O Looker reduz a carga no seu banco de dados e melhora o desempenho usando resultados em cache de consultas anteriores quando disponíveis e permitidos pela sua política de armazenamento em cache. Além disso, é possível criar consultas complexas como tabelas derivadas permanentes (PDTs, na sigla em inglês), que armazenam os resultados para simplificar as consultas futuras.
Os grupos de dados são muito úteis para coordenar a programação de ETL (extração, transformação e carga) do banco de dados com a política de armazenamento em cache do Looker e a programação de recriação de PDT. É possível usar um grupo de dados para especificar o gatilho de recriação para PDTs com base em quando novos dados são adicionados ao seu banco de dados. No mesmo grupo de dados, você pode especificar uma idade máxima de cache para que as consultas do Explorações funcionem como uma proteção contra falhas se a recriação de PDT não for acionada por algum motivo. Dessa forma, o modo de falha de um grupo de dados será consultar o banco de dados em vez de exibir dados desatualizados do cache do Looker.
Também é possível usar um grupo de dados para desacoplar o acionador de recriação de PDT da idade máxima do cache. Isso pode ser útil se você tiver uma exploração com base em dados que são atualizados com muita frequência e que ela é vinculada a uma PDT recriada com menos frequência. Nesse caso, é melhor que seu cache de consultas seja redefinido com mais frequência do que o PDT é recriado.
Para mais detalhes sobre o armazenamento em cache das consultas, veja a seção Como o Looker usa consultas em cache nesta página de documentação.
Definir um grupo de dados
Um grupo de dados é definido com o parâmetro datagroup, seja em um arquivo de modelo ou no próprio arquivo LookML. É possível definir vários grupos de dados se você quiser diferentes políticas de recriação de PDT e armazenamento em cache para diferentes explorações e/ou PDTs no projeto.
O parâmetro datagroup pode ter os seguintes subparâmetros:
label: especifica um rótulo opcional para o grupo de dados.description: especifica uma descrição opcional para o grupo de dados que pode ser usada para explicar a finalidade e o mecanismo do grupo.max_cache_age: especifica uma string que define um período. Quando a idade do cache de uma consulta excede o período, o Looker invalida o cache. Na próxima vez que a consulta for emitida, o Looker enviará a consulta ao banco de dados para novos resultados.interval_trigger: especifica uma programação para acionar o grupo de dados, como"24 hours".
Consulte a página de documentação do grupo de dados para mais informações sobre esses parâmetros.
No mínimo, um grupo de dados precisa ter pelo menos o parâmetro max_cache_age, sql_trigger ou interval_trigger.
Um grupo de dados não pode ter os parâmetros
sql_triggereinterval_trigger. Se você definir um grupo de dados com os dois parâmetros, o grupo usará o valorinterval_triggere ignorará o valorsql_trigger, já que o parâmetrosql_triggerexige que o Looker use recursos de banco de dados ao consultar o banco de dados.
Veja um exemplo de um grupo de dados com uma sql_trigger configurada para recriar o PDT todos os dias. Além disso, o max_cache_age é definido para limpar o cache da consulta a cada duas horas, caso os Explorações mesclem PDTs para outros dados que são atualizados com mais frequência do que uma vez por dia.
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
Depois de definir o grupo de dados, você pode atribuí-lo a "explores" e "PDTs":
- Para atribuir o grupo a uma PDT, use o parâmetro
datagroup_triggerno parâmetroderived_table. Consulte a seção Como usar um grupo de dados para especificar um gatilho de recriação para PDTs nesta página para ver um exemplo. - Para atribuir o grupo de dados a uma exploração, use o parâmetro
persist_withno nível do modelo ou explorar. Consulte a seção Como usar um grupo de dados para especificar a redefinição do cache de consultas de explorações nesta página para ver um exemplo.
