このガイドでは、 Google Cloudにデプロイされた SAP HANA システムの障害復旧オプションの概要を説明します。
このガイドは、標準の SAP ドキュメントに代わるものではありません。
障害復旧の準備
障害に備えて、SAP HANA システムからセカンダリ SAP HANA システムへのレプリケーションを使用するか、SAP HANA のバックアップを作成して復旧を有効にするか、あるいはこれらの両方を利用できます。
高速な復旧時間を必要とするミッション クリティカルなワークロードの場合、HANA システム レプリケーションを使用してダウンタイムを最小限に抑えます。バックアップを使用してシステムを復旧する場合、新しいシステムを作成してからバックアップを復元して目的の時点に回復する必要があるため、コストは低くなりますが時間がかかります。
いずれの場合も、ネットワーク ベースのリダイレクトを使用して、SAP HANA システムを使用するクライアント アプリケーションを使用可能な代替システムの IP アドレスにリダイレクトする必要があります。詳しくは、SAP HANA 管理ガイドをご覧ください。
SAP HANA SPS09 以降、SAP HANA に付属する Python ベースの API を使用して、独自の高可用性 / 障害復旧(HA/DR)プロバイダを作成し、SAP HANA システム レプリケーションのテイクオーバー プロセスと統合することで、テイクオーバー後に、プライマリ システムからセカンダリ システムにデータベース クライアント接続をリダイレクトするなどのタスクを自動化できます。詳細は、HA/DR プロバイダの実装をご覧ください。
同期レプリケーションの距離制限など、SAP によって定義された制限は Google Cloudでも有効であるので注意してください。
クロスリージョンのアクティブ / パッシブな障害復旧(DR)では、ネイティブの障害復旧オプションの代わりに Persistent Disk の非同期レプリケーション(PD 非同期レプリケーション)を使用できます。PD 非同期レプリケーションは、Google Cloud の 2 つのリージョン間でデータの非同期レプリケーションを行います。
SAP HANA システム レプリケーションを使用した障害復旧
インフラストラクチャ リソースの使用率を最大化し、DR ソリューションの費用を最適化するために、セカンダリ システムを開発システムや QA システムなどの非本番環境のユースケースに使用できます。この場合、セカンダリ システムにはデータがプリロードされていないため、セカンダリ システムにデータをプリロードしてプライマリ システムとの同期を維持する場合よりもフェイルオーバー時間が長くなります。
HANA 2 SPS00 には、アクティブ / アクティブ(読み取り可能)構成モードのサポートが含まれ、SAP HANA システム レプリケーションで、セカンダリ システムへの読み取りアクセスをサポートできます。詳細については、アクティブ / アクティブ(読み取り可能)をご覧ください。
AP HANA システム レプリケーションを Google Cloudで使用する場合、同期レプリケーションと非同期レプリケーションの両方がサポートされます。
