Damit die Anwendungsfälle von Datennutzern erfüllt werden, ist es wichtig, dass Datenprodukte in einem Data Mesh sorgfältig designt und erstellt werden. Das Design eines Datenprodukts beginnt mit der Definition, wie Datennutzer dieses Produkt verwenden und wie dieses Produkt dann den Nutzern zugänglich gemacht wird. Datenprodukte in einem Data Mesh basieren auf einem Datenspeicher (z. B. einem Domain Data Warehouse oder Data Lake). Wenn Sie Datenprodukte in einem Data Mesh erstellen, sollten Sie einige wichtige Faktoren während dieses Prozesses berücksichtigen. Diese Überlegungen werden in diesem Dokument beschrieben.
Dieses Dokument ist Teil einer Reihe, in der beschrieben wird, wie ein Data Mesh in Google Cloudimplementiert wird. Dabei wird davon ausgegangen, dass Sie die Artikel Architektur und Funktionen in einem Data Mesh und Modernes, verteiltes Data Mesh mit Google Clouderstellen gelesen haben und mit den darin beschriebenen Konzepten vertraut sind.
Die Reihe besteht aus folgenden Teilen:
- Architektur und Funktionen in einem Data Mesh
- Self-Service-Datenplattform für ein Data Mesh entwerfen
- Datenprodukte in einem Data Mesh erstellen (dieses Dokument)
- Datenprodukte in einem Data Mesh ermitteln und nutzen
Wenn Sie Datenprodukte aus einem Domain-Data-Warehouse erstellen, empfehlen wir Datenerstellern, die analytischen (Verbrauchs-)Schnittstellen für diese Produkte sorgfältig zu entwickeln. Diese Verbrauchsschnittstellen bilden ebenso wie ein Produktsupportmodell und eine Produktdokumentation eine sichere Grundlage für die Datenqualität und Betriebsparameter Die Kosten für das Ändern der Verbrauchsschnittstellen sind in der Regel hoch, da der Datenersteller und möglicherweise mehrere Datennutzer ihre verarbeitenden Prozesse und Anwendungen ändern müssen. Da sich die Datennutzer höchstwahrscheinlich in Organisationseinheiten befinden, die von den Datenerstellern getrennt sind, kann die Koordinierung der Änderungen schwierig sein.
Die folgenden Abschnitte enthalten Hintergrundinformationen dazu, was Sie beim Erstellen eines Domain-Warehouse, beim Definieren von Verbrauchsschnittstellen und beim Freigeben dieser Schnittstellen für Datennutzer beachten müssen.
Domain-Data-Warehouse erstellen
Es gibt keinen grundlegenden Unterschied zwischen dem Erstellen eines eigenständigen Data Warehouse und dem Erstellen eines Domain-Data-Warehouse, aus dem das Team der Datenersteller Datenprodukte erstellt. Der einzige reale Unterschied zwischen den beiden besteht darin, dass Letzteres eine Teilmenge der Daten über die Verbrauchsschnittstellen bereitstellt.
In vielen Data Warehouses werden die aus Betriebsdaten aufgenommenen Rohdaten durch den Prozess der Anreicherung und Überprüfung der Datenqualität geführt. In von Dataplex Universal Catalog verwalteten Data Lakes werden ausgewählte Daten normalerweise in bestimmten ausgewählten Zonen gespeichert. Wenn die Datenpflege abgeschlossen ist, sollte eine Teilmenge der Daten für den Extern-zu-Domain-Verbrauch über verschiedene Schnittstellentypen bereit sein. Zum Definieren dieser Verbrauchsschnittstellen sollte eine Organisation einer Reihe von Tools für Domainteams bereitstellen, die noch nicht mit einem Data Mesh-Ansatz vertraut sind. Mit diesen Tools können Datenersteller neue Datenprodukte auf Self-Service-Basis erstellen. Empfohlene Vorgehensweisen finden Sie unter Self-Service-Datenplattform entwerfen.
Darüber hinaus müssen Datenprodukte die zentral definierten Anforderungen der Data Governance erfüllen. Diese Anforderungen betreffen Datenqualität, Datenverfügbarkeit und Lebenszyklusverwaltung. Da diese Anforderungen das Vertrauen von Datennutzern in die Datenprodukte aufbauen und die Nutzung der Datenprodukte fördern, lohnt die Implementierung dieser Anforderungen den Aufwand der Unterstützung.
Verbrauchsschnittstellen definieren
Wir empfehlen Datenerstellern, mehrere Schnittstellentypen zu verwenden, anstatt nur ein oder zwei Schnittstellen zu definieren. Jeder Schnittstellentyp hat in der Datenanalyse Vor- und Nachteile und es gibt keinen einzigen Schnittstellentyp, der alles abdeckt. Wenn Datenersteller die Eignung der einzelnen Schnittstellentypen prüfen, müssen sie Folgendes berücksichtigen:
- Fähigkeit, die erforderliche Datenverarbeitung durchzuführen.
- Skalierbarkeit zur Unterstützung aktueller und zukünftiger Anwendungsfälle für Datennutzer.
- Erforderliche Leistung für die Datennutzer.
- Kosten für Entwicklung und Wartung.
- Kosten für die Ausführung der Schnittstelle.
- Unterstützung durch die von Ihrer Organisation verwendeten Sprachen und Tools.
- Unterstützung für die Trennung von Speicher und Computing.
