This document is the second part of a series that discusses disaster recovery (DR) in Google Cloud. This part discusses services and products that you can use as building blocks for your DR plan—both Google Cloud products and products that work across platforms.
The series consists of these parts:
- Disaster recovery planning guide
- Disaster recovery building blocks (this article)
- Disaster recovery scenarios for data
- Disaster recovery scenarios for applications
- Architecting disaster recovery for locality-restricted workloads
- Disaster recovery use cases: locality-restricted data analytic applications
- Architecting disaster recovery for cloud infrastructure outages
Google Cloud has a wide range of products that you can use as part of your disaster recovery architecture. This section discusses DR-related features of the products that are most commonly used as Google Cloud DR building blocks.
Many of these services have high availability (HA) features. HA doesn't entirely overlap with DR, but many of the goals of HA also apply to designing a DR plan. For example, by taking advantage of HA features, you can design architectures that optimize uptime and that can mitigate the effects of small-scale failures, such as a single VM failing. For more about the relationship of DR and HA, see the Disaster recovery planning guide.
The following sections describe these Google Cloud DR building blocks and how they help you implement your DR goals.
Compute and storage
The following table provides a summary of the features in Google Cloud compute and storage services that serve as building blocks for DR:
| Product | Feature |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
For more information about how the features and the design of these and other Google Cloud products might influence your DR strategy, see Architecting disaster recovery for cloud infrastructure outages: product reference.
Compute Engine
Compute Engine provides virtual machine (VM) instances; it's the workhorse of Google Cloud. In addition to configuring, launching, and monitoring Compute Engine instances, you typically use a variety of related features in order to implement a DR plan.
For DR scenarios, you can prevent accidental deletion of VMs by setting the delete protection flag. This is particularly useful where you are hosting stateful services such as databases.
For information about how to meet low RTO and RPO values, see Designing resilient systems.
Instance templates
You can use Compute Engine instance templates to save the configuration details of the VM and then create Compute Engine instances from existing instance templates. You can use the template to launch as many instances as you need, configured exactly the way you want when you need to stand up your DR target environment. Instance templates are globally replicated, so you can recreate the instance anywhere in Google Cloud with the same configuration.
For more information, see the following resources:
For details about using Compute Engine images, see the balancing image configuration and deployment speed section later in this document.
Managed instance groups
Managed instance groups work with Cloud Load Balancing (discussed later in this document) to distribute traffic to groups of identically configured instances that are copied across zones. Managed instance groups allow for features like autoscaling and autohealing, where the managed instance group can delete and recreate instances automatically.
Reservations
Compute Engine allows for the reservation of VM instances in a specific zone, using custom or predefined machine types, with or without additional GPUs or local SSDs. In order to assure capacity for your mission critical workloads for DR, you should create reservations in your DR target zones. Without reservations, there is a possibility that you might not get the on-demand capacity you need to meet your recovery time objective. Reservations can be useful in cold, warm, or hot DR scenarios. They let you keep recovery resources available for failover to meet lower RTO needs, without having to fully configure and deploy them in advance.
Persistent disks and snapshots
Persistent disks are durable network storage devices that your instances can access. They are independent of your instances, so you can detach and move persistent disks to keep your data even after you delete your instances.
You can take incremental backups or snapshots of Compute Engine VMs that you can copy across regions and use to recreate persistent disks in the event of a disaster. Additionally, you can create snapshots of persistent disks to protect against data loss due to user error. Snapshots are incremental, and take only minutes to create even if your snapshot disks are attached to running instances.
Persistent disks have built-in redundancy to protect your data against equipment failure and to ensure data availability through data center maintenance events. Persistent disks are either zonal or regional. Regional persistent disks replicate writes across two zones in a region. In the event of a zonal outage, a backup VM instance can force-attach a regional persistent disk in the secondary zone. To learn more, see High availability options using regional persistent disks.
Transparent maintenance
Google regularly maintains its infrastructure by patching systems with the latest software, performing routine tests and preventative maintenance, and working to ensure that Google infrastructure is as fast and efficient as possible.
By default, all Compute Engine instances are configured so that these maintenance events are transparent to your applications and workloads. For more information, see Transparent maintenance.
When a maintenance event occurs, Compute Engine uses Live Migration to automatically migrate your running instances to another host in the same zone. Live Migration lets Google perform maintenance that's integral to keeping infrastructure protected and reliable without interrupting any of your VMs.
