Dieses Dokument ist der dritte Teil einer Reihe, in der die Notfallwiederherstellung (Disaster Recovery, DR) in Google Cloudbehandelt wird. In diesem Teil werden Szenarien für die Sicherung und Wiederherstellung von Daten beschrieben.
Die Reihe besteht aus folgenden Teilen:
- Leitfaden zur Planung der Notfallwiederherstellung
- Bausteine der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung von Daten (dieses Dokument)
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektur der Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
Einführung
In Plänen zur Notfallwiederherstellung legen Sie fest, wie Sie bei einem Notfall den Verlust von Daten vermeiden. Der Begriff Daten bezieht sich hier auf zwei Szenarien. Es geht um die Sicherung und Wiederherstellung von Datenbanken, Logdaten und anderen Datentypen in einem der folgenden Szenarien:
- Datensicherungen: Bei der Sicherung von Daten wird eine bestimmte Menge an Daten von einem Ort an einen anderen kopiert. Sicherungen sind Bestandteil eines Wiederherstellungsplans. Damit können einerseits Daten in der Produktionsumgebung nach einer Beschädigung in einwandfreiem Zustand wiederhergestellt werden. Andererseits lassen sich mit einem solchen Plan Daten in der DR-Umgebung wiederherstellen, sollte die Produktionsumgebung ausfallen. In der Regel gelten für Datensicherungen niedrige bis mittlere RTO-Werte (Recovery Time Objective, Wiederherstellungsdauer) und niedrige RPO-Werte (Recovery Point Objective, Wiederherstellungszeitpunkt).
- Datenbanksicherungen: Datenbanksicherungen sind etwas komplexer, da sie in der Regel bis zu einem bestimmten Zeitpunkt wiederhergestellt werden müssen. Neben der Sicherung und Wiederherstellung der Datenbanken sowie der exakten Spiegelung der Produktionskonfiguration durch das Wiederherstellungsdatenbanksystem (gleiche Version, gespiegelte Laufwerkskonfiguration) muss deshalb auch die Sicherung der Transaktionslogs berücksichtigt werden. Bei der Notfallwiederherstellung müssen Sie nach der Wiederherstellung der Datenbankfunktionalität die letzte Datenbanksicherung und dann die wiederhergestellten Transaktionslogs übernehmen, die nach der letzten Sicherung gesichert wurden. Aufgrund der komplexen Rahmenbedingungen von Datenbanksystemen, wie z. B. die notwendige Abstimmung der Versionen zwischen Produktions- und Wiederherstellungssystemen, muss vorrangig eine hohe Verfügbarkeit sichergestellt werden. Damit können der Zeitraum der Wiederherstellung in einer Situation, in der der Ausfall des Datenbankservers droht, minimiert und so niedrigere RTO- bzw. RPO-Werte realisiert werden
Wenn Sie Produktionsarbeitslasten auf Google Cloudausführen, können Sie ein global verteiltes System verwenden, sodass die Anwendung im Falle eines Fehlers in einer Region weiterhin Dienste bereitstellt, auch wenn sie allgemein weniger verfügbar ist. Im Wesentlichen ruft diese Anwendung hier ihren DR-Plan auf.
Im weiteren Verlauf dieses Dokuments werden Beispiele für das Entwerfen von Szenarien für Daten und Datenbanken beschrieben, mit denen Sie Ihre RTO- und RPO-Ziele erreichen können.
Lokale Produktionsumgebung
In diesem Szenario ist die Produktionsumgebung lokal angesiedelt. Der Plan zur Notfallwiederherstellung sieht Google Cloud als Medium zur Wiederherstellung vor.
Datensicherung und -wiederherstellung
Es gibt eine Reihe von Strategien, um einen Prozess für die regelmäßige Sicherung lokaler Daten in Google Cloudzu implementieren. In diesem Abschnitt werden zwei der am häufigsten verwendeten Lösungen behandelt.
Lösung 1: Sicherung auf Cloud Storage mithilfe einer geplanten Aufgabe
Bei diesem Muster werden die folgenden DR-Bausteine verwendet:
- Cloud Storage
Eine Möglichkeit der Datensicherung ist das Erstellen einer geplanten Aufgabe, die ein Skript oder eine Anwendung zur Übertragung der Daten nach Cloud Storage ausführt. Sie können diesen Vorgang zur Sicherung der Daten in Cloud Storage mithilfe des gcloud storage-Befehls der Google Cloud CLI oder mit einer der Clientbibliotheken von Cloud Storage automatisieren.
Mit dem folgenden gcloud storage-Befehl werden beispielsweise alle Dateien aus einem Quellverzeichnis in einen bestimmten Bucket kopiert.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Ersetzen Sie SOURCE_DIRECTORY durch den Pfad zu Ihrem Quellverzeichnis und BUCKET_NAME durch einen Namen Ihrer Wahl für den Bucket.
Der Name muss den Anforderungen für Bucket-Namen entsprechen.
Mit den folgenden Schritten können Sie einen Sicherungs- und Wiederherstellungsvorgang mithilfe des gcloud storage-Befehls implementieren.
- Installieren Sie
gcloud CLIauf dem lokalen Computer, von dem Sie die Datendateien hochladen. - Erstellen Sie einen Bucket als Ziel für die Datensicherung.
