本文档介绍如何将 Apache Spark 作业迁移到 Dataproc。该文档面向大数据工程师和架构师。该文档涵盖了迁移、准备、作业迁移和管理的注意事项等主题。
概览
如果您希望将 Apache Spark 工作负载从本地环境移到 Google Cloud,我们建议使用 Dataproc 来运行 Apache Spark/Apache Hadoop 集群。Dataproc 是 Google Cloud 提供的一种享有全面支持的全代管式服务。借助该服务,您可以将存储和计算分隔开来,这有助于您管理费用并更加灵活地扩缩工作负载。
如果托管 Hadoop 环境不符合您的需求,您还可以使用其他设置,例如在 Google Kubernetes Engine (GKE) 上运行 Spark,或在 Compute Engine 上租用虚拟机并自行设置 Hadoop 或 Spark 集群。但请注意,除 Dataproc 外的其他方案均属自管式方案,并且只享有社区支持。
对迁移进行规划
在本地运行 Spark 作业与在 Compute Engine 上的 Dataproc 或 Hadoop 集群上运行 Spark 作业之间存在许多差异。请务必仔细查看工作负载并做好迁移准备工作。在本部分中,我们会概述需要考虑的注意事项,以及迁移 Spark 作业前要做的准备工作。
确定作业类型并对集群进行计划
Spark 工作负载分为三种类型,如本部分所述。
定期执行的批量作业
定期执行的批量作业包括每天或每小时 ETL 等用例,或使用 Spark ML 训练机器学习模型的流水线。对于这些情况,我们建议您为每个批量工作负载创建一个集群,然后在作业完成后删除集群。您可以灵活配置集群,因为您可以单独调整每个工作负载的配置。Dataproc 集群在第一分钟后以一秒为增量计费,由于您可以为集群加标签,因此该方法也经济实惠。如需了解详情,请参阅 Dataproc 价格页面。
您可以使用工作流模板或按照以下步骤实现批量作业:
创建一个集群并等待集群完成创建。(您可以使用 API 调用或 gcloud 命令监控是否已创建集群。)如果您在专用的 Dataproc 集群上运行作业,关闭动态分配和外部重排服务可能会有所帮助。以下
gcloud命令显示了创建 Dataproc 集群时提供的 Spark 配置属性:dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'将作业提交到集群。(您可以使用 API 调用或 gcloud 命令监控作业的状态。)例如:
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'
流式作业
对于流式作业,您需要创建一个长期运行的 Dataproc 集群,并将集群配置为以高可用性模式运行。对此情况,我们不建议使用抢占式虚拟机。
用户提交的临时或交互式工作负载
临时工作负载的示例可包括在白天编写查询或执行分析作业的用户。
对于这些情况,您必须决定是否需要集群以高可用性模式运行,是否要使用抢占式虚拟机,以及如何管理对集群的访问权限。您可以安排集群创建和终止(例如,如果您在夜间或周末从不需要集群),并且可以根据时间安排实现横向和纵向扩缩。
