このガイドでは、Terraform: SAP HANA スケールアップ デプロイガイドに従って Google Cloud にデプロイされた SAP HANA システムの運用手順について説明します。このガイドは、標準の SAP ドキュメントに代わるものではありません。
Google Cloudでの SAP HANA システムの管理
このセクションでは、SAP HANA システムの運用に必要な管理タスク(システムの起動、停止、クローンの作成など)の実行方法を示します。
インスタンスの起動と停止
1 つまたは複数の SAP HANA ホストをいつでも停止できます。インスタンスを停止すると、インスタンスはシャットダウンされます。シャットダウンがシャットダウン期間内に完了しない場合、インスタンスは強制的に停止されます。データの損失やファイル システムの破損を回避するには、次のいずれか、または両方を行うことをおすすめします。
インスタンスを停止する前に、インスタンスで実行されている SAP HANA を停止します。
インスタンスのシャットダウン期間を延長するには、インスタンスで正常なシャットダウンを有効にします。
インスタンスを停止または再起動する方法については、Compute Engine インスタンスを停止または再起動するをご覧ください。
VM の変更
VM のデプロイ後に、VM の種類など、VM のさまざまな属性を変更できます。変更の内容によって、SAP システムをバックアップから復元する必要がある場合や、VM の再起動のみを行う必要がある場合があります。
詳細については、SAP システムの VM 構成の変更をご覧ください。
SAP HANA のスナップショットを作成する
永続ディスクの特定の時点におけるバックアップを生成するには、スナップショットを作成します。Compute Engine は、各スナップショットの複数のコピーを複数の場所に重複して保存し、自動チェックサムを使用してデータの整合性を確保します。
スナップショットを作成するには、スナップショットの作成に記載されている Compute Engine の手順を行います。スナップショットの一貫性を確保するため、スナップショットを作成する前の準備手順(ディスク バッファをディスクにフラッシュするなど)に注意してください。
スナップショットは、次のユースケースに役立ちます。
| ユースケース | 詳細 |
|---|---|
| ソフトウェアに依存しない簡単で費用対効果の高いデータ バックアップ ソリューションを提供する。 | スナップショットを使用して、データ、ログ、バックアップ、共有ディスクをバックアップします。データセット全体の特定の時点におけるバックアップを保存するため、それらのディスクの日次バックアップのスケジュールを設定します。 最初のスナップショットを作成したら、その後のスナップショットでは増分ブロック変更のみを格納します。これは費用の削減に役立ちます。 |
| 別のストレージ タイプに移行する。 | Compute Engine には、標準(磁気)ストレージでサポートされるタイプと、ソリッド ステート ドライブ ストレージ(SSD ベースの永続ディスク)を利用するタイプがあります。コストとパフォーマンス特性はそれぞれ異なります。たとえば、バックアップ ボリュームには標準タイプを使用しますが、/hana/log ボリュームと /hana/data ボリュームには高いパフォーマンスが必要になるため、SSD ベースのタイプを使用します。別のストレージ タイプに移行するには、ボリュームのスナップショットを使用して新しいボリュームを作成し、別のストレージ タイプを選択します。 |
| SAP HANA を別のリージョンまたはゾーンに移行する。 | スナップショットを使用して、SAP HANA システムを同じリージョン内の別のゾーンか、または別のリージョンに移動します。スナップショットをGoogle Cloud 内でグローバルに使用して、別のゾーンまたはリージョンにディスクを作成できます。別のリージョンまたはゾーンに移行するには、ルートディスクを含むディスクのスナップショットを作成した後、それらのスナップショットから作成したディスクを使用して、目的のゾーンまたはリージョンに仮想マシンを作成します。 |
ディスク設定の変更
プロビジョニングした IOPS またはスループットの変更、または Hyperdisk ボリュームのサイズ増加は、4 時間に 1 回行うことができます。4 時間が経過する前にディスクを再び変更しようとすると、Cannot update provisioned throughput due to being rate limited のようなレート制限エラー メッセージが表示されます。このエラーを解決するには、前回の変更から 4 時間が経過してからディスクの変更を行ってください。
この手順は、Hyperdisk ボリュームのディスクサイズ、プロビジョニングした IOPS、スループットの調整を 4 時間待機できない緊急時にのみ使用します。
ディスク設定を変更するには、次の手順を行います。
次のいずれかのコマンドを実行して、SAP HANA インスタンスを停止します。
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
INSTANCE_NUMBERは、SAP HANA システムのインスタンス番号に置き換えます。詳細については、SAP HANA システムの起動と停止をご覧ください。
既存のディスクのスナップショットまたはイメージを作成します。
スナップショット ベースのバックアップ
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION次のように置き換えます。
SNAPSHOT_NAME: 作成するスナップショットの名前。PROJECT_NAME: Google Cloud プロジェクトの名前。SOURCE_DISK_NAME: スナップショットの作成に使用されるソースディスク。ZONE: 操作するソースディスクのゾーン。LOCATION: スナップショットのコンテンツが保存される Cloud Storage のロケーション(リージョンまたはマルチリージョン)。詳細については、ディスク スナップショットを作成して管理するをご覧ください。
イメージベースのバックアップ
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION次のように置き換えます。
IMAGE_NAME: 作成するディスク イメージの名前。PROJECT_NAME: Google Cloud プロジェクトの名前。SOURCE_DISK_NAME: イメージの作成に使用されるソースディスク。ZONE: 操作するソースディスクのゾーン。LOCATION: イメージのコンテンツが保存される Cloud Storage のロケーション(リージョンまたはマルチリージョン)。詳細については、カスタム イメージを作成するをご覧ください。
スナップショットまたはイメージから新しいディスクを作成します。
Hyperdisk ボリュームの場合は、ワークロードの要件を満たすようにディスクサイズ、IOPS、スループットを指定してください。Hyperdisk の IOPS とスループットのプロビジョニングの詳細については、Hyperdisk にプロビジョニングされたパフォーマンスについてをご覧ください。
スナップショットから作成
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT次のように置き換えます。
