Depois de proteger e configurar seu banco de dados, você está pronto para conectá-lo ao Looker.
Como criar uma nova conexão de banco de dados
Selecione Conexões na seção Banco de dados no painel Administrador. Na página Conexões, clique no botão Adicionar conexão. O Looker mostra a página Configurações de conexão. Os campos exibidos na página Configurações de conexão dependem da configuração do dialeto.
Para mais informações sobre como aplicar atributos de usuário às configurações de conexão, consulte a seção Conexões da página de documentação de Atributos do usuário.
Para mais informações sobre como usar a coluna Substituição de PDT para configurar credenciais de login separadas para processos de PDT, consulte a seção Configurar credenciais de login separadas para processos de PDT.
Por exemplo, as opções a seguir estão disponíveis para configuração ao conectar o Looker ao Amazon Redshift.
Nome
O nome da conexão como você quer referenciá-la. Não use o nome de pastas. Esse valor não precisa corresponder a nada no seu banco de dados, é apenas um identificador que você atribui. Ele é usado no parâmetro connection do seu modelo LookML.
Dialeto
O dialeto SQL que corresponde à sua conexão. É importante escolher o valor correto para ver as opções de conexão adequadas e fazer com que o Looker traduza o LookML corretamente em SQL.
Servidor SSH
A opção Servidor SSH estará disponível se a instância estiver implantada na infraestrutura do Kubernetes e apenas se a capacidade de adicionar informações de configuração do servidor SSH à sua instância do Looker tiver sido ativada. Se você não quiser usar essa opção na sua instância do Looker e quiser ativá-la, entre em contato com seu gerente de contas do Looker ou abra uma solicitação de suporte na Central de Ajuda do Looker.
O servidor SSH escolhe automaticamente a porta do localhost para você. No momento, não é possível especificar a porta do localhost. Se você precisar criar uma conexão SSH que exija que você especifique uma porta do host local, entre em contato com seu gerente de contas do Looker ou abra uma solicitação de suporte na Central de Ajuda do Looker.
Para se conectar ao seu banco de dados usando um túnel SSH, ative a opção e selecione uma configuração do servidor SSH na lista suspensa.
Host remoto:porta
O nome do host do banco de dados e a porta que o Looker deve usar para se conectar ao seu host de banco de dados.
Se você trabalhou com um analista do Looker para configurar um túnel SSH para seu banco de dados, no campo Host, digite "localhost" e, no campo Porta, insira o número da porta que redireciona para seu banco de dados, que o analista do Looker deve ter fornecido.
Se você aplicar um atributo de usuário ao campo Host, o atributo de usuário não poderá ter um nível de acesso do usuário definido como Editável.
Se você configurou um túnel SSH para se conectar ao seu banco de dados, não é possível aplicar um atributo de usuário ao campo Host remoto:Porta.
Banco de dados
O nome do banco de dados no seu host. Por exemplo, você pode ter um nome de host my-instance.us-east-1.redshift.amazonaws.com em que haja um banco de dados chamado sales_info. Insira sales_info neste campo. Se você tiver vários bancos de dados no mesmo host, talvez precise criar várias conexões para usá-los (com exceção do MySQL, em que a palavra database significa algo um pouco diferente da maioria dos dialetos SQL).
Usar OAuth
Para conexões do Snowflake e do Google BigQuery, você tem a opção de usar o OAuth. Isso significa que os usuários precisam fazer login no Snowflake ou no Google, respectivamente, para enviar consultas do Looker.
Ao selecionar Usar OAuth, você verá os campos ID do cliente OAuth e Chave secreta do cliente OAuth:

Esses valores são gerados pelo banco de dados da Snowflake ou pelo Google. Veja a página de documentação que descreve a configuração do OAuth do Snowflake ou a configuração do OAuth do Google BigQuery para o procedimento completo.
