This guide provides an overview of disaster recovery options for SAP HANA systems deployed on Google Cloud.
This guide is not intended to replace the standard SAP documentation.
Preparing for disaster recovery
To prepare for disasters, you can use SAP HANA system replication to a secondary SAP HANA system, take backups of SAP HANA to enable recovery, or use both.
For mission critical workloads that require fast recovery times, use HANA system replication to minimize downtime. Using backups to recover a system costs less but takes longer, in that a new system must be created and then the backups restored into it to recover to the desired point in time.
In either case, you must use network-based redirection to redirect client applications that use the SAP HANA system to the IP address of the replacement system once it is available. For more information, see the SAP HANA Administration Guide.
Starting with SAP HANA SPS09, you can use the Python-based API included with SAP HANA to create your own high-availability/disaster-recovery (HA/DR) provider and integrate it with the SAP HANA System Replication takeover process to automate tasks like redirecting database client connections from the primary system to the secondary system after a takeover. For more information, see Implementing a HA/DR Provider.
Note that any restrictions defined by SAP, including distance limitation for synchronous replication, are also in effect on Google Cloud.
As an alternative to native disaster recovery options, for cross-region active-passive disaster recovery (DR), you can use Persistent Disk Asynchronous Replication (PD Async Replication). PD Async Replication provides asynchronous replication of data between two Google Cloud regions.
Disaster recovery using SAP HANA System Replication
To maximize infrastructure resource utilization and to cost-optimize your DR solution, you can use the secondary system for non-production use cases, such as for a development or QA system. In this case, the secondary system isn't preloaded with data, so the failover time is longer than having the secondary system preloaded with data and kept in sync with the primary system.
HANA 2 SPS00 includes support for Active/Active (read enabled) configuration mode, which enables SAP HANA system replication to support read access on the secondary system. For more information, see Active/Active (Read Enabled).
Both synchronous and asynchronous replication are supported when using SAP HANA system replication with Google Cloud.
If possible, we recommend using synchronous replication, where SQL transactions are not committed on the primary database instance until they are committed on the standby instance. This keeps the standby instance 100% in sync and ensures a zero recovery point objective. Synchronous replication can be used for instances that reside in any zones within the same region.
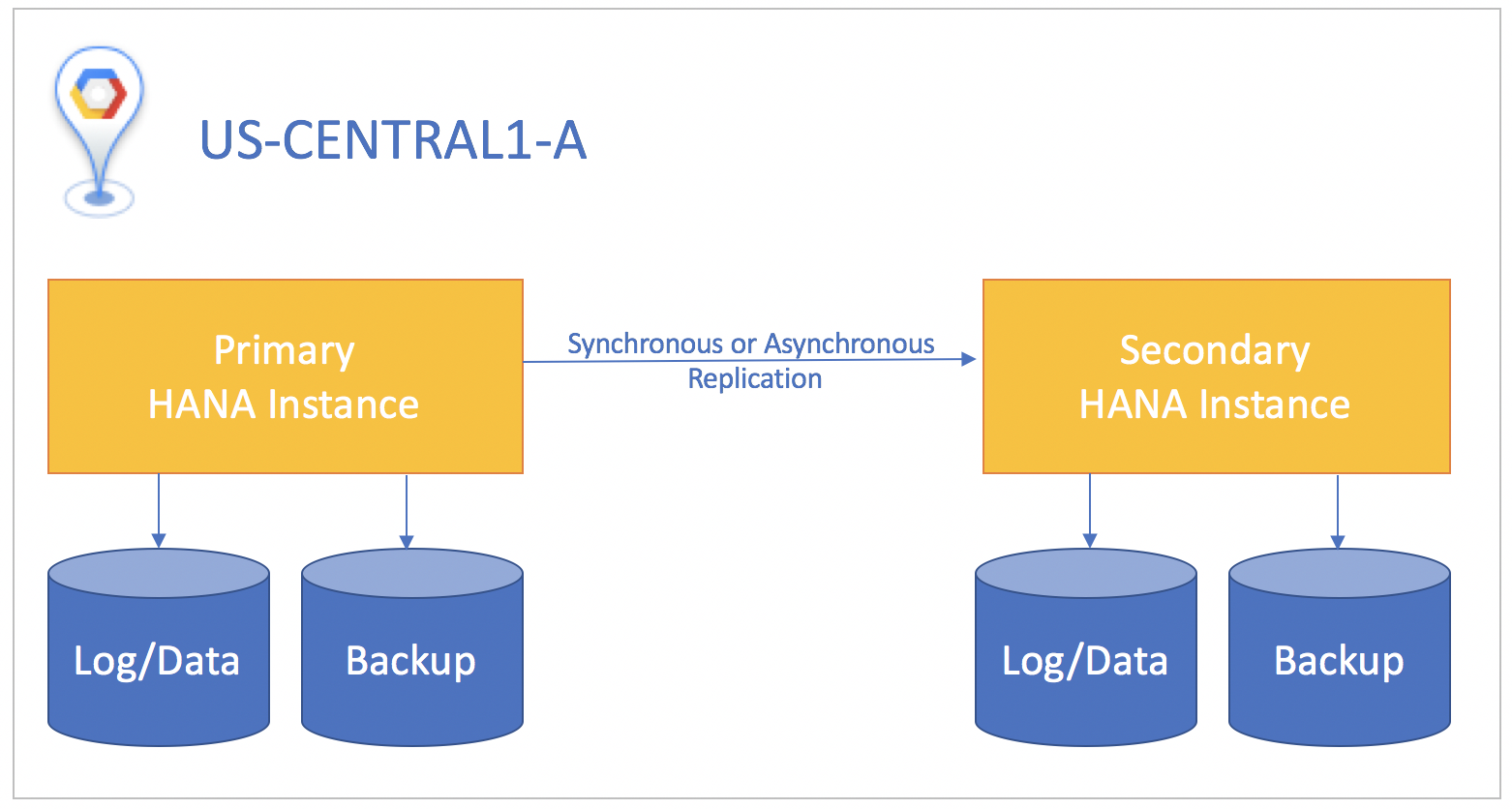
If the standby system is in a different region than the primary system, use asynchronous replication, where there is no wait for the standby instance to acknowledge the data before the commit on the primary instance. In this scenario, you might lose small amounts of data if a disaster happens. A tradeoff is that asynchronous replication gives you a greater than zero recovery point objective.