确定数据源和依赖项
每个作业都有自己的依赖项(例如其所需数据源),而您的公司的其他团队可能依赖于您的作业的结果。 因此,您必须确定所有依赖项,然后创建包含以下操作过程的迁移计划:
将所有数据源分步迁移到 Google Cloud。一开始,在 Google Cloud 中建立数据源的镜像非常有用,这样您便可以在两个位置使用该数据源。
迁移相应数据源之后,立即将 Spark 工作负载按作业逐个迁移到 Google Cloud。与数据类似,在某一时刻,您可能在旧环境和 Google Cloud 中并行运行两个工作负载。
迁移依赖于 Spark 工作负载输出的其他工作负载。或者,您可以仅将输出复制回初始环境。
当所有相关团队确认其不再需要这些作业后,在旧环境中关闭 Spark 作业。
选择存储选项
有两种存储选项可用于 Dataproc 集群:您可以将所有数据存储在 Cloud Storage 中,也可以将本地磁盘或永久性磁盘用于集群工作器。您可根据作业特点作出正确选择。
比较 Cloud Storage 和 HDFS
Dataproc 集群的每个节点均安装了 Cloud Storage 连接器。默认情况下,连接器安装在 /usr/lib/hadoop/lib 下。该连接器实现了 Hadoop FileSystem 接口,使 Cloud Storage 与 HDFS 兼容。
由于 Cloud Storage 是二进制大对象 (BLOB) 存储系统,因此连接器会根据对象的名称模拟目录。您可以使用 gs:// 前缀(而不是 hdfs:// 前缀)来访问数据。
Cloud Storage 连接器通常不需要任何自定义。但是,如果需要进行更改,您可以按照配置连接器的说明进行操作。 另外还提供了配置键的完整列表。
如果符合以下条件,则 Cloud Storage 是一种不错的选择:
- 采用 ORC、Parquet、Avro 或任何其他格式的数据将用于不同集群或作业,如果集群终止,您需要数据具有持久性。
- 您需要高吞吐量,并且您的数据存储在大于 128 MB 的文件中。
- 您的数据需要具有跨地区耐用性。
- 您需要数据具有高可用性 - 例如,您希望消除作为单个故障点的 HDFS NameNode。
如果符合以下条件,则本地 HDFS 存储是一种不错的选择:
- 您的作业需要执行大量元数据操作 - 例如,您有数千个分区和目录,且每个文件大小较小。
- 您经常修改 HDFS 数据或者重命名目录。 (Cloud Storage 对象不可变,因此重命名目录是一项成本较高的操作,因为这涉及将所有对象复制到新键并在之后将其删除。)
- 您对 HDFS 文件频繁使用附加操作。
您的工作负载涉及大量 I/O。例如,您具有大量分区写入,如下所示:
spark.read().write.partitionBy(...).parquet("gs://")您的 I/O 工作负载对延迟特别敏感。例如,您要求每个存储操作具有单数位毫秒级延迟。
通常,我们建议使用 Cloud Storage 作为大数据流水线中的初始和最终数据源。例如,如果工作流包含五个连续的 Spark 作业,则第一个作业从 Cloud Storage 检索初始数据,然后将重排数据和中间作业输出写入 HDFS。最后一个 Spark 作业将其结果写入 Cloud Storage。
