In diesem Artikel wird eine Lösung zum Exportieren von Cloud Monitoring-Messwerten für die Langzeitanalyse beschrieben. Cloud Monitoring bietet eine Monitoring-Lösung fürGoogle Cloud und Amazon Web Services (AWS). und bewahrt die Messwerte sechs Wochen lang auf, da der Wert der Monitoring-Messwerte häufig zeitgebunden ist. Der Wert historischer Messwerte nimmt mit der Zeit ab. Nach Ablauf des sechswöchigen Zeitraums können aggregierte Messwerte für eine Langzeitanalyse von Trends von Wert sein, die bei einer Kurzzeitanalyse möglicherweise nicht erkennbar sind.
Diese Lösung bietet eine Anleitung zum Verständnis der Messwertdetails für den Export und eine serverlose Referenzimplementierung für den Messwertexport nach BigQuery.
Die State of DevOps-Berichte haben Faktoren aufgezeigt, die die Leistung bei der Softwarebereitstellung beeinflussen. Diese Lösung hilft Ihnen bei den folgenden Ressourcen:
- Monitoring und Beobachtbarkeit
- Monitoringsysteme für fundierte Geschäftsentscheidungen
- Fähigkeiten des visuellen Managements
Anwendungsfälle für den Export von Messwerten
Cloud Monitoring erfasst Messwerte und Metadaten aus Google Cloud, AWS und der Anwendungsinstrumentierung. Mit Monitoring-Messwerten können Sie die Leistung, Verfügbarkeit und den allgemeinen Zustand von Cloud-Anwendungen über eine API, Dashboards und einen Metrics Explorer genau beobachten. Anhand dieser Tools können Sie die Messwerte der letzten sechs Wochen analysieren. Wenn Sie eine Langzeitanalyse von Messwerten benötigen, können Sie mit der Cloud Monitoring API die Messwerte zur langfristigen Speicherung exportieren.
Cloud Monitoring bewahrt die Messwerte der letzten sechs Wochen auf und wird häufig für operative Zwecke verwendet, beispielsweise für das Monitoring der VM-Infrastruktur (Messwerte zu CPU, Speicher, Netzwerk) und der Messwerte zur Anwendungsleistung (Anfrage- oder Antwortlatenz). Wenn diese Messwerte vordefinierte Schwellenwerte überschreiten, wird durch Benachrichtigungen ein operativer Prozess ausgelöst.
Die erfassten Messwerte können auch für die Langzeitanalyse nützlich sein. Sie können beispielsweise Messwerte für die Anwendungsleistung am Cyber Monday oder im Verlauf von anderen Ereignissen mit hohem Traffic mit Messwerten aus dem Vorjahr vergleichen, um das nächste Ereignis mit hohem Traffic zu planen. Ein weiterer Anwendungsfall besteht darin, die Nutzung des Google Cloud -Dienstes über ein Quartal oder ein Jahr hinweg zu betrachten, um die Kosten besser prognostizieren zu können. Möglicherweise möchten Sie sich auch Messwerte für die Anwendungsleistung in bestimmten Monaten oder Jahren ansehen.
In diesen Beispielen müssen die Messwerte für die Analyse über einen längeren Zeitraum hinweg aufbewahrt werden. Wenn Sie diese Messwerte nach BigQuery exportieren, erhalten Sie die erforderlichen Analysefunktionen, um diese Beispiele zu implementieren.
Voraussetzungen
Für die Langzeitanalyse von Monitoring-Messwertdaten sind drei zentrale Schritte erforderlich:
- Exportieren Sie die Daten aus Cloud Monitoring. Sie müssen die Cloud Monitoring-Messwertdaten als aggregierten Messwert exportieren.
Diese Aggregation ist notwendig, da das Speichern von
timeseries-Rohdatenpunkten keinen Nutzen bietet, auch wenn es technisch machbar ist. Die meisten Langzeitanalysen werden auf aggregierter Ebene über einen längeren Zeitraum hinweg durchgeführt. Der Detaillierungsgrad der Aggregation hängt individuell von Ihrem Anwendungsfall ab, wir empfehlen jedoch eine Aggregation von mindestens einer Stunde. - Erfassen Sie die Daten zur Analyse. Sie müssen die exportierten Cloud Monitoring-Messwerte für die Analyse in eine Analyse-Engine importieren.
- Schreiben Sie Abfragen und erstellen Sie Dashboards für die Daten. Sie benötigen Dashboards und Standard-SQL-Zugriff, um die Daten abzufragen, zu analysieren und zu visualisieren.
Funktionale Schritte
- Erstellen Sie eine Liste mit Messwerten, die in den Export einbezogen werden sollen.
- Rufen Sie Messwerte aus der Monitoring API ab.
- Ordnen Sie die Messwerte aus der exportierten JSON-Ausgabe der Monitoring API dem BigQuery-Tabellenformat zu.
- Schreiben Sie die Messwerte in BigQuery.
- Erstellen Sie einen programmatischen Zeitplan, um die Messwerte regelmäßig zu exportieren.
Architektur
Durch das Design dieser Architektur werden durch verwaltete Dienste Ihr Betriebs- und Verwaltungsaufwand verringert, Kosten gesenkt sowie die Skalierbarkeit nach Bedarf gewährleistet.
