En esta página, se hace referencia al parámetro
typeque forma parte de una medida.
typetambién se puede usar como parte de una dimensión o un filtro, que se describe en la página de documentación Dimensión, filtro y tipos de parámetros.
typetambién se puede usar como parte de un grupo de dimensiones, que se describe en la página de documentación del parámetrodimension_group.
Uso
measure: field_name {
type: measure_field_type
}
}
|
Jerarquía
type |
Tipos de campos posibles
MedirAcepta
Un tipo de medida |
En esta página, se incluyen detalles sobre los distintos tipos que se pueden asignar a una medida. Una medida solo puede tener un tipo y su valor predeterminado es string si no se especifica ningún tipo.
Algunos tipos de medición tienen parámetros complementarios, que se describen en la sección adecuada.
Medir categorías de tipos
Cada tipo de medición corresponde a una de las siguientes categorías. Estas categorías determinan si el tipo de medición realiza agregaciones, el tipo de campos a los que puede hacer referencia el tipo de medición y si puedes filtrar el tipo de medición con el parámetro filters:
- Medidas agregadas: Los tipos de mediciones agregadas realizan agregaciones, como
sumyaverage. Las medidas agregadas solo pueden hacer referencia a dimensiones, no a otras. Este es el único tipo de medición que funciona con el parámetrofilters. - Medidas no agregadas: Como sugiere el nombre, las medidas no agregadas son las que no realizan agregaciones, como
numberyyesno. Estos tipos de medición realizan transformaciones simples y, como no realizan agregaciones, solo pueden hacer referencia a medidas agregadas o dimensiones agregadas previamente. No puedes usar el parámetrofilterscon estos tipos de medición. - Medidas post-SQL: Las medidas post-SQL son tipos de medidas especiales que realizan cálculos específicos después de que Looker genera consultas en SQL. Solo pueden hacer referencia a medidas numéricas o dimensiones numéricas. No puedes usar el parámetro
filterscon estos tipos de medición.
Lista de definiciones de tipos
| Tipo | Categoría | Descripción |
|---|---|---|
average |
Agregación | Genera un promedio (media) de valores dentro de una columna. |
average_distinct |
Agregación | Genera correctamente un promedio (media) de valores cuando usas datos desnormalizados. Consulte la definición a continuación para obtener una descripción completa. |
count |
Agregación | Genera un recuento de filas |
count_distinct |
Agregación | Genera un recuento de valores únicos dentro de una columna. |
date |
No globales | Para medidas que contengan fechas |
list |
Agregación | Genera una lista de los valores únicos dentro de una columna. |
max |
Agregación | Genera el valor máximo dentro de una columna |
median |
Agregación | Genera la mediana (valor medio) de los valores dentro de una columna. |
median_distinct |
Agregación | Genera correctamente una mediana (valor medio) de los valores cuando una unión genera una distribución. Consulte la definición a continuación para obtener una descripción completa. |
min |
Agregación | Genera el valor mínimo dentro de una columna |
number |
No globales | Para medidas que contienen números |
percent_of_previous |
PosSQL | Genera la diferencia de porcentaje entre las filas que se muestran |
percent_of_total |
PosSQL | Genera el porcentaje del total para cada fila que se muestra |
percentile |
Agregación | Genera el valor en el percentil especificado dentro de una columna. |
percentile_distinct |
Agregación | Genera correctamente el valor en el percentil especificado cuando una unión genera una distribución. Consulte la definición a continuación para obtener una descripción completa. |
running_total |
PosSQL | Genera el total para cada fila que se muestra |
string |
No globales | Para medidas que contienen letras o caracteres especiales (como con la función GROUP_CONCAT de MySQL) |
sum |
Agregación | Genera una suma de valores dentro de una columna. |
sum_distinct |
Agregación | Genera correctamente una suma de valores cuando se usan datos desnormalizados. Consulta la definición a continuación para obtener una descripción completa. |
yesno |
No globales | Para campos que se mostrarán si algo es verdadero o falso |
int |
No globales |
REMOVED 5.4
Reemplazada por type: number |
average
type: average promedia los valores en un campo determinado. Es similar a la función AVG de SQL. Sin embargo, a diferencia de SQL sin procesar, Looker calculará los promedios de forma adecuada, incluso si las uniones de su consulta contienen distribuciones.