调整存储空间大小
通过将 Dataproc 与 Cloud Storage 配合使用,您可以将数据存储在 Cloud Storage(而不是 HDFS)中,从而减少磁盘需求并节省费用。如果将数据保留在 Cloud Storage 上且不将其存储在本地 HDFS 上,则可以为集群使用较小的磁盘。如前所述,通过使集群真正按需运行,您还能够将存储和计算分隔开来,这有助于大幅减少费用。
即使您将所有数据存储在 Cloud Storage 中,您的 Dataproc 集群也需要使用 HDFS 来执行某些操作,如存储控制和恢复文件或聚合日志。它还需要非 HDFS 本地磁盘空间进行重排。如果您不是频繁使用本地 HDFS,则可以减小每个工作器的磁盘大小。
以下是调整本地 HDFS 大小的一些方式:
- 通过减小主实例和工作器的主永久性磁盘大小来减小本地 HDFS 的总大小。主永久性磁盘还包含启动卷和系统库,因此请至少分配 100 GB。
- 通过增加工作器的主永久性磁盘大小来增加本地 HDFS 的总大小。请谨慎考虑此方式:与使用 Cloud Storage 或具有 SSD 的本地 HDFS 相比,将 HDFS 与标准永久性磁盘配合使用时,很少有工作负载能够获得更好的性能。
- 最多可以将 8 个 SSD(每个 375 GB)附加到每个工作器,然后将这些磁盘用于 HDFS。如果您需要将 HDFS 用于 I/O 密集型工作负载,并且需要单数位毫秒级延迟,这是不错的方式。请确保您使用的机器类型在工作器上具有足够 CPU 和内存来支持这些磁盘。
- 使用永久性磁盘 SSD (PD-SSD) 作为主磁盘用于主实例或工作器。
访问 Dataproc
访问 Compute Engine 上的 Dataproc 或 Hadoop 与访问本地集群有所不同。您需要确定安全设置和网络访问选项。
网络
Dataproc 集群的所有虚拟机实例都需要相互进行内部联网,并且需要开放的 UDP、TCP 和 ICMP 端口。您可以使用默认网络配置或使用 VPC 网络,允许从外部 IP 地址访问您的 Dataproc 集群。在您使用的任何网络选项中,您的 Dataproc 集群将具有对所有 Google Cloud 服务(Cloud Storage 存储桶、API 等)的网络访问权限。要允许对本地资源或从本地资源进行网络访问,请选择 VPC 网络配置并设置相应的防火墙规则。 如需了解详情,请参阅下面的 Dataproc 集群网络配置指南和访问 YARN 部分。
身份和访问权限管理
除网络访问权限外,您的 Dataproc 集群还需要访问资源的权限。例如,要将数据写入 Cloud Storage 存储桶,您的 Dataproc 集群必须具有对存储桶的写入权限。您可以使用角色建立访问权限。 扫描您的 Spark 代码,找到代码所需的所有非 Dataproc 资源,并将合适的角色授予集群的服务账号。此外,请确保要创建集群、作业、操作和工作流模板的用户具有适当权限。
如需了解详情和最佳做法,请参阅 IAM 文档。
验证 Spark 和其他库依赖项