- Erstellen Sie ein Dienstkonto.
- Erstellen Sie eine IAM-Richtlinie zur Einschränkung des Zugriffs auf den Bucket und seine Objekte. Erteilen Sie dabei dem speziell für diesen Zweck erstellten Dienstkonto den Zugriff. Weitere Informationen zu Berechtigungen für den Zugriff auf Cloud Storage finden Sie unter IAM-Berechtigungen für
gcloud storage. - Mit der Identitätsübernahme des Dienstkontos gewähren Sie Ihrem lokalen Google Cloud-Nutzer (oder Dienstkonto) Zugriff, um sich als das zuvor erstellte Dienstkonto auszugeben. Alternativ können Sie einen neuen Nutzer speziell für diesen Zweck erstellen.
- Testen Sie, ob Sie Dateien in den Ziel-Bucket hochladen und von dort herunterladen können.
- Richten Sie mithilfe von Tools wie Linux
crontabund dem Windows-Aufgabenplaner einen Zeitplan für das Script ein, mit dem Sie Ihre Sicherungen hochladen. - Konfigurieren Sie einen Wiederherstellungsprozess, der den Befehl
gcloud storageverwendet, um Ihre Daten in Ihrer Wiederherstellungs-DR-Umgebung in Google Cloudwiederherzustellen.
Sie können auch den Befehl gcloud storage rsync verwenden, um inkrementelle Echtzeitsynchronisierungen zwischen Ihren Daten und einem Cloud Storage-Bucket durchzuführen.
Mit dem folgenden gcloud storage rsync-Befehl werden z. B. die Inhalte in einem Cloud Storage-Bucket mit dem Inhalt des Quellverzeichnisses identisch gemacht. Dazu werden alle fehlenden Dateien oder Objekte oder diejenigen, deren Daten sich geändert haben, kopiert. Wenn die Datenmenge, die zwischen den aufeinanderfolgenden Sicherungssitzungen geändert wurde, relativ klein im Verhältnis zum gesamten Umfang der Quelldaten ist, kann gcloud storage rsync effizienter sein als der Befehl gcloud storage cp. Mit gcloud storage rsync können Sie einen häufigeren Sicherungsplan implementieren und einen niedrigeren RPO erzielen.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Weitere Informationen finden Sie unter gcloud storage-Befehl für kleinere Übertragungen lokaler Daten.
Lösung 2: Sicherung auf Cloud Storage mit dem Transfer Service für lokale Daten
Bei diesem Muster werden die folgenden DR-Bausteine verwendet:
- Cloud Storage
- Transfer Service für lokale Daten
Die Übertragung großer Datenmengen über ein Netzwerk erfordert häufig eine sorgfältige Planung und robuste Ausführungsstrategien. Es ist keine triviale Aufgabe, benutzerdefinierte Skripts zu erstellen, die skalierbar, zuverlässig und verwaltbar sind. Benutzerdefinierte Skripts können häufig zu niedrigeren RPO-Werten und sogar zu erhöhten Risiken bei Datenverlust führen.
Eine Anleitung zum Verschieben großer Datenmengen von lokalen Speicherorten zu Cloud Storage finden Sie unter Daten aus lokalem Speicher verschieben oder sichern.
Lösung 3: Sicherung auf Cloud Storage mithilfe einer Partner-Gateway-Lösung
Bei diesem Muster werden die folgenden DR-Bausteine verwendet:
- Cloud Interconnect
- Mehrstufige Speicherung in Cloud Storage
Lokale Anwendungen sind häufig in Lösungen von Drittanbietern eingebunden, die im Rahmen der Datensicherungs- und Wiederherstellungsstrategie verwendet werden. Diese Lösungen nutzen häufig ein Muster für eine mehrstufige Speicherung, bei der die letzten Sicherungen auf einem schnelleren Speicher abgelegt werden und ältere Sicherungen zu einem kostengünstigeren, langsameren Speicher migriert werden. Wenn Sie Google Cloud als Ziel verwenden, stehen Ihnen mehrere Speicherklassenoptionen zur Verfügung, die Sie analog zur langsameren Stufe verwenden können.
Eine Möglichkeit zur Implementierung dieses Musters ist die Verwendung eines Partner-Gateways zwischen Ihrem lokalen Speicher und Google Cloud für diese Datenübertragung nach Cloud Storage. Im folgenden Diagramm ist diese Konstellation veranschaulicht, in der die Übertragung von der lokalen NAS-Appliance oder vom SAN über eine Partnerlösung ausgeführt wird.

Bei Auftreten eines Fehlers müssen die gesicherten Daten in der DR-Umgebung wiederhergestellt werden. Der Produktionstraffic wird dann über diese DR-Umgebung geleitet, bis die Produktionsumgebung wiederhergestellt ist. Die jeweils erforderliche Vorgehensweise hängt von Ihrer Anwendung, der Partnerlösung und deren Architektur ab. Im DR-Anwendungsdokument werden verschiedene End-to-End-Szenarien erläutert.