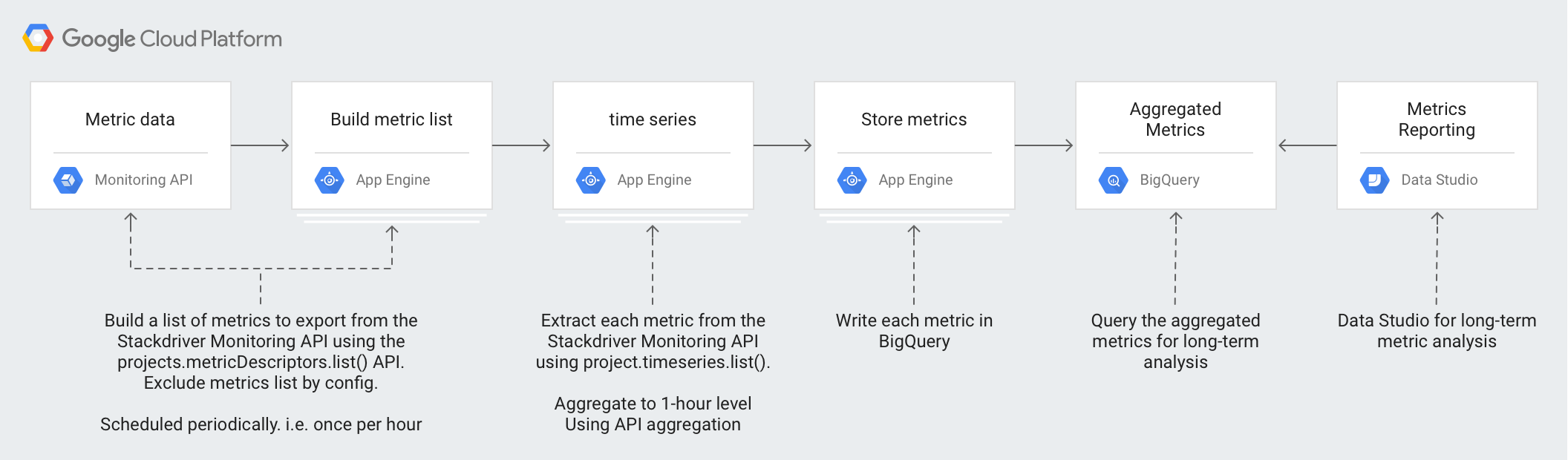
In der Architektur werden diese Technologien eingesetzt:
- App Engine: skalierbare PaaS-Lösung (Platform as a Service) zum Aufrufen der Monitoring API und zum Schreiben in BigQuery.
- BigQuery: eine vollständig verwaltete Analyse-Engine zum Aufnehmen und Analysieren der
timeseries-Daten. - Pub/Sub: ein vollständig verwalteter Echtzeit-Messaging-Dienst zum skalierbaren asynchronen Verarbeiten von Daten.
- Cloud Storage: ein einheitlicher Objektspeicher für Entwickler und Unternehmen zum Speichern der Metadaten zum Exportstatus.
- Cloud Scheduler: ein cron-ähnlicher Planer zum Ausführen des Exportvorgangs.
Informationen zu Messwertdetails von Cloud Monitoring
Für den bestmöglichen Export von Messwerten aus Cloud Monitoring müssen Sie wissen, wie darin Messwerte gespeichert werden.
Messwerttypen
Es gibt vier exportfähige Haupttypen von Messwerten in Cloud Monitoring.
- Die Google Cloud Messwertliste umfasst Messwerte aus Google Cloud Diensten wie Compute Engine und BigQuery.
- Die Liste der Agent-Messwerte enthält Messwerte von VM-Instanzen, auf denen die Cloud Monitoring-Agents ausgeführt werden.
- Die Liste der AWS-Messwerte umfasst Messwerte aus AWS-Diensten wie Amazon Redshift und Amazon CloudFront.
- Messwerte aus externen Quellen umfassen Messwerte aus Anwendungen von Drittanbietern und benutzerdefinierte Messwerte.
Jeder dieser Messwerttypen hat einen Messwertdeskriptor, der den Messwerttyp sowie andere Metadaten zu den Messwerten enthält. Der folgende Messwert dient als Beispiel für eine Liste von Messwertdeskriptoren aus der Methode projects.metricDescriptors.list der Monitoring API.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
Die Felder type, valueType und metricKind sind die wichtigsten Werte aus dem Messwertdeskriptor, deren Bedeutung Sie kennen sollten. Diese Felder identifizieren den Messwert und wirken sich auf die Aggregation aus, die für einen Messwertdeskriptor möglich ist.
Messwertarten
Jeder Messwert hat eine Messwertart und einen Werttyp. Weitere Informationen finden Sie unter Werttypen und Messwertarten. Die Messwertart und der zugehörige Werttyp sind wichtig, da sich ihre Kombination auf die Art und Weise auswirkt, in der die Messwerte aggregiert werden.
Im vorherigen Beispiel hat der Messwerttyp pubsub.googleapis.com/subscription/push_request_count metric die Messwertart DELTA und den Werttyp INT64.

In Cloud Monitoring werden die Messwertart und die Werttypen in metricsDescriptors gespeichert, die in der Monitoring API verfügbar sind.