Beispiel: Wenn eine Geschäftsanforderung ist, analytische Abfragen in einem Dataset im Petabyte-Bereich auszuführen, dann ist die einzige praktische Schnittstelle eine BigQuery-Ansicht. Wenn es jedoch erforderlich ist, Streamingdaten nahezu in Echtzeit bereitzustellen, ist eine Pub/Sub-basierte Schnittstelle besser geeignet.
Bei vielen dieser Schnittstellen müssen Sie vorhandene Daten nicht kopieren oder replizieren. Bei den meisten von ihnen können Sie auch Speicher und Datenverarbeitung voneinander trennen, ein wichtiges Feature vonGoogle Cloud -Analysetools. Nutzer, denen Daten über diese Schnittstellen bereitgestellt werden, verarbeiten die Daten mithilfe der ihnen zur Verfügung stehenden Rechenressourcen. Datenersteller müssen keine zusätzliche Infrastrukturbereitstellung vornehmen.
Es gibt eine Vielzahl von Verbrauchsschnittstellen. Die folgenden Schnittstellen sind die am häufigsten in einem Data Mesh verwendeten Schnittstellen und werden in den folgenden Abschnitten erläutert:
- Autorisierte Ansichten und Funktionen
- APIs mit direktem Lesevorgang
- Daten als Streams
- Data Access API
- Looker Blocks
- Modelle für maschinelles Lernen (ML)
Die Liste der Schnittstellen in diesem Dokument ist nicht vollständig. Es gibt auch andere Optionen, die Sie für Ihre Verbrauchsschnittstellen in Betracht ziehen können, z. B. BigQuery Sharing (früher Analytics Hub). Diese anderen Schnittstellen werden in diesem Dokument jedoch nicht behandelt.
Autorisierte Ansichten und Funktionen
Datenprodukte sollten so weit wie möglich über autorisierte Ansichten und autorisierte Funktionen verfügbar gemacht werden, einschließlich Tabellenfunktionen. Autorisierte Datasets bieten eine bequeme Möglichkeit, mehrere Ansichten automatisch zu autorisieren. Durch die Verwendung