このガイドでは、 Google Cloud上の SUSE Linux Enterprise Server(SLES)高可用性(HA)クラスタで SAP HANA スケールアウト システムのデプロイを自動化する方法について説明します。
このガイドでは、Terraform を使用して、 Google Cloud、SAP、SUSE のベスト プラクティスに従って、マルチホストの SAP HANA スケールアウト システム、内部パススルー ネットワーク ロードバランサを使用する仮想 IP アドレス(VIP)、OS ベースの HA クラスタをデプロイします。
SAP HANA システムの一つがプライマリのアクティブ システムとして機能し、もう一つはセカンダリのスタンバイ システムとして機能します。両方の SAP HANA システムは同じリージョンにデプロイします(異なるゾーンにデプロイすることが理想的です)。
デプロイされたクラスタには、以下の機能が含まれます。
- Pacemaker 高可用性クラスタ リソース マネージャー。
- Google Cloud フェンシング メカニズム。
- レベル 4 の TCP 内部ロードバランサの実装を使用する仮想 IP(VIP)。以下を含みます。
- VIP 用に選択した IP アドレスの予約。
- 2 つの Compute Engine インスタンス グループ。
- TCP 内部ロードバランサ。
- Compute Engine ヘルスチェック
- SUSE 高可用性パターン。
- SUSE SAPHanaSR リソース エージェント パッケージ。
- 同期システム レプリケーション。
- メモリ プリロード。
- 障害が発生したインスタンスを新しいセカンダリ インスタンスとして自動的に再起動。
SAP HANA 自動ホスト フェイルオーバー用のスタンバイ ホストを備えたスケールアウト システムが必要な場合は、代わりに Terraform: ホストの自動フェイルオーバーを備える SAP HANA スケールアウト システムのデプロイガイドをご覧ください。
Linux 高可用性クラスタまたはスタンバイ ホストなしで SAP HANA システムをデプロイする場合は、Terraform: SAP HANA デプロイガイドをご覧ください。
このガイドは、SAP HANA 用の Linux 高可用性構成に精通している SAP HANA の上級ユーザーを対象としています。
前提条件
SAP HANA 高可用性クラスタを作成する前に、次の前提条件を満たしていることを確認してください。
- SAP HANA プランニング ガイドと SAP HANA 高可用性プランニング ガイドを読んでいる。
- 個人または組織の Google Cloud アカウントがあり、SAP HANA をデプロイするためのプロジェクトが作成済み。Google Cloud アカウントとプロジェクトの作成方法については、Google アカウントの設定をご覧ください。
- データ所在地、アクセス制御、サポート担当者、規制要件に準拠しながら SAP ワークロードを実行する必要がある場合は、必要な Assured Workloads フォルダを作成する必要があります。詳細については、 Google Cloudでの SAP のコンプライアンスと主権管理をご覧ください。
SAP HANA のインストール メディアが、ユーザーのデプロイ プロジェクトおよびリージョンで利用可能な Cloud Storage バケットに格納されている。SAP HANA インストール メディアを Cloud Storage バケットにアップロードする方法については、SAP HANA インストール ファイル用の Cloud Storage バケットの作成をご覧ください。
プロジェクト メタデータで OS Login が有効になっている場合は、デプロイが完了するまで一時的に OS Login を無効にする必要があります。デプロイのために、次の手順によりインスタンス メタデータで SSH 認証鍵を構成します。OS Login が有効になっている場合、メタデータ ベースの SSH 認証鍵構成は無効になり、このデプロイは失敗します。デプロイが完了したら、再度 OS Login を有効にできます。
詳細については、以下をご覧ください。
VPC 内部 DNS を使用している場合は、 Google Cloud プロジェクト メタデータの
vmDnsSetting変数の値をGlobalDefaultまたはZonalPreferredにして、ゾーン間でノード名を解決できるようにする。vmDnsSettingのデフォルト設定はZonalOnlyです。詳細については、次のトピックをご覧ください。
ネットワークの作成
セキュリティ上の理由から、新しいネットワークを作成します。アクセスできるユーザーを制御するには、ファイアウォール ルールを追加するか、別のアクセス制御方法を使用します。
プロジェクトにデフォルトの VPC ネットワークがある場合、デフォルトは使用せず、明示的に作成したファイアウォール ルールが唯一の有効なルールとなるように、独自の VPC ネットワークを作成してください。
デプロイ中、Compute Engine インスタンスは通常、 Google Cloudの SAP 用エージェントをダウンロードするためにインターネットにアクセスする必要があります。 Google Cloudから入手できる SAP 認定の Linux イメージのいずれかを使用している場合も、ライセンスを登録して OS ベンダーのリポジトリにアクセスするために、コンピューティング インスタンスからインターネットにアクセスする必要があります。このアクセスをサポートするために、NAT ゲートウェイを配置し、VM ネットワーク タグを使用して構成します。ターゲットのコンピューティング インスタンスに外部 IP がない場合でもこの構成が可能です。
プロジェクトの VPC ネットワークを作成するには、次の操作を行います。
-
カスタムモードのネットワークを作成します。詳細については、カスタムモード ネットワークの作成をご覧ください。
-
サブネットワークを作成し、リージョンと IP 範囲を指定します。詳細については、サブネットの追加をご覧ください。
NAT ゲートウェイの設定
パブリック IP アドレスなしで 1 台以上の VM を作成する必要がある場合は、ネットワーク アドレス変換(NAT)を使用して、VM がインターネットにアクセスできるようにする必要があります。Cloud NAT は Google Cloud の分散ソフトウェア定義マネージド サービスであり、VM からインターネットへのアウトバウンド パケットの送信と、それに対応するインバウンド レスポンス パケットの受信を可能にします。また、別個の VM を NAT ゲートウェイとして設定することもできます。
プロジェクトに Cloud NAT インスタンスを作成する方法については、Cloud NAT の使用をご覧ください。
プロジェクトに Cloud NAT を構成すると、VM インスタンスはパブリック IP アドレスなしでインターネットに安全にアクセスできるようになります。
ファイアウォール ルールの追加
デフォルトでは、暗黙のファイアウォール ルールにより、Virtual Private Cloud(VPC)ネットワークの外部からの受信接続がブロックされます。受信側の接続を許可するには、VM にファイアウォール ルールを設定します。VM との受信接続が確立されると、トラフィックはその接続を介して双方向に許可されます。
特定のポートへの外部アクセスを許可するファイアウォール ルールや、同じネットワーク上の VM 間のアクセスを制限するファイアウォール ルールも作成できます。VPC ネットワーク タイプとして default が使用されている場合は、default-allow-internal ルールなどの追加のデフォルト ルールも適用されます。追加のデフォルト ルールは、同じネットワークであれば、すべてのポートで VM 間の接続を許可します。
ご使用の環境に適用可能な IT ポリシーによっては、データベース ホストへの接続を分離するか制限しなければならない場合があります。これを行うには、ファイアウォール ルールを作成します。
目的のシナリオに応じて、次の対象にアクセスを許可するファイアウォール ルールを作成できます。
- すべての SAP プロダクトの TCP/IP にリストされているデフォルトの SAP ポート。
- パソコンまたは企業のネットワーク環境から Compute Engine VM インスタンスへの接続。使用すべき IP アドレスがわからない場合は、社内のネットワーク管理者に確認してください。
プロジェクトのファイアウォール ルールを作成するには、ファイアウォール ルールの作成をご覧ください。
SAP HANA がインストールされている高可用性 Linux クラスタを作成する
次の手順では、Terraform 構成ファイルを使用して、同じ Compute Engine リージョンに、プライマリ SAP HANA システムと、セカンダリまたはスタンバイ SAP HANA システムの 2 つの SAP HANA システムを持つ SLES クラスタを作成します。SAP HANA システムは同期システム レプリケーションを使用し、スタンバイ システムは複製されたデータをプリロードします。
Terraform 構成ファイルで SAP HANA 高可用性クラスタの構成オプションを定義します。
次の手順では Cloud Shell を使用していますが、通常は、Terraform がインストールされ、Google プロバイダが構成されているローカル ターミナルに適用できます。
