Este tutorial é a segunda parte de uma série que mostra como criar uma solução completa para fornecer aos analistas de dados acesso seguro aos dados ao usar ferramentas do Business Intelligence (BI).
Este tutorial se destina a operadores e administradores de TI que configuram ambientes que fornecem recursos de dados e processamento para as ferramentas do Business Intelligence (BI) usadas pelos analistas de dados.
Tableau é usado como a ferramenta de BI neste tutorial. Para acompanhar este tutorial, você precisa ter o Tableau Desktop instalado na estação de trabalho.
A série é composta das seguintes partes:
- A primeira parte da série, Arquitetura para conectar software de visualização ao Hadoop no Google Cloud, define a arquitetura da solução, seus componentes e como os componentes interagem.
- Nesta segunda parte da série, você aprenderá a configurar os componentes de arquitetura que compõem a topologia do Hive completa no Google Cloud. Neste tutorial, são usadas ferramentas de código aberto do ecossistema Hadoop, com o Tableau como ferramenta de BI.
Os snippets de código neste tutorial estão disponíveis em um repositório do GitHub (em inglês). O repositório do GitHub também inclui arquivos de configuração do Terraform para ajudar você a configurar um protótipo funcional.
No tutorial, use o nome sara como a identidade fictícia do usuário
de um analista de dados. Essa identidade de usuário está no diretório LDAP usado pelo
Apache Knox e pelo Apache Ranger (ambos em inglês). Também é possível configurar grupos LDAP, mas esse procedimento está
fora do escopo deste tutorial.
Objetivos
- Crie uma configuração completa para que uma ferramenta de BI use dados de um ambiente do Hadoop.
- Autentique e autorize solicitações de usuários.
- Configure e use canais de comunicação segura entre a ferramenta de BI e o cluster.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
Como inicializar seu ambiente
-
In the Google Cloud console, activate Cloud Shell.
No Cloud Shell, defina variáveis de ambiente com o ID do projeto e a região e zonas dos clusters do Dataproc:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bÉ possível escolher qualquer região e zona. No entanto, você precisa mantê-las consistentes conforme segue este tutorial.
Como configurar uma conta de serviço
No Cloud Shell, crie uma conta de serviço.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"O cluster usa essa conta para acessar recursos do Google Cloud.
Adicione os seguintes papéis à conta de serviço:
- Worker do Dataproc: para criar e gerenciar clusters do Dataproc.
- Editor do Cloud SQL: para o Ranger se conectar ao banco de dados usando o Cloud SQL Proxy.
Descriptografador do Cloud KMS CryptoKey: para descriptografar as senhas criptografadas com o Cloud KMS.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Como criar o cluster de back-end
Nesta seção, você cria o cluster de back-end em que o Ranger está localizado. Você também cria o banco de dados do Ranger para armazenar as regras de política e uma tabela de amostra no Hive para aplicar as políticas do Ranger.
Crie a instância do banco de dados do Ranger
Crie uma instância do MySQL para armazenar as políticas do Apache Ranger:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Esse comando cria uma instância chamada
cloudsql-mysqlcom o tipo de máquinadb-n1-standard-1localizado na região especificada pela variável${REGION}. Para mais informações, consulte a documentação do Cloud SQL.Defina a senha da instância para o usuário
rootque se conecta a partir de qualquer host. Você pode usar a senha de exemplo para fins demonstrativos ou criar sua própria senha. Se você criar sua própria senha, use pelo menos oito caracteres, incluindo no mínimo uma letra e um número.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Criptografar as senhas
Nesta seção, você cria uma chave criptográfica para criptografar as senhas do Ranger e do MySQL. Para evitar a exfiltração, armazene a chave criptográfica no Cloud KMS. Por motivos de segurança, não é possível ver, extrair ou exportar os bits de chave.
Use a chave criptográfica para criptografar as senhas e gravá-las em arquivos.
Faça upload desses arquivos para um bucket do Cloud Storage para que possam ser
acessados pela conta de serviço que atua em nome dos clusters.