Sie können auch verwaltete Google Cloud Datenbanken als Ziele für die Notfallwiederherstellung verwenden. Cloud SQL for SQL Server unterstützt beispielsweise Transaktionslogimporte. Sie können Transaktionslogs aus Ihrer lokalen SQL Server-Instanz exportieren, in Cloud Storage hochladen und in Cloud SQL for SQL Server importieren.
Eine Anleitung zu den verschiedenen Möglichkeiten der Übertragung von lokalen Daten aufGoogle Cloudfinden Sie unter Große Datenmengen in Google Cloudübertragen.
Weitere Informationen zu Partnerlösungen finden Sie auf der Partnerseite der Google Cloud -Website.
Datenbanksicherung und -wiederherstellung
Es gibt eine Reihe von Strategien, um einen Prozess zur Wiederherstellung eines lokalen Datenbanksystems in Google Cloudzu implementieren. In diesem Abschnitt werden zwei der am häufigsten verwendeten Lösungen behandelt.
Die verschiedenen integrierten Sicherungs- und Wiederherstellungsverfahren der Datenbanken von Drittanbietern werden in diesem Dokument nicht erläutert. Dieser Abschnitt bietet nur eine allgemeine Anleitung im Rahmen der vorgestellten Lösungen.
Lösung 1: Sicherung und Wiederherstellung mit einem Wiederherstellungsserver auf Google Cloud
- Erstellen Sie mit den integrierten Sicherungsverfahren Ihres Datenbankverwaltungssystems eine Datenbanksicherung.
- Verbinden Sie Ihr lokales Netzwerk mit Ihrem Google Cloud Netzwerk.
- Erstellen Sie einen Cloud Storage-Bucket als Ziel für die Datensicherung.
- Kopieren Sie die Sicherungsdateien mithilfe von
gcloud storageder gcloud CLI oder einer Partner-Gateway-Lösung nach Cloud Storage. Verwenden Sie dafür die oben im Abschnitt „Datensicherung und -wiederherstellung“ beschriebenen Schritte. Weitere Informationen finden Sie unter Zu Google Cloudmigrieren: Große Datasets übertragen. - Kopieren Sie die Transaktionslogs an den Wiederherstellungsort auf Google Cloud. Mit einer Sicherungskopie der Transaktionslogs erreichen Sie niedrige RPO-Werte.
Nach der Konfiguration dieser Sicherungstopologie prüfen Sie, ob eine Wiederherstellung auf dem System in Google Cloudmöglich ist. Bei diesem Schritt muss nicht nur die Sicherungsdatei in der Zieldatenbank wiederhergestellt werden. In der Regel müssen Sie auch die Transaktionslogs wiederverwenden, um einen möglichst niedrigen RTO-Wert zu erzielen. Im Folgenden wird ein typischer Wiederherstellungsablauf dargestellt:
- Erstellen Sie ein benutzerdefiniertes Image Ihres Datenbankservers auf Google Cloud. Der Datenbankserver muss im Image dieselbe Konfiguration haben wie der lokale Datenbankserver.
- Implementieren Sie einen Vorgang zum Kopieren der lokalen Sicherungsdateien und Transaktionslogdateien nach Cloud Storage. Eine Beispielimplementierung finden Sie unter Lösung 1.
- Starten Sie aus dem benutzerdefinierten Image eine Instanz mit minimaler Größe und fügen Sie alle erforderlichen nichtflüchtigen Speicher hinzu.
- Setzen Sie das Flag für das automatische Löschen für die nichtflüchtigen Speicher auf "false" (falsch).
- Übernehmen Sie die letzte, zuvor nach Cloud Storage kopierte Sicherungsdatei. Folgen Sie dazu der Anleitung für Ihr Datenbanksystem zur Wiederherstellung von Sicherungsdateien.
- Übernehmen Sie die neuesten Transaktions-Log-Dateien, die nach Cloud Storage kopiert wurden.
- Ersetzen Sie die Minimalinstanz durch eine größere Instanz, die in der Lage ist, den Produktionstraffic zu verarbeiten.
- Wechseln Sie die Clients und verweisen Sie auf die wiederhergestellte Datenbank in Google Cloud.
Wenn Ihre Produktionsumgebung ausgeführt wird und Produktionsarbeitslasten unterstützt, müssen Sie die Schritte für das Failover in dieGoogle Cloud -Wiederherstellungsumgebung rückgängig machen. Im Folgenden wird ein typischer Ablauf für die Rückkehr zur Produktionsumgebung dargestellt:
- Erstellen Sie eine Sicherung der Datenbank, die auf Google Cloudausgeführt wird.
- Kopieren Sie die Sicherungsdatei in Ihre Produktionsumgebung.
- Übernehmen Sie die Sicherungsdatei für Ihr Produktionsdatenbanksystem.
- Verhindern Sie, dass Clients eine Verbindung zum Datenbanksystem inGoogle Cloudherstellen können. Stoppen Sie dazu z. B. den Datenbanksystemdienst. Ab diesem Zeitpunkt ist die Anwendung bis zur Wiederherstellung der Produktionsumgebung nicht verfügbar.
- Kopieren Sie alle Transaktionslogdateien in die Produktionsumgebung und übernehmen Sie sie.
- Leiten Sie die Clientverbindungen zur Produktionsumgebung um.