Como usar um grupo de dados para especificar um gatilho de recriação para PDTs
Para definir um gatilho de recriação de PDT usando grupos de dados, crie um parâmetro datagroup com o subparâmetro sql_trigger ou interval_trigger. Em seguida, atribua o grupo de dados a PDTs individuais usando o subparâmetro datagroup_trigger na definição do derived_table do PDT'. Se você usar datagroup_trigger para sua PDT, não será preciso especificar outra estratégia de persistência para a tabela derivada. Se você especificar várias estratégias de persistência para um PDT, receberá um aviso no ambiente de desenvolvimento integrado do Looker, e apenas o datagroup_trigger será usado.
Veja um exemplo de definição de PDT que usa o grupo de dados customers_datagroup. Essa definição também adiciona vários índices, customer_id e first_order_date. Para mais informações sobre como definir PDTs, consulte a página de documentação Tabelas derivadas no Looker.
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
Se você tiver PDTs em cascata, PDTs que dependem de outros PDTs, tenha cuidado para não especificar políticas de armazenamento em cache incompatíveis do grupo de dados.
Para conexões com atributos de usuário para especificar os parâmetros de conexão, você precisa criar uma conexão separada usando os campos de modificação de PDT se quiser realizar uma das seguintes ações:
• Usar PDTs no seu modelo
• Usar um grupo de dados para definir um gatilho de recriação PDT
Sem as substituições de PDT, você ainda pode usar um grupo de dados commax_cache_agepara definir a política de armazenamento em cache para "Explorar".
Consulte a página de documentação Tabelas derivadas no Looker para mais informações sobre como os grupos de dados funcionam com PDTs.
Como usar um grupo de dados para especificar a redefinição do cache de consultas de "explores"
Quando um grupo de dados é acionado, o regenerador do Looker (link em inglês) recria os PDTs que usam esse grupo de dados como uma estratégia de persistência. Quando as PDTs do grupo de dados forem recriadas, o Looker limpará o cache das explorações que usam as PDTs recriadas dos grupos de dados. É possível adicionar o parâmetro max_cache_age à definição do grupo de dados se você quiser personalizar uma programação de redefinição de cache de consulta para o grupo. O parâmetro max_cache_age permite limpar o cache de consultas em uma programação especificada, além da redefinição automática do cache de consultas que o Looker realiza quando as PDTs do grupo de dados são recriadas.
Para definir uma política de armazenamento em cache de consultas com grupos de dados, crie um parâmetro datagroup com o subparâmetro max_cache_age.
Para especificar um grupo de dados a ser usado para redefinições do cache de consultas em "Explorar", use o parâmetro persist_with:
- Para atribuir o grupo de dados como padrão para todas as explorações em um modelo, use o parâmetro
persist_withno nível do modelo (em um arquivo de modelo). - Para atribuir o grupo de dados a "explores" individuais, use o parâmetro
persist_withem um parâmetroexplore.
Os exemplos a seguir mostram um grupo de dados chamado orders_datagroup que é definido em um arquivo de modelo. O grupo de dados tem um parâmetro sql_trigger, que especifica que a consulta select max(id) from my_tablename será usada para detectar quando um ETL aconteceu. Mesmo que esse ETL não aconteça por um tempo, o max_cache_age do grupo de dados especifica que os dados armazenados em cache serão usados apenas por no máximo 24 horas.
O parâmetro persist_with do modelo aponta para a política de armazenamento em cache orders_datagroup, o que significa que será a política de armazenamento em cache padrão para todos os exploradores no modelo. No entanto, não queremos usar a política de armazenamento em cache padrão do modelo para os customer_facts e customer_background. Por isso, podemos adicionar o parâmetro persist_with para especificar uma política de armazenamento em cache diferente para esses dois explorações. As explorações orders e orders_facts não têm um parâmetro persist_with. Por isso, elas usarão a política de armazenamento em cache padrão do modelo: orders_datagroup.
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
Se persist_with e persist_for forem especificados, você receberá um aviso de validação, e o persist_with será usado.
Como usar um grupo de dados para acionar entregas programadas
Grupos de dados também podem ser usados para acionar a entrega de um painel, um painel legado ou um Look. Com esta opção, o Looker envia seus dados quando o grupo de dados é concluído, de modo que o conteúdo programado esteja atualizado.
