Este documento explica a pesquisadores, cientistas de dados e analistas de negócios os processos e considerações para analisar dados de recursos rápidos de interoperabilidade de saúde (FHIR, na sigla em inglês) no BigQuery
Especificamente, este documento se concentra nos dados de recursos dos pacientes que são exportados do armazenamento de FHIR na API Cloud Healthcare. Este documento também apresenta uma série de consultas que demonstram como os dados do esquema de FHIR funcionam em um formato relacional e mostra como acessar essas consultas para reutilização por meio de visualizações.
Como usar o BigQuery para analisar dados de FHIR
A API FHIR-specific da API Cloud Healthcare foi projetada para interação transacional em tempo real com dados FHIR no nível de um único recurso FHIR ou de um conjunto de recursos FHIR. No entanto, a API FHIR não foi projetada para casos de uso de análise. Para esses casos de uso, recomendamos exportar seus dados da API FHIR para o BigQuery. O BigQuery é um armazenamento de dados escalonável e sem servidor que permite analisar grandes quantidades de dados de maneira retroativa ou potencial.
Além disso, o BigQuery está em conformidade com o ANSI:2011 SQL, que torna os dados acessíveis a cientistas de dados e analistas de negócios por meio de ferramentas que eles costumam usar, como Tableau, Looker ou Notebooks do Cloud AI
Em alguns aplicativos, como o Cloud AI Notebooks, você tem acesso por meio de clientes integrados, como a biblioteca de cliente do Python para BigQuery. Nesses casos, os dados retornados ao aplicativo estão disponíveis por meio de estruturas de dados de linguagem integradas.
Como acessar o BigQuery
Você pode acessar o BigQuery por meio da IU da Web do BigQuery no Console do Google Cloud e também com as seguintes ferramentas:
- a ferramenta de linha de comando do BigQuery;
- A API REST do BigQuery ou as bibliotecas de cliente.
- drivers ODBC e JDBC
Ao usar essas ferramentas, você pode integrar o BigQuery a praticamente qualquer aplicativo.
Como trabalhar com a estrutura de dados do FHIR
A estrutura de dados padrão FHIR integrada é complexa, com tipos de dados FHIR aninhados e incorporados em qualquer recurso FHIR. Esses tipos de dados FHIR incorporáveis são chamados de tipos de dados complexos.
As matrizes e estruturas também são chamadas de tipos de dados complexos em bancos de dados relacionais. A estrutura de dados padrão FHIR funciona bem quando é serializada como um arquivo XML ou JSON em um sistema orientado a documentos. Porém, poderá ser difícil de trabalhar com ela se ela for convertida em um banco de dados relacionais.
A captura de tela a seguir mostra uma visualização parcial de um tipo de dados patient resource FHIR, o que ilustra a natureza complexa da estrutura de dados padrão incorporada do FHIR.
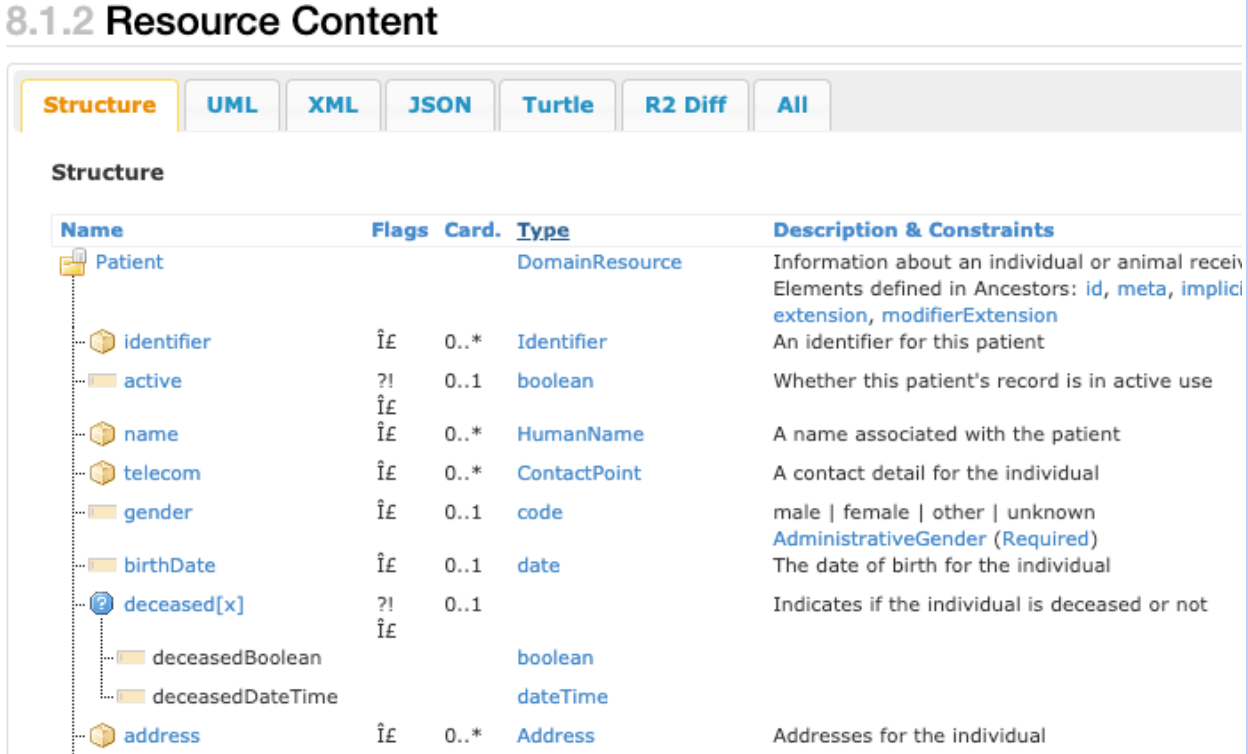
A captura de tela anterior mostra os principais componentes de tipos de dados patient
