Many Looker customers want to empower their users to go beyond reporting on data in their data warehouse to actually writing back to and updating that data warehouse.
Through its Action API, Looker supports this use case for any data warehouse or destination. This documentation page walks customers who use Google Cloud infrastructure through deploying a solution on Cloud Run functions to write back to BigQuery. This page covers the following topics:
Solution considerations
Use this list of considerations to validate that this solution aligns with your needs.
- Cloud Run functions
- Why Cloud Run functions? As Google's "serverless" offering, Cloud Run functions is a great choice for ease of operations and maintenance. One consideration to keep in mind is that latency, particularly for cold invocations, may be longer than with a solution that relies on a dedicated server.
- Language and Runtime Cloud Run functions supports multiple languages and runtimes. This documentation page will focus on an example in JavaScript and Node.js. However, the concepts are directly translatable to the other supported languages and runtimes.
- BigQuery
- Why BigQuery? Although this documentation page assumes that you're already using BigQuery, BigQuery is a great choice for a data warehouse in general. Keep in mind the following considerations:
- BigQuery Storage Write API: BigQuery offers multiple interfaces for updating data in your data warehouse, including, for example, Data Manipulation Language (DML) statements in SQL-based jobs. However, the best option for high-volume writes is the BigQuery Storage Write API.
- Appending rather than updating: Even though this solution will only be appending rows, not updating rows, you can always derive "current state" tables at query time from an append-only log, thus simulating updates.
- Why BigQuery? Although this documentation page assumes that you're already using BigQuery, BigQuery is a great choice for a data warehouse in general. Keep in mind the following considerations:
- Supporting services
- Secret Manager: Secret Manager holds secret values to make sure they aren't stored in overly accessible places like directly in the function's configuration.
- Identity and Access Management (IAM): IAM authorizes the function to access the necessary secret at runtime and to write to the intended BigQuery table.
- Cloud Build: Although Cloud Build will not be discussed in depth on this page, Cloud Run functions uses it in the background, and you can use Cloud Build to automate continuously deployed updates to your functions from changes to your source code in a Git repository.
- Action and user authentication
- Cloud Run Service Account The primary and easiest way to use Looker actions for integration with your organization's own first-party assets and resources is to authenticate requests as coming from your Looker instance using the Looker Action API's token-based authentication mechanism, and then authorizing the function to update data in BigQuery using a Service Account.
- OAuth: Another option, not covered on this page, would be to use the Looker Action API's OAuth feature. This approach is more complex and generally not required, but it may be used if you need to define end users' access to write to the table using IAM, rather than using their access in Looker or ad hoc logic within your function code.
Demo code walkthrough
We have a single file containing the entirety of our demo action's logic available on GitHub. In this section, we'll walk through the key elements of the code.
Setup code
The first section has a few demo constants that identify the table that the action will write to. In the Deployment guide section later on this page, you'll be instructed to replace the project ID with your own, which will be the only necessary modification to the code.
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
The next section declares and initializes a few code dependencies that your action will use. We provide an example that accesses Secret Manager "in-code" by using the Secret Manager Node.js module; however, you could also eliminate this code dependency by using Cloud Run functions' built-in feature to retrieve a secret for you during its initialization.
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
Note that the referenced @google-cloud dependencies are also declared in our package.json file to allow the dependencies to be pre-loaded and available to our Node.js runtime. crypto is a built-in Node.js module and isn't declared in package.json.
HTTP request handling and routing
The main interface that your code exposes to the Cloud Run functions runtime is an exported JavaScript function that follows Node.js Express web server conventions. In particular, your function receives two arguments: the first represents the HTTP request, from which you can read various request parameters and values; and the second represents a response object, to which you issue your response data. Although the name of the function can be anything you want, you'll have to provide the name to Cloud Run functions later, as detailed in the Deployment guide section.
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
The first section of the httpHandler function declares the various routes that our action will recognize, closely mirroring the Action API required endpoints for a single action, and the functions that will handle each route, defined later in the file.
While some actions + Cloud Run functions examples deploy a separate function for each such route to align one-to-one with Cloud Run functions' default routing, functions are capable of applying additional "sub-routing" within their code as demonstrated here. This is ultimately a matter of preference, but doing this additional routing in-code minimizes the number of functions we have to deploy and helps us maintain a single coherent code state across all of the actions' endpoints.