可能であれば、SQL トランザクションがスタンバイ インスタンスでコミットされるまでプライマリ データベース インスタンスでコミットされない「同期レプリケーション」を使用することをおすすめします。これにより、スタンバイ インスタンスが 100% 同期され、リカバリ ポイント目標をゼロにできます。同期レプリケーションは、同じリージョン内の任意のゾーンに存在するインスタンスに対して使用できます。
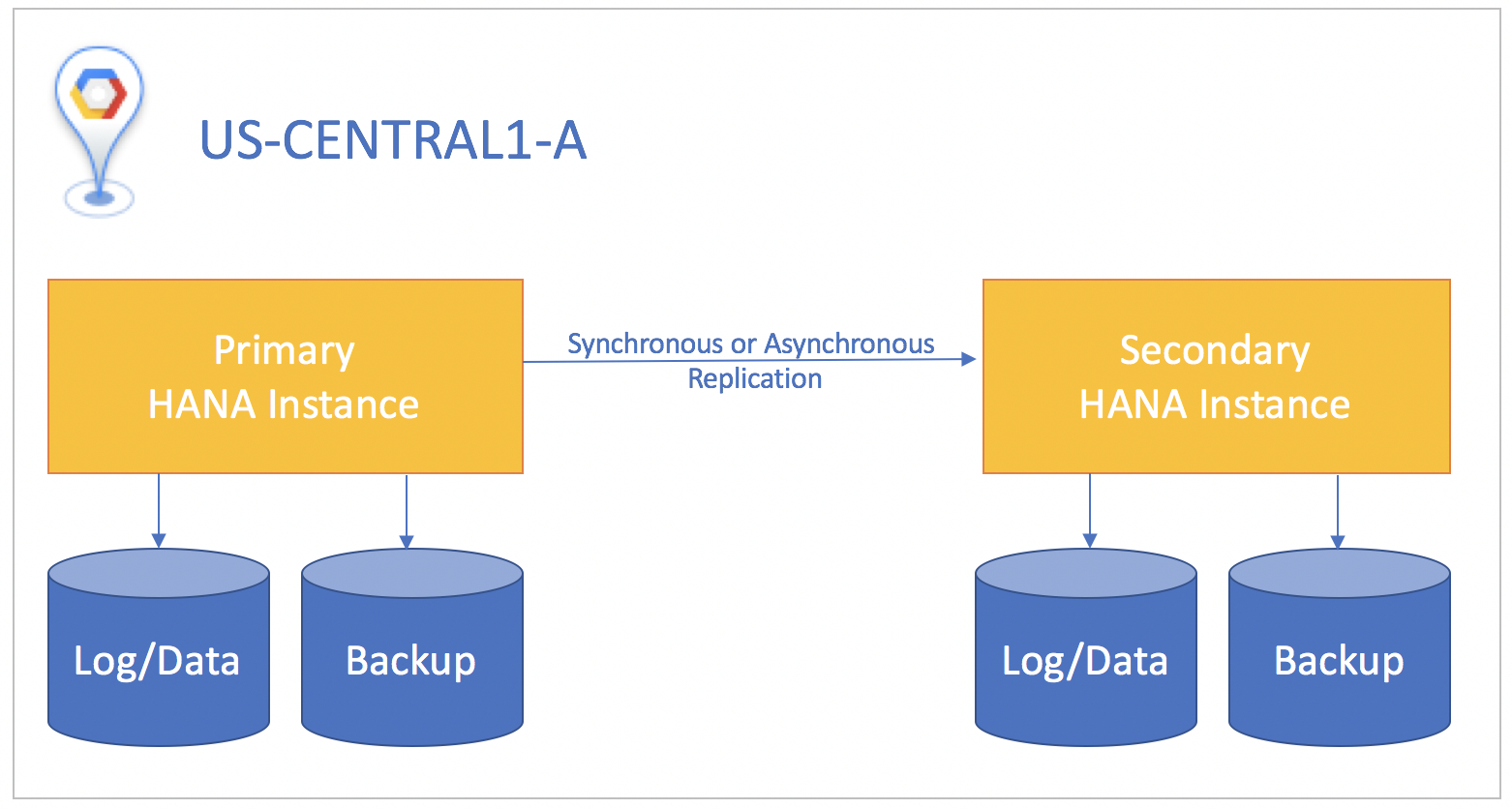
スタンバイ システムがプライマリ システムとは異なるリージョンにある場合は、プライマリ インスタンスで commit する前にスタンバイ インスタンスがデータを確認するのを待たない非同期レプリケーションを使用してください。このシナリオの場合は、障害が発生すると少量のデータが失われる可能性があります。そのトレードオフとして、非同期レプリケーションでは少なくとも 1 つのリカバリ ポイント目標が提供されます。
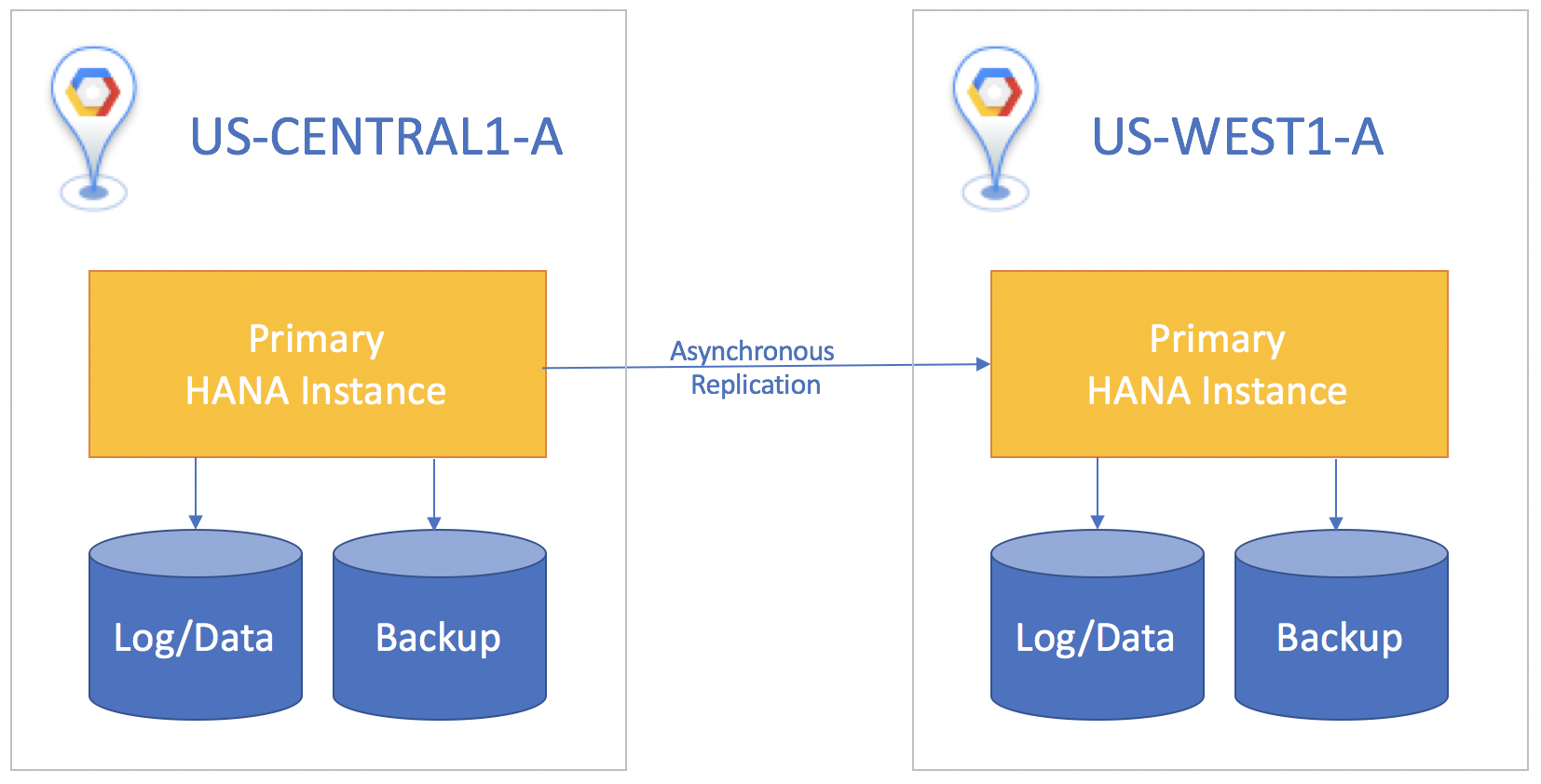
どのレプリケーション シナリオでも、障害復旧を開始するには、スタンバイ システム上で引き継ぎを手動で実行する必要があります。また、SAP HANA データベースを使用するアプリケーションはすべて、手動でリダイレクトして、スタンバイ システムでフェイルオーバーしたインスタンスをターゲットに指定する必要があります。
リカバリ時間目標(RTO)やリカバリ ポイント目標(RPO)など、ビジネスニーズに最適な HANA システム レプリケーションのオプションを選択します。詳細は、SAP HANA システム レプリケーションのレプリケーション モードをご覧ください。
プリロードありの SAP HANA システム レプリケーション
このシナリオでは、SAP HANA システムが専用のスタンバイ システムに複製されます。SAP HANA データベースは、一意のホスト名と独自の永続ディスクが接続された Compute Engine VM にレプリケートされます。また、すべての SAP HANA データがスタンバイ システムのメモリに読み込まれます。フェイルオーバーが必要な場合、すべてのデータがプリロードされているため、フェイルオーバー時間は約 90 秒しかかかりません。
プリロードありの SAP HANA システム レプリケーションの詳細については、SAP HANA – 高可用性のシステム レプリケーションのセクションをご覧ください。
プリロードなしの SAP HANA システム レプリケーション
このシナリオでは、SAP HANA システムが専用のスタンバイ システムに複製されます。SAP HANA データベースは、一意のホスト名と独自の永続ディスクが接続された Compute Engine VM にレプリケートされます。ただし、SAP HANA データはスタンバイ システムのメモリに読み込まれません。フェイルオーバーの際には、データセットのサイズに応じてフェイルオーバーに数分から数時間かかることがあります。