resource de FHIR. Por exemplo, a coluna cardinalidade, indicada na tabela como Card., mostra vários itens que podem ter zero, um ou mais de uma entrada. A coluna Tipo mostra o Identificador, o HumanName e os tipos de dados Address, que são exemplos de tipos de dados complexos que compõem o tipo de dados patient
resource. Cada uma dessas linhas pode ser registrada várias vezes, como uma matriz de estruturas.
Como usar matrizes e estruturas
O BigQuery é compatível com matrizes e STRUCT tipos de dados, (estruturas de dados aninhadas e repetidas) porque eles são representados em recursos FHIR, o que possibilita a conversão de dados do FHIR para o BigQuery.
No BigQuery, uma matriz é uma lista ordenada que consiste em zero ou mais valores do mesmo tipo de dados. É possível criar matrizes de tipos de dados simples, como o tipo de dados INT64, e tipos de dados complexos, como o tipo de dados STRUCT. A exceção é o tipo de dados ARRAY, porque as matrizes de
matrizes não são compatíveis no momento. No BigQuery, uma matriz de estruturas aparece como um registro repetível.
É possível especificar dados aninhados ou dados aninhados e repetidos na IU do BigQuery ou em um arquivo de esquema JSON. Para especificar colunas aninhadas ou colunas aninhadas e repetidas, use o tipo de dados RECORD (STRUCT).
A API Cloud Healthcare é compatível com o esquema SQL no FHIR no BigQuery. Esse esquema de análise é o esquema padrão no método ExportResources() e é compatível com a comunidade FHIR.
O BigQuery é compatível com dados desnormalizados. Isso significa que, ao armazenar os dados, em vez de criar um esquema relacional, como em estrela ou em floco de neve, desnormalize os dados e use colunas aninhadas e repetidas. Elas se relacionam entre os elementos de dados sem o impacto no desempenho por preservarem um esquema relacional (normalizado).
Como acessar os dados por meio do operador UNNEST
Cada recurso FHIR na API FHIR é exportado para o BigQuery como uma linha de dados. Pense em uma matriz ou estrutura dentro de qualquer linha como uma tabela incorporada. É possível acessar dados nessa "tabela" na cláusula SELECT ou na cláusula WHERE da consulta achatando a matriz ou estrutura usando o operador UNNEST.
O operador UNNEST usa uma matriz e retorna uma tabela com uma única linha para cada elemento na matriz. Para mais informações, consulte Como trabalhar com matrizes no SQL padrão.
A operação UNNEST não preserva a ordem dos elementos da matriz, mas você pode reordenar a tabela usando a cláusula WITH OFFSET opcional. Isso retorna uma coluna adicional com a cláusula OFFSET para cada elemento da matriz.
É possível usar a cláusula ORDER BY para ordenar as linhas pelo deslocamento delas.
Ao unir dados não aninhados, o BigQuery usa uma operação correlated CROSS JOIN que faz referência à coluna de matrizes de cada item na matriz com a tabela de origem, que precede diretamente a chamada para UNNEST na cláusula FROM. Para cada linha na tabela de origem, a operação UNNEST nivela a matriz dessa linha em um conjunto de linhas contendo os elementos da matriz. A operação CROSS JOIN correlacionada faz parte desse novo conjunto de linhas com a única linha da tabela de origem.