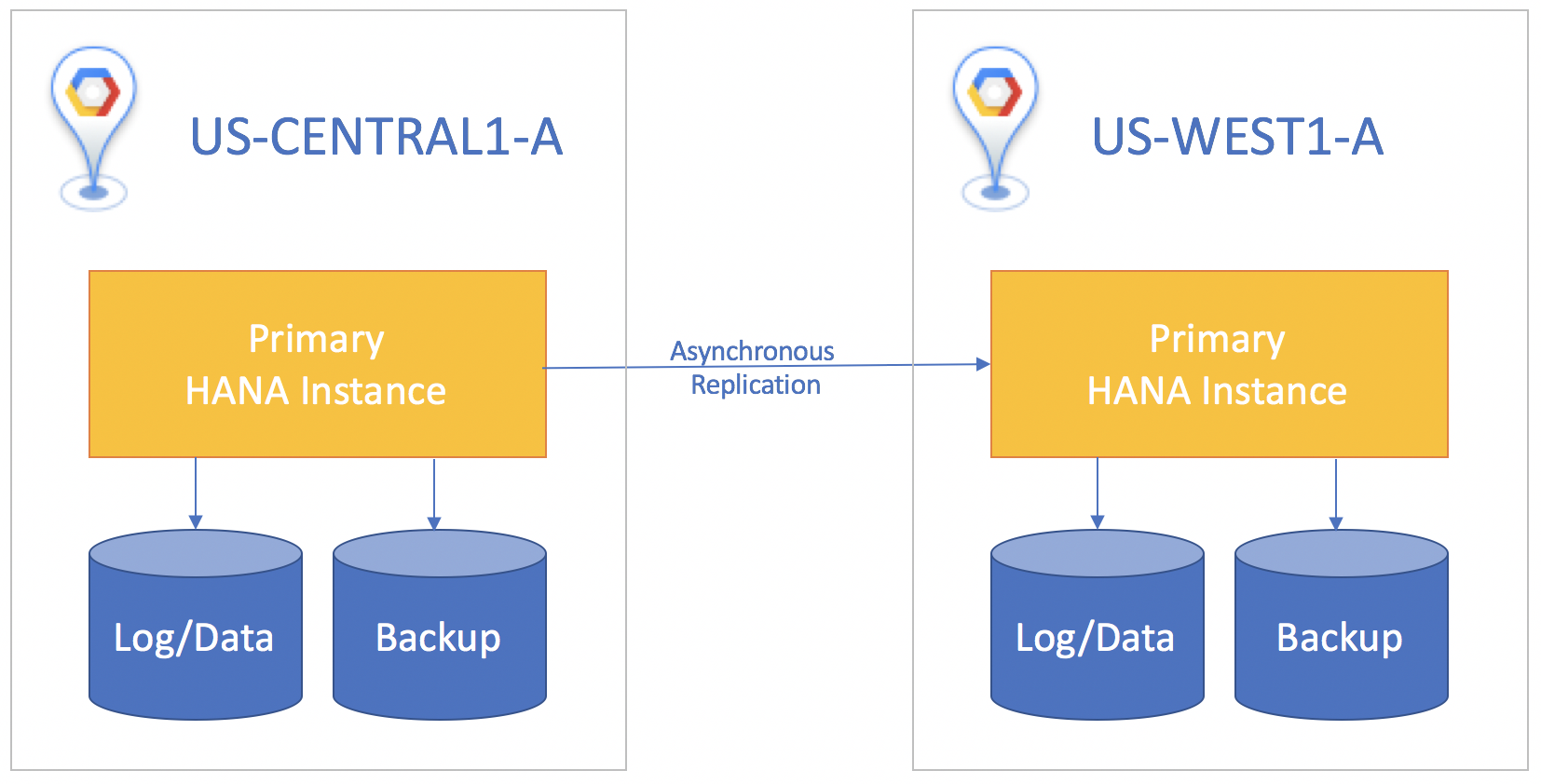
For all replication scenarios, you must manually perform a takeover on the standby system to start disaster recovery. You also need to manually redirect any applications that use the SAP HANA database to target the instance it has failed over to in the standby system.