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
The remainder of the HTTP handler function implements the handling of the HTTP request against the preceding route declarations and connects the return values from those handlers to the response object.
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
With the HTTP handler and route declarations out of the way, we will dive into the three main action endpoints that we have to implement:
Actions List Endpoint
When a Looker administrator first connects a Looker instance to an Action server, Looker will call the provided URL, referred to as the "Actions List endpoint," to get information about the actions that are available through the server.
In our route declarations that we showed previously, we made this endpoint available at the root path (/) under our function's URL, and indicated that it would be handled by the hubListing function.
As you can see from the following function definition, there isn't too much "code" to it at all - it just returns the same JSON data every time. One thing to note is that it does dynamically include its "own" URL into some of the fields, allowing the Looker instance to send later requests back to the same function.
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
For demo purposes, our code has not required authentication to retrieve this listing. However, if you consider your action metadata to be sensitive, you can also require authentication for this route, as shown in the next section.
Also note that our Cloud Run function could expose and handle multiple actions, which explains our route convention of /action-X/.... However, our demo Cloud Run function will implement only one action.
Action Form Endpoint
Although not all use cases will require a form, having one fits well with the use case of database writebacks, as users can inspect data in Looker and then provide values to be inserted into the database. Since our Actions List provided a form_url parameter, Looker will invoke this Action Form endpoint when a user starts interacting with your action, to determine what additional data to capture from the user.
In our route declarations, we made this endpoint available under the /action-0/form path, and associated two handlers with it: requireInstanceAuth and action0Form.
We set up our route declarations to allow multiple handlers like this because some logic can be re-used for multiple endpoints.
For example, we can see that requireInstanceAuth is used for multiple routes. We use this handler wherever we want to require that a request must have come from our Looker instance. The handler retrieves the secret expected token value from Secret Manager and rejects any requests that don't have that expected token value.
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
Note that we use a timingSafeEqual implementation, rather than the standard equality check (==), to prevent leaking side-channel timing information that would allow an attacker to quickly figure out the value of our secret.
Assuming that a request passes the instance authentication check, the request is then handled by the action0Form handler.
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
Although our demo example is very static, the form code can be more interactive for certain use cases. For example, depending on a user's selection in an initial drop-down, different fields can be displayed.
Action Execute Endpoint
The Action Execute endpoint is where the bulk of any action's logic lives, and where we will get into logic specific to the BigQuery insert use case.
In our route declarations, we made this endpoint available under the /action-0/execute path, and associated three handlers with it: requireInstanceAuth, processRequestBody, and action0Execute.
We already covered requireInstanceAuth, and the processRequestBody handler provides mostly uninteresting pre-processing to make certain inconvenient fields in Looker's request body into a more convenient format, but you can refer to it in the full code file.
The action0Execute function starts by showing examples of extracting information from several parts of the action request that could be useful. In practice, note that the request elements that our code refers to as formParams and actionParams can contain different fields, depending on what you declare in your Listing and Form endpoints.
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
The code then transitions into some standard BigQuery code to actually insert the data. Note that the BigQuery Storage Write APIs offer other, more complex variations that are better suited for a persistent streaming connection or bulk inserts of many records; but, for responding to individual user interactions in the context of a Cloud Run function, this is the most direct variation.
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
The demo code also includes a "status" endpoint for troubleshooting purposes, but this endpoint isn't required for the Action API integration.
Deployment guide
Finally, we will provide a step-by-step guide for deploying the demo for yourself, covering pre-requisites, Cloud Run function deployment, BigQuery configuration, and Looker configuration.
Project and service prerequisites
Before starting to configure any specifics, review this list to understand what services and policies the solution will need:
- A new project: You will need a new project to house the resources from our example.
- Services: When first using BigQuery and Cloud Run functions in the Cloud console UI, you'll be prompted to enable required APIs for necessary services, including BigQuery, Artifact Registry, Cloud Build, Cloud Functions, Cloud Logging, Pub/Sub, Cloud Run Admin, and Secret Manager.