Zeitachse
timeseries sind regelmäßige Messungen im Zeitverlauf für jeden gespeicherten Messwerttyp, die den Messwerttyp, Metadaten, Labels und die einzelnen gemessenen Datenpunkte enthalten. Von Monitoring automatisch erfasste Messwerte wieGoogle Cloud - und AWS-Messwerte werden regelmäßig erfasst. Der Messwert appengine.googleapis.com/http/server/response_latencies wird beispielsweise alle 60 Sekunden ermittelt.
Ein erfasster Satz von Punkten für einen bestimmten timeseries kann im Zeitverlauf zunehmen, abhängig von der Häufigkeit der gemeldeten Daten und von den Labels, die mit dem Messwerttyp verknüpft sind. Wenn Sie die timeseries-Rohdatenpunkte exportieren, erhalten Sie möglicherweise einen sehr umfangreichen Export. Sie können jedoch die Messwerte für einen bestimmten Ausrichtungszeitraum zusammenfassen und so die Anzahl der zurückgegebenen timeseries-Datenpunkte reduzieren. Durch die Zusammenfassung können Sie beispielsweise für die timeseries eines bestimmten Messwerts mit einem Datenpunkt pro Minute einen Datenpunkt pro Stunde zurückgeben. Dies reduziert die Anzahl der exportierten Datenpunkte und die in der Analyse-Engine erforderliche analytische Verarbeitung. In diesem Artikel werden timeseries für jeden ausgewählten Messwerttyp zurückgegeben.
Messwertaggregation
Durch die Zusammenfassung können Sie Daten aus mehreren timeseries in einem einzigen timeseries kombinieren. Die Monitoring API bietet leistungsstarke Ausrichtungs- und Zusammenfassungsfunktionen, sodass Sie sich nicht selbst um die Zusammenfassung kümmern müssen. Übergeben Sie einfach die Ausrichtungs- und Zusammenfassungsparameter im API-Aufruf. Weitere Informationen zur Zusammenfassung mit der Monitoring API finden Sie unter Filtern und zusammenfassen und in diesem Blogpost.
Bei der Zusammenfassung ordnen Sie den metric type dem aggregation type zu, damit die Messwerte ausgerichtet sind und die timeseries so reduziert werden, dass sie Ihren Analyseanforderungen entsprechen.
Es stehen Ihnen Listen mit Alignern und Reducern zur Verfügung, über die Sie die timeseries-Werte aggregieren können. Aligner und Reducer haben eine Reihe von Messwerten, mit denen Sie Ihre Daten auf Basis der Messwertarten und Werttypen ausrichten oder reduzieren können. Wenn Sie beispielsweise für eine Stunde zusammenfassen, wird als Ergebnis ein Punkt pro Stunde für timeseries zurückgegeben.
Eine weitere Möglichkeit zur Feinabstimmung der Zusammenfassung ist die Funktion Group By, mit der Sie die zusammengefassten Werte in Listen von zusammengefassten timeseries gruppieren können. Gruppieren Sie beispielsweise App Engine-Messwerte anhand des App Engine-Moduls. Die Gruppierung nach App Engine-Modul ergibt in Kombination mit den über eine Stunde aggregierenden Alignern und Reducern einen Datenpunkt pro App Engine-Modul pro Stunde.
Die Messwertaggregation bietet eine Balance zwischen den erhöhten Kosten für die Aufzeichnung einzelner Datenpunkte und der Notwendigkeit, genügend Daten für eine detaillierte Langzeitanalyse zu speichern.
Details zur Referenzimplementierung
Die Referenzimplementierung enthält dieselben Komponenten wie im Diagramm des Architekturdesigns dargestellt. Im Folgenden werden die funktionalen und relevanten Implementierungsdetails für jeden Schritt erläutert.
Messwertliste erstellen
In Cloud Monitoring sind über tausend Messwerttypen definiert, mit denen Sie Google Cloud, AWS und Software von Drittanbietern überwachen können. Die Monitoring API bietet die Methode projects.metricDescriptors.list, mit der eine Liste der für ein Google Cloud-Projekt verfügbaren Messwerte zurückgegeben wird. In der Monitoring API können Sie mit einem Filtermechanismus nach einer Liste mit Messwerten filtern, die Sie für die langfristige Speicherung und Analyse exportieren möchten.
Die Referenzimplementierung in GitHub ruft mit einer Python-Anwendung in App Engine eine Liste von Messwerten ab und schreibt dann jede Nachricht separat in ein Pub/Sub-Thema. Der Export wird von einem Cloud Scheduler initiiert, der eine Pub/Sub-Benachrichtigung zur Ausführung der Anwendung erzeugt.
Für das Aufrufen der Monitoring API gibt es viele Möglichkeiten. In diesem Fall werden die Cloud Monitoring API und die Pub/Sub API über die Google API-Clientbibliothek für Python aufgerufen, da diese flexibel auf die Google APIs zugreifen können.
Zeitachsen abrufen
Extrahieren Sie timeseries für den Messwert und schreiben Sie dann jeden timeseries in Pub/Sub. Mit der Monitoring API können Sie die Messwerte für einen bestimmten Ausrichtungszeitraum mit der Methode project.timeseries.list zusammenfassen. Durch das Zusammenfassen von Daten reduzieren Sie die Verarbeitungslast, die Speicheranforderungen, die Abfragezeiten und die Analysekosten. Die Datenaggregation ist eine Best Practice zur effizienten Durchführung von Langzeitanalysen für Messwerte.
