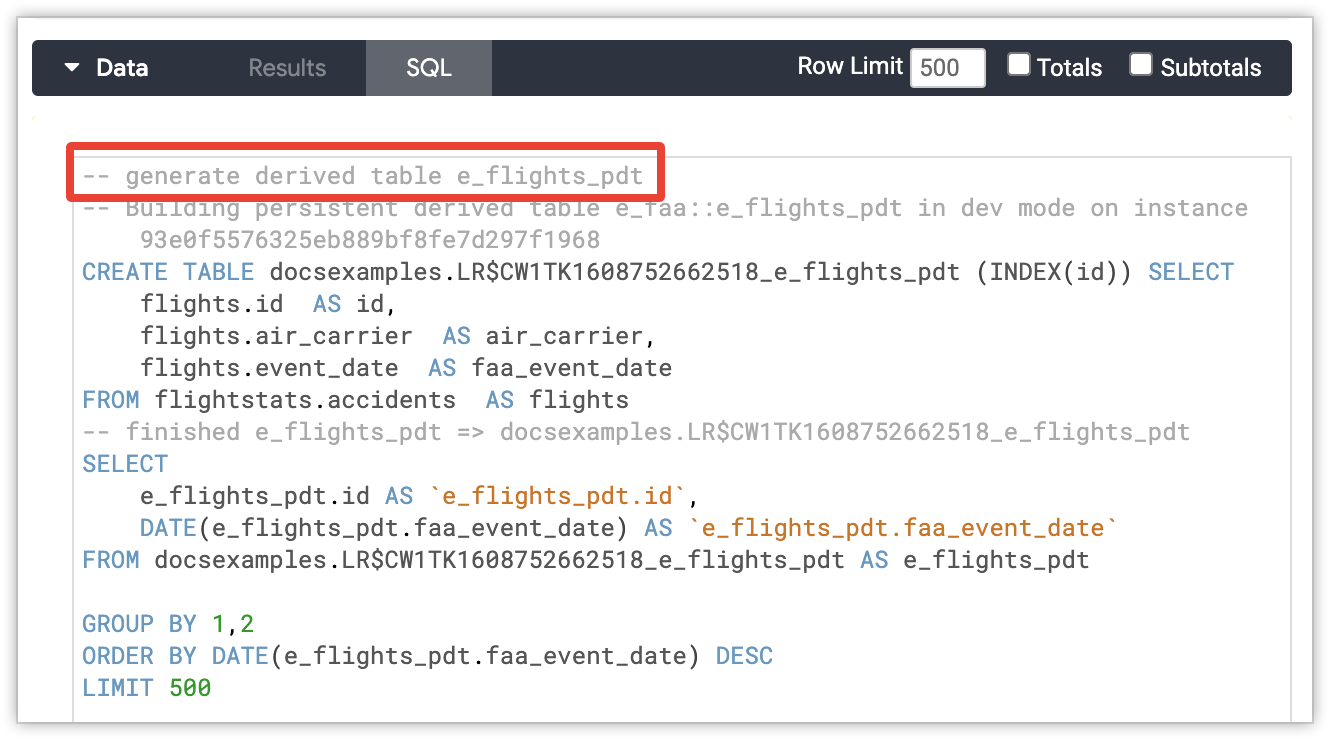
Finally, the PDT generation comment appears in the Message field on the Info tab of the Query Details pop-up for each query on the Queries admin page.
Rebuilding PDTs after a failure
When a persistent derived table (PDT) has a failure, here is what happens when that PDT is queried:
- Looker will use the results in the cache if the same query was previously run. (See the Caching queries documentation page for an explanation of how this works.)
- If the results aren't in the cache, Looker will pull results from the PDT in the database, if a valid version of the PDT exists.
- If there is no valid PDT in the database, Looker will attempt to rebuild the PDT.
- If the PDT can't be rebuilt, Looker will return an error for a query. The Looker regenerator will attempt to rebuild the PDT the next time the PDT is queried or the next time the PDT's persistence strategy triggers a rebuild.
With cascading PDTs, the same logic applies, except that with cascading PDTs:
- A failure to build for one table prevents the building of the PDTs down the dependency chain.