永続ディスクや CPU などリソースの現在の割り当てが、インストールしようとしている SAP HANA システムに対して十分であることを確認します。割り当てが不足していると、デプロイは失敗します。
SAP HANA の割り当て要件については、SAP HANA の料金と割り当てに関する考慮事項をご覧ください。
Cloud Shell またはローカル ターミナルを開きます。
Cloud Shell またはターミナルで次のコマンドを実行して、
sap_hana_ha.tf構成ファイルを作業ディレクトリにダウンロードします。$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfsap_hana_ha.tfファイルを Cloud Shell コードエディタで開きます。または、ターミナルを使用している場合は、任意のテキスト エディタで開きます。Cloud Shell コードエディタを開くには、Cloud Shell ターミナル ウィンドウの右上にある鉛筆アイコンをクリックします。
sap_hana_ha.tfファイルで、二重引用符で囲まれた内容をご使用のインストール環境の値に置き換えて、引数値を更新します。引数については、次の表をご覧ください。引数 データ型 説明 source文字列 デプロイ時に使用する Terraform モジュールの場所とバージョンを指定します。
sap_hana_ha.tf構成ファイルには、source引数の 2 つのインスタンスがあります。1 つは有効で、もう 1 つはコメントとして追加されています。デフォルトで有効なsource引数に、モジュール バージョンとしてlatestを指定します。デフォルトでは、source引数の 2 番目のインスタンスの先頭に#文字があり、引数が無効になっています。この引数には、モジュール バージョンを識別するタイムスタンプを指定します。すべてのデプロイで同じモジュール バージョンを使用する必要がある場合は、バージョン タイムスタンプを指定する
source引数の先頭から#文字を削除し、latestを指定するsource引数の先頭にコメント文字を追加します。project_id文字列 このシステムをデプロイする Google Cloud プロジェクトの ID を指定します。たとえば、 my-project-xのようにします。machine_type文字列 SAP システムの実行に必要な Compute Engine 仮想マシン(VM)のタイプを指定します。カスタム VM タイプが必要な場合は、必要な数に最も近く、かつ必要数以上の vCPU 数を持つ事前定義された VM タイプを指定します。デプロイが完了したら、vCPU 数とメモリ量を変更してください。 例:
n1-highmem-32sole_tenant_deploymentブール値 省略可。SAP HANA デプロイ用に単一テナントノードのプロビジョニングを行う場合は、値
trueを指定します。デフォルト値は
falseです。この引数は
sap_hana_haバージョン1.3.704310921以降で使用できます。sole_tenant_name_prefix文字列 省略可。SAP HANA デプロイ用に単一テナントノードのプロビジョニングを行っている場合は、この引数を使用して、対応する単一テナント テンプレートと単一テナント グループの名前に Terraform が設定する接頭辞を指定できます。
デフォルト値は
st-SID_LCです。単一テナント テンプレートと単一テナント グループの詳細については、単一テナンシーの概要をご覧ください。
この引数は
sap_hana_haバージョン1.3.704310921以降で使用できます。sole_tenant_node_type文字列 省略可。SAP HANA デプロイ用に単一テナントノードのプロビジョニングを行う場合は、対応するノード テンプレートに設定するノードタイプを指定します。
この引数は
sap_hana_haバージョン1.3.704310921以降で使用できます。network文字列 VIP を管理するロードバランサを作成するネットワークの名前を指定します。 共有 VPC ネットワークを使用している場合は、ホスト プロジェクトの ID をネットワーク名の親ディレクトリとして追加する必要があります。例:
HOST_PROJECT_ID/NETWORK_NAMEsubnetwork文字列 前の手順で作成したサブネットワークの名前を指定します。共有 VPC にデプロイする場合は、この値を SHARED_VPC_PROJECT_ID/SUBNETWORKとして指定します。例:myproject/network1linux_image文字列 SAP システムをデプロイする Linux オペレーティング システム イメージの名前を指定します。たとえば、 sles-15-sp5-sapのようにします。使用可能なオペレーティング システム イメージのリストについては、 Google Cloud コンソールの [イメージ] ページをご覧ください。linux_image_project文字列 引数 linux_imageに指定したイメージを含む Google Cloud プロジェクトを指定します。このプロジェクトは独自のプロジェクトか、 Google Cloud イメージ プロジェクトです。Compute Engine イメージの場合は、suse-sap-cloudを指定します。ご利用のオペレーティング システムのイメージ プロジェクトを確認するには、オペレーティング システムの詳細をご覧ください。primary_instance_name文字列 プライマリ SAP HANA システムの VM インスタンスの名前を指定します。名前には、小文字、数字、ハイフンを使用できます。 primary_zone文字列 プライマリ SAP HANA システムがデプロイされているゾーンを指定します。プライマリ ゾーンとセカンダリ ゾーンは同じリージョンにする必要があります。例: us-east1-csecondary_instance_name文字列 セカンダリ SAP HANA システムの VM インスタンスの名前を指定します。名前には、小文字、数字、ハイフンを使用できます。 secondary_zone文字列 セカンダリ SAP HANA システムがデプロイされているゾーンを指定します。プライマリ ゾーンとセカンダリ ゾーンは同じリージョンにする必要があります。例: us-east1-bmajority_maker_instance_name文字列 マジョリティ メーカーとして機能する Compute Engine VM インスタンスの名前を指定します。
この引数は
sap_hana_haモジュール バージョン202307270727以降で使用できます。majority_maker_instance_type文字列 マジョリティ メーカー インスタンスに使用する Compute Engine 仮想マシン(VM)のタイプを指定します。例: n1-highmem-32カスタム VM タイプを使用する場合は、必要な数に最も近く、かつ必要数以上の vCPU 数を持つ事前定義された VM タイプを指定します。デプロイが完了したら、vCPU 数とメモリ量を変更してください。
この引数は
sap_hana_haモジュール バージョン202307270727以降で使用できます。majority_maker_zone文字列 マジョリティ メーカー VM インスタンスがデプロイされているゾーンを指定します。このゾーンは、プライマリ ゾーンおよびセカンダリ ゾーンと同じリージョンに存在する必要があります。例: us-east1-dGoogle Cloud では、マジョリティ メーカー VM インスタンスは、プライマリおよびセカンダリ SAP HANA システムとは異なるゾーンにデプロイすることをおすすめします。
この引数は
sap_hana_haモジュール バージョン202307270727以降で使用できます。sap_hana_deployment_bucket文字列 デプロイした VM に SAP HANA を自動的にインストールするには、SAP HANA インストール ファイルを含む Cloud Storage バケットのパスを指定します。パスには gs://を含めないでください。バケット名とフォルダ名のみを含めます。たとえば、my-bucket-name/my-folderのようにします。Cloud Storage バケットは、
project_id引数に指定した Google Cloud プロジェクト内に存在する必要があります。sap_hana_scaleout_nodes整数 スケールアウト システムで必要なワーカーホストの数を指定します。スケールアウト システムをデプロイするには、少なくとも 1 つのワーカーホストが必要です。 Terraform は、プライマリ SAP HANA インスタンスに加えてワーカーホストも作成します。たとえば、
3を指定した場合は、4 つの SAP HANA インスタンスが、プライマリ ゾーンとセカンダリ ゾーンの両方のスケールアウト システムにデプロイされます。primary_sap_hana_shared_nfs文字列 省略可。NFS ソリューションを使用して、スケールアウト HA デプロイのプライマリ ノードのワーカーホストと
/hana/sharedボリュームを共有するには、NFS ソリューションのマウント ポイントを指定します。たとえば、10.151.90.120:/hana_shared_nfsのようにします。詳細については、マルチホスト スケールアウト デプロイ用のファイル共有ソリューションをご覧ください。
この引数は
