Wir empfehlen, Ihr Data Mesh so zu gestalten, dass es eine Vielzahl von Anwendungsfällen für die Datennutzung unterstützt. In diesem Dokument werden die häufigsten Anwendungsfälle für die Datennutzung in einer Organisation beschrieben. Außerdem wird erläutert, welche Informationen Datennutzer bei der Bestimmung des richtigen Datenprodukts für ihren Anwendungsfall berücksichtigen müssen und wie sie Datenprodukte finden und verwenden. Das Verständnis dieser Faktoren kann Organisationen helfen sicherzustellen, dass sie die richtigen Anleitungen und Tools haben, um Datennutzer zu unterstützen.
Dieses Dokument ist Teil einer Reihe, in der beschrieben wird, wie ein Data Mesh in Google Cloudimplementiert wird. Dabei wird davon ausgegangen, dass Sie die Artikel Architektur und Funktionen in einem Data Mesh und Modernes, verteiltes Data Mesh mit Google Clouderstellen gelesen haben und mit den darin beschriebenen Konzepten vertraut sind.
Die Reihe besteht aus folgenden Teilen:
- Architektur und Funktionen in einem Data Mesh
- Self-Service-Datenplattform für ein Data Mesh entwerfen
- Datenprodukte in einem Data Mesh erstellen
- Datenprodukte in einem Data Mesh ermitteln und nutzen (dieses Dokument)
Das Design einer Datennutzungsschicht, insbesondere die Art und Weise, wie die domainbasierten Datennutzer Datenprodukte verwenden, hängt von den Anforderungen der Datennutzer ab. Es wird davon ausgegangen, dass die Nutzer einen bestimmten Anwendungsfall haben. Es wird davon ausgegangen, dass sie die erforderlichen Daten identifiziert haben und sie im zentralen Datenproduktkatalog suchen können. Wenn sich diese Daten nicht im Katalog oder nicht im bevorzugten Zustand befinden (z. B. wenn die Schnittstelle nicht geeignet ist oder die SLAs unzureichend sind), muss der Nutzer den Datenersteller kontaktieren.
Alternativ kann der Nutzer sich mit dem Kompetenzzentrum (Center of excellence, COE) für das Data Mesh in Verbindung setzen, um zu ermitteln, welche Domain am besten zum Erstellen dieses Datenprodukts geeignet ist. Die Datennutzer können auch fragen, wie sie ihre Anfrage stellen sollen. Wenn Ihre Organisation groß ist, sollte es einen Prozess geben, um Anfragen für Datenprodukte auf Self-Service-Ebene anzuzeigen.
Datennutzer verwenden Datenprodukte über die von ihnen ausgeführten Anwendungen. Die Art der erforderlichen Informationen bestimmt die Wahl des Designs der Datennutzungsanwendung. Beim Entwickeln des Anwendungsdesigns gibt der Datennutzer auch die bevorzugte Verwendung von Datenprodukten in der Anwendung an. Sie bauen das nötige Vertrauen in die Zuverlässigkeit dieser Daten auf. Die Datennutzer können dann einen Überblick über die Datenproduktschnittstellen und SLAs gewinnen, die die Anwendung erfordert.
Anwendungsfälle für die Datennutzung
Damit Datennutzer Datenanwendungen erstellen können, kann es sich bei Quellen um ein oder mehrere Datenprodukte und möglicherweise um die Daten aus der eigenen Domain des Datennutzers handeln. Wie unter Datenprodukte in einem Data Mesh erstellen beschrieben, können analytische Datenprodukte aus Datenprodukten erstellt werden, die auf verschiedenen physischen Daten-Repositories basieren.
Obwohl die Datennutzung innerhalb derselben Domain erfolgen kann, werden am häufigsten Nutzungsmuster verwendet, die unabhängig von der Domain als Quelle für die Anwendung nach dem richtigen Datenprodukt suchen. Wenn das richtige Datenprodukt in einer anderen Domain vorhanden ist, müssen Sie gemäß dem Nutzungsmuster den nachfolgenden Mechanismus für den Zugriff auf die Daten und für deren Nutzung über Domains hinweg einrichten. Die Nutzung von Datenprodukten, die in anderen Domains als der nutzenden Domain erstellt wurden, wird unter Schritte zur Datenaufnahme erläutert.