A conta de serviço pode descriptografar esses arquivos porque tem o
papel cloudkms.cryptoKeyDecrypter e o acesso aos arquivos e à chave
criptográfica. Mesmo que um arquivo seja exfiltrado, ele não pode ser descriptografado sem o papel
e a chave.
Como medida de segurança extra, você cria arquivos de senha separados para cada serviço. Essa ação minimiza a área possivelmente afetada se uma senha for exfiltrada.
Para mais informações sobre o gerenciamento de chaves, consulte a documentação do Cloud KMS.
No Cloud Shell, crie um keyring do Cloud KMS para armazenar as chaves:
gcloud kms keyrings create my-keyring --location globalPara criptografar suas senhas, crie uma chave criptográfica do Cloud KMS:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionCriptografe a senha de usuário administrador do Ranger usando a chave. É possível usar a senha de exemplo ou criar a sua. A senha precisa ter no mínimo oito caracteres, incluindo pelo menos uma letra e um número.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedCriptografe a senha de usuário administrador do banco de dados do Ranger com a chave:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedCriptografe sua senha raiz do MySQL com a chave:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedCrie um bucket do Cloud Storage para armazenar arquivos de senha criptografados:
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Faça upload dos arquivos de senha criptografados para o bucket do Cloud Storage:
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Crie o cluster
Nesta seção, você cria um cluster de back-end compatível com o Ranger. Para mais informações sobre o componente opcional do Ranger no Dataproc, consulte a página de documentação do componente Dataproc Ranger.
No Cloud Shell, crie um bucket do Cloud Storage para armazenar os registros de auditoria do Apache Solr:
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Exporte todas as variáveis necessárias para criar o cluster:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedPara facilitar, algumas das variáveis que você definiu antes são repetidas nesse comando para que você possa modificá-las conforme necessário.
As novas variáveis contêm:
- O nome do cluster de back-end.
- O URI da chave criptográfica para que a conta de serviço possa descriptografar as senhas.
- O URI dos arquivos que contêm as senhas criptografadas.
Se você usou um keyring ou chave diferente ou nomes de arquivo diferentes, use os valores correspondentes no comando.
Crie o cluster de back-end do Dataproc:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Esse comando tem as seguintes propriedades:
- As três linhas finais no comando são as propriedades do Hive para configurar o HiveServer2 no modo HTTP, para que o Apache Knox possa chamar o Apache Hive usando HTTP.
- Os outros parâmetros do comando funcionam da seguinte forma:
- O parâmetro
--optional-components=SOLR,RANGERativa o Apache Ranger e a dependência do Solr. - O parâmetro
--enable-component-gatewaypermite que o Gateway de componentes do Dataproc disponibilize o Ranger e outras interfaces de usuário do Hadoop diretamente da página do cluster no console do Google Cloud. Quando você define esse parâmetro, não há necessidade de tunelamento SSH no nó mestre de back-end. - O parâmetro
--scopes=default,sql-adminautoriza o Apache Ranger a acessar o banco de dados do Cloud SQL.
- O parâmetro
Se você precisar criar um metastore externo do Hive que persista além da vida útil de
qualquer cluster e possa ser usado em vários clusters, consulte Como usar o Apache Hive no Dataproc.
Para executar o procedimento, você precisa executar os exemplos de criação de tabela
diretamente no Beeline. Embora os comandos gcloud dataproc jobs submit hive usem o transporte binário Hive, esses comandos
não são compatíveis com o HiveServer2 quando estão configurados no modo HTTP.
Crie uma tabela Hive de amostra
No Cloud Shell, crie um bucket do Cloud Storage para armazenar um arquivo Apache Parquet de amostra:
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Copie uma amostra de arquivo Parquet disponível publicamente para o bucket:
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetConecte-se ao nó mestre do cluster de back-end criado na seção anterior usando SSH:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mO nome do nó mestre do cluster é o nome do cluster seguido por
-m.. Os nomes do nó mestre do cluster de alta disponibilidade têm um sufixo extra.Se for a primeira vez que você se conecta ao nó mestre pelo Cloud Shell, você precisará gerar chaves SSH.