El parámetro sql para las mediciones type: average puede tomar cualquier expresión de SQL válida que den como resultado una columna de tabla numérica, una dimensión de LookML o una combinación de dimensiones de LookML.
Los campos type: average se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, el siguiente LookML crea un campo llamado avg_order promediando la dimensión sales_price y, luego, lo muestra en formato de dinero ($1,234.56):
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct se usa con conjuntos de datos desnormalizados. Promedia los valores no repetidos de un campo determinado según los valores únicos que define el parámetro sql_distinct_key.
Este es un concepto avanzado que se puede explicar más claramente con un ejemplo. Considera usar una tabla desnormalizada como la siguiente:
| ID de artículo del pedido | ID de pedido | Envío del pedido |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
En esta situación, puede ver que hay varias filas para cada pedido. En consecuencia, si agregaste una medida type: average simple para la columna order_shipping, obtendrías un valor de 16.00, aunque el promedio real sea 15.00.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
Para obtener un resultado preciso, puedes explicarle a Looker cómo debe identificar cada entidad única (en este caso, cada orden único) mediante el parámetro sql_distinct_key. Esto calculará el importe correcto de 15.00:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ten en cuenta que cada valor único de sql_distinct_key debe tener solo un valor correspondiente en sql. En otras palabras, el ejemplo anterior funciona porque todas las filas con un order_id de 1 tienen el mismo order_shipping de 10.00, todas las filas con un order_id de 2 tienen el mismo order_shipping de 20.00, y así sucesivamente.
Los campos type: average_distinct se pueden formatear mediante los parámetros value_format o value_format_name.
count
type: count realiza un recuento de tabla, similar a la función COUNT de SQL. Sin embargo, a diferencia de SQL sin procesar, Looker calculará correctamente los recuentos incluso si las uniones de su consulta contienen distribuciones.
Las medidas type: count no admiten el parámetro sql, ya que una medida type: count realiza recuentos de tablas según la clave primaria de la tabla. Si deseas realizar un recuento de la tabla en un campo que no sea la clave primaria de la tabla, usa una medida type: count_distinct.
Por ejemplo, la siguiente LookML crea un campo number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
Es muy común proporcionar un parámetro drill_fields (para campos) cuando se define una medida type: count, de modo que los usuarios puedan ver los registros individuales que conforman un recuento cuando hacen clic en él.
Cuando usas una medida de
type: counten Explorar, la visualización etiqueta los valores resultantes con el nombre de la vista en lugar de la palabra "Count". Para evitar confusiones, recomendamos pluralizar el nombre de la vista, seleccionar Mostrar nombre completo del campo en la sección Series en la configuración de visualización o utilizar unaview_labelcon una versión en plural de tu nombre de vista.
Si deseas realizar una COUNT (no una COUNT_DISTINCT) en un campo que no sea la clave primaria, puedes hacerlo con una medida de type: number. Si deseas obtener más información, consulta el artículo del Centro de ayuda Las diferencias entre los tipos de medición count y count_distinct.
Puedes agregar un filtro a una medida de type: count mediante el parámetro filters.
count_distinct
type: count_distinct calcula la cantidad de valores distintos en un campo determinado. Usa la función COUNT DISTINCT de SQL.
El parámetro sql para las medidas type: count_distinct puede tomar cualquier expresión de SQL válida que den como resultado una columna de la tabla, una dimensión de LookML o una combinación de dimensiones de LookML.
Por ejemplo, la siguiente imagen de LookML crea un campo number_of_unique_customers, que cuenta la cantidad de ID únicos de cliente:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
Puedes agregar un filtro a una medida de type: count_distinct mediante el parámetro filters.
date
type: date se usa con campos que contienen fechas.
El parámetro sql para las medidas type: date puede tomar cualquier expresión de SQL válida que genere una fecha. En la práctica, este tipo se usa con muy poca frecuencia, ya que la mayoría de las funciones de agregación de SQL no muestran fechas. Una excepción común es un MIN o MAX de una dimensión de fecha.
