Questo documento descrive un'architettura di riferimento che ti aiuta a creare un meccanismo di esportazione dei log scalabile, tollerante ai guasti e pronto per la produzione che trasmette in streaming log ed eventi dalle tue risorse in Google Cloud a Splunk. Splunk è un popolare strumento di analisi che offre sicurezza e osservabilità unificati completamente gestita. Infatti, puoi scegliere di esportare i dati di logging in Splunk Enterprise o Splunk Cloud Platform. Se sei un amministratore, puoi utilizzare questa architettura anche per le operazioni IT o per casi d'uso di sicurezza. Per eseguire il deployment di questa architettura di riferimento, consulta Esegui il deployment di flussi di log da Google Cloud a Splunk.
Questa architettura di riferimento presuppone una gerarchia delle risorse simile nel seguente diagramma. Tutti i log delle risorse Google Cloud a livello di organizzazione, cartella e progetto vengono raccolti in un sink aggregato. Quindi, il sink aggregato invia questi log a una pipeline di esportazione dei log, che elabora i log e li esporta in Splunk.

Architettura
Il seguente diagramma mostra l'architettura di riferimento utilizzata per il deployment di questa soluzione. Questo diagramma mostra come i dati dei log fluiscono da Google Cloud a Splunk.

Questa architettura include i seguenti componenti:
- Cloud Logging: per avviare il processo, Cloud Logging raccoglie i log in un'area di destinazione dei log aggregata a livello di organizzazione e li invia a Pub/Sub.
- Pub/Sub: il servizio Pub/Sub crea un singolo argomento e una sottoscrizione per i log e li inoltra alla pipeline Dataflow principale.
- Dataflow: in questa architettura di riferimento sono presenti due
pipeline Dataflow:
- Pipeline Dataflow principale: al centro del processo, la pipeline Dataflow principale è Pipeline di flusso da Pub/Sub a Splunk che estrae i log dalla Pub/Sub e le consegna a Splunk.
- Pipeline Dataflow secondaria: parallela alla pipeline Dataflow principale, la pipeline Dataflow secondaria è una pipeline di streaming Pub/Sub to Pub/Sub per riprodurre i messaggi in caso di mancata consegna.
- Splunk: alla fine del processo, Splunk Enterprise o Splunk Cloud La piattaforma agisce come raccoglitore di eventi HTTP (HEC) e riceve i log per ulteriori e analisi. Puoi eseguire il deployment di Splunk on-premise, Google Cloud come SaaS o tramite un approccio ibrido.
Caso d'uso
Questa architettura di riferimento utilizza un approccio cloud basato su push. In questo basato su push, utilizzerai il comando Pub/Sub to Splunk Dataflow modello per trasmettere i log a un raccoglitore di eventi HTTP Splunk (HEC) di Google. L'architettura di riferimento illustra anche la pipeline Dataflow della capacità e come gestire potenziali errori di distribuzione a causa di problemi temporanei del server o della rete.
Sebbene questa architettura di riferimento si concentri sui log di Google Cloud, la stessa architettura può essere utilizzata per esportare altri dati di Google Cloud, come le modifiche in tempo reale delle risorse e i risultati di sicurezza. Se integri i log di Cloud Logging, puoi continuare a utilizzare i servizi partner esistenti come Splunk come soluzione di analisi dei log unificata.
Il metodo push per l'importazione in streaming dei dati di Google Cloud in Splunk presenta i seguenti vantaggi:
- Servizio gestito. In qualità di servizio gestito, Dataflow gestisce le risorse richieste in Google Cloud per attività di elaborazione dei dati come l'esportazione dei log.
- Carico di lavoro distribuito. Questo metodo ti consente di distribuire i carichi di lavoro su più worker per l'elaborazione in parallelo, quindi non esiste un singolo punto di errore.
- Sicurezza. Poiché Google Cloud esegue il push dei dati a Splunk HEC, non c'è nessun carico di manutenzione e sicurezza associato alla creazione e la gestione delle chiavi degli account di servizio.