autorisierter Ansichten wird der direkte Zugriff auf die Basistabellen verhindert. Außerdem können Sie die zugrunde liegenden Tabellen und Abfragen dafür optimieren, ohne dass die Nutzung dieser Ansichten durch den Nutzer beeinträchtigt wird. Nutzer dieser Schnittstelle fragen die Daten mit SQL ab. Das folgende Diagramm veranschaulicht die Verwendung autorisierter Datasets als Verbrauchsschnittstelle.
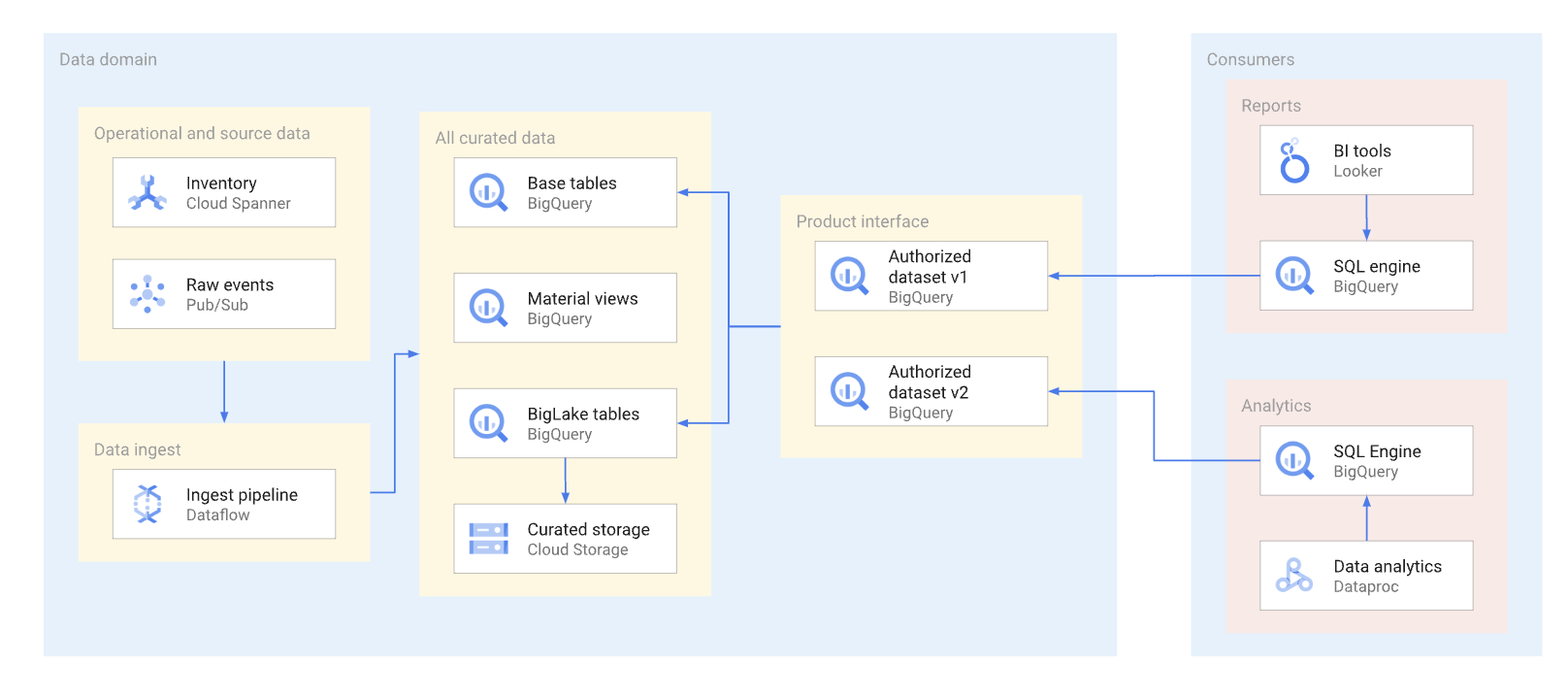
Autorisierte Datasets und Ansichten ermöglichen eine einfache Versionsverwaltung von Schnittstellen. Wie im folgenden Diagramm dargestellt, können Datenersteller zwei primäre Versionsverwaltungsansätze verfolgen:
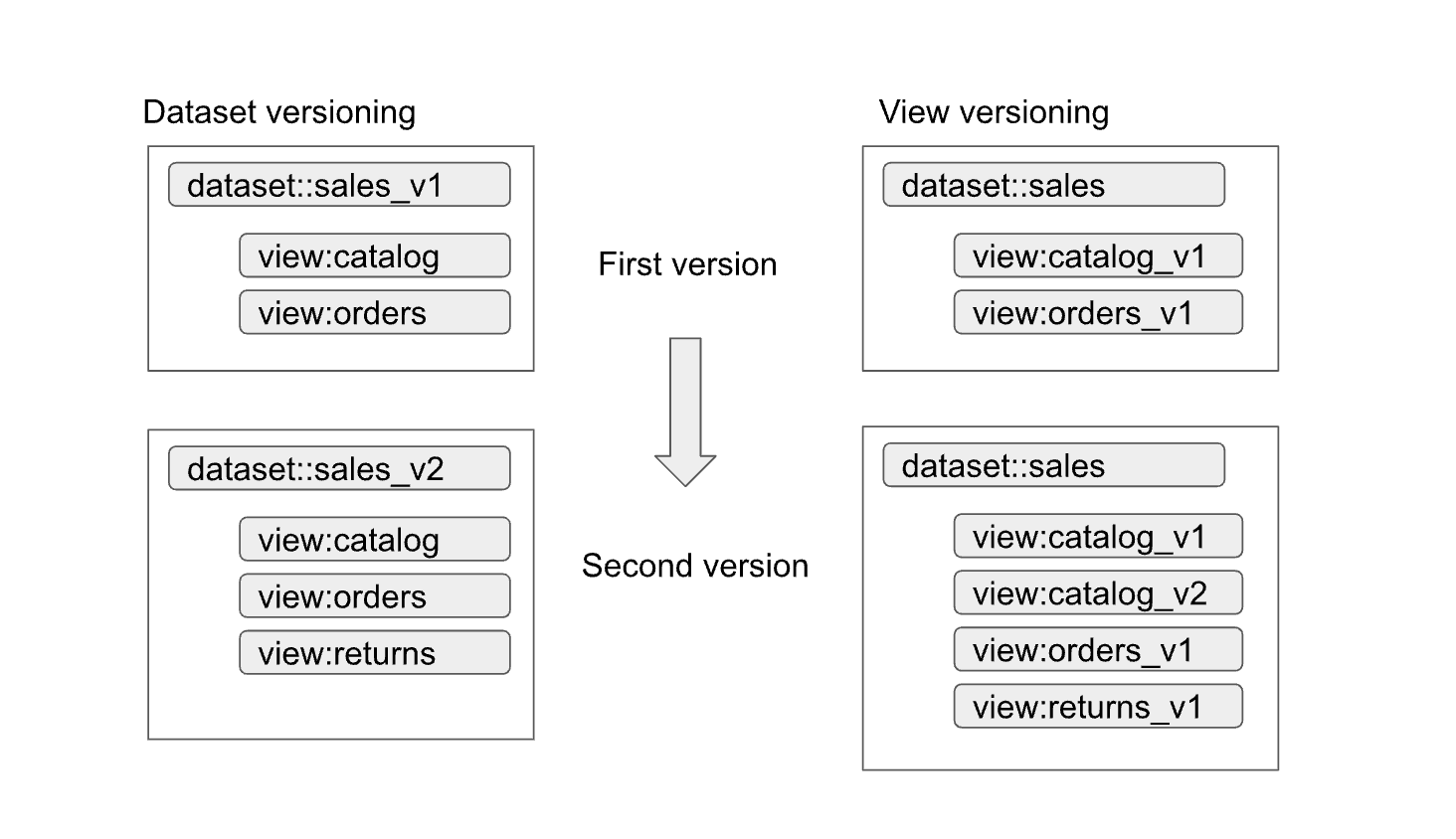
Die Ansätze können so zusammengefasst werden:
- Dataset-Versionsverwaltung: Bei diesem Ansatz versionieren Sie den Dataset-Namen.
Sie versionieren die Ansichten und Funktionen im Dataset nicht. Sie behalten die gleichen Namen für die Ansichten und Funktionen, unabhängig von der Version. Beispiel: Die erste Version eines Verkaufs-Datasets wird in einem Dataset namens
sales_v1mit den zwei Ansichtencatalogundordersdefiniert. In der zweiten Version wurde das Verkaufs-Dataset insales_v2umbenannt. Alle vorherigen Ansichten im Dataset behalten ihre vorherigen Namen bei, haben jedoch neue Schemas. In der zweiten Version des Datasets können auch neue Ansichten hinzugefügt oder eine der vorherigen Ansichten entfernt werden. - Ansichts-Versionsverwaltung: Bei diesem Ansatz werden die Ansichten im Dataset statt des Datasets selbst versioniert. Beispielsweise behält das Verkaufs-Dataset unabhängig von der Version den Namen
salesbei. Die Namen der Ansichten im Dataset ändern sich jedoch entsprechend den neuen Versionen der Ansicht (z. B.catalog_v1,catalog_v2,orders_v1,orders_v2undorders_v3).