No terminal que você abriu com SSH, conecte-se ao HiveServer2 local usando o Apache Beeline, pré-instalado no nó mestre:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Esse comando inicia a ferramenta de linha de comando Beeline e passa o nome do projeto do Cloud em uma variável de ambiente.
O Hive não está executando a autenticação de usuários, mas é necessário ter uma identidade de usuário para executar a maioria das tarefas. O usuário
adminaqui é um usuário padrão configurado no Hive. O provedor de identidade que você configura com o Apache Knox posteriormente neste tutorial lida com a autenticação do usuário para quaisquer solicitações provenientes de ferramentas de BI.No prompt do Beeline, crie uma tabela usando o arquivo Parquet que você copiou anteriormente para o bucket do Hive:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Verifique se a tabela foi criada corretamente:
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Os resultados das duas consultas aparecem no prompt do Beeline.
Saia da ferramenta de linha de comando Beeline:
!quitCopie o nome DNS interno do mestre do back-end:
hostname -A | tr -d '[:space:]'; echoUse esse nome na próxima seção como
backend-master-internal-dns-namepara configurar a topologia do Apache Knox. Use-o também para configurar um serviço no Ranger.Saia do terminal no nó:
exit
Como criar o cluster de proxy
Nesta seção, você cria o cluster de proxy que tem a ação de inicialização do Apache Knox.
Crie uma topologia
No Cloud Shell, clone o repositório do GitHub para ações de inicialização do Dataproc:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitCrie uma topologia para o cluster de back-end:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlO Apache Knox usa o nome do arquivo como caminho do URL para a topologia. Nesta etapa, você altera o nome para representar uma topologia chamada
hive-us-transactions. Acesse os dados fictícios de transação carregados no Hive em Criar uma tabela de amostra do HiveEdite o arquivo de topologia:
vi hive-us-transactions.xmlPara ver como os serviços de back-end são configurados, consulte o arquivo do descritor de topologia. Este arquivo define uma topologia que aponta para um ou mais serviços de back-end. Dois serviços são configurados com valores de amostra: WebHDFS e HIVE. O arquivo também define o provedor de autenticação para os serviços nesta topologia e as ACLs de autorização.
Adicione a amostra de identidade do usuário LDAP do analista de dados
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Adicionar a identidade de amostra permite que o usuário acesse o serviço de back-end do Hive por meio do Apache Knox.
Altere o URL do HIVE para apontar para o serviço do Hive do cluster de back-end. Você encontra a definição de serviço do HIVE na parte inferior do arquivo, em WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Substitua o marcador
<backend-master-internal-dns-name>pelo nome DNS interno do cluster de back-end que você comprou em Criar uma tabela de amostra do Hive.Salve o arquivo e feche o editor.
Para criar topologias adicionais, repita as etapas nesta seção. Crie um descritor XML independente para cada topologia.
Em Criar o cluster do proxy, copie esses arquivos para um bucket do Cloud Storage. Para criar novas topologias ou alterá-las depois de criar o cluster de proxy, modifique os arquivos e faça upload deles novamente para o bucket. A ação de inicialização do Apache Knox cria um cron job que copia regularmente as alterações do bucket para o cluster de proxy.
Configure o certificado SSL/TLS
Um cliente usa um certificado SSL/TLS quando se comunica com o Apache Knox. A ação de inicialização pode gerar um certificado autoassinado ou você pode fornecer seu certificado assinado pela CA.
No Cloud Shell, edite o arquivo de configuração geral do Apache Knox:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlSubstitua
HOSTNAMEpelo nome de DNS externo do nó do mestre de proxy como o valor do atributocertificate_hostname. Neste tutorial, uselocalhost.certificate_hostname: localhostMais adiante neste tutorial, crie um túnel SSH e o cluster de proxy para o valor
localhost.O arquivo de configuração geral do Apache Knox também contém o
master_keyque criptografa os certificados usados pelas ferramentas de BI para se comunicar com o cluster de proxy. Por padrão, essa chave é a palavrasecret.Se você estiver fornecendo seu próprio certificado, altere as duas propriedades a seguir:
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Salve o arquivo e feche o editor.