Die Referenzimplementierung in GitHub abonniert über eine Python-Anwendung in App Engine das Thema, in das jeder zu exportierende Messwert als separate Nachricht gesendet wird. Für jede empfangene Nachricht überträgt Pub/Sub die Nachricht per Push an die App Engine-Anwendung. Die Anwendung ruft dann den timeseries für einen bestimmten Messwert ab, der anhand der Eingabekonfiguration zusammengefasst wurde. In diesem Fall werden die Cloud Monitoring API und die Pub/Sub API über die Google API-Clientbibliothek aufgerufen.
Jeder Messwert kann einen oder mehrere timeseries. zurückgeben und wird von einer separaten Pub/Sub-Nachricht gesendet, die in BigQuery eingefügt wird. Die Zuordnung des Messwerts type-to-aligner und des Messwerts type-to-reducer ist in die Referenzimplementierung eingebunden. In dieser Tabelle wird die in der Referenzimplementierung verwendete Zuordnung anhand der von den Alignern und Reducern unterstützten Klassen von Messwertarten und Werttypen veranschaulicht.
| Werttyp | GAUGE |
Aligner | Reducer | DELTA |
Aligner | Reducer | CUMULATIVE2 |
Aligner | Reducer |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
Ja |
ALIGN_FRACTION_TRUE
|
keiner | Nein | – | – | Nein | – | – |
INT64 |
Ja |
ALIGN_SUM
|
keiner | Ja |
ALIGN_SUM
|
keiner | Ja | keiner | keiner |
DOUBLE |
Ja |
ALIGN_SUM
|
keiner | Ja |
ALIGN_SUM
|
keiner | Ja | keiner | keiner |
STRING |
Ja | ausgeschlossen | ausgeschlossen | Nein | – | – | Nein | – | – |
DISTRIBUTION |
Ja |
ALIGN_SUM
|
keiner | Ja |
ALIGN_SUM
|
keiner | Ja | keiner | keiner |
MONEY |
Nein | – | – | Nein | – | – | Nein | – | – |
Beachten Sie besonders die Zuordnung von valueType zu Alignern und Reducern. Bei jedem Aligner und Reducer ist die Zusammenfassung nur für bestimmte valueTypes und metricKinds möglich.
Ein Beispiel ist der Typ pubsub.googleapis.com/subscription/push_request_count metric. Wenn die Messwertart DELTA und der Werttyp INT64 ist, können Sie den Messwert so zusammenfassen:
- Ausrichtungszeitraum: 3.600 Sek. (1 Stunde)
Aligner = ALIGN_SUM: Das Ergebnis des Datenpunkts im Ausrichtungszeitraum ist die Summe aller Datenpunkte im Ausrichtungszeitraum.Reducer = REDUCE_SUM: Die Reduzierung erfolgt durch Berechnung der Summe dertimeseries-Werte in den einzelnen Ausrichtungszeiträumen.
Neben den Werten für Ausrichtungszeitraum, Aligner und Reducer sind für die Methode project.timeseries.list mehrere weitere Eingaben erforderlich:
filter: Wählen Sie den zurückzugebenden Messwert aus.startTime: Wählen Sie den Startzeitpunkt aus, ab demtimeserieszurückgegeben werden soll.endTime: Wählen Sie den letzten Zeitpunkt aus, bis zu demtimeserieszurückgegeben werden soll.groupBy: Geben Sie die Felder ein, nach denen die Antworttimeseriesgruppiert werden soll.alignmentPeriod: Geben Sie die Zeiträume ein, in denen die Messwerte ausgerichtet werden sollen.perSeriesAligner: Richten Sie die Punkte in gleichmäßigen Zeitintervallen aus, die durch denalignmentPerioddefiniert werden.crossSeriesReducer: Kombinieren Sie mehrere Punkte mit unterschiedlichen Labelwerten zu einem Punkt pro Zeitintervall.
Die GET-Anfrage an die API enthält alle in der vorhergehenden Liste beschriebenen Parameter.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
Der Aufruf HTTP GET dient als Beispiel für einen Aufruf der API-Methode projects.timeseries.list. Dabei werden diese Eingabeparameter verwendet:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
Der vorhergehende Aufruf der Monitoring API enthält crossSeriesReducer=REDUCE_SUM. Die Messwerte werden also zusammengefasst und wie in diesem Beispiel dargestellt auf eine einzige Summe reduziert.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
Diese Aggregationsebene aggregiert Daten zu einem einzelnen Datenpunkt und ist somit ein idealer Messwert für Ihr Google Cloud Gesamtprojekt. Sie können jedoch nicht aufschlüsseln, welche Ressourcen zum Messwert beigetragen haben. Im vorigen Beispiel lässt sich etwa nicht erkennen, welches Pub/Sub-Abo am meisten zur Anzahl der Anfragen beigetragen hat.
Wenn Sie die Details der einzelnen Komponenten prüfen möchten, die die timeseries erzeugen, können Sie den Parameter crossSeriesReducer entfernen.
Ohne den Parameter crossSeriesReducer kombiniert die Monitoring API die verschiedenen timeseries nicht zu einem einzigen Wert.
