本文档介绍如何衡量您在部署可扩缩的 TensorFlow 推理系统中创建的 TensorFlow 推理系统的性能。此外还介绍了如何应用参数调节来提高系统吞吐量。
该部署基于可扩缩的 TensorFlow 推理系统中所述的参考架构。
本系列文章面向熟悉 Google Kubernetes Engine 和机器学习 (ML) 框架(包括 TensorFlow 和 TensorRT)的开发者。
本文档并非用于提供特定系统的性能数据。相反,它会提供有关性能衡量过程的一般指导。 您看到的性能指标(例如每秒总请求数 [RPS] 和响应时间 [ms])将根据您使用的训练模型、软件版本和硬件配置而有所不同。
架构
如需了解 TensorFlow 推理系统的架构概览,请参阅可扩缩的 TensorFlow 推理系统。
目标
- 定义性能目标和指标
- 衡量基准性能
- 执行图表优化
- 衡量 FP16 转换
- 衡量 INT8 量化
- 调整实例数
费用
如需详细了解与部署关联的费用,请参阅费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
确保您已完成部署可扩缩的 TensorFlow 推理系统中的步骤。
在本文档中,您将使用以下工具:
- 您在创建工作环境时准备的工作实例的 SSH 终端。
- 您在使用 Prometheus 和 Grafana 部署监控服务器时准备的 Grafana 信息中心。
- 您在部署负载测试工具时准备的 Locust 控制台。
设置目录
在 Google Cloud 控制台中,转到 Compute Engine > 虚拟机实例。
您会看到您创建的
working-vm实例。如需打开实例的终端控制台,请点击 SSH。
在 SSH 终端中,将当前目录设置为
client子目录:cd $HOME/gke-tensorflow-inference-system-tutorial/client在本文档中,您将通过此目录运行所有命令。
定义性能目标
在测量推理系统的性能时,您必须根据系统的用例定义性能目标和适当的性能指标。出于演示目的,本文档使用以下性能目标:
- 至少 95% 的请求在 100 毫秒内收到响应。
- 总吞吐量(由每秒请求数 [RPS] 表示)可在不破坏之前的目标的情况下提高。
使用这些假设条件,您可以衡量和提高以下采用不同优化的 ResNet-50 模型的吞吐量。当客户端发送推理请求时,它会使用此表中的模型名称指定模型。
| 模型名称 | 优化 |
|---|---|
original |
原始模型(未经 TF-TRT 优化) |
tftrt_fp32 |
图优化 (批次大小:64,实例组:1) |
tftrt_fp16 |
除图优化外,转换为 FP16 (批次大小:64,实例组:1) |
tftrt_int8 |
除图优化外,使用 INT8 进行量化 (批次大小:64,实例组:1) |
tftrt_int8_bs16_count4 |
除图优化外,使用 INT8 进行量化 (批次大小:16,实例组:4) |
衡量基准性能
首先,您需要将 TF-TRT 用作基准,以衡量未经优化的原始模型的性能。您可以将其他模型的性能与原始模型的性能进行比较,以便以量化方式评估性能的提升。部署 Locust 后,它已配置为发送对原始模型的请求。
打开您在部署负载测试工具时准备的 Locust 控制台。
确认客户端数量(称为从属)数量为 10。
如果数字小于 10,则客户端仍在启动。在这种情况下,请等待几分钟,直到它变为 10 为止。
衡量性能:
- 在要模拟的用户数字段中,输入
3000。 - 在填充率字段中,输入
5。 - 如需将每秒模拟使用次数增加 5 次,直到达到 3000 次,请点击开始聚合。