Crea una medida de fecha máxima o mínima con type: date
Si desea crear una medida de una fecha máxima o mínima, podría considerar inicialmente que usaría una medida type: max o type: min. Sin embargo, estos tipos de medición solo son compatibles con campos numéricos. En su lugar, puedes capturar una fecha máxima o mínima. Para ello, define una medida de type: date y une el campo de fecha al que se hace referencia en el parámetro sql en una función MIN() o MAX().
Supongamos que tiene un grupo de dimensiones de type: time, llamado updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
Puede crear una medida de type: date para capturar la fecha máxima de este grupo de dimensiones de la siguiente manera:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
En este ejemplo, en lugar de usar una medida de type: max para crear la medida last_updated_date, se aplica la función MAX() en el parámetro sql. La medida last_updated_date también tiene el parámetro convert_tz configurado en no para evitar la conversión de zona horaria doble, ya que la conversión de zona horaria ya se produjo en la definición del grupo de dimensiones updated. Para obtener más información, consulta la documentación sobre el parámetro convert_tz.
En el LookML de ejemplo para la medida last_updated_date, se podría omitir type: date, y el valor se trataría como una string, porque string es el valor predeterminado de type. Sin embargo, obtendrás una mejor capacidad de filtrado para los usuarios si usas type: date.
También puedes notar que la definición de medición last_updated_date hace referencia al período de tiempo de ${updated_raw} en lugar de ${updated_date}. Como el valor que muestra ${updated_date} es una string, es necesario usar ${updated_raw} para hacer referencia al valor de fecha real.
También puedes usar el parámetro datatype con type: date para mejorar el rendimiento de las consultas mediante la especificación del tipo de datos de fecha que usa tu tabla de base de datos.
Crea una medida máxima o mínima para una columna de fecha y hora
El cálculo máximo de una columna type: datetime es un poco diferente. En este caso, quieres crear una medida sin declarar el tipo, como se muestra a continuación:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list crea una lista de los valores distintos en un campo determinado. Es similar a la función GROUP_CONCAT de MySQL.
No es necesario incluir un parámetro sql para las medidas type: list. En su lugar, usarás el parámetro list_field para especificar la dimensión a partir de la que deseas crear listas.
El uso es el siguiente:
measure: field_name {
type: list
list_field: my_field_name
}
}
Por ejemplo, el siguiente LookML crea una name_list de medición basada en la dimensión name:
measure: name_list {
type: list
list_field: name
}
Ten en cuenta lo siguiente para list:
- El tipo de medida
listno admite el filtrado. No puedes usar el parámetrofiltersen una medidatype: list. - No se puede hacer referencia al tipo de medida
listcon el operador de sustitución ($). No puedes usar la sintaxis${}para hacer referencia a una medidatype: list.
Dialectos de base de datos compatibles para list
Para que Looker admita type: list en tu proyecto de Looker, el dialecto de la base de datos también debe admitirlo. En la siguiente tabla, se muestra qué dialectos son compatibles con type: list en la versión más reciente de Looker:
max
type: max encuentra el valor más grande en un campo determinado. Usa la función MAX de SQL.
El parámetro sql para las medidas de type: max puede tomar cualquier expresión de SQL válida que den como resultado una columna numérica de la tabla, una dimensión de LookML o una combinación de dimensiones de LookML.
Dado que las mediciones de type: max solo son compatibles con campos numéricos, no puedes usar una medida de type: max para encontrar una fecha máxima. En su lugar, puedes usar la función MAX() en el parámetro sql de una medida de type: date para capturar una fecha máxima, como se mostró antes en los ejemplos de la sección date.
Los campos type: max se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, el siguiente LookML crea un campo llamado largest_order observando la dimensión sales_price y, luego, lo muestra en formato de dinero ($1,234.56):
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
Por el momento, no puedes usar medidas type: max para strings o fechas, pero puedes agregar manualmente la función MAX a fin de crear un campo como este:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median muestra el valor de punto medio para los valores en un campo determinado. Esto es especialmente útil cuando los datos tienen pocos valores atípicos grandes o pequeños que distorsionen un promedio simple (media).
Considera usar una tabla como la siguiente:
ID de artículo del pedido | Costo | Punto medio -------------:|--------------: 2 | 10.00 | 4 | 10.00 | 3 | 20.00 | Valor de punto medio 1 | 80.00 | 5 | 90.00 |
Para facilitar la visualización, la tabla se ordena por costo, pero eso no afecta el resultado. Mientras que el tipo average mostraría 42 (que suma todos los valores y se dividirá por 5), el tipo median mostrará el valor de punto medio: 20.00.