Lösung 2: Replikation auf einen Standby-Server auf Google Cloud
Eine Möglichkeit zum Erzielen sehr niedriger RTO- und RPO-Werte besteht darin, Daten sowie in einigen Fällen den Datenbankstatus nicht einfach nur zu sichern, sondern in Echtzeit auf ein Replikat des Datenbankservers zu replizieren.
- Verbinden Sie Ihr lokales Netzwerk mit Ihrem Google Cloud Netzwerk.
- Erstellen Sie ein benutzerdefiniertes Image Ihres Datenbankservers auf Google Cloud. Die Konfiguration des Datenbankserver im Image muss mit der Konfiguration des lokalen Datenbankservers identisch sein.
- Starten Sie aus dem benutzerdefinierten Image eine Instanz und fügen Sie alle erforderlichen nichtflüchtigen Speicher hinzu.
- Setzen Sie das Flag für das automatische Löschen für die nichtflüchtigen Speicher auf "false" (falsch).
- Konfigurieren Sie die Replikation zwischen dem lokalen Datenbankserver und dem Zieldatenbankserver in Google Cloud anhand der Anleitung für die Datenbanksoftware.
- Clients werden im Normalbetrieb so konfiguriert, dass sie auf den lokalen Datenbankserver verweisen.
Stellen Sie nach der Konfiguration dieser Replikationstopologie die Clients so um, dass sie auf den Standby-Server verweisen, der im Google Cloud Netzwerk ausgeführt wird.
Sobald die Produktionsumgebung gesichert und in der Lage ist, Produktionsarbeitslasten zu unterstützen, müssen Sie den Produktionsdatenbankserver mit demGoogle Cloud -Datenbankserver neu synchronisieren und dann die Clients so umstellen, dass sie wieder auf die Produktionsumgebung verweisen.
Die Produktionsumgebung ist Google Cloud
In diesem Szenario werden sowohl Ihre Produktionsumgebung als auch Ihre Notfallwiederherstellungsumgebung auf Google Cloudausgeführt.
Datensicherung und -wiederherstellung
Eine gängige Variante für Datensicherungen ist die Verwendung eines Musters für einen mehrstufigen Speicher. Wenn sich die Produktionsarbeitslast auf Google Cloudbefindet, entspricht das mehrstufige Speichersystem dem folgenden Diagramm. Sie migrieren dabei Daten auf eine Stufe mit geringeren Speicherkosten, da die Notwendigkeit des Zugriffs auf diese gesicherten Daten weniger wahrscheinlich ist.
Bei diesem Muster werden die folgenden DR-Bausteine verwendet:
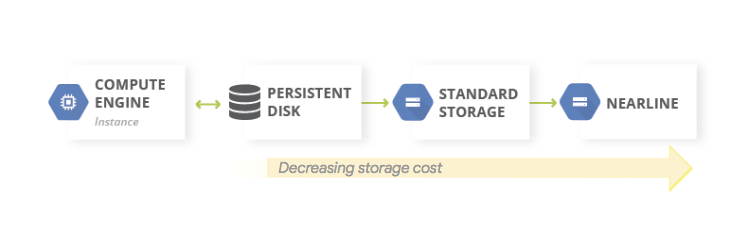
Da die Speicherklassen Nearline, Coldline und Archive für die Speicherung von Daten gedacht sind, auf die nur selten zugegriffen wird, fallen zusätzliche Kosten für den Abruf von Daten oder Metadaten an, die in diesen Klassen gespeichert sind, sowie für die Mindestspeicherdauer, die Ihnen in Rechnung gestellt wird.
Datenbanksicherung und -wiederherstellung
Wenn Sie eine selbstverwaltete Datenbank verwenden, wenn also z. B. auf einer Instanz von Compute Engine MySQL, PostgreSQL oder SQL Server installiert ist, gelten die gleichen Anforderungen wie für die Verwaltung von lokalen Produktionsdatenbanken. Sie müssen dabei aber nicht mehr die zugrunde liegende Infrastruktur verwalten.
Der Backup- und DR-Dienst ist eine zentrale, cloudnative Lösung zum Sichern und Wiederherstellen von Cloud- und Hybrid-Arbeitslasten. Er ermöglicht eine schnelle Datenwiederherstellung und erleichtert die schnelle Wiederaufnahme wichtiger Geschäftsabläufe.
Weitere Informationen zur Verwendung von Backup und DR für selbst verwaltete Datenbankszenarien in Google Cloudfinden Sie unter:
Alternativ können Sie mit den entsprechenden DR-Bausteinfunktionen Konfigurationen für hohe Verfügbarkeit einrichten, die für niedrige RTO-Werte sorgen. Mit der entsprechenden Datenbankkonfiguration lässt sich auf einfache Weise ein Status wiederherstellen, der dem Zustand vor dem Notfall so nahe wie möglich kommt. Dies ermöglicht niedrige RPO-Werte. Google Cloud bietet eine Vielzahl von Optionen für dieses Szenario.
In diesem Abschnitt werden zwei gängige Ansätze für eine Architektur zur Datenbankwiederherstellung für selbstverwaltete Datenbanken auf Google Cloud erläutert.
