Para ver um guia sobre como implementar o reconhecimento agregado, consulte também o artigo da Central de Ajuda sobre reconhecimento agregado.
Visão geral
O Looker usa a lógica de reconhecimento agregado para encontrar a menor tabela e a mais eficiente disponível em seu banco de dados para executar uma consulta, mantendo a precisão.
Para tabelas muito grandes no seu banco de dados, os desenvolvedores do Looker podem criar tabelas de agregação menores, agrupadas por várias combinações de atributos. As tabelas de agregação atuam como visualizações completas ou tabelas de resumo que o Looker pode usar para consultas sempre que possível, em vez da tabela grande original. Quando implementados estrategicamente, o reconhecimento agregado pode acelerar a consulta média por ordens de magnitude.
Por exemplo, é possível ter uma tabela de dados com escala de petabyte com uma linha para cada pedido feito no seu site. Nesse banco de dados, você pode criar uma tabela agregada com seus totais de vendas diárias. Se o site recebe mil pedidos por dia, a tabela agregada diária representa 999 linhas menos do que a tabela original todos os dias. Você pode criar outra tabela agregada com totais mensais de vendas que serão ainda mais eficientes. Portanto, agora, se um usuário fizer uma consulta de vendas diárias ou semanais, o Looker usará a tabela de total de vendas diárias. Se um usuário executa uma consulta sobre vendas anuais e você não tem uma tabela de agregação anual, o Looker usa a próxima melhor opção, que é a tabela de vendas de vendas mensal neste exemplo.
Esta imagem mostra como o Looker responde às perguntas dos seus usuários com tabelas de agregação sempre que possível:
- Para uma consulta sobre o total de vendas mensais, o Looker usa a tabela agregada com base nas vendas mensais (
sales_monthly_aggregate_table). - Para uma consulta sobre o total de cada venda em um dia, não há uma tabela agregada com essa granularidade. Por isso, o Looker recebe os resultados da consulta da tabela de banco de dados original (
orders_database). No entanto, se os usuários executam esse tipo de consulta com frequência, é fácil criar uma tabela de agregação para ela. - Para uma consulta sobre vendas semanais, não há uma tabela de agregação semanal. Por isso, o Looker usa a próxima melhor opção, que é a tabela de agregação com base nas vendas diárias (
sales_daily_aggregate_table).

Com a lógica de reconhecimento agregado, o Looker consultará a menor tabela agregada possível para responder às perguntas dos seus usuários. A tabela original seria usada apenas para consultas que exigem granularidade mais precisa do que as tabelas agregadas podem fornecer.
As tabelas agregadas não precisam ser mescladas ou adicionadas a uma exploração separada. Em vez disso, o Looker ajusta dinamicamente a cláusula FROM da consulta "Explorar" para acessar a melhor tabela de agregação da consulta. Isso significa que seus furos são mantidos e os Explorars podem ser consolidados. Com o reconhecimento agregado, uma ferramenta Explorar pode usar automaticamente tabelas agregadas, mas sem deixar de se aprofundar em dados granulares, se necessário.
Também é possível aproveitar as tabelas agregadas para melhorar significativamente o desempenho dos painéis, especialmente para blocos que consultam conjuntos de dados muito grandes. Veja mais detalhes na seção Como conseguir uma tabela agregada LookML de um painel na página de documentação do parâmetro aggregate_table.
Como adicionar tabelas de agregação ao projeto
Para que haja reconhecimento de agregação, as tabelas agregadas devem ser mantidas no seu banco de dados. Como as tabelas de agregação são um tipo de tabela derivada permanente (PDT, na sigla em inglês), as tabelas de agregação têm os mesmos requisitos que as PDTs. Consulte a página de documentação Tabelas derivadas no Looker para ver mais detalhes.