Der Aufruf HTTP GET dient als Beispiel für den Aufruf der API-Methode projects.timeseries.list. Dabei werden diese Eingabeparameter verwendet. crossSeriesReducer ist nicht enthalten.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
In der folgenden JSON-Antwort sind die metric.labels.keys in beiden Ergebnissen gleich, da die timeseries gruppiert sind. Für jeden Wert von resource.labels.subscription_ids werden separate Punkte zurückgegeben. Prüfen Sie die Werte metric_export_init_pub und metrics_list in der unten aufgeführten JSON-Antwort. Diese Aggregationsebene wird empfohlen, da Sie damit in Ihren BigQuery-AbfragenGoogle Cloud -Produkte in Form von Ressourcenlabels verwenden können.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Jeder Messwert in der JSON-Ausgabe des API-Aufrufs projects.timeseries.list wird direkt als separate Nachricht in Pub/Sub geschrieben. Potenziell kann es zu einem Fan-Out kommen, bei dem ein Eingabemesswert einen oder mehrere timeseries erzeugt.
Mit Pub/Sub können Sie mögliche große Fan-Outs verarbeiten, ohne Zeitlimits zu überschreiten.
Der angegebene Ausrichtungszeitraum bedeutet, dass die Werte in diesem Zeitraum wie in der vorigen Beispielantwort zu einem einzigen Wert zusammengefasst werden. Der Ausrichtungszeitraum gibt auch an, wie oft der Export ausgeführt wird. Wenn Ihr Ausrichtungszeitraum beispielsweise 3.600 Sekunden oder eine Stunde beträgt, wird der Export jede Stunde ausgeführt, um die timeseries regelmäßig zu exportieren.
Messwerte speichern
Die Referenzimplementierung in GitHub liest mit einer Python-Anwendung in App Engine jeden timeseries und fügt anschließend die Datensätze in die BigQuery-Tabelle ein. Für jede empfangene Nachricht überträgt Pub/Sub die Nachricht per Push an die App Engine-Anwendung. Die Pub/Sub-Nachricht enthält Messwertdaten, die aus der Monitoring API im JSON-Format exportiert wurden und einer Tabellenstruktur in BigQuery zugeordnet werden müssen. In diesem Fall werden die BigQuery APIs über die Google API-Clientbibliothek aufgerufen.
Das BigQuery-Schema ist so konzipiert, dass die Zuordnung der aus der Monitoring API exportierten JSON-Antwort ähnelt. Beim Erstellen des BigQuery-Tabellenschemas sollten Sie berücksichtigen, wie Datengrößen im Zeitverlauf zunehmen.
Wir empfehlen, die Tabelle in BigQuery anhand eines Datumsfelds zu partitionieren. Der Grund dafür ist, dass Abfragen effizienter gestaltet werden, wenn Datumsbereiche ausgewählt werden können und kein vollständiger Tabellenscan durchgeführt werden muss. Wenn Sie den Export regelmäßig ausführen möchten, können Sie die Standardpartition anhand des Aufnahmedatums sicher verwenden.
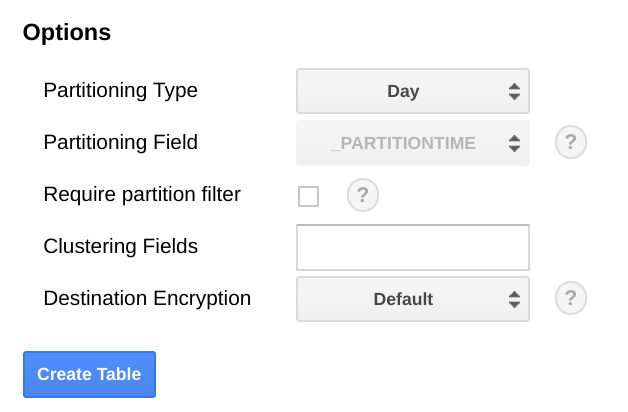
Wenn Sie Messwerte in großem Umfang hochladen oder den Export nicht regelmäßig ausführen möchten, sollten Sie eine Partitionierung nach end_time, ausführen. Hierfür sind Änderungen am BigQuery-Schema erforderlich. Sie können end_time entweder in ein Feld der obersten Ebene im Schema verschieben und es dort für die Partitionierung verwenden oder ein neues Feld zum Schema hinzufügen. Das Feld end_time muss verschoben werden, da es in einem BigQuery-Datensatz enthalten ist und die Partitionierung mit einem Feld auf oberster Ebene erfolgen muss. Weitere Informationen dazu finden Sie in der Dokumentation zur Partitionierung in BigQuery.
Mit BigQuery können Sie Datasets, Tabellen und Tabellenpartitionen auch mit einem Ablaufdatum versehen.
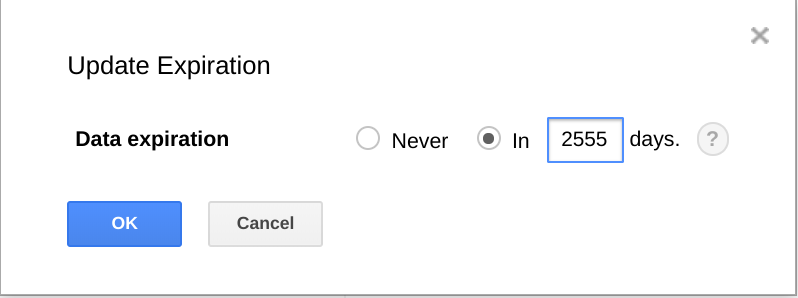
Mit dieser Funktion können Sie ältere Daten dauerhaft löschen, wenn sie nicht mehr benötigt werden. Wenn Ihre Analyse beispielsweise einen Zeitraum von drei Jahren abdeckt, können Sie eine Richtlinie zum Löschen von Daten hinzufügen, die älter als drei Jahre sind.
