In diesem Dokument werden Verfahren zur Implementierung und Automatisierung von Continuous Integration (CI), Continuous Delivery (CD) und Continuous Training (CT) für ML-Systeme (Maschinelles Lernen) beschrieben. Dieses Dokument bezieht sich hauptsächlich auf Systeme mit prädiktiver KI.
Data Science und ML entwickeln sich heutzutage zu zentralen Technologien für die Lösung komplexer Probleme in der realen Welt, für die Umgestaltung von Branchen und für die Wertschöpfung in allen Bereichen. Derzeit stehen Ihnen folgende Bestandteile für die Anwendung eines effektiven maschinellen Lernens zur Verfügung:
- Große Datasets
- Preisgünstige On-Demand-Rechenressourcen
- Spezielle Beschleuniger für ML auf verschiedenen Cloud-Plattformen
- Schnelle Fortschritte in verschiedenen ML-Forschungsbereichen (z. B. Computer Vision, Natural Language Understanding, generative KI und Recommendations AI-Systeme).
Daher investieren viele Unternehmen in ihre Data-Science-Teams und ML-Funktionen mit dem Ziel, Vorhersagemodelle zu entwickeln, die ihren Nutzern einen geschäftlichen Mehrwert bieten.
Dieses Dokument richtet sich an Data Scientists und ML-Entwickler, die DevOps-Prinzipien auf ML-Systeme (MLOps) anwenden möchten. MLOps ist eine ML-Entwicklungskultur und -praxis, die darauf abzielt, die ML-Systementwicklung (Dev) und den ML-Systembetrieb (Ops) zu verbinden. MLOps zu praktizieren bedeutet, auf Automatisierung und Überwachung zu setzen, und zwar in allen Phasen der ML-Systemkonfiguration wie Integration, Testen, Freigabe, Bereitstellung und Infrastrukturverwaltung.
Data Scientists können ein ML-Modell mit Vorhersageleistung auf einem Dataset eines Offline-Holdouts implementieren und trainieren, sofern relevante Trainingsdaten für ihren Anwendungsfall vorliegen. Die eigentliche Herausforderung besteht jedoch nicht darin, ein ML-Modell zu entwickeln. Vielmehr soll ein integriertes ML-System aufgebaut und kontinuierlich in der Produktion betrieben werden. Aus der langjährigen Geschichte von Produktions-ML-Diensten bei Google haben wir gelernt, dass der Betrieb ML-basierter Systeme in der Produktion viele Probleme mit sich bringen kann. Einige dieser Probleme finden Sie unter Machine Learning: The High Interest Credit Card of Technical Debt zusammengefasst.
Wie im folgenden Diagramm dargestellt, besteht nur ein kleiner Teil eines realen ML-Systems aus ML-Code. Die zusätzlich erforderlichen Elemente, die den ML-Code umgeben, sind umfangreich und komplex.
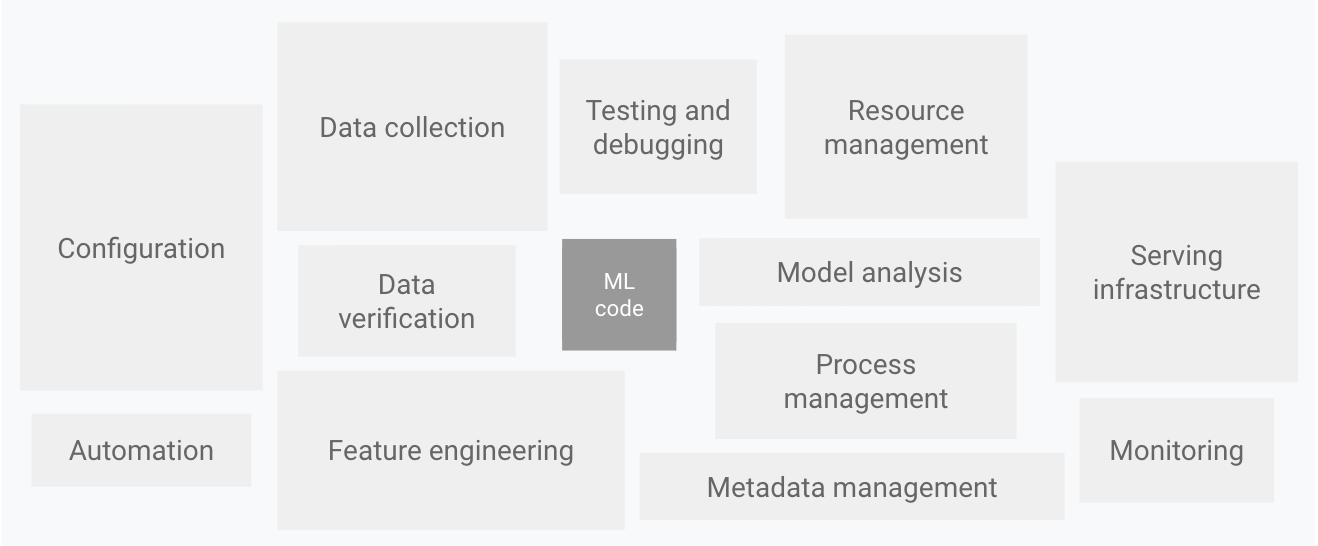
Abbildung 1. Elemente für ML-Systeme. Adaptiert aus Hidden Technical Debt in Machine Learning Systems.