Os desenvolvedores do Looker podem criar tabelas de agregação estratégicas que minimizarão o número de consultas necessárias nas tabelas grandes de um banco de dados. As tabelas agregadas precisam ser persistidas no banco de dados para que possam ser acessadas pelo reconhecimento agregado. Portanto, as tabelas agregadas são um tipo de tabela derivada permanente (PDT, na sigla em inglês).
Uma tabela agregada é definida usando o parâmetro aggregate_table em um parâmetro explore no projeto LookML.
Veja um exemplo de explore com uma tabela agregada no LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
Para criar uma tabela agregada, escreva o LookML do zero ou use o LookML do tabela em uma guia Explorar ou em um painel. Consulte a página de documentação do parâmetro aggregate_table para ver as especificações do parâmetro aggregate_table e os subparâmetros.
Como criar tabelas agregadas
Para que uma consulta "Explorar" use uma tabela agregada, ela precisa fornecer dados precisos. O Looker pode usar uma tabela agregada para uma consulta "Explorar" se todas as condições a seguir forem verdadeiras:
- Os campos "Explorar consulta" são um subconjunto dos campos da tabela agregada. Consulte a seção Fatores de campo nesta página. Os períodos de "Explorar" podem ser derivados dos períodos na tabela agregada. Consulte a seção Fatores do período nesta página.
- A consulta "Explorar" contém tipos de medição com suporte do reconhecimento agregado (consulte a seção Fatores de tipo de medição nesta página) ou a consulta "Explorar" tem uma tabela agregada que é uma correspondência exata. Consulte a seção Como criar tabelas agregadas que correspondem exatamente às consultas do Explorar nesta página).
- O fuso horário de "Explorar consulta" corresponde ao da tabela agregada. Consulte a seção Fatores de fuso horário nesta página.
- Os filtros de consulta "Explorar consulta" estão disponíveis como dimensões na tabela agregada, ou cada um dos filtros da consulta "Explorar" corresponde a um filtro na tabela agregada. Consulte a seção Fatores de filtro nesta página.
Para garantir que uma tabela agregada forneça dados precisos para uma consulta do Explorar, basta criar uma tabela agregada que corresponda exatamente a uma consulta do Explorar. Consulte a seção Como criar tabelas de agregação exatamente iguais à seção "Explorar consultas" nesta página para mais detalhes.
Fatores de campo
Para ser usada em uma consulta "Explorar", uma tabela agregada precisa ter todas as dimensões e medidas necessárias para essa consulta, incluindo os campos usados para filtros na consulta "Explorar". Se uma consulta de exploração tiver uma dimensão ou medida que não esteja em uma tabela de agregação, o Looker não poderá usar a tabela de agregação e usará a tabela de base.
Por exemplo, se uma consulta é agrupada pelas dimensões A e B, é agregada pela medida C e filtra pela dimensão D, a tabela agregada precisa ter A, B e D minimamente como dimensões e C como uma medida.
A tabela agregada também pode ter outros campos, mas ela precisa ter pelo menos os campos de consulta do Explorar para que seja viável para otimização. A única exceção são as dimensões de período, porque os períodos de granularidade mais amplas podem ser derivados dos detalhes mais granulares.
Por causa disso, uma tabela agregada é específica da exploração em que ela é definida. Uma tabela agregada definida em uma exploração não será usada para consultas em uma exploração diferente.
Fatores de período
A lógica de reconhecimento agregado do Looker pode derivar um período de outro. Uma tabela agregada pode ser usada para uma consulta, desde que o período da tabela agregada tenha uma granularidade mais refinada (ou igual) que a consulta "Explorar". Por exemplo, uma tabela agregada com base em dados diários pode ser usada em uma consulta "Explorar" que exige outros períodos, como consultas de dados diários, mensais e anuais ou até mesmo em dados de dia do mês, dia do ano e semana do ano. Mas uma tabela de agregação anual não pode ser usada para uma consulta de exploração que chame dados por hora, já que os dados da tabela agregada não têm granularidade suficiente para a consulta de exploração.