Se você estiver fornecendo seu próprio certificado, poderá especificá-lo na propriedade
custom_cert_name.
Crie o cluster de proxy
No Cloud Shell, crie um bucket do Cloud Storage.
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}Este bucket fornece as configurações criadas na seção anterior para a ação de inicialização do Apache Knox.
Copie todos os arquivos da pasta de ações de inicialização do Apache Knox para o bucket:
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveExporte todas as variáveis necessárias para criar o cluster:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bNesta etapa, algumas das variáveis que você definiu anteriormente são repetidas para que você possa fazer modificações conforme necessário.
Crie o cluster de proxy:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Verifique a conexão por meio do proxy
Depois que o cluster de proxy for criado, use o SSH para se conectar ao nó mestre a partir do Cloud Shell:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mNo terminal do nó mestre do cluster de proxy, execute a seguinte consulta:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Esse comando tem as seguintes propriedades:
- O comando
beelineusalocalhostem vez do nome interno de DNS porque o certificado gerado quando você configurou o Apache Knox especificalocalhostcomo o nome do host. Se você estiver usando seu próprio certificado ou nome DNS, use o nome de host correspondente. - A porta é
8443, que corresponde à porta SSL padrão do Apache Knox. - A linha que inicia
ssl=trueativa o SSL e fornece o caminho e a senha do SSL Trust Store a serem usados por aplicativos clientes, como o Beeline. - A linha
transportModeindica que a solicitação precisa ser enviada por HTTP e fornece o caminho do serviço HiveServer2. O caminho é composto pela palavra-chavegateway, o nome da topologia definido em uma seção anterior e o nome do serviço configurado na mesma topologia, neste casohive. - O parâmetro
-efornece a consulta a ser executada no Hive. Se você omitir esse parâmetro, abrirá uma sessão interativa na ferramenta de linha de comando Beeline. - O parâmetro
-nfornece uma identidade e uma senha de usuário. Nesta etapa, você está usando o usuárioadminpadrão do Hive. Nas próximas seções, você cria uma identidade de usuário analista e configura as credenciais e políticas de autorização para esse usuário.
Adicione um usuário ao armazenamento de autenticação
Por padrão, o Apache Knox inclui um provedor de autenticação baseado no
Apache Shiro.
Esse provedor é configurado com a autenticação BASIC em um
armazenamento LDAP do ApacheDS. Nesta seção, você adiciona uma amostra de identidade de usuário
do analista de dados sara ao armazenamento de autenticação.
No terminal no nó mestre do proxy, instale os utilitários LDAP:
sudo apt-get install ldap-utilsCrie um arquivo de Formato de troca de dados LDAP (LDIF, na sigla em inglês) para o novo usuário
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifAdicione o ID do usuário ao diretório LDAP:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389O parâmetro
-Despecifica o nome distinto (DN, na sigla em inglês) a ser vinculado quando o usuário representado porldapaddacessa o diretório. O DN precisa ser uma identidade de usuário que já esteja no diretório, neste caso, o usuárioadmin.Verifique se o novo usuário está no armazenamento de autenticação:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Os detalhes do usuário aparecem no seu terminal.
Copie e salve o nome DNS interno do nó mestre do proxy:
hostname -A | tr -d '[:space:]'; echoUse esse nome na próxima seção como
<proxy-master-internal-dns-name>para configurar a sincronização LDAP.Saia do terminal no nó:
exit
Como configurar a autorização
Nesta seção, você configura a sincronização de identidade entre o serviço LDAP e o Ranger.
Sincronize identidades de usuários no Ranger
Para garantir que as políticas do Ranger se apliquem às mesmas identidades de usuário que o Apache Knox, configure o daemon UserSync do Ranger para sincronizar as identidades do mesmo diretório.
Neste exemplo, você se conecta ao diretório LDAP local que está disponível por padrão com o Apache Knox. No entanto, em um ambiente de produção, recomendamos configurar um diretório de identidade externo. Para mais informações, consulte o Guia do usuário do Apache Knox e a documentação do Cloud Identity do Google Cloud, do Active Directory gerenciado e do AD federado.