Architektur
Das folgende Diagramm zeigt ein Beispielszenario, in dem Nutzer Datenprodukte über eine Reihe von Schnittstellen verwenden, darunter autorisierte Datasets und APIs.
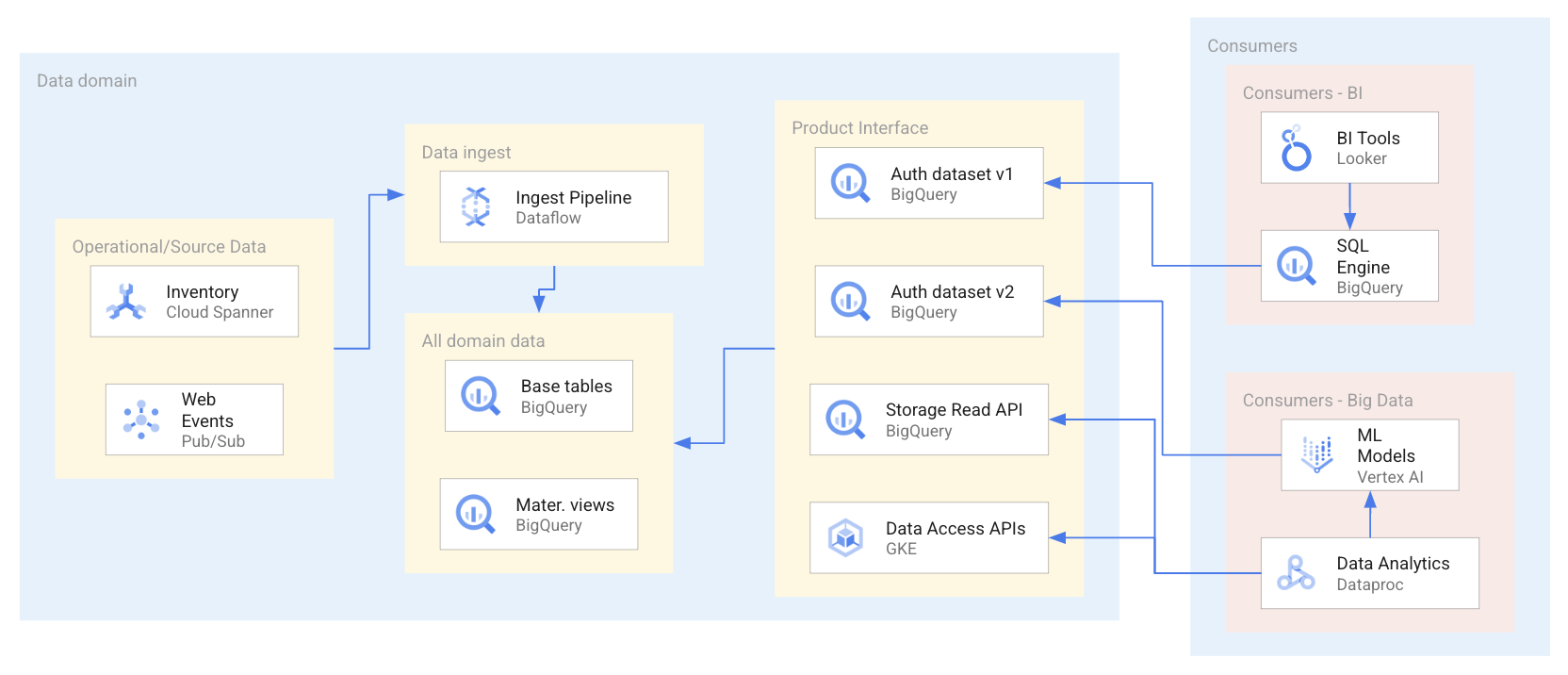
Wie im vorherigen Diagramm dargestellt, hat der Datenersteller vier Datenproduktschnittstellen verfügbar gemacht: zwei autorisierte BigQuery-Datasets, ein BigQuery-Dataset, das von der BigQuery Storage Read API bereitgestellt wird, und Datenzugriffs-APIs, die in Google Kubernetes Engine gehostet werden: Bei der Verwendung der Datenprodukte verwenden Datennutzer eine Reihe von Anwendungen, die die Datenressourcen innerhalb der Datenprodukte abfragen oder direkt darauf zugreifen. In diesem Szenario greifen Datennutzer je nach ihren spezifischen Zugriffsanforderungen auf zwei verschiedene Arten auf Datenressourcen zu. Bei der ersten Art wird von Looker BigQuery SQL verwendet, um ein autorisiertes Dataset abzufragen. Bei der zweiten Art greift Dataproc über die BigQuery API direkt auf ein Dataset zu und verarbeitet dann diese aufgenommenen Daten, um ein ML-Modell zu trainieren.