sap_hana_haモジュール バージョン1.3.730053050以降で使用できます。secondary_sap_hana_shared_nfs文字列 省略可。NFS ソリューションを使用して、スケールアウト HA デプロイのセカンダリ ノードのワーカーホストと
/hana/sharedボリュームを共有するには、NFS ソリューションのマウント ポイントを指定します。たとえば、10.151.90.110:/hana_shared_nfsのようにします。詳細については、マルチホスト スケールアウト デプロイ用のファイル共有ソリューションをご覧ください。
この引数は
sap_hana_haモジュール バージョン1.3.730053050以降で使用できます。primary_sap_hana_backup_nfs文字列 省略可。NFS ソリューションを使用して、スケールアウト HA デプロイのプライマリ ノードのワーカーホストと
/hanabackupボリュームを共有するには、NFS ソリューションのマウント ポイントを指定します。たとえば、10.151.90.130:/hana_backup_nfsのようにします。詳細については、マルチホスト スケールアウト デプロイ用のファイル共有ソリューションをご覧ください。
この引数は
sap_hana_haモジュール バージョン1.3.730053050以降で使用できます。secondary_sap_hana_backup_nfs文字列 省略可。NFS ソリューションを使用して、スケールアウト HA デプロイのセカンダリ ノードのワーカーホストと
/hanabackupボリュームを共有するには、NFS ソリューションのマウント ポイントを指定します。たとえば、10.151.90.140:/hana_backup_nfsのようにします。詳細については、マルチホスト スケールアウト デプロイ用のファイル共有ソリューションをご覧ください。
この引数は
sap_hana_haモジュール バージョン1.3.730053050以降で使用できます。sap_hana_sid文字列 デプロイされた VM に SAP HANA を自動的にインストールするには、SAP HANA システム ID を指定します。ID は英数字 3 文字で、最初の文字はアルファベットにする必要があります。文字は大文字のみ使用できます。例: ED1sap_hana_instance_number整数 省略可。SAP HANA システムのインスタンス番号(0~99)を指定します。デフォルトは 0です。sap_hana_sidadm_password文字列 デプロイした VM に SAP HANA を自動的にインストールするには、デプロイ時に使用するインストール スクリプトで SIDadmの一時パスワードを指定します。パスワードは 8 文字以上で設定し、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含める必要があります。パスワードを書式なしテキストとして指定する代わりに、シークレットを使用することをおすすめします。詳細については、パスワード管理をご覧ください。
sap_hana_sidadm_password_secret文字列 省略可。Secret Manager を使用して SIDadmパスワードを保存している場合は、このパスワードに対応するシークレットの名前を指定します。Secret Manager では、Secret 値(パスワード)は 8 文字以上で、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含めるようにします。
詳細については、パスワード管理をご覧ください。
sap_hana_system_password文字列 デプロイした VM に SAP HANA を自動的にインストールするには、デプロイ時に使用するインストール スクリプトで一時的なデータベース スーパーユーザーのパスワードを指定します。パスワードは 8 文字以上で設定し、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含める必要があります。 パスワードを書式なしテキストとして指定する代わりに、シークレットを使用することをおすすめします。詳細については、パスワード管理をご覧ください。
sap_hana_system_password_secret文字列 省略可。Secret Manager を使用してデータベースのスーパーユーザーのパスワードを保存している場合は、このパスワードに対応するシークレットの名前を指定します。 Secret Manager では、Secret 値(パスワード)は 8 文字以上で、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含めるようにします。
詳細については、パスワード管理をご覧ください。
sap_hana_double_volume_sizeブール値 省略可。HANA のボリューム サイズを 2 倍にするには、 trueを指定します。この引数は、複数の SAP HANA インスタンスまたは障害復旧 SAP HANA インスタンスを同じ VM にデプロイしたい場合に便利です。デフォルトでは、SAP の認証とサポート要件を満たしつつ、ボリューム サイズが VM のサイズに必要な最小サイズとして自動的に計算されます。デフォルト値はfalseです。sap_hana_backup_size整数 省略可。 /hanabackupボリュームのサイズを GB 単位で指定します。この引数を指定しない場合、または0に設定した場合、インストール スクリプトは、合計メモリの 2 倍の HANA バックアップ ボリュームを持つ Compute Engine インスタンスをプロビジョニングします。sap_hana_sidadm_uid整数 省略可。SID_LC adm ユーザー ID のデフォルト値をオーバーライドする値を指定します。デフォルト値は 900です。SAP ランドスケープ内での整合性を保つために、別の値に変更できます。sap_hana_sapsys_gid整数 省略可。 sapsysのデフォルトのグループ ID をオーバーライドします。デフォルト値は79です。sap_vip文字列 省略可。VIP に使用する IP アドレスを指定します。IP アドレスは、サブネットワークに割り当てられている IP アドレスの範囲内でなければなりません。この IP アドレスは、Terraform 構成ファイルで予約されます。
sap_hana_haモジュールのバージョン1.3.730053050以降、sap_vip引数は省略可能です。指定しない場合、Terraform はsubnetwork引数に指定されたサブネットから使用可能な IP アドレスを自動的に割り当てます。primary_instance_group_name文字列 省略可。プライマリ ノードの非マネージド インスタンス グループの名前を指定します。デフォルト名は ig-PRIMARY_INSTANCE_NAMEです。secondary_instance_group_name文字列 省略可。セカンダリ ノードの非マネージド インスタンス グループの名前を指定します。デフォルト名は ig-SECONDARY_INSTANCE_NAMEです。loadbalancer_name文字列 省略可。内部パススルー ネットワーク ロードバランサの名前を指定します。デフォルト名は lb-SAP_HANA_SID-ilbです。network_tags文字列 省略可。ファイアウォールまたはルーティングの目的で使用され、VM インスタンスに関連付けるネットワーク タグを 1 つ以上カンマ区切りで指定します。 public_ip = falseを指定していて、ネットワーク タグを指定しない場合は、インターネットへの別のアクセス手段を必ず指定してください。nic_type文字列 省略可。VM インスタンスで使用するネットワーク インターフェースを指定します。値には GVNICまたはVIRTIO_NETを指定できます。Google Virtual NIC(gVNIC)を使用するには、linux_image引数の値として gVNIC をサポートする OS イメージを指定する必要があります。OS イメージの一覧については、オペレーティング システムの詳細をご覧ください。この引数の値を指定しなかった場合は、
この引数はmachine_type引数に指定したマシンタイプに基づいて、ネットワーク インターフェースが自動的に選択されます。sap_hanaモジュール バージョン202302060649以降で使用できます。disk_type文字列 省略可。デプロイの SAP データとログボリュームにデプロイする Persistent Disk または Hyperdisk ボリュームのデフォルト タイプを指定します。 Google Cloudが提供する Terraform 構成によって実行されるデフォルトのディスク デプロイについては、Terraform によるディスク デプロイをご覧ください。 この引数の有効な値は
pd-ssd、pd-balanced、hyperdisk-extreme、hyperdisk-balanced、pd-extremeです。SAP HANA スケールアップ デプロイでは、/hana/sharedディレクトリに個別のバランス永続ディスクもデプロイされます。いくつかの高度な引数を使用して、このデフォルトのディスクタイプと関連するデフォルトのディスクサイズとデフォルトの IOPS をオーバーライドできます。詳細については、作業ディレクトリに移動してから、