- Scalabilità automatica. Il servizio Dataflow scala automaticamente il numero di worker in risposta alle variazioni del volume dei log e del backlog in entrata.
- Tolleranza di errore. In caso di problemi temporanei al server o alla rete, basato su push tenta automaticamente di inviare di nuovo i dati a Splunk HEC. it supporta anche gli argomenti non elaborati (noti anche come messaggi non recapitabili argomenti) per qualsiasi i messaggi di log non recapitabili per evitare la perdita di dati.
- Semplicità. Eviti il sovraccarico di gestione e il costo di esecuzione di uno o più forwarder pesanti in Splunk.
Questa architettura di riferimento si applica ad attività in molti settori verticali diversi, compresi quelli regolamentati come i servizi farmaceutici e finanziari. Quando scegli di esportare i dati di Google Cloud in Splunk, potresti farlo per i seguenti motivi:
- Analisi dell'attività
- operazioni IT
- Monitoraggio delle prestazioni delle applicazioni
- Operazioni di sicurezza
- Conformità
Alternative di progettazione
Un metodo alternativo per l'esportazione dei log in Splunk è quello che ti consente di estrarre i log da Google Cloud. In questo metodo basato su pull, utilizzi le API Google Cloud per recuperare i dati tramite il plug-in Splunk per Google Cloud. Puoi scegliere di utilizzare il metodo basato su pull nelle seguenti situazioni:
- Il tuo deployment di Splunk non offre un endpoint HEC di Splunk.
- Il volume del log è basso.
- Vuoi analizzare le metriche di Cloud Monitoring, gli oggetti Cloud Storage, i metadati dell'API Cloud Resource Manager o i log a basso volume.
- Gestisci già uno o più spedizionieri pesanti in Splunk.
- Utilizzi il Gestore dei dati di input per Splunk Google Cloud.
Inoltre, tieni presente le considerazioni aggiuntive che si presentano quando utilizzi questo metodo basato su pull:
- Un singolo worker gestisce il carico di lavoro di importazione dati, il che non offre di scalabilità automatica.
- In Splunk, l'utilizzo di un forwarder pesante per estrarre i dati potrebbe causare un singolo punto di errore.
- Il metodo basato su pull richiede di creare e gestire le chiavi degli account di servizio utilizzate per configurare il componente aggiuntivo Splunk per Google Cloud.
Per attivare il componente aggiuntivo Splunk, segui questi passaggi:
- In Splunk, segui le istruzioni di Splunk per installare il componente aggiuntivo Splunk per Google Cloud.
- In Google Cloud, crea un argomento Pub/Sub per esportare i tuoi dati di logging.
- Crea una sottoscrizione pull Pub/Sub per questo argomento.
- Crea un account di servizio.
- Crea una chiave dell'account di servizio per l'account di servizio che hai appena creato.
- Concedi al visualizzatore Pub/Sub (
roles/pubsub.viewer) e i ruoli di Sottoscrittore Pub/Sub (roles/pubsub.subscriber) alla di account di servizio per consentire all'account di ricevere messaggi sottoscrizione Pub/Sub. In Splunk, segui le istruzioni di Splunk per configurare un nuovo input Pub/Sub nel componente aggiuntivo Splunk per Google Cloud.
I messaggi Pub/Sub dell'esportazione dei log vengono visualizzati in Splunk.
Per verificare che il componente aggiuntivo funzioni, segui questi passaggi:
- In Cloud Monitoring, apri Metrics Explorer.
- Nel menu Risorse, seleziona
pubsub_subscription. - Nelle categorie Metrica, seleziona
pubsub/subscription/pull_message_operation_count. - Monitora il numero di operazioni di pull dei messaggi per uno o due minuti.
Note sul layout
Le seguenti linee guida possono aiutarti a sviluppare un'architettura che soddisfi i requisiti della tua organizzazione in termini di sicurezza, privacy, conformità, efficienza, affidabilità, tolleranza di errore, prestazioni e ottimizzazione dei costi.