Das obige Diagramm zeigt die folgenden Systemkomponenten:
- Konfiguration
- Automatisierung
- Datenerhebung
- Datenüberprüfung
- Testen und Fehlerbehebung
- Ressourcenverwaltung
- Modellanalyse
- Prozess- und Metadatenverwaltung
- Infrastruktur bereitstellen
- Monitoring
Was die Entwicklung und den Betrieb solcher komplexen Systeme angeht, können Sie problemlos die bekannten DevOps-Prinzipien auf ML-Systeme übertragen (MLOps). In diesem Dokument werden Konzepte erläutert, die beim Einrichten einer MLOps-Umgebung für Ihre Data-Science-Praktiken zu berücksichtigen sind, z. B. CI, CD und CT in ML.
Folgende Themen werden behandelt:
- DevOps im Vergleich zu MLOps
- Schritte zur Entwicklung von ML-Modellen
- Reifestufen von MLOps
- MLOps für generative KI
DevOps im Vergleich zu MLOps
DevOps ist eine beliebte Vorgehensweise bei der Entwicklung und dem Betrieb großer Softwaresysteme. Sie bietet Vorteile wie eine Verkürzung der Entwicklungszyklen, eine Erhöhung der Bereitstellungsgeschwindigkeit und zuverlässige Releases. Sie führen zwei Konzepte in die Entwicklung des Softwaresystems ein, um diese Vorteile zu erzielen:
Ein ML-System ist ein Softwaresystem. Daher gelten ähnliche Vorgehensweisen, mit denen Sie gewährleisten, dass ML-Systeme zuverlässig in großem Umfang aufgebaut und betrieben werden können.
Sie unterscheiden sich jedoch durch folgende Anforderungen von anderen Softwaresystemen:
Zusammenarbeit im Team: In einem ML-Projekt besteht ein Teil des Teams normalerweise aus Data Scientists oder ML-Forschern, die sich schwerpunktmäßig mit explorativer Datenanalyse, Modellentwicklung und Experimenten beschäftigen. Solche Teammitglieder sind nicht unbedingt erfahrene Softwareentwickler, die Dienste auf Produktionsebene entwickeln können.
Entwicklung: ML ist experimentell. Sie als Entwickler sollten verschiedene Funktionen, Algorithmen, Modellierungstechniken und Parameterkonfigurationen ausprobieren, um so schnell wie möglich die beste Lösung für das Problem zu finden. Die Herausforderung besteht darin, zu erfassen, was funktioniert hat und was nicht, die Reproduzierbarkeit der Ergebnisse zu erhalten und gleichzeitig die Wiederverwendbarkeit des Codes zu maximieren.
Tests: Das Testen eines ML-Systems ist aufwendiger als das Testen anderer Softwaresysteme. Zusätzlich zu den typischen Einheiten- und Integrationstests ist die Datenvalidierung, Qualitätsbewertung trainierter Modelle und Modellvalidierung erforderlich.
Bereitstellung: In ML-Systemen ist die Bereitstellung nicht so einfach wie die Bereitstellung eines offline trainierten ML-Modells als Vorhersagedienst. ML-Systeme erfordern unter Umständen die Bereitstellung einer mehrstufigen Pipeline, mit der Modelle automatisch neu trainiert und bereitgestellt werden. Diese Pipeline ist komplexer und erfordert die Automatisierung der Schritte, die von Data Scientists zum Trainieren und Validieren neuer Modelle vor der Bereitstellung sonst manuell ausgeführt werden.
Produktion: ML-Modelle können nicht nur aufgrund von suboptimalem Coding, sondern auch aufgrund sich ständig weiterentwickelnder Datenprofile eine verminderte Leistung aufweisen. Für ML-Modelle gibt es also mehr Möglichkeiten als für herkömmliche Softwaresysteme, an Leistung einzubüßen, und Sie müssen diese Einbußen berücksichtigen. Sie müssen daher die zusammenfassenden Statistikdaten für Ihr Modell im Auge behalten und seine Onlineleistung beobachten, um gegebenenfalls Benachrichtigungen zu senden oder ein Rollback durchzuführen, wenn Werte von Ihren Erwartungen abweichen.
Jeweils ähnlich aufgebaut sind bei ML und bei anderen Softwaresystemen die Continuous Integration der Versionsverwaltung, die Einheitentests, die Integrationstests und die Continuous Delivery des Softwaremoduls oder des Pakets. Dennoch gibt es bei ML einige Unterschiede zu beachten:
- Bei CI geht es nicht mehr nur um das Testen und Validieren von Code und Komponenten, sondern auch um das Testen und Validieren von Daten, Datenschemas und Modellen.
- CD bezieht sich nicht nur auf ein einzelnes Softwarepaket oder einen Dienst, sondern auf ein System (eine ML-Trainingspipeline), das automatisch einen anderen Dienst (Modellvorhersagedienst) bereitstellen soll.
- CT ist ein neues, für ML-Systeme spezifisches Merkmal der Systementwicklung, bei dem es um das automatische erneute Trainieren und Bereitstellen der Modelle geht.
Der folgende Abschnitt beschreibt die typischen Schritte zum Trainieren und Bewerten eines ML-Modells, das als Vorhersagedienst verwendet wird.