- Policy for unauthenticated invocations: This use case requires us to deploy Cloud Run functions that "allow public access", since we will handle the authentication for incoming requests in our code according to the Action API, rather than using IAM. While this is allowed by default, organizational policy often restricts this usage. Specifically, the
constraints/iam.allowedPolicyMemberDomainspolicy restricts who can be granted IAM permissions, and you may need to adjust it to allow theallUsersprincipal for unauthenticated access. See this guide, How to create public Cloud Run services when Domain Restricted Sharing is enforced for more information if you find yourself unable to allow public access. - Other policies: Keep in mind that other Google Cloud organization policy constraints can also prevent deployment of services that are otherwise allowed by default.
Deploying the Cloud Run function
Once you have created a new project, follow these steps to deploy the Cloud Run function
- In Cloud Run functions, click Create Function.
- Choose any name for your function (for example, "demo-bq-insert-action").
- Under Trigger settings:
- The trigger type should already be "HTTPS".
- Set Authentication to Allow unauthenticated invocations.
- Copy the URL value to your clipboard.
- Under the Runtime > Runtime environment variables settings:
- Click Add variable.
- Set the variable name to
CALLBACK_URL_PREFIX. - Paste the URL from the previous step as the value.
- Click Next.
- Click the
package.jsonfile, and paste in the contents. - Click the
index.jsfile, and paste in the contents. - Assign the
projectIdvariable at the top of the file to your own project ID. - Set the Entry Point to
httpHandler. - Click Deploy.
- Grant the requested permissions (if any) to the build Service Account.
- Wait for the deployment to complete.
- If, in any future steps, you get an error directing you to review the Google Cloud logs, note that you can access the logs for this function from the Logs tab on this page.
- Before navigating away from your Cloud Run function's page, under the Details tab, locate and note the Service Account that the function has. We will use this in later steps to ensure that the function has the permissions that it needs.
- Test your function deployment directly in your browser by visiting the URL. You should see a JSON response containing your integration listing.
- If you get a 403 error, your attempt to set Allow unauthenticated invocations may have silently failed as a result of an organization policy. Check whether your function is allowing unauthenticated invocations, review your organization policy setting, and try to update the setting.
Access to the BigQuery destination table
In practice, the destination table to be inserted into can reside in a different Google Cloud project; but, for demonstration purposes, we will create a new destination table in our same project. In either case, you'll need to ensure that your Cloud Run function's Service Account has permissions to write to the table.
- Navigate to the BigQuery console.
Create the demo table:
- In the Explorer bar, use the ellipsis menu next to your project and select Create dataset.
- Give your dataset the ID
demo_dataset, and click Create dataset. - Use the ellipsis menu on your newly created dataset, and select Create table.
- Give your table the name
demo_table. Under Schema, select Edit as text, use the following schema, and then click Create table.
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
Assign permissions:
- In the Explorer bar, click your dataset.
- On the dataset page, click Sharing > Permissions.
- Click Add Principal.
- Set the New Principal to the Service Account for your function, noted earlier on this page.
- Assign the BigQuery Data Editor role.
- Click Save.
Connecting to Looker
Now that your function is deployed, we will get Looker connected to it.
- We will need a shared secret for your action to authenticate that requests are coming from your Looker instance. Generate a long random string and keep it secure. We will use it in subsequent steps as our Looker secret value.
- In Cloud console, navigate to Secret Manager.
- Click Create Secret.
- Set the Name to
LOOKER_SECRET. (This is hard-coded in the code for this demo, but you can effectively choose any name when working with your own code.) - Set the Secret Value to the secret value that you generated.
- Click Create Secret.
- On the Secret page, click the Permissions tab.
- Click Grant Access.
- Set New Principals to the Service Account for your function, noted previously.
- Assign the Secret Manager Secret Accessor role.
- Click Save.
- You can confirm that your function is successfully accessing the secret by visiting the
/statusroute appended to your function URL.
- In your Looker instance:
- Navigate to Admin > Platform > Actions.
- Go to the bottom of the page to click Add Action Hub.
- Provide the URL of your function (for example, https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action), and confirm by clicking Add Action Hub.
- You should now see a new Action Hub entry with one action named Demo BigQuery Insert.
- On the Action Hub entry, click Configure Authorization.
- Enter your generated Looker Secret into the Authorization Token field, and click Update Token.
- On the Demo BigQuery Insert action, click Enable.
- Toggle the Enabled switch to on.
- A test of the action should automatically run, confirming that your function is accepting Looker's request and correctly responding to the form endpoint.
- Click Save.