データをプリロードしない場合、SAP HANA データベースをホストする Compute Engine VM のメモリ要件ははるかに小さくなります。最新のサイジング ガイドについては、SAP Note 1999880 - FAQ: SAP HANA System Replication で、セカンダリ システム レプリケーション サイトのメモリ使用率に適用されるルールに関する説明をご覧ください。
次のクエリを実行すると、行ストアのメモリ フットプリントに関する情報を取得できます。
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
メモリ所要量が少なくなることで、Compute Engine マシンタイプを選択する際のコスト削減オプションが提供されます。
スタンバイ システムで SAP HANA データベースのホストにメモリ仕様が低いマシンタイプを使用することで、ランニング コストを削減できます。低メモリ VM は本番環境システムの SAP HANA ではサポートされていませんが、この低コストの VM を使用して障害復旧シナリオでテイクオーバーを実行し、その後 VM を変更してサポートされているメモリ量を持つマシンタイプに変更できます。これを行うには、VM を停止してアップグレードを実行する必要があります。そのため、SAP HANA システムが使用可能になる前に追加のダウンタイムが発生します。
スタンバイ システムにもメモリ量の多いマシンタイプを使用し、SAP HANA データベースをホストさせて開発システムやテストシステムとして共有して使用することにより、費用対効果を向上させることができます。グローバル メモリ割り当て上限の変更の手順に従って、SAP HANA データベースのグローバル割り当て上限を 64 GB に設定し、残りのメモリを他のシステムが使用できるようにします。スタンバイ システムが必要な場合は、dev と test のオペレーションをシャットダウンして、テイクオーバーを実行してから、グローバル割り当ての上限を削除します。
プリロードなしの同期レプリケーションと非同期レプリケーションの両方を使用できます。ただし、同期レプリケーションを行うには、ソース インスタンスとターゲット インスタンスが同じ Google Cloud リージョンに存在する必要があります。
HA/DR プロバイダを使用すれば、セカンダリ ホストの dev システムや test システムのシャットダウンなどの問題に対処できます。
引き継ぎのトリガー
障害復旧を呼び出すには、スタンバイ システムで SAP HANA System Replication Takeover プロシージャをトリガーします。SAP Note 2063657 には、引き継ぎが最善の選択肢であるかどうかを判断するためのガイドラインが記載されています。
引き継ぎをトリガーするには、標準の SAP HANA 引き継ぎプロセスに従います。この手順の詳細については、How To Perform System Replication for SAP HANA 2.0 をご覧ください。
データの問題やソフトウェア障害が発生した場合に、引き継ぎを実行するための自動通知が送信されない場合があります。Cloud Monitoring または HANA モニタリング ツールを使用してアラートを送信するカスタム ソリューションを作成することを検討してください。
SAP HANA バックアップを使用した障害復旧
長い目標復旧時間が許容されておりリカバリ ポイント目標が 15 分を超える場合は、バックアップを復元することで障害復旧できます。バックアップを使用して正常に復旧するには、バックアップ ファイル、特にログ バックアップを、Cloud Storage バケット、または SAP HANA システムが実行されているリージョン外に存在するその他の長期保存場所に頻繁にコピーしておく必要があります。プライマリ システムのインフラストラクチャを文書化し、バックアップを復元する代替システムをすばやく作成できるスクリプトを作成しておくことをおすすめします。
詳しくは、SAP HANA 運用ガイドをご覧ください。
PD 非同期レプリケーションを使用した障害復旧
Google Cloud上で実行される SAP ワークロードでは、PD 非同期レプリケーションは 2 つの Google Cloud リージョン間でデータを複製することにより、障害復旧を可能にします。PD 非同期レプリケーションは、リージョン目標(RPO)が低く、リカバリ時間目標(RTO)が低いブロック ストレージを提供します。これにより、クロスリージョンのアクティブ / パッシブな障害復旧での非同期レプリケーションが可能になります。万一リージョンが停止した場合、PD 非同期レプリケーションを使用すると、SAP データをセカンダリ リージョンにフェイルオーバーし、そのリージョンで SAP ワークロードを再起動できます。
PD 非同期レプリケーションを使用して、SAP HANA システム レプリケーションなどの SAP ワークロード レベルではなく、Compute Engine ベースの SAP ワークロードのレプリケーションをインフラストラクチャ レベルで管理できます。
PD 非同期レプリケーションは、SAP データを、実行中のワークロードにアタッチされているプライマリ ディスクから別のリージョンにある空のセカンダリ ディスクに複製します。詳細については、Persistent Disk の非同期レプリケーションについてをご覧ください。
PD 非同期レプリケーションの制限事項
PD 非同期レプリケーションでは、サポートされているリージョンペアでバランス永続ディスク(pd-balanced)とパフォーマンス(SSD)永続ディスク(pd-ssd)ボリュームのみを使用できます。詳細については、制限事項をご覧ください。
Persistent Disk の非同期レプリケーション パフォーマンスを確認するで説明されているように、デバイスペアのモニタリング指標を確認して、PD 非同期レプリケーションの機能に対するワークロードの変化率をモニタリングし、評価します。
指標 async_replication/sent_bytes_count は、クロスリージョン ネットワークを介して送信されたバイト数の差を表すため、転送されるデータ量が一定に増加することは想定されません。