Data-Science-Schritte für ML
Nachdem Sie in einem ML-Projekt den geschäftlichen Anwendungsfall definiert und die Erfolgskriterien festgelegt haben, umfasst der Prozess zur Bereitstellung eines ML-Modells für die Produktion folgende Schritte. Diese Schritte können manuell oder durch eine automatische Pipeline durchgeführt werden.
- Datenextraktion: Sie wählen die relevanten Daten aus verschiedenen Datenquellen für die ML-Aufgabe aus und integrieren sie.
- Datenanalyse: Sie führen eine explorative Datenanalyse (EDA) durch, um die verfügbaren Daten zum Erstellen des ML-Modells zu ermitteln. Aus diesem Prozess ergibt sich Folgendes:
- Identifikation des Datenschemas und der Merkmale, die vom Modell erwartet werden.
- Feststellung, welche Datenvorbereitung und welches Feature Engineering für das Modell erforderlich sind.
- Datenvorbereitung: Die Daten werden für die ML-Aufgabe vorbereitet. Diese Vorbereitung umfasst die Datenbereinigung, bei der Sie die Daten in Trainings-, Validierungs- und Test-Sets aufteilen. Außerdem wenden Sie Datentransformationen und Feature Engineering auf das Modell an, das die Zielaufgabe löst. Die Ausgabe dieses Schritts sind die Datenaufteilungen im vorbereiteten Format.
- Modelltraining: Der Data Scientist implementiert verschiedene Algorithmen mit den vorbereiteten Daten, um damit unterschiedliche ML-Modelle zu trainieren. Darüber hinaus unterziehen Sie die implementierten Algorithmen einer Hyperparameter-Abstimmung, um ein ML-Modell mit der besten Leistung zu erhalten. Die Ausgabe dieses Schritts ist ein trainiertes Modell.
- Modellbewertung: Das Modell wird mit einem Holdout-Test-Set bewertet, um die Modellqualität zu evaluieren. Die Ausgabe dieses Schritts ist eine Reihe von Messwerten, mit denen die Qualität des Modells bewertet wird.
- Modellvalidierung: Es wird bestätigt, dass das Modell für die Bereitstellung geeignet ist, seine Vorhersageleistung also besser ist als eine bestimmte Referenz.
- Modellbereitstellung: Das validierte Modell wird in einer Zielumgebung bereitgestellt, um Vorhersagen abzurufen. Für diese Bereitstellung gibt es folgende Möglichkeiten:
- Als Mikrodienste mit einer REST API zur Bereitstellung von Onlinevorhersagen
- Als in ein Edge- oder Mobilgerät eingebettetes Modell
- Als Teil eines Batchvorhersagesystems
- Modellmonitoring: Die Vorhersageleistung des Modells wird beobachtet, um potenziell eine neue Iteration im ML-Prozess aufzurufen.
Der Grad der Automatisierung dieser Schritte definiert die Reife des ML-Prozesses, worunter hier die Geschwindigkeit zu verstehen ist, die im Training neuer Modelle bei Vorliegen neuer Daten oder bei neuen Implementierungen erreicht wird. In den folgenden Abschnitten werden drei MLOps-Stufen beschrieben: von der häufigsten Stufe, die keine Automatisierung umfasst, bis hin zur Automatisierung von ML- und CI/CD-Pipelines.
MLOps-Stufe 0: Manueller Prozess
In vielen Teams gibt es Data Scientists und ML-Forscher, die hochmoderne Modelle erstellen können. Der Prozess zum Erstellen und Bereitstellen von ML-Modellen erfolgt allerdings vollständig manuell. Das wird als einfache Reifestufe oder als Stufe 0 angesehen. Das folgende Diagramm zeigt den Workflow dieses Prozesses.

Abbildung 2. Manuelle ML-Schritte zur Bereitstellung des Modells als Vorhersagedienst
Merkmale
In der folgenden Liste sind die Merkmale des Prozesses für MLOps Stufe 0 hervorgehoben, wie in Abbildung 2 dargestellt:
Manueller, skriptgesteuerter und interaktiver Prozess: Jeder Schritt ist manuell, einschließlich Datenanalyse, Datenvorbereitung, Modelltraining und Validierung. Er erfordert die manuelle Ausführung jedes einzelnen Schritts und den manuellen Übergang von einem Schritt zum anderen. Dieser Prozess wird in der Regel durch experimentellen Code gesteuert, der von Data Scientists interaktiv in Notebooks geschrieben und ausgeführt wird, bis ein praktikables Modell erstellt ist.
Trennung zwischen ML und operativer Entwicklung: Der Prozess unterscheidet zwischen Data Scientists, die das Modell erstellen, und Entwicklern, die das Modell als Vorhersagedienst bereitstellen. Die Data Scientists übergeben ein trainiertes Modell als Artefakt an das Entwicklerteam, damit diese es in ihrer API-Infrastruktur bereitstellen können. Diese Übergabe kann das Platzieren des trainierten Modells an einem Speicherort, das Prüfen des Modellobjekts in einem Code-Repository oder das Hochladen in eine Modell-Registry umfassen. Anschließend müssen die Entwickler, die das Modell bereitstellen, die erforderlichen Funktionen in der Produktion so verfügbar machen, dass sie eine niedrige Latenz bieten. Dies kann zu Abweichungen zwischen Training und Bereitstellung führen.