Datenbankserver ohne Statussynchronisierung wiederherstellen
Ein gängiges Muster ist die Wiederherstellung eines Datenbankservers, bei dem der Systemstatus nicht mit einem aktuellen Standby-Replikat synchronisiert werden muss.
Bei diesem Muster werden die folgenden DR-Bausteine verwendet:
- Compute Engine
- Verwaltete Instanzgruppen
- Cloud Load Balancing (internes Load-Balancing)
Im folgenden Diagramm ist eine Beispielarchitektur für dieses Szenario veranschaulicht. Mit Implementierung dieser Architektur erhalten Sie einen DR-Plan, der automatisch auf einen Fehlerstatus reagiert, sodass keine manuelle Wiederherstellung erforderlich ist.

Mit den folgenden Schritten können Sie ein solches Szenario konfigurieren:
- Erstellen Sie ein VPC-Netzwerk.
Erstellen Sie ein benutzerdefiniertes Image, das mit dem Datenbankserver konfiguriert ist. Führen Sie dazu folgende Schritte aus:
- Konfigurieren Sie den Server so, dass die Datenbankdateien und Log-Dateien in einen hinzugefügten nichtflüchtigen Standardspeicher geschrieben werden.
- Erstellen Sie einen Snapshot vom hinzugefügten nichtflüchtigen Speicher.
- Konfigurieren Sie ein Startskript, das einen nichtflüchtigen Speicher aus dem Snapshot erstellt und das Laufwerk bereitstellt.
- Erstellen Sie ein benutzerdefiniertes Image des Startlaufwerks.
Erstellen Sie eine Instanzvorlage, die das Image verwendet.
Konfigurieren Sie mithilfe der Instanzvorlage eine verwaltete Instanzgruppe mit einer Zielgröße von 1.
Konfigurieren Sie die Systemdiagnose mithilfe von Cloud Monitoring-Messwerten.
Konfigurieren Sie das interne Load Balancing mithilfe der verwalteten Instanzgruppe.
Konfigurieren Sie eine geplante Aufgabe zum Erstellen von regelmäßigen Snapshots des nichtflüchtigen Speichers.
Wenn eine Ersatzdatenbankinstanz erforderlich ist, hat diese Konfiguration folgende Auswirkungen:
- Ein weiterer Datenbankserver der richtigen Version wird in derselben Zone aufgerufen.
- Der neu erstellten Datenbankserverinstanz wird ein nichtflüchtiger Speicher mit den neuesten Sicherungs- und Transaktionslogdateien hinzugefügt.
- Die Notwendigkeit einer Neukonfiguration von Clients, die als Reaktion auf ein Ereignis mit Ihrem Datenbankserver kommunizieren, wird minimiert.
- Die Google Cloud -Sicherheitskontrollen (IAM-Richtlinien, Firewalleinstellungen), die für den Produktionsdatenbankserver gelten, werden auf den wiederhergestellten Datenbankserver angewendet.
Da die Ersatzinstanz aus einer Instanzvorlage erstellt wird, gelten die Kontrollen für das Original auch für die Ersatzinstanz.
In diesem Szenario werden einige der inGoogle Cloudverfügbaren Funktionen für Hochverfügbarkeit genutzt. Sie müssen keine Failover-Schritte initiieren, da sie im Notfall automatisch ausgeführt werden. Der interne Load-Balancer sorgt dafür, dass bei einer erforderlichen Ersatzinstanz dieselbe IP-Adresse für den Datenbankserver verwendet wird. Die Instanzvorlage und das benutzerdefinierte Image garantieren, dass die Ersatzinstanz wie die Instanz konfiguriert ist, die sie ersetzt. Erstellen Sie regelmäßig Snapshots der nichtflüchtigen Speicher. Dies stellt sicher, dass die Ersatzinstanz, wenn Laufwerke aus den Snapshots neu erstellt und der Ersatzinstanz hinzugefügt wurden, Daten verwendet, die gemäß einem durch Häufigkeit der Snapshots bestimmten RPO-Wert wiederhergestellt wurden. In dieser Architektur werden auch die neuesten Transaktions-Logdateien, die auf den nichtflüchtigen Speicher geschrieben wurden, automatisch wiederhergestellt.
Die verwaltete Instanzgruppe ermöglicht eine umfassende Hochverfügbarkeit. Sie bietet auf Anwendungs- oder Instanzebene automatisierte Verfahren zur Reaktion auf Fehler. Sie müssen also nicht manuell eingreifen, wenn eines dieser Szenarien eintritt. Wenn Sie eine Zielgröße von eins festlegen, haben Sie immer nur eine aktive Instanz, die in der verwalteten Instanzgruppe ausgeführt wird und Traffic bereitstellt.
Nichtflüchtige Standardspeicher sind zonale Ressourcen. Wenn ein Zonenfehler auftritt, sind Snapshots für die Neuerstellung von Laufwerken erforderlich. Snapshots sind auch regionenübergreifend verfügbar. Dadurch können Sie ein Laufwerk nicht nur in derselben, sondern auch in einer anderen Region wiederherstellen.