Die Verwendung einer Datennutzungsanwendung führt möglicherweise nicht immer zu einem BI-Bericht (Business Intelligence) oder einem BI-Dashboard. Die Nutzung von Daten aus einer Domain kann auch zu ML-Modellen führen, die analytische Produkte weiter anreichern, in Datenanalysen verwendet werden oder Teil von operativen Prozessen wie der Betrugserkennung sind.
Typische Anwendungsfälle für die Datenproduktnutzung sind beispielsweise:
- BI-Berichterstellung und Datenanalyse: In diesem Fall werden Datenanwendungen so erstellt, dass Daten aus mehreren Datenprodukten genutzt werden. Beispielsweise benötigen Datennutzer aus dem CRM-Team (Customer Relationship Management) Zugriff auf Daten aus mehreren Domains wie Vertrieb, Kunden und Finanzen. Die von diesen Datennutzern entwickelte CRM-Anwendung muss möglicherweise sowohl eine autorisierte BigQuery-Ansicht in einer Domain abfragen als auch Daten aus einer Cloud Storage Read API in einer anderen Domain extrahieren. Für Datennutzer sind die Optimierungsfaktoren, die sich auf ihre bevorzugte Nutzungsschnittstelle auswirken, die Computing-Kosten sowie jede zusätzliche Datenverarbeitung, die nach der Abfrage des Datenprodukts erforderlich ist. In BI- und Datenanalyse-Anwendungsfällen werden autorisierte BigQuery-Ansichten wahrscheinlich am häufigsten verwendet.
- Data-Science-Anwendungsfälle und Modelltraining: In diesem Fall verwendet das Datennutzungsteam die Datenprodukte aus anderen Domains, um sein eigenes analytisches Datenprodukt (z. B. ein ML-Modell) anzureichern. Durch die Verwendung vonGoogle Cloud Serverless for Apache Spark Google Cloud bietet Google Cloud Funktionen zur Datenvorverarbeitung und für das Feature Engineering, um die Datenanreicherung zu ermöglichen, bevor ML-Aufgaben ausgeführt werden. Die wichtigsten Aspekte sind die Verfügbarkeit ausreichender Mengen an Trainingsdaten zu angemessenen Kosten sowie das Vertrauen in die Eignung der Trainingsdaten. Um die Kosten niedrig zu halten, sind die bevorzugten Nutzungsschnittstellen wahrscheinlich APIs für direktes Lesen. Es ist möglich, dass ein Datennutzungsteam ein ML-Modell als Datenprodukt erstellt. Dieses Team wird dann wiederum zu einem neuen Team zur Datenerstellung.
- Operatorprozesse: Die Nutzung ist Teil des operativen Prozesses innerhalb der Datennutzungsdomain. Beispielsweise kann ein Datennutzer in einem Team, das sich mit Betrug befasst, Transaktionsdaten verwenden, die aus operativen Datenquellen in der Händlerdomain stammen. Durch die Verwendung einer Datenintegrationsmethode wie Change Data Capture werden diese Transaktionsdaten nahezu in Echtzeit abgefangen. Sie können dann mit Pub/Sub ein Schema für diese Daten definieren und diese Informationen als Ereignisse bereitstellen. In diesem Fall sind die entsprechenden Schnittstellen als Pub/Sub-Themen bereitgestellte Daten.