Seltene Versionsiterationen: Bei diesem Prozess wird davon ausgegangen, dass Ihr Data-Science-Team einige Modelle verwaltet, die sich nicht häufig ändern, also entweder die Modellimplementierung geändert oder das Modell mit neuen Daten neu trainiert wird. Eine neue Modellversion wird nur wenige Male pro Jahr bereitgestellt.
Keine CI: Da nur wenige Implementierungsänderungen angenommen werden, wird CI ignoriert. Normalerweise ist das Testen des Codes Teil der Notebook- oder Skriptausführung. Die Skripts und Notebooks, die die Testschritte implementieren, sind quellengesteuert und erzeugen Artefakte wie trainierte Modelle, Bewertungsmesswerte und Visualisierungen.
Keine CD: Da es keine häufigen Bereitstellungen von Modellversionen gibt, ist CD in diesem Fall nicht relevant.
Bereitstellung bezieht sich auf den Vorhersagedienst: Der Prozess betrifft lediglich die Bereitstellung des trainierten Modells als Vorhersagedienst, z. B. einen Mikrodienst mit einer REST API, und nicht die Bereitstellung des gesamten ML-Systems.
Fehlendes aktives Leistungsmonitoring: Der Prozess erfasst oder protokolliert keine Modellvorhersagen und -aktionen, die erforderlich sind, um eine Verschlechterung der Modellleistung und andere unerwünschte Verhaltenstendenzen des Modells zu erkennen.
Das Entwicklerteam verfügt unter Umständen über eine eigene komplexe Einrichtung für API-Konfiguration, -Tests und -Bereitstellung, einschließlich Sicherheit, Regression sowie Last- und Canary-Tests. Außerdem durchläuft die Produktionsbereitstellung einer neuen Version eines ML-Modells in der Regel A/B Testing oder Onlinetests, bevor das Modell zur Bereitstellung des gesamten Traffics für die Vorhersageanforderung hochgestuft wird.
Herausforderungen
MLOps-Stufe 0 ist in vielen Unternehmen üblich, die damit beginnen, ML auf ihre Anwendungsfälle anzuwenden. Dieser manuelle, von Data Scientists gesteuerte Prozess kann ausreichen, wenn Modelle selten geändert oder trainiert werden. In der Praxis funktionieren die Modelle häufig nicht, wenn sie in der realen Welt bereitgestellt werden. Die Modelle passen sich nicht an Änderungen in der Dynamik der Umgebung oder an Änderungen der Daten an, die die Umgebung beschreiben. Weitere Informationen finden Sie unter Why Machine Learning Models Crash and Burn in Production.
Gehen Sie folgendermaßen vor, um diese Probleme zu beheben und die Treffsicherheit Ihres Modells in der Produktion aufrechtzuerhalten:
Beobachten Sie aktiv die Qualität Ihres Modells in der Produktion: Mithilfe von Monitoring können Sie Leistungseinbußen und veraltete Modelle erkennen. Das Monitoring dient als Ausgangspunkt für eine neue Experimentieriteration und für das (manuelle) erneute Trainieren des Modells auf neue Daten.
Trainieren Sie Ihre Produktionsmodelle regelmäßig neu: Um die in der Entwicklung befindlichen und die neu entstehenden Muster zu erfassen, müssen Sie Ihr Modell mit den neuesten Daten neu trainieren. Wenn Ihre Anwendung z. B. Modeartikel mit ML empfiehlt, sollten sich die Empfehlungen an die jeweils neuesten Trends und Produkte anpassen.
Experimentieren Sie bei der Erstellung des Modells fortlaufend mit neuen Implementierungen: Damit Sie die neuesten Ideen und Fortschritte in der Technologie nutzen können, müssen Sie neue Implementierungen wie Feature Engineering, Modellarchitektur und Hyperparameter ausprobieren. Wenn Sie beispielsweise bei der Gesichtserkennung Computer Vision verwenden, sind die Gesichtsmuster zwar festgelegt, bessere neue Techniken können jedoch die Erkennungsgenauigkeit verbessern.
Spezielle MLOps-Verfahren für CI/CD und CT sind hilfreich, um die Herausforderungen dieses manuellen Prozesses zu meistern. Eine ML-Trainingspipeline gibt Ihnen die Möglichkeit des CT (Continuous Training) und der Einrichtung eines CI/CD-Systems, mit dem Sie neue Implementierungen der ML-Pipeline schnell testen, erstellen und bereitstellen können. Diese Features werden in den nächsten Abschnitten ausführlicher behandelt.
MLOps-Stufe 1: ML-Pipelineautomatisierung
Ziel von Stufe 1 ist es, durch Automatisierung der ML-Pipeline ein kontinuierliches Training des Modells zu ermöglichen. Zugleich erreichen Sie so die kontinuierliche Bereitstellung des Modellvorhersagedienstes. Zur Automatisierung des Prozesses, bei dem neue Daten zum erneuten Trainieren von Modellen in der Produktion verwendet werden, müssen Sie in der Pipeline automatisierte Daten- und Modellvalidierungsschritte sowie Pipeline-Trigger und die Metadatenverwaltung einführen.
Die folgende Abbildung zeigt eine schematische Darstellung einer automatisierten ML-Pipeline für CT.