terraform initコマンドを実行して、/.terraform/modules/sap_hana_ha/variables.tfファイルを確認してください。これらの引数を本番環境で使用する前に、非本番環境でテストしてください。SAP HANA ネイティブ ストレージ拡張機能(NSE)を使用する場合は、高度な引数を使用して、より大きなディスクをプロビジョニングする必要があります。
use_single_shared_data_log_diskブール値 省略可。デフォルト値は falseです。これは、SAP ボリューム(/hana/data、/hana/log、/hana/shared、/usr/sap)ごとに、個別の永続ディスクまたは Hyperdisk をデプロイするように Terraform に指示します。これらの SAP ボリュームを同じ永続ディスクまたは Hyperdisk にマウントするには、trueを指定します。enable_data_stripingブール値 省略可。この引数を使用すると、 /hana/dataボリュームを 2 つのディスクにデプロイできます。デフォルト値はfalseで、/hana/dataボリュームをホストする単一のディスクをデプロイするように Terraform に指示します。この引数は
sap_hana_haモジュール バージョン1.3.674800406以降で使用できます。include_backup_diskブール値 省略可。この引数は、SAP HANA スケールアップ デプロイに適用されます。デフォルト値は trueです。これは、/hanabackupディレクトリをホストする別のディスクをデプロイするように Terraform に指示します。ディスクタイプは、
backup_disk_type引数によって決まります。このディスクのサイズは、sap_hana_backup_size引数によって決まります。include_backup_diskの値をfalseに設定すると、/hanabackupディレクトリ用のディスクはデプロイされません。enable_fast_restartブール値 省略可。この引数により、デプロイで SAP HANA 高速再起動オプションが有効かどうかが決まります。デフォルト値は trueです。 Google Cloud では、SAP HANA 高速再起動オプションを有効にすることを強くおすすめします。この引数は
sap_hana_haモジュール バージョン202309280828以降で使用できます。public_ipブール値 省略可。パブリック IP アドレスを VM インスタンスに追加するかどうかを指定します。デフォルト値は trueです。service_account文字列 省略可。ホスト VM とホスト VM で実行されるプログラムで使用されるユーザー管理のサービス アカウントのメールアドレスを指定します。例: svc-acct-name@project-id.この引数に値を指定しない場合、または省略した場合、インストール スクリプトは、Compute Engine のデフォルトのサービス アカウントを使用します。詳細については、 Google Cloud上での SAP プログラム向け Identity and Access Management をご覧ください。
sap_deployment_debugブール値 省略可。Cloud カスタマーケアでデプロイのデバッグを有効にするよう求められた場合にのみ、 trueを指定します。これにより、デプロイの際に詳細なログが生成されます。デフォルト値はfalseです。primary_reservation_name文字列 省略可。HA クラスタのプライマリ SAP HANA インスタンスをホストする VM インスタンスをプロビジョニングするために、特定の Compute Engine VM 予約を使用するには、予約の名前を指定します。 デフォルトでは、インストール スクリプトは、次の条件に基づいて使用可能な Compute Engine 予約を選択します。 予約を使用するときに名前を指定するのか、インストール スクリプトで自動的に選択するかに関係なく、予約は次のように設定する必要があります。
-
specificReservationRequiredオプションはtrueに設定されているか、 Google Cloud コンソールで [特定の予約を選択する] オプションが選択されています。 -
Compute Engine のマシンタイプによっては、マシンタイプの SAP 認定に含まれていない CPU プラットフォームに対応しているものもあります。対象となる予約が次のいずれかのマシンタイプの場合、予約には指示された最小の CPU プラットフォームを指定する必要があります。
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Google Cloud での使用が SAP に認定されている他のすべてのマシンタイプの最小 CPU プラットフォームは、SAP の最小 CPU 要件に準拠しています。
secondary_reservation_name文字列 省略可。HA クラスタのセカンダリ SAP HANA インスタンスをホストする VM インスタンスをプロビジョニングするために、特定の Compute Engine VM 予約を使用するには、予約の名前を指定します。 デフォルトでは、インストール スクリプトは、次の条件に基づいて使用可能な Compute Engine 予約を選択します。 予約を使用するときに名前を指定するのか、インストール スクリプトで自動的に選択するかに関係なく、予約は次のように設定する必要があります。
-
specificReservationRequiredオプションはtrueに設定されているか、 Google Cloud コンソールで [特定の予約を選択する] オプションが選択されています。 -
Compute Engine のマシンタイプによっては、マシンタイプの SAP 認定に含まれていない CPU プラットフォームに対応しているものもあります。対象となる予約が次のいずれかのマシンタイプの場合、予約には指示された最小の CPU プラットフォームを指定する必要があります。
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Google Cloud での使用が SAP に認定されている他のすべてのマシンタイプの最小 CPU プラットフォームは、SAP の最小 CPU 要件に準拠しています。
primary_static_ip文字列 省略可。高可用性クラスタ内のプライマリ VM インスタンスに有効な静的 IP アドレスを指定します。IP アドレスを指定しない場合は、VM インスタンスに対して IP アドレスが自動的に生成されます。例: 128.10.10.10この引数は
sap_hana_haモジュール バージョン202306120959以降で使用できます。secondary_static_ip文字列 省略可。高可用性クラスタ内のセカンダリ VM インスタンスに有効な静的 IP アドレスを指定します。IP アドレスを指定しない場合は、VM インスタンスに対して IP アドレスが自動的に生成されます。例: 128.11.11.11この引数は
sap_hana_haモジュール バージョン202306120959以降で使用できます。primary_worker_static_ipsリスト(文字列) 省略可。SAP HANA スケールアウト HA システムのプライマリ インスタンス内のワーカー インスタンスに対して、有効な静的 IP アドレスの配列を指定します。この引数の値を指定しない場合、ワーカー VM インスタンスごとに IP アドレスが自動的に生成されます。例: [ "1.0.0.1", "2.3.3.4" ]静的 IP アドレスは、インスタンスの作成順に割り当てられます。たとえば、3 つのワーカー インスタンスをデプロイするものの、引数
primary_worker_static_ipsに 2 つの IP アドレスのみを指定する場合、これらの IP アドレスは、Terraform の構成がデプロイされる最初の 2 つの VM インスタンスに割り当てられます。3 つ目のワーカー VM インスタンスでは、IP アドレスが自動的に生成されます。この引数は
sap_hana_haモジュール バージョン202307270727以降で使用できます。secondary_worker_static_ipsリスト(文字列) 省略可。SAP HANA スケールアウト HA システムのセカンダリ インスタンス内のワーカー インスタンスに対して、有効な静的 IP アドレスの配列を指定します。この引数の値を指定しない場合、ワーカー VM インスタンスごとに IP アドレスが自動的に生成されます。例: [ "1.0.0.2", "2.3.3.5" ]静的 IP アドレスは、インスタンスの作成順に割り当てられます。たとえば、3 つのワーカー インスタンスをデプロイするものの、引数
secondary_worker_static_ipsに 2 つの IP アドレスのみを指定する場合、これらの IP アドレスは、Terraform の構成がデプロイされる最初の 2 つの VM インスタンスに割り当てられます。3 つ目のワーカー VM インスタンスでは、IP アドレスが自動的に生成されます。この引数は
sap_hana_haモジュール バージョン202307270727以降で使用できます。can_ip_forwardブール値 送信元 IP または宛先 IP が一致しないパケットの送受信を許可するかどうかを指定します。 許可すると、VM がルーターのように動作することが可能になります。 デフォルト値は
