When you have permission to create custom fields, you can create ad hoc custom groups for dimensions without using logical functions in Looker expressions or developingCASE WHENlogic insqlparameters ortype: casefields.
You can also create ad hoc custom bins for numeric type dimensions without needing to use logical functions in Looker expressions or needing to develop type: tier LookML fields when you have permission to create custom fields.
Bucketing can be very useful for creating custom grouping dimensions in Looker.
There are three ways to create buckets in Looker:
- Using the
tierdimensiontype - Using the
caseparameter - Using a SQL
CASE WHENstatement in theSQLparameter of a LookML field
Using tier for bucketing
To create integer buckets, we can simply define the dimension type as tier:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
You can use the style parameter to customize how your tiers appear when exploring. The four options for style are as follows:
For example:
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
The style parameter classic is the default and takes the format Tx[x,x] with Tx indicating the tier number and [x,x] indicating the range. The following image is an Explore data table with Users Count grouped by Users Age:
![The top available Users Age tier in the data table is T02[10,20] indicating a count of 808 users from ages 10 to 20.](/static/looker/docs/images/bucketing-in-looker-1-2210.png)
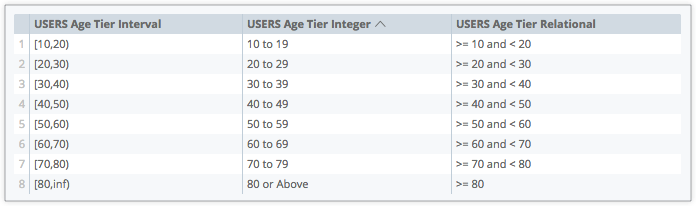
The next image shows examples of the other style parameter options:
-
interval— With the format[x,x], which indicates the lowest value and the highest value of a tier -
integer— With the formatx to x, which indicates the lowest value and the highest value of a tier -
relational— With the format>= x and <x, which indicates that a value is greater than or equal to the lowest tier value and less than the highest tier value
Things to consider
Using tier in conjunction with dimension fill can result in unexpected tier buckets.
For example, a type: tier dimension, Age Tier, will display tier buckets for Below 0 and 0 to 9 when dimension fill is enabled, although the data does not include age values for those buckets:

When dimension fill is disabled for Age Tier, the buckets more accurately reflect the age values available in the data, beginning with the bucket 10 to 19:

You can enable or disable dimension fill by hovering over the dimension name in the Explore, clicking the field-level gear icon, and selecting either Remove Filled in Tier Values to disable, or Fill in Missing Tier Values to enable.
Find out more about Looker tiers on the Dimension, filter, and parameter types documentation page.
Using case for bucketing
You can use the case parameter to create custom-named buckets with custom sorting. The case parameter is recommended for a fixed set of buckets, as it can help control the way values are presented, ordered, and used in UI filters and visualizations. For example, with case, a user will be able to select only the defined bucket values in a filter.
To create buckets with case, you can define a dimension, like a bucket for order amounts:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
The case parameter will typically sort values in the order in which the buckets are listed. For the order_amount_bucket dimension, the order of the buckets is Small, Medium, and Large:

If you would like to sort alphanumerically, add the alpha_sort parameter
to the dimension, like so:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
For dimensions where many distinct values are desired in the output (this would require you to define each output with a WHEN or an ELSE statement), or when you would like to implement a more complex ELSE statement, we recommend that you use a SQL CASE WHEN, discussed in the next section.
Read more about the case parameter on the Field parameters documentation page.
Using SQL CASE WHEN for bucketing
A SQL CASE WHEN statement is recommended for more complex bucketing, or for implementation of a more nuanced ELSE statement.
For example, you may want to use different bucketing methods, depending on the destination of an order. A SQL CASE WHEN statement could be used to create a compound bucket dimension, where the THEN statement returns dimensions rather than strings:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}