Abbildung 3. ML-Pipelineautomatisierung für CT
Merkmale
In der folgenden Liste sind die Merkmale der MLOps-Einrichtung der Stufe 1 aufgeführt, wie in Abbildung 3 dargestellt:
Schnelltest: Die Schritte des ML-Tests werden aufeinander abgestimmt. Der Übergang zwischen den Schritten erfolgt automatisiert, was zu einer schnellen Iteration von Tests und dazu führt, dass die gesamte Pipeline schneller auf dem Stand ist, auf dem sie in die Produktion überführt werden kann.
CT des Modells in der Produktion: Das Modell wird in der Produktion automatisch mit neuen Daten anhand von Live-Pipeline-Triggern trainiert, die im nächsten Abschnitt erläutert werden.
Experimentell-operative Symmetrie: Die Pipelineimplementierung, die in der Entwicklungs- oder Testumgebung verwendet wird, wird auch in der Vorproduktions- und Produktionsumgebung eingesetzt. Dies ist ein wichtiger Aspekt der MLOps-Praxis zur Vereinheitlichung von DevOps.
Modulierter Code für Komponenten und Pipelines: Zum Erstellen von ML-Pipelines müssen Komponenten wiederverwendbar, zusammensetzbar und potenziell für alle ML-Pipelines freigebbar sein. Daher muss der EDA-Code zwar weiterhin in Notebooks gespeichert werden, der Quellcode für Komponenten muss jedoch modularisiert werden. Darüber hinaus sollten die Komponenten idealerweise containerisiert werden, damit Folgendes möglich ist:
- Entkoppeln der Ausführungsumgebung von der Laufzeit des benutzerdefinierten Codes
- Reproduzierbar-Machen des Codes in Entwicklungs- und Produktionsumgebungen
- Isolieren der einzelnen Komponente in der Pipeline Komponenten können eine eigene Version der Laufzeitumgebung sowie verschiedene Sprachen und Bibliotheken haben.
Continuous Delivery von Modellen: Eine ML-Pipeline in der Produktion stellt kontinuierlich Vorhersagedienste für neue Modelle bereit, die mit neuen Daten trainiert werden. Der Modellbereitstellungsschritt, bei dem das trainierte und validierte Modell als Vorhersagedienst für Onlinevorhersagen bereitgestellt wird, wird automatisiert.
Pipelinebereitstellung: In Stufe 0 stellen Sie ein trainiertes Modell als Vorhersagedienst für die Produktion bereit. Für Stufe 1 stellen Sie eine gesamte Trainingspipeline bereit, die automatisch und wiederholt ausgeführt wird, um das trainierte Modell als Vorhersagedienst bereitzustellen.
Zusätzliche Komponenten
In diesem Abschnitt werden die Komponenten beschrieben, die Sie der Architektur hinzufügen müssen, um kontinuierliches Training für ML zu ermöglichen.
Daten- und Modellvalidierung
Wenn Sie Ihre ML-Pipeline in der Produktion bereitstellen, bewirkt mindestens einer der im Abschnitt ML-Pipeline-Trigger genannten Trigger automatisch, dass die Pipeline ausgeführt wird. Die Pipeline erwartet, dass neue Live-Daten eine neue Modellversion erzeugen, die auf die neuen Daten trainiert ist (siehe Abbildung 3). Daher sind in der Produktionspipeline automatisierte Schritte zur Datenvalidierung und Modellvalidierung erforderlich, um das folgende erwartete Verhalten zu gewährleisten:
Datenvalidierung: Dieser Schritt ist vor dem Modelltraining erforderlich, um zu entscheiden, ob Sie das Modell neu trainieren oder die Ausführung der Pipeline beenden sollten. Diese Entscheidung wird automatisch getroffen, wenn die Pipeline Folgendes identifiziert hat.
- Abweichungen des Datenschemas: Diese Abweichungen werden als Anomalien in den Eingabedaten betrachtet. Daher werden Eingabedaten, die nicht dem erwarteten Schema entsprechen, von den nachgelagerten Pipelineschritten empfangen, einschließlich der Schritte zur Datenverarbeitung und zum Modelltraining. In diesem Fall sollten Sie die Pipeline anhalten, damit das Data-Science-Team dies prüfen kann. Das Team veröffentlicht möglicherweise eine Fehlerkorrektur oder ein Update der Pipeline, um diese Änderungen im Schema zu verarbeiten. Bei Schemaabweichungen werden unerwartete Funktionen, nicht alle erwarteten Funktionen oder Funktionen mit unerwarteten Werten empfangen.
- Datenwertabweichungen: Diese Abweichungen sind erhebliche Änderungen an den statistischen Attributen von Daten, was eine Änderung der Datenmuster bedeutet. Sie müssen ein erneutes Training des Modells auslösen, um diese Änderungen zu erfassen.
Modellvalidierung: Dieser Schritt erfolgt, nachdem Sie das Modell anhand der neuen Daten erfolgreich trainiert haben. Sie werten das Modell aus und validieren es, bevor es in die Produktion übertragen wird. Dieser Schritt zur Überprüfung des Offline-Modells umfasst Folgendes:
- Erstellen von Bewertungsmesswerten mithilfe des trainierten Modells in einem Test-Dataset, um die Vorhersagequalität des Modells zu beurteilen.
- Vergleichen der von Ihrem neu trainierten Modell erstellten Bewertungsmesswerte mit dem aktuellen Modell, z. B. dem Produktionsmodell, Basismodell oder anderen Geschäftsanforderungsmodellen. Sie sorgen dafür, dass das neue Modell eine bessere Leistung erzielt als das aktuelle Modell, bevor Sie es in die Produktion übertragen.