Virtual disk import tool
The virtual disk import tool lets you import file formats including VMDK, VHD, and RAW to create new Compute Engine virtual machines. Using this tool, you can create Compute Engine virtual machines that have the same configuration as your on-premises virtual machines. This is a good approach for when you are not able to configure Compute Engine images from the source binaries of software that's already installed on your images.
Automated backups
You can automate backups of your Compute Engine instances using tags. For example, you can create a backup plan template using Backup and DR Service, and automatically apply the template to your Compute Engine instances.
For more information, see Automate protection of new Compute Engine instances.
Cloud Storage
Cloud Storage is an object store that's ideal for storing backup files. It provides different storage classes that are suited for specific use cases, as outlined in the following diagram.

In DR scenarios, Nearline, Coldline, and Archive storage are of particular interest. These storage classes reduce your storage cost compared to Standard storage. However, there are additional costs associated with retrieving data or metadata stored in these classes, as well as minimum storage durations that you are charged for. Nearline is designed for backup scenarios where access is at most once a month, which is ideal for allowing you to undertake regular DR stress tests while keeping costs low.
Nearline, Coldline, and Archive are optimized for infrequent access, and the pricing model is designed with this in mind. Therefore, you are charged for minimum storage durations, and there are additional costs for retrieving data or metadata in these classes earlier than the minimum storage duration for the class.
To protect your data in a Cloud Storage bucket against accidental or malicious deletion, you can use the Soft Delete feature to preserve deleted and overwritten objects for a specified period, and the Object holds feature to prevent deletion or updates to objects.
Storage Transfer Service lets you import data from Amazon S3, Azure Blob Storage, or on-premises data sources into Cloud Storage. In DR scenarios, you can use Storage Transfer Service to do the following:
- Back up data from other storage providers to a Cloud Storage bucket.
- Move data from a bucket in a dual-region or multi-region to a bucket in a region to lower your costs for storing backups.
Filestore
Filestore instances are fully managed NFS file servers for use with applications running on Compute Engine instances or GKE clusters.
Filestore Basic and Zonal tiers are zonal resources and don't support replication across zones, while Filestore Enterprise tier instances are regional resources. To help you increase the resiliency of your Filestore environment, we recommend that you use Enterprise tier instances.
Google Kubernetes Engine
GKE is a managed, production-ready environment for deploying containerized applications. GKE lets you orchestrate HA systems, and includes the following features:
- Node auto repair. If a node fails consecutive health checks over an extended time period (approximately 10 minutes), GKE initiates a repair process for that node.
- Liveness and readiness probes. You can specify a liveness probe, which periodically tells GKE that the pod is running. If the pod fails the probe, it can be restarted.
- Multi-zone and regional clusters. You can distribute Kubernetes resources across multiple zones within a region.
- Multi-cluster Gateway lets you configure shared load balancing resources across multiple GKE clusters in different regions.
- Backup for GKE lets you back up and restore workloads in GKE clusters.
Networking and data transfer
The following table provides a summary of the features in Google Cloud networking and data transfer services that serve as building blocks for DR:
| Product | Feature |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing provides HA for Google Cloud computing products by distributing user traffic across multiple instances of your applications. You can configure Cloud Load Balancing with health checks that determine whether instances are available to do work so that traffic is not routed to failing instances.
Cloud Load Balancing provides a single anycast IP address to front your applications. Your applications can have instances running in different regions (for example, in Europe and in the US), and your end users are directed to the closest set of instances. In addition to providing load balancing for services that are exposed to the internet, you can configure internal load balancing for your services behind a private load-balancing IP address. This IP address is accessible only to VM instances that are internal to your Virtual Private Cloud (VPC).
For more information see Cloud Load Balancing overview.
Cloud Service Mesh
Cloud Service Mesh is a Google-managed service mesh that's available on Google Cloud. Cloud Service Mesh provides in-depth telemetry to help you gather detailed insights about your applications. It supports services that run on a range of computing infrastructures.
Cloud Service Mesh also supports advanced traffic management and routing features, such as circuit breaking and fault injection. With circuit breaking, you can enforce limits on requests to a particular service. When circuit breaking limits are reached, requests are prevented from reaching the service, which prevents the service from degrading further. With fault injection, Cloud Service Mesh can introduce delays or abort a fraction of requests to a service. Fault injection enables you to test your service's ability to survive request delays or aborted requests.