trueです。デプロイされた VM の仮想 IP を Google の内部ロードバランサのみを使用して 管理する場合は、値を
falseに設定します。内部ロードバランサは、高可用性テンプレートの一部として自動的にデプロイされます。以下は、SLES 上の SAP HANA スケールアウト システムの高可用性クラスタを定義する、完成した構成ファイルの例です。このクラスタは、内部パススルー ネットワーク ロードバランサを使用して VIP を管理します。
Terraform は構成ファイルで定義されている Google Cloud リソースをデプロイします。その後、スクリプトが処理を引き継ぎ、オペレーティング システムの構成、SAP HANA のインストール、レプリケーションの構成、Linux HA クラスタの構成を行います。
わかりやすくするために、次の構成例ではコメントを省略しています。
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # ... project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp4-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-b" majority_maker_instance_name = "example-ha-mj" majority_maker_instance_type = "n2-highmem-32" majority_maker_zone = "us-central1-c" sap_hana_scaleout_nodes = 2 primary_sap_hana_shared_nfs = "10.74.146.58:/hana_shared_nfs" secondary_sap_hana_shared_nfs = "10.74.146.68:/hana_shared_nfs" primary_sap_hana_backup_nfs = "10.188.249.180:/hana_backup_nfs" secondary_sap_hana_backup_nfs = "10.188.249.190:/hana_backup_nfs" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password_secret = "hana_sid_adm_pwd" sap_hana_system_password_secret = "hana_sys_pwd" # ... sap_vip = "10.0.0.100" primary_instance_group_name = "ig-example-ha-vm1" secondary_instance_group_name = "ig-example-ha-vm2" loadbalancer_name = "lb-ha1" # ... network_tags = \["hana-ha-ntwk-tag"\] service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" primary_worker_static_ips = \["10.0.0.3", "10.0.0.4"\] secondary_worker_static_ips = \["10.0.0.5", "10.0.0.6"\] enable_fast_restart = true # ... }-
現在の作業ディレクトリを初期化し、 Google Cloud用の Terraform プロバイダ プラグインとモジュール ファイルをダウンロードします。
terraform init
terraform initコマンドで、他の Terraform コマンドの作業ディレクトリを準備します。作業ディレクトリのプロバイダ プラグインと構成ファイルを強制的に更新するには、
--upgradeフラグを指定します。--upgradeフラグが省略されていて、作業ディレクトリに変更を加えていない場合、sourceURL でlatestが指定されている場合でも、Terraform はローカル キャッシュに保存されたコピーを使用します。terraform init --upgrade
必要に応じて、Terraform 実行プランを作成します。
terraform plan
terraform planコマンドによって、現在の構成で必要な変更が表示されます。この手順をスキップすると、terraform applyコマンドは自動的に新しいプランを作成し、それを承認するように求めます。実行計画を適用します。
terraform apply
アクションを承認するように求められたら、「
yes」と入力します。terraform applyコマンドは、 Google Cloud インフラストラクチャをセットアップした後、HA クラスタを構成し、Terraform 構成ファイルで定義された引数に従って SAP HANA をインストールするスクリプトに制御を渡します。Terraform によって制御が行われる間、Cloud Shell にステータス メッセージが書き込まれます。スクリプトが呼び出されると、ログを確認するで説明されているように、ステータス メッセージが Logging に書き込まれ、 Google Cloud コンソールで表示できるようになります。
HANA HA システムのデプロイを確認する
SAP HANA HA クラスタの検証では、いくつかの手順を行う必要があります。
- Logging を確認する
- VM と SAP HANA の構成を確認する
- クラスタの構成を確認する
- ロードバランサとインスタンス グループの健全性を確認する
- SAP HANA Studio を使用して SAP HANA システムを確認する
- フェイルオーバー テストを実行する
ログを調べる
Google Cloud コンソールで Cloud Logging を開いて、インストールの進行状況をモニタリングし、エラーがないか確認します。
ログをフィルタします。
ログ エクスプローラ
[ログ エクスプローラ] ページで、[クエリ] ペインに移動します。
[リソース] プルダウン メニューから [グローバル] を選択し、[追加] をクリックします。
[グローバル] オプションが表示されない場合は、クエリエディタに次のクエリを入力します。
resource.type="global" "Deployment"[クエリを実行] をクリックします。
以前のログビューア
- [以前のログビューア] ページの基本的なセレクタ メニューから、ロギング リソースとして [グローバル] を選択します。
フィルタされたログを分析します。
"--- Finished"が表示されている場合、デプロイメントは完了しています。次の手順に進んでください。割り当てエラーが発生した場合:
[IAM と管理] の [割り当て] ページで、SAP HANA プランニング ガイドに記載されている SAP HANA の要件を満たしていない割り当てを増やします。
Cloud Shell を開きます。
作業ディレクトリに移動してデプロイを削除し、失敗したインストールから VM と永続ディスクをクリーンアップします。
terraform destroy
アクションの承認を求められたら、「
yes」と入力します。デプロイを再実行します。
VM と SAP HANA の構成を確認する
SAP HANA システムが正常にデプロイされたら、SSH を使用して VM に接続します。Compute Engine の [VM インスタンス] ページで、各 VM インスタンスの [SSH] ボタンをクリックします。または、任意の SSH メソッドを使用することもできます。

root ユーザーに切り替えます。
sudo su -
コマンド プロンプトで次のように入力します。
df -h
出力は次のようになります。出力に
/hanaディレクトリ(例:/hana/data)が含まれていることを確認します。example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 48M 189G 1% /dev/shm tmpfs 51G 26M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sda3 30G 6.2G 24G 21% / /dev/sda2 20M 3.0M 17M 15% /boot/efi /dev/mapper/vg_hana_shared-shared 256G 41G 215G 16% /hana/shared /dev/mapper/vg_hana_data-data 308G 12G 297G 4% /hana/data /dev/mapper/vg_hana_log-log 128G 8.8G 120G 7% /hana/log /dev/mapper/vg_hana_usrsap-usrsap 32G 265M 32G 1% /usr/sap /dev/mapper/vg_hanabackup-backup 512G 8.5G 504G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/174 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1000
オペレーティング システムに固有の status コマンドを入力し、新しいクラスタのステータスを確認します。
crm status次の例のような出力が表示されます。この例では、プライマリとセカンダリの SAP HANA システムの VM インスタンスと、マジョリティ メーカー インスタンスが起動します。