Si hay un número par de valores, el valor medio se calcula tomando la media de los dos valores más cercanos al punto medio. Considera una tabla como esta con una cantidad par de filas:
ID de artículo del pedido | Costo | Punto medio -------------:|--------------: 2 | 10 | 3 | 20 | Más cercano antes del punto medio 1 | 80 | Más cercano después del punto medio 4 | 90
La mediana, el valor medio, es (20 + 80)/2 = 50.
La mediana también es igual al valor del percentil 50.
El parámetro sql para las mediciones type: median puede tomar cualquier expresión de SQL válida que den como resultado una columna de tabla numérica, una dimensión de LookML o una combinación de dimensiones de LookML.
Los campos type: median se pueden formatear mediante los parámetros value_format o value_format_name.
Ejemplo
Por ejemplo, el siguiente LookML crea un campo llamado median_order promediando la dimensión sales_price y, luego, lo muestra en formato de dinero ($1,234.56):
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
Consideraciones para median
Si usas median para un campo involucrado en una fanout, Looker intentará usar median_distinct en su lugar. Sin embargo, medium_distinct solo es compatible con ciertos dialectos. Si median_distinct no está disponible para tu dialecto, Looker muestra un error. Dado que el median se puede considerar el percentil 50, el error indica que el dialecto no admite percentiles distintos.
Dialectos de base de datos compatibles para median
Para que Looker admita el tipo median en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlo. En la siguiente tabla, se muestra qué dialectos admiten el tipo median en la versión más reciente de Looker:
Cuando hay una distribución involucrada en una consulta, Looker intenta convertir el median en median_distinct. Esto solo funciona en dialectos que admiten median_distinct.
median_distinct
Usa type: median_distinct cuando tu unión incluya un fanout. Promedia los valores no repetidos de un campo determinado según los valores únicos que define el parámetro sql_distinct_key. Si la medida no tiene un parámetro sql_distinct_key, Looker intenta usar el campo primary_key.
Considere el resultado de una consulta que une las tablas Order y Item:
| ID de artículo del pedido | ID de pedido | Envío del pedido |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
En esta situación, puede ver que hay varias filas para cada pedido. Esta consulta incluyó una distribución, ya que cada pedido se asigna a varios artículos del pedido. median_distinct toma esto en cuenta y encuentra la mediana entre los valores distintos 10, 20 y 50, por lo que obtendrás un valor de 20.
Para obtener un resultado preciso, puedes explicarle a Looker cómo debe identificar cada entidad única (en este caso, cada orden único) mediante el parámetro sql_distinct_key. Esto calculará el importe correcto:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Tenga en cuenta que cada valor único de sql_distinct_key debe tener solo un valor correspondiente en el parámetro sql de la medida. En otras palabras, el ejemplo anterior funciona porque todas las filas con un order_id de 1 tienen el mismo order_shipping de 10, todas las filas con un order_id de 2 tienen el mismo order_shipping de 20, y así sucesivamente.
Los campos type: median_distinct se pueden formatear mediante los parámetros value_format o value_format_name.
Consideraciones para median_distinct
El tipo de medida medium_distinct solo es compatible con ciertos dialectos. Si median_distinct no está disponible para el dialecto, Looker muestra un error. Dado que el median se puede considerar el percentil 50, el error indica que el dialecto no admite percentiles distintos.
Dialectos de base de datos compatibles para median_distinct
Para que Looker admita el tipo median_distinct en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlo. En la siguiente tabla, se muestra qué dialectos admiten el tipo median_distinct en la versión más reciente de Looker:
min
type: min encuentra el valor más pequeño en un campo determinado. Usa la función MIN de SQL.
El parámetro sql para las medidas de type: min puede tomar cualquier expresión de SQL válida que den como resultado una columna numérica de la tabla, una dimensión de LookML o una combinación de dimensiones de LookML.
Dado que las mediciones de type: min solo son compatibles con campos numéricos, no puedes usar una medida de type: min para encontrar una fecha mínima. En su lugar, puedes usar la función MIN() en el parámetro sql de una medida de type: date para capturar un mínimo, al igual que puedes usar la función MAX() con una medida de type: date para capturar una fecha máxima. Esto se muestra anteriormente en esta página en la sección date, que incluye ejemplos de cómo usar la función MAX() en el parámetro sql para encontrar una fecha máxima.