O mesmo se aplica aos subconjuntos de períodos. Por exemplo, se você tiver uma tabela de agregação filtrada para os últimos três meses e um usuário consultar os dados com um filtro para os últimos dois meses, o Looker poderá usar a tabela de agregação para essa consulta.
Além disso, a mesma lógica se aplica a consultas com filtros de período: uma tabela agregada pode ser usada para uma consulta com um filtro de período, desde que o período da tabela agregada tenha uma granularidade mais refinada (ou igual) que o filtro de período usado na consulta "Explorar". Por exemplo, uma tabela agregada com uma dimensão de período diário pode ser usada para uma consulta "Explorar" que filtra por dia, semana ou mês.
Medir os fatores de tipo
Para que uma consulta "Explorar" use uma tabela agregada, as medidas na tabela agregada precisam fornecer dados precisos para ela.
Por esse motivo, somente determinados tipos de medidas são compatíveis, conforme descrito nas seções a seguir:
- Medidas com tipos de medição compatíveis
- Medidas definidas por expressões SQL
- Medidas que não são definidas com
${TABLE} - Mede aproximadamente contagens distintas
Se uma consulta "Explorar" usar qualquer outro tipo de medida, o Looker usará a tabela original, não a tabela agregada, para retornar resultados. A única exceção é se a consulta "Explorar" é uma correspondência exata de uma consulta de tabela agregada, conforme descrito na seção Como criar tabelas agregadas que correspondem exatamente às consultas do recurso Explorar.
Caso contrário, o Looker usará a tabela original, não a tabela agregada, para retornar resultados.
Medições com tipos de medição compatíveis
O reconhecimento agregado pode ser usado em consultas "Explorar" que usam medidas com estes tipos de medida:
Se uma exploração mescla várias tabelas de banco de dados, o Looker pode renderizar medidas do tipo
SUM,COUNTeAVERAGEcomoSUM DISTINCT,COUNT DISTINCTeAVERAGE DISTINCT, respectivamente. O Looker faz isso para evitar erros de cálculo de fanout, conforme descrito na seção Agregações simétricas para Explorar com mesclas nesta página.
Para usar uma tabela agregada para uma consulta do Explorar, o Looker precisa conseguir operar nas medidas da tabela agregada para fornecer dados precisos na consulta do Explorar. Por exemplo, uma medida com type: sum pode ser usada para gerar reconhecimento agregado, porque é possível somar várias somas: uma tabela agregada de somas semanais pode ser adicionada para ter uma soma mensal precisa. Da mesma forma, uma medida com type: max pode ser usada porque uma tabela agregada de valores máximos diários pode ser usada para encontrar o máximo semanal preciso.
No caso de medidas com type: average, o reconhecimento agregado é compatível porque o Looker usa dados de soma e contagem para derivar com precisão os valores médios das tabelas de agregação.
Medidas definidas com expressões SQL
O reconhecimento agregado também pode ser usado com medidas definidas com expressões no parâmetro sql. Quando definidos com expressões SQL, os seguintes tipos de medidas também são compatíveis:
O reconhecimento agregado é compatível com medidas que são definidas como combinações de outras medidas, como neste exemplo:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
O reconhecimento agregado também é compatível com medidas em que os cálculos são definidos no parâmetro sql, como esta:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
O reconhecimento agregado é compatível com medidas em que as operações MIN, MAX e COUNT estão definidas no parâmetro sql, como esta medida:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
O reconhecimento agregado só é compatível com operações
MIN(),MAX()eCOUNT(). Se você quiser usar uma medida média ou de soma na tabela agregada, crie uma medidatype: averageoutype: sumcom suporte ao reconhecimento agregado.
Medidas que se referem aos campos do LookML
Quando expressões sql são usadas em medidas, o reconhecimento agregado oferece suporte aos seguintes tipos de referências de campo:
- Referências que usam o formato
${view_name.field_name}, que indica campos em outras visualizações - Referências que usam o formato
${field_name}, que indica campos na mesma visualização
Não há suporte ao reconhecimento agregado para medidas definidas no formato ${TABLE}.column_name, que indica uma coluna em uma tabela. Consulte a página de documentação Como incorporar SQL e se referir a objetos LookML para ter uma visão geral de como usar referências no LookML.