Export planen
Cloud Scheduler ist ein vollständig verwalteter Cronjob-Planer. Mit Cloud Scheduler können Sie im standardmäßigen Cron-Zeitplanformat das Ausführen einer App Engine-Anwendung auslösen, eine Nachricht über Pub/Sub versenden oder sie an einen beliebigen HTTP-Endpunkt senden.
In der Referenzimplementierung in GitHub löst Cloud Scheduler jede Stunde das Ausführen der App Engine-Anwendung list-metrics aus. Dazu wird eine Pub/Sub-Nachricht mit einem Token gesendet, das der App Engine-Konfiguration entspricht. Der Standardzeitraum für die Aggregation in der Anwendungskonfiguration beträgt 3.600 Sekunden oder 1 Stunde. Dies entspricht der Häufigkeit, mit der die Ausführung der Anwendung ausgelöst wird. Wir empfehlen eine Aggregation von mindestens einer Stunde, da Sie hierdurch ein Gleichgewicht zwischen der Reduzierung des Datenvolumens und der Aufbewahrung hochwertiger Daten erzielen. Wenn Sie einen anderen Ausrichtungszeitraum verwenden, ändern Sie die Häufigkeit des Exports entsprechend. Die Referenzimplementierung speichert den letzten Wert für end_time in Cloud Storage und verwendet diesen Wert als nachfolgenden start_time-Wert, sofern nicht ein start_time-Wert als Parameter übergeben wird.
In dieser Abbildung wird gezeigt, wie Sie Cloud Scheduler mit der Google Cloud Console so konfigurieren, dass die App Engine-Anwendung list-metrics stündlich aufgerufen wird.
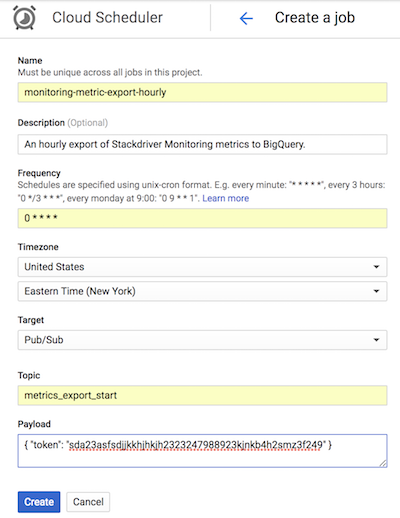
Im Feld Häufigkeit wird die Syntax im Cron-Stil verwendet, um für Cloud Scheduler festzulegen, wie häufig die Anwendung ausgeführt werden soll. Unter Ziel wird eine erzeugte Pub/Sub-Nachricht angegeben und das Feld Nutzlast enthält die in der Pub/Sub-Nachricht enthaltenen Daten.
Exportierte Messwerte verwenden
Mit den exportierten Daten in BigQuery können Sie jetzt über Standard-SQL die Daten abfragen oder Dashboards erstellen, um Trends in Ihren Messwerten im Zeitverlauf zu visualisieren.
Beispielabfrage: App Engine-Latenzen
Diese Abfrage bestimmt den Mindest- und Höchstwert sowie den Durchschnitt der Messwerte zur mittleren Latenz einer App Engine-Anwendung. metric.type identifiziert den App Engine-Messwert und die Labels identifizieren die App Engine-Anwendung anhand des Labelwerts für project_id. Dabei wird der Messwert point.value.distribution_value.mean verwendet, da dies ein DISTRIBUTION-Wert in der Monitoring API ist, der in BigQuery dem Feldobjekt distribution_value zugeordnet ist. Das Feld end_time legt den Zeitraum für die Werte auf die letzten 30 Tage fest.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Beispielabfrage: Anzahl der BigQuery-Abfragen
Diese Abfrage gibt die Anzahl der Abfragen pro Tag an ein BigQuery-Projekt zurück. Dabei wird das Feld int64_value verwendet, da dieser Messwert ein INT64-Wert in der Monitoring API ist, der dem Feld int64_value in BigQuery zugeordnet ist. metric.type identifiziert den BigQuery-Messwert und die Labels identifizieren das Projekt anhand des Labelwerts project_id. Das Feld end_time legt den Zeitraum für die Werte auf die letzten 30 Tage fest.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
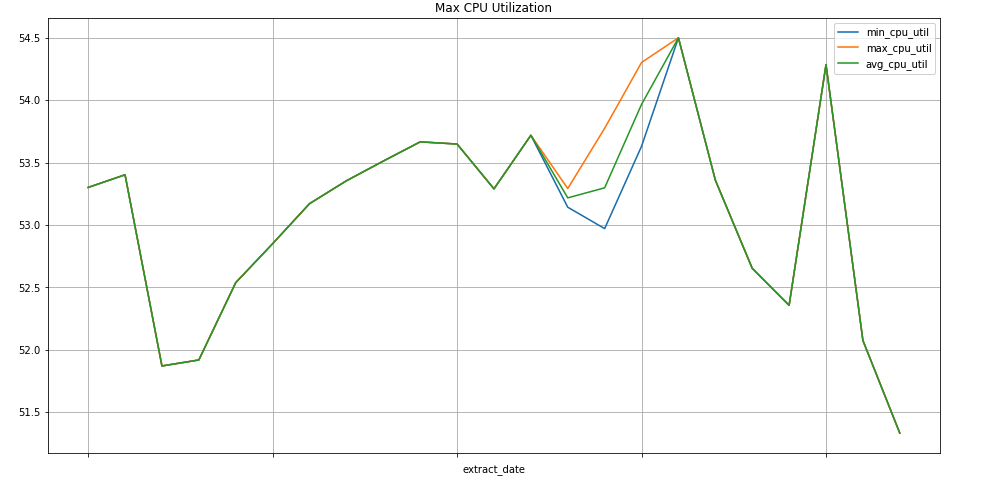
Beispielabfrage: Compute Engine-Instanzen
Diese Abfrage ermittelt den wöchentlichen Mindest- und Höchstwert sowie den Durchschnitt der Messwerte zur CPU-Nutzung der Compute Engine-Instanzen eines Projekts. metric.type identifiziert den Compute Engine-Messwert und die Labels identifizieren die Instanzen anhand des Labelwerts project_id. Das Feld end_time legt den Zeitraum für die Werte auf die letzten 30 Tage fest.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Datenvisualisierung
BigQuery ist in viele Tools eingebunden, die Sie zur Datenvisualisierung verwenden können.