Los campos type: min se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, el siguiente LookML crea un campo llamado smallest_order observando la dimensión sales_price y, luego, lo muestra en formato de dinero ($1,234.56):
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
Por el momento, no puedes usar medidas type: min para strings o fechas, pero puedes agregar manualmente la función MIN a fin de crear un campo como este:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number se usa con números o números enteros. Una medida de type: number no realiza ninguna agregación y está diseñada para realizar transformaciones simples sobre otras medidas. Si define una medida basada en otra, la medida nueva debe ser type: number para evitar errores de agregación anidados.
El parámetro sql para las medidas type: number puede tomar cualquier expresión de SQL válida que den como resultado un número o un número entero.
Los campos type: number se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, el siguiente LookML crea una medida llamada total_gross_margin_percentage en función de las mediciones agregadas total_sale_price y total_gross_margin, luego la muestra en un formato de porcentaje con dos decimales (12.34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
En el ejemplo anterior, también se usa la función SQL NULLIF() para quitar la posibilidad de errores de división por cero.
Consideraciones para type: number
Hay varios aspectos importantes que debes tener en cuenta cuando uses las medidas type: number:
- Una medida de
type: numberpuede realizar aritméticas solo en otras medidas, no en otras dimensiones. - Las agregaciones simétricas de Looker no protegerán las funciones de agregación en el SQL de una medida
type: numbercuando se calculen en una unión. - El parámetro
filtersno se puede usar con las medidastype: number, pero en la documentación defiltersse explica una solución alternativa. type: numbermedidas no proporcionarán sugerencias a los usuarios.
percent_of_previous
type: percent_of_previous calcula la diferencia de porcentaje entre una celda y la celda anterior de su columna.
El parámetro sql para las mediciones type: percent_of_previous debe hacer referencia a otra medida numérica.
Los campos type: percent_of_previous se pueden formatear mediante los parámetros value_format o value_format_name. Sin embargo, los formatos de porcentaje del parámetro value_format_name no funcionan con las medidas type: percent_of_previous. Estos formatos de porcentaje multiplican los valores por 100, lo que sesga los resultados de un porcentaje de cálculo anterior.
En el siguiente ejemplo, este LookML crea una medida count_growth basada en la medida count:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
En la IU de Looker, se vería de la siguiente manera:

Ten en cuenta que los valores percent_of_previous dependen del orden de clasificación. Si cambias el orden, debes volver a ejecutar la consulta para volver a calcular los valores percent_of_previous. En los casos en que se dinamiza una consulta, percent_of_previous se ejecuta en la fila en lugar de en la columna. Por el momento, no puedes cambiar este comportamiento.
Además, las medidas percent_of_previous se calculan después de que se muestran los datos de tu base de datos. Esto significa que no debes hacer referencia a una medida percent_of_previous dentro de otra medida, ya que podrían calcularse en diferentes momentos y es posible que no obtengas resultados precisos. También significa que no se pueden filtrar las medidas percent_of_previous.
percent_of_total
type: percent_of_total calcula la parte total de una celda del total de una celda. El porcentaje se calcula en función del total de las filas que muestra tu consulta y no el total de todas las filas posibles. Sin embargo, si los datos que muestra tu consulta exceden el límite de filas, los valores del campo aparecerán como nulos, ya que necesita los resultados completos para calcular el porcentaje del total.
El parámetro sql para las mediciones type: percent_of_total debe hacer referencia a otra medida numérica.
Los campos type: percent_of_total se pueden formatear mediante los parámetros value_format o value_format_name. Sin embargo, los formatos de porcentaje del parámetro value_format_name no funcionan con las medidas type: percent_of_total. Estos formatos de porcentaje multiplican los valores por 100, lo que sesga los resultados de un cálculo de percent_of_total.