Nome de usuário
O nome de usuário que o Looker deve usar para se conectar ao seu banco de dados. Configure o usuário antecipadamente, de acordo com nossas instruções de configuração do banco de dados.
Senha
A senha que o Looker deve usar para se conectar ao seu banco de dados. Configure a senha antecipadamente, de acordo com as instruções de configuração do banco de dados.
Esquema
O esquema padrão que o Looker usa quando um esquema não é especificado. Isso se aplica quando você está usando o SQL Runner, durante a geração de projetos do LookML e quando está consultando tabelas.
Tabelas derivadas permanentes
Marque esta caixa para ativar tabelas derivadas permanentes. Isso revela outros campos de PDT e a coluna Substituição de PDT. O Looker mostra essa opção apenas se o dialeto de banco de dados for compatível com o uso de PDTs.
Observe o seguinte sobre PDTs:
- As PDTs não são compatíveis com conexões Snowflake que usam OAuth.
- A desativação dos PDTs em uma conexão não desativa os grupos de dados associados aos seus PDTs. Mesmo que você desative os PDTs, os grupos de dados existentes ainda executarão as consultas
sql_triggerno banco de dados. Se você quiser impedir que um grupo de dados execute a consultasql_triggerno seu banco de dados, exclua ou comente o parâmetrodatagroupdo seu projeto LookML ou atualize a configuração PDT e Datagroup Manutenção Schedule para a conexão de modo que o Looker verifique PDTs e grupos de dados com pouca frequência ou nunca. - Para conexões do Snowflake, o Looker define o valor do parâmetro
AUTOCOMMITcomoTRUE(valor padrão do Snowflake').AUTOCOMMITé necessário para os comandos SQL que o Looker executa para manter o sistema de registro PDT.
Banco de dados temporário
Embora seja rotulado como Banco de dados temporário, você digitará o nome do banco de dados ou do esquema, conforme apropriado para seu dialeto SQL, que o Looker deve usar para criar tabelas derivadas permanentes. Você deve configurar este banco de dados ou esquema antecipadamente, com as permissões de gravação apropriadas. Na página de documentação Instruções de configuração de bancos de dados, selecione o dialeto do banco de dados para ver as instruções desse dialeto.
Cada conexão precisa ter o próprio Temp Database ou Schema. Elas não podem ser compartilhadas entre conexões.
Conexões máximas do Criador de PDT
A configuração Max PDT Builder Connections permite especificar quantas versões simultâneas da tabela o regenerador do Looker pode iniciar. A configuração Max PDT Builder Connections se aplica apenas aos tipos de tabelas em que o regenerador do Looker inicia as recriações:
- Tabelas persistentes para acionadores (tabelas derivadas permanentes e tabelas agregadas que usam a estratégia de persistência
datagroup_triggerousql_trigger_value) - Tabelas persistentes que usam a estratégia
persist_for, mas apenas quando a tabelapersist_forfizer parte de uma cascata de tabelas derivadas em que depende de uma tabela que usa a estratégia de persistênciadatagroup_triggerousql_trigger_value. Neste caso, o regenerador do Looker recria uma tabelapersist_for, já que ela é necessária para recriar outra tabela na cascata. Caso contrário, o regenerador não inicia versões para tabelaspersist_for.
A configuração Max PDT Builder Connections define 1 como padrão, mas pode ser definida como 10. No entanto, o valor não pode ser maior do que o valor definido no campo Max Connections ou no per-user-query-limit definido nas opções de inicialização do Looker.
Defina esse valor com cuidado. Se o valor for muito alto, você poderá sobrecarregar seu banco de dados. Se o valor for baixo, PDTs ou tabelas de agregação de longa duração podem atrasar a criação de outras tabelas persistentes ou desacelerar outras consultas na conexão. Os bancos de dados que oferecem suporte a multilocação, como BigQuery, Snowflake e Redshift, podem ter melhor desempenho no processamento de builds de consultas paralelas.