For more information, see Cloud Service Mesh overview.
Cloud DNS
Cloud DNS provides a programmatic way to manage your DNS entries as part of an automated recovery process. Cloud DNS uses Google's global network of Anycast name servers to serve your DNS zones from redundant locations around the world, providing high availability and lower latency for your users.
If you chose to manage DNS entries on-premises, you can enable VMs in Google Cloud to resolve these addresses through Cloud DNS forwarding.
Cloud DNS supports policies to configure how it responds to DNS requests. For example, you can configure DNS routing policies to steer traffic based on specific criteria, such as enabling failover to a backup configuration to provide high availability, or to route DNS requests based on their geographic location.
Cloud Interconnect
Cloud Interconnect provides ways to move information from other sources to Google Cloud. We discuss this product later under Transferring data to and from Google Cloud.
Management and monitoring
The following table provides a summary of the features in Google Cloud management and monitoring services that serve as building blocks for DR:
| Product | Feature |
|---|---|
| Cloud Status Dashboard |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service for Prometheus |
|
Cloud Status Dashboard
The Cloud Status Dashboard shows you the current availability of Google Cloud services. You can view the status on the page, and you can subscribe to an RSS feed that is updated whenever there is news about a service.
Cloud Monitoring
Cloud Monitoring collects metrics, events, and metadata from Google Cloud, AWS, hosted uptime probes, application instrumentation, and a variety of other application components. You can configure alerting to send notifications to third-party tools such as Slack or Pagerduty in order to provide timely updates to administrators.
Cloud Monitoring lets you create uptime checks for publicly available endpoints and for endpoints within your VPCs. For example, you can monitor URLs, Compute Engine instances, Cloud Run revisions, and third-party resources, such as Amazon Elastic Compute Cloud (EC2) instances.
Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus is a Google-managed, multi-cloud, cross-project solution for Prometheus metrics. It lets you globally monitor and alert on your workloads, using Prometheus, without having to manually manage and operate Prometheus at scale.
For more information, see Google Cloud Managed Service for Prometheus.
Cross-platform DR building blocks
When you run workloads across more than one platform, a way to reduce the operational overhead is to select tooling that works with all of the platforms you're using. This section discusses some tools and services that are platform-independent and therefore support cross-platform DR scenarios.
Infrastructure as code
By defining your infrastructure using code, instead of graphical interfaces or scripts, you can adopt declarative templating tools and automate the provisioning and configuration of infrastructure across platforms. For example, you can use Terraform and Infrastructure Manager to actuate your declarative infrastructure configuration.
Configuration management tools
For large or complex DR infrastructure, we recommend platform-agnostic software management tools such as Chef and Ansible. These tools ensure that reproducible configurations can be applied no matter where your compute workload is.
Orchestrator tools
Containers can also be considered a DR building block. Containers are a way to package services and introduce consistency across platforms.
If you work with containers, you typically use an orchestrator. Kubernetes works not just to manage containers within Google Cloud (using GKE), but provides a way to orchestrate container-based workloads across multiple platforms. Google Cloud, AWS, and Microsoft Azure all provide managed versions of Kubernetes.
To distribute traffic to Kubernetes clusters running in different cloud platforms, you can use a DNS service that supports weighted records and incorporates health checking.
You also need to ensure you can pull the image to the target environment. This means you need to be able to access your image registry in the event of a disaster. A good option that's also platform-independent is Artifact Registry.
Data transfer
Data transfer is a critical component of cross-platform DR scenarios. Make sure that you design, implement, and test your cross-platform DR scenarios using realistic mockups of what the DR data transfer scenario calls for. We discuss data transfer scenarios in the next section.
Backup and DR Service
Backup and DR Service is a backup and DR solution for cloud workloads. It helps you recover data and resume critical business operation, and supports several Google Cloud products and third-party databases and data storage systems.
For more information, see Backup and DR Service overview.
Patterns for DR
This section discusses some of the most common patterns for DR architectures based on the building blocks discussed earlier.