Sicurezza, privacy e conformità
Le seguenti sezioni descrivono le considerazioni sulla sicurezza per questo riferimento dell'architettura:
- Utilizzare indirizzi IP privati per proteggere le VM che supportano la pipeline Dataflow
- Abilitare l'accesso privato Google
- Limita il traffico in entrata di Splunk HEC agli indirizzi IP noti utilizzati da Cloud NAT
- Archivia il token HEC Splunk in Secret Manager
- Crea un account di servizio worker Dataflow personalizzato per seguire le best practice relative privilegio minimo minimi
- Configurare la convalida SSL per un certificato CA principale interno se utilizzi una CA privata
Usa indirizzi IP privati per proteggere le VM che supportano la pipeline Dataflow
Devi limitare l'accesso alle VM worker utilizzate Dataflow. Per limitare l'accesso, esegui il deployment di queste VM con e i loro indirizzi IP privati. Tuttavia, queste VM devono anche essere in grado di utilizzare HTTPS inviare in Splunk i log esportati in modalità flusso e accedere a internet. Per fornire Per l'accesso HTTPS è necessario un gateway Cloud NAT che alloca automaticamente gli indirizzi IP Cloud NAT alle VM che ne hanno bisogno. Assicurati di mappare la subnet che contiene le VM al gateway Cloud NAT.
Abilita l'accesso privato Google
Quando crei un gateway Cloud NAT, l'accesso privato Google diventa attivati automaticamente. Tuttavia, per consentire ai worker Dataflow di indirizzi IP privati per accedere agli indirizzi IP esterni che Google le API e i servizi Cloud, devi anche abilitare manualmente Accesso privato Google per la subnet.
Limita il traffico in entrata di Splunk HEC agli indirizzi IP noti utilizzati da Cloud NAT
Se vuoi limitare il traffico in Splunk HEC a un sottoinsieme di IP noti indirizzi IP statici, puoi prenotare indirizzi IP statici e assegnarli manualmente il gateway Cloud NAT. A seconda del deployment di Splunk, puoi quindi configura le regole firewall in entrata di Splunk HEC utilizzando questi indirizzi IP statici indirizzi IP esterni. Per saperne di più su Cloud NAT, consulta Configurare e gestire Network Address Translation con Cloud NAT.
Memorizza il token HEC di Splunk in Secret Manager
Quando esegui il deployment della pipeline Dataflow, puoi passare il valore del token in uno dei seguenti modi:
- Testo normale
- Testo crittografato con una chiave Cloud Key Management Service
- Versione del secret criptata e gestita da Secret Manager
In questa architettura di riferimento viene utilizzata l'opzione di Secret Manager perché questa opzione offre il modo meno complesso ed efficiente il tuo token HEC Splunk. Questa opzione impedisce anche la fuga del token HEC di Splunk dalla console Dataflow o dai dettagli del job.
Un secret in Secret Manager contiene una raccolta di versioni del secret. Ogni versione del secret archivia i dati effettivi del secret, come lo Splunk token HEC. Se in un secondo momento scegli di ruotare il token HEC di Splunk come misura di sicurezza aggiuntiva, puoi aggiungere il nuovo token come nuova versione del secret. Per informazioni generali sulla rotazione dei secret, consulta Informazioni pianificazioni della rotazione.
Crea un account di servizio worker Dataflow personalizzato per seguire le best practice dei privilegi minimi
I worker nella pipeline Dataflow utilizzano l'account di servizio worker Dataflow per accedere alle risorse ed eseguire operazioni. Per impostazione predefinita, i worker utilizzano l'account di servizio predefinito di Compute Engine del progetto come account di servizio dei worker, il che consente loro di disporre di autorizzazioni ampie per tutte le risorse del progetto. Tuttavia, per eseguire i job Dataflow in produzione, ti consigliamo di creare un account di servizio personalizzato con un insieme minimo di ruoli e autorizzazioni. Puoi quindi assegnare questo account di servizio personalizzato dei worker della pipeline Dataflow.