Der beste Versionsverwaltungsansatz für Ihre Organisation hängt von den Richtlinien Ihrer Organisation und der Anzahl der Ansichten ab, die durch die Aktualisierung der zugrunde liegenden Daten veraltet sind. Die Dataset-Versionsverwaltung eignet sich am besten, wenn ein umfangreiches Produktupdate erforderlich ist und sich die meisten Ansichten ändern müssen. Die Ansichts-Versionsverwaltung führt zu weniger identisch benannten Ansichten in verschiedenen Datasets, kann jedoch zu Uneindeutigkeiten führen, beispielsweise wie festgestellt werden kann, ob eine Zusammenführung zwischen Datasets ordnungsgemäß funktioniert. Ein hybrider Ansatz kann ein guter Kompromiss sein. Bei einem hybriden Ansatz sind kompatible Schemaänderungen in einem einzelnen Dataset zulässig und inkompatible Änderungen erfordern ein neues Dataset.
Überlegungen zu BigLake-Tabellen
Autorisierte Ansichten können nicht nur in BigQuery-Tabellen, sondern auch in BigLake-Tabellen erstellt werden. Mit BigLake-Tabellen können Nutzer die in Cloud Storage gespeicherten Daten über die BigQuery-SQL-Schnittstelle abfragen. BigLake-Tabellen unterstützen eine differenzierte Zugriffssteuerung, ohne dass Datennutzer Leseberechtigungen für den zugrunde liegenden Cloud Storage-Bucket haben müssen.
Datenersteller müssen für BigLake-Tabellen Folgendes berücksichtigen:
- Das Design der Dateiformate und das Datenlayout beeinflussen die Leistung der Abfragen. Spaltenbasierte Formate wie Parquet oder ORC sind für Analyseabfragen im Allgemeinen besser als JSON- oder CSV-Formate geeignet.
- Mit einem Hive-partitionierten Layout können Sie Partitionen bereinigen und beschleunigen, die Partitionierungsspalten verwenden.
- Auch die Anzahl der Dateien und die bevorzugte Abfrageleistung für die Dateigröße müssen in der Designphase berücksichtigt werden.
Wenn Abfragen mit BigLake-Tabellen nicht die Service Level Agreement-Anforderungen (SLA) für die Schnittstelle erfüllen und nicht abgestimmt werden können, empfehlen wir die folgenden Aktionen:
- Daten, die dem Datennutzer zugänglich gemacht werden müssen, müssen in den BigQuery-Speicher konvertiert werden.
- Definieren Sie die autorisierten Ansichten neu, um die BigQuery-Tabellen zu verwenden.
Im Allgemeinen verursacht dieser Ansatz keine Unterbrechung für die Datennutzer oder erfordert Änderungen an den Abfragen. Die Abfragen im BigQuery-Speicher können mit Techniken optimiert werden, die mit BigLake-Tabellen nicht möglich sind. Mit dem BigQuery-Speicher können Nutzer beispielsweise materialisierte Ansichten abfragen, die andere Partitionierungs- und Clustering-Funktionen haben als die Basistabellen. Außerdem können sie die BigQuery BI Engine verwenden.
APIs mit direktem Lesevorgang
Obwohl wir grundsätzlich nicht empfehlen, dass Datenersteller Datennutzern direkten Lesezugriff auf die Basistabellen gewähren, kann es gelegentlich praktikabel sein, einen solchen Zugriff aus Gründen wie Leistung oder Kosten zuzulassen. In solchen Fällen sollte besonders darauf geachtet werden, dass das Tabellenschema stabil ist.
Es gibt zwei Möglichkeiten, um direkt in einem typischen Data Warehouse auf Daten zuzugreifen. Datenersteller können entweder die BigQuery Storage Read API oder die Cloud Storage JSON oder XML APIs verwenden. Das folgende Diagramm veranschaulicht zwei Beispiele für Nutzer, die diese APIs verwenden. Eines ist der Anwendungsfall für maschinelles Lernen (ML) und das andere ein Datenverarbeitungsjob.