Usando SSH, conecte-se ao nó mestre do cluster de back-end que você criou:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mNo terminal, edite o arquivo de configuração
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlDefina os valores das seguintes propriedades LDAP. Modifique as propriedades
usere não as propriedadesgroup, que têm nomes semelhantes.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Substitua o marcador
<proxy-master-internal-dns-name>pelo nome DNS interno do servidor proxy, que você recuperou na última seção.Essas propriedades são um subconjunto de uma configuração LDAP completa que sincroniza usuários e grupos. Para mais informações, consulte Como integrar o Ranger ao LDAP.
Salve o arquivo e feche o editor.
Reinicie o daemon
ranger-usersync:sudo service ranger-usersync restartExecute este comando:
grep sara /var/log/ranger-usersync/*Se as identidades forem sincronizadas, você verá pelo menos uma linha de registro para o usuário
sara.
Como criar políticas do Ranger
Nesta seção, você configura um novo serviço do Hive no Ranger. Você também configura e testa uma política do Ranger para limitar o acesso aos dados do Hive para uma identidade específica.
Configure o serviço do Ranger
No terminal do nó mestre, edite a configuração do Hive do Ranger:
sudo vi /etc/hive/conf/ranger-hive-security.xmlEdite a propriedade
<value>da propriedaderanger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Salve o arquivo e feche o editor.
Reinicie o serviço do administrador do HiveServer2:
sudo service hive-server2 restartVocê está pronto para criar políticas do Ranger.
Configure o serviço no Admin Console do Ranger
No console do Google Cloud, acesse a página Dataproc.
Clique no nome do cluster de back-end e, depois, em Interfaces da Web.
Como criou seu cluster com o Gateway de componentes, você vê uma lista dos componentes do Hadoop que estão instalados no cluster.
Clique no link Ranger para abrir o console do Ranger.
Faça login no Ranger com o usuário
admine sua senha de administrador do Ranger. O console do Ranger mostra a página "Gerenciador de serviços" com uma lista de serviços.Clique no sinal de mais no grupo do HIVE para criar um novo serviço do Hive.

No formulário, defina os seguintes valores:
- Nome do serviço:
ranger-hive-service-01. Você definiu esse nome anteriormente no arquivo de configuraçãoranger-hive-security.xml. - Nome de usuário:
admin - Senha:
admin-password jdbc.driverClassName: mantenha o nome padrão comoorg.apache.hive.jdbc.HiveDriverjdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Substitua o marcador
<backend-master-internal-dns-name>pelo nome recuperado em uma seção anterior.
- Nome do serviço:
Clique em Adicionar.
Cada instalação do plug-in do Ranger é compatível com um único serviço do Hive. Uma maneira fácil de configurar outros serviços do Hive é iniciar outros clusters de back-end. Cada cluster tem o próprio plug-in do Ranger. Esses clusters podem compartilhar o mesmo banco de dados do Ranger para que você tenha uma visão unificada de todos os serviços sempre que acessar o Admin Console do Ranger de qualquer um desses clusters.
Configurar uma política do Ranger com permissões limitadas
A política permite que a amostra de usuário LDAP do analista sara acesse colunas
específicas da tabela do Hive.
Na janela do Service Manager, clique no nome do serviço que você criou.
O Admin Console do Ranger mostra a janela Políticas.
Clique em Adicionar nova política.
Com essa política, você concede permissão a
sarapara ver apenas as colunassubmissionDateetransactionTypedas transações da tabela.No formulário, defina os seguintes valores:
- Nome da política: qualquer nome, por exemplo,
allow-tx-columns - Banco de dados:
default - Tabela:
transactions - Coluna do Hive:
submissionDate, transactionType - Permitir condições:
- Selecionar usuário:
sara - Permissões:
select
- Selecionar usuário:
- Nome da política: qualquer nome, por exemplo,
Na parte inferior da tela, clique em Adicionar.
Testar a política com Beeline
No terminal do nó mestre, inicie a ferramenta de linha de comando Beeline com o usuário
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Ainda que a ferramenta de linha de comando Beeline não exija a senha, é necessário fornecer uma senha para executar o comando anterior.