Eine Variante dieser Konfiguration besteht darin, regionale nichtflüchtige Speicher anstelle von nichtflüchtigen Standardspeichern zu verwenden. In diesem Fall müssen Sie den Snapshot im Rahmen des Wiederherstellungsschritts nicht wiederherstellen.
Die jeweils geeignete Variante hängt von Ihrem Budget sowie von den RTO- und RPO-Werten ab.
Nach teilweiser Beschädigung in sehr großen Datenbanken wiederherstellen
Die asynchrone Replikation nichtflüchtiger Speicher bietet eine Blockspeicherreplikation mit niedrigem RPO und RTO für die regionsübergreifende Aktiv-Passiv-Notfallwiederherstellung. Mit dieser Speicheroption können Sie die Replikation für Compute Engine-Arbeitslasten auf Infrastrukturebene statt auf Arbeitslastebene verwalten.
In Datenbanken mit einer Speicherkapazität im Petabyte-Bereich können Ausfälle auftreten, die sich nur auf einen Teil der Daten auswirken. In diesem Fall können Sie die Menge der wiederherzustellenden Daten minimieren. Sie müssen also nicht die gesamte Datenbank wiederherstellen, nur um einige Daten daraus wiederherzustellen.
Dabei sind mehrere Strategien zur Reduzierung möglich:
- Speichern der Daten in unterschiedlichen Tabellen für bestimmte Zeiträume. Dadurch wird gewährleistet, dass nur eine Teilmenge von Daten in einer neuen Tabelle wiederhergestellt werden muss und nicht das gesamte Dataset.
Speichern der Originaldaten in Cloud Storage. So können Sie eine neue Tabelle erstellen und die unbeschädigten Daten noch einmal laden. Daraufhin können Sie die Anwendungen so anpassen, dass sie auf die neue Tabelle verweisen.
Wenn Ihr RTO-Wert es zulässt, können Sie außerdem den Zugriff auf die Tabelle mit den beschädigten Daten verhindern. Dazu belassen Sie die Anwendungen im Offline-Modus, bis die unbeschädigten Daten in einer neuen Tabelle wiederhergestellt sind.
Verwaltete Datenbankdienste auf Google Cloud
In diesem Abschnitt werden einige Methoden erläutert, mit denen Sie geeignete Sicherungs- und Wiederherstellungsverfahren für die verwalteten Datenbankdienste aufGoogle Cloudimplementieren können.
Verwaltete Datenbanken sind auf Skalierbarkeit ausgelegt. Daher sind die herkömmlichen Sicherungs- und Wiederherstellungsverfahren traditioneller RDMBS-Systeme dafür in der Regel nicht verfügbar. Wie bei selbstverwalteten Datenbanken soll bei einer Datenbank, in der sich Petabyte von Daten speichern lassen, grundsätzlich die Datenmenge minimiert werden, die in einem DR-Szenario wiederhergestellt werden muss. Für jede verwaltete Datenbank gibt es eine Reihe von Strategien zur Erreichung dieses Ziels.
Bigtable bietet Bigtable-Replikation. Eine replizierte Bigtable-Datenbank bietet bei zonalen oder regionalen Ausfällen eine höhere Verfügbarkeit als ein einzelner Cluster, zusätzlichen Lesedurchsatz und eine höhere Langlebigkeit und Ausfallsicherheit.
Bigtable-Sicherungen bieten einen vollständig verwalteten Dienst, mit dem Sie eine Kopie des Schemas und der Daten einer Tabelle speichern und später von der Sicherung in einer neuen Tabelle wiederherstellen können.
Außerdem können Sie Tabellen als eine Reihe von Hadoop-Sequenzdateien aus Bigtable exportieren. Diese Dateien lassen sich dann in Cloud Storage speichern oder Sie verwenden sie, um die Daten wieder in eine andere Bigtable-Instanz zu importieren. Sie können Ihr Bigtable-Dataset asynchron in Zonen einer Google Cloud -Region replizieren.
BigQuery: Für die Archivierung von Daten bietet BigQuery einen langfristigen Speicher. Wenn eine Tabelle innerhalb von 90 aufeinanderfolgenden Tagen nicht bearbeitet wird, reduziert sich der Preis für die Speicherung dieser Tabelle automatisch um 50 %. Wenn eine Tabelle in die Langzeitspeicherung übergeht, kommt es zu keiner Beeinträchtigung von Leistung, Langlebigkeit, Verfügbarkeit oder anderer Funktionen. Wird die Tabelle jedoch wieder bearbeitet, gelten wieder die regulären Speicherpreise und der 90-Tage-Zeitraum tritt von Neuem in Kraft.