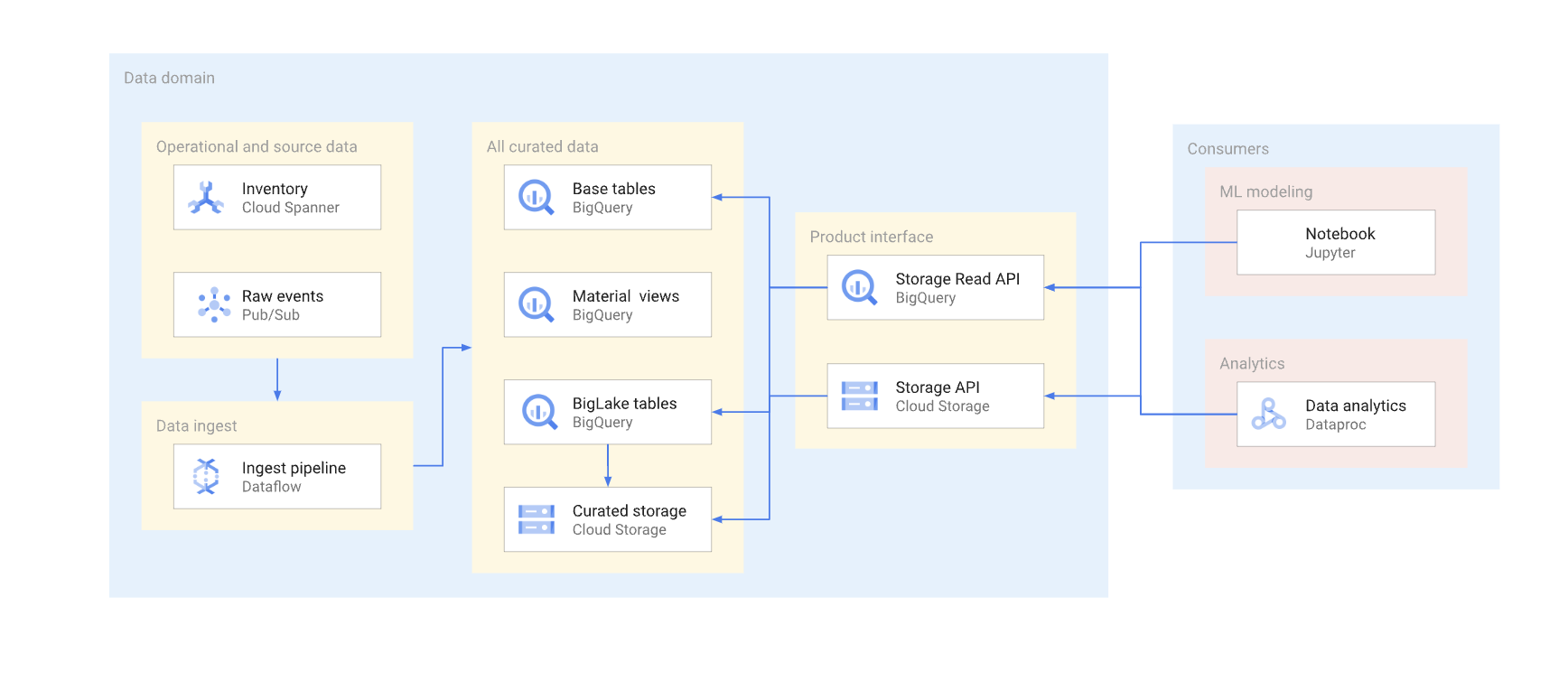
Die Versionierung einer direkten Leseschnittstelle ist komplex. In der Regel müssen Datenersteller eine andere Tabelle mit einem anderen Schema erstellen. Außerdem müssen sie zwei Versionen der Tabelle beibehalten, bis alle Datennutzer der verworfenen Version zur neuen Version migriert sind. Wenn die Nutzer die Unterbrechung der Neuerstellung der Tabelle und den Wechsel zum neuen Schema tolerieren, können Sie die Datenduplizierung vermeiden. Wenn Schemaänderungen abwärtskompatibel sind, kann die Migration der Basistabelle vermieden werden. Beispielsweise müssen Sie die Basistabelle nicht migrieren, wenn nur neue Spalten hinzugefügt werden und die Daten in diesen Spalten für alle Zeilen aufgefüllt werden.
Im Folgenden finden Sie eine Zusammenfassung der Unterschiede zwischen der Storage Read API und der Cloud Storage API. Im Allgemeinen empfehlen wir nach Möglichkeit die Verwendung von BigQuery API für analytische Anwendungen.
Storage Read API: Die Storage Read API kann zum Lesen von Daten in BigQuery-Tabellen und zum Lesen von BigLake-Tabellen verwendet werden. Diese API unterstützt das Filtern und die detaillierte Zugriffssteuerung und kann eine gute Option für stabile Datenanalysen oder ML-Nutzer sein.
Cloud Storage API: Datenersteller müssen möglicherweise einen bestimmten Cloud Storage-Bucket direkt für Datennutzer freigeben. Datenersteller können den Bucket beispielsweise freigeben, wenn Nutzer die SQL-Schnittstelle aus irgendeinem Grund nicht verwenden können oder der Bucket Datenformate hat, die nicht von der Storage Read API unterstützt werden.
Im Allgemeinen empfehlen wir Datenerstellern nicht, den direkten Zugriff über die Storage APIs zu ermöglichen, da direkter Zugriff keine Filterung und keine detaillierte Zugriffssteuerung zulässt. Der Ansatz für den direkten Zugriff kann jedoch eine praktikable Wahl für stabile, kleine Datasets (Gigabyte) sein.
Wenn Pub/Sub Zugriff auf den Bucket gewährt, können Datennutzer ganz einfach die Daten in ihre Projekte kopieren und dort verarbeiten. Im Allgemeinen empfehlen wir das Kopieren von Daten nicht, wenn dies vermieden werden kann. Mehrere Kopien von Daten erhöhen die Speicherkosten und erhöhen den Aufwand für Wartung und Lineage-Tracking.
Daten als Streams
Eine Domain kann Streamingdaten verfügbar machen. Dazu werden diese Daten in einem Pub/Sub-Thema veröffentlicht. Abonnenten, die die Daten nutzen möchten, erstellen Abos, um die für dieses Thema veröffentlichten Nachrichten zu nutzen. Jeder Abonnent empfängt und nutzt Daten unabhängig. Das folgende Diagramm zeigt ein Beispiel für solche Datenströme.