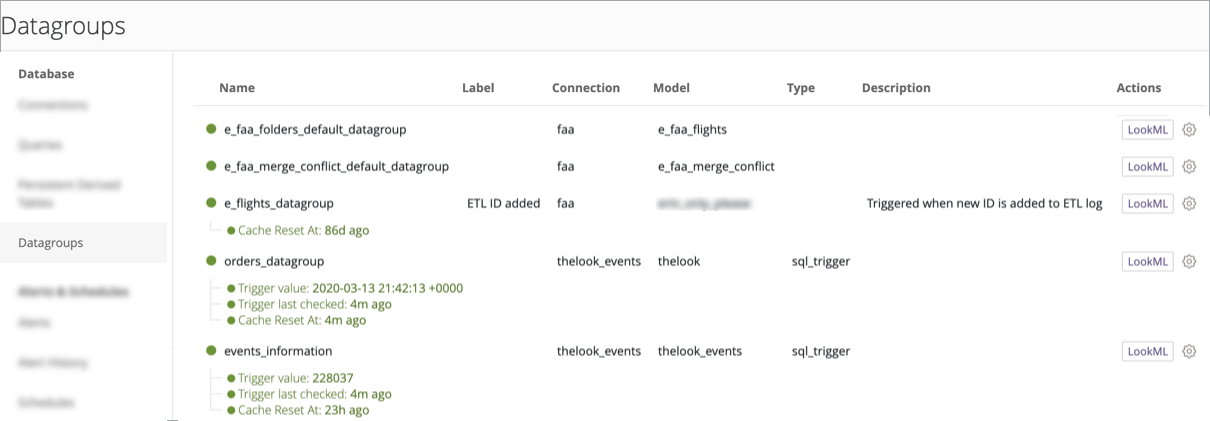
Usar o painel Administrador para grupos de dados
Se você tiver o papel de administrador do Looker, poderá usar a página Grupos de dados do painel Administrador para visualizar os grupos de dados existentes. Você pode ver a conexão, o modelo e o status atual de cada grupo de dados e, se especificado no LookML, um rótulo e uma descrição para cada grupo de dados. Você também pode redefinir o cache de um grupo de dados, acionar o grupo ou acessar o LookML do grupo de dados.
Como o Looker usa consultas em cache
Para consultas, o mecanismo de armazenamento em cache no Looker funciona da seguinte maneira:
- Quando um usuário executa uma consulta específica, o resultado dela é armazenado em cache. Os resultados são armazenados em um arquivo criptografado na instância do Looker.
Quando uma nova consulta é escrita, o cache é verificado para confirmar se a consulta exata foi executada anteriormente. Todos os campos, filtros e parâmetros precisam ser iguais, incluindo configurações como limites de linhas. Se a consulta não for encontrada, o Looker a executará no banco de dados para receber novos resultados (e esses resultados serão armazenados em cache).
Os comentários de contexto não afetam o armazenamento em cache. O Looker adiciona um comentário exclusivo ao início de cada consulta SQL. No entanto, desde que a própria consulta SQL seja igual a uma consulta anterior (sem incluir os comentários de contexto), o Looker usará os resultados armazenados em cache.
Se a consulta for encontrada no cache, o Looker verificará a política de armazenamento em cache definida no modelo para ver se o cache ainda é válido. Por padrão, o Looker invalida os resultados armazenados em cache após uma hora. É possível usar um parâmetro
persist_for(no nível do modelo ou explorar) ou o parâmetrodatagroupmais eficiente para especificar a política de armazenamento em cache que determina as circunstâncias em que os resultados armazenados em cache se tornam inválidos e precisam ser ignorados. Um administrador também pode invalidar os resultados armazenados em cache de um grupo de dados.- Se o cache ainda for válido, esses resultados serão usados.
- Se o cache não for mais válido, o Looker executará a consulta no banco de dados para receber novos resultados. Esses novos resultados também são armazenados em cache.
Como ver se uma consulta foi retornada do cache
Em uma janela Explorar, você pode determinar se uma consulta foi retornada do cache ao olhar para ela no canto superior direito.
Quando uma consulta é retornada do cache, "do cache" é exibido. Caso contrário, o tempo para retornar a consulta é exibido.