En el siguiente ejemplo, este LookML crea una medida percent_of_total_gross_margin basada en la medida total_gross_margin:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
En la IU de Looker, se vería de la siguiente manera:
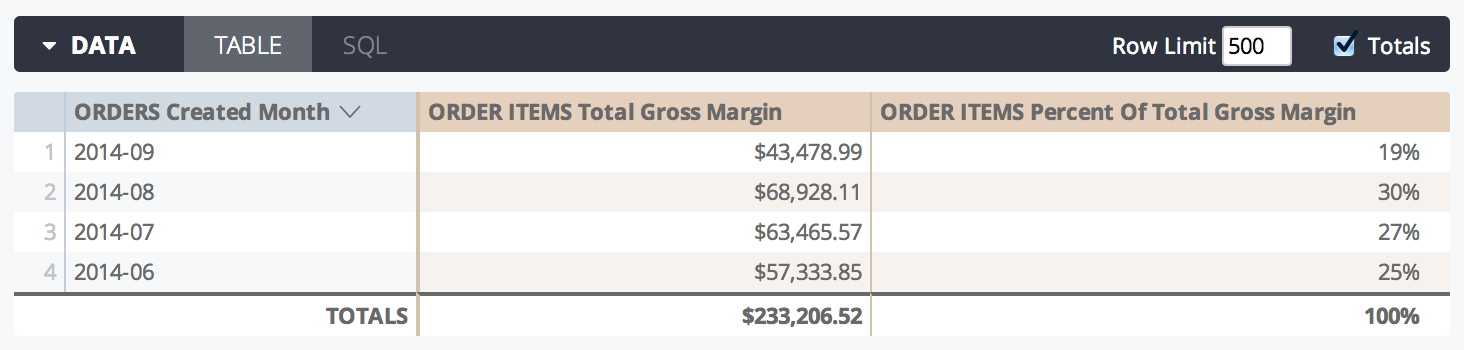
En los casos en que se dinamiza una consulta, percent_of_total se ejecuta en la fila en lugar de en la columna. Si no quieres que esto suceda, agrega direction: "column" a la definición de la medida.
Además, las medidas percent_of_total se calculan después de que se muestran los datos de tu base de datos. Esto significa que no debes hacer referencia a una medida percent_of_total dentro de otra medida, ya que podrían calcularse en diferentes momentos y es posible que no obtengas resultados precisos. También significa que no se pueden filtrar las medidas percent_of_total.
percentile
type: percentile muestra el valor en el percentil especificado de valores en un campo determinado. Por ejemplo, si especificas el percentil 75, se mostrará el valor que sea superior al 75% de los otros valores del conjunto de datos.
Para identificar el valor que se muestra, Looker calcula la cantidad total de valores de datos y multiplica el percentil especificado por la cantidad total de valores de datos. Sin importar cómo se ordenen realmente, Looker identifica el orden relativo de los valores de datos en el aumento del valor. El valor de datos que muestra Looker depende de si el cálculo genera un número entero o no, como se explica a continuación.
Si el valor calculado no es un número entero
Looker redondea el valor calculado hacia arriba y lo usa para identificar el valor de datos que se mostrará. En este conjunto de 19 puntuaciones de prueba de ejemplo, el percentil 75 se identificaría con 19 * 0.75 = 14.25, lo que significa que el 75% de los valores se encuentran en los primeros 14 valores de datos, es decir, debajo de la posición 15. Por lo tanto, Looker muestra el valor de datos 15 (87) como más del 75% de los valores de datos.

Si el valor calculado es un número entero
En este caso un poco más complejo, Looker muestra un promedio del valor de los datos en esa posición y el siguiente valor de datos. Para entenderlo, considere un conjunto de 20 puntuaciones de prueba. El percentil 75 se identificaría con 20 * 0.75 = 15, lo que significa que el valor de los datos en la posición 15 forma parte del percentil 75 y debemos mostrar un valor que esté superior al 75%. Al mostrar el promedio de los valores en la posición 15 (82) y la 16 (87), Looker se asegura de que 75%. Ese promedio (84.5) no existe en el conjunto de valores de datos, pero sería mayor que el 75% de los valores de datos.

Parámetros obligatorios y opcionales
Usa la palabra clave percentile: para especificar el valor fraccionario, es decir, el porcentaje de los datos que deben estar por debajo del valor que se muestra. Por ejemplo, usa percentile: 75 para especificar el valor en el percentil 75 en el orden de los datos, o percentile: 10 a fin de mostrar el valor en el percentil 10. Si deseas encontrar el valor en el percentil 50, puedes especificar percentile: 50 o simplemente usar el tipo mediana.