Como investigar o esquema com consultas
Para consultar dados de FHIR no BigQuery, é importante entender o esquema criado por meio do processo de exportação. O BigQuery permite inspecionar a estrutura de colunas de cada tabela no conjunto de dados por meio do recurso INFORMATION_SCHEMA, uma série de visualizações que exibem metadados. No restante deste documento, usamos o esquema SQL no FHIR, projetado para ser acessível e recuperar dados.
A consulta de amostra a seguir explora os detalhes da tabela do paciente no esquema SQL no FHIR. A consulta faz referência ao conjunto de dados públicos do Dados sintéticos gerados pelo Synthea no FHIR, que hospeda mais de um milhão de registros sintéticos de pacientes gerados nos formatos Synthea e FHIR.
Os resultados das consultas na visualização
INFORMATION_SCHEMA.COLUMNS
contêm uma linha para cada coluna (campo) da tabela. A consulta a seguir retorna todas as colunas na tabela de pacientes:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
A captura de tela a seguir do resultado da consulta mostra os tipos de dados identifier e a matriz dentro dos tipos de dados que contêm os tipos de dados STRUCT.

Como usar o recurso de paciente FHIR no BigQuery
O número de registro médico do paciente (MRN, na sigla em inglês), uma informação importante armazenada nos dados de FHIR, é usado em todos os sistemas de dados médicos e operacionais de uma organização para todos os pacientes. Qualquer método de acesso a dados para um paciente individual ou um conjunto de pacientes precisa filtrar ou retornar o MRN, ou ambos.
O exemplo de consulta a seguir retorna o identificador interno do servidor FHIR para o próprio recurso do paciente, incluindo o MRN e a data de nascimento de todos os pacientes. O filtro a ser consultado em um MRN específico também está incluído, mas é comentado neste exemplo.