Por exemplo, uma medida definida com este parâmetro sql não seria compatível com uma tabela agregada, já que ela usa o formato ${TABLE}.column_name:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
Se você quiser incluir essa medida em uma tabela de agregação, crie uma dimensão definida com o formato ${TABLE}.column_name e, em seguida, crie uma medida que faça referência a ela, desta forma:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Agora é possível usar a medida wholesale_value na tabela de agregação.
Medidas que aproximam contagens distintas
Em geral, contagens distintas não são compatíveis com o reconhecimento agregado, porque não será possível conseguir dados precisos se você tentar agregar contagens distintas. Por exemplo, se você estiver contando os usuários diferentes em um site, pode haver um usuário que acessou o site duas vezes, três semanas de distância. Se você tentar aplicar uma tabela de agregação semanal para ver uma contagem mensal de usuários distintos no seu site, esse usuário será contado duas vezes na consulta de contagem distinta mensal e os dados ficarão incorretos.
Uma solução alternativa é criar uma tabela agregada que corresponda exatamente a uma consulta "Explorar", conforme descrito na seção Como criar tabelas agregadas que correspondam exatamente às consultas do Explorar nesta página. Quando a consulta "Explorar" e a consulta da tabela agregada são iguais, medidas de contagem distintas fornecem dados precisos para que sejam usadas no reconhecimento agregado.
Outra opção é usar aproximações para contagens distintas. Para dialetos compatíveis com esboços do HyperLogLog, o Looker pode aproveitar o algoritmo HyperLogLog para aproximar contagens distintas para tabelas de agregação.
Sabe-se que o algoritmo HyperLogLog tem um erro de cerca de 2%. O parâmetro allow_approximate_optimization: yes exige que os desenvolvedores do Looker reconheçam que é permitido usar dados aproximados para a medida, de modo que ela possa ser calculada aproximadamente a partir das tabelas de agregação.
Consulte a página de documentação do parâmetro allow_approximate_optimization para mais informações e para ver a lista de dialetos compatíveis com a contagem usando HyperLogLog.
Fatores de fuso horário
Em muitos casos, os administradores de banco de dados usam UTC como o fuso horário para os bancos de dados. No entanto, muitos usuários podem não estar no fuso horário UTC. O Looker tem várias opções para converter fusos horários, de modo que seus usuários recebam resultados de consulta no próprio fuso horário:
- Fuso horário da consulta, uma configuração que se aplica a todas as consultas na conexão do banco de dados. Se todos os usuários estiverem no mesmo fuso horário, defina um único fuso horário para a consulta. Assim, todas as consultas serão convertidas do fuso horário do banco de dados para o fuso horário da consulta.
- Fusos horários específicos do usuário, em que os usuários podem ser atribuídos e selecionar fusos horários individualmente. Nesse caso, as consultas são convertidas do fuso horário do banco de dados para o fuso horário do usuário individual.
Consulte a página de documentação Usar configurações de fuso horário para mais informações sobre essas opções.
Esses conceitos são importantes para entender o reconhecimento agregado porque, para que uma tabela agregada seja usada em uma consulta com dimensões ou filtros de data, o fuso horário dela precisa corresponder à configuração de fuso horário usada na consulta original.
As tabelas agregadas usam o fuso horário do banco de dados se nenhum valor timezone for especificado. Sua conexão de banco de dados também usará o fuso horário do banco de dados se alguma das condições a seguir for verdadeira:
- Seu banco de dados não é compatível com fusos horários.
- O fuso horário da consulta do seu banco de dados está configurado para o mesmo fuso horário do banco de dados.
- Sua conexão de banco de dados não tem um fuso horário específico para a consulta nem específico para o usuário. Nesse caso, sua conexão de banco de dados usará o fuso horário do banco de dados.