example-ha-vm1は、アクティブなプライマリ インスタンスです。example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36) - partition with quorum * Last updated: Sat Jul 15 19:42:56 2023 * Last change: Sat Jul 15 19:42:21 2023 by root via crm_attribute on example-ha-vm1 * 7 nodes configured * 23 resource instances configured Node List: * Online: \[ example-ha-mj example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-mj * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * STONITH-example-ha-mj (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-vm1w1 (stonith:fence_gce): Started example-ha-vm1w2 * STONITH-example-ha-vm2w1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm1w2 (stonith:fence_gce): Started example-ha-vm2w1 * STONITH-example-ha-vm2w2 (stonith:fence_gce): Started example-ha-mj * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 \[rsc_SAPHanaTopology_HA1_HDB00\]: * Started: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \] * Clone Set: msl_SAPHana_HA1_HDB00 \[rsc_SAPHana_HA1_HDB00\] (promotable): * Masters: \[ example-ha-vm1 \] * Slaves: \[ example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \]次のコマンドの SID_LC を
sap_hana_ha.tfファイルで指定したsap_hana_sid値に置き換えて、SAP 管理ユーザーに切り替えます。SID_LC の値は小文字にする必要があります。su - SID_LCadm次のコマンドを入力して、
hdbnameserver、hdbindexserverなどの SAP HANA サービスがインスタンス上で実行されていることを確認します。HDB info
クラスタの構成を確認する
クラスタが正常にデプロイされたら、クラスタのパラメータ設定を確認する必要があります。クラスタ ソフトウェアに表示される設定とクラスタ構成ファイルのパラメータ設定の両方を確認します。設定例を、以下の例で使用されている設定と比較してください。これは、このガイドで使用されている自動化スクリプトによって作成されたものです。
クラスタ リソース構成を表示します。
crm config show
このガイドで使用する自動化スクリプトでは、次の例に示すリソース構成を作成します。
node 1: example-ha-vm1 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 2: example-ha-vm2 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 node 3: example-ha-mj node 4: example-ha-vm1w1 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 5: example-ha-vm2w1 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 node 6: example-ha-vm1w2 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 7: example-ha-vm2w2 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 primitive STONITH-example-ha-mj stonith:fence_gce \ params port=example-ha-mj zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1 stonith:fence_gce \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1w1 stonith:fence_gce \ params port=example-ha-vm1w1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1w2 stonith:fence_gce \ params port=example-ha-vm1w2 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2 stonith:fence_gce \ params port=example-ha-vm2 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2w1 stonith:fence_gce \ params port=example-ha-vm2w1 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2w2 stonith:fence_gce \ params port=example-ha-vm2w2 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 \ op start timeout=20s interval=0s \ op stop timeout=20s interval=0s primitive rsc_vip_int-primary IPaddr2 \ params ip=10.1.0.23 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s \ op start timeout=20s interval=0s \ op stop timeout=20s interval=0s group g-primary rsc_vip_int-primary rsc_vip_hc-primary \ meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 master-max=1 interleave=true target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm1w1 STONITH-example-ha-vm1w1 -inf: example-ha-vm1w1 location LOC_STONITH_example-ha-vm1w2 STONITH-example-ha-vm1w2 -inf: example-ha-vm1w2 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 location LOC_STONITH_example-ha-vm2w1 STONITH-example-ha-vm2w1 -inf: example-ha-vm2w1 location LOC_STONITH_example-ha-vm2w2 STONITH-example-ha-vm2w2 -inf: example-ha-vm2w2 location SAPHanaCon_not_on_mm msl_SAPHana_HA1_HDB00 -inf: example-ha-mj location SAPHanaTop_not_on_mm cln_SAPHanaTopology_HA1_HDB00 -inf: example-ha-mj colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property SAPHanaSR: \ hana_ha1_glob_mts=true \ hana_ha1_site_srHook_example-ha-vm2=SOK \ hana_ha1_site_lss_example-ha-vm1=4 \ hana_ha1_site_srr_example-ha-vm1=P \ hana_ha1_site_lss_example-ha-vm2=4 \ hana_ha1_site_srr_example-ha-vm2=S \ hana_ha1_glob_srmode=syncmem \ hana_ha1_glob_upd=ok \ hana_ha1_site_mns_example-ha-vm1=example-ha-vm1 \ hana_ha1_site_mns_example-ha-vm2=example-ha-vm2 \ hana_ha1_site_lpt_example-ha-vm2=30 \ hana_ha1_site_srHook_example-ha-vm1=PRIM \ hana_ha1_site_lpt_example-ha-vm1=1689450463 \ hana_ha1_glob_sync_state=SOK \ hana_ha1_glob_prim=example-ha-vm1 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true \ concurrent-fencing=true rsc_defaults build-resource-defaults: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600クラスタ構成ファイル