Il seguente diagramma elenca i ruoli richiesti da assegnare a un servizio per consentire ai worker Dataflow di eseguire Job Dataflow riuscito.
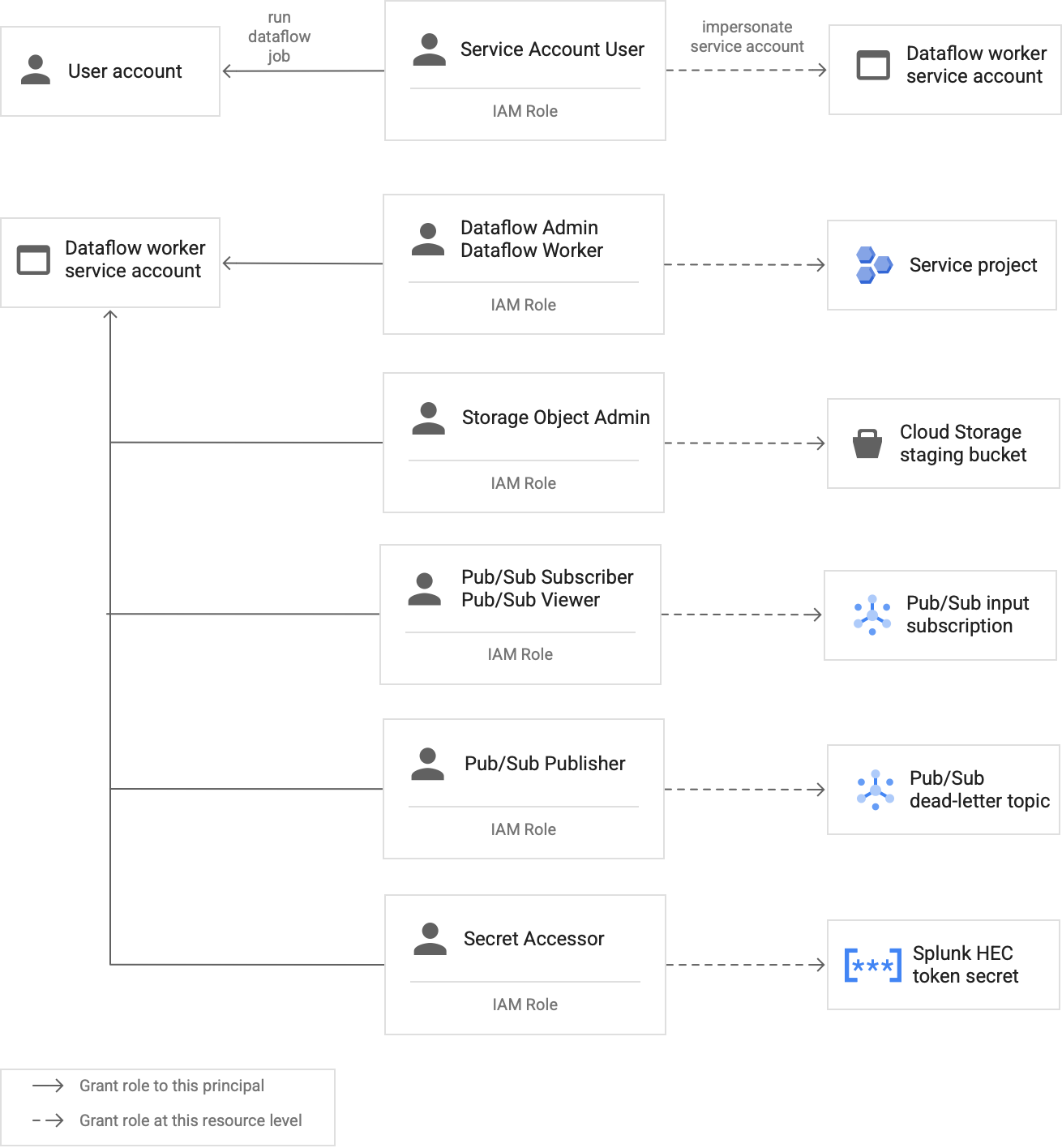
Come mostrato nel diagramma, devi assegnare i seguenti ruoli all'account di servizio per il tuo worker Dataflow:
- Dataflow Admin
- Dataflow Worker
- Storage Object Admin
- Pub/Sub Subscriber
- Pub/Sub Viewer
- Publisher Pub/Sub
- Funzione di accesso ai secret
Per maggiori dettagli sui ruoli che devi assegnare al Account di servizio worker Dataflow, consulta Concedi ruoli e accesso al servizio worker Dataflow Google Cloud della guida al deployment.