Schritte zur Datennutzung
Datenersteller dokumentieren ihr Datenprodukt im zentralen Katalog, einschließlich einer Anleitung zur Nutzung der Daten. Für eine Organisation mit mehreren Domains erstellt dieser Dokumentationsansatz eine Architektur, die sich von der traditionellen zentral erstellten ELT/ETL-Pipeline unterscheidet, bei der Verarbeiter Ausgaben ohne die Grenze von Geschäftsdomains erstellen. Datennutzer in einem Data Mesh müssen eine gut konzipierte Erkennungs- und Nutzungsschicht haben, um einen Datennutzungslebenszyklus erstellen zu können. Die Schicht sollte Folgendes enthalten:
Schritt 1: Datenprodukte durch deklarative Suche und Untersuchung von Datenproduktspezifikationen entdecken: Datennutzer können nach jedem Datenprodukt suchen, das von Datenerstellern im zentralen Katalog registriert wurde. Bei allen Datenprodukten gibt das Datenprodukt-Tag an, wie Datenzugriffsanfragen gestellt werden und wie Daten über die erforderliche Datenproduktschnittstelle genutzt werden. Die Felder in den Datenprodukt-Tags können über eine Suchanwendung durchsucht werden. Datenproduktschnittstellen implementieren Daten-URIs. Das bedeutet, dass Daten nicht in eine separate Nutzungszone für Dienstnutzer verschoben werden müssen. Wenn keine Echtzeitdaten erforderlich sind, fragen Nutzer Datenprodukte ab und erstellen Berichte mit den generierten Ergebnissen.
Schritt 2: Daten mit interaktivem Datenzugriff und Prototyping untersuchen: Datennutzer verwenden interaktive Tools wie dem BigQuery Studio und Jupyter-Notebooks, um die Daten zu interpretieren und mit ihnen zu experimentieren, um die Abfragen zu verfeinern, die sie für die Produktion benötigen. Durch interaktive Abfragen können Datennutzer neuere Datendimensionen untersuchen und die Korrektheit der in Produktionsszenarien generierten Informationen verbessern.
Schritt 3: Datenprodukt über eine Anwendung nutzen, mit programmatischem Zugriff und Produktion:
- BI-Berichte. Batch- und echtzeitnahe Berichte und Dashboards sind die häufigste Gruppe von analytischen Anwendungsfällen, die von Datennutzern benötigt werden. Berichte erfordern unter Umständen datenübergreifenden Produktzugriff, um die Entscheidungsfindung zu erleichtern. Beispiel: Eine Kundendatenplattform erfordert das programmatische Abfragen sowohl von Bestellungen als auch von CRM-Datenprodukten nach einem Zeitplan. Die Ergebnisse eines solchen Ansatzes bieten den Geschäftsnutzern, die die Daten nutzen, eine ganzheitliche Kundenansicht.
- KI/ML-Modell für Batch- und Echtzeitvorhersagen. Data Scientists verwenden gängige MLOps-Prinzipien, um ML-Modelle zu erstellen und zu betreiben, die Datenprodukte nutzen, die von den Datenproduktteams zur Verfügung gestellt werden. ML-Modelle bieten Echtzeit-Inferenzfunktionen für Transaktionsanwendungsfälle wie die Betrugserkennung. Bei einer explorativen Datenanalyse können Datennutzer Quelldaten anreichern. Die explorative Datenanalyse mit Vertriebs- und Marketingkampagnendaten zeigt beispielsweise demografische Kundensegmente an, in denen die höchsten Verkaufszahlen erwartet werden und in denen daher die Kampagnen laufen sollten.
Nächste Schritte
- Referenzimplementierung der Data-Mesh-Architektur
- Weitere Informationen zu BigQuery
- Weitere Informationen zu Vertex AI
- Informationen zu Data Science in Dataproc
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.