将您的 Spark 版本和其他库的版本与官方 Dataproc 版本列表进行比较,查找尚不可用的库。我们建议您使用受 Dataproc 官方支持的 Spark 版本。
如果需要添加库,您可以执行以下操作:
- 创建 Dataproc 集群的自定义映像。
- 在 Cloud Storage 中为您的集群创建初始化脚本。您可以使用初始化脚本来安装其他依赖项、复制二进制文件等。
- 使用 Gradle、Maven、Sbt 或其他工具,重新编译 Java 或 Scala 代码,并将不属于基本发行版的所有其他依赖项打包为“fat JAR”。
调整 Dataproc 集群大小
在任何集群配置中,无论是在本地还是在云中,集群大小对于 Spark 作业性能都至关重要。没有足够资源的 Spark 作业要么速度很慢,要么会失败,如果 Spark 作业没有足够的执行程序内存,便更是如此。如需调整任何 Hadoop 集群大小时需考虑事项的建议,请参阅 Hadoop 迁移指南的调整集群大小部分。
以下各部分介绍了调整集群大小的一些方式。
获取当前 Spark 作业的配置
查看当前 Spark 作业的配置方式,确保 Dataproc 集群足够大。如果从共享集群移动到多个 Dataproc 集群(一个集群对应一个批量工作负载),请查看每个应用的 YARN 配置,以便了解所需的执行程序数目、每个执行程序的 CPU 数目以及执行程序内存总量。如果您的本地集群设置了 YARN 队列,请查看哪些作业在共享每个队列的资源并确定瓶颈。借助此迁移,您可以移除本地集群中可能存在的任何资源限制。
选择机器类型和磁盘选项
选择虚拟机数量和虚拟机类型,以满足工作负载的需求。如果您决定使用本地 HDFS 进行存储,请确保虚拟机具有适当磁盘类型和大小。请务必在计算中包含驱动程序的资源需求。
每个虚拟机的网络出站流量上限为每个 vCPU 2 Gbps。向永久性磁盘或永久性 SSD 写入数据时产生的流量会计入此上限,因此,当数据写入这些磁盘时,vCPU 数量很少的虚拟机可能会受到限制。在重排阶段,当 Spark 将重排数据写入磁盘并通过网络在执行程序之间移动重排数据时,这种情况很可能发生。永久性磁盘需要至少 2 个 vCPU 才能达到最高写入性能,而永久性 SSD 需要 4 个 vCPU 才能达到最高写入性能。请注意,这些最小值未考虑流量,例如虚拟机之间的通信。此外,每个磁盘的大小均会影响其峰值性能。
您选择的配置将对 Dataproc 集群的费用产生影响。对于每个虚拟机和其他 Google Cloud 资源而言,Dataproc 价格未计入 Compute Engine 每实例价格。如需了解详情以及使用 Google Cloud 价格计算器来估算费用,请参阅 Dataproc 价格页面。
基准化分析性能及优化
如果已完成作业迁移阶段,但尚未停止在本地集群中运行 Spark 工作负载,请对 Spark 作业进行基准化分析并考虑任何优化。 请记住,如果配置并非最佳配置,您可以对集群调整大小。
Dataproc Serverless for Spark 的自动扩缩
使用 Dataproc Serverless 运行 Spark 工作负载,而无需预配和管理您自己的集群。指定工作负载参数,然后将工作负载提交到 Dataproc Serverless 服务。该服务将在托管式计算基础架构上运行工作负载,并根据需要自动扩缩资源。Dataproc Serverless 仅在执行工作负载时产生费用。
执行迁移
本部分讨论数据迁移、更改作业代码以及更改作业的运行方式。
迁移数据
在 Dataproc 集群中运行任何 Spark 作业之前,您需要将数据迁移到 Google Cloud。如需了解详情,请参阅数据迁移指南。
迁移 Spark 代码
计划好迁移到 Dataproc 并移动任何所需数据源之后,您可以迁移作业代码。如果两个集群之间的 Spark 版本没有差异,并且您希望将数据存储在 Cloud Storage 而不是本地 HDFS 上,您仅需将所有 HDFS 文件路径的前缀从 hdfs:// 更改为 gs://。
如果您使用的是不同 Spark 版本,请参阅 Spark 版本说明,比较两个版本,并相应地调整 Spark 代码。
您可以将 Spark 应用的 jar 文件复制到与 Dataproc 集群关联的 Cloud Storage 存储桶或复制到 HDFS 文件夹。下一部分介绍运行 Spark 作业的可用方式。
如果您决定使用工作流模板,我们建议您单独测试您计划添加的每个 Spark 作业。然后,您可以运行模板的最终测试,以确保模板的工作流正确(未缺失上游作业、输出存储在正确位置等等)。
运行作业
您可以通过以下方式运行 Spark 作业:
使用以下
gcloud命令:gcloud dataproc jobs submit [COMMAND]
其中:
[COMMAND]是spark、pyspark或spark-sql您可以使用
--properties选项设置 Spark 属性。如需了解详情,请参阅此命令的文档。使用将作业迁移到 Dataproc 前所使用的同一过程。Dataproc 集群必须可从本地访问,并且您需要使用相同的配置。
使用 Cloud Composer。 您可以创建环境(托管 Apache Airflow 服务器),将多个 Spark 作业定义为 DAG 工作流,然后运行整个工作流。
如需了解详情,请参阅提交作业指南。
在迁移后管理作业
将 Spark 作业迁移到 Google Cloud 后,请务必使用 Google Cloud 提供的工具和机制管理这些作业。在本部分中,我们会讨论日志记录、监控、访问集群、扩缩集群和优化作业。
使用日志记录和性能监控
在 Google Cloud 中,您可以使用 Cloud Logging 和 Cloud Monitoring 来查看和自定义日志,以及监控作业和资源。
要查找导致 Spark 作业失败的错误,最佳方法是查看 Spark 执行程序生成的驱动程序输出和日志。
您可以使用 Google Cloud 控制台或使用 gcloud 命令检索驱动程序输出。输出还存储在 Dataproc 集群的 Cloud Storage 存储分区中。如需了解详情,请参阅 Dataproc 文档中有关作业驱动程序输出的部分。
所有其他日志位于该集群机器内的不同文件中。您可以从 Spark 应用网页界面(或在程序结束后从 History Server)的执行程序标签中查看每个容器的日志。要查看每个日志,您需要浏览每个 Spark 容器。如果在应用代码中向 stdout 或 stderr 写入日志或输出,则日志会保存在 stdout 或 stderr 的重定向中。
在 Dataproc 集群中,YARN 默认配置为收集所有这些日志,并且这些日志在 Cloud Logging 中可用。Cloud Logging 可提供所有日志的简明汇总视图,因此您无需花费时间浏览容器日志来查找错误。
下图显示了 Google Cloud 控制台中的“Cloud Logging”页面。您可以通过在选择器菜单中选择集群名称来查看您的 Dataproc 集群中的所有日志。请务必在时间范围选择器中展开持续时间。
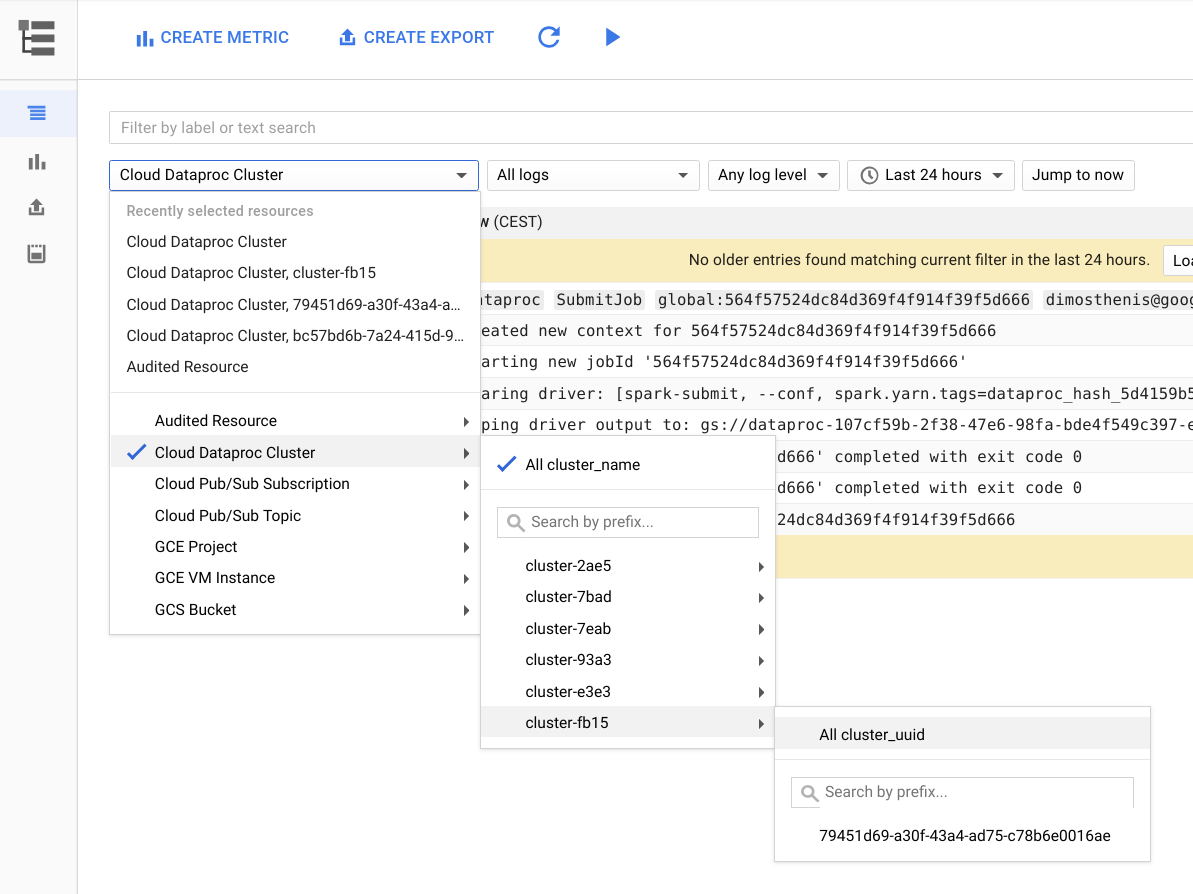
您可以通过按 ID 过滤,从 Spark 应用获取日志。您可以从驱动程序输出中获取应用 ID。
创建和使用标签
要提高日志查找速度,您可以为每个集群或每个 Dataproc 作业创建自己的标签,并使用这些标签。例如,您可以使用键 env 和值 exploration 创建标签,并将其用于数据探索作业。然后,您可以通过在 Cloud Logging 中使用 label:env:exploration 进行过滤,获取所有探索作业创建日志。请注意,此过滤器不会返回此作业的所有日志,只会返回资源创建日志。
设置日志级别
您可以使用以下 gcloud 命令设置驱动程序日志级别:
gcloud dataproc jobs submit hadoop --driver-log-levels
您可以从 Spark 上下文为应用的其余部分设置日志级别。 例如:
spark.sparkContext.setLogLevel("DEBUG")监控作业
Cloud Monitoring 可以监控集群的 CPU、磁盘、网络用量和 YARN 资源。您可以创建自定义信息中心以获取这些指标和其他指标的最新图表。Dataproc 在 Compute Engine 上运行。如果希望在图表中直观显示 CPU 使用率、磁盘 I/O 或网络指标,您需要选择 Compute Engine 虚拟机实例作为资源类型,然后按集群名称过滤。下图显示了输出的一个示例。
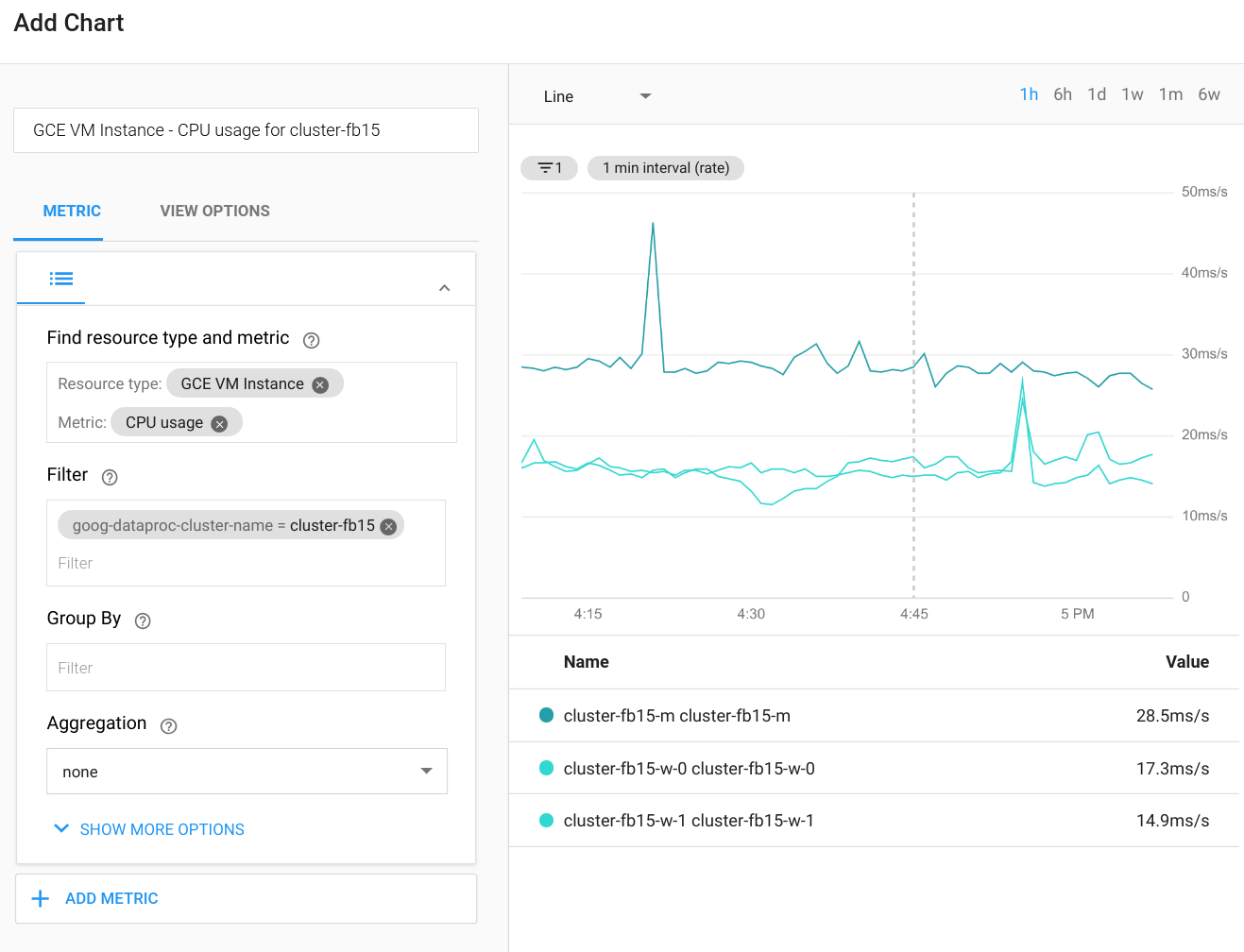
要查看 Spark 查询、作业、阶段或任务的指标,请连接到 Spark 应用的网页界面。下一部分将介绍如何执行此操作。要详细了解如何创建自定义指标,请参阅代理中的自定义指标指南。
访问 YARN
您可以通过设置 SSH 隧道,从 Dataproc 集群外部访问 YARN 资源管理器网页界面。最好使用轻量级 SOCKS 代理,而不是本地端口转发,因为这样浏览网页界面会更轻松。
以下网址对 YARN 访问非常有用:
YARN 资源管理器:
http://[MASTER_HOST_NAME]:8088Spark History Server:
http://[MASTER_HOST_NAME]:18080
如果 Dataproc 集群仅具有内部 IP 地址,您可以通过 VPN 连接或堡垒主机进行连接。如需了解详情,请参阅为内部专用的虚拟机选择连接选项。
扩缩 Dataproc 集群并调整其大小