Configura la convalida SSL con un certificato CA radice interno se utilizzi una CA privata
Per impostazione predefinita, la pipeline Dataflow utilizza l'archivio di attendibilità predefinito del worker Dataflow per convalidare il certificato SSL per l'endpoint HEC di Splunk. Se utilizzi un certificato privato l'autorità di certificazione (CA) per firmare un certificato SSL utilizzato dalla Splunk HEC puoi importare il certificato CA radice interno nell'archivio di attendibilità. Dataflow i worker possono quindi utilizzare il certificato importato per la convalida del certificato SSL.
Puoi utilizzare e importare il tuo certificato CA radice interno per Splunk con certificati autofirmati o con firma privata. Puoi anche disattiva completamente la convalida SSL per scopi di sviluppo e test interni . Questo metodo CA radice interno è ideale per i deployment di Splunk interni non rivolti a internet.
Per ulteriori informazioni, consulta i parametri del modello Dataflow da Pub/Sub a SplunkrootCaCertificatePath e disableCertificateValidation.
Efficienza operativa
Le seguenti sezioni descrivono le considerazioni sull'efficienza operativa per questa architettura di riferimento:
- Usa la funzione definita dall'utente per trasformare i log o gli eventi in corso
- Riprodurre di nuovo i messaggi non elaborati
Utilizza la funzione definita dall'utente per trasformare i log o gli eventi in corso
Il modello Dataflow da Pub/Sub a Splunk supporta funzioni definite dall'utente per la trasformazione di eventi personalizzati. Alcuni esempi di casi d'uso includono l'arricchimento dei record con campi aggiuntivi, l'oscuramento di alcuni campi sensibili o l'esclusione dei record indesiderati. Le funzioni definite dall'utente ti consentono di modificare il formato dell'output della pipeline di Dataflow senza dover ricompilare o gestire il codice del modello stesso. Questa architettura di riferimento utilizza una UDF per gestire i messaggi che la pipeline non è in grado di inviare a Splunk.
Riproduci i messaggi non elaborati
A volte, la pipeline riceve errori di recapito e non tenta di inviare nuovamente il messaggio. In questo caso, Dataflow invia questi dati non elaborati a un argomento non elaborato, come illustrato nel diagramma seguente. Dopo aver corretto la causa principale del mancato recapito, puoi riprodurre i messaggi non elaborati.
I passaggi che seguono descrivono la procedura mostrata nel diagramma precedente:
- La pipeline di invio principale da Pub/Sub a Splunk inoltra automaticamente i messaggi non recapitabili all'argomento non elaborato per le indagini degli utenti.
L'operatore o il Site Reliability Engineer (SRE) esaminano la mancata riuscita messaggi nella sottoscrizione non elaborata. L'operatore risolve i problemi corregge la causa principale dell'errore di recapito. Ad esempio, la correzione di un modello HEC l'errata configurazione del token potrebbe abilitare la consegna dei messaggi.