BigQuery wird in zwei Zonen in einer einzelnen Region repliziert, was aber bei der Beschädigung von Tabellen wenig nützt. Sie benötigen daher einen Plan zur Wiederherstellung bei einem solchen Szenario. Sie haben zum Beispiel folgende Möglichkeiten:
- Wenn die Beschädigung innerhalb von sieben Tagen festgestellt wird, fragen Sie die Tabelle für einen früheren Zeitpunkt ab, um sie in einem Zustand vor der Beschädigung mithilfe von Snapshot-Decorators wiederherzustellen
- Sie exportieren die Daten aus BigQuery und erstellen eine neue Tabelle mit den exportierten Daten, in der die beschädigten Daten nicht enthalten sind
- Speichern der Daten in unterschiedlichen Tabellen für bestimmte Zeiträume. Dies stellt sicher, dass Sie nur eine Teilmenge der Daten in einer neuen Tabelle wiederherstellen müssen und nicht das gesamte Dataset
- Erstellen Sie Kopien eines Datasets in bestimmten Zeiträumen. Sie können diese Kopien verwenden, wenn eine Datenkorruption auftritt, die jenseits eines Zeitpunkts stattfindet, der von einer zeitnahen Abfrage erfasst werden kann (z. B. vor mehr als 7 Tagen). Sie können ein Dataset auch von einer Region in eine andere kopieren, um die Verfügbarkeit der Daten bei regionalen Ausfällen zu gewährleisten.
- Speichern der Originaldaten in Cloud Storage, damit Sie eine neue Tabelle erstellen und die unbeschädigten Daten noch einmal laden können. Daraufhin können Sie die Anwendungen so anpassen, dass sie auf die neue Tabelle verweisen.
Firestore. Mit dem verwalteten Export- und Importdienst können Sie Firestore-Entitäten mithilfe einer Cloud Storage-Bucket importieren und exportieren. Auf diese Weise lässt sich ein Vorgang implementieren, mit dem sich Daten nach einem versehentlichen Löschen wiederherstellen lassen.
Cloud SQL Wenn Sie Cloud SQL, die vollständig verwalteteGoogle Cloud MySQL-Datenbank, verwenden, sollten Sie automatische Sicherungen und binäres Logging für Ihre Cloud SQL-Instanzen aktivieren. So können Sie eine Wiederherstellung zu einem bestimmten Zeitpunkt ausführen. Dabei wird die Datenbank aus einer Sicherung in einer neuen Cloud SQL-Instanz wiederhergestellt. Weitere Informationen finden Sie unter Informationen zu Cloud SQL-Sicherungen und Notfallwiederherstellung (Disaster Recovery, DR) in Cloud SQL.
Cloud SQL lässt sich auch in einer HA-Konfiguration und regionenübergreifenden Replikaten konfigurieren, um bei einem zonalen oder regionalen Ausfall die Betriebszeit hoch zu halten.
Wenn Sie eine geplante Wartung mit nahezu keinen Ausfallzeiten für Cloud SQL aktiviert haben, können Sie die Auswirkungen der Wartungsereignisse auf Ihre Instanzen bewerten, indem Sie geplante Wartungsereignisse mit nahezu keinen Ausfallzeiten auf Cloud SQL für MySQL und auf Cloud SQL für PostgreSQL simulieren.
Bei der Cloud SQL Enterprise Plus-Version können Sie die erweiterte Notfallwiederherstellung verwenden, um die Wiederherstellung und den Fallback nach einem regionenübergreifenden Failover zu vereinfachen und Datenverluste zu vermeiden.
Spanner Mit Dataflow-Vorlagen haben Sie die Möglichkeit, Ihre Datenbank vollständig in Avro-Dateien in einen Cloud Storage-Bucket zu exportieren. Mit einer anderen Vorlage können Sie die exportierten Dateien dann wieder in eine neue Spanner-Datenbank importieren.
Der Dataflow-Connector bietet Ihnen die Möglichkeit, den entsprechenden Code zu schreiben, um Daten in Spanner in einer Dataflow-Pipeline zu lesen bzw. in diese zu schreiben. Dadurch können Sie Sicherungen besser steuern. Mit dem Connector lassen sich beispielsweise Daten aus Spanner in Cloud Storage als Sicherungsziel kopieren. Die Geschwindigkeit, mit der Daten aus Spanner gelesen oder zurückgeschrieben werden können, hängt dabei von der Anzahl der konfigurierten Knoten ab. Dies hat direkten Einfluss auf Ihre RTO-Werte.
Das Commit-Zeitstempelfeature von Spanner kann für inkrementelle Sicherungen hilfreich sein. Es bietet die Möglichkeit, nur die Zeilen auszuwählen, die seit der letzten kompletten Sicherung hinzugefügt oder geändert wurden.
Für verwaltete Sicherungen können Sie mit Cloud Spanner Backup and Restore einheitliche Sicherungen erstellen, die bis zu 1 Jahr lang aufbewahrt werden können. Der RTO-Wert ist im Vergleich zu export niedriger, da durch die Wiederherstellung die Sicherung direkt bereitgestellt wird, ohne die Daten zu kopieren.
Bei kleinen RTO-Werten können Sie eine Warm-Stand-by-Spanner-Instanz einrichten und bei dieser die mindestens erforderlichen Knoten konfigurieren, um Ihrem Speicher-, Lese- und Schreibdurchsatz Rechnung zu tragen.
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt (Point-in-Time-Recovery, PITR) von Spanner können Sie Daten von einem bestimmten Zeitpunkt in der Vergangenheit wiederherstellen. Wenn ein Operator beispielsweise versehentlich Daten schreibt oder eine Anwendungseinführung eine beschädigte Datenbank verursacht, können Sie mit PITR die Daten eines früheren Zeitpunkts wiederherstellen, der maximal sieben Tage zurückliegt.