Nesta consulta, você desaninha o tipo de dados complexo identifier duas vezes. Você também usa operações CROSS JOIN relacionadas para mesclar dados não aninhados com a tabela de origem.
A tabela bigquery-public-data.fhir_synthea.patient na consulta foi criada usando a versão do esquema SQL na FHIR para a exportação do FHIR para o BigQuery.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
O resultado será assim:
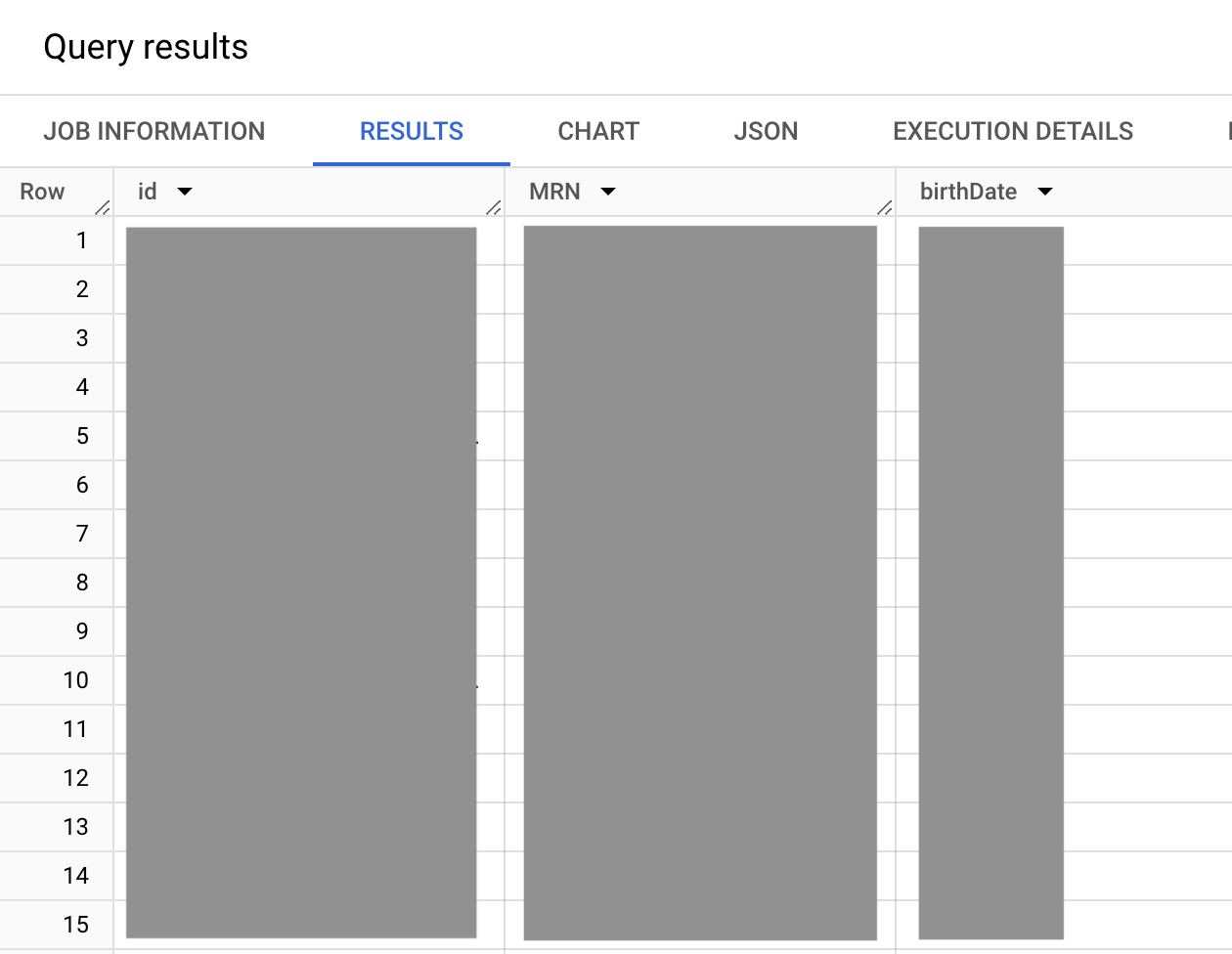
Na consulta anterior, o valor identifier.type.coding.code definido é o valor FHIR identifier definido que enumera os tipos de dados de identidade disponíveis, como o MRN (tipo de dados de identidade MR), documentos de identificação pessoal (tipo de dados de identidade DL) e número do passaporte (tipo de dados de identidade PPN). Como o valor identifier.type.coding é definido como uma matriz, pode haver qualquer número de identificadores listados para um paciente. Mas, nesse caso, você quer o MRN (tipo de dados de identidade MR).
Como unir a tabela do paciente a outras tabelas
Com base na consulta da tabela do paciente, mescle a tabela do paciente com outras tabelas neste conjunto de dados, como a tabela de condições. A tabela de condições é onde os diagnósticos dos pacientes são registrados.
A consulta de amostra a seguir recupera todas as entradas da condição médica de "hipertensão".
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
O resultado será assim:
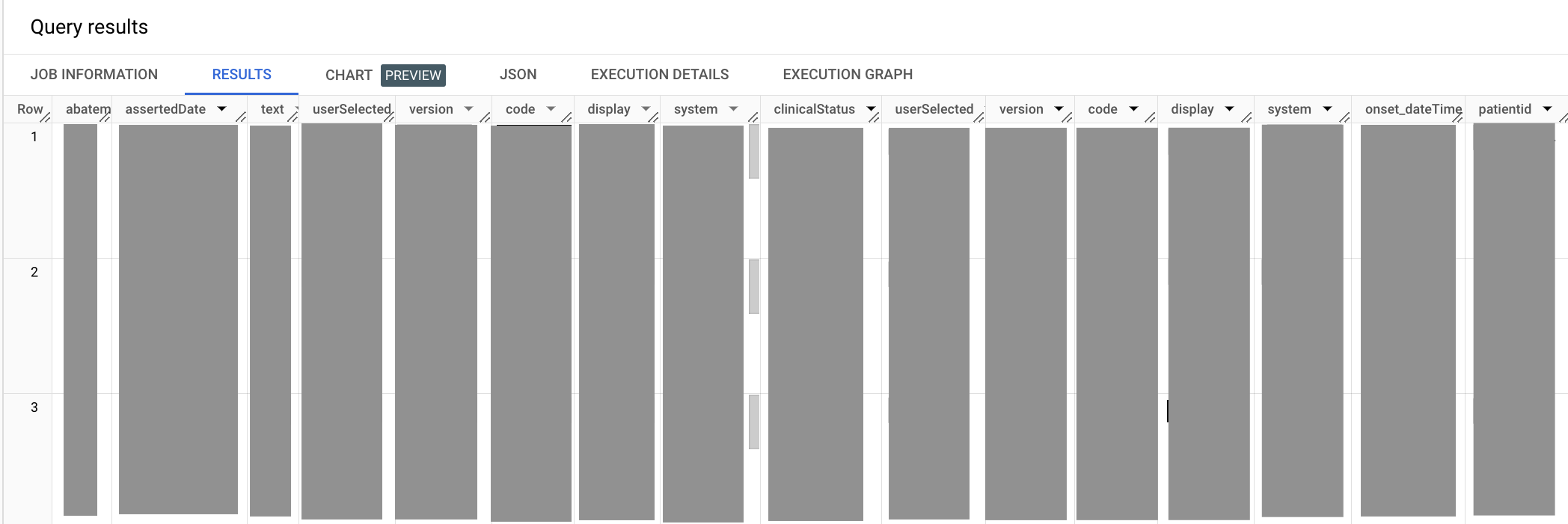
Na consulta anterior, você reutiliza o método UNNEST para simplificar o campo code.coding. Os elementos de código abatement.dateTime e onset.dateTime na instrução SELECT estão em um alias porque ambos terminam em dateTime, o que resultaria em nomes de coluna ambíguos na saída de uma instrução SELECT. Ao selecionar o código Hypertension, você também precisa declarar o sistema de terminologia de origem do código. Neste caso, o sistema de terminologia clínica SNOMED CT.