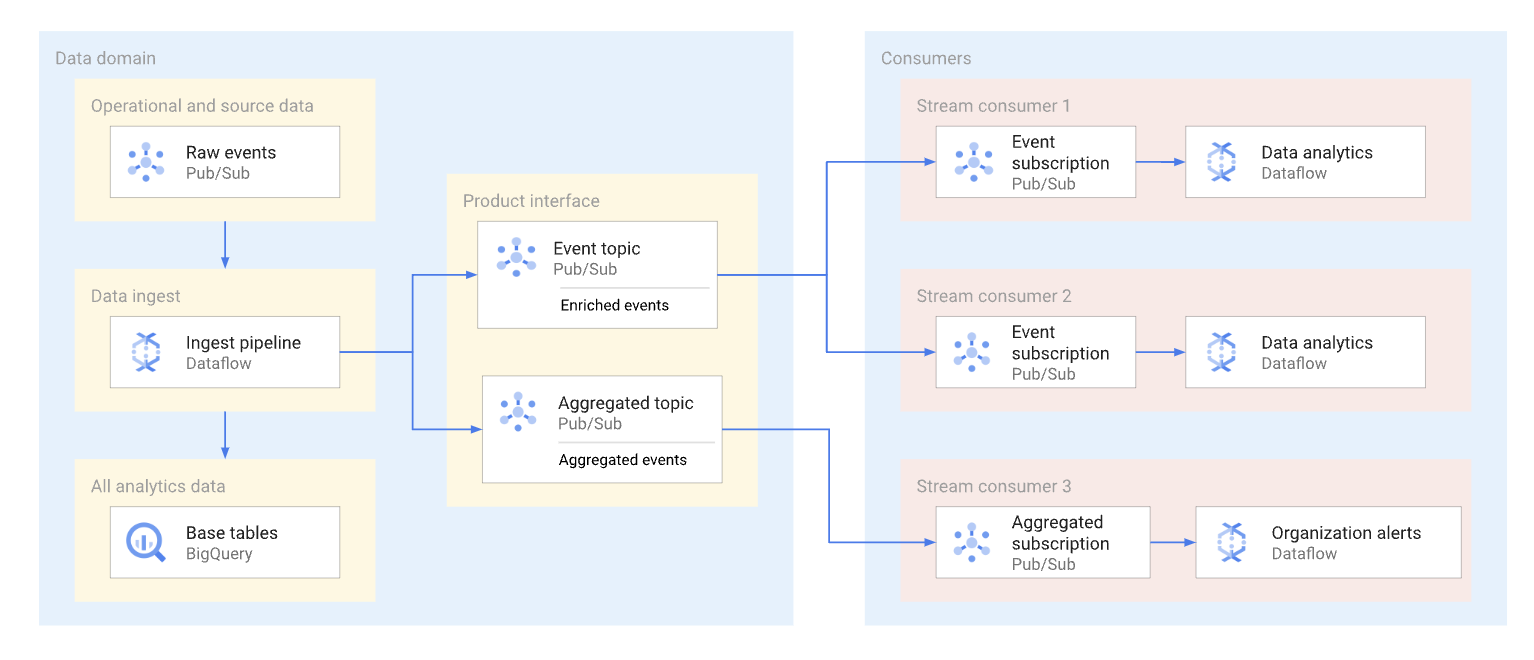
Im Diagramm liest die Aufnahme-Pipeline die Rohereignisse, reichert sie an (Datenpflege) und speichert diese ausgewählten Daten im analytischen Datenspeicher (BigQuery-Basistabelle). Gleichzeitig veröffentlicht die Pipeline die angereicherten Ereignisse in einem dedizierten Thema. Dieses Thema wird von mehreren Abonnenten genutzt, die jeweils möglicherweise diese Ereignisse filtern, um nur die relevanten Ereignisse zu erhalten. Die Pipeline fasst auch Ereignisstatistiken in ihrem eigenen Thema zusammen und veröffentlicht sie zur Verarbeitung durch einen anderen Datennutzer.
Im Folgenden finden Sie Beispielanwendungsfälle für Pub/Sub-Abos:
- Angereicherte Ereignisse, z. B. die Bereitstellung vollständiger Kundenprofilinformationen sowie Daten zu einer bestimmten Kundenbestellung.
- Echtzeitnahe Benachrichtigungen zur Aggregation, z. B. Gesamtstatistik für die Bestellungen der letzten 15 Minuten.
- Benachrichtigungen auf Geschäftsebene, z. B. das Generieren einer Benachrichtigung, wenn das Bestellvolumen im Vergleich zu einem ähnlichen Zeitraum am Vortag um 20% gesunken ist.
- Benachrichtigungen über Datenänderungen (ähnlich dem Konzept der Änderungserfassungsbenachrichtigung), z. B. einem bestimmten Auftragsänderungsstatus.
Das Datenformat, das Datenersteller für Pub/Sub-Nachrichten verwenden, wirkt sich auf die Kosten und die Verarbeitung dieser Nachrichten aus. Für Streams mit hohem Volumen in einer Data-Mesh-Architektur sind Avro- oder Protobuf-Formate gute Optionen. Wenn Datenersteller diese Formate verwenden, können sie Pub/Sub-Themen Schemas zuweisen. Die Schemas sorgen dafür, dass die Nutzer wohlgeformte Nachrichten erhalten.