Como forçar novos resultados a serem gerados do banco de dados
Em uma janela Explorar, é possível forçar a recuperação de novos resultados do banco de dados. Selecione a opção Limpar cache & atualizar no menu de engrenagem, que pode ser encontrado no canto superior direito da tela depois de executar uma consulta (incluindo as consultas dos resultados mesclados):
![]()
Uma tabela derivada permanente normalmente é gerada novamente com base na estratégia de persistência do PDT' É possível forçar a recriação da tabela derivada antecipadamente se o administrador tiver concedido a permissão develop e você estiver vendo um recurso Explorar que inclui campos do PDT. Selecione a opção Recriar tabelas derivadas e executar no menu suspenso da engrenagem, que pode ser encontrado no canto superior direito da tela depois de executar uma consulta:
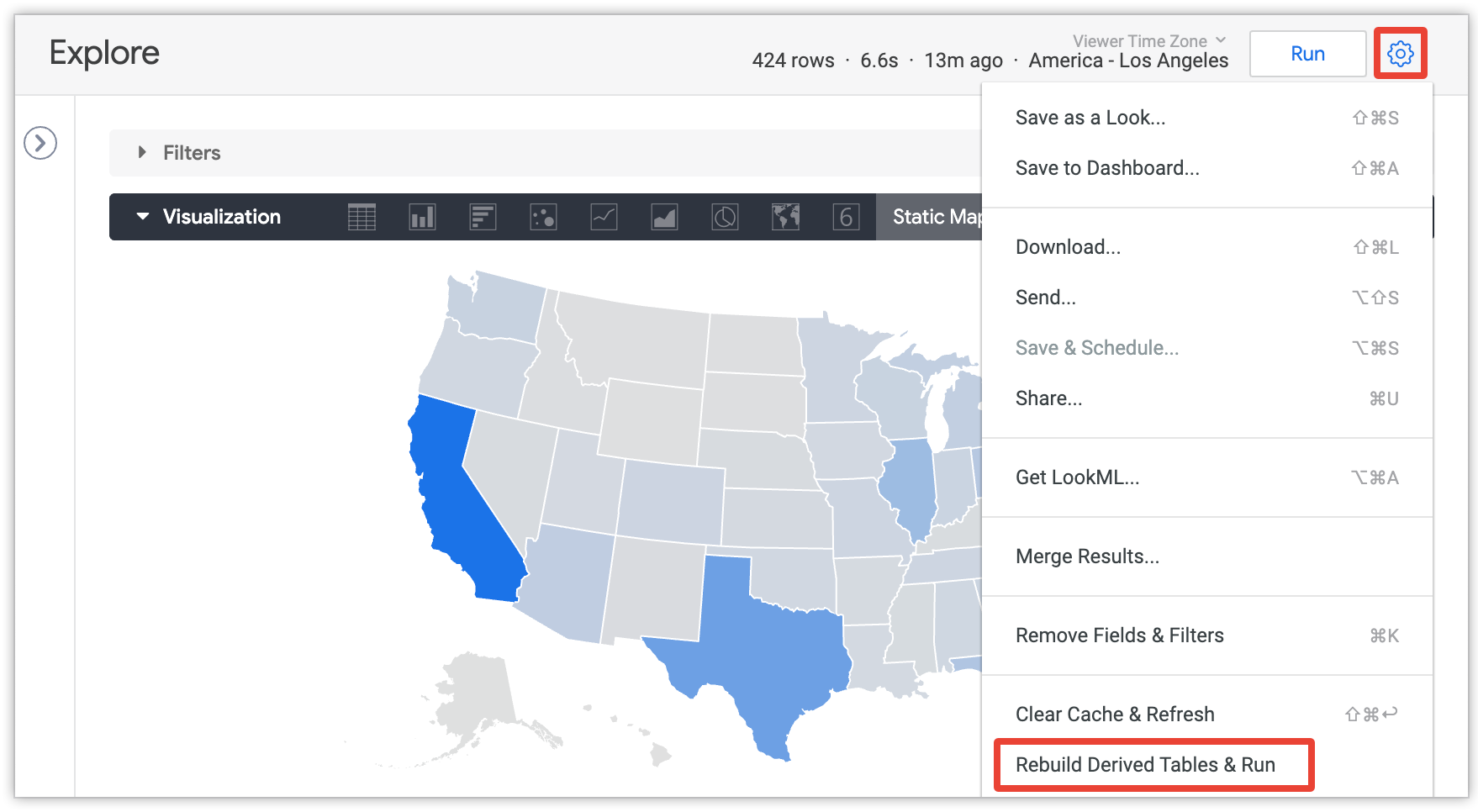
Consulte a página de documentação Tabelas derivadas no Looker para ver mais detalhes sobre a opção Recriar tabelas derivadas e execução.