Transferring data to and from Google Cloud
An important aspect of your DR plan is how quickly data can be transferred to and from Google Cloud. This is critical if your DR plan is based on moving data from on-premises to Google Cloud or from another cloud provider to Google Cloud. This section discusses networking and Google Cloud services that can ensure good throughput.
When you are using Google Cloud as the recovery site for workloads that are on-premises or on another cloud environment, consider the following key items:
- How do you connect to Google Cloud?
- How much bandwidth is there between you and the interconnect provider?
- What is the bandwidth provided by the provider directly to Google Cloud?
- What other data will be transferred using that link?
For more information about transferring data to Google Cloud, see Migrate to Google Cloud: Transfer your large datasets.
Balancing image configuration and deployment speed
When you configure a machine image for deploying new instances, consider the effect that your configuration will have on the speed of deployment. There is a tradeoff between the amount of image preconfiguration, the costs of maintaining the image, and the speed of deployment. For example, if a machine image is minimally configured, the instances that use it will require more time to launch, because they need to download and install dependencies. On the other hand, if your machine image is highly configured, the instances that use it launch more quickly, but you must update the image more frequently. The time taken to launch a fully operational instance will have a direct correlation to your RTO.
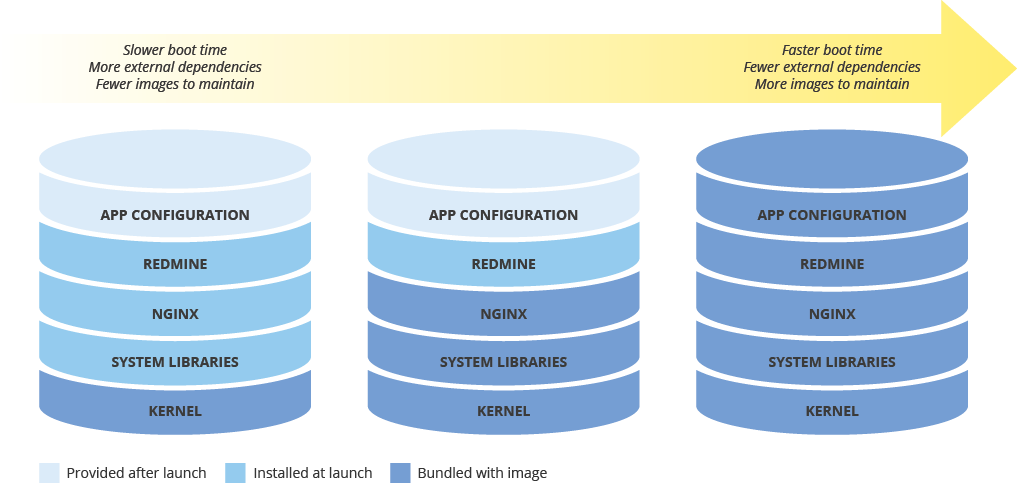
Maintaining machine image consistency across hybrid environments
If you implement a hybrid solution (on-premises-to-cloud or cloud-to-cloud), you need to find a way to maintain image consistency across production environments.
If a fully configured image is required, consider something like Packer, which can create identical machine images for multiple platforms. You can use the same scripts with platform-specific configuration files. In the case of Packer, you can put the configuration file in version control to keep track of what version is deployed in production.
As another option, you can use configuration management tools such as Chef, Puppet, Ansible, or Saltstack to configure instances with finer granularity, creating base images, minimally-configured images, or fully-configured images as needed.
You can also manually convert and import existing images such as Amazon AMIs, Virtualbox images, and RAW disk images to Compute Engine.
Implementing tiered storage
The tiered storage pattern is typically used for backups where the most recent backup is on faster storage, and you slowly migrate your older backups to lower cost (but slow) storage. By applying this pattern, you migrate backups between buckets of different storage classes, typically from Standard to lower cost storage classes, such as Nearline and Coldline.
To implement this pattern, you can use Object Lifecycle Management. For example, you can automatically change the storage class of objects older than a certain amount of time to Coldline.
What's next
- Read about Google Cloud geography and regions.
Read other articles in this DR series:
- Disaster recovery planning guide
- Disaster recovery scenarios for data
- Disaster recovery scenarios for applications
- Architecting disaster recovery for locality-restricted workloads
- Disaster recovery use cases: locality-restricted data analytic applications
- Architecting disaster recovery for cloud infrastructure outages
For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
Contributors
Authors:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect