No Looker, uma tabela derivada é uma consulta cujos resultados são usados como se fosse uma tabela real no banco de dados.
Por exemplo, é possível ter uma tabela de banco de dados chamada orders que tem muitas colunas. Você quer calcular algumas métricas agregadas no nível do cliente, como quantos pedidos foram feitos por cada cliente ou quando cada um deles fez o primeiro pedido. Com uma tabela derivada nativa ou uma tabela derivada baseada em SQL, é possível criar uma nova tabela de banco de dados chamada customer_order_summary que inclui essas métricas.
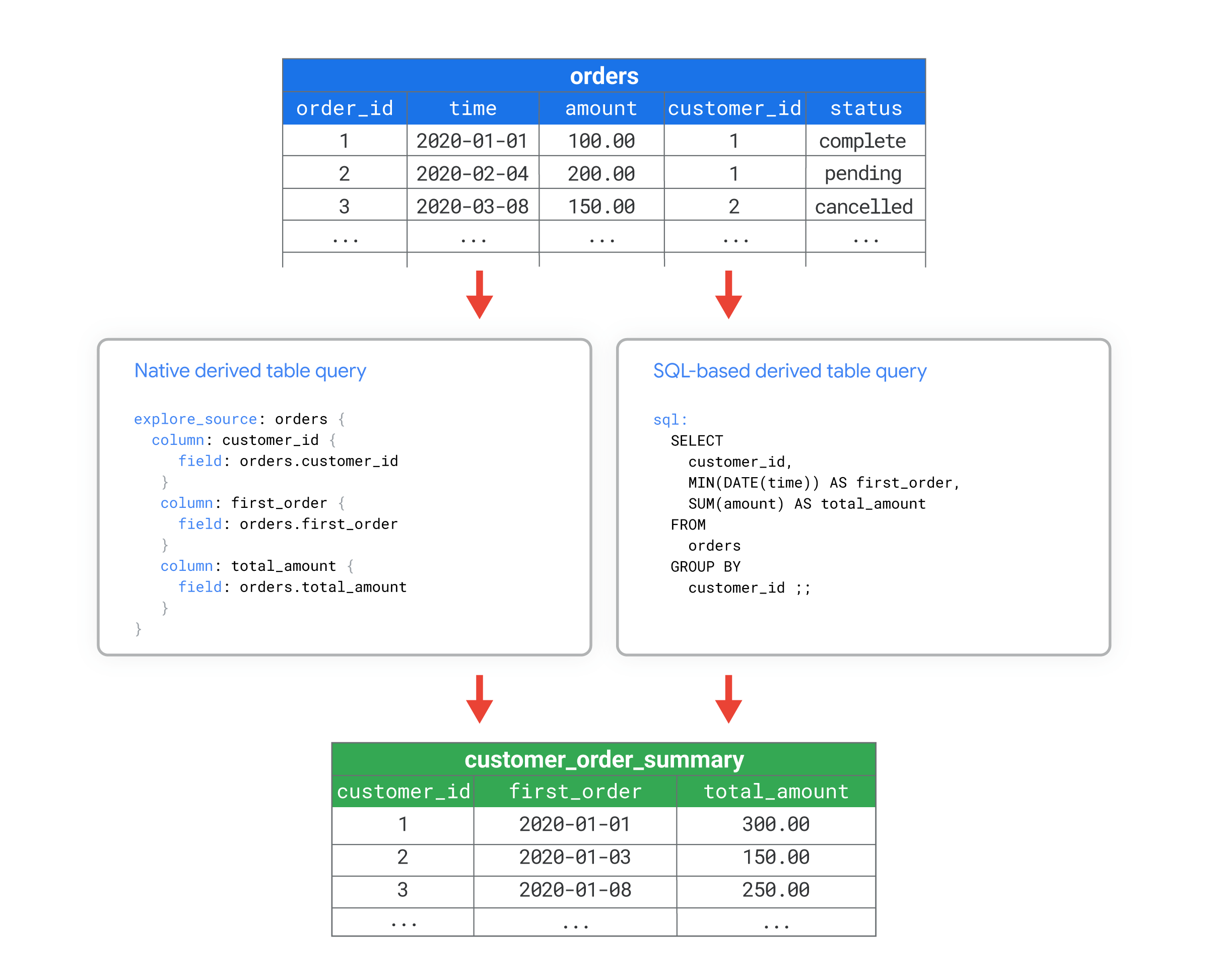
Em seguida, você pode trabalhar com a tabela derivada customer_order_summary como se fosse qualquer outra tabela no banco de dados.
Tabelas nativas nativas e tabelas derivadas de SQL
Para criar uma tabela derivada no projeto do Looker, use o parâmetro derived_table em um parâmetro de visualização. No parâmetro derived_table, é possível definir a consulta para a tabela derivada de duas maneiras:
- Para uma tabela derivada nativa, você define a tabela derivada com uma consulta baseada em LookML.
- Para uma tabela derivada baseada em SQL, defina a tabela derivada com uma consulta SQL.
Por exemplo, os arquivos de visualização a seguir mostram como usar o LookML para criar uma visualização da tabela derivada customer_order_summary. As duas versões do LookML ilustram como é possível criar tabelas derivadas equivalentes usando o LookML ou o SQL para definir a consulta para a tabela derivada:
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
As duas versões criam uma visualização chamada customer_order_summary, que é baseada na tabela orders, com as colunas customer_id, first_order, e total_amount.
Além do parâmetro derived_table e dos subparâmetros, a visualização customer_order_summary funciona como qualquer outro arquivo de visualização. Ao definir a consulta da tabela derivada com o LookML ou o SQL, é possível criar dimensões e dimensões de LookML baseadas nas colunas da tabela derivada.
Depois de definir a tabela derivada, use-a como qualquer outra tabela no banco de dados.
Tabelas derivadas nativas
As tabelas derivadas nativas têm como base as consultas definidas usando termos do LookML. Para criar uma tabela derivada nativa, use o parâmetro explore_source dentro do parâmetro derived_table de um parâmetro view. É possível criar as colunas da tabela derivada nativa consultando as dimensões ou medidas do LookML no seu modelo. Consulte o arquivo nativo de visualização da tabela derivada no exemplo anterior.
Em comparação com as tabelas derivadas baseadas em SQL, as tabelas derivadas nativas são muito mais fáceis de ler e entender à medida que você modela seus dados.
Consulte a página de documentação Como criar tabelas derivadas nativas para ver detalhes sobre como criar tabelas derivadas nativas.
Tabelas derivadas baseadas em SQL
Para criar uma tabela derivada baseada em SQL, defina uma consulta em termos de SQL, criando colunas na tabela usando uma consulta SQL. Não é possível consultar dimensões e medidas do LookML em uma tabela derivada baseada em SQL. Consulte o arquivo de visualização em tabela derivado baseado em SQL no exemplo anterior.
Geralmente, você define a consulta SQL usando o parâmetro sql dentro do parâmetro derived_table de um parâmetro view.
Um atalho útil para criar consultas baseadas em SQL no Looker é usar o SQL Runner para criar a consulta SQL e transformá-la em uma definição de tabela derivada.
Alguns casos extremos não permitem o uso do parâmetro sql. Nesses casos, o Looker oferece suporte aos seguintes parâmetros para definir uma consulta SQL para tabelas derivadas permanentes (PDTs, na sigla em inglês):
create_process: quando você usa o parâmetrosqlpara uma PDT, em segundo plano o Looker envolve a dialetoCREATE TABLEDDL (Linguagem de definição de dados) da consulta para criar o PDT a partir da sua consulta SQL. Alguns dialetos não são compatíveis com uma instrução SQLCREATE TABLEem uma única etapa. Para esses dialetos, não é possível criar um PDT com o parâmetrosql. Em vez disso, use o parâmetrocreate_processpara criar um PDT em várias etapas. Consulte a página de documentação dos parâmetroscreate_processpara ver mais informações e exemplos.sql_create: se o caso de uso exigir comandos DDL personalizados e o dialeto oferecer suporte a DDL (por exemplo, o BigQuery ML preditivo do Google), use o parâmetrosql_createpara criar um PDT em vez de usar o parâmetrosql. Consulte a página de documentação dosql_createpara ver mais informações e exemplos.
Independentemente de você usar o parâmetro sql, create_process ou sql_create, em todos esses casos, você vai definir a tabela derivada com uma consulta SQL. Todas essas tabelas são consideradas tabelas derivadas baseadas em SQL.
Ao definir uma tabela derivada baseada em SQL, atribua um alias limpo a cada coluna usando AS. Isso ocorre porque você precisará fazer referência aos nomes das colunas do conjunto de resultados nas suas dimensões, como ${TABLE}.first_order. É por isso que o exemplo anterior usa MIN(DATE(time)) AS first_order em vez de apenas MIN(DATE(time)).
Tabelas derivadas temporárias e permanentes (PDTs)
Além da distinção entre as tabelas derivadas nativas e baseadas em SQL, também há uma distinção entre uma tabela derivada temporária (não gravada no banco de dados) e uma tabela derivada permanente, ou PDT (escrito em um esquema de raspadinha no banco de dados).
As tabelas derivadas nativas e baseadas em SQL podem ser temporárias ou persistentes.
Tabelas derivadas temporárias
As tabelas derivadas mostradas anteriormente são exemplos de tabelas derivadas temporárias. Elas são temporárias porque não há uma estratégia de persistência definida no parâmetro derived_table.
As tabelas derivadas temporárias não são gravadas no banco de dados. Quando um usuário executa uma consulta "Explorar" envolvendo uma ou mais tabelas derivadas, o Looker constrói uma consulta SQL usando uma combinação específica do SQL para as tabelas derivadas, além dos campos, mesclas e valores de filtro solicitados. Se a combinação já tiver sido executada e os resultados ainda forem válidos no cache, o Looker usará os resultados em cache. Consulte a página de documentação Como armazenar em cache as consultas e recriar PDTs com grupos de dados para mais informações sobre o armazenamento em cache das consultas no Looker.
Caso contrário, se o Looker não puder usar os resultados armazenados em cache, ele precisará executar uma nova consulta no banco de dados sempre que um usuário solicitar dados de uma tabela derivada temporária. Por isso, é importante garantir que suas tabelas derivadas temporárias tenham um bom desempenho e não sobrecarreguem demais o banco de dados. Nos casos em que a consulta levará algum tempo para ser executada, uma PDT costuma ser uma opção melhor.
Dialetos do banco de dados compatíveis com tabelas derivadas temporárias
Para que o Looker ofereça suporte a tabelas derivadas em seu projeto do Looker, o dialeto do banco de dados também precisará torná-las compatíveis. A tabela a seguir mostra quais dialetos são compatíveis com tabelas derivadas na versão mais recente do Looker:
Tabelas derivadas permanentes (PDTs, na sigla em inglês)
Uma tabela derivada permanente (PDT, na sigla em inglês) é uma tabela derivada gravada em um esquema de raspadinha no banco de dados e gerada novamente na programação que você especifica com uma estratégia de persistência.
Um PDT pode ser uma tabela derivada nativa ou uma tabela derivada baseada em SQL.
Requisitos para PDTs
Para usar PDTs no seu projeto do Looker, você precisa de:
- Um dialeto de banco de dados compatível com PDTs. Consulte a seção Dialetos de banco de dados compatíveis com PDTs posteriormente nesta página para ver as listas de dialetos compatíveis com tabelas derivadas permanentes baseadas em SQL e tabelas derivadas nativas permanentes.
- Um esquema de raspadinha no banco de dados. Qualquer esquema pode ser usado no seu banco de dados, mas recomendamos criar um novo que será usado apenas para esse fim. Seu administrador de banco de dados precisa configurar o esquema com permissão de gravação para o usuário do banco de dados do Looker.
- Uma conexão Looker que esteja configurada com a opção Tabelas derivadas permanentes ativada. Isso geralmente é estabelecido quando você configura inicialmente sua conexão do Looker (consulte as páginas de documentação de dialetos do Looker para ver instruções para seu dialeto do banco de dados), mas também é possível ativar PDTs para sua conexão após a configuração inicial.
Dialetos do banco de dados com suporte a PDTs
Para que o Looker ofereça suporte a PDTs no seu projeto do Looker, o dialeto do banco de dados também precisará torná-lo compatível.
Para oferecer suporte a qualquer tipo de PDT (com base em LookML ou SQL), o dialeto precisa oferecer suporte a gravações no banco de dados, entre outros requisitos. Algumas configurações de banco de dados somente leitura não permitem que a persistência funcione (em geral, bancos de dados de réplica de hot-swap do Postgres). Nesses casos, é possível usar tabelas derivadas temporárias.
A tabela a seguir mostra os dialetos compatíveis com as tabelas derivadas baseadas em SQL permanentes na versão mais recente do Looker:
Para oferecer compatibilidade com tabelas derivadas nativas permanentes (que têm consultas baseadas em LookML), o dialeto também precisa ser compatível com uma função DDL CREATE TABLE. Veja uma lista dos dialetos compatíveis com tabelas derivadas nativas (baseadas em LookML) permanentes na versão mais recente do Looker:
Como criar PDTs de modo incremental
Você pode criar PDTs incrementais no seu projeto, se o dialeto oferecer suporte a eles. Um PDT incremental é uma tabela derivada permanente (PDT, na sigla em inglês) que o Looker cria anexando novos dados à tabela em vez de reconstruí-la totalmente. Consulte a página de documentação de PDTs incrementais para mais informações.
Dialetos do banco de dados compatíveis com PDTs incrementais
Para que o Looker ofereça suporte a PDTs incrementais no seu projeto do Looker, o dialeto do banco de dados também precisa apoiá-los. A tabela a seguir mostra quais dialetos são compatíveis com PDTs incrementais na versão mais recente do Looker:
Como criar tabelas derivadas permanentes (PDTs, na sigla em inglês)
Para transformar uma tabela derivada em uma tabela derivada permanente (PDT, na sigla em inglês), defina uma estratégia de persistência para a tabela. Para otimizar o desempenho, adicione também uma estratégia de otimização.
Estratégias de persistência
A persistência de uma tabela derivada pode ser gerenciada pelo Looker ou, para dialetos compatíveis com visualizações materializadas, pelo seu banco de dados usando visualizações materializadas.
Para tornar uma tabela derivada permanente, adicione um dos seguintes parâmetros à definição derived_table:
- Parâmetros de persistência gerenciados pelo Looker:
- Parâmetros de persistência gerenciados pelo banco de dados:
Com estratégias de persistência baseadas em gatilho (datagroup_trigger, sql_trigger e interval_trigger), o Looker mantém a PDT no banco de dados até que a PDT seja acionada para a recriação. Quando o PDT é acionado, o Looker recria o PDT para substituir a versão anterior. Isso significa que, com PDTs baseados em gatilhos, os usuários não precisarão esperar pela PDT ser criada para receber respostas a consultas de Explorar do PDT.
datagroup_trigger
Os grupos de dados são o método mais flexível de criação de persistência. Se você tiver definido um datagroup para suas políticas de armazenamento em cache, poderá usar o parâmetro datagroup_trigger para iniciar a recriação do PDT na mesma programação das políticas de armazenamento em cache.
O Looker mantém o PDT no banco de dados até que seu grupo de dados seja acionado. Quando o grupo de dados é acionado, o Looker recria a PDT para substituir a versão anterior. Isso significa que, na maioria dos casos, seus usuários não precisarão esperar pela criação do PDT. Se um usuário solicitar dados da PDT enquanto ela está sendo criada e os resultados da consulta não estiverem no cache, o Looker retornará dados da PDT atual até que a nova PDT seja criada. Consulte a página de documentação Como armazenar em cache as consultas e recriar PDTs com grupos de dados para ter uma visão geral dos grupos de dados.
Consulte a seção sobre o regenerador do Looker para mais informações sobre como ele gera PDTs.
sql_trigger_value
O parâmetro sql_trigger_value aciona a regeneração de um PDT com base em uma instrução SQL que você fornecer. Se o resultado da instrução SQL for diferente do valor anterior, a PDT será gerada novamente. Caso contrário, a PDT atual será mantida no banco de dados. Isso significa que, na maioria dos casos, seus usuários não precisarão esperar pela criação do PDT. Se um usuário solicitar dados da PDT enquanto ela está sendo criada e os resultados da consulta não estiverem no cache, o Looker retornará dados da PDT atual até que a nova PDT seja criada.
Consulte a seção sobre o regenerador do Looker para mais informações sobre como ele gera PDTs.
interval_trigger
O parâmetro interval_trigger aciona a regeneração de uma PDT com base em um intervalo de tempo que você fornece, como "24 hours" ou "60 minutes". De modo semelhante ao parâmetro sql_trigger, isso significa que normalmente o PDT será pré-criado quando os usuários o consultarem. Se um usuário solicitar dados da PDT enquanto ela está sendo criada e os resultados da consulta não estiverem no cache, o Looker retornará dados da PDT atual até que a nova PDT seja criada.
persist_for
Outra opção é usar o parâmetro persist_for para definir o período de armazenamento da tabela derivada antes de ser marcada como expirada, para que ela não seja mais usada para consultas e seja descartada do banco de dados.
Uma PDT persist_for é criada quando um usuário executa uma consulta na primeira vez. Em seguida, o Looker mantém a PDT no banco de dados pelo período especificado no parâmetro persist_for da PDT' Se um usuário consultar a PDT no prazo persist_for, o Looker usará os resultados armazenados em cache, se possível, ou executará a consulta na PDT.
Após persist_for vez, o Looker limpa a PDT do seu banco de dados, e a PDT será recriada na próxima vez que um usuário a consultar, o que significa que a consulta precisará aguardar a reconstrução.
As PDTs que usam persist_for não são recriadas automaticamente pelo regenerador do Looker, exceto no caso de uma cascata de dependências de PDTs. Quando uma tabela persist_for faz parte de uma cascata de dependência com PDTs baseados em gatilho (PDTs que usam a estratégia de persistência datagroup_trigger, interval_trigger ou sql_trigger_value), o regenerador monitora e recria a tabela persist_for para recriar outras tabelas na cascata. Consulte a seção Como o Looker cria tabelas derivadas em cascata nesta página.
materialized_view: yes
As visualizações materializadas permitem que você aproveite a funcionalidade do seu banco de dados para manter as tabelas derivadas no seu projeto do Looker. Se o dialeto do banco de dados for compatível com visualizações materializadas e sua conexão Looker estiver configurada com a opção Tabelas derivadas permanentes ativada, você poderá criar uma visualização materializada especificando materialized_view: yes para uma tabela derivada. As visualizações materializadas são compatíveis com tabelas derivadas nativas e tabelas derivadas baseadas em SQL.
Assim como uma tabela derivada permanente (PDT, na sigla em inglês), uma visualização materializada é um resultado de consulta armazenado como uma tabela no esquema de raspadinha do banco de dados. A principal diferença entre uma PDT e uma visualização materializada é a atualização das tabelas:
- Para PDTs, a estratégia de persistência é definida no Looker e ela é gerenciada pelo Looker.
- Para visualizações materializadas, o banco de dados é responsável por manter e atualizar os dados na tabela.
Por isso, a funcionalidade de visualização materializada exige conhecimento avançado do dialeto e dos recursos dele. Na maioria dos casos, o banco de dados atualizará a visualização materializada sempre que detectar novos dados nas tabelas consultadas por ela. As visualizações materializadas são ideais para cenários que exigem dados em tempo real.
Consulte a página de documentação do parâmetro materialized_view para ver informações sobre suporte, requisitos e considerações importantes sobre o dialeto.
Estratégias de otimização
Como os PDTs são armazenados no seu banco de dados, otimize-os usando as seguintes estratégias, como apoiadas pelo seu dialeto:
Por exemplo, para adicionar persistência ao exemplo da tabela derivada, defina-a para ser recriada quando o grupo de dados orders_datagroup for acionado e adicione índices em customer_id e first_order, desta maneira:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Se você não adicionar um índice (ou um equivalente para seu dialeto), o Looker avisará que precisa fazer isso para melhorar o desempenho da consulta.
Casos de uso de PDTs
Os PDTs são úteis porque, quando um usuário solicita dados de uma tabela, geralmente a tabela já terá sido criada, reduzindo o tempo de consulta e a carga do banco de dados.
Como prática recomendada geral, os desenvolvedores devem tentar modelar dados sem usar PDTs até que seja absolutamente necessário.
Em alguns casos, os dados podem ser otimizados de outras maneiras. Por exemplo, adicionar um índice ou alterar um tipo de dados de uma coluna pode resolver um problema sem a necessidade de criar um PDT. Analise os planos de execução de consultas lentas usando a ferramenta Explicar do SQL Runner.
Além de reduzir o tempo da consulta e a carga do banco de dados em consultas executadas com frequência, há vários outros casos de uso de PDTs, incluindo:
Também é possível usar uma PDT para definir uma chave primária nos casos em que não há uma maneira razoável de identificar uma linha única em uma tabela como uma chave primária.
Como usar PDTs para testar otimizações
É possível usar PDTs para testar diferentes índices, distribuições e outras opções de otimização sem precisar de uma grande quantidade de suporte dos desenvolvedores de DBA ou ETL.
Considere um caso em que você tem uma tabela, mas quer testar índices diferentes. O LookML inicial para a visualização pode ser assim:
view: customer {
sql_table_name: warehouse.customer ;;
}
Para testar estratégias de otimização, use o parâmetro indexes e adicione índices ao LookML da seguinte forma:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Consulte a visualização uma vez para gerar o PDT. Em seguida, execute as consultas de teste e compare os resultados. Se os resultados forem favoráveis, peça à equipe de DBA ou ETL para adicionar os índices à tabela original.
Altere o código de visualização novamente para remover o PDT.
Como usar PDTs para pré-mesclar ou agregar dados
Pode ser útil pré-agregar ou agregar dados para ajustar a otimização de consultas em volumes altos ou em vários tipos de dados.
Por exemplo, suponha que você queira gerar relatórios de clientes por coorte com base no momento em que fizeram o primeiro pedido. A execução dessa consulta pode ser cara várias vezes, sempre que os dados forem necessários em tempo real. No entanto, é possível calcular a consulta apenas uma vez e, em seguida, reutilizar os resultados com um PDT:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id&, order_id, order_sequence, first_order_date]
}
}
Tabelas derivadas de cascata
É possível fazer referência a uma tabela derivada na definição de outra, criando uma cadeia de tabelas derivadas em cascata ou PDTs em cascata, conforme o caso. Um exemplo de tabelas derivadas em cascata seria uma tabela, TABLE_D, que depende de outra tabela, TABLE_C, enquanto TABLE_C depende de TABLE_B, e TABLE_B depende de TABLE_A.
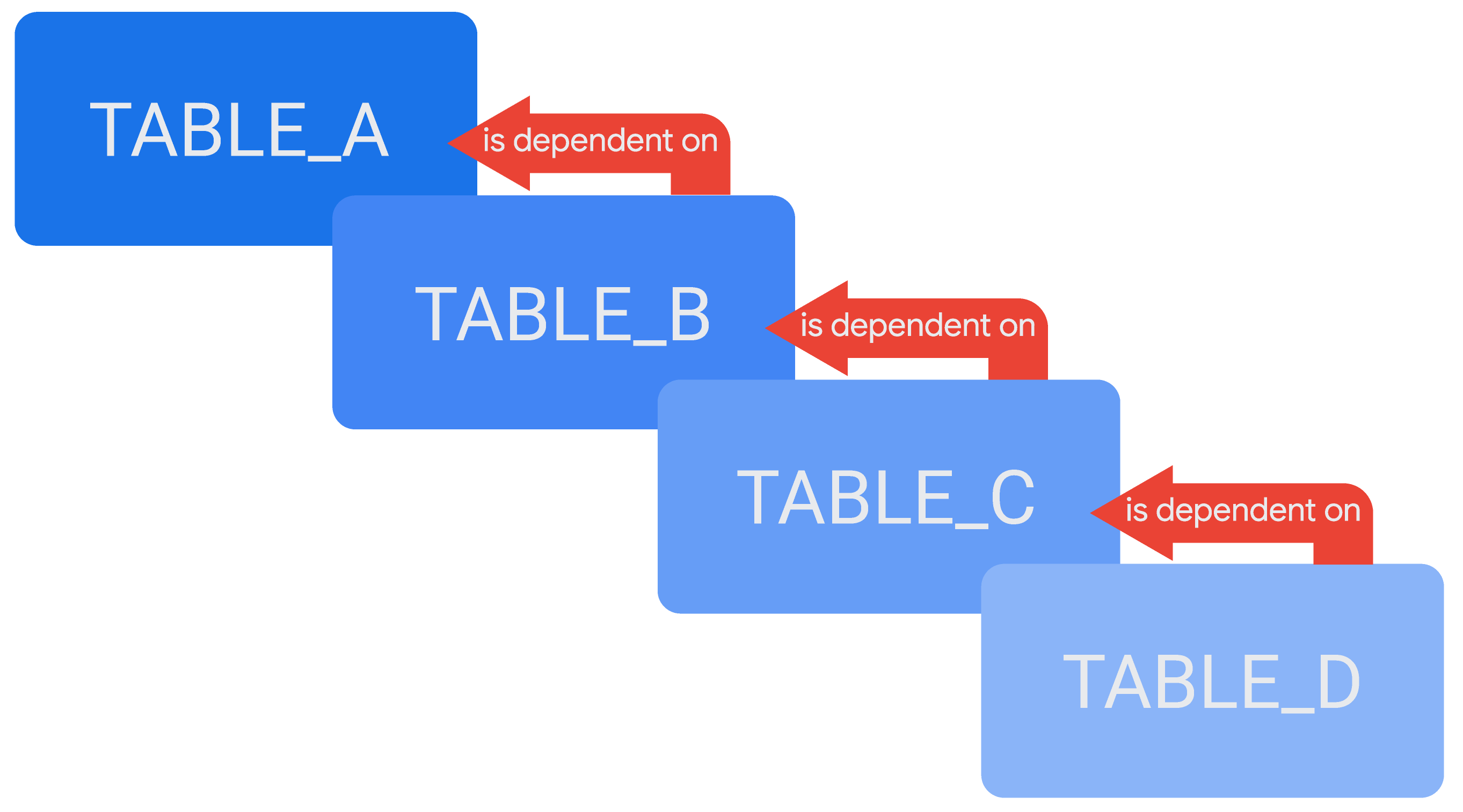
Sintaxe de uma tabela derivada
Para fazer referência a uma tabela derivada em outra tabela derivada, use esta sintaxe:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
Nesse formato, SQL_TABLE_NAME é uma string literal. Por exemplo, é possível referenciar a tabela derivada clean_events com esta sintaxe:
`${clean_events.SQL_TABLE_NAME}`
É possível usar essa mesma sintaxe para se referir a uma visualização do LookML. Novamente, nesse caso, a SQL_TABLE_NAME é uma string literal.
No próximo exemplo, a PDT clean_events é criada a partir da tabela events no banco de dados. A PDT clean_events não inclui linhas indesejadas da tabela do banco de dados events. Em seguida, é mostrada uma segunda PDT. A PDT event_summary é um resumo da PDT clean_events. A tabela event_summary é gerada novamente sempre que novas linhas são adicionadas ao clean_events.
O PDT do event_summary e o PDT do clean_events são PDTs em cascata, em que event_summary depende do clean_events (já que event_summary é definido usando o PDT do clean_events). Esse exemplo específico poderia ser feito de maneira mais eficiente em uma única PDT, mas é útil para demonstrar as referências de tabelas derivadas.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Embora não seja sempre necessário, quando você se refere a uma tabela derivada dessa maneira, muitas vezes é útil criar um alias para a tabela usando este formato:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
O exemplo anterior faz isto:
${clean_events.SQL_TABLE_NAME} AS clean_events
É útil usar um alias porque, nos bastidores, as PDTs são nomeadas com códigos longos no seu banco de dados. Em alguns casos (especialmente com cláusulas ON), é fácil esquecer que você precisa usar a sintaxe ${derived_table_or_view_name.SQL_TABLE_NAME} para recuperar esse nome longo. Um alias pode ajudar a evitar esse tipo de erro.
Como o Looker cria tabelas derivadas em cascata
No caso de cascata de tabelas derivadas temporárias, se os resultados da consulta de um usuário não estiverem no cache, o Looker criará todas as tabelas derivadas necessárias para a consulta. Se você tiver um TABLE_D em que a definição contém uma referência para TABLE_C, TABLE_D será dependente de TABLE_C. Isso significa que, se você consultar TABLE_D e a consulta não estiver no cache do Looker, o Looker vai recriar TABLE_D. No entanto, primeiro é necessário recriar TABLE_C.
Agora, vamos usar um cenário de tabelas derivadas temporárias em cascata em que TABLE_D depende de TABLE_C, que depende de TABLE_B, que depende de TABLE_A. Se o Looker não tiver resultados válidos para uma consulta em TABLE_C no cache, o Looker criará todas as tabelas necessárias para a consulta. O Looker vai criar TABLE_A, depois TABLE_B e depois TABLE_C:
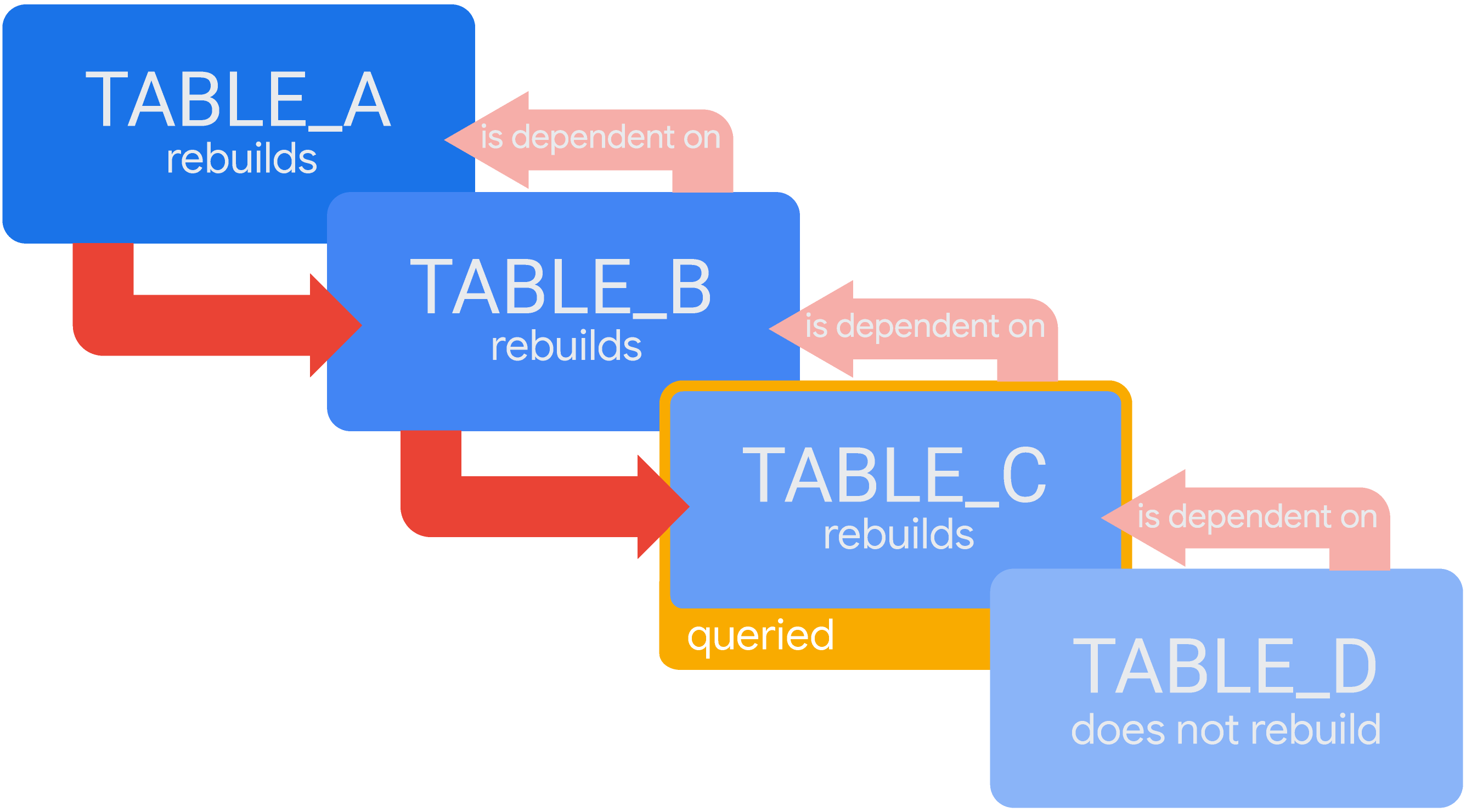
Nesse cenário, a TABLE_A precisa ser gerada antes que o Looker possa começar a gerar TABLE_B e assim por diante, até que TABLE_C seja concluído e o Looker possa fornecer os resultados da consulta. Como TABLE_D não é necessário para responder a essa consulta, o Looker não recriará TABLE_D no momento.
Consulte a página de documentação do parâmetro datagroup para ver um exemplo de cenário de PDTs em cascata que usam o mesmo grupo de dados.
A mesma lógica básica se aplica a PDTs: o Looker criará qualquer tabela necessária para responder a uma consulta, até a cadeia de dependências. Mas com PDTs, geralmente é o caso de que as tabelas já existem e não precisam ser recriadas. Com consultas de usuário padrão sobre PDTs em cascata, o Looker recria os PDTs na cascata apenas se não houver uma versão válida dos PDTs no banco de dados. Se você quiser forçar uma recriação de todos os PDTs em cascata, é possível recriar manualmente as tabelas para uma consulta em uma exploração.
Um ponto lógico importante a entender é que, no caso de uma cascata PDT, um PDT dependente está essencialmente consultando o PDT de que ele depende. Isso é significativo especialmente para PDTs que usam a estratégia persist_for. Normalmente, as PDTs persist_for são criadas quando um usuário as consulta, permanecem no banco de dados até que o intervalo persist_for aumente, e não são recriadas até serem consultadas pela próxima vez por um usuário. No entanto, se um PDT persist_for fizer parte de uma cascata com PDTs baseados em gatilho (PDTs que usam a estratégia de persistência datagroup_trigger, interval_trigger ou sql_trigger_value), o PDT persist_for será basicamente consultado sempre que os PDTs dependentes forem recriados. Portanto, nesse caso, a PDT persist_for será recriada de acordo com a programação de PDTs dependentes. Isso significa que as PDTs de persist_for podem ser afetadas pela estratégia de persistência dos dependentes.
Como recriar manualmente tabelas permanentes para uma consulta
Os usuários podem selecionar a opção Recriar tabelas derivadas e execução no menu "Explorar" para substituir as configurações de persistência e recriar todas as PDTs e tabelas agregadas necessárias para a consulta atual em "Explorar":
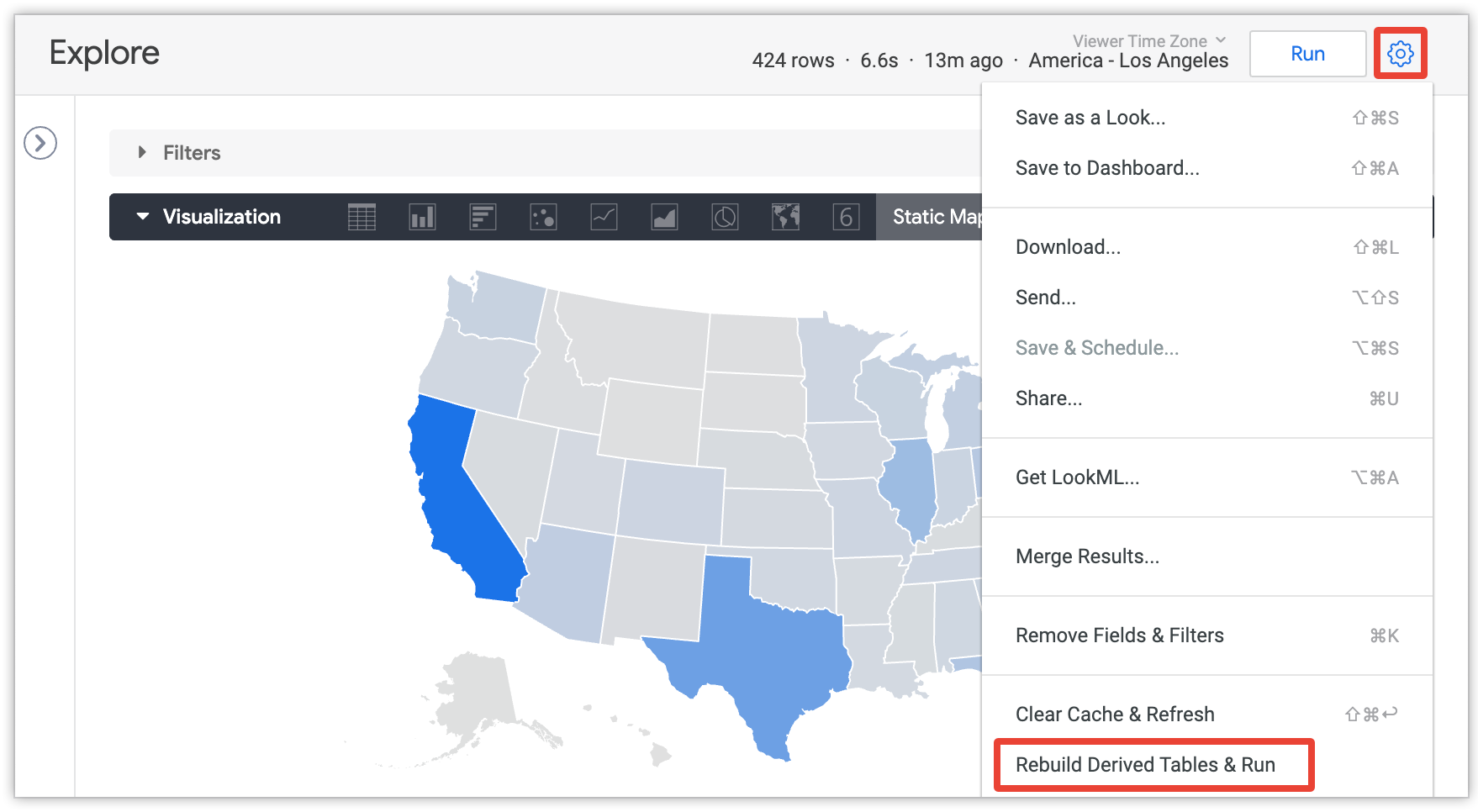
Essa opção só é visível para usuários com a permissão develop e após o carregamento da consulta do Explorar.
A opção Recriar tabelas derivadas e execução recria todas as tabelas persistentes (todas as PDTs e tabelas agregadas) que são necessárias para responder à consulta, independentemente da estratégia de persistência. Isso inclui todas as tabelas de agregação e PDTs na consulta atual, além de todas as tabelas de agregação e PDTs referenciados pelas tabelas de agregação e PDTs na consulta atual.
No caso de PDTs incrementais, a opção Recriar tabelas derivadas e execução aciona o build de um novo incremento. Com PDTs incrementais, um incremento inclui o período especificado no parâmetro increment_key e também o número de períodos anteriores especificados no parâmetro increment_offset, se houver. Consulte a página de documentação PDTs incrementais para ver alguns exemplos de cenários que mostram como os PDTs incrementais são criados, dependendo da configuração.
No caso de PDTs em cascata, isso significa recriar todas as tabelas derivadas na cascata, começando do topo. Esse comportamento é igual ao de uma tabela em uma cascata de tabelas derivadas temporárias:
Observe o seguinte sobre a recriação manual de tabelas derivadas:
- Para o usuário que inicia a operação Recriar tabelas derivadas & executar, a consulta irá esperar que as tabelas sejam recriadas antes de carregar os resultados. As consultas de outros usuários continuarão usando as tabelas atuais. Quando as tabelas persistentes forem recriadas, todos os usuários usarão as tabelas recriadas. Esse processo é projetado para evitar a interrupção de consultas de outros usuários enquanto as tabelas são reconstruídas, mas esses usuários ainda podem ser afetados pela carga adicional no banco de dados. Se você estiver em uma situação em que o acionamento de uma recriação durante o horário de funcionamento pode sobrecarregar seu banco de dados de forma inaceitável, talvez seja necessário informar aos usuários que eles nunca devem reconstruir determinados PDTs ou tabelas de agregação durante esse horário.
Se um usuário estiver no modo de desenvolvimento, e a ferramenta Explorar for baseada em uma tabela de desenvolvimento, a operação Recriar tabelas derivadas e execução recriará a tabela de desenvolvimento, não a tabela de produção, para a exploração. Mas, se o Explorar no Modo de desenvolvimento estiver usando a versão de produção de uma tabela derivada, a tabela de produção será reconstruída. Consulte Tabelas persistentes no modo de desenvolvimento para mais informações sobre tabelas de desenvolvimento e de produção.
Para instâncias hospedadas pelo Looker, se a tabela derivada levar mais de uma hora para ser recriada, ela não será recriada e a sessão do navegador expirará. Consulte o artigo Tempo limite de fila e fila de consultas na Central de Ajuda para saber mais sobre o tempo limite que pode afetar os processos do Looker.
Tabelas mantidas no modo de desenvolvimento
O Looker tem alguns comportamentos especiais para gerenciar tabelas persistentes no Modo de desenvolvimento.
Se você consultar uma tabela persistente no modo de desenvolvimento sem alterar a definição, o Looker consultará a versão de produção dessa tabela. Se você fizer a mudança na definição da tabela que afeta os dados ou a forma como ela é consultada, uma nova versão de desenvolvimento será criada na próxima vez que você consultar a tabela no modo de desenvolvimento. Com uma tabela de desenvolvimento, é possível testar as alterações sem afetar os usuários finais.
O que pede ao Looker para criar uma tabela de desenvolvimento
Quando possível, o Looker usa a tabela de produção atual para responder a consultas, independentemente de você estar no modo de desenvolvimento ou não. Mas há alguns casos em que o Looker não pode usar a tabela de produção para consultas no modo de desenvolvimento:
- Se a tabela persistente tiver um parâmetro que restringe o conjunto de dados para trabalhar mais rapidamente no modo de desenvolvimento
- Se você fez alterações na definição da tabela persistente que afeta os dados dela.
O Looker criará uma tabela de desenvolvimento se você estiver no modo de desenvolvimento e consultar uma tabela derivada baseada em SQL definida com uma cláusula WHERE condicional com instruções if prod e if dev.
Para tabelas persistentes que não têm um parâmetro para restringir o conjunto de dados no modo de desenvolvimento, o Looker usa a versão de produção da tabela para responder a consultas no modo de desenvolvimento, a menos que você altere a definição da tabela e depois consulte a tabela no modo de desenvolvimento. Isso vale para qualquer alteração na tabela que afete os dados ou a forma como ela é consultada.
Veja alguns exemplos dos tipos de alterações que solicitarão que o Looker crie uma versão de desenvolvimento de uma tabela persistente. O Looker criará a tabela somente se você consultar a tabela posteriormente depois de fazer essas alterações:
- a alteração da consulta em que a tabela permanente se baseia, como a modificação do parâmetro
explore_source,sql,query,sql_createoucreate_processna tabela permanente ou em qualquer tabela necessária (no caso de tabelas derivadas em cascata). - Mudança na estratégia de persistência da tabela, como modificar o parâmetro
datagroup_trigger,sql_trigger_value,interval_triggeroupersist_forda tabela. - Mudar o nome de uma tabela derivada
view - Mudar o
increment_keyouincrement_offsetde um PDT incremental. - Alterar o
connectionusado pelo modelo associado
Para alterações que não modifiquem os dados da tabela ou afetem a forma como o Looker consulta a tabela, o Looker não criará uma tabela de desenvolvimento. O parâmetro publish_as_db_view é um bom exemplo: no modo de desenvolvimento, se você alterar apenas a configuração publish_as_db_view para uma tabela derivada, o Looker não precisará recriar a tabela derivada, portanto, não criará uma tabela de desenvolvimento.
Por quanto tempo o Looker persiste nas tabelas de desenvolvimento
Independentemente da estratégia de persistência real da tabela, o Looker trata as tabelas persistentes de desenvolvimento como se tivessem uma estratégia de persistência de persist_for: "24 hours". O Looker faz isso para garantir que as tabelas de desenvolvimento não sejam mantidas por mais de um dia, já que um desenvolvedor do Looker pode consultar muitas iterações de uma tabela durante o desenvolvimento e cada vez que uma nova tabela de desenvolvimento é criada. Para evitar que as tabelas de desenvolvimento poluam o banco de dados, o Looker aplica a estratégia persist_for: "24 hours". Isso garante que as tabelas sejam limpas com frequência no banco de dados.
Caso contrário, o Looker cria PDTs e tabelas agregadas no modo de desenvolvimento da mesma forma que cria tabelas persistentes no modo de produção.
Se uma tabela de desenvolvimento for mantida no seu banco de dados quando você implantar alterações em um PDT ou em uma tabela de agregação, o Looker poderá usar essa tabela como a tabela de produção. Dessa forma, seus usuários não precisarão esperar a tabela ser criada ao consultar a tabela.
Quando você implanta as alterações, a tabela ainda precisa ser recriada para ser consultada na produção, dependendo da situação:
- Caso já tenha se passado mais de 24 horas desde que você consultou a tabela no modo de desenvolvimento, a versão de desenvolvimento da tabela é marcada como expirada e não vai ser usada para consultas. É possível verificar PDTs não criados usando o ambiente de desenvolvimento integrado do Looker ou a guia Desenvolvimento da página Tabelas derivadas permanentes. Se você tiver PDTs não criados, poderá consultá-los no modo de desenvolvimento antes de fazer as alterações para que a tabela de desenvolvimento esteja disponível para uso na produção.
- Se uma tabela persistente tiver o parâmetro
dev_filters(para tabelas derivadas nativas) ou a cláusula condicional condicional que está usando as instruçõesif prodeif dev(para tabelas derivadas baseadas em SQL), a tabela de desenvolvimento não poderá ser usada como a versão de produção, porque a versão de desenvolvimento tem um conjunto de dados abreviado. Se esse for o caso, depois que você terminar de desenvolver a tabela e antes de implantar as alterações, comente o parâmetrodev_filtersou a cláusula condicionalWHEREe consulte a tabela no modo de desenvolvimento. O Looker criará uma versão completa da tabela que poderá ser usada para produção quando você implantar suas alterações.
Caso contrário, se você implantar as alterações quando não houver uma tabela de desenvolvimento válida que possa ser usada como a tabela de produção, o Looker a recriará na próxima vez que a tabela for consultada no Modo de produção (para tabelas persistentes que usam a estratégia persist_for) ou na próxima vez que o regenerador for executado (para tabelas persistentes que usam datagroup_trigger, interval_trigger ou sql_trigger_value).
Como verificar PDTs não criados no modo de desenvolvimento
Se uma tabela de desenvolvimento for mantida no seu banco de dados quando você implantar alterações em um PDT ou em uma tabela de agregação, o Looker poderá usar essa tabela como a tabela de produção. Dessa forma, seus usuários não precisarão esperar a tabela ser criada ao consultar a tabela. Consulte as seções Por quanto tempo o Looker persiste nas tabelas de desenvolvimento e O que solicita ao Looker para criar uma tabela de desenvolvimento nesta página para mais detalhes.
Portanto, o ideal é que todos os PDTs sejam criados durante a implantação na produção. Assim, as tabelas podem ser usadas imediatamente como as versões de produção.
Você pode verificar se há PDTs não criados no seu projeto no painel Integridade do projeto. Clique no ícone Project Health no ambiente de desenvolvimento integrado do Looker para abrir o painel Integridade do projeto. Depois clique no botão Validar status PDT.
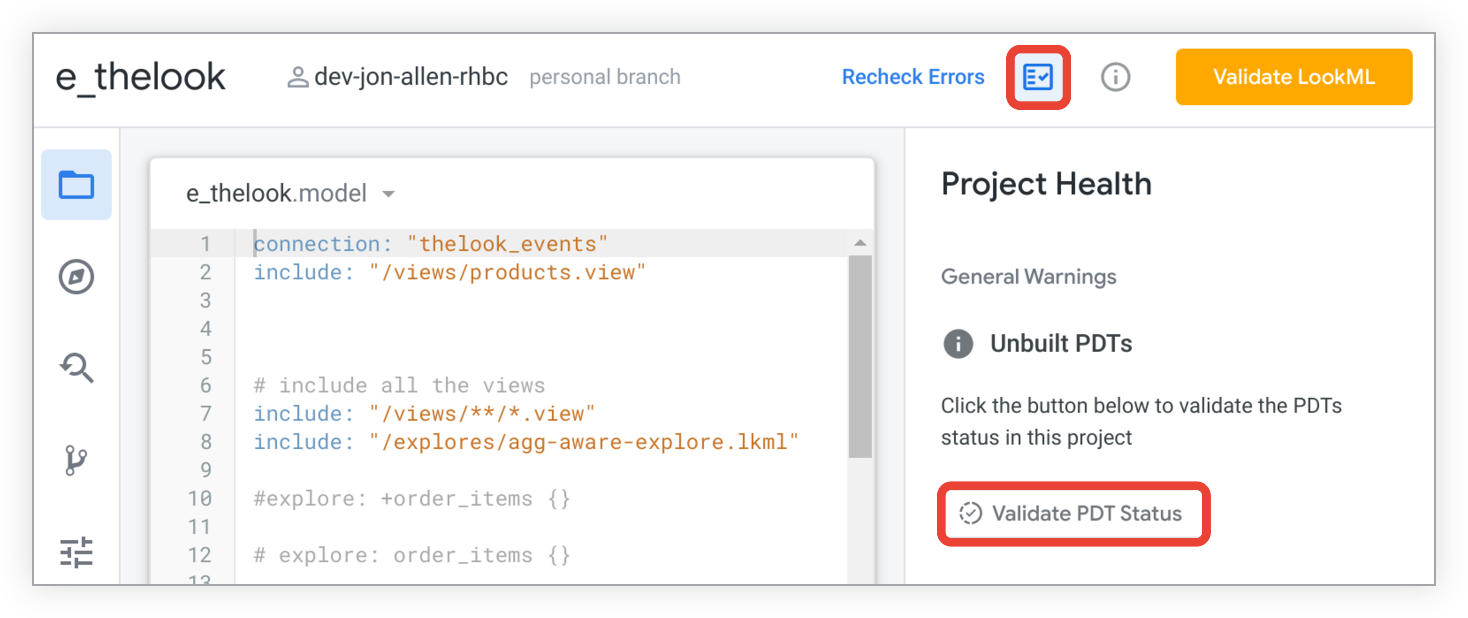 Se houver PDTs não criados, o painel Integridade do projeto vai listá-los:
Se houver PDTs não criados, o painel Integridade do projeto vai listá-los:
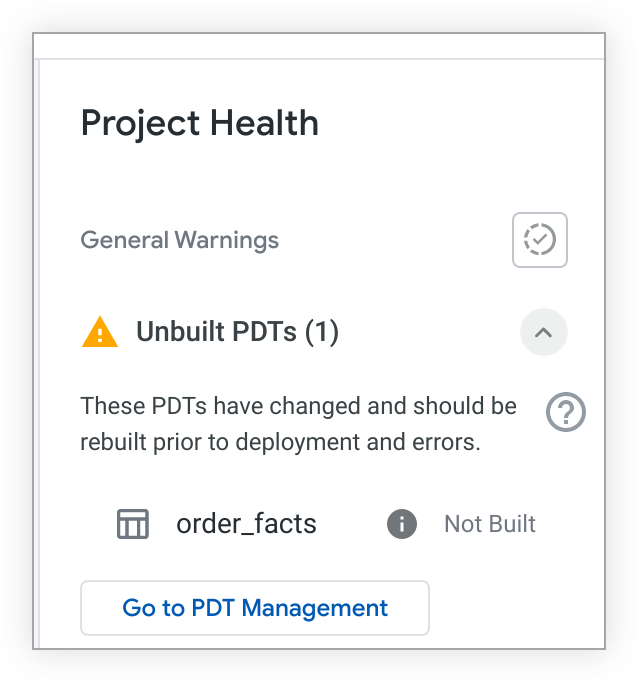
Se você tiver a permissão see_pdts, clique no botão Go to PDT Management. O Looker abrirá a guia Desenvolvimento da página Tabelas derivadas permanentes e filtrará os resultados do projeto específico do LookML. Com base nisso, é possível ver quais PDTs de desenvolvimento foram criados ou não e acessar outras informações de solução de problemas. Consulte a página de documentação Configurações do administrador: tabelas derivadas permanentes para saber mais.
Depois de identificar um PDT não criado no seu projeto, você pode criar uma versão de desenvolvimento abrindo uma guia"Explorar"que consulta a tabela e, em seguida, usando a opção Recriar tabelas derivadas e executar no menu"Explorar". Consulte a seção Como recriar tabelas permanentes manualmente para uma consulta nesta página.
Compartilhamento e limpeza de tabelas
Em qualquer instância do Looker, as tabelas persistentes serão compartilhadas entre os usuários se as tabelas tiverem a mesma definição e a mesma configuração do método de persistência. Além disso, se uma definição de tabela deixa de existir, o Looker marca a tabela como expirada.
Isso traz vários benefícios:
- Se você não tiver feito alterações em uma tabela no modo de desenvolvimento, suas consultas usarão as tabelas de produção existentes. Isso é válido a menos que sua tabela seja uma tabela derivada baseada em SQL definida com uma cláusula
WHEREcondicional com instruçõesif prodeif dev. Se a tabela for definida com uma cláusulaWHEREcondicional, o Looker criará uma tabela de desenvolvimento se você a consultar no modo de desenvolvimento. Para tabelas derivadas nativas com o parâmetrodev_filters, o Looker tem a lógica para usar a tabela de produção a fim de responder a consultas no modo de desenvolvimento, a menos que você altere a definição da tabela e consulte a tabela no modo de desenvolvimento. - Se dois desenvolvedores fizerem a mesma mudança em uma tabela no Modo de desenvolvimento, eles compartilharão a mesma tabela de desenvolvimento.
- Quando você enviar as alterações do modo de desenvolvimento para o de produção, a definição de produção antiga não existirá mais. Portanto, a tabela de produção antiga será marcada como expirada e será descartada.
- Se você decidir descartar as mudanças no modo de desenvolvimento, essa definição da tabela não vai mais existir. Portanto, as tabelas de desenvolvimento desnecessárias serão marcadas como expiradas e serão descartadas.
Como trabalhar mais rapidamente no modo de desenvolvimento
Existem situações em que a PDT criada é muito demorada, o que pode demorar bastante se você estiver testando muitas alterações no modo de desenvolvimento. Nesses casos, você pode solicitar que o Looker crie versões menores de uma tabela derivada quando você estiver no modo de desenvolvimento.
Em tabelas derivadas nativas, use o subparâmetro dev_filters de explore_source para especificar filtros que são aplicados somente a versões de desenvolvimento da tabela derivada:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa../_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Este exemplo inclui um parâmetro dev_filters que filtra os dados para os últimos 90 dias e um parâmetro filters que filtra os dados para os últimos dois anos e para o Aeroporto do Vale do Yucca.
O parâmetro dev_filters atua em conjunto com o filters para que todos os filtros sejam aplicados à versão de desenvolvimento da tabela. Se dev_filters e filters especificarem filtros para a mesma coluna, dev_filters terá precedência para a versão de desenvolvimento da tabela. Neste exemplo, a versão de desenvolvimento da tabela vai filtrar os dados para os últimos 90 dias do Aeroporto de Yucca Valley.
Para tabelas derivadas baseadas em SQL, o Looker suporta uma cláusula WHERE condicional com opções diferentes para as versões de produção (if prod) e desenvolvimento (if dev) da tabela:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
Neste exemplo, a consulta incluirá todos os dados a partir de 2000 no Modo de produção, mas somente os dados de 2020 em diante no Modo de desenvolvimento. Usar esse recurso de maneira estratégica para limitar o conjunto de resultados e aumentar a velocidade da consulta pode tornar as mudanças do Modo de desenvolvimento muito mais fáceis de serem validadas.
Como o Looker cria PDTs
Depois que um PDT é definido e é executado pela primeira vez ou acionado pelo regenerador para reconstrução, de acordo com a estratégia de persistência, o Looker passa pelas seguintes etapas:
- Use o SQL da tabela derivada para criar uma instrução CREATE TABLE AS SELECT (ou CTAS) e executá-la. Por exemplo, para recriar um PDT chamado
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Emita as instruções para criar os índices quando a tabela for criada
- Renomeie a tabela de LC$.. ("Looker Create") para LR$... ("Looker Read"), para indicar que a tabela está pronta para uso.
- Solte qualquer versão mais antiga da tabela que não possa mais ser usada
Há algumas implicações importantes:
- O SQL que forma a tabela derivada precisa ser válido dentro de uma instrução de CTAS.
- Os aliases de coluna no conjunto de resultados da instrução SELECT precisam ser nomes de colunas válidos.
- Os nomes usados ao especificar a distribuição, as chaves de classificação e os índices precisam ser os nomes das colunas listadas na definição SQL da tabela derivada, não os nomes de campos definidos no LookML.
O regenerador do Looker
O regenerador do Looker verifica o status e inicia recriações de tabelas mantidas pelo gatilho. Uma tabela persistente é um PDT que usa um gatilho como estratégia de persistência:
- Para tabelas que usam
sql_trigger_value, o gatilho é uma consulta especificada no parâmetrosql_trigger_valueda tabela. O regenerador do Looker aciona uma recriação da tabela quando o resultado da verificação mais recente da consulta do acionador é diferente do resultado da verificação anterior. Por exemplo, se a tabela derivada for mantida com a consulta SQLSELECT CURDATE(), o regenerador do Looker recriará a tabela na próxima vez que o regenerador verificar o gatilho após a data de alteração. Por padrão, as verificações de regenerador do Looker acionam consultas a cada cinco minutos para ver se a tabela persistente é acionada e deve ser recriada. No entanto, outros fatores podem afetar o tempo necessário para reconstruir suas tabelas, conforme descrito na seção Considerações importantes sobre a implementação de tabelas persistentes nesta página. - Para tabelas que usam
interval_trigger, o acionador é uma duração de tempo especificada no parâmetrointerval_triggerda tabela. O regenerador do Looker aciona uma recriação da tabela após o período especificado. - Para tabelas que usam
datagroup_trigger, o acionador pode ser uma consulta especificada no parâmetrosql_triggerdo grupo de dados ou o tempo pode ser especificado no parâmetrointerval_triggerdo grupo de dados.
O regenerador do Looker também inicia recriações para tabelas persistentes que usam o parâmetro persist_for, mas apenas quando a tabela persist_for é uma cascata de dependência de uma tabela mantida pelo gatilho. Nesse caso, o regenerador do Looker iniciará as recriações para uma tabela persist_for, já que a tabela é necessária para recriar as outras tabelas na cascata. Caso contrário, o regenerador não monitora tabelas persistentes que usam a estratégia persist_for.
Quando a PDT não é criada, o regenerador pode tentar recriar a tabela no próximo ciclo:
- Se a configuração Sempre tentar novamente versões PDT com falha estiver ativada em sua conexão de banco de dados, o regenerador do Looker tentará recriar a tabela durante o próximo ciclo de regeneração, mesmo se a condição de gatilho da tabela não for atendida.
- Se a configuração Sempre tentar novamente PDT Builds estiver desativada, o regenerador do Looker não tentará recriar a tabela até que a condição de gatilho PDT' seja atendida.
Se um usuário solicita dados da tabela persistente enquanto ela está sendo criada e os resultados da consulta não estão no cache, o Looker verifica se a tabela existente ainda é válida. A tabela anterior pode não ser válida se não for compatível com a nova versão da tabela. Isso pode acontecer se a nova tabela tiver uma definição diferente, a nova tabela usar uma conexão de banco de dados diferente ou a nova tabela tiver sido criada com uma versão diferente do Looker. Se a tabela atual ainda for válida, o Looker retornará dados da tabela atual até que a nova seja criada. Caso contrário, se a tabela atual não for válida, o Looker fornecerá os resultados da consulta assim que a nova tabela for recriada.
Considerações importantes para implementar tabelas persistentes
Considerando a utilidade das tabelas persistentes (PDTs e tabelas agregadas), é fácil acumular muitas delas na instância do Looker. É possível criar um cenário em que o regenerador do Looker precisa criar muitas tabelas ao mesmo tempo. Especialmente com tabelas em cascata ou tabelas de longa duração, é possível criar um cenário em que as tabelas têm um longo atraso antes da reconstrução ou em que os usuários apresentam um atraso na geração de resultados da consulta de uma tabela enquanto o banco de dados está trabalhando duro para gerar a tabela.
Por padrão, o regenerador do Looker verifica os gatilhos de PDT a cada cinco minutos para ver se é necessário recriar as tabelas persistentes por gatilho (PDTs e tabelas agregadas que usam a estratégia de persistência datagroup_trigger, interval_trigger ou sql_trigger_value).
Mas outros fatores podem afetar o tempo necessário para reconstruir suas tabelas:
- O administrador do Looker pode ter alterado o intervalo das verificações do acionador do regenerador usando a configuração Programação de manutenção do grupo de dados e PDT na sua conexão do banco de dados.
- Por padrão, o regenerador pode iniciar a recriação de um PDT ou uma tabela agregada de cada vez por uma conexão. Um administrador do Looker pode ajustar o número permitido de recriações simultâneas no regenerador usando o campo Máximo de conexões do builder PDT nas configurações de uma conexão.
- Todas as PDTs e tabelas de agregação acionadas pela mesma
datagroupvão ser recriadas durante o mesmo processo de nova geração. Isso pode ser uma carga pesada se você tiver muitas tabelas usando o grupo de dados, diretamente ou como resultado de dependências em cascata.
Além das considerações anteriores, há algumas situações em que é preciso evitar a adição de persistência a uma tabela derivada:
- Quando as tabelas derivadas serão estendidas: cada extensão de uma PDT criará uma nova cópia da tabela no banco de dados.
- Quando tabelas derivadas usam filtros com modelo ou parâmetros de líquido, não há suporte para tabelas derivadas que usam filtros de modelo ou parâmetros de líquido.
- Quando tabelas derivadas nativas são criadas com base em "Explorar" que usam atributos de usuário com
access_filtersou comsql_always_where, cópias dos dados da tabela são criadas no seu banco de dados para cada valor do atributo do usuário especificado. - Quando os dados subjacentes mudam com frequência e o dialeto do seu banco de dados não é compatível com PDTs incrementais.
- Quando o custo e o tempo envolvidos na criação de PDTs são muito altos.
Dependendo do número e da complexidade das tabelas persistidas na conexão do Looker, a fila pode conter muitas tabelas persistentes que precisam ser verificadas e recriadas em cada ciclo. Portanto, é importante ter esses fatores em mente ao implementar as tabelas derivadas na instância do Looker.
Como gerenciar PDTs em escala com a API
Monitorar e gerenciar PDTs atualizados com diferentes programações fica cada vez mais complexo à medida que você cria mais PDTs na sua instância. Considere usar a integração do Apache Airflow do Looker para gerenciar seus agendamentos de PDT com outros processos de ETL e ELT.
Como monitorar e solucionar problemas de PDTs
Se você usa PDTs, e especialmente PDTs em cascata, é útil ver o status dos PDTs. Use a página de administrador Tabelas derivadas permanentes do Looker para ver o status das suas PDTs. Veja mais informações na página de documentação Configurações do administrador - Tabelas derivadas permanentes.
Ao tentar resolver problemas de PDTs:
- Preste atenção especial à distinção entre tabelas de desenvolvimento e tabelas de produção ao investigar o Log de eventos PDT.
- Verifique se nenhuma mudança foi feita no esquema de rascunho em que o Looker armazena tabelas derivadas permanentes. Se mudanças tiverem sido feitas, talvez seja necessário atualizar as configurações de Conexão na seção Administrador do Looker e, possivelmente, reiniciar o Looker para restaurar a funcionalidade normal de PDT.
- Determine se há problemas com todos os PDTs ou apenas um. Se houver um problema com um deles, o problema provavelmente é causado por um erro do LookML ou SQL.
- Determine se problemas com o PDT correspondem aos horários em que ele está programado para ser recriado.
- Verifique se todas as consultas
sql_trigger_valueforam avaliadas corretamente e retorne apenas uma linha e uma coluna. Para PDTs baseados em SQL, é possível fazer isso no SQL Runner. Aplicar umLIMITprotege contra consultas descontroladas. Para mais informações sobre como usar o SQL Runner para depurar tabelas derivadas, consulte este tópico da comunidade. - Para PDTs baseados em SQL, use o SQL Runner para verificar se o SQL do PDT é executado sem erros. Lembre-se de aplicar uma
LIMITno SQL Runner para manter os tempos de consulta razoáveis. - Para tabelas derivadas baseadas em SQL, evite usar expressões de tabela comuns (CTEs). O uso de CTEs com DTs cria instruções
WITHaninhadas que podem fazer com que os PDTs falhem sem aviso prévio. Em vez disso, use o SQL do CTE para criar uma DT secundária e faça referência a ela por meio da sintaxe de${derived_table_or_view_name.SQL_TABLE_NAME}. - Verifique se as tabelas de que o PDT tem problema, sejam elas tabelas normais ou PDTs, existem e podem ser consultadas.
- Verifique se as tabelas de que o problema PDT depende não têm bloqueios compartilhados ou exclusivos. Para que o Looker crie um PDT, ele precisa adquirir um bloqueio exclusivo na tabela a ser atualizada. Essa opção entrará em conflito com outros bloqueios compartilhados ou exclusivos que estão atualmente na tabela. O Looker não pode atualizar a PDT até que todos os outros bloqueios sejam apagados. O mesmo vale para todos os bloqueios exclusivos da tabela que o Looker está criando de um PDT. Se houver um bloqueio exclusivo em uma tabela, o Looker não poderá adquirir um bloqueio compartilhado para executar consultas até que o bloqueio exclusivo seja apagado.
- Use o botão Show Processes no SQL Runner. Se houver muitos processos ativos, isso poderá reduzir os tempos de consulta.
- Monitore os comentários na consulta. Consulte a seção Comentários da consulta para PDTs nesta página.
Comentários da consulta para PDTs
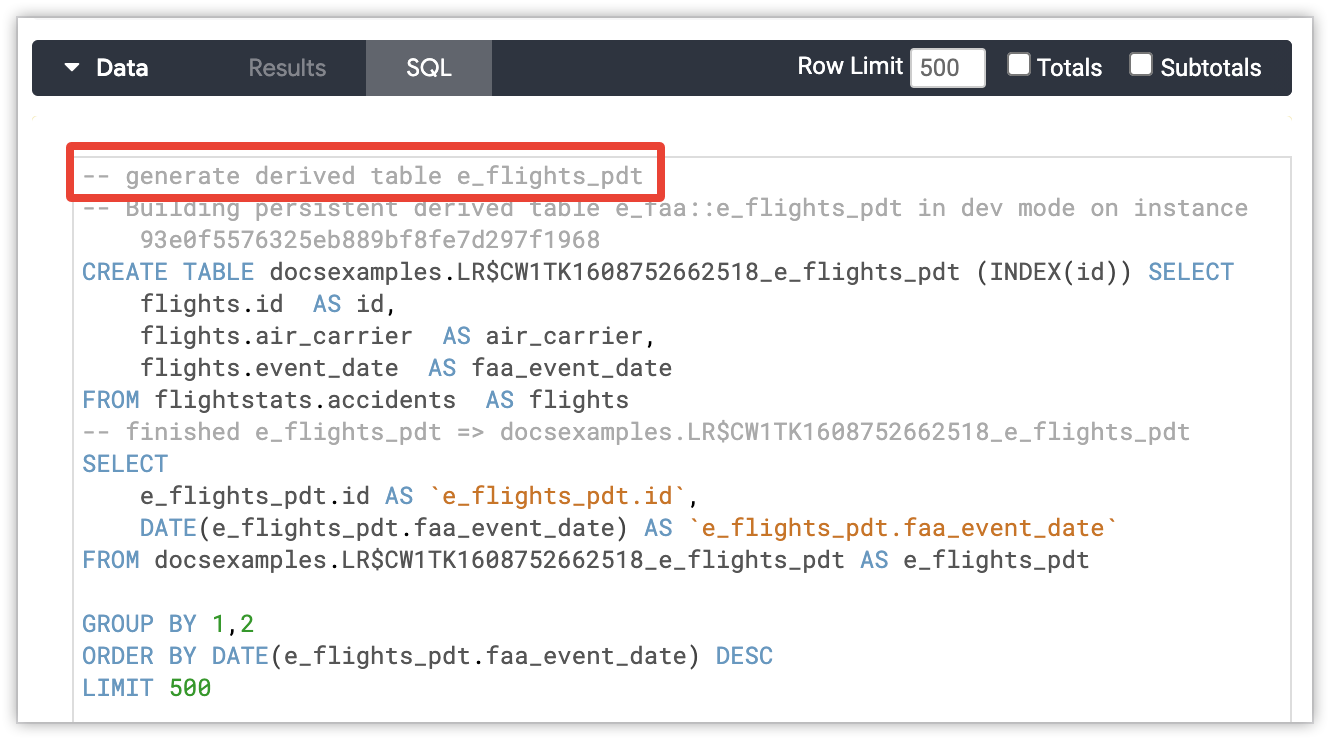
Os administradores de bancos de dados podem diferenciar facilmente as consultas normais das que geram PDTs. O Looker adiciona comentários à instrução CREATE TABLE ... AS SELECT ..., que inclui o modelo e a visualização do LookML da PDT' além de um identificador exclusivo (slug) para a instância do Looker. Se o PDT estiver sendo gerado em nome de um usuário no Modo de desenvolvimento, os comentários vão indicar o ID do usuário. Os comentários da geração de PDT seguem este padrão:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
O comentário de geração de PDT aparecerá na guia SQL "Explorar" se o Looker tiver que gerar um PDT para a consulta do "Explorar". O comentário aparecerá na parte superior da instrução SQL.
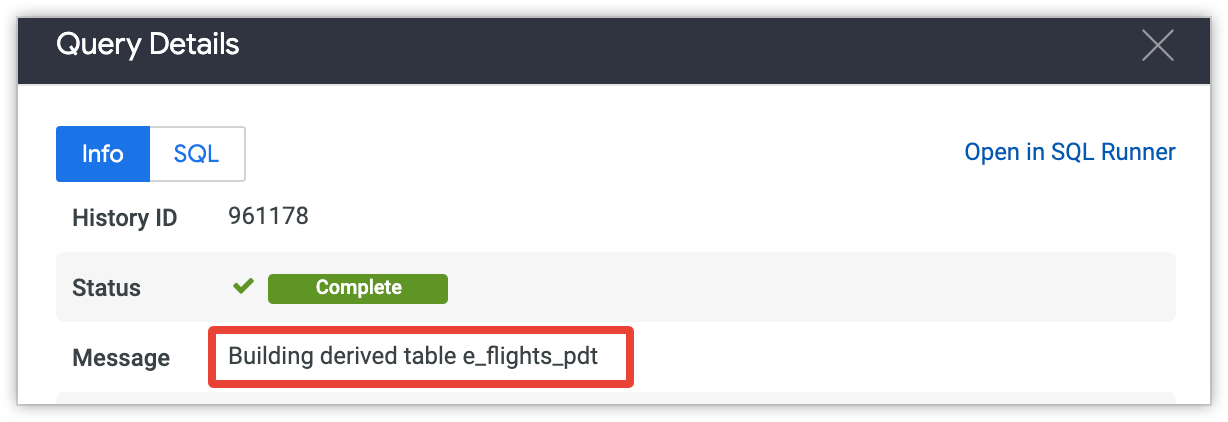
Por fim, o comentário de geração de PDT é exibido no campo Mensagem, na guia Informações do pop-up Detalhes da consulta para cada consulta na página de administrador Consultas.
Como recriar PDTs após uma falha
Quando uma PDT falha, veja o que acontece quando ela é consultada:
- O Looker usará os resultados no cache se a mesma consulta tiver sido executada anteriormente. Consulte a página de documentação Como armazenar em cache as consultas e recriar PDTs com grupos de dados para saber como isso funciona.
- Se os resultados não estiverem no cache, o Looker extrairá resultados do PDT no banco de dados, se houver uma versão válida do PDT.
- Se não houver PDT válida no banco de dados, o Looker tentará reconstruir o PDT.
- Se não for possível recriar o PDT, o Looker retornará um erro para uma consulta. O regenerador do Looker tentará recriar o PDT na próxima vez que ele for consultado ou na estratégia de persistência do PDT'
Com PDTs em cascata, a mesma lógica se aplica, exceto que com PDTs em cascata:
- Uma falha de compilação em uma tabela impede a criação de PDTs na cadeia de dependências.
- Um PDT dependente consulta basicamente o PDT de que depende, portanto, a estratégia de persistência de uma tabela pode acionar a recriação dos PDTs indo para cima na cadeia.
Revisitando o exemplo anterior de tabelas em cascata, em que TABLE_D depende de TABLE_C, que depende de TABLE_B, que depende de TABLE_A:
Se TABLE_B falhar, todo o comportamento padrão (não em cascata) será aplicado a TABLE_B: se TABLE_B for consultado, primeiro o Looker tentará usar o cache para retornar resultados, depois tentará usar uma versão anterior da tabela se possível. Em seguida, tentará recriar a tabela. Por fim, retornará um erro se TABLE_B não puder ser recriado. O Looker tentará recriar TABLE_B novamente na próxima consulta da tabela ou quando a estratégia de persistência da tabela acionar uma recriação.
O mesmo se aplica aos dependentes do TABLE_B. Portanto, se TABLE_B não puder ser criado e houver uma consulta em TABLE_C:
- O Looker tentará usar o cache para a consulta em
TABLE_C. - Se os resultados não estiverem no cache, o Looker tentará extrair os resultados de
TABLE_Cno banco de dados. - Se não houver uma versão válida de
TABLE_C, o Looker tentará recriarTABLE_C, o que cria uma consulta emTABLE_B. - O Looker tentará recriar
TABLE_B, que falhará seTABLE_Bnão tiver sido corrigido. - Se
TABLE_Bnão puder ser recriado,TABLE_Cnão poderá ser recriado, então o Looker retornará um erro para a consulta emTABLE_C. - O Looker tentará recriar o
TABLE_Cde acordo com a estratégia de persistência habitual ou na próxima vez que o PDT for consultado, o que inclui a próxima vez que oTABLE_Dtentar criar, já que oTABLE_Ddepende doTABLE_C.
Depois de resolver o problema com TABLE_B, TABLE_B e cada uma das tabelas dependentes vão tentar se recriar de acordo com as estratégias de persistência ou na próxima vez em que forem consultadas, o que inclui a próxima vez que um PDT dependente tentar se recriar. Ou, se uma versão de desenvolvimento dos PDTs na cascata foi criada no Modo de desenvolvimento, as versões de desenvolvimento podem ser usadas como os novos PDTs de produção. Consulte a seção Tabelas persistentes no modo de desenvolvimento nesta página para saber como isso funciona. Também é possível usar uma exploração para executar uma consulta em TABLE_D e recriar manualmente os PDTs da consulta, o que força uma reconstrução de todos os PDTs caindo na cascata de dependência.
Como melhorar o desempenho de PDT
Quando você cria PDTs, o desempenho pode ser um problema. Especialmente quando a tabela é muito grande, a consulta a ela pode ser lenta, assim como para qualquer tabela grande no seu banco de dados.
Para melhorar o desempenho, filtre os dados ou controle como os dados no PDT são classificados e indexados.
Como adicionar filtros para limitar o conjunto de dados
Com conjuntos de dados particularmente grandes, ter muitas linhas desacelera as consultas em relação a um PDT. Se você geralmente consulta apenas dados recentes, adicione um filtro à cláusula WHERE da sua PDT, o que limita a tabela a 90 dias ou menos de dados. Dessa forma, somente os dados relevantes serão adicionados à tabela sempre que ela for recriada para que a execução de consultas seja muito mais rápida. Em seguida, é possível criar um PDT separado e maior para análise histórica, permitindo consultas rápidas de dados recentes e a capacidade de consultar dados antigos.
Como usar indexes ou sortkeys e distribution
Quando você cria um PDT grande, indexar a tabela (para dialetos como MySQL ou Postgres) ou adicionar chaves de classificação e distribuição (para Redshift) pode ajudar no desempenho.
Normalmente, é melhor adicionar o parâmetro indexes aos campos de código ou data.
Para o Redshift, geralmente é melhor adicionar o parâmetro sortkeys aos campos de ID ou de data e o parâmetro distribution no campo usado para a participação.
Configurações recomendadas para melhorar o desempenho
As configurações a seguir controlam como os dados no PDT são classificados e indexados. Essas configurações são opcionais, mas altamente recomendadas:
- Para o Redshift e o Aster, use o parâmetro
distributionpara especificar o nome da coluna cujo valor é usado para espalhar os dados em um cluster. Quando duas tabelas são mescladas pela coluna especificada no parâmetrodistribution, o banco de dados pode encontrar os dados de mesclagem no mesmo nó. Portanto, a E/S entre os nós é minimizada. - Para o Redshift, defina o parâmetro
distribution_stylecomoallpara instruir o banco de dados a manter uma cópia completa dos dados em cada nó. Isso costuma ser usado para minimizar a E/S entre nós quando tabelas menores são mescladas. Defina esse valor comoevenpara instruir o banco de dados a espalhar os dados de maneira uniforme pelo cluster sem usar uma coluna de distribuição. Este valor só pode ser especificado quandodistributionnão for especificado. - Para o Redshift, use o parâmetro
sortkeys. Os valores especificam quais colunas de PDT são usadas para classificar os dados no disco para facilitar a pesquisa. No Redshift, é possível usarsortkeysouindexes, mas não ambos. Exemplo:
* On most databases, use the [`indexes`](/reference/view-params/indexes) parameter. The values specify which columns of the PDT are indexed. (On Redshift, indexes are used to generate interleaved sort keys.)