Execute a consulta a seguir para verificar se o Ranger o bloqueou.
SELECT * FROM transactions LIMIT 10;A consulta inclui a coluna
transactionAmount, quesaranão tem permissão para selecionar.Um erro
Permission deniedé exibido.Verifique se o Ranger permite a seguinte consulta:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Saia da ferramenta de linha de comando Beeline:
!quitSaia do terminal:
exitNo console do Ranger, clique na guia Auditoria. Os eventos negados e os permitidos são exibidos. É possível filtrar os eventos pelo nome de serviço que você definiu anteriormente, por exemplo,
ranger-hive-service-01.
Como se conectar usando uma ferramenta de BI
A etapa final neste tutorial é consultar os dados do Hive usando o Tableau Desktop.
Criar regra de firewall
- Copie e salve seu endereço IP público.
No Cloud Shell, crie uma regra de firewall que abra a porta TCP
8443para entrada da sua estação de trabalho:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Substitua o marcador
<your-public-ip>pelo seu endereço IP público.Aplique a tag de rede da regra de firewall ao nó mestre do cluster de proxy:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Criar um túnel SSH
Esse procedimento só será necessário se você estiver usando um certificado
autoassinado válido para localhost. Se você estiver usando seu próprio certificado ou se o nó mestre de proxy
tiver seu próprio nome de DNS externo, pule para Conectar ao Hive.
No Cloud Shell, gere o comando para criar o túnel:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Execute
gcloud initpara autenticar sua conta de usuário e conceder permissões de acesso.Abra um terminal na estação de trabalho.
Crie um túnel SSH para encaminhar a porta
8443. Copie o comando gerado na primeira etapa, cole-o no terminal da estação de trabalho e execute o comando.Deixe o terminal aberto para que o túnel permaneça ativo.
Conecte-se ao Hive
- Na estação de trabalho, instale o driver ODBC do Hive.
- Abra o Tableau Desktop ou reinicie-o se estiver aberto.
- Na página inicial, em Conectar/a um servidor, selecione Mais.
- Pesquise e selecione Cloudera Hadoop.
Usando o usuário LDAP de analista de dados de amostra
saracomo identidade do usuário, preencha os campos da seguinte maneira:- Servidor: se você criou um túnel, use
localhost. Se você não criou um túnel, use o nome DNS externo do seu nó mestre do proxy. - Porta:
8443 - Tipo:
HiveServer2 - Autenticação:
UsernameePassword - Nome de usuário:
sara - Senha:
sara-password - Caminho HTTP:
gateway/hive-us-transactions/hive - Requerer SSL:
yes
- Servidor: se você criou um túnel, use
Clique em Fazer login.

Consultar dados do Hive
- Na tela Fonte de dados, clique em Selecionar esquema e pesquise
default. Clique duas vezes no nome do esquema
default.O painel Tabela será carregado.
No painel Tabela, clique duas vezes em Novo SQL personalizado.
A janela Editar SQL personalizado é aberta.
Insira a seguinte consulta, que seleciona a data e o tipo de transação na tabela de transações:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Clique em OK.
Os metadados da consulta são recuperados do Hive.
Clique em Atualizar agora.