L'operatore attiva la pipeline di messaggi con errori di ripetizione. Questa pipeline da Pub/Sub a Pub/Sub (evidenziata nella sezione tratteggiata del diagramma precedente) è una pipeline temporanea che sposta i messaggi con errori dall'abbonamento non elaborato all'argomento sink dei log originale.
La pipeline di distribuzione principale rielabora i messaggi precedentemente non riusciti. Questo passaggio richiede che la pipeline utilizzi la funzione UDF di esempio per il rilevamento e la decodifica corretti dei payload dei messaggi con errori. Il codice seguente mostra la parte della funzione che implementa questa logica di decodifica condizionale, incluso un conteggio dei tentativi di invio per finalità di monitoraggio:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Affidabilità e tolleranza di errore
Per quanto riguarda l’affidabilità e la tolleranza agli errori, la seguente tabella, Tabella 1,
elenca alcuni possibili errori di recapito di Splunk. Nella tabella sono inoltre elencate le
attributi errorMessage corrispondenti registrati dalla pipeline con ciascuno
prima di inoltrare questi messaggi all'argomento non elaborato.
Tabella 1: tipi di errori di importazione di Splunk
| Tipo di errore di recapito | Nuovo tentativo automatico da parte della pipeline? | Esempio di attributo errorMessage |
|---|---|---|
Errore di rete temporaneo |
Sì |
o
|
Errore 5xx del server Splunk |
Sì |
|
Errore 4xx dello Splunk Server |
No |
|
Server Splunk non attivo |
No |
|
Certificato SSL Splunk non valido |
No |
|
Errore di sintassi JavaScript nella funzione definita dall'utente |
No |
|
In alcuni casi, la pipeline applica il backoff
esponenziale e
prova automaticamente a recapitare il messaggio di nuovo. Ad esempio, quando il
server Splunk genera un codice di errore 5xx, la pipeline deve recapitare il messaggio. Questi codici di errore si verificano quando l'endpoint HEC di Splunk è sovraccaricato.
In alternativa, potrebbe esserci un problema persistente che impedisce a un messaggio di inviate all'endpoint HEC. Per questi problemi persistenti, la pipeline non prova a recapitare nuovamente il messaggio. Di seguito sono riportati alcuni esempi di problemi persistenti:
- Un errore di sintassi nella funzione UDF.
- Un token HEC non valido che causa la generazione da parte del server Splunk di una risposta del server
4xx"Forbidden".
Ottimizzazione delle prestazioni e dei costi
In merito all'ottimizzazione delle prestazioni e dei costi, devi determinare le dimensioni e la velocità massime per la pipeline Dataflow. Devi calcolare i valori corretti di dimensioni e velocità effettiva in modo che la pipeline possa gestire il picco del volume di log giornaliero (GB/giorno) e la frequenza dei messaggi di log (eventi al secondo, o EPS) dalla sottoscrizione Pub/Sub upstream.
Devi selezionare i valori di dimensione e velocità effettiva in modo che il sistema non uno dei seguenti problemi:
- Ritardi causati da backlogging o limitazione dei messaggi.
- Costi aggiuntivi dovuti al provisioning eccessivo di una pipeline.
Dopo aver eseguito i calcoli delle dimensioni e del throughput, puoi utilizzare i risultati per configurare una pipeline ottimale che bilanci prestazioni e costi. A configurare la capacità della pipeline, utilizza le seguenti impostazioni:
- I flag Tipo di macchina e Numero di macchine fanno parte del comando gcloud che esegue il deployment del job Dataflow. Questi flag consentono di definire il tipo e il numero di VM da utilizzare.
- I parametri Parallelism e Conteggio batch fanno parte del modulo Pub/Sub to Splunk Dataflow modello. Questi parametri sono importanti per aumentare l'EPS evitando al contempo di sovraccaricare l'endpoint HEC di Splunk.
Le sezioni seguenti forniscono una spiegazione di queste impostazioni. Ove applicabile, queste sezioni forniscono anche formule e calcoli di esempio che utilizzano ciascuna formula. Questi calcoli di esempio e i valori risultanti presuppongono con le seguenti caratteristiche:
- Genera 1 TB di log al giorno.