corosync.confを表示します。cat /etc/corosync/corosync.conf
このガイドで使用する自動化スクリプトは、次の例のように
corosync.confファイルでパラメータ設定を指定します。totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: "10.1.0.7" mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } quorum { provider: corosync_votequorum } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } node { ring0_addr: example-ha-mj nodeid: 3 } node { ring0_addr: example-ha-vm1w1 nodeid: 4 } node { ring0_addr: example-ha-vm2w1 nodeid: 5 } node { ring0_addr: example-ha-vm1w2 nodeid: 6 } node { ring0_addr: example-ha-vm2w2 nodeid: 7 } }
ロードバランサとインスタンス グループの健全性を確認する
ロードバランサとヘルスチェックが正しくセットアップされていることを確認するには、 Google Cloud コンソールでロードバランサとインスタンス グループを確認します。
Google Cloud コンソールで、[ロード バランシング] ページを開きます。
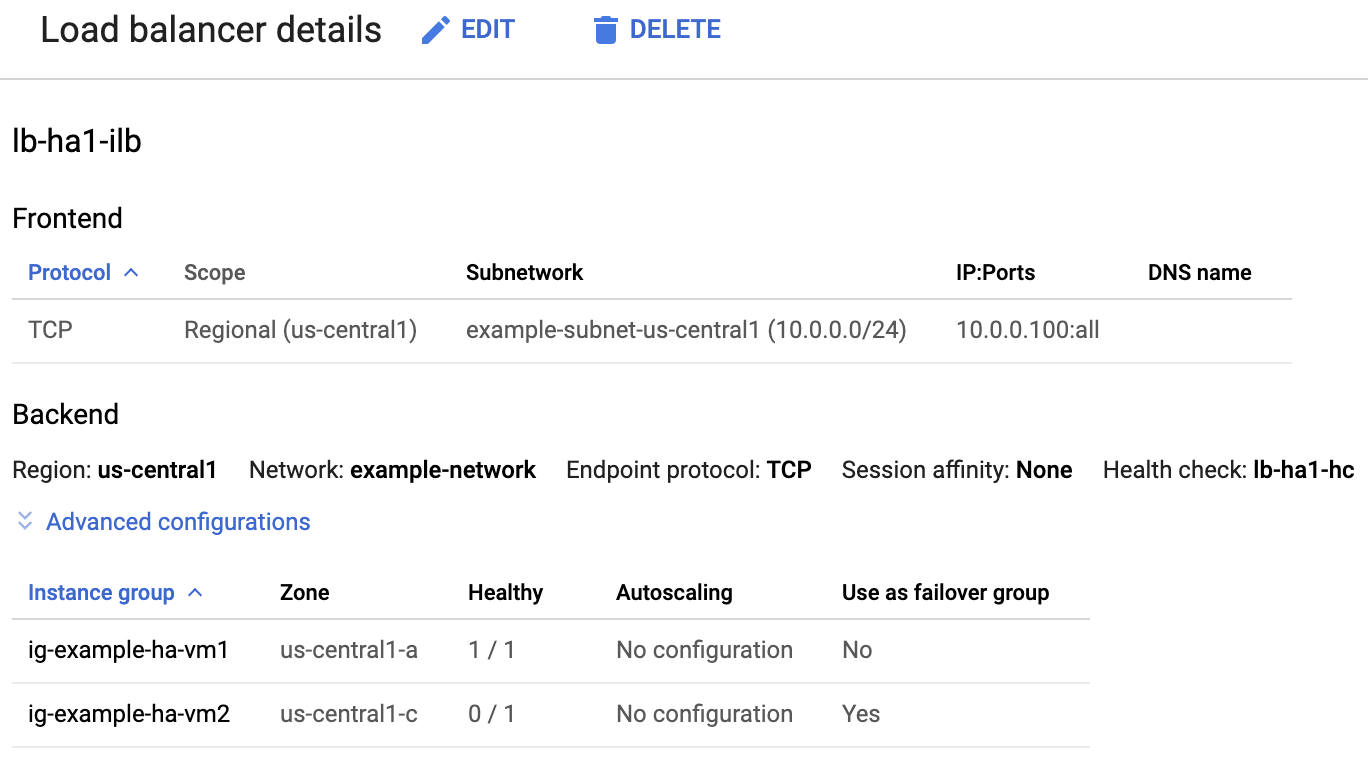
ロードバランサのリストで、HA クラスタ用のロードバランサが作成されたことを確認します。
[ロードバランサの詳細] ページの [バックエンド] セクションにある [正常] 列で、1 つのインスタンス グループに [1/1] が表示され、別のインスタンス グループに [0/1] が表示されていることを確認します。フェイルオーバー後、正常インジケーター [1/1] が新しいアクティブなインスタンス グループに切り替わります。
SAP HANA Studio を使用して SAP HANA システムを確認する
SAP HANA Cockpit または SAP HANA Studio を使用すると、高可用性クラスタで SAP HANA システムをモニタリングし、管理できます。
SAP HANA Studio を使用して HANA システムに接続します。接続を定義するときに、次の値を指定します。
- [Specify System] パネルで、ホスト名としてフローティング IP アドレスを指定します。
- [Connection Properties] パネルのデータベース ユーザー認証で、データベースのスーパーユーザー名と、
sap_hana_ha.tfファイルのsap_hana_system_password引数で指定したパスワードを入力します。
SAP から提供されている SAP HANA Studio のインストール情報については、SAP HANA Studio のインストールおよび更新ガイドをご覧ください。
SAP HANA Studio が HANA HA システムに接続したら、ウィンドウ左側のナビゲーション パネルでシステム名をダブルクリックして、システム概要を表示します。
[概要] タブの [全般情報] で、以下の状態になっていることを確認します。
- [オペレーション ステータス] に
All services startedが表示されている。 - [システム レプリケーション ステータス] に
All services are active and in syncが表示されている。
![SAP HANA Studio の [Overview] タブのスクリーンショット](https://cloud.google.com/static/solutions/sap/docs/images/ha-hana-hdbstudio-system-info.png?authuser=9&hl=ja)
- [オペレーション ステータス] に
[全般情報] の [システム レプリケーション ステータス] をクリックして、レプリケーション モードを確認します。同期レプリケーションの場合は、[システム レプリケーション] タブの [REPLICATION_MODE] 列に
SYNCMEMが表示されます。![SAP HANA Studio の [System Replication Status] タブのスクリーンショット](https://cloud.google.com/static/solutions/sap/docs/images/ha-hana-hdbstudio-replication-status.png?authuser=9&hl=ja)
クリーンアップしてデプロイを再試行する
前のセクションのデプロイ検証ステップのいずれかでインストールが正常に完了しなかった場合は、デプロイを元に戻し、次の手順を行ってデプロイを再試行する必要があります。
エラーが発生した場合は、同じ理由でデプロイが再び失敗することがないようにエラーを解決してください。ログの確認または割り当て関連のエラーの解決について詳しくは、ログを調べるをご覧ください。
Cloud Shell を開くか、Google Cloud CLI をローカル ワークステーションにインストールしている場合はターミナルを開きます。
このデプロイに使用した Terraform 構成ファイルがあるディレクトリに移動します。
次のコマンドを実行して、デプロイメントに含まれるすべてのリソースを削除します。
terraform destroy
アクションの承認を求められたら、「
yes」と入力します。このガイドで前述したように、デプロイを再試行します。
フェイルオーバー テストを行う
SAP HANA システムが正常にデプロイされたことを確認したら、フェイルオーバー機能をテストする必要があります。
次の手順では、ip link set eth0 down コマンドを使用してネットワーク インターフェースをオフラインにします。このコマンドは、フェイルオーバーとフェンシングの両方を検証します。
フェイルオーバー テストを行うには、次の手順を行います。
プライマリ SAP HANA インスタンスで、SSH を使用してマスターノードに接続します。Compute Engine の [VM インスタンス] ページから、各 VM インスタンスの SSH ボタンをクリックして接続するか、任意の SSH メソッドを使用できます。
コマンド プロンプトで、次のコマンドを入力します。
ip link set eth0 down
ip link set eth0 downコマンドは、プライマリ SAP HANA インスタンスとの通信を切断してフェイルオーバーをトリガーします。SSH を使用してクラスタ内の他のノードに接続し、root ユーザーに切り替えます。
次のコマンドを実行して、セカンダリ インスタンスを格納する VM でプライマリ SAP HANA インスタンスがアクティブになったことを確認します。
crm statusクラスタで自動再起動が有効になっているため、停止したインスタンスが再起動し、セカンダリ インスタンスのロールを引き継ぎます。次の例は、各 SAP HANA インスタンスのロールが切り替わったことを示しています。
example-ha-vm2:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36) - partition with quorum * Last updated: Mon Jul 17 19:47:11 2023 * Last change: Mon Jul 17 19:46:56 2023 by root via crm_attribute on example-ha-vm2 * 7 nodes configured * 23 resource instances configured Node List: * Online: \[ example-ha-mj example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-mj * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-mj (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-vm1w1 (stonith:fence_gce): Started example-ha-vm1w2 * STONITH-example-ha-vm2w1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm1w2 (stonith:fence_gce): Started example-ha-vm2w1 * STONITH-example-ha-vm2w2 (stonith:fence_gce): Started example-ha-mj * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 \[rsc_SAPHanaTopology_HA1_HDB00\]: * Started: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \] * Clone Set: msl_SAPHana_HA1_HDB00 \[rsc_SAPHana_HA1_HDB00\] (promotable): * Masters: \[ example-ha-vm2 \] * Slaves: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \]Google Cloud コンソールの [ロードバランサの詳細] ページで、新しいアクティブなプライマリ インスタンスの [正常] 列に「1/1」が表示されていることを確認します。必要に応じてページを更新します。