Por quanto tempo os dados são armazenados em cache?
Para especificar o período antes de os resultados armazenados em cache se tornarem inválidos, use o parâmetro persist_for (para um modelo ou para um Explorar) ou o parâmetro max_cache_age (para um grupo de dados). Veja os diferentes comportamentos ao longo da linha do tempo, dependendo de o tempo persist_for ou max_cache_age ter expirado:
- Antes do tempo de
persist_foroumax_cache_ageexpirar: se a consulta for executada novamente, o Looker extrairá os dados do cache. - Quando o tempo
persist_foroumax_cache_ageexpirar: o Looker excluirá os dados do cache, a menos que você tenha ativado o recurso Looker Labs dos Painéis instantâneos. - Depois que o tempo
persist_foroumax_cache_ageexpirar: se a consulta for executada novamente, o Looker extrai os dados do banco de dados diretamente e redefine o timerpersist_foroumax_cache_age.
Um ponto-chave aqui é que os dados são excluídos do cache quando o tempo persist_for ou max_cache_age expira, desde que o recurso Painéis instantâneos do Looker Labs esteja desativado. O recurso Painéis instantâneos exige que o cache seja carregado imediatamente para carregar resultados armazenados em cache em um painel. Se você ativar os Painéis instantâneos, os dados permanecerão no cache por 30 dias ou até atingir os limites de armazenamento. Se o cache atingir o limite de armazenamento, os dados serão ejetados com base em um algoritmo de uso menos recente (LRU), sem garantia de que os dados com temporizadores persist_for ou max_cache_age expirados serão excluídos de uma só vez.
Minimizar o tempo que os dados passam no cache
O Looker exige o cache de disco para processos internos. Portanto, os dados sempre serão gravados no cache, mesmo que você defina os parâmetros persist_for e max_cache_age como 0. Depois de gravados no cache, os dados serão sinalizados para exclusão, mas podem permanecer até 10 minutos no disco.
No entanto, todos os dados do cliente que aparecem no cache de disco são criptografados com o Padrão de criptografia avançado (AES), e é possível minimizar a quantidade de tempo em que eles são armazenados no cache fazendo estas mudanças:
- Desative o recurso Looker Labs Looker Labs, que exige que o Looker armazene dados em cache.
- Para qualquer parâmetro
persist_for(para um modelo ou explorador) oumax_cache_age(para um grupo de dados), defina o valor como 0. Para instâncias do Looker com painéis instantâneos desativados, o Looker exclui o cache quando o tempopersist_forexpira ou quando os dados alcançam omax_cache_ageespecificado no grupo de dados. Isso não é necessário para o parâmetropersist_fordas tabelas derivadas permanentes, porque as tabelas derivadas permanentes são gravadas no próprio banco de dados, e não no cache. - Defina o parâmetro
suggest_persist_forcomo um pequeno período. O valorsuggest_persist_forespecifica por quanto tempo o Looker precisa manter as sugestões de filtro no cache. As sugestões de filtro são baseadas em uma consulta dos valores do campo que está sendo filtrado. Esses resultados da consulta são mantidos em cache para que o Looker possa fornecer sugestões rapidamente conforme o usuário digita no campo de texto do filtro. O padrão é armazenar em cache as sugestões de filtro por seis horas. Para minimizar o tempo que seus dados ficam no cache, defina o valorsuggest_persist_forcomo algo menor, como 5 minutos.