Se você quiser aumentar a configuração Max PDT Builder Connections, recomendamos aumentar essa configuração com um incremento de 1. Se ocorrer algum comportamento inesperado, defina-o novamente como 1. Caso contrário, se o desempenho da consulta não for afetado, você pode continuar a aumentá-lo de modo incremental em 1 e verificar o desempenho em cada incremento antes de aumentar ainda mais a configuração.
Observe o seguinte sobre a configuração Max PDT Builder Connections:
- A configuração Max PDT Builder Connections se aplica somente às conexões necessárias para a recriação das tabelas, e não às conexões necessárias para verificações de gatilho. Uma verificação de acionador é uma consulta que verifica se a estratégia de persistência da tabela é acionada. Como essas consultas de verificação de acionador são sempre executadas em sequência, a configuração Max PDT Builder Connections não se aplica.
- Em uma instância do Looker em cluster, o regenerador é executado apenas no nó principal. A configuração Max PDT Builder Connections se aplica apenas ao nó principal e, portanto, define o limite para todo o cluster.
- A configuração Max PDT Builder Connections não se aplica aos seguintes tipos de tabela. Esses tipos de tabelas são criados consecutivamente:
- Tabelas mantidas pelo parâmetro
persist_for(a menos que a tabela dependa de tabelas que usam as estratégiasdatagroup_triggerousql_trigger_value). - Tabelas no modo de desenvolvimento.
- Tabelas recriadas com a opção Recriar tabelas derivadas e execução.
- Tabelas em que uma depende de outra em uma dependência cascade. Não é possível criar uma tabela ao mesmo tempo que uma tabela de que ela depende. Por exemplo, se
table_Bdepender detable_A, entãotable_Aprecisará terminar a recriação antes quetable_Bpossa começar a ser reconstruída.
- Tabelas mantidas pelo parâmetro
Sempre repetir builds de PDT com falha
A configuração Sempre tentar novamente builds PDT com falha configura como o regenerador do Looker tenta recriar tabelas mantidas pelo gatilho que falharam no ciclo de regeneração anterior. O regenerador do Looker é o processo que recria tabelas mantidas por gatilhos (PDTs e tabelas agregadas) de acordo com o intervalo definido na configuração da conexão de Programação de manutenção do PTS e do grupo de dados. Quando a configuração Sempre tentar novamente versões PDT com falha estiver ativada, o regenerador do Looker tentará reconstruir uma PDT que falhou no ciclo de regeneração anterior, mesmo se a condição do gatilho PDT's não for atendida. Quando ela estiver desativada, o regenerador do Looker tentará recriar uma PDT que falhou anteriormente apenas quando a condição de acionamento da PDT'só for atendida. A opção Sempre tentar novamente versões PDT com falha fica desativada por padrão.
Consulte a página de documentação Tabelas derivadas no Looker para mais informações sobre o regenerador do Looker.
Ativar controle de API PDT
A configuração Ativar controle de API PDT determina se as chamadas de API start_pdt_build, check_pdt_build e stop_pdt_build podem ser usadas para essa conexão. Quando essa configuração está desativada, essas chamadas de API falham quando fazem referência a PDTs nessa conexão. A opção Ativar Controle de API PDT fica desativada por padrão.
Parâmetros adicionais
É possível incluir outros parâmetros de Java Database Connectivity (JDBC) para suas consultas aqui, se necessário.
Para fazer referência a um atributo do usuário em um parâmetro JDBC, use a sintaxe Modelo de líquido: _user_attributes['name_of_attribute']. Exemplo:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Veja como ela pode ficar no campo Parâmetros adicionais no Looker:

Parâmetros JDBC adicionais não foram testados pelo Looker e podem causar um comportamento não intencional.
Programação de manutenção de PDT e grupo de dados
Essa configuração aceita uma expressão cron que indica quando o regenerador do Looker deve verificar grupos de dados e tabelas persistentes (tabelas agregadas e tabelas derivadas permanentes) baseadas em sql_trigger_value e ver quais tabelas devem ser geradas ou descartadas.