NEW_DISK_NAME: 作成するディスクの名前。PROJECT_NAME: Google Cloud プロジェクトの名前。DISK_TYPE: 作成するディスクのタイプ。DISK_SIZE: ディスクのサイズ。ZONE: ディスクを作成するゾーン。SOURCE_SNAPSHOT: ディスクの作成に使用されるソース スナップショット。IOPS: 作成するディスクにプロビジョニングする IOPS。THROUGHPUT: 作成するディスクにプロビジョニングするスループット。
イメージから作成
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT次のように置き換えます。
NEW_DISK_NAME: 作成するディスクの名前。PROJECT_NAME: Google Cloud プロジェクトの名前。DISK_TYPE: 作成するディスクのタイプ。DISK_SIZE: ディスクのサイズ。ZONE: ディスクを作成するゾーン。SOURE_IMAGE_NAME: 作成するディスクに適用するソースイメージ。IMAGE_PROJECT_NAME: すべてのイメージとイメージ ファミリーの参照を解決するための Google Cloud プロジェクト。IOPS: 作成するディスクにプロビジョニングする IOPS。THROUGHPUT: 作成するディスクにプロビジョニングするスループット。
詳細については、
gcloud compute disks createをご覧ください。SAP HANA システムから既存のディスクを切断します。
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME次のように置き換えます。
INSTANCE_NAME: 操作するインスタンスの名前。OLD_DISK_NAME: 切断するディスク(リソース名で指定)。ZONE: 操作するインスタンスのゾーン。PROJECT_NAME: Google Cloud プロジェクトの名前。
詳細については、
gcloud compute instances detach-diskをご覧ください。SAP HANA システムに新しいディスクをアタッチします。
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME次のように置き換えます。
INSTANCE_NAME: 操作するインスタンスの名前。NEW_DISK_NAME: インスタンスにアタッチするディスクの名前。ZONE: 操作するインスタンスのゾーン。PROJECT_NAME: Google Cloud プロジェクトの名前。
詳細については、
gcloud compute instances attach-diskをご覧ください。マウント ポイントが正しくアタッチされているかどうかを確認します。
lsblk出力は次のようになります。
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/log次のいずれかのコマンドを実行して、SAP HANA インスタンスを起動します。
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
INSTANCE_NUMBERは、SAP HANA システムのインスタンス番号に置き換えます。詳細については、SAP HANA システムの起動と停止をご覧ください。
新しい Hyperdisk ボリュームのディスクサイズ、IOPS、スループットを検証します。
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAME次のように置き換えます。
DISK_NAME: 情報を取得するディスクの名前。ZONE: 情報を取得するディスクのゾーン。PROJECT_NAME: Google Cloud プロジェクトの名前。
詳細については、
gcloud compute disks describeをご覧ください。
SAP HANA システムのクローンを作成する
Google Cloud 上の既存の SAP HANA システムのスナップショットを作成して、システムの正確なクローンを作成できます。
単一ホストの SAP HANA システムのクローンを作成するには:
データとバックアップ ディスクのスナップショットを作成します。
スナップショットを使用して新しいディスクを作成します。
Google Cloud コンソールで [VM インスタンス] ページに移動します。
クローンを作成するインスタンスをクリックしてインスタンスの詳細ページを開き、[クローンを作成] をクリックします。
スナップショットから作成したディスクをアタッチします。
マルチホストの SAP HANA システムのクローンを作成するには:
クローンを作成する SAP HANA システムと同じ構成の新しい SAP HANA システムをプロビジョニングします。
元のシステムのデータ バックアップを実行します。
元のシステムのバックアップを新しいシステムとして復元します。
gcloud CLI のインストールと更新
SAP HANA 用の VM をデプロイしてオペレーティング システムをインストールしたら、さまざまな目的のために最新の Google Cloud CLI が必要になります。たとえば、Cloud Storage とのファイルの転送、ネットワーク サービスとの通信などです。
SAP HANA デプロイガイドの操作を行うと、gcloud CLI が自動的にインストールされます。
ただし、独自のオペレーティング システムをカスタム イメージとして Google Cloud に実装する場合や、Google Cloudにより提供された古い公開イメージを使用している場合は、gcloud CLI を手動でインストールまたは更新する必要があります。
gcloud CLI がインストールされているかどうか、および更新が可能かどうかを確認するには、ターミナルまたはコマンド プロンプトを開いて次のコマンドを入力します。
gcloud version
コマンドが認識されない場合、gcloud CLI はインストールされません。
gcloud CLI をインストールするには、gcloud CLI のインストールの手順を行ってください。
バージョン 140 以前の SLES と統合された gcloud CLI を置き換えるには:
sshを使用して VM にログインします。スーパー ユーザーに切り替えます。
sudo su次のコマンドを入力します。
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
SAP HANA 高速再起動の有効化
Google Cloud では、SAP HANA の各インスタンス(特に大規模なインスタンス)で SAP HANA Fast Restart を有効にすることを強くおすすめします。SAP HANA Fast Restart により、SAP HANA の終了後もオペレーティング システムが稼働し続けている場合の再起動時間が短縮されます。
Google Cloud が提供する自動化スクリプトによって構成されるように、オペレーティング システムとカーネルの設定は、すでに SAP HANA Fast Restart をサポートしています。tmpfs ファイル システムを定義し、SAP HANA を構成する必要があります。
tmpfs ファイル システムを定義して SAP HANA を構成するには、手動の手順を行うか、Google Cloud が提供する自動化スクリプトを使用して SAP HANA Fast Restart を有効にします。詳細については、次の情報をご覧ください。