- Gewährleisten, dass die Leistung des Modells in verschiedenen Segmenten der Daten konsistent ist. Beispielsweise kann Ihr neu trainiertes Modell zur Kundenabwanderung im Vergleich zum vorherigen Modell eine insgesamt bessere Vorhersagerichtigkeit liefern, aber die Treffsicherheitswerte pro Kundenregion können stark variieren.
- Gewährleisten, dass Sie Ihr Modell für die Bereitstellung testen, einschließlich Infrastrukturkompatibilität und Konsistenz mit der Prediction Service API.
Zusätzlich zur Offline-Modellvalidierung wird ein neu bereitgestelltes Modell einer Onlinemodellvalidierung in einer Canary-Bereitstellung oder einer A/B Testing-Einrichtung unterzogen, bevor es eine Vorhersage für den Online-Traffic liefert.
Feature Store
Eine optionale zusätzliche Komponente für die ML-Pipelineautomatisierung der Stufe 1 ist ein Feature Store. Ein Feature Store ist ein zentrales Repository, in dem Sie die Definition, Speicherung und den Zugriff auf Features für Training und Bereitstellung vereinheitlichen. Ein Feature Store muss eine API für die Batchbereitstellung mit hohem Durchsatz und für die Echtzeitbereitstellung mit niedriger Latenz für die Featurewerte bereitstellen sowie Trainings- und Bereitstellungsarbeitslasten unterstützen.
Mit dem Feature Store haben Data Scientists folgende Möglichkeiten:
- Erkennen und Verwenden verfügbarer Feature-Sets für ihre Entitäten, anstatt dieselben oder ähnliche Entitäten neu zu erstellen.
- Vermeiden ähnlicher Features mit unterschiedlichen Definitionen, indem Features und die zugehörigen Metadaten beibehalten werden.
- Bereitstellen aktueller Featurewerte aus dem Feature Store.
Vermeiden von Abweichungen zwischen Training und Bereitstellung, indem der Feature Store als Datenquelle für Experimente, kontinuierliches Training und Onlinebereitstellung verwendet wird. Mit diesem Ansatz wird gewährleistet, dass die für das Training verwendeten Features dieselben sind wie bei der Bereitstellung:
- Für Experimente können Data Scientists einen Offlineauszug aus dem Feature Store abrufen, um ihre Experimente auszuführen.
- Für das kontinuierliche Training kann die automatisierte ML-Trainingspipeline einen Batch der aktuellen Featurewerte des Datasets abrufen, die für die Trainingsaufgabe verwendet werden.
- Für die Onlinevorhersage kann der Vorhersagedienst einen Batch der Featurewerte abrufen, die mit der angeforderten Entität in Zusammenhang stehen, z. B. demografische Merkmale des Kunden, Produktfunktionen und Zusammenfassungsfunktionen der aktuellen Sitzung.
- Für die Onlinevorhersage und den Feature-Abruf ermittelt der Vorhersagedienst die relevanten Features für eine Entität. Wenn es sich bei der Einheit beispielsweise um einen Kunden handelt, können relevante Merkmale Alter, Kaufhistorie und Surfverhalten sein. Der Dienst fasst diese Feature-Werte zusammen und ruft alle erforderlichen Features für die Entität auf einmal ab, anstatt einzeln. Diese Abrufmethode ist besonders effizient, wenn Sie mehrere Rechtspersönlichkeiten oder Entitäten verwalten müssen.
Metadatenverwaltung
Informationen über die einzelnen Ausführungen der ML-Pipeline werden aufgezeichnet, um die Herkunft von Daten und Artefakten nachvollziehbar zu machen sowie ihre Reproduzierbarkeit und Vergleiche zwischen ihnen zu unterstützen. Außerdem können Fehler und Anomalien behoben werden. Jedes Mal, wenn Sie die Pipeline ausführen, werden im ML-Metadatenspeicher die folgenden Metadaten aufgezeichnet:
- Die Pipeline- und Komponentenversionen, die ausgeführt wurden.
- Das Start- und Enddatum, die Uhrzeit und die Dauer, bis die Pipeline die einzelnen Schritte abgeschlossen hat.
- Der Ausführer der Pipeline.
- Die Parameterargumente, die an die Pipeline übergeben wurden.
- Die Verweise auf die Artefakte, die von den einzelnen Schritten der Pipeline erzeugt werden, z. B. die Position der vorbereiteten Daten, Validierungsanomalien, berechnete Statistikwerte und extrahiertes Vokabular aus den kategorischen Features. Wenn Sie diese Zwischenausgaben verfolgen, können Sie die Pipeline ab dem letzten Schritt fortsetzen, wenn die Pipeline aufgrund eines fehlgeschlagenen Schritts gestoppt wurde, ohne die bereits abgeschlossenen Schritte noch einmal ausführen zu müssen.
- Ein Zeiger auf das zuvor trainierte Modell, falls Sie ein Rollback zu einer vorherigen Modellversion durchführen oder Bewertungsmesswerte für eine vorherige Modellversion erstellen müssen, wenn die Pipeline während des Modellvalidierungsschritts neue Testdaten erhält.