O Tableau recupera os dados do Hive porque
saraestá autorizado a ler essas duas colunas da tabelatransactions.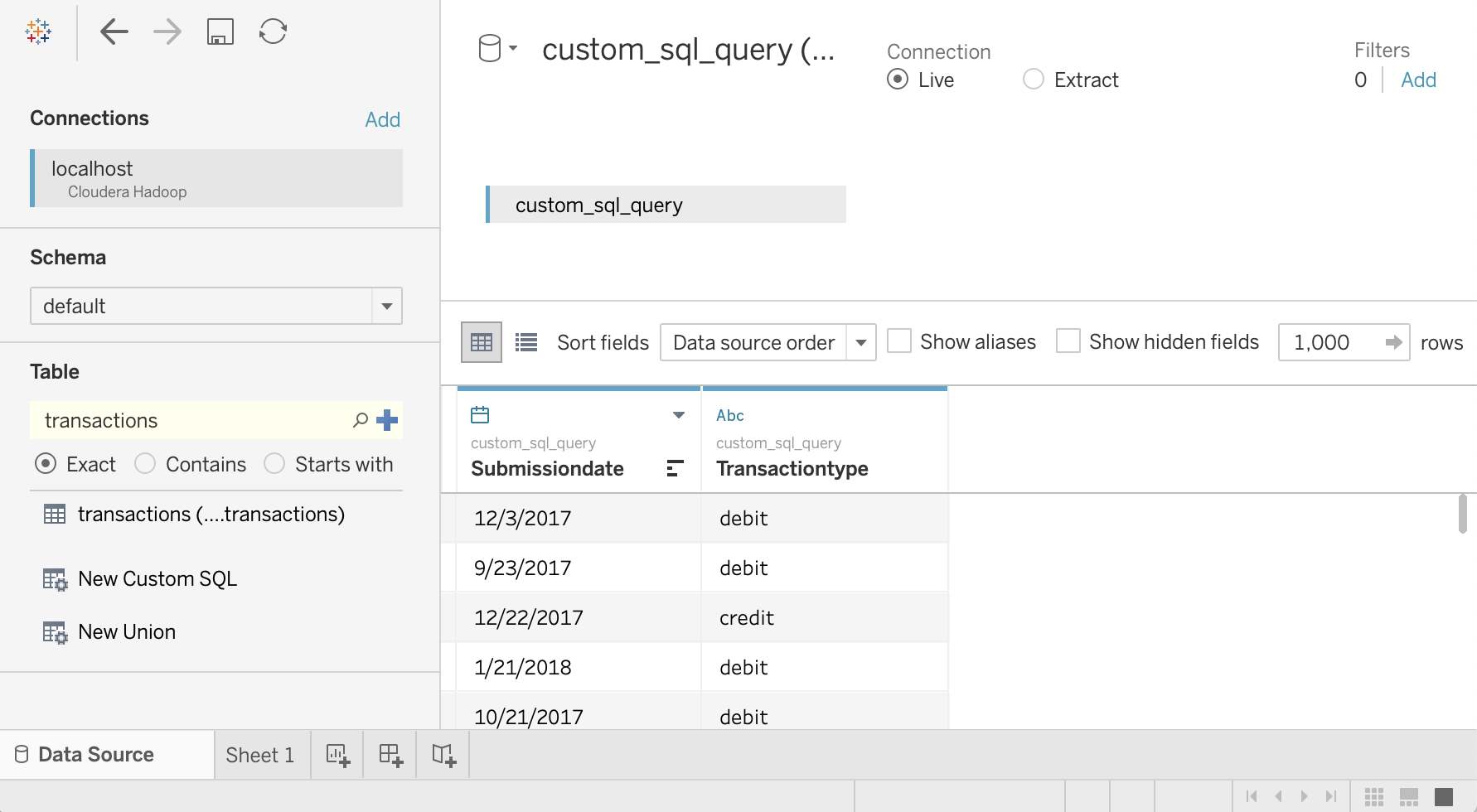
Para tentar selecionar todas as colunas da tabela
transactions, no painel Tabela, clique duas vezes em Novo SQL personalizado novamente. A janela Editar SQL personalizado é aberta.Digite a seguinte consulta:
SELECT * FROM `default`.`transactions`Clique em OK. A seguinte mensagem de erro é exibida:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Como
saranão tem autorização do Ranger para ler a colunatransactionAmount, essa mensagem é esperada. Neste exemplo, mostramos como limitar os dados que os usuários do Tableau podem acessar.Para ver todas as colunas, repita as etapas usando o usuário
admin.Feche o Tableau e a janela do terminal.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Leia a primeira parte desta série: Arquitetura para conectar o software de visualização ao Hadoop no Google Cloud.
- Leia o Guia de segurança de migração do Hadoop.
- Saiba como migrar jobs do Apache Spark para o Dataproc.
- Aprenda a migrar a infraestrutura do Hadoop local para o Google Cloud.
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.