O valor padrão de */5 * * * * significa "verificar a cada 5 minutos," que é a frequência máxima de verificações. Uma expressão cron que indica verificações mais frequentes resultará em verificações a cada cinco minutos.
Enquanto os PDTs estão sendo criados, o Looker não faz outras verificações de gatilhos. Depois de criar todos os PDTs da última verificação de gatilho, o Looker retoma a verificação dos acionadores de grupo de dados e PDT com base na programação de manutenção do PDT e do grupo de dados.
Se o seu banco de dados não estiver disponível 24 horas por dia, 7 dias por semana, recomendamos que você limite as verificações aos horários em que ele está ativo. Veja algumas expressões cron adicionais:
Expressão cron |
Definição |
|---|---|
*/5 8-17 * * MON-FRI |
Verifique os grupos de dados e PDTs a cada 5 minutos durante o horário comercial, de segunda a sexta-feira. |
*/5 8-17 * * * |
Verificar grupos de dados e PDTs a cada 5 minutos durante o horário comercial, todos os dias |
0 8-17 * * MON-FRI |
Verificar grupos de dados e PDTs a cada hora durante o horário comercial, de segunda a sexta-feira |
1 3 * * * |
Verificar grupos de dados e PDTs todos os dias às 3h01 |
Alguns pontos a serem considerados ao criar uma expressão cron:
- O Looker usa parse-cron v0.1.3, que não é compatível com
?em expressõescron. - A expressão
cronusa o fuso horário do aplicativo do Looker para determinar quando as verificações são feitas. - Se os PDTs não estiverem sendo criados, redefina a string cron de volta para o padrão de
*/5 * * * *.
Veja abaixo alguns recursos que ajudam a criar strings cron:
- https://crontab.guru: ajude a editar e testar as strings
cron. - http://www.crontab-generator.org: selecione as configurações de horário, e o gerador criará a string
croncorrespondente.
SSL
Escolha se quer ou não usar a criptografia SSL para proteger dados durante a transmissão entre o Looker e seu banco de dados. O SSL é apenas uma opção que pode ser usada para proteger seus dados. Outras opções seguras estão descritas na página de documentação Como ativar o acesso seguro a banco de dados.
Verificar certificado SSL
Escolha se você quer exigir a verificação do certificado SSL usado pela conexão. Se a verificação for necessária, a autoridade certificadora (CA, na sigla em inglês) que assinou o certificado SSL precisará vir da lista de fontes confiáveis do cliente. Se a CA não for uma fonte confiável, a conexão do banco de dados não será estabelecida.
Se essa caixa não estiver selecionada, a criptografia SSL ainda será usada na conexão. No entanto, a verificação da conexão SSL não é necessária e, por isso, uma conexão pode ser estabelecida quando a CA não estiver na lista de fontes confiáveis do cliente.
Máximo de conexões
Aqui é possível definir o número máximo de conexões que o Looker pode estabelecer com seu banco de dados. Na maior parte, você define o número de consultas simultâneas que o Looker pode executar no seu banco de dados. O Looker também reserva até três conexões para encerramento de consultas. Se o pool de conexões for muito pequeno, o Looker reservará menos conexões.
Defina esse valor com cuidado. Se o valor for muito alto, você pode sobrecarregar seu banco de dados. Se o valor for muito baixo, as consultas precisarão compartilhar um pequeno número de conexões. Assim, muitas consultas podem parecer lentas para os usuários, já que precisam consultar outras consultas anteriores.
O valor padrão (que varia de acordo com o dialeto SQL) é normalmente um ponto de partida razoável. A maioria dos bancos de dados também tem configurações próprias para o número máximo de conexões que eles aceitam. Se a configuração do banco de dados limitar conexões, verifique se o valor de Max Connections é igual ou menor que o limite do seu banco de dados.
Tempo limite do pool de conexões
Se os usuários solicitarem mais conexões do que a configuração Max Connections, as solicitações aguardarão até que outras pessoas terminem antes de serem executadas. O tempo máximo em que uma solicitação aguarda é configurado aqui. Defina esse valor com cuidado. Se ela for muito baixa, os usuários poderão achar que as consultas deles foram canceladas porque não há tempo suficiente para que as consultas de outros usuários sejam concluídas. Se ele for muito alto, um grande número de consultas pode aumentar e os usuários podem esperar muito tempo. O valor padrão costuma ser um ponto de partida razoável.
Estimativa de custo
A caixa de seleção Estimativa de custo se aplica somente às seguintes conexões de banco de dados:
- Floco de neve
- Amazon Redshift
- Arábia Saudita
- PostgreSQL, Cloud SQL para PostgreSQL e Microsoft Azure PostgreSQL
A caixa de seleção Estimativa de custo ativa os seguintes recursos na conexão:
- Estimativas de custo das consultas do Explorar
- Estimativas de custo das consultas do SQL Runner
- Estimativas de economias de computação para consultas de reconhecimento agregado
As conexões do BigQuery e do MySQL também aceitam o recurso Estimativa de custo. No entanto, como o recurso está sempre ativado, não há caixas de seleção Estimativa de custo para conexões BigQuery e MySQL.
Consulte a página de documentação Como explorar dados no Looker para mais informações.
Pré-cache do SQL Runner
No SQL Runner, todas as informações da tabela são pré-carregadas assim que você seleciona uma conexão e um esquema. Assim, o SQL Runner pode exibir colunas de tabelas rapidamente assim que você clicar no nome de uma tabela. No entanto, para conexões e esquemas com muitas tabelas ou com tabelas muito grandes, talvez você não queira que o SQL Runner pré-carregue todas as informações.
Se preferir que o SQL Runner carregue informações da tabela somente quando uma tabela for selecionada, é possível desmarcar a opção SQL Runner Precache para desativar o pré-carregamento do SQL Runner para a conexão.
Buscar esquema de informações para gravação SQL
Para alguns recursos de escrita SQL, como reconhecimento agregado, o Looker usa o esquema de informações do seu banco de dados para otimizar a escrita SQL. Se o esquema de informações não for armazenado em cache, o Looker talvez precise bloquear a gravação do SQL no banco de dados ocasionalmente para buscar o esquema de informações. Para dialetos que usam o sistema de arquivos distribuídos do Hadoop (HDFS, na sigla em inglês), a busca do esquema de informações pode levar tempo suficiente para afetar significativamente o desempenho das consultas do Looker. Se você souber que seu esquema de informações está lento, desative a opção Buscar esquema de informação para gravação SQL na conexão. Desativar esse recurso impedirá que parte da otimização de SQL do Looker seja feita em certos recursos, portanto, ative a opção Buscar esquema de informação para gravação em SQL, a menos que você saiba que o esquema de informações da sua conexão é particularmente lento.
Desativar comentário de contexto
A opção Desativar comentário de contexto só é aplicável a conexões do BigQuery. Os comentários de contexto nas conexões do Google BigQuery são desativados por padrão porque esses comentários invalidam a capacidade do Google BigQuery de armazenar em cache e podem afetar negativamente o desempenho do cache. É possível ativar comentários de contexto para uma conexão do BigQuery desmarcando a configuração Desativar comentário de contexto na página Configurações de conexão para a conexão. Veja a página de documentação do Google BigQuery para mais informações.
fuso horário do banco de dados
O fuso horário em que o banco de dados armazena informações com base no tempo. O Looker precisa saber disso para converter valores de tempo para os usuários e facilitar o entendimento e o uso de dados com base no tempo. Consulte a página de documentação Usar configurações de fuso horário para mais informações.
fuso horário de consultas
A opção Fuso horário da consulta vai ficar visível apenas se você tiver desativado Fusos horários específicos do usuário.
Quando os Fusos horários específicos do usuário estão desativados, o Fuso horário da consulta é o fuso horário exibido para os usuários quando eles consultam dados baseados em tempo, e o fuso horário em que o Looker converte dados baseados no tempo do Fuso horário do banco de dados.
Consulte a página de documentação Usar configurações de fuso horário para mais informações.
Como configurar credenciais de login separadas para processos de PDT
Se o banco de dados for compatível com tabelas derivadas permanentes e você tiver marcado a caixa Tabelas derivadas permanentes nas configurações de conexão, o Looker exibirá a coluna PDT Overrides. Na coluna PDT Overrides, é possível inserir parâmetros JDBC separados (host, porta, banco de dados, nome de usuário, senha, esquema e parâmetros adicionais) que sejam específicos aos processos PDT. Isso pode ser valioso por vários motivos:
- Ao criar um usuário de banco de dados separado para processos de PDT, é possível usar PDTs no seu modelo, mesmo que você atribua atributos de usuário às suas credenciais de login do banco de dados.
- Os processos de PDT podem se autenticar usando um usuário de banco de dados separado que tem prioridade mais alta. Assim, o banco de dados pode priorizar os jobs de PDT em vez de consultas menos críticas dos usuários.
- O acesso de gravação pode ser revogado para a conexão padrão do banco de dados do Looker e concedido apenas a um usuário especial que os processos de PDT usarão para autenticação. Essa é uma estratégia de segurança melhor para a maioria das organizações.
- Em bancos de dados, como o Snowflake, os processos de PDT podem ser roteados para um hardware mais eficiente que não seja compartilhado com os outros usuários do Looker. Dessa forma, os PDTs podem ser criados rapidamente sem gerar custos de hardware de alto custo em tempo integral.
Por exemplo, a configuração a seguir mostra uma conexão em que os campos de nome de usuário e senha são definidos como atributos do usuário. Dessa forma, cada usuário pode acessar o banco de dados usando as credenciais individuais. A coluna Substituição de PPD cria um usuário separado (pdt_user) com a própria senha. A conta do pdt_user será usada para todos os processos de PDT, com níveis de acesso adequados à criação e atualização de PDT:
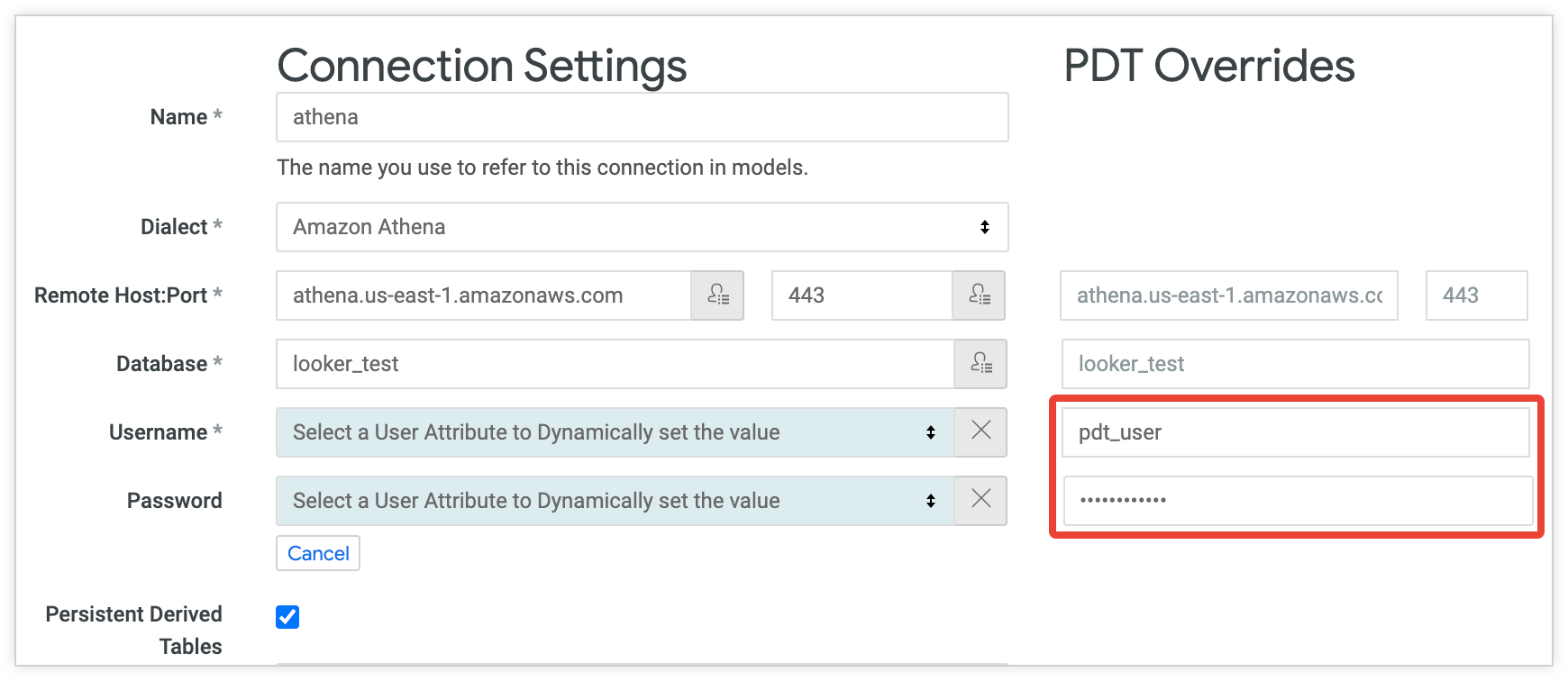
Enquanto a coluna PDT Overrides permite alterar o usuário do banco de dados e outras propriedades de conexão, uma substituição PDT deve ler os mesmos dados que a conexão padrão e deve gravar dados no mesmo local. O Looker não pode ler dados de um local e gravá-los em outro.
Como testar as configurações de conexão
Depois de inserir as credenciais, clique em Testar estas configurações para verificar se as informações estão corretas e se o banco de dados pode se conectar.
Se a conexão não passar em um ou mais testes:
- Teste algumas etapas de solução de problemas na página de documentação Como testar a conectividade do banco de dados.
- Se você estiver usando o Mongo versão 3.6 ou anterior do Atlas e receber uma falha no link de comunicação, consulte a página de documentação do Mongo Connector.
- Para receber mensagens de conexão bem-sucedidas relacionadas ao esquema temporário e aos PDTs, permita essa funcionalidade ao configurar o banco de dados do Looker. As instruções para fazer isso podem ser encontradas na página de documentação Instruções de configuração do banco de dados.
As conexões de banco de dados que usam OAuth, como Snowflake e Google BigQuery, exigem login do usuário. Se você não tiver feito login na sua conta de usuário do OAuth ao testar uma dessas conexões, o Looker exibirá um aviso com um link Fazer login. Clique no link para inserir as credenciais do OAuth ou permitir que o Looker acesse as informações da sua conta do OAuth.
Se você ainda estiver com problemas, entre em contato com o suporte do Looker para receber ajuda.
Testar como usuário
Se você tiver definido um ou mais valores de parâmetros de conexão para um atributo do usuário, a opção Testar como usuário aparecerá acima do botão Testar estas configurações. Selecione um usuário e clique em Testar estas configurações para verificar se o banco de dados pode conectar e executar consultas como esse usuário.
Como adicionar a conexão do banco de dados
Depois de definir e testar as configurações de conexão do banco de dados, clique em Add Connection. Sua conexão de banco de dados foi adicionada à lista na página Conexões.
Próximas etapas
Depois de conectar seu banco de dados ao Looker, você estará pronto para configurar opções de login para seus usuários.