- Die Modellbewertungsmesswerte, die während des Modellbewertungsschritts für die Trainings- und die Test-Sets erstellt wurden. Mit diesen Messwerten können Sie die Leistung eines neu trainierten Modells mit der aufgezeichneten Leistung des vorherigen Modells während der Modellvalidierung vergleichen.
ML-Pipeline-Trigger
Sie können die ML-Produktionspipelines automatisieren, um die Modelle je nach Anwendungsfall mit neuen Daten neu zu trainieren:
- Bei Bedarf: Manuelle Ad-hoc-Ausführung der Pipeline.
- Nach Zeitplan: Neue, mit Labels versehene Daten sind für das ML-System täglich, wöchentlich oder monatlich verfügbar. Die Häufigkeit des erneuten Trainings hängt auch davon ab, wie häufig sich die Datenmuster ändern und wie teuer es ist, Ihre Modelle neu zu trainieren.
- Bei Verfügbarkeit neuer Trainingsdaten: Neue Daten sind für das ML-System nicht systematisch verfügbar. Stattdessen stehen sie ad hoc zur Verfügung, wenn neue Daten erfasst und in den Quelldatenbanken zur Verfügung gestellt werden.
- Bei Beeinträchtigung der Modellleistung: Das Modell wird neu trainiert, wenn die Leistung merklich nachlässt.
- Bei wichtigen Änderungen in den Datenverteilungen (Konzeptabweichung). Es ist schwierig, die vollständige Leistung des Onlinemodells zu beurteilen. Sie bemerken jedoch erhebliche Änderungen bei den Datenverteilungen der Features, die für die Vorhersage verwendet werden. Diese Änderungen deuten darauf hin, dass Ihr Modell veraltet ist und mit aktuellen Daten neu trainiert werden muss.
Herausforderungen
Wenn man davon ausgeht, dass neue Implementierungen der Pipeline nicht häufig bereitgestellt werden und Sie nur wenige Pipelines verwalten, testen Sie die Pipeline und ihre Komponenten normalerweise manuell. Darüber hinaus stellen Sie auch neue Pipelineimplementierungen manuell bereit. Außerdem senden Sie den geprüften Quellcode für die Pipeline an das IT-Team, das ihn in der Zielumgebung bereitstellt. Diese Einrichtung ist dann geeignet, wenn Sie neue Modelle anhand neuer Daten und nicht deshalb bereitstellen, weil neue ML-Ideen umgesetzt werden sollen.
In Ihrem Fall müssen Sie jedoch tatsächlich neue ML-Ideen ausprobieren und schnell neue Implementierungen der ML-Komponenten bereitstellen. Wenn Sie viele ML-Pipelines in der Produktion verwalten, benötigen Sie eine CI/CD-Einrichtung, um das Erstellen, Testen und Bereitstellen von ML-Pipelines zu automatisieren.
MLOps-Stufe 2: CI/CD-Pipelineautomatisierung
Für eine schnelle und zuverlässige Aktualisierung der Pipelines in der Produktion benötigen Sie ein robustes automatisiertes CI/CD-System. Mit diesem automatisierten CI/CD-System können Ihre Data Scientists schnell neue Ideen zu Feature Engineering, Modellarchitektur und Hyperparametern ausprobieren. Sie können diese Ideen umsetzen und die neuen Pipelinekomponenten automatisch erstellen, testen und in der Zielumgebung bereitstellen.
Das folgende Diagramm zeigt die Implementierung der ML-Pipeline unter Verwendung von CI/CD. Dabei weist die Pipeline die Merkmale der automatisierten ML-Pipeline-Einrichtung sowie zusätzlich der automatisierten CI/CD-Routinen auf.

Abbildung 4. CI/CD und automatisierte ML-Pipeline
Diese MLOps-Einrichtung umfasst die folgenden Komponenten:
- Versionsverwaltung
- Dienste zum Testen und Erstellen
- Bereitstellungsdienste
- Modell-Registry
- Feature Store
- ML-Metadatenspeicher
- ML-Pipeline-Orchestrator
Merkmale
Das folgende Diagramm zeigt die Phasen der ML CI/CD-Automatisierungspipeline:

Abbildung 5. Phasen der automatisierten CI/CD-ML-Pipeline
Die Pipeline besteht aus den folgenden Phasen:
Entwicklung und Experiment: Sie testen iterativ neue ML-Algorithmen und neue Modelle, bei denen die Testschritte aufeinander abgestimmt werden. Die Ausgabe dieser Phase ist der Quellcode der ML-Pipelineschritte, die dann in ein Quell-Repository übertragen werden.
Continuous Integration der Pipeline: Sie erstellen Quellcode und führen verschiedene Tests aus. Die Ausgaben dieser Phase sind Pipelinekomponenten (Pakete, ausführbare Dateien und Artefakte), die in einer späteren Phase bereitgestellt werden.
Continuous Delivery der Pipeline: Sie stellen die von der CI-Phase erzeugten Artefakte in der Zielumgebung bereit. Die Ausgabe dieser Phase ist eine bereitgestellte Pipeline mit der neuen Implementierung des Modells.
Automatisierte Trigger: Die Pipeline wird in der Produktion anhand eines Zeitplans oder als Reaktion auf einen Trigger automatisch ausgeführt. Die Ausgabe dieser Phase ist ein trainiertes Modell, das in die Modell-Registry übertragen wird.