- Ha una dimensione media del messaggio di 1 kB.
- Ha una frequenza di picco dei messaggi sostenuta pari al doppio della frequenza media.
Poiché il tuo ambiente Dataflow è unico, sostituisci valori di esempio con i valori della tua organizzazione mentre lavori passaggi.
Tipo di macchina
Best practice: imposta il parametro
--worker-machine-type flag a n1-standard-4 per
selezionare una dimensione macchina che offra il miglior rapporto costo/prestazioni.
Poiché il tipo di macchina n1-standard-4 può gestire 12.000 EPS, ti consigliamo di utilizzare questo tipo di macchina come linea di base per tutti i tuoi worker Dataflow.
Per questa architettura di riferimento, imposta il flag --worker-machine-type su un valore
di n1-standard-4.
Conteggio macchine
Best practice: imposta il parametro
--max-workers per controllare il numero massimo di
i lavoratori necessari a gestire il picco previsto per gli utili per azione.
La scalabilità automatica di Dataflow consente al servizio di modificare in modo adattativo il numero di worker utilizzati per eseguire la pipeline di streaming quando si verificano variazioni nell'utilizzo e nel carico delle risorse. Per evitare il provisioning eccessivo durante la scalabilità automatica, ti consigliamo di definire sempre il numero massimo di macchine virtuali utilizzate come worker Dataflow. Definisci il numero massimo di
macchine virtuali con il flag --max-workers quando esegui il deployment della
pipeline Dataflow.
Dataflow esegue il provisioning statico del componente di archiviazione nel modo seguente:
Una pipeline di scalabilità automatica esegue il deployment di un disco permanente dati per ogni potenziale per il worker in modalità flusso. La dimensione predefinita del disco permanente è di 400 GB e hai impostato il numero massimo di worker con il flag
--max-workers. I dischi vengono montati sui worker in esecuzione in qualsiasi momento, inclusa l'avvio.Poiché ogni istanza worker è limitata a 15 dischi permanenti, il numero minimo il numero di worker iniziali è
⌈--max-workers/15⌉. Quindi, se il valore predefinito è--max-workers=20, l'utilizzo (e il costo) della pipeline è il seguente:- Archiviazione: statica con 20 dischi permanenti.
- Computing: dinamico con un minimo di 2 istanze worker (⌈20/15⌉ = 2) e un massimo di 20.
Questo valore equivale a 8 TB di un disco permanente. Queste dimensioni Persistent Disk potrebbe comportare costi inutili se i dischi non sono usato completamente, soprattutto se solo uno o due worker eseguono la maggior parte delle volte.
Per determinare il numero massimo di worker necessari per la pipeline, usa le seguenti formule in sequenza:
Determina gli eventi al secondo (EPS) medi utilizzando la seguente formula:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Calcolo di esempio: dati i valori di esempio di 1 TB di log al giorno con una dimensione media del messaggio di 1 KB, questa formula genera un valore EPS medio di 11.500 EPS.
Determina il picco massimo di EPS utilizzando la seguente formula, dove il moltiplicatore N rappresenta la natura intermittente della registrazione:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Esempio di calcolo:dato un valore di esempio N=2 e l'EPS medio 11,5k calcolato nel passaggio precedente, questa formula genera un valore EPS di picco sostenuto pari a 23.000 EPS.
Determina il numero massimo di vCPU richieste utilizzando la seguente formula:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Esempio di calcolo: utilizzando il valore EPS di picco sostenuto di 23.000 calcolato nel passaggio precedente, questa formula genera un massimo di ⌈23 / 3⌉ = 8 core vCPU.
Determina il numero massimo di worker Dataflow utilizzando la seguente formula:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Calcolo di esempio: utilizzando il valore massimo di vCPU pari a 8 calcolato nel passaggio precedente, questa formula [8/4] genera un numero massimo di 2 per un tipo di macchina
n1-standard-4.