Looker Studio ist ein kostenloses Tool von Google, mit dem Sie Datendiagramme und Dashboards erstellen können, um die Messwertdaten zu visualisieren und sie dann an Ihr Team weiterzugeben. Dieses Beispiel zeigt ein Trendliniendiagramm zur Latenz und zur Anzahl der Anfragen für den Messwert appengine.googleapis.com/http/server/response_latencies im Zeitverlauf.
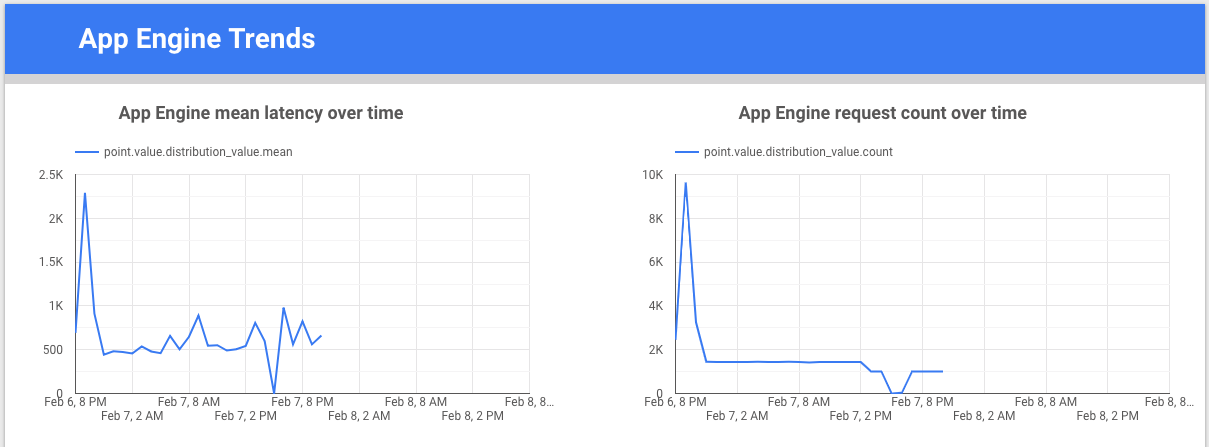
Colaboratory ist ein Recherchetool für die Bildung und Forschung im Bereich maschinelles Lernen. Sie müssen diese gehostete Jupyter-Notebookumgebung nicht einrichten, um Daten in BigQuery zu verwenden und darauf zuzugreifen. Mit einem Colab-Notebook, Python-Befehlen und SQL-Abfragen können Sie detaillierte Analysen und Visualisierungen entwickeln.
Referenzimplementierung für den Export überwachen
Wenn der Export ausgeführt wird, müssen Sie ihn überwachen. Legen Sie ein Service Level Objective (SLO) fest und entscheiden Sie darüber, welche Messwerte überwacht werden sollen. Ein SLO ist ein Zielwert oder ein Wertebereich für ein Servicelevel, das über einen Messwert gemessen wird. Im Buch Site Reliability Engineering werden vier Hauptbereiche für SLOs beschrieben: Verfügbarkeit, Durchsatz, Fehlerrate und Latenz. Bei einem Datenexport sind Durchsatz und Fehlerrate zwei wichtige Faktoren, die Sie anhand dieser Messwerte überwachen können:
- Durchsatz:
appengine.googleapis.com/http/server/response_count - Fehlerrate:
logging.googleapis.com/log_entry_count
Sie können die Fehlerrate beispielsweise anhand des Messwerts log_entry_count überwachen. Dazu filtern Sie ihn nach App Engine-Anwendungen (list-metrics, get-timeseries, write-metrics) mit einem Schweregrad ERROR. Anschließend können Sie sich durch Benachrichtigungsrichtlinien in Cloud Monitoring über Fehler in der Exportanwendung informieren lassen.