Choose the HANA System Replication option that best fits your business needs, such as recovery time objective (RTO), and recovery point objective (RPO). For more information, see Replication Modes for SAP HANA System Replication.
SAP HANA System Replication with preload
In this scenario, your SAP HANA system is replicated to a dedicated standby system. The SAP HANA database is replicated to a Compute Engine VM that has a unique hostname and its own persistent disks attached. All of the SAP HANA data is loaded into memory on the standby system. If you have to failover, the failover time only takes around 90 seconds because all of the data is preloaded.
For more information about SAP HANA System Replication with preload, see the System Replication section in SAP HANA – High Availability.
SAP HANA System Replication without preload
In this scenario, your SAP HANA system is replicated to a dedicated standby system. The SAP HANA database is replicated to a Compute Engine VM that has a unique hostname and its own persistent disks attached. The SAP HANA data is not loaded into memory on the standby system. If you have to fail over, the failover time can take from minutes to hours, depending on the size of your dataset.
When you don't preload the data, the memory requirements for the Compute Engine VM that hosts the SAP HANA database are much smaller. For the latest sizing guidance, consult SAP note 1999880 - FAQ: SAP HANA System Replication under "Which rules apply for memory utilization on secondary system replication sites?".
You can get information about the rowstore memory footprint by running the following query:
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
The reduced memory requirement gives you cost-saving options when choosing a Compute Engine machine type.
You can use a machine type that has low memory specifications for hosting the SAP HANA database in the standby system to lower your running cost. A low-memory VM isn't supported for SAP HANA in a production system, but you could use this lower-cost VM to perform a takeover in a disaster-recovery scenario, and then can modify the VM afterwards to change the machine type to one with a supported amount of memory. To do this, you must stop the VM to perform the upgrade, and so will have additional downtime before the SAP HANA system is available.
You can use a high-memory machine type for hosting the SAP HANA database in the standby system, and can share it with development or test systems to improve your return on investment. You can set the global allocation limit for the SAP HANA database to 64 GB by following the instructions at Change the Global Memory Allocation Limit, leaving the rest of the memory for other systems to use. When the standby system is needed, shut down dev and test operations, perform a takeover, and then remove the global allocation limit.
You can use either synchronous and asynchronous replication without preload. However, synchronous replication requires that the source and target instances be in the same Google Cloud region.
You can use an HA/DR provider to address issues such as shutting down the development and/or test systems in the secondary host.
Triggering a takeover
To invoke disaster recovery, trigger the SAP HANA System Replication Takeover procedure in your standby system. SAP Note 2063657 provides guidelines to help you decide whether takeover is the best option.
To trigger the takeover, follow the standard SAP HANA takeover process. For more details information about this procedure, see How To Perform System Replication for SAP HANA 2.0.
In cases of data issues or software failure, there might not be automatic notifications so that you can perform the takeover. Consider creating a custom solution to send alerts using Cloud Monitoring or HANA monitoring tools.
Disaster recovery using SAP HANA backups
In cases where a longer recovery time objective is acceptable and your recovery point objective is greater than 15 minutes, you can recover from disaster by restoring from backup. To ensure successful recovery when using backups, make frequent copies of your backup files, especially log backups, to a Cloud Storage bucket, or some other long-term storage location that exists outside of the region where your SAP HANA system runs. We recommend documenting the infrastructure of your primary system and creating scripts that allow you to quickly create a replacement system to restore your backups to.
For more information, see the SAP HANA operations guide.
Disaster recovery using PD Async Replication
For your SAP workloads running on Google Cloud, PD Async Replication enables disaster recovery by replicating data between two Google Cloud regions. PD Async Replication provides low recovery point objective (RPO) and low recovery time objective (RTO) block storage asynchronous replication for cross-region active-passive disaster recovery. In the unlikely event of a regional outage, PD Async Replication enables you to failover your SAP data to a secondary region and restart your SAP workload in that region.
You can use PD Async Replication to manage replication for Compute Engine based SAP workloads at the infrastructure-level, instead of the SAP workload-level such as SAP HANA System Replication.
PD Async Replication replicates SAP data from a primary disk that is attached to a running workload to a secondary blank disk that is located in another region. For more information, see About Persistent Disk Asynchronous Replication.
PD Async Replication limitations
For PD Async Replication, you can only use
balanced Persistent Disk (pd-balanced) and performance (SSD) Persistent Disk (pd-ssd) volumes in supported region pairs.
For more information, see Limitations.
Monitor and evaluate the rate of change on your workload against the capability of PD Async Replication by reviewing the monitoring metrics for your device pair as described in Review Persistent Disk Asynchronous Replication performance.
The metric async_replication/sent_bytes_count is not expected to show a
constant increase in the amount of data transferred because this metric
represents the delta of the number of bytes sent through the cross-region network.