Como etapa final, use a chave subject.patientid para mesclar a tabela de condições com a tabela do paciente. Essa chave aponta para o identificador do próprio recurso do paciente no servidor FHIR.
Como reunir as consultas
No exemplo de consulta a seguir, você usa as consultas das duas seções anteriores e as une usando a cláusula WITH enquanto faz alguns cálculos simples.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
O resultado será assim:
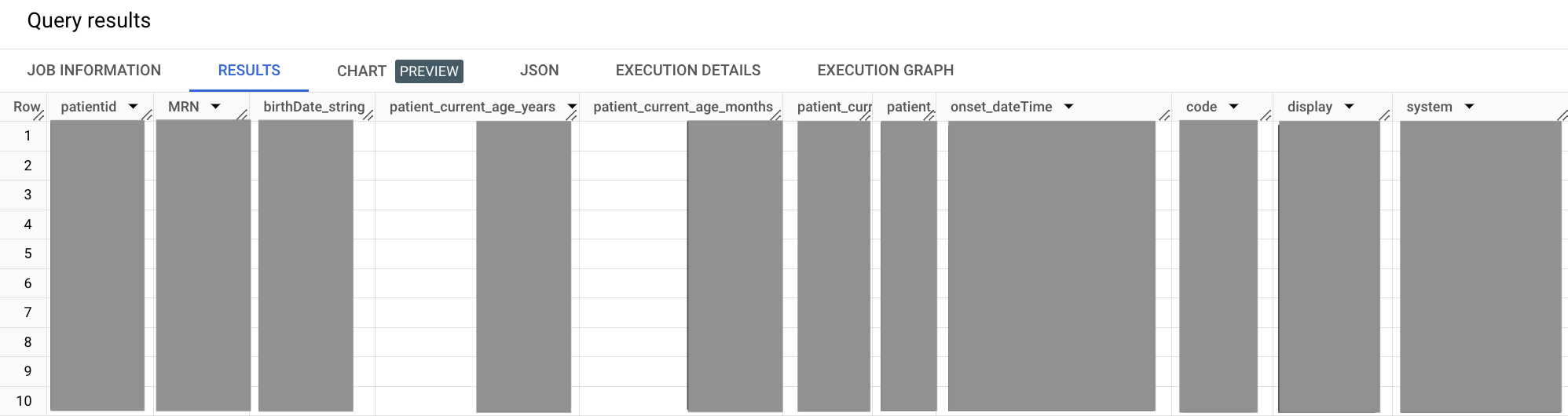
Na consulta de amostra anterior, a cláusula WITH permite isolar subconsultas nos próprios segmentos definidos. Essa abordagem pode ajudar com a legibilidade, que se torna mais importante à medida que sua consulta aumenta. Nesta consulta, você isola a subconsulta e condições de pacientes nos próprios segmentos WITH e os junta no segmento SELECT principal.
Também é possível aplicar cálculos a dados brutos. O código de amostra a seguir, uma instrução SELECT, mostra como calcular a idade do paciente no início da doença.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Conforme indicado no exemplo de código anterior, é possível executar várias
operações na string dateTime fornecida, condition.onset_dateTime. Primeiro, selecione o componente de data da string com o valor SUBSTR. Em seguida, converta a string em um tipo de dado DATE usando a sintaxe CAST. Também converta o campo patient.birthDate em um campo DATE.
Por fim, calcule a diferença entre as duas datas usando a função DATE_DIFF.
A seguir
- Analise dados clínicos usando o BigQuery e o AI Platform Notebooks.
- Como visualizar dados do BigQuery em um notebook do Jupyter.
- Segurança da API Cloud Healthcare.
- Controle de acesso do BigQuery.
- Soluções de saúde e ciências biológicas no Google Cloud Marketplace.
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.