Se algum desses itens for verdadeiro, você poderá omitir o parâmetro timezone das tabelas de agregação.
Caso contrário, o fuso horário da tabela agregada precisará ser definido para corresponder às possíveis consultas, aumentando a probabilidade de a tabela agregada ser usada:
- Se a conexão do banco de dados usar um único fuso horário da consulta, você precisará corresponder o valor
timezoneda tabela agregada ao valor do fuso horário da consulta. - Caso sua conexão de banco de dados use fusos horários específicos do usuário, crie tabelas de agregação idênticas, cada uma com um valor
timezonediferente para corresponder aos possíveis fusos horários dos usuários.
O Looker não pode usar uma tabela agregada para uma consulta "Explorar" se o fuso horário da tabela agregada não corresponder ao da consulta. Se a conexão do banco de dados tiver fusos horários específicos ao usuário, isso significa que você precisa de uma tabela de agregação separada para cada um dos fusos horários do usuário.
Filtrar fatores
Tenha cuidado ao incluir filtros na sua tabela agregada. Os filtros em uma tabela agregada podem restringir os resultados ao ponto em que a tabela agregada não pode ser utilizada. Por exemplo, digamos que você crie uma tabela agregada para a contagem diária de pedidos e os filtros da tabela agregada apenas para pedidos de óculos de sol na Austrália. Se um usuário executar uma consulta "Explorar" para a contagem diária de óculos de sol no mundo todo, o Looker não poderá usar a tabela agregada para essa consulta, porque ela só tem dados para a Austrália. A tabela de agregação filtra os dados de forma muito restrita para que sejam usados pela consulta "Explorar".
Além disso, considere os filtros que seus desenvolvedores do Looker podem ter integrado em "Explorar", como:
access_filters: aplica restrições de dados específicos do usuário.always_filter: exigir que os usuários incluam um determinado conjunto de filtros em uma consulta de exploração. Os usuários podem alterar o valor do filtro padrão para a consulta, mas não podem remover o filtro completamente.conditionally_filter: define um conjunto de filtros padrão que os usuários podem substituir se aplicarem pelo menos um filtro de uma segunda lista que também é definida em "Explorar".
Esses tipos de filtro são baseados em campos específicos. Se a guia "Explorar" tiver esses filtros, você precisará incluir os campos deles no parâmetro dimensions do aggregate_table.
Por exemplo, aqui está uma exploração com um filtro de acesso baseado no campo orders.region:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
Para criar uma tabela agregada que seria usada para esta exploração, ela precisa incluir o campo em que o filtro de acesso se baseia. No exemplo a seguir, o filtro de acesso é baseado no campo orders.region, que é incluído como uma dimensão na tabela de agregação:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Como a consulta da tabela agregada inclui a dimensão orders.region, o Looker pode filtrar dinamicamente os dados na tabela agregada para corresponder ao filtro da consulta "Explorar". Portanto, o Looker ainda pode usar a tabela agregada para as consultas do "Explorar", mesmo que ele tenha um filtro de acesso.
Isso também se aplica a consultas "Explorar" que usam uma tabela derivada nativa configurada com bind_filters. O parâmetro bind_filters transmite filtros especificados de uma consulta"Explorar"para a subconsulta da tabela derivada nativa. No caso do reconhecimento agregado, se a consulta "Explorar" exigir uma tabela derivada nativa que usa bind_filters, a consulta "Explorar" só poderá usar uma tabela agregada se todos os campos usados no parâmetro bind_filters da tabela nativa nativa tiverem os mesmos valores de filtro na consulta "Explorar" que a tabela de agregação.