El parámetro sql para las mediciones type: percentile puede tomar cualquier expresión de SQL válida que den como resultado una columna de tabla numérica, una dimensión de LookML o una combinación de dimensiones de LookML.
Los campos type: percentile se pueden formatear mediante los parámetros value_format o value_format_name.
Ejemplo
Por ejemplo, el siguiente LookML crea un campo llamado test_scores_75th_percentile que muestra el valor en el percentil 75 en la dimensión test_scores:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
Consideraciones para percentile
Si usas percentile para un campo involucrado en una distribución, Looker intentará usar percentile_distinct en su lugar. Si percentile_distinct no está disponible para el dialecto, Looker muestra un error. Para obtener más información, consulta los dialectos compatibles con percentile_distinct.
Dialectos de base de datos compatibles para percentile
Para que Looker admita el tipo percentile en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlo. En la siguiente tabla, se muestra qué dialectos admiten el tipo percentile en la versión más reciente de Looker:
percentile_distinct
El type: percentile_distinct es una forma especializada de percentil y se debe usar cuando la unión implica un fanout. Usa los valores no repetidos en un campo determinado según los valores únicos definidos por el parámetro sql_distinct_key. Si la medida no tiene un parámetro sql_distinct_key, Looker intenta usar el campo primary_key.
Considere el resultado de una consulta que une las tablas Order y Item:
| ID de artículo del pedido | ID de pedido | Envío del pedido |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
En esta situación, puede ver que hay varias filas para cada pedido. Esta consulta incluyó una distribución, ya que cada pedido se asigna a varios artículos del pedido. percentile_distinct toma esto en cuenta y encuentra el valor de percentil con los diferentes valores 10, 20, 50, 70 y 110. El percentil 25 mostrará el segundo valor distinto, o 20, mientras que el percentil 80 mostrará el promedio del cuarto y el quinto valor, o 90.
Parámetros obligatorios y opcionales
Usa la palabra clave percentile: para especificar el valor fraccionario. Por ejemplo, usa percentile: 75 para especificar el valor en el percentil 75 en el orden de los datos, o percentile: 10 a fin de mostrar el valor en el percentil 10. Si intentas encontrar el valor en el percentil 50, puedes usar el tipo median_distinct en su lugar.
Para obtener un resultado preciso, especifica cómo Looker debe identificar cada entidad única (en este caso, cada orden único) mediante el parámetro sql_distinct_key.
Aquí tienes un ejemplo del uso de percentile_distinct para mostrar el valor en el percentil 90:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Tenga en cuenta que cada valor único de sql_distinct_key debe tener solo un valor correspondiente en el parámetro sql de la medida. En otras palabras, el ejemplo anterior funciona porque todas las filas con order_id de 1 tienen el mismo order_shipping de 10, todas las filas con order_id de 2 tienen el mismo order_shipping de 20, y así sucesivamente.
Los campos type: percentile_distinct se pueden formatear mediante los parámetros value_format o value_format_name.
Consideraciones para percentile_distinct
Si percentile_distinct no está disponible para el dialecto, Looker muestra un error. Para obtener más información, consulta los dialectos compatibles con percentile_distinct.
Dialectos de base de datos compatibles para percentile_distinct
Para que Looker admita el tipo percentile_distinct en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlo. En la siguiente tabla, se muestra qué dialectos admiten el tipo percentile_distinct en la versión más reciente de Looker:
running_total
type: running_total calcula una suma acumulativa de las celdas en una columna. No se puede usar para calcular sumas en una fila, a menos que la fila sea el resultado de una tabla dinámica.
El parámetro sql para las mediciones type: running_total debe hacer referencia a otra medida numérica.
Los campos type: running_total se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, el siguiente LookML crea una medida cumulative_total_revenue basada en la medida total_sale_price:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
En la IU de Looker, se vería de la siguiente manera:

Ten en cuenta que los valores running_total dependen del orden de clasificación. Si cambias el orden, debes volver a ejecutar la consulta para volver a calcular los valores de running_total. En los casos en que se dinamiza una consulta, running_total se ejecuta en la fila en lugar de en la columna. Si no quieres que esto suceda, agrega direction: "column" a la definición de la medida.