Da sich die Streamingdatenstruktur ständig ändern kann, erfordert die Versionsverwaltung dieser Schnittstelle eine Abstimmung zwischen Datenersteller und Datennutzern. Datenersteller können folgende verschiedene Ansätze verwenden:
- Bei jeder Änderung der Nachrichtenstruktur wird ein neues Thema erstellt. Dieses Thema hat häufig ein explizites Pub/Sub-Schema. Datennutzer, die die neue Schnittstelle benötigen, können mit der Nutzung der neuen Daten beginnen. Die Nachrichtenversion wird durch den Namen des Themas impliziert, z. B.
click_events_v1. Nachrichtenformate sind stark typisiert. Es gibt keine Variation im Nachrichtenformat zwischen Nachrichten im selben Thema. Der Nachteil dieses Ansatzes ist, dass Datennutzer möglicherweise nicht auf das neue Abo umstellen können. In diesem Fall muss der Datenersteller für einige Zeit Ereignisse in allen aktiven Themen veröffentlichen. Datennutzer, die das Thema abonnieren, müssen entweder mit einer Lücke im Nachrichtenfluss umgehen oder die Nachrichten deduplizieren. - Daten werden immer im selben Thema veröffentlicht. Die Struktur der Nachricht kann sich jedoch ändern. Ein Pub/Sub-Nachrichtenattribut (getrennt von der Nutzlast) definiert die Version der Nachricht. Beispiel:
v=1.0Bei diesem Ansatz müssen keine Lücken oder Duplikate mehr vermieden werden. Allerdings müssen alle Datennutzer bereit sein, Nachrichten eines neuen Typs zu empfangen. Datenersteller können für diesen Ansatz auch keine Pub/Sub-Themenschemas verwenden. - Ein hybrider Ansatz. Das Nachrichtenschema kann einen beliebigen Datenabschnitt haben, der für neue Felder verwendet werden kann. Dieser Ansatz bietet eine angemessene Balance zwischen typisierten Daten und häufigen und komplexen Versionsänderungen.
Data Access API
Datenersteller können eine benutzerdefinierte API erstellen, um direkt auf die Basistabellen in einem Data Warehouse zuzugreifen. In der Regel geben diese Ersteller diese benutzerdefinierte API als REST oder gRPC API an und stellen sie in Cloud Run oder einem Kubernetes-Cluster bereit. Ein API-Gateway wie Apigee kann andere zusätzliche Funktionen bieten, z. B. Trafficdrosselung oder eine Caching-Ebene. Diese Funktionen sind nützlich, wenn die Datenzugriffs-API für Nutzer außerhalb einer Google Cloud -Organisation verfügbar gemacht wird. Potenzielle Kandidaten für eine Datenzugriffs-API sind latenzempfindliche Abfragen mit hoher Gleichzeitigkeit, die beide ein relativ kleines Ergebnis in einer einzigen API zurückgeben und effektiv im Cache gespeichert werden können.
Beispiele für eine solche benutzerdefinierte API für den Datenzugriff:
- Kombinierte Ansicht der SLA-Messwerte der Tabelle oder des Produkts.
- Die Top-10 (möglicherweise im Cache gespeicherten) Datensätze aus einer bestimmten Tabelle.
- Ein Dataset mit Tabellenstatistiken (Gesamtzahl der Zeilen oder Datenverteilung innerhalb von Schlüsselspalten).
Alle Richtlinien und Governance, die das Unternehmen zum Erstellen von Anwendungs-APIs hat, gelten auch für die von Datenerstellern erstellten benutzerdefinierten APIs. Die Richtlinien und Governance der Organisation sollten Probleme wie Hosting, Monitoring, Zugriffssteuerung und Versionsverwaltung umfassen.
Der Nachteil einer benutzerdefinierten API ist, dass die Datenersteller für jede weitere Infrastruktur, die zum Hosten dieser Schnittstelle erforderlich ist, sowie für die benutzerdefinierte API-Codierung und -Wartung verantwortlich sind. Wir empfehlen Datenerstellern, andere Optionen zu untersuchen, bevor sie sich entscheiden, benutzerdefinierte Datenzugriffs-APIs zu erstellen. Datenersteller können beispielsweise BigQuery BI Engine verwenden, um die Antwortlatenz zu verringern und die Gleichzeitigkeit zu erhöhen.
Looker Blocks
Für Produkte wie Looker, die häufig in BI-Tools (Business Intelligence) verwendet werden, kann es hilfreich sein, eine Reihe von BI-Tool-spezifischen Widgets zu verwalten. Da das Datenerstellerteam das in der Domain verwendete zugrunde liegende Datenmodell kennt, ist dieses Team am besten geeignet, um einen vordefinierten Satz von Visualisierungen zu erstellen und zu verwalten.
Im Fall von Looker kann diese Visualisierung eine Reihe von Looker Blocks (vorgefertigte LookML-Datenmodelle) sein. Die Looker Blocks können problemlos in Dashboards eingebunden werden, die von Nutzern gehostet werden.
ML-Modelle
Da Teams, die in Datendomains arbeiten, ein tiefes Verständnis und umfassende Kenntnisse ihrer Daten haben, sind sie oft die besten Teams, um ML-Modelle zu erstellen und zu verwalten, die mit den Domaindaten trainiert werden. Diese ML-Modelle können über mehrere verschiedene Schnittstellen verfügbar gemacht werden, darunter:
- BigQuery ML-Modelle können in einem dedizierten Dataset bereitgestellt und für Datennutzer für BigQuery-Batchvorhersagen freigegeben werden.
- BigQuery ML-Modelle können zur Verwendung für Onlinevorhersagen in Vertex AI exportiert werden.
Überlegungen zum Speicherort von Daten für Verbrauchsschnittstellen
Eine wichtige Überlegung, wenn Datenersteller Verbrauchsschnittstellen für Datenprodukte definieren, ist der Speicherort von Daten. Um die Kosten zu minimieren, sollten die Daten im Allgemeinen in derselben Region verarbeitet werden, in der sie gespeichert sind. Dieser Ansatz hilft, Gebühren für regionenübergreifenden ausgehenden Traffic zu vermeiden. Dieser Ansatz hat auch die niedrigste Datenverbrauchslatenz. Aus diesen Gründen sind Daten, die an multiregionalen BigQuery-Standorten gespeichert sind, normalerweise der beste Kandidat für die Freigabe als Datenprodukt.