Criar tabelas agregadas que correspondam exatamente às consultas do Explorar
Para ter certeza de que uma tabela agregada pode ser usada para uma consulta "Explorar", basta criar uma tabela agregada que corresponda exatamente à consulta "Explorar". Se a consulta "Explorar" e a tabela agregada usarem as mesmas medidas, dimensões, filtros, fusos horários e outros parâmetros, os resultados da tabela agregada serão aplicados à consulta "Explorar". Se uma tabela agregada corresponder exatamente a uma consulta Explorar, o Looker poderá usar tabelas agregadas que incluem qualquer tipo de medida.
Você pode criar uma tabela agregada com base em uma exploração usando a opção Get LookML no menu de engrenagem de uma Explore. Também é possível criar correspondências exatas para todos os blocos em um painel usando a opção Consultar LookML no menu de engrenagem de um painel.
Como determinar qual tabela agregada é usada para uma consulta
Usuários com permissões see_sql podem usar os comentários na guia SQL de um recurso Explorar para ver qual tabela agregada será usada em uma consulta. Os comentários da guia SQL também são exibidos no Modo de desenvolvimento, para que os desenvolvedores possam testar novas tabelas de agregação para ver como o Looker as usa antes de enviar novas tabelas para produção.
Por exemplo, com base na tabela de exemplo mensal de agregação mostrada anteriormente, podemos acessar "Explorar" e executar uma consulta para os totais de vendas anuais. Clique na guia SQL para ver os detalhes da consulta criada pelo Looker. Se você estiver no modo de desenvolvimento, o Looker mostrará comentários para indicar a tabela de agregação que ele usou para a consulta:

A partir dos comentários na guia SQL, vemos que o Looker está usando a tabela de agregação sales_monthly para essa consulta e informações sobre por que outras tabelas de agregação não foram usadas para a consulta:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
Consulte a seção Solução de problemas nesta página para ver comentários possíveis na guia SQL e sugestões para resolvê-los.
Estimativas de economia de computação para reconhecimento agregado
Se a conexão do banco de dados for compatível com as estimativas de custo e se for possível usar uma tabela agregada para uma consulta, a janela "Explorar" mostrará a economia computacional de usar a tabela de agregação em vez de consultar o banco de dados diretamente. A economia de reconhecimento agregada é mostrada à esquerda do botão Executar em uma exploração antes da execução da consulta:

Antes de executar a consulta, se você quiser ver qual tabela agregada será usada para a consulta, clique na guia SQL, conforme descrito na seção Como determinar qual tabela agregada é usada para uma consulta desta página de documentação.
Depois que a consulta é executada, a janela "Explorar" mostra qual tabela agregada foi usada para responder à consulta:

A economia agregada de reconhecimento é exibida para conexões de banco de dados ativadas para estimativas de custo. Consulte a página de documentação Como analisar dados no Looker para mais informações.
O Looker une novos dados às tabelas de agregação.
Para tabelas de agregação com filtros de tempo, o Looker pode unir dados atualizados na tabela de agregação. Talvez você tenha uma tabela agregada com dados dos últimos três dias, mas ela pode ter sido criada ontem. A tabela de agregação não mostraria as informações de hoje. Por isso, você não gostaria de usá-la em uma consulta "Explorar" com as informações diárias mais recentes.
No entanto, o Looker ainda pode usar os dados da tabela agregada para a consulta porque o Looker vai executar uma consulta nos dados mais recentes e, em seguida, unir esses resultados nos resultados da tabela de agregação.
O Looker pode mesclar dados atualizados com os dados agregados da sua tabela de acordo com as seguintes circunstâncias:
- A tabela agregada tem um filtro de tempo.
- A tabela agregada inclui uma dimensão com base no mesmo campo de tempo do filtro de tempo.
Por exemplo, a tabela agregada a seguir tem uma dimensão com base no campo orders.created_date e um filtro de tempo ("3 days") com base no mesmo campo:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
Se esta tabela agregada tiver sido criada ontem, o Looker recuperará os dados mais recentes que ainda não foram incluídos na tabela de agregação. Em seguida, eles serão unidos com os resultados da tabela de agregação. Isso significa que seus usuários receberão os dados mais recentes e, ao mesmo tempo, otimizarão o desempenho usando o reconhecimento agregado.