SAP HANA Fast Restart の詳しい手順については、SAP HANA Fast Restart オプションのドキュメントをご覧ください。
手動で行う場合の手順
tmpfs ファイル システムを構成する
ホスト VM とベースとなる SAP HANA システムが正常にデプロイされたら、tmpfs ファイル システムで NUMA ノードのディレクトリを作成してマウントする必要があります。
VM の NUMA トポロジを表示する
必要な tmpfs ファイル システムをマッピングする前に、VM に含まれる NUMA ノードの数を確認する必要があります。Compute Engine VM で利用可能な NUMA ノードを表示するには、次のコマンドを入力します。
lscpu | grep NUMA
たとえば、m2-ultramem-208 VM タイプには、次の例に示すように、0~3 の番号が付いた 4 つの NUMA ノードがあります。
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
NUMA ノード ディレクトリを作成する
VM に NUMA ノードごとにディレクトリを作成し、権限を設定します。
たとえば、0~3 の番号が付いた 4 つの NUMA ノードの場合、次のようになります。
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDNUMA ノード ディレクトリを tmpfs にマウントする
tmpfs ファイル システム ディレクトリをマウントし、mpol=prefer を使用してそれぞれの NUMA ノードの優先順位を指定します。
SID: SID を大文字で指定します。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
/etc/fstab の更新
オペレーティング システムの再起動後にマウント ポイントを使用できるようにするには、次のように、ファイル システム テーブル /etc/fstab にエントリを追加します。
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
省略可: メモリ使用量の上限を設定する
tmpfs ファイル システムは動的に拡張および縮小できます。
tmpfs ファイル システムで使用されるメモリを制限するには、size オプションを使用して NUMA ノード ボリュームのサイズ制限を設定します。次に例を示します。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
また、global.ini ファイルの [memorymanager] セクションで persistent_memory_global_allocation_limit パラメータを設定して、特定の SAP HANA インスタンスと特定のサーバーノードにおけるすべての NUMA ノードについて、全体的な tmpfs メモリ使用量を制限できます。
Fast Restart 用の SAP HANA の構成
Fast Restart 用に SAP HANA を構成するには、global.ini ファイルを更新し、永続メモリに保存するテーブルを指定します。
global.ini ファイルの [persistence] セクションを更新する
tmpfs の場所を参照するように、SAP HANA の global.ini ファイルの [persistence] セクションを構成します。各 tmpfs の場所をセミコロンで区切ります。
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
上記の例では、4 つの NUMA ノードに 4 つのメモリ ボリュームを指定しています。これは、m2-ultramem-208 に対応しています。m2-ultramem-416 で実行している場合は、8 つのメモリ ボリューム(0~7)を構成する必要があります。
global.ini ファイルを変更したら、SAP HANA を再起動します。
SAP HANA では、tmpfs の場所を永続メモリ領域として使用できるようになりました。
永続メモリに保存するテーブルを指定する
永続メモリに保存する特定の列テーブルまたはパーティションを指定します。
たとえば、既存のテーブルの永続メモリを有効にするには、SQL クエリを実行します。
ALTER TABLE exampletable persistent memory ON immediate CASCADE
新しいテーブルのデフォルトを変更するには、indexserver.ini ファイルにパラメータ table_default を追加します。次に例を示します。
[persistent_memory] table_default = ON
列、テーブルのコントロール方法の詳細や、どのモニタリング ビューが詳細情報を提供するかは、SAP HANA 永続メモリをご確認ください。
自動で行う場合の手順
SAP HANA Fast Restart を有効にするために Google Cloud が提供する自動化スクリプトは、ディレクトリ /hana/tmpfs*、ファイル /etc/fstab、SAP HANA の構成を変更します。スクリプトを実行する際に、これが SAP HANA システムの初期デプロイか、マシンを別の NUMA サイズに変更するかによって、追加の手順が必要になる場合があります。
SAP HANA システムの初期デプロイや、NUMA ノードの数を増やすためにマシンのサイズを変更する場合は、 Google Cloud提供の自動化スクリプトで SAP HANA Fast Restart を有効にするときに、SAP HANA が稼働している必要があります。
NUMA ノードの数を減らすためにマシンサイズを変更する場合は、SAP HANA Fast Restart を有効にするために Google Cloud が提供する自動化スクリプトの実行中に SAP HANA が停止していることを確認してください。スクリプトの実行後、SAP HANA の構成を手動で更新し、SAP HANA Fast Restart の設定を完了する必要があります。詳細については、Fast Restart 用の SAP HANA の構成をご覧ください。
SAP HANA Fast Restart を有効にするには、次の手順を行います。
ホスト VM との SSH 接続を確立します。
root に切り替えます。
sudo su -
sap_lib_hdbfr.shスクリプトをダウンロードします。wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
ファイルを実行可能にします。
chmod +x sap_lib_hdbfr.sh
スクリプトにエラーがないことを確認します。
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
コマンドからエラーが返された場合は、Cloud カスタマーケアにお問い合わせください。カスタマーケアへのお問い合わせ方法については、 Google Cloudでの SAP に関するサポートを利用するをご覧ください。
スクリプトを実行する前に、SAP HANA のシステム ID(SID)とパスワードを SAP HANA データベースの SYSTEM ユーザーのものと置き換えてください。パスワードを安全に提供するには、Secret Manager でシークレットを使用することをおすすめします。
Secret Manager で、シークレットの名前を使用してスクリプトを実行します。このシークレットは、ホスト VM インスタンスを含む Google Cloud プロジェクトに存在している必要があります。
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
次のように置き換えます。
SID: SID を大文字で指定します。例:AHASECRET_NAME: SAP HANA データベースの SYSTEM ユーザーのパスワードに対応するシークレットの名前を指定します。このシークレットは、ホスト VM インスタンスを含む Google Cloud プロジェクトに存在している必要があります。
書式なしテキストのパスワードを使用してスクリプトを実行することもできます。SAP HANA Fast Restart を有効にした後、パスワードを変更します。パスワードは VM のコマンドライン履歴に記録されるため、書式なしテキストのパスワードの使用はおすすめしません。
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
次のように置き換えます。
SID: SID を大文字で指定します。例:AHAPASSWORD: SAP HANA データベースの SYSTEM ユーザーのパスワードを指定します。
初期実行に成功すると、次のような出力が表示されます。
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
SAProuter を使用して SAP サポート チャネルを設定する
SAP のサポート エンジニアがGoogle Cloud上の SAP HANA システムにアクセスできるようにする必要がある場合は、SAProuter でそれを実現できます。手順は次のとおりです。
SAProuter ソフトウェアをインストールする Compute Engine VM インスタンスを起動し、インスタンスがインターネットにアクセスできるように外部 IP アドレスを割り当てます。
新しい静的外部 IP アドレスを作成し、インスタンスにこの IP アドレスを割り当てます。
ネットワークに特定の SAProuter ファイアウォール ルールを作成して構成します。このルールでは、SAProuter インスタンスに対して、SAP サポート ネットワークへの必要な受信アクセスと送信アクセスのみを許可します。
受信アクセスと送信アクセスを、SAP が接続用に提供する特定の IP アドレスと、TCP ポート
3299に制限します。ターゲットタグをファイアウォール ルールに追加してインスタンス名を入力します。これにより、ファイアウォール ルールは新しいインスタンスにのみ適用されます。ファイアウォール ルールの作成と構成に関する詳細については、ファイアウォール ルールのドキュメントをご覧ください。SAP Note 1628296 に従って SAProuter ソフトウェアをインストールし、SAP から Google Cloud上の SAP HANA システムへのアクセスを許可する
saprouttabファイルを作成します。SAP との接続を設定します。インターネット接続には、セキュア ネットワーク コミュニケーションを使用します。詳細については、SAP リモート サポートのヘルプをご覧ください。
ネットワークを構成する
SAP HANA システムは、Google Cloud 仮想ネットワークで VM を使用してプロビジョニングされています。 Google Cloud は、最先端のソフトウェア定義ネットワーキングと分散システム技術により、世界中でサービスをホストし、提供しています。
SAP HANA に対しては、ネットワーク内の各サブネットワークの CIDR IP アドレス範囲と重複しないような、デフォルトでないサブネット ネットワークを作成します。各サブネットワークとその内部 IP アドレス範囲は、単一のリージョンにマッピングされることに注意してください。
サブネットワークは、サブネットワークが作成されたリージョン内のすべてのゾーンにわたって広がります。
ただし、VM インスタンスを作成する際には、VM のゾーンとサブネットワークを指定します。たとえば、必要に応じて、subnetwork1 と、region1 の zone1 に 1 組のインスタンスを作成し、subnetwork2 と、region1 の zone2 にもう 1 組のインスタンスを作成できます。
新しいネットワークにはファイアウォール ルールがなく、したがってネットワーク アクセスもありません。最小権限モデルに基づいて、SAP HANA インスタンスへのアクセスを可能にするファイアウォール ルールを作成する必要があります。ファイアウォール ルールはネットワーク全体に適用されますが、タグ付けメカニズムにより特定のターゲット インスタンスに適用されるように構成することもできます。
ルートは 1 つのネットワークに接続されるグローバルなリソースであり、リージョンに限定されません。ユーザーが作成したルートは、ネットワーク内のすべてのインスタンスに適用されます。つまり、外部 IP アドレスを指定しなくても、同じネットワーク内のインスタンス間で、サブネットワークを越えてトラフィックを転送するルートを追加できます。
SAP HANA インスタンスについては、外部 IP アドレスを指定せずにインスタンスを起動し、別の VM を外部アクセス用の NAT ゲートウェイとして構成します。この構成では、SAP HANA インスタンスのルートとして NAT ゲートウェイを追加する必要があります。この手順については、デプロイガイドをご覧ください。
セキュリティ
このセクションでは、セキュリティの運用について説明します。
最小権限モデル
防御の最前線として、インスタンスにアクセスできるユーザーを制限するファイアウォールを使用します。ファイアウォール ルールを作成すると、特定のポートでネットワークやターゲット マシンに流れ込むすべてのトラフィックを、特定のソース IP アドレスからのものだけに制限できます。最小権限モデルに従って、アクセスを必要とする特定の IP アドレス、プロトコル、ポートにのみアクセスを許可する必要があります。たとえば、踏み台インスタンスを常時設定して、そこから SAP HANA システムにアクセスする SSH のみを許可します。
構成の変更
SAP HANA システムとオペレーティング システムを、推奨されるセキュリティ設定で構成する必要があります。たとえば、アクセスを許可するネットワーク ポートのみを一覧表示し、SAP HANA を実行しているオペレーティング システムを強化します。
以下の SAP ノートをご覧ください(SAP ユーザー アカウントが必要)。
- 1944799: Guidelines for SLES SAP HANA installation
- 1730999: Recommended configuration changes
- 1731000: Unrecommended configuration changes
不要な SAP HANA サービスを無効にする
SAP HANA 拡張アプリケーション サービス(SAP HANA XS)が不要な場合は、このサービスを無効にします。SAP ノート 1697613: Removing the SAP HANA XS Classic Engine service from the topology をご覧ください。
サービスを無効にした後、そのサービス用に開いていたすべての TCP ポートを削除します。 Google Cloudでは、ネットワークのファイアウォール ルールを編集して、アクセスリストからポートを削除します。
監査ロギング
Cloud Audit Logs は、管理アクティビティとデータアクセスという 2 つのログストリームで構成されます。どちらのログも Google Cloudによって自動的に生成されます。これらは、Google Cloud プロジェクトで「誰がいつどこで何をしたか」という疑問に答えるのに役立ちます。
管理アクティビティ ログには、サービスまたはプロジェクトの構成またはメタデータを変更する API 呼び出しや管理アクションのログエントリが記録されます。このログは常時有効になっており、プロジェクトの全員が見ることができます。
データアクセス ログには、サービスが管理するユーザー入力データ(データベース サービスに格納されているデータなど)の作成、変更、読み取りを行う API 呼び出しのログエントリが記録されます。このロギングは、プロジェクトでデフォルトで有効になっており、Cloud Logging またはアクティビティ フィードを通じて参照できます。
Cloud Storage バケットの保護
Cloud Storage でデータとログのバックアップをホストする場合、転送中のデータを保護するために、インスタンスから Cloud Storage にデータを送信する際は必ず TLS(HTTPS)を使用してください。Cloud Storage は、保存データを自動的に暗号化します。独自の鍵管理システムを使用している場合は、独自の暗号鍵を指定できます。
関連のセキュリティ ドキュメント
Google Cloud上の SAP HANA 環境については、以下のセキュリティ リソースもご覧ください。
Google Cloud上の SAP HANA の高可用性
Google Cloud には、Compute Engine のライブ マイグレーションや自動再起動機能など、SAP HANA システムの高可用性を確保するためのさまざまなオプションがあります。それらの機能を使用すれば、Compute Engine VM の 1 か月あたりの稼働率が高いこともあって、スタンバイ システムに対する支払いやメンテナンスが不要になることもあります。
ただし、必要であれば、SAP HANA ホストの自動フェイルオーバー用のスタンバイ ホストを含む、マルチホストのスケールアウト システムをデプロイできます。また、可用性の高い Linux クラスタ内にスタンバイ SAP HANA インスタンスを設定したスケールアップ システムをデプロイすることもできます。
Google Cloudでの SAP HANA の高可用性オプションの詳細については、SAP HANA 高可用性プランニング ガイドをご覧ください。
SAP HANA HA/DR プロバイダ フックを有効にする
障害復旧
SAP HANA システムには、ソフトウェア レベルまたはインフラストラクチャ レベルの障害に対して SAP HANA データベースの耐久性を確保する高可用性機能がいくつか用意されています。そうした機能の中に SAP HANA システム レプリケーションと SAP HANA バックアップがあり、いずれも Google Cloud でサポートされています。
SAP HANA バックアップの詳細については、バックアップと復元をご覧ください。
システム レプリケーションの詳細については、SAP HANA 障害復旧プランニング ガイドをご覧ください。
バックアップとリカバリ
バックアップは、記録システム(データベース)を保護するために不可欠です。SAP HANA はインメモリ データベースであるため、バックアップを定期的に作成し、適切なバックアップ戦略を実装することで、計画外の停止やインフラストラクチャの障害でデータの破損や消失が発生した場合に SAP HANA データベースを復元できます。SAP HANA システムには、バックアップと復元機能が組み込まれています。SAP HANA バックアップのバックアップ先として、Cloud Storage などの Google Cloudサービスを使用できます。
Google Cloudの SAP 用エージェントの Backint 機能を有効にして、バックアップと復元に Cloud Storage を直接使用することもできます。
X4 などの Compute Engine ベアメタル インスタンスで実行されている SAP HANA システムのバックアップと復元の推奨事項については、ベアメタル インスタンス上の SAP HANA のバックアップと復元をご覧ください。
このドキュメントは、読者が SAP HANA のバックアップと復元に加えて、以下の SAP サービスノートに精通していることを前提としています。
- 1642148: FAQ: SAP HANA Database Backup & Recovery
- 1821207: Determining required recovery files
- 1869119: Checking backups using
hdbbackupcheck - 1873247: Checking recoverability with
hdbbackupdiag --check - 1651055: Scheduling SAP HANA Database Backups in Linux
バックアップに Compute Engine Persistent Disk ボリュームと Cloud Storage を使用する
Google Cloud が提供する Terraform ベースのデプロイ手順で SAP HANA システムをデプロイすると、SAP HANA がインストールされたバランス永続ディスク ボリュームに /hanabackup ディレクトリが作成されます。
/hanabackup ディレクトリにオンライン データベースのバックアップを作成するには、SAP HANA Studio、SAP HANA Cockpit、SAP ABAP トランザクション DB13、SAP HANA SQL ステートメントなど、標準の SAP ツールを使用します。バックアップが完了したら、Cloud Storage バケットにアップロードして保存します。SAP HANA システムを復元する必要が生じたときは、そこからバックアップをダウンロードできます。
Compute Engine を使用してバックアップとディスク スナップショットを作成する
SAP HANA のバックアップに Compute Engine を使用できます。また、標準のディスク スナップショットを使用して、SAP HANA のデータとログボリュームをホストするディスク全体をバックアップすることもできます。
デプロイガイドの手順を実施している場合は、SAP HANA のインストール先にオンライン データベース バックアップ用として /hanabackup ディレクトリが作成されています。同じディレクトリに /hanabackup ボリュームのスナップショットを格納することで、SAP HANA データとログボリュームのポイントインタイム バックアップを維持できます。
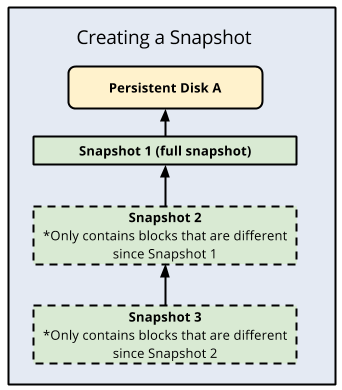
標準ディスクのスナップショットの利点は増分のみが保存されることです。2 回目以降の各バックアップでは、まったく新しいバックアップが作成されるのではなく、増分ブロック変更のみが格納されます。Compute Engine は、各スナップショットの複数のコピーを複数の場所に重複して保存し、自動チェックサムを使用してデータの整合性を確保します。
次の図は、増分バックアップを示しています。
バックアップ先として Cloud Storage を使用する
Cloud Storage はデータの耐久性と可用性が高いため、SAP HANA のバックアップ先として適しています。
Cloud Storage は、あらゆるタイプや形式のファイルを格納できるオブジェクト ストアです。実質的に無制限のストレージを利用できるため、プロビジョニングや容量の追加について心配する必要はありません。Cloud Storage 内のオブジェクトはファイルデータとそれに関連付けられたメタデータで構成され、最大許容サイズは 5 TB です。Cloud Storage バケットには、任意の数のオブジェクトを格納できます。
Cloud Storage では、データが複数の場所に保存されるため、耐久性と可用性が高くなります。Cloud Storage へのデータのアップロードや Cloud Storage 内のデータのコピーを行った場合、Cloud Storage はオブジェクトの冗長性が確保されたときだけ操作が成功したと報告します。
次の表に、Cloud Storage で提供されるストレージ オプションを示します。
| データの読み取り / 書き込み頻度 | 推奨される Cloud Storage オプション |
|---|---|
| 読み取りまたは書き込みの頻度が高い | バックアップ ファイルの書き込みや読み取りのために、Cloud Storage に頻繁にアクセスする可能性があるため、使用中のデータベースには標準のストレージ クラスを選択します。 |
| 読み取りまたは書き込みの頻度が低い | アクセス頻度の低いデータ(組織の保持ポリシーに従って維持する必要のあるアーカイブ バックアップなど)には、Nearline ストレージまたは Coldline ストレージを選択します。Nearline は、バックアップ データにアクセスする頻度が最大でも 1 か月に 1 回程度の場合に適しています。一方、Coldline はアクセスする頻度がかなり低い(1 年に 1 回程度)の場合に適しています。 |
| アーカイブ データ | 長期アーカイブ データには Archive ストレージを選択します。Archive は、長期間コピーを保持する必要があるが、1 年に 1 回しかアクセスしないデータに適しています。たとえば、規制要件を満たすために長期間保持する必要があるバックアップには、Archive ストレージを使用します。テープベースのバックアップ ソリューションは、Archive に置き換えることを検討してください。 |
上記のストレージ オプションの使用を計画する場合は、アクセスする頻度が高い順に、バックアップ データを保存する階層を検討します。一般的に、バックアップは古くなるにつれて使用機会が減少します。3 年前のバックアップが必要になる可能性は非常に低いため、このバックアップを Archive 階層に保存することで費用を抑えることができます。Cloud Storage の費用については、Cloud Storage の料金をご覧ください。
Cloud Storage とテープ バックアップの比較
これまでのオンプレミスのバックアップ先はテープです。Cloud Storage にはテープよりも多くの利点があります。たとえば、Cloud Storage のデータは複数の施設で複製されるため、ソースシステムのバックアップを「オフサイト」に自動的に保存できます。これは、Cloud Storage に保存されるバックアップの可用性が高いことも意味します。
もう一つの大きな違いは、バックアップが必要になったときにバックアップを復元する速度です。バックアップから新しい SAP HANA システムを作成したり、バックアップから既存のシステムを復元する必要がある場合、Cloud Storage のほうがデータに迅速にアクセスでき、システムの構築にかかる時間も短くなります。
Google Cloudの SAP 用エージェントの Backint 機能
Google Cloudの SAP 用エージェントの SAP 認定 Backint 機能を使用すると、オンプレミスとクラウドの両方のインストールのバックアップと復元に Cloud Storage を直接使用できます。
この機能の詳細については、SAP HANA の Backint ベースのバックアップと復元をご覧ください。
Backint を使用した SAP HANA のバックアップと復元
以降のセクションでは、 Google Cloudの SAP 用エージェントの Backint 機能を使用した SAP HANA のバックアップと復元の方法について説明します。
データのバックアップと差分バックアップのトリガー
Google Cloudの SAP 用エージェントの Backint 機能を使用して SAP HANA データ ボリュームのバックアップをトリガーし、Cloud Storage に送信するには、SAP HANA Studio、SAP HANA Cockpit、SAP HANA SQL、または DBA Cockpit を使用します。
データ バックアップをトリガーするための SAP HANA SQL ステートメントは次のとおりです。
システム データベースの完全バックアップを作成するには:
BACKUP DATA USING BACKINT ('BACKUP_NAME');BACKUP_NAMEは、バックアップに設定する名前に置き換えます。テナント データベースの完全バックアップを作成するには:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');TENANT_SIDは、テナント データベースの SID に置き換えます。差分バックアップと増分バックアップを作成するには:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');作成するバックアップのタイプに応じて、
BACKUP_TYPEをDIFFERENTIALまたはINCREMENTALに置き換えます。
データのバックアップをトリガーするときに使用できるオプションは複数あります。これらのオプションの詳細については、SAP HANA SQL リファレンス ガイドの BACKUP DATA ステートメント(バックアップと復元)をご覧ください。
データ バックアップと差分バックアップの詳細については、SAP ドキュメントの Data Backups と Delta Backups をご覧ください。
ログ バックアップのトリガー
Google Cloudの SAP 用エージェントの Backint 機能を使用して SAP HANA ログボリュームのバックアップをトリガーし、Cloud Storage に送信するには、次の操作を行います。
- データベースの完全バックアップを作成します。手順については、ご使用の SAP HANA バージョンの SAP ドキュメントをご覧ください。
- SAP HANA
global.iniファイルで、catalog_backup_using_backintパラメータをyesに設定します。
SAP HANA システムのログモードがデフォルト値の normal であることを確認します。ログモードが overwrite に設定されている場合、SAP HANA データベースはログ バックアップの作成を無効にします。
ログ バックアップの詳細については、SAP ドキュメントの Log Backups をご覧ください。
バックアップ カタログのクエリ
SAP HANA バックアップ カタログはバックアップと復元のオペレーションに不可欠な要素です。これには、SAP HANA データベース用に作成されたバックアップに関する情報が含まれています。
テナント データベースのバックアップに関する情報をバックアップ カタログにクエリするには、次の操作を行います。
- テナント データベースをオフラインにします。
システム データベースで、次の SQL ステートメントを実行します。
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
特定の時点に対してクエリを実行するには、次の SQL ステートメントを実行します。
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
このステートメントは、
/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SIDディレクトリにstrategyOutput.xmlファイルを作成します。
BACKUP LIST DATA ステートメントの詳細については、SAP HANA SQL リファレンス ガイドの BACKUP DATA ステートメント(バックアップと復元)をご覧ください。バックアップ カタログの詳細については、SAP ドキュメントの Backup Catalog をご覧ください。
データベースの復元
マルチストリーミング データ バックアップを使用して復元を実行する場合、SAP HANA は、バックアップの作成時と同じ数のチャネルを使用します。詳細については、SAP ドキュメントの Prerequisites: Recovery Using Multistreamed Backups をご覧ください。
Google Cloudの SAP 用エージェントの Backint 機能を使用して作成した SAP HANA データベースのバックアップを復元するために、SAP HANA には RECOVER DATA と RECOVER DATABASE SQL ステートメントが用意されています。
どちらの SQL ステートメントも、recover_bucket パラメータにバケットを指定しない限り、PARAMETERS.json ファイルの bucket パラメータに指定した Cloud Storage バケットからバックアップを復元します。
次に、Google Cloudの SAP 用エージェントの Backint 機能を使用して作成したバックアップを使用して SAP HANA データベースを復元するためのサンプル SQL ステートメントを示します。
バックアップ ファイル名を指定してテナント データベースを復元するには:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;バックアップ ID を指定してテナント データベースを復元するには:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
BACKUP_IDは、必要なバックアップの ID に置き換えます。Cloud Storage バケットに保存されている SAP HANA バックアップ カタログのバックアップを使用する必要があるときに、バックアップ ID を指定してテナント データベースを復元するには:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
テナント データベースを特定の時点または特定のログ位置に復元するには:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
外部データベースのバックアップを使用してテナント データベースを復元するには:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
次のように置き換えます。
SOURCE_TENANT_SID: ソーステナント データベースの SIDSOURCE_SID: ソーステナント データベースが存在する SAP システムの SID
Cloud Storage バケットに保存されているバックアップで SAP HANA バックアップ カタログが利用できないときに、SAP HANA データベースを復元する必要がある場合は、SAP Note 3227931 - Recover a HANA DB From Backint Without a HANA Backup Catalog に記載されている手順を実施してください。
バックアップに関する ID とアクセスの管理
Cloud Storage または Compute Engine を使用して SAP HANA データをバックアップする場合、バックアップへのアクセスは Identity and Access Management(IAM)によって制御されます。管理者は、この機能を使用して、特定のリソースにアクションを実行するユーザーを承認できます。IAM を使用すると、バックアップを含め、すべてのGoogle Cloud リソースを一元管理でき、可視性を向上させることができます。
また、IAM は、権限の承認、削除、委任の完全な監査証跡履歴を管理者に自動的に提供します。したがって、バックアップ内のデータへのアクセスをモニタリングするポリシーを構成して、データに対するアクセス制御サイクル全体を管理できます。IAM は、組織全体のセキュリティ ポリシーを一元管理し、コンプライアンス プロセスを簡素化する組み込みの監査機能を提供します。
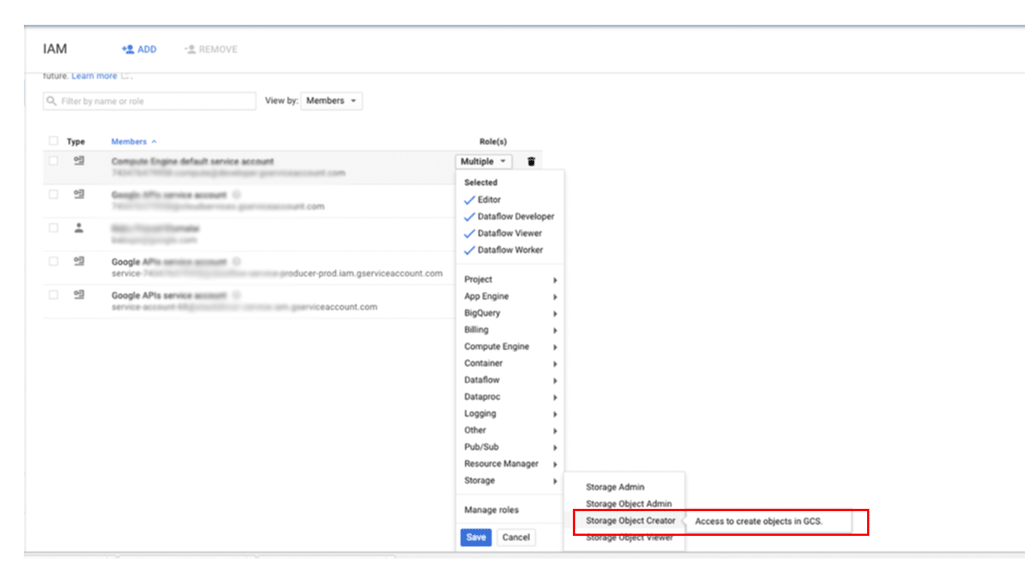
プリンシパルに Cloud Storage 内のバックアップへのアクセス権を付与するには:
Google Cloud コンソールで、[IAM と管理] ページに移動します。
アクセス権を付与するユーザーを指定し、[ストレージ] > [ストレージのオブジェクト作成者] のロールを割り当てます。
SAP HANA のファイル システム ベースのバックアップを作成する方法
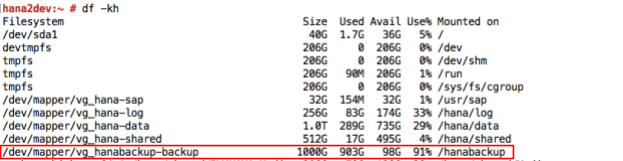
デプロイガイドに従って Google Cloud にデプロイされた SAP HANA システムには、NFS にマウントされるバックアップ先として一連の Persistent Disk または Hyperdisk ボリュームが構成されています。最初、SAP HANA バックアップはこれらのローカル ディスクに保存されますが、その後、長期保存のために Cloud Storage にコピーする必要があります。手動で Cloud Storage にバックアップをコピーするか、Cloud Storage にコピーするスケジュールを crontab で設定します。
Google Cloudの SAP 用エージェントの Backint 機能を使用している場合は、Cloud Storage バケットへのバックアップと Cloud Storage バケットからの復元を直接行うため、バックアップ用の永続ディスク ストレージは不要になります。
SAP HANA データのバックアップを開始またはスケジュールするには、SAP HANA Studio、SQL コマンド、DBA Cockpit を使用します。ログのバックアップは、無効にしない限り、自動的に書き込まれます。次のスクリーンショットの例をご覧ください。
SAP HANA global.ini の構成
デプロイガイドの手順を実施していれば、SAP HANA の global.ini 構成ファイルは、/hanabackup/data/ に格納されるデータベース バックアップ用にカスタマイズされ、自動ログアーカイブ ファイルが /hanabackup/log/ に保存されます。global.ini の例を次に示します。
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Google Cloudの SAP 用エージェントの Backint 機能用に global.ini 構成ファイルをカスタマイズするには、Backint 機能用に SAP HANA を構成するをご覧ください。
スケールアウト デプロイに関する注意事項
スケールアウト実装では、ライブ マイグレーションと自動再起動を使用する高可用性ソリューションは、単一ホスト設定と同じように機能します。主な違いは、/hana/shared ボリュームがすべてのワーカーホストに NFS でマウントされ、HANA マスターがマスターとなる点です。マスターホストのライブ マイグレーションまたは自動再起動の実行中は、NFS ボリュームにしばらくアクセスできなくなります。マスターホストが再起動すると、NFS ボリュームはすぐにすべてのホストで再び機能し、通常のオペレーションが自動的に再開します。
バックアップと復元に際しては、SAP HANA バックアップ ボリューム /hanabackup がすべてのホストで利用できる必要があります。障害が発生したときは、/hanabackup がすべてのホストにマウントされていることを確認し、それ以外のボリュームを再マウントしてください。バックアップ セットを別のボリュームまたは Cloud Storage にコピーする場合は、I/O パフォーマンスを向上させてネットワーク使用量を減らすため、マスターホストでコピーを実行します。バックアップと復元のプロセスを簡素化するには、Cloud Storage Fuse を使用して各ホストに Cloud Storage バケットをマウントします。
スケールアウトのパフォーマンスは、データ分散と同程度です。データの分散が適切であるほど、クエリのパフォーマンスは向上します。そのためには、データを十分に理解し、データがどのように消費されているかを把握して、それに応じてテーブルの分散とパーティショニングを設計する必要があります。詳細については、SAP Note 2081591 - FAQ: SAP HANA Table Distribution をご覧ください。
Gcloud Python
Gcloud Python は、Google Cloud サービスへのアクセスに慣用的に使われている Python クライアントです。このガイドでは、Gcloud Python を使用して、SAP HANA データベースを Cloud Storage にバックアップし、そこから復元する操作について説明します。
デプロイガイドの手順を実施していれば、Compute Engine インスタンスで Gcloud Python ライブラリが利用可能になっています。
このライブラリはオープンソースであり、Cloud Storage バケットを操作してバックアップ データを保存および取得するために使用できます。
次のコマンドを実行すると、Cloud Storage バケット内のオブジェクトを一覧表示できます。これを使用して、使用可能なバックアップのリストを取得できます。
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Gcloud Python の詳細については、ストレージ クライアント ライブラリのリファレンス ドキュメントをご覧ください。
バックアップと復元の例
以降のセクションでは、SAP HANA Studio を使用して一般的なバックアップ タスクと復元タスクを行う手順について説明します。
バックアップの作成例
SAP HANA バックアップ エディタで、[Open Backup Wizard] を選択します。
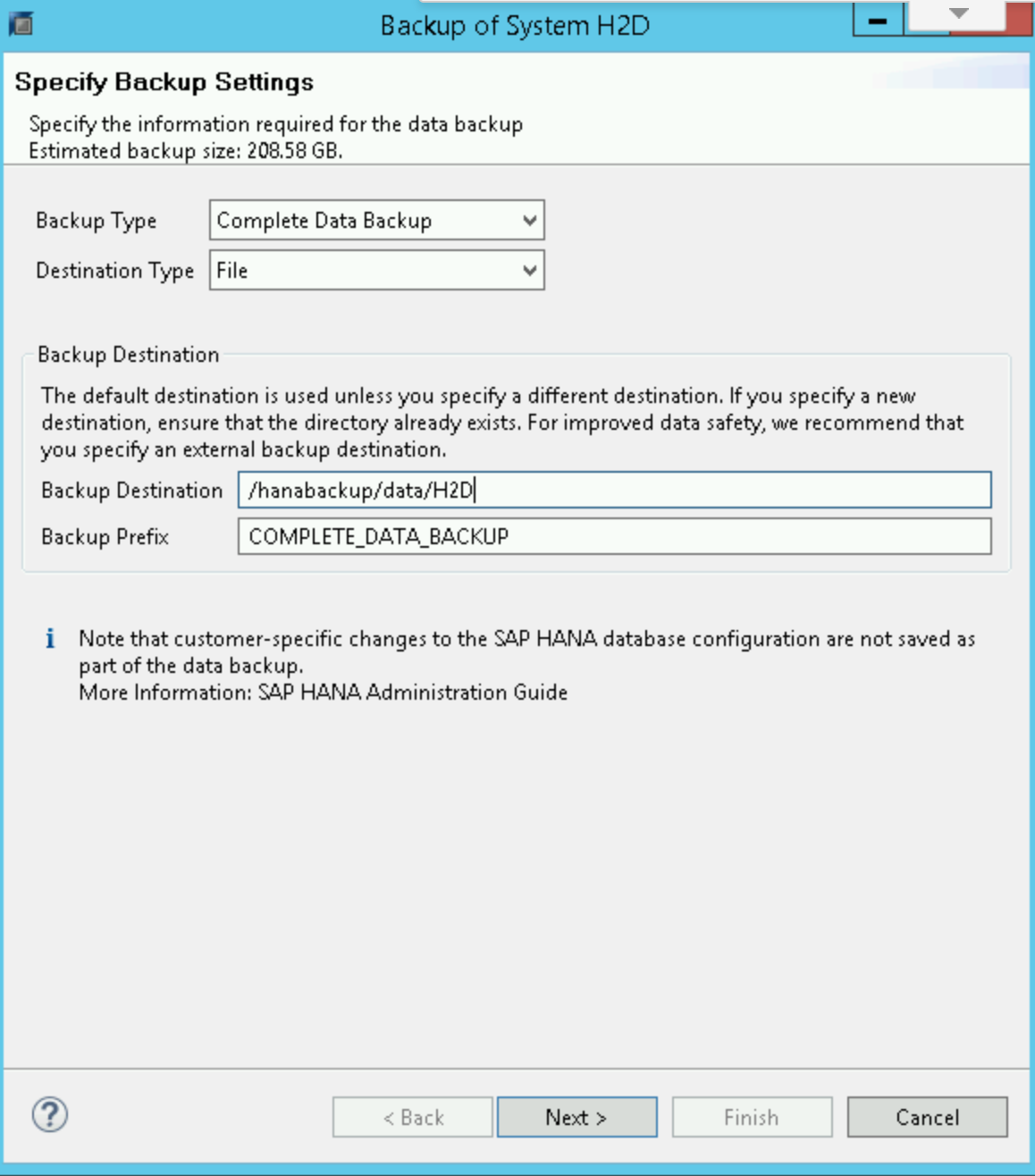
- 宛先タイプとして [File] を選択します。これにより、指定されたファイル システム内のファイルにデータベースがバックアップされます。
- バックアップ先(
/hanabackup/data/SID)とバックアップの接頭辞を指定します。SIDは、SAP システムのシステム ID に置き換えます。 - [Next] をクリックします。
確認フォームで [Finish] をクリックして、バックアップを開始します。
バックアップが開始されると、バックアップの進捗状況がステータス ウィンドウに表示されます。バックアップが完了するまで待ちます。
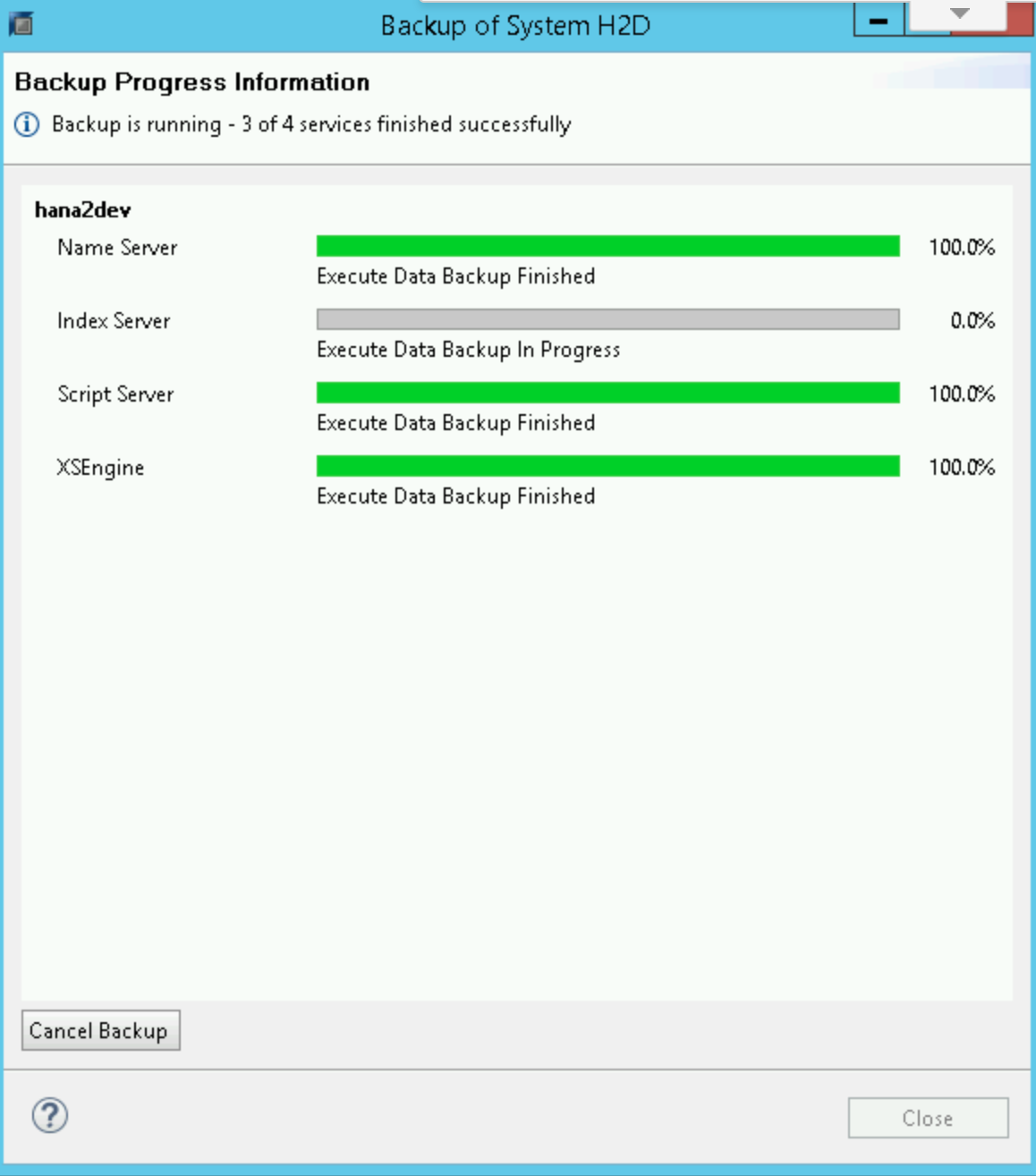
バックアップが完了すると、バックアップの概要に「
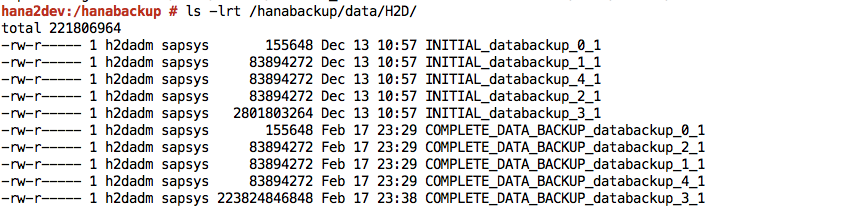
Finished」というメッセージが表示されます。SAP HANA システムにログインして、バックアップがファイル システム内の指定した場所にあることを確認します。例:

/hanabackupファイル システムから Cloud Storage にバックアップ ファイルを push または同期します。次のサンプル Python スクリプトは、バックアップに使用するバケットに、/hanabackup/dataと/hanabackup/logのデータをNODE_NAME/DATAまたはLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAMEの形式で push します。これにより、バックアップがコピーされた時間でバックアップ ファイルを識別できます。オペレーティング システムの bash プロンプトで、このgcloud Pythonスクリプトを実行します。python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFGcloud Python ライブラリ、または Google Cloud コンソールを使用してバックアップ データを一覧表示します。
バックアップの復元例
バックアップ ファイルが
/hanabackupディレクトリにはなく Cloud Storage にある場合は、オペレーティング システムの bash プロンプトから次のスクリプトを実行して、Cloud Storage からファイルをダウンロードします。python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFSAP HANA データベースを復元するには、[Backup and Recovery] > [Recover System] をクリックします。
[Next] をクリックします。
ローカル ファイル システム内のバックアップの場所を指定して、[Add] をクリックします。
[Next] をクリックします。
[Recover without the backup catalog] を選択します。
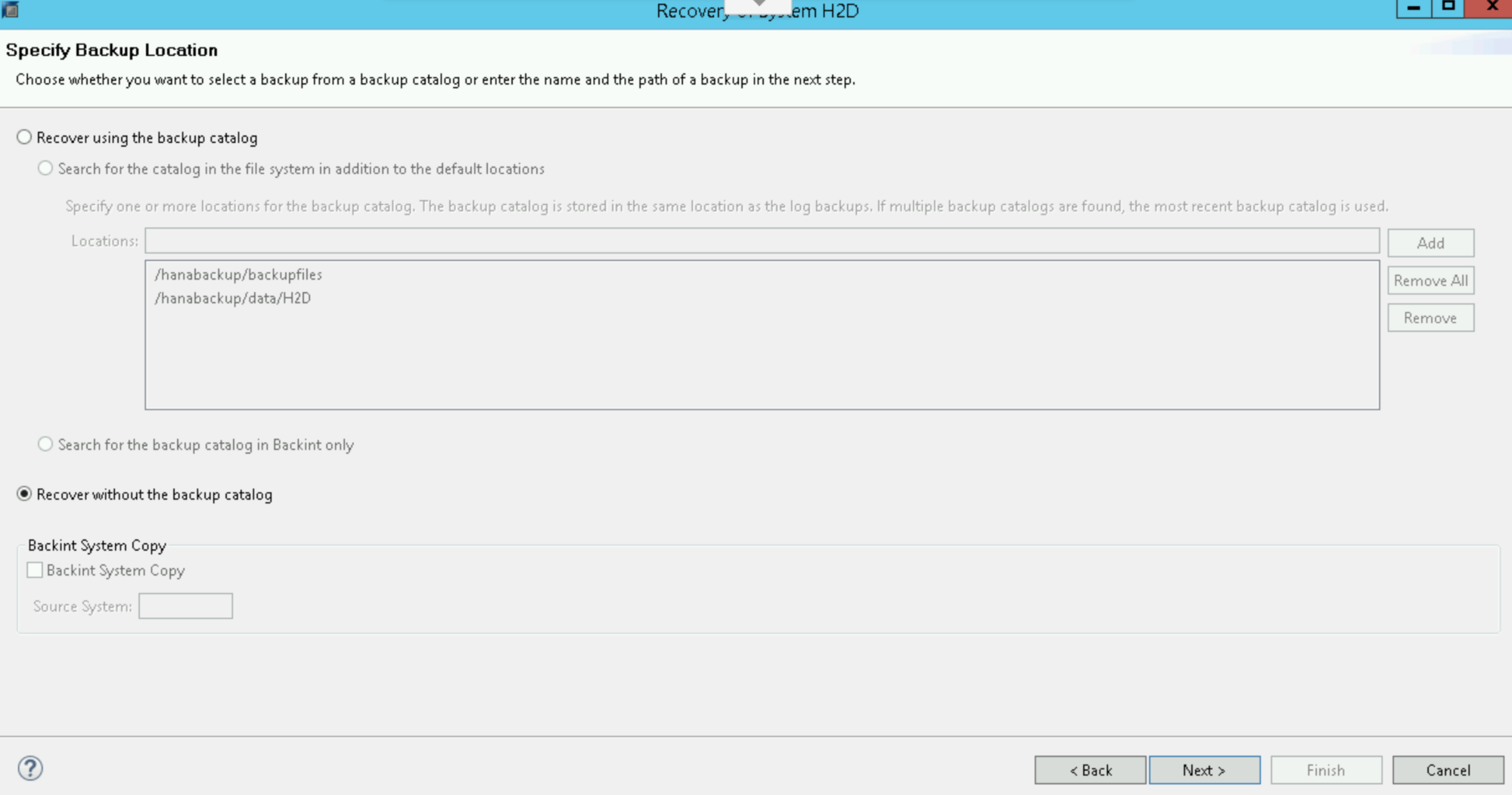
[Next] をクリックします。
宛先タイプとして [File] を選択し、バックアップ ファイルの場所と正しい接頭辞を指定します。バックアップ作成の例の手順を実施した場合、接頭辞として
COMPLETE_DATA_BACKUPが設定されていることを忘れないでください。[Next] を 2 回クリックします。
[Finish] をクリックして、復元を開始します。
復元が完了したら、通常の運用を再開し、バックアップ ファイルを
/hanabackup/data/SID/*ディレクトリから削除します。
次のステップ
以下の標準の SAP ドキュメントが参考になります。
以下の Google Cloud のドキュメントも役に立ちます。