Aus Leistungsgründen sollten die in Cloud Storage gespeicherten und über BigLake-Tabellen oder direkten Lese-APIs bereitgestellten Daten jedoch in regionalen Buckets gespeichert werden.
Wenn sich Daten, die in einem Produkt bereitgestellt werden, in einer Region befinden und mit Daten in einer anderen Domain in einer anderen Region verknüpft werden müssen, müssen Datennutzer folgende Einschränkungen berücksichtigen:
- Regionenübergreifende Abfragen, die BigQuery-SQL verwenden, werden nicht unterstützt. Wenn die primäre Verbrauchsmethode für die Daten BigQuery SQL ist, müssen sich alle Tabellen in der Abfrage am selben Standort befinden.
- Zusicherungen zu BigQuery-Pauschalpreisen sind regional. Wenn für ein Projekt nur eine Pauschalzusicherung in einer Region verwendet wird, aber ein Datenprodukt in einer anderen Region abgefragt wird, gelten die On-Demand-Preise.
- Datennutzer können APIs mit direkten Lesezugriffen verwenden, um Daten aus einer anderen Region zu lesen. Es fallen jedoch Gebühren für regionenübergreifenden ausgehenden Netzwerktraffic an. Datennutzer haben für große Datenübertragungen höchstwahrscheinlich eine Latenz.
Daten, auf die häufig über Regionen zugegriffen wird, können in diese Regionen repliziert werden, um die Kosten und Latenzen von Abfragen der Produktnutzer zu reduzieren. BigQuery-Datasets können beispielsweise in andere Regionen kopiert werden. Daten sollten jedoch nur kopiert werden, wenn es erforderlich ist. Wir empfehlen Datenerstellern, dass Sie beim Kopieren von Daten nur einen Teil der verfügbaren Produktdaten für mehrere Regionen verfügbar machen. Dieser Ansatz hilft, die Replikationslatenz und die Kosten zu minimieren. Bei diesem Ansatz müssen möglicherweise mehrere Versionen der Verbrauchsschnittstelle mit der explizit benannten Datenspeicher-Region angegeben werden. Beispielsweise können autorisierte BigQuery-Ansichten durch Benennung wie sales_eu_v1 und sales_us_v1 angezeigt werden.
Datenstream-Schnittstellen mit Pub/Sub-Themen benötigen keine zusätzliche Replikationslogik, um Nachrichten in Regionen zu verarbeiten, die sich nicht in derselben Region befinden wie die Nachricht. In diesem Fall gelten jedoch zusätzliche Gebühren für regionenübergreifenden ausgehenden Traffic.
Verbrauchsschnittstellen für Datennutzer freigeben
In diesem Abschnitt wird erläutert, wie Verbrauchsschnittstellen für potenzielle Nutzer sichtbar werden. Data Catalog ist ein vollständig verwalteter Dienst, mit dem Organisationen die Dienste für die Datenermittlung und Metadatenverwaltung bereitstellen können. Datenersteller müssen die Verbrauchsschnittstellen ihrer Datenprodukte auffindbar machen und mit den entsprechenden Metadaten annotieren, damit Produktnutzer selbst auf sie zugreifen können. Mi
In den folgenden Abschnitten wird erläutert, wie jeder Schnittstellentyp als Data Catalog-Eintrag definiert ist.
BigQuery-basierte SQL-Schnittstellen
Technische Metadaten wie ein vollständig qualifizierter Tabellenname oder Tabellenschema werden automatisch für autorisierte Ansichten, BigLake-Ansichten und BigQuery-Tabellen registriert, die über die Storage Read API verfügbar sind. Wir empfehlen Datenerstellern, zusätzliche Informationen in der Datenproduktdokumentation bereitzustellen, um Datennutzer zu unterstützen. Um Nutzern beispielsweise die Produktdokumentation für einen Eintrag zu erleichtern, können Datenersteller einem der Tags, die auf den Eintrag angewendet wurden, eine URL hinzufügen. Ersteller können auch Folgendes angeben:
- Sets von geclusterten Spalten, die in Abfragefiltern verwendet werden sollten.
- Aufzählungswerte für Felder mit logischem Aufzählungstyp, wenn der Typ nicht als Teil der Feldbeschreibung bereitgestellt wird.
- Unterstützte Joins mit anderen Tabellen.
Datenstreams
Pub/Sub-Themen werden automatisch in Data Catalog registriert. Datenersteller müssen jedoch das Schema in der Datenprodukt-Dokumentation beschreiben.
Cloud Storage API
Data Catalog unterstützt die Definition von Cloud Storage-Dateieinträgen und deren Schema. Wenn ein Data Lake-Dateisatz von Dataplex Universal Catalog verwaltet wird, wird er automatisch in Data Catalog registriert. Dateisätze, die nicht mit Dataplex Universal Catalog verknüpft sind, werden mit einem anderen Ansatz hinzugefügt.
Andere Schnittstellen
Mit benutzerdefinierten Einträgen können Sie andere Schnittstellen hinzufügen, die keine integrierte Unterstützung aus Data Catalog haben.
Nächste Schritte
- Referenzimplementierung der Data-Mesh-Architektur
- Weitere Informationen zu BigQuery
- Informationen zu Dataplex lesen.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.