Se você estiver no modo de desenvolvimento, clique na guia SQL de um "Explorar" para ver a tabela agregada que o Looker usou para a consulta e a instrução UNION que o Looker usou para trazer dados mais recentes que não foram incluídos na tabela de agregação.
Atualmente, se o Looker não conseguir mesclar dados atualizados com sua tabela de agregação, o Looker usará os dados existentes da tabela de agregação.
As tabelas agregadas precisam ser mantidas
Para que seja possível acessar o reconhecimento agregado, sua tabela agregada precisa persistir no banco de dados. A estratégia de persistência é especificada no parâmetro materialization da tabela agregada. Como as tabelas de agregação são um tipo de tabela derivada permanente (PDT, na sigla em inglês), as tabelas de agregação têm os mesmos requisitos que as PDTs. Consulte a página de documentação Tabelas derivadas no Looker para ver mais detalhes.
Você pode criar PDTs incrementais no seu projeto, se o dialeto oferecer suporte a eles. O Looker cria PDTs incrementais anexando novos dados à tabela, em vez de recriá-la totalmente. Como as tabelas de agregação são um tipo de PDT, você também pode criar tabelas de agregação incrementais. Consulte a página de documentação de PDTs incrementais para mais informações. Consulte a página de documentação do parâmetro increment_key para ver um exemplo de tabela de agregação incremental.
Um usuário com a permissão develop pode modificar as configurações de persistência e recriar todas as tabelas agregadas de uma consulta para ter os dados mais atualizados. Para recriar as tabelas de uma consulta, use a opção Recriar tabelas derivadas e execução no menu "Explorar":
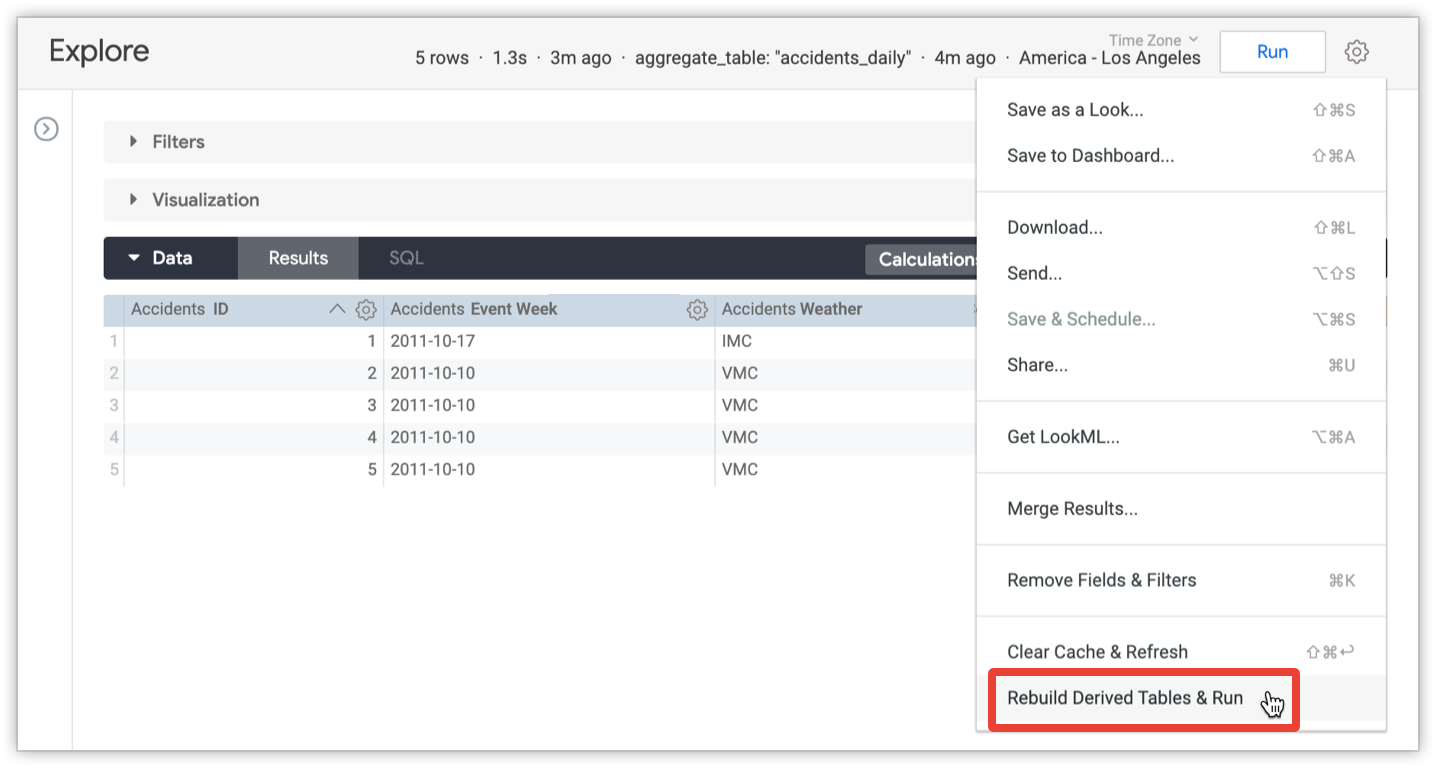
Aguarde até que a consulta "Explorar" seja carregada antes que essa opção seja disponibilizada.
A opção Recriar tabelas derivadas e execução recriará todas as tabelas derivadas referenciadas na consulta e todas as tabelas derivadas que dependem das tabelas na consulta. Isso inclui tabelas agregadas, que são um tipo de tabela derivada permanente.