- 在要模拟的用户数字段中,输入
点击图表。
图表会显示效果结果。请注意,虽然每秒请求总数值会线性提高,但响应时间(毫秒)值会相应增加。
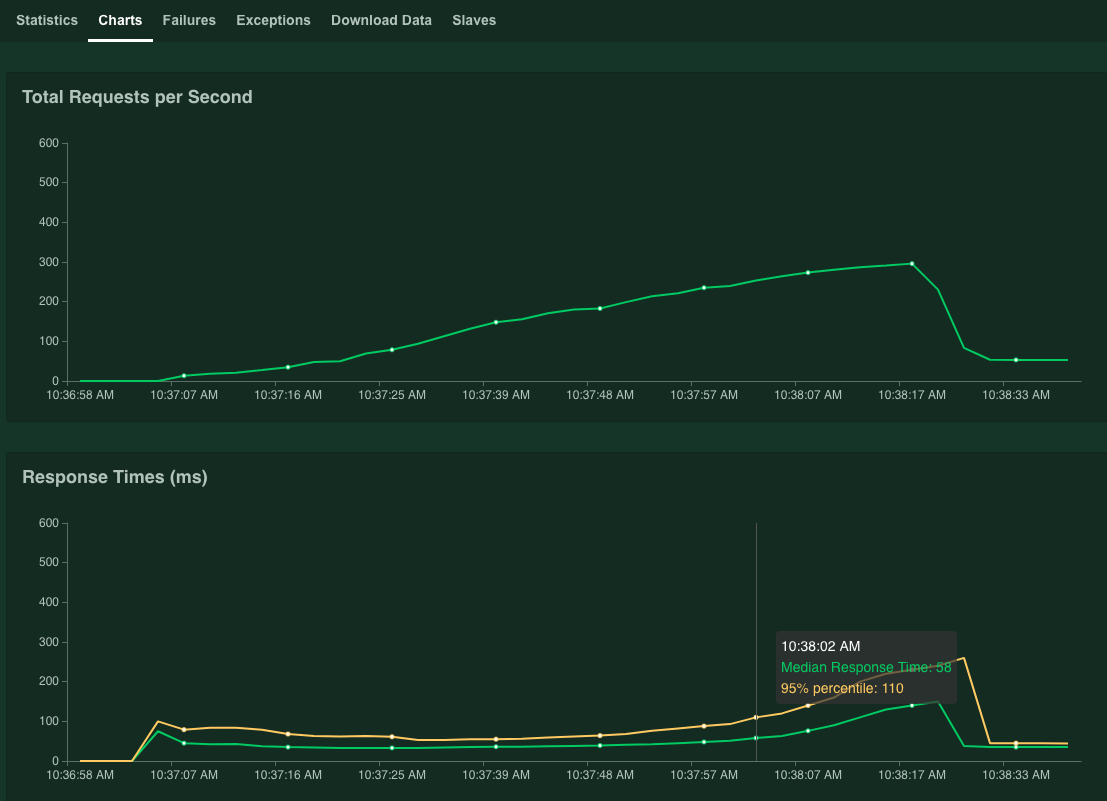
当响应时间的 95% 值超过 100 毫秒时,点击停止即可停止模拟。
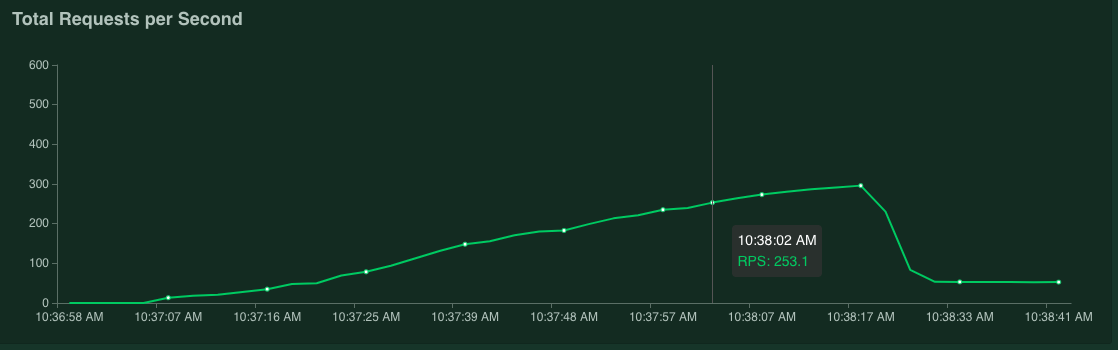
如果将鼠标指针移到图表上,则可以查看每秒 95% 响应时间百分位数超过 100 毫秒的请求数。
例如,在以下屏幕截图中,每秒请求数为 253.1。
我们建议您多次重复执行该测量,并取平均值来应对波动情况。
在 SSH 终端中,重启 Locust:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust要重复测量,请重复此过程。
优化图表
在本部分中,您将衡量模型 tftrt_fp32 的性能,该模型已使用 TF-TRT 优化图表。这是一种与大多数 NVIDIA GPU 卡兼容的常见优化方式。
在 SSH 终端中,重启负载测试工具:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustconfigmap资源将模型指定为tftrt_fp32。重启 Triton 服务器:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1等待几分钟,直到服务器过程准备就绪。
检查服务器状态:
kubectl get pods输出类似于以下内容,其中
READY列显示了服务器状态:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sREADY列中的值1/1表示服务器已准备就绪。衡量性能:
- 在要模拟的用户数字段中,输入
3000。 - 在填充率字段中,输入
5。 - 如需将每秒模拟使用次数增加 5 次,直到达到 3000 次,请点击开始聚合。
这些图表显示了 TF-TRT 图优化的性能改进。
例如,图表可能会显示每秒请求数现在为 381 个,中位响应时间为 59 毫秒。
- 在要模拟的用户数字段中,输入
转换为 FP16
在本部分中,您将衡量模型 tftrt_fp16 的性能,该模型已使用 TF-TRT 优化图表并转换为 FP16。这是适用于 NVIDIA T4 的优化方法。
在 SSH 终端中,重启负载测试工具:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust重启 Triton 服务器:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1等待几分钟,直到服务器过程准备就绪。
衡量性能:
- 在要模拟的用户数字段中,输入
3000。 - 在填充率字段中,输入
5。 - 如需将每秒模拟使用次数增加 5 次,直到达到 3000 次,请点击开始聚合。
这些图表显示了 FP16 转换的性能改进,以及 TF-TRT 图优化的性能改进。
例如,图表可能会显示每秒请求数为 1072.5,中位数响应时间为 63 毫秒。
- 在要模拟的用户数字段中,输入
使用 INT8 量化
在本部分中,您将衡量模型 tftrt_int8 的性能,该模型已使用 TF-TRT 优化图表并使用 INT8 量化。此优化方法适用于 NVIDIA T4。
在 SSH 终端中,重启负载测试工具。
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust重启 Triton 服务器:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1等待几分钟,直到服务器过程准备就绪。