- A dependent PDT is essentially querying the PDT it relies on, so the persistence strategy of one table can trigger rebuilds of the PDTs going up the chain.
Revisiting the previous example of cascading tables, where TABLE_D is dependent on TABLE_C, which is dependent on TABLE_B, which is dependent on TABLE_A:
If TABLE_B has a failure, all the standard (non-cascade) behavior applies for TABLE_B:
- If
TABLE_Bis queried, Looker first tries to use the cache to return results. - If this attempt fails, Looker next tries to use a previous version of the table, if possible.
- If this attempt also fails, Looker then tries to rebuild the table.
- Finally, if
TABLE_Bcan't be rebuilt, Looker will return an error.
Looker will try again to rebuild TABLE_B when the table is next queried or when the table's persistence strategy next triggers a rebuild.
The same also applies for the dependents of TABLE_B. So if TABLE_B can't be built, and there is a query on TABLE_C, the following sequence occurs:
- Looker will try to use the cache for the query on
TABLE_C. - If the results aren't in the cache, Looker will try to pull results from
TABLE_Cin the database. - If there is no valid version of
TABLE_C, Looker will try to rebuildTABLE_C, which creates a query onTABLE_B. - Looker will then try to rebuild
TABLE_B(which will fail ifTABLE_Bhasn't been fixed). - If
TABLE_Bcan't be rebuilt, thenTABLE_Ccan't rebuild, so Looker will return an error for the query onTABLE_C. - Looker will then attempt to rebuild
TABLE_Caccording to its usual persistence strategy, or the next time the PDT is queried (which includes the next timeTABLE_Dtries to build, sinceTABLE_Ddepends onTABLE_C).
Once you resolve the problem with TABLE_B, then TABLE_B and each of the dependent tables will attempt to rebuild according to their persistence strategies, or the next time they are queried (which includes the next time a dependent PDT attempts to rebuild). Or, if a development version of the PDTs in the cascade was built in Development Mode, the development versions may be used as the new production PDTs. (See the Persisted tables in Development Mode section on this page for how this works.) Or you can use an Explore to run a query on TABLE_D and then manually rebuild the PDTs for the query, which will force a rebuild of all the PDTs going up the dependency cascade.
Improving PDT performance
When you create persistent derived tables (PDTs), performance can be a concern. Especially when the table is very large, querying the table may be slow, just as it can be for any large table in your database.
You can improve performance by filtering the data or by controlling how the data in the PDT is sorted and indexed.
Adding filters to limit the dataset
With particularly large datasets, having many rows will slow down queries against a persistent derived table (PDT). If you usually query only recent data, consider adding a filter to the WHERE clause of your PDT that limits the table to 90 days or fewer of data. This way, only relevant data will be added to the table each time it rebuilds so that running queries will be much faster. Then, you can create a separate, larger PDT for historical analysis to allow for both fast queries for recent data and the ability to query old data.
Using indexes or sortkeys and distribution
When you create a large persistent derived table (PDT), indexing the table (for dialects such as MySQL or Postgres) or adding sortkeys and distribution (for Redshift) can help with performance.
It is usually best to add the indexes parameter on ID or date fields.
For Redshift, it is usually best to add the sortkeys parameter on ID or date fields and the distribution parameter on the field that is used for joining.
Recommended settings to improve performance
The following settings control how the data in the persistent derived table (PDT) is sorted and indexed. These settings are optional, but highly recommended:
- For Redshift and Aster, use the
distributionparameter to specify the column name whose value is used to spread the data around a cluster. When two tables are joined by the column specified in thedistributionparameter, the database can find the join data on the same node, so inter-node I/O is minimized. - For Redshift, set the
distribution_styleparameter toallto instruct the database to keep a complete copy of the data on each node. This is often used to minimize inter-node I/O when reltively small tables are joined. Set this value toevento instruct the database to spread the data evenly through the cluster without using a distribution column. This value can only be specified whendistributionis not specified. - For Redshift, use the
sortkeysparameter. The values specify which columns of the PDT are used to sort the data on disk to make searching easier. On Redshift, you may use eithersortkeysorindexes, but not both. - On most databases, use the
indexesparameter. The values specify which columns of the PDT are indexed. (On Redshift, indexes are used to generate interleaved sort keys.)