Per questo esempio, imposta il flag --max-workers su un valore 2
in base al precedente insieme di calcoli di esempio. Tuttavia, ricordati di utilizzare i tuoi valori e calcoli univoci quando esegui il deployment di questa architettura di riferimento nel tuo ambiente.
Parallelismo
Best practice: imposta il parametro
Parametro parallelism
nel modello Dataflow da Pub/Sub a Splunk per fare due volte
il numero di vCPU utilizzate dal numero massimo di Dataflow
worker.
Il parametro parallelism consente di massimizzare il numero di connessioni HEC di Splunk in parallelo, il che a sua volta massimizza la frequenza EPS per la pipeline.
Il valore predefinito parallelism di 1 disattiva il parallelismo e limita il
e la velocità di output. Devi sostituire questa impostazione predefinita per tenere conto di 2-4 connessioni parallele per vCPU, con il numero massimo di worker di cui è stato eseguito il deployment. Come
, calcoli il valore di sostituzione per questa impostazione moltiplicando
numero massimo di worker Dataflow per il numero di vCPU per
worker, raddoppiando questo valore.
Per determinare il numero totale di connessioni parallele all'HEC di Splunk su tutti i worker Dataflow, utilizza la seguente formula:
Calcolo di esempio: utilizzando le vCPU massime di esempio pari a 8 calcolate in precedenza per il numero di macchine, questa formula genera un numero di connessioni parallele pari a 8 x 2 = 16.
Per questo esempio, devi impostare il parametro parallelism sul valore 16
in base al calcolo di esempio precedente. Tuttavia, ricordati di utilizzare i tuoi
di valori e calcoli univoci quando esegui il deployment
di questa architettura di riferimento in
del tuo ambiente.
Conteggio batch
Best practice: per consentire a Splunk HEC di elaborare gli eventi in batch anziché uno alla volta, imposta il parametro batchCount su un valore compreso tra 10 e 50 eventi/richiesta per i log.
La configurazione del conteggio dei batch consente di aumentare gli EPS e ridurre il carico
Endpoint HEC Splunk. L'impostazione combina più eventi in un unico batch per un'elaborazione più efficiente. Ti consigliamo di impostare il parametro batchCount
su un valore compreso tra 10 e 50 eventi/richiesta per i log, a condizione che il ritardo di buffering massimo di due secondi sia accettabile.
Poiché in questo esempio la dimensione media del messaggio di log è 1 KB, ti consigliamo di aggregare almeno 10 eventi per richiesta. Per questo esempio, devi impostare il parametro
batchCount con il valore 10. Tuttavia, ricordati di utilizzare i tuoi
di valori e calcoli univoci quando esegui il deployment
di questa architettura di riferimento in
del tuo ambiente.
Per ulteriori informazioni su queste ottimizzazioni di rendimento e costi consulta Pianificazione di Dataflow pipeline di controllo.
Deployment
Per eseguire il deployment di questa architettura di riferimento, consulta Esegui il deployment di flussi di log da Google Cloud Splunk
Passaggi successivi
- Per un elenco completo dei parametri del modello Dataflow da Pub/Sub a Splunk, consulta la documentazione di Dataflow da Pub/Sub a Splunk.
- Per i modelli Terraform corrispondenti che ti aiutano a eseguire il deployment di questa architettura di riferimento, consulta il repository GitHub
terraform-splunk-log-export. Include una dashboard di Cloud Monitoring predefinita per il monitoraggio della pipeline Splunk Dataflow. - Per ulteriori dettagli sulle metriche personalizzate e sul logging di Splunk Dataflow per aiutarti a monitorare e risolvere i problemi delle pipeline di Splunk Dataflow, consulta questo blog Nuove funzionalità di osservabilità per le pipeline di streaming di Splunk Dataflow.
- Esplora le architetture di riferimento, i diagrammi e le best practice su in Google Cloud. Consulta il nostro Cloud Architecture Center.