衡量性能:
- 在要模拟的用户数字段中,输入
3000。 - 在填充率字段中,输入
5。 - 如需将每秒模拟使用次数增加 5 次,直到达到 3000 次,请点击开始聚合。
图表会显示效果结果。
例如,图表可能会显示每秒请求数为 1085.4,中位响应时间为 32 毫秒。
在此示例中,与 FP16 转换相比,结果没有显著提升性能。从理论上讲,NVIDIA T4 GPU 可以比 FP16 转换模型更快地处理 INT8 量化模型。在这种情况下,除了 GPU 性能之外,可能存在瓶颈。您可以通过 Grafana 信息中心上的 GPU 利用率数据进行确认。例如,如果利用率低于 40%,则意味着模型无法充分利用 GPU 性能。
如下一节所示,您可以通过增加实例组的数量来简化此瓶颈。例如,将实例组的数量从 1 增加到 4,并将批次大小从 64 减小至 16。此方法可将单个 GPU 中处理的请求总数保持在 64 个。
- 在要模拟的用户数字段中,输入
调整实例数
在本部分中,您将衡量模型 tftrt_int8_bs16_count4 的性能。此模型与 tftrt_int8 的结构相同,但您需要按照使用 INT8 进行量化中所述更改批次大小和实例组的数量。
在 SSH 终端中,重启 Locust:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locust在此命令中,您使用
configmap资源将模型指定为tftrt_int8_bs16_count4。您还需要增加 Locust 客户端 Pod 的数量,以生成足够的工作负载来衡量模型的性能限制。重启 Triton 服务器:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1等待几分钟,直到服务器过程准备就绪。
衡量性能:
- 在要模拟的用户数字段中,输入
3000。 - 在填充率字段中,输入
15。 对于此模型,如果填充率设置为5,则达到性能限制可能需要很长时间。 - 如需将每秒模拟使用次数增加 5 次,直到达到 3000 次,请点击开始聚合。
图表会显示效果结果。
例如,图表可能会显示每秒请求数为 2236.6,中位数响应时间为 38 毫秒。
通过调整实例数量,您几乎可以实现每秒的两次请求。请注意,Grafana 信息中心上的 GPU 利用率已增加(例如,利用率可能达到 75%)。
- 在要模拟的用户数字段中,输入
性能和多个节点
使用多个节点进行扩缩时,您可以衡量单个 Pod 的性能。由于推理过程以无共享的方式单独在不同的 Pod 上执行,因此您可以假设总吞吐量将与 Pod 的数量线性扩缩。只要客户端和推理服务器之间的网络带宽不存在瓶颈,就可以如此假设。
但是,请务必了解如何在多个推理服务器之间实现推断请求。Triton 使用 gRPC 协议在客户端和服务器之间建立 TCP 连接。由于 Titon 会重复使用发送的连接来发送多个推理请求,因此单个客户端的请求始终会发送到同一服务器。如需分发多个服务器的请求,您必须使用多个客户端。
清理
为避免系统因本系列教程中使用的资源向您的 Google Cloud 账号收取费用,您可以删除该项目。
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 了解如何配置用于预测的计算资源。
- 详细了解 Google Kubernetes Engine (GKE)。
- 详细了解 Cloud Load Balancing。
- 如需查看更多参考架构、图表和最佳实践,请浏览云架构中心。