Continuous Delivery des Modells: Sie stellen das trainierte Modell als Vorhersagedienst für die Vorhersagen bereit. Die Ausgabe dieser Phase ist ein bereitgestellter Modellvorhersagedienst.
Monitoring: Sie erfassen Statistiken zur Modellleistung anhand der Live-Daten. Die Ausgabe dieser Phase ist ein Trigger zum Ausführen der Pipeline oder eines neuen Testzyklus.
Der Datenanalyseschritt ist für Data Scientists immer noch ein manueller Prozess, bevor die Pipeline eine neue Iteration des Tests startet. Der Schritt zur Modellanalyse ist ebenfalls ein manueller Prozess.
Continuous Integration
Bei dieser Einrichtung werden die Pipeline und ihre Komponenten erstellt, getestet und gepackt, wenn neuer Code per Commit oder Push in das Quellcode-Repository übertragen wird. Neben der Erstellung von Paketen, Container-Images und ausführbaren Dateien kann der CI-Prozess die folgenden Tests umfassen:
Einheitentest der Feature-Engineering-Logik.
Einheitentest der verschiedenen in Ihrem Modell implementierten Methoden. Sie haben z. B. ein Feature, das eine kategorische Datenspalte akzeptiert, und Sie codieren das Feature als One-Hot-Feature.
Testen, ob das Modelltraining konvergent ist (d. h., der Verlust des Modells sinkt durch Iterationen und es erfolgt eine Überanpassung einiger Beispieldatensätze).
Testen, ob das Modelltraining durch Division durch null oder Änderung kleiner oder großer Werte keine NaN-Werte erzeugt.
Testen, ob die einzelnen Komponenten in der Pipeline die erwarteten Artefakte erzeugen.
Testen der Integration der Pipelinekomponenten
Continuous Delivery
Auf dieser Stufe liefert Ihr System kontinuierlich neue Pipelineimplementierungen an die Zielumgebung, die wiederum Vorhersagedienste des neu trainierten Modells bereitstellen. Für eine schnelle und zuverlässige Continuous Delivery von Pipelines und Modellen sollten Sie Folgendes in Betracht ziehen:
Prüfen der Kompatibilität des Modells mit der Zielinfrastruktur, bevor Sie das Modell bereitstellen. Sie müssen z. B. prüfen, ob die für das Modell erforderlichen Pakete in der Bereitstellungsumgebung installiert sind und welche Speicher-, Rechen- und Beschleunigerressourcen verfügbar sind.
Testen des Vorhersagedienstes, indem Sie die Dienst-API mit den erwarteten Eingaben aufrufen und dafür sorgen, dass Sie die erwartete Antwort erhalten. Dieser Test erfasst normalerweise Probleme, die auftreten können, wenn Sie die Modellversion aktualisieren und eine andere Eingabe erwartet wird.
Testen der Leistung des Vorhersagedienstes. Hierzu gehören Lasttests des Dienstes, um Messwerte, z. B. Abfragen pro Sekunde und Modelllatenz, zu erfassen.
Validieren der Daten entweder für das erneute Training oder für Batchvorhersagen.
Prüfen, ob Modelle die Vorhersageleistungsziele erfüllen, bevor sie bereitgestellt werden.
Automatisierte Bereitstellung in einer Testumgebung, z. B. eine Bereitstellung, die durch Senden von Code an den Entwicklungszweig ausgelöst wird.
Teilweise automatisierte Bereitstellung in einer Vorproduktionsumgebung, z. B. eine Bereitstellung, die ausgelöst wird, indem der Code mit dem Haupt-Branch zusammengeführt wird, nachdem die Prüfer die Änderungen genehmigt haben.
Manuelle Bereitstellung in einer Produktionsumgebung nach mehreren erfolgreichen Ausführungen der Pipeline in der Vorproduktionsumgebung.
Zusammengefasst beinhaltet die Implementierung von ML in einer Produktionsumgebung nicht nur die Bereitstellung Ihres Modells als API für Vorhersagen. Die Implementierung umfasst vielmehr die Bereitstellung einer ML-Pipeline, mit der das erneute Trainieren und Bereitstellen neuer Modelle automatisiert werden kann. Durch die Einrichtung eines CI/CD-Systems können Sie neue Pipelineimplementierungen automatisch testen und bereitstellen. Mithilfe dieses Systems können Sie souverän auf rasche Veränderungen Ihrer Daten und der Unternehmensumgebung reagieren. Sie müssen nicht alle Ihre Prozesse sofort von einer Stufe in eine andere verschieben. Sie können diese Vorgehensweisen schrittweise implementieren, um die Automatisierung zur Entwicklung und Produktion Ihres ML-Systems zu verbessern.
Nächste Schritte
- Weitere Informationen zur Architektur für MLOps mit TensorFlow Extended, Vertex AI Pipelines und Cloud Build
- Informationen zum Leitfaden für ML-Vorgänge (MLOps)
- MLOps Best Practices on Google Cloud (Cloud Next '19) auf YouTube ansehen
- Eine Übersicht über Architekturprinzipien und Empfehlungen, die speziell für KI- und ML-Arbeitslasten in Google Cloudgelten, finden Sie im Well-Architected Framework in der KI- und ML-Perspektive.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autoren:
- Jarek Kazmierczak | Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
- Valentin Huerta | KI-Entwickler
Weiterer Beitragender: Sunil Kumar Jang Bahadur | Customer Engineer