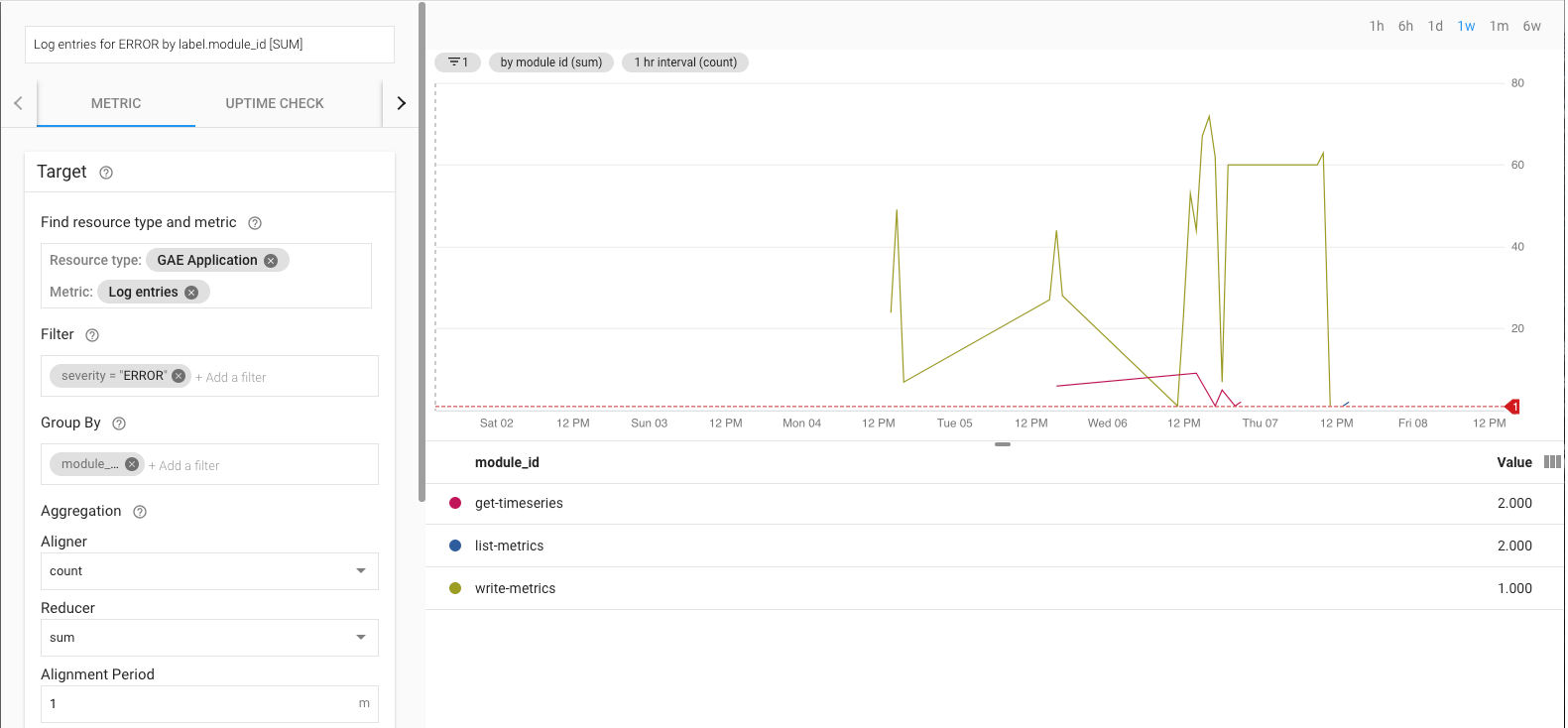
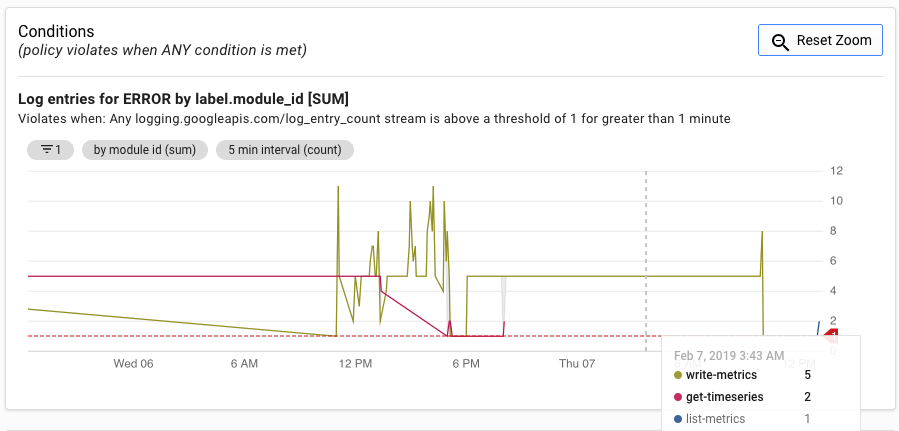
In der UI für Benachrichtigungen wird eine Grafik des Messwerts log_entry_count im Vergleich mit dem Schwellenwert für das Erzeugen der Benachrichtigung angezeigt.
Nächste Schritte
- Referenzimplementierung auf GitHub ansehen
- Lesen Sie die Dokumentation zu Cloud Monitoring.
- Lesen Sie die Dokumentation für die Cloud Monitoring API-Version 3.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
- Ressourcen zu DevOps
Mehr über die DevOps-Ressourcen aus dieser Lösung erfahren:
Über den DevOps Quick Check erfahren, wo Sie im Vergleich zum Rest der Branche stehen