Para o usuário que iniciar a opção Recriar tabelas derivadas e execução, a consulta aguardará a reconstrução das tabelas antes de carregar os resultados. As consultas de outros usuários continuarão usando as tabelas atuais. Quando as tabelas persistentes forem recriadas, todos os usuários usarão as tabelas recriadas.
Consulte a página de documentação Tabelas derivadas no Looker para ver mais detalhes sobre a opção Recriar tabelas derivadas e execução.
Solução de problemas
Conforme descrito na seção Como determinar qual tabela agregada é usada para uma consulta, se você estiver no Modo de desenvolvimento, é possível executar consultas no Explorar e clicar na guia SQL para ver comentários sobre a tabela de agregação usada para a consulta.
A guia SQL também inclui comentários sobre o motivo de as tabelas agregadas não serem usadas em uma consulta, se esse for o caso. O comentário começa com estas tabelas agregadas que não são usadas:
Did not use [explore name]::[aggregate table name];
Por exemplo, este é um comentário sobre o motivo pelo qual a tabela de agregação sales_daily definida na exploração order_items não foi usada para uma consulta:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
Nesse caso, os filtros na consulta impediram o uso da tabela agregada.
A tabela a seguir mostra alguns outros possíveis motivos para que uma tabela agregada não possa ser usada, além das etapas que você pode seguir para aumentar a usabilidade da tabela agregada.
| Motivo para não usar a tabela agregada |
Explicação e possíveis etapas |
|---|---|
| Este campo em "Explorar" não existe. | Há um erro do tipo de validação LookML. Isso provavelmente ocorre porque a tabela agregada não foi definida corretamente ou houve um erro de digitação no LookML na tabela agregada. Um provável culpado é o nome incorreto do campo ou algo semelhante. Para resolver isso, verifique se as dimensões e medidas na tabela agregada correspondem aos nomes dos campos em Explorar. Consulte a página de documentação do parâmetro aggregate_table para mais informações sobre como definir uma tabela agregada. |
| A tabela de agregação não inclui os campos a seguir na consulta. | Para ser usada em uma consulta "Explorar", uma tabela agregada precisa ter todas as dimensões e medidas necessárias para essa consulta, incluindo os