Cloud Composer: Mit Cloud Composer, einer verwalteten Version von Apache Airflow, lassen sich regelmäßige Sicherungen mehrererGoogle Cloud -Datenbanken planen. Sie können einen gerichteten azyklischen Graphen (Directed Acyclic Graph, DAG) erstellen, der nach einem bestimmten Zeitplan (z. B. täglich) ausgeführt wird, um die Daten entweder in ein anderes Projekt, ein anderes Dataset oder in eine andere Tabelle (je nach verwendeter Lösung) zu kopieren oder nach Cloud Storage zu exportieren.
Das Exportieren oder Kopieren von Daten kann mit den verschiedenen Cloud Platform-Operatoren ausgeführt werden.
Sie können einen DAG beispielsweise für einen der folgenden Schritte erstellen:
- Exportieren einer BigQuery-Tabelle in Cloud Storage mit BigQueryToCloudStorageOperator
- Exportieren von Firestore im Datastore-Modus (Datastore) mit dem DatastoreExportOperator in Cloud Storage
- Exportieren von MySQL-Tabellen nach Cloud Storage mit dem MySqlToGoogleCloudStorageOperator
- Exportieren von Postgres-Tabellen nach Cloud Storage mit dem PostgresToGoogleCloudStorageOperator
Andere Cloud als Produktionsumgebung
In diesem Szenario verwendet Ihre Produktionsumgebung einen anderen Cloud-Anbieter. In Ihrem Plan für die Notfallwiederherstellung wird Google Cloud als Wiederherstellungsort genutzt.
Datensicherung und -wiederherstellung
Die Übertragung von Daten zwischen Objektspeichern ist ein häufiger Anwendungsfall für DR-Szenarien. Der Storage Transfer Service ist mit Amazon S3 kompatibel und wird für die Übertragung von Objekten von Amazon S3 nach Cloud Storage empfohlen.
Sie können einen Übertragungsjob für die Planung einer regelmäßigen Synchronisierung von der Datenquelle zur Datensenke konfigurieren. Dabei stehen erweiterte Filter basierend auf dem Datum der Dateierstellung, den Dateinamen und den bevorzugten Tageszeiten zur Verfügung. Um den gewünschten RPO-Wert zu erreichen, müssen Sie die folgenden Faktoren berücksichtigen:
Änderungsrate. Die Datenmenge, die für einen bestimmten Zeitraum generiert oder aktualisiert wird. Je höher die Änderungsrate, desto mehr Ressourcen sind für die Übertragung der Änderungen an das Ziel bei jedem inkrementellen Übertragungszeitraum erforderlich.
Übertragungsleistung Die für das Übertragen von Dateien benötigte Zeit. Bei großen Dateiübertragungen wird dieser Wert normalerweise durch die verfügbare Bandbreite zwischen Quelle und Ziel bestimmt. Wenn ein Übertragungsjob jedoch aus einer großen Anzahl kleiner Dateien besteht, können die Abfragen pro Sekunde zu einem einschränkenden Faktor werden. In diesem Fall können Sie mehrere gleichzeitige Jobs planen, um die Leistung zu skalieren, solange die Bandbreite ausreicht. Wir empfehlen Ihnen, die Übertragungsleistung mithilfe einer repräsentativen Teilmenge Ihrer realen Daten zu messen.
Häufigkeit. Das zeitliche Intervall zwischen Sicherungsjobs. Die Aktualität der Daten am Ziel entspricht dem Zeitpunkt, zu dem ein Übertragungsjob das letzte Mal geplant wurde. Daher ist es wichtig, dass die Intervalle zwischen aufeinanderfolgenden Übertragungsjobs nicht länger als das RPO-Ziel sind. Wenn das RPO-Ziel beispielsweise 1 Tag beträgt, muss der Übertragungsjob mindestens einmal am Tag geplant werden.
Monitoring und Warnungen. Storage Transfer Service bietet Pub/Sub-Benachrichtigungen für verschiedene Ereignisse. Wir empfehlen, diese Benachrichtigungen zu abonnieren, um unerwartete Fehler oder Änderungen bei den Abschlusszeiten des Jobs zu bewältigen.
Datenbanksicherung und -wiederherstellung
In diesem Dokument werden weder die verschiedenen integrierten Sicherungs- und Wiederherstellungsverfahren der Datenbanken von Drittanbietern noch die Sicherungs- und Wiederherstellungstechniken anderer Cloudanbieter im Detail behandelt. Wenn Sie nicht verwaltete Datenbanken für die Compute-Dienste verwenden, stehen Ihnen Hochverfügbarkeitsfunktionen Ihres Produktionscloudanbieters zur Verfügung. Sie können diese erweitern, um eine Hochverfügbarkeitsbereitstellung in Google Cloudeinzubinden. Alternativ bietet sich Cloud Storage als kalter Datenspeicher für Ihre Sicherungsdateien von Datenbanken an.
Nächste Schritte
- Google Cloud Geografie und Regionen
Weitere Dokumente in dieser DR-Reihe:
- Leitfaden zur Planung der Notfallwiederherstellung
- Bausteine der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
- Architekturen für Hochverfügbarkeit von MySQL-Clustern in Compute Engine
Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center