Además, las medidas running_total se calculan después de que se muestran los datos de tu base de datos. Esto significa que no debes hacer referencia a una medida running_total dentro de otra medida, ya que podrían calcularse en diferentes momentos y es posible que no obtengas resultados precisos. También significa que no se pueden filtrar las medidas running_total.
string
type: string se usa con campos que contienen letras o caracteres especiales.
El parámetro sql para las medidas type: string puede tomar cualquier expresión de SQL válida que den como resultado una string. En la práctica, este tipo se usa con muy poca frecuencia, ya que la mayoría de las funciones de agregación de SQL no muestran strings. Una excepción común es la función GROUP_CONCAT de MySQL, aunque Looker proporciona type: list para ese caso práctico.
Por ejemplo, el siguiente LookML crea un campo category_list mediante la combinación de los valores únicos de un campo llamados category:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
En este ejemplo, se podría omitir type: string, porque string es el valor predeterminado de type.
sum
type: sum suma los valores de un campo determinado. Es similar a la función SUM de SQL. Sin embargo, a diferencia de SQL sin procesar, Looker calculará correctamente las sumas, incluso si las uniones de su consulta contienen distribuciones.
El parámetro sql para las mediciones type: sum puede tomar cualquier expresión de SQL válida que den como resultado una columna de tabla numérica, una dimensión de LookML o una combinación de dimensiones de LookML.
Los campos type: sum se pueden formatear mediante los parámetros value_format o value_format_name.
Por ejemplo, la siguiente LookML crea un campo llamado total_revenue mediante la adición de la dimensión sales_price, luego la muestra en un formato de dinero ($1,234.56):
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct se usa con conjuntos de datos desnormalizados. Suma los valores no repetidos de un campo determinado según los valores únicos que define el parámetro sql_distinct_key.
Este es un concepto avanzado que se puede explicar más claramente con un ejemplo. Considera usar una tabla desnormalizada como la siguiente:
| ID de artículo del pedido | ID de pedido | Envío del pedido |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
En esta situación, puede ver que hay varias filas para cada pedido. En consecuencia, si agregaste una medida type: sum simple para la columna order_shipping, obtendrías un total de 80.00, aunque el total de envíos recopilados sea en realidad de 30.00.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
Para obtener un resultado preciso, puedes explicarle a Looker cómo debe identificar cada entidad única (en este caso, cada orden único) mediante el parámetro sql_distinct_key. Esto calculará el importe correcto de 30.00:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ten en cuenta que cada valor único de sql_distinct_key debe tener solo un valor correspondiente en sql. En otras palabras, el ejemplo anterior funciona porque todas las filas con un order_id de 1 tienen el mismo order_shipping de 10.00, todas las filas con un order_id de 2 tienen el mismo order_shipping de 20.00, y así sucesivamente.
Los campos type: sum_distinct se pueden formatear mediante los parámetros value_format o value_format_name.
yesno
type: yesno crea un campo que indica si algo es verdadero o falso. En la IU de Explorar, los valores aparecen como Sí y No.
El parámetro sql para una medida type: yesno toma una expresión SQL válida que se evalúa como TRUE o FALSE. Si la condición se evalúa como TRUE, se muestra Sí al usuario. De lo contrario, se muestra No.
La expresión de SQL para las medidas type: yesno debe incluir solo agregaciones, lo que significa agregaciones de SQL o referencias a medidas de LookML. Si quieres crear un campo yesno que incluya una referencia a una dimensión de LookML o una expresión de SQL que no sea una agregación, usa una dimensión con type: yesno, no una medida.
De manera similar a las mediciones con type: number, una medida con type: yesno no realiza ninguna agregación; solo hace referencia a otras agregaciones.
Por ejemplo, la medida de total_sale_price que aparece a continuación es la suma del precio total de venta de los artículos de un pedido. Una segunda medida llamada is_large_total es type: yesno. La medida is_large_total tiene un parámetro sql que evalúa si el valor total_sale_price es mayor que $1,000.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
Si deseas hacer referencia a un campo type: yesno en otro campo, debes tratar el campo type: yesno como booleano (en otras palabras, como si ya tuviera un valor verdadero o falso). Por ejemplo:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
}
# This is correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}