たとえば、次の画像をご覧ください。
![ロードバランサの詳細ページ。ig-example-ha-vm2 インスタンスの [正常] 列に「1/1」が表示されています。](https://cloud.google.com/static/solutions/sap/docs/images/hana-ha-ig-failover.png?authuser=9&hl=ja)
SAP HANA Studio で、ナビゲーション パネルのシステム エントリをダブルクリックしてシステム情報を更新し、システムに接続していることを確認します。
[System Replication Status] リンクをクリックして、プライマリ ホストとセカンダリ ホストでホストが切り替わり、アクティブになっていることを確認します。
![SAP HANA Studio の [System Replication Status] タブのスクリーンショット](https://cloud.google.com/static/solutions/sap/docs/images/ha-hana-hdbstudio-replication-status-failover.png?authuser=9&hl=ja)
Google Cloudの SAP 用エージェントのインストールを検証する
インフラストラクチャがデプロイされ、SAP HANA システムがインストールされたら、 Google Cloudの SAP 用エージェントが正常に機能していることを確認します。
Google Cloudの SAP 用エージェントが実行されていることを確認する
エージェントの動作確認の手順は次のとおりです。
Compute Engine インスタンスと SSH 接続を確立します。
次のコマンドを実行します。
systemctl status google-cloud-sap-agent
エージェントが正常に機能している場合、出力には
active (running)が含まれます。次に例を示します。google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
エージェントが実行されていない場合は、エージェントを再起動します。
SAP Host Agent が指標を受信していることを確認する
Google Cloudの SAP 用エージェントによってインフラストラクチャの指標が収集され、SAP Host Agent に正しく送信されていることを確認するには、次の操作を行います。
- SAP システムで、トランザクションとして「
ST06」を入力します。 概要ウィンドウで可用性と以下のフィールドの内容を確認し、SAP と Google モニタリング インフラストラクチャのエンドツーエンドの設定が正しいか調べます。
- クラウド プロバイダ:
Google Cloud Platform - Enhanced Monitoring Access:
TRUE - Enhanced Monitoring Details:
ACTIVE
- クラウド プロバイダ:
SAP HANA のモニタリングを設定する
必要に応じて、Google Cloudの SAP 用エージェントを使用して SAP HANA インスタンスをモニタリングできます。バージョン 2.0 以降では、SAP HANA モニタリング指標を収集して Cloud Monitoring に送信するようにエージェントを構成できます。Cloud Monitoring を使用すると、これらの指標を可視化するダッシュボードを作成し、指標のしきい値などに基づくアラートを設定できます。
Google Cloudの SAP 用エージェントを使用した SAP HANA モニタリング指標の収集の詳細については、SAP HANA モニタリング指標の収集をご覧ください。
SAP HANA に接続する
この手順では SAP HANA に外部 IP を使用しないため、SAP HANA インスタンスに接続できるのは、SSH を使用して踏み台インスタンスを経由するか、SAP HANA Studio を使用して Windows サーバーを経由する場合だけになるのでご注意ください。
踏み台インスタンスを介して SAP HANA に接続するには、踏み台インスタンスに接続してから、任意の SSH クライアントを使用して SAP HANA インスタンスに接続します。
SAP HANA Studio を経由して SAP HANA データベースに接続するには、リモート デスクトップ クライアントを使用して、Windows Server インスタンスに接続します。接続後、手動で SAP HANA Studio をインストールし、SAP HANA データベースにアクセスします。
HANA アクティブ / アクティブ構成(読み取り可能)を構成する
SAP HANA 2.0 SPS1 以降では、Pacemaker クラスタで HANA アクティブ / アクティブ(読み取り可能)を構成できます。手順については、SUSE Pacemaker クラスタで HANA アクティブ / アクティブ(読み取り可能)を構成するをご覧ください。
デプロイ後のタスクを実行する
SAP HANA インスタンスを使用する前に、次のデプロイ後の手順を実行することをおすすめします。詳細については、SAP HANA のインストールおよび更新ガイドをご覧ください。
SAP HANA システム管理者とデータベースのスーパーユーザーの仮のパスワードを変更します。
SAP HANA ソフトウェアを、最新のパッチで更新します。
SAP HANA システムが VirtIO ネットワーク インターフェースにデプロイされている場合は、TCP パラメータ
/proc/sys/net/ipv4/tcp_limit_output_bytesの値を1048576に設定することをおすすめします。この変更により、ネットワーク レイテンシに影響を与えることなく、VirtIO ネットワーク インターフェースの全体的なネットワーク スループットを改善できます。アプリケーション機能ライブラリ(AFL)またはスマートデータ アクセス(SDA)などの、追加コンポーネントがあればインストールします。
新しい SAP HANA データベースを、構成してバックアップをとります。詳細については、SAP HANA オペレーション ガイドをご覧ください。
SAP HANA ワークロードを評価する
Google Cloud上で実行される SAP HANA 高可用性ワークロードの継続的な検証チェックを自動化するには、Workload Manager を使用します。
Workload Manager を使用すると、SAP HANA 高可用性ワークロードを自動的にスキャンし、SAP、 Google Cloud、OS ベンダーのベスト プラクティスに対して評価できます。これにより、ワークロードの品質、パフォーマンス、信頼性が向上します。
Google Cloudで実行されている SAP HANA 高可用性ワークロードの評価で Workload Manager がサポートするベスト プラクティスについては、SAP 向けの Workload Manager のベスト プラクティスをご覧ください。Workload Manager を使用して評価を作成および実行する方法については、評価を作成して実行するをご覧ください。
トラブルシューティング
SLES での SAP HANA 用の高可用性構成に関する問題のトラブルシューティングについては、SAP 高可用性構成のトラブルシューティングをご覧ください。
サポートを利用する
SLES の SAP HANA 用高可用性クラスタの問題解決についてサポートを必要とされる場合は、必要な診断情報を収集し、Cloud カスタマーケアにお問い合わせください。詳細については、SLES の診断情報での高可用性クラスタをご覧ください。
次のステップ
- Persistent Disk または Hyperdisk ボリュームの代わりに Google Cloud NetApp Volumes を使用して
/hana/sharedや/hanabackupなどの SAP HANA ディレクトリをホストする必要がある場合は、SAP HANA プランニング ガイドの NetApp Volumes のデプロイ情報をご覧ください。 - VM の管理とモニタリングの詳細については、SAP HANA 運用ガイドをご覧ください。