End-to-end test
We should now be able to actually use our new action. This action is configured to work with any query, so pick any Explore (for example, a built-in System Activity Explore), add some fields to a new query, run it, and then choose Send from the gear menu. You should see the action as one of the available destinations, and you should be prompted for some field inputs:
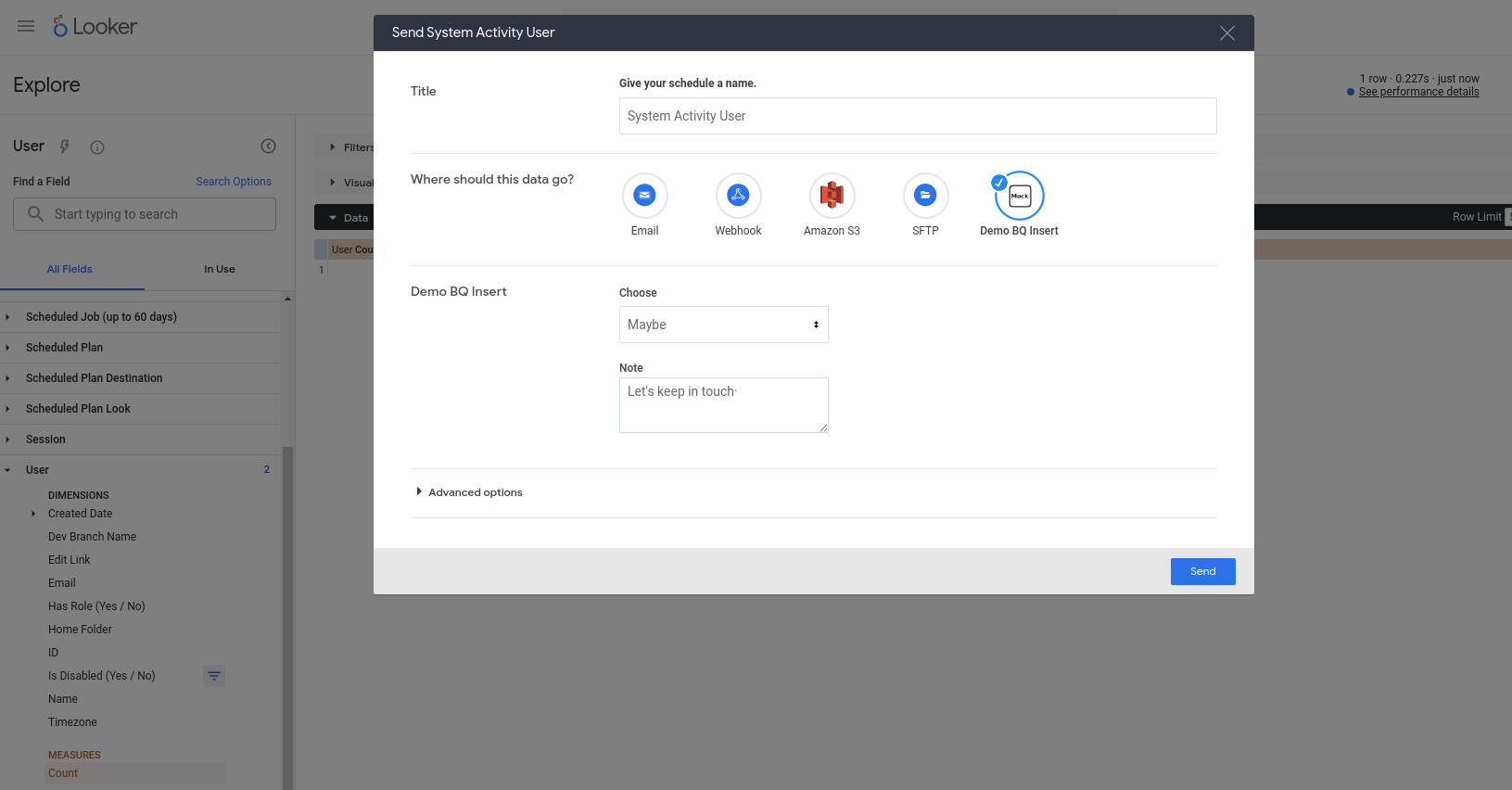
Upon pressing Send, you should have a new row inserted into your BigQuery table (and have the email of your Looker user account identified in the invoked_by column)!