可以通过增加或减少主要或辅助(抢占式)工作器的数量来扩缩 Dataproc 集群。Dataproc 还支持安全停用。
Spark 中的缩减受到许多因素的影响。请考虑以下因素:
建议不要使用
ExternalShuffleService,特别是对于定期缩减集群的情况。重排会使用执行计算阶段后写入工作器本地磁盘的结果,因此,即使不再使用计算资源,也无法移除该节点。Spark 在内存(RDD 和数据集)中缓存数据,用于缓存的执行程序从不会退出。因此,如果将工作器用于缓存,则绝不会安全停用。强行移除工作器会影响整体性能,因为缓存的数据会丢失。
默认情况下,Spark Streaming 停用动态分配,并且不会记录设置此行为的配置键。(您可以关注 Spark 问题对话中关于动态分配行为的讨论。)如果您在使用 Spark Streaming 或 Spark Structured Streaming,还必须明确停用动态分配,如前面的确定作业类型并对集群进行计划中所述。
通常,如果您运行的是批量或流式工作负载,我们建议您不要缩减 Dataproc 集群。
优化性能
本部分讨论在运行 Spark 作业时提高性能和减少费用的方法。
管理 Cloud Storage 文件大小
要获得最佳性能,请将 Cloud Storage 中的数据拆分成大小为 128 MB 到 1 GB 的文件。使用大量小型文件可能会产生瓶颈。如果您有许多小型文件,请考虑将文件复制到本地 HDFS 进行处理,然后将结果复制回来。
切换到 SSD 磁盘
如果执行大量重排操作或分区写入,请切换到 SSD 以提高性能。
将虚拟机放在同一可用区
要减少网络费用并提高性能,请使用用于 Dataproc 集群的 Cloud Storage 存储桶的同一区域位置。
默认情况下,如果您使用全球或区域 Dataproc 端点,在创建集群时,集群的虚拟机将放置在同一地区(或具有足够容量的同一区域中的另一个地区)中。您还可以在创建集群时指定地区。
使用抢占式虚拟机
Dataproc 集群可以将抢占式虚拟机实例用作工作器。与使用常规实例相比,这会降低非关键工作负载的每小时计算费用。但是,使用抢占式虚拟机时需要考虑以下因素:
- 抢占式虚拟机不能用于 HDFS 存储。
- 默认情况下,抢占式虚拟机是使用较小的启动磁盘大小创建的,如果您要运行重排操作频繁的工作负载,可能需要替换此配置。如需了解详情,请参阅 Dataproc 文档中有关抢占式虚拟机的页面。
- 我们不建议让占总数一半以上的工作器都成为抢占式工作器。
使用抢占式虚拟机时,我们建议您调整集群配置,以便更好地容忍任务失败,因为虚拟机的可用性可能会降低。例如,在 YARN 配置中进行如下设置:
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
您可以轻松地从集群中添加或移除抢占式虚拟机。如需了解详情,请参阅抢占式虚拟机。
后续步骤
- 请参阅关于如何将本地 Hadoop 基础架构迁移到 Google Cloud 的指南。
- 请参阅我们对 Dataproc 作业的生命周期的介绍。
- 探索有关 Google Cloud 的参考架构、图表和最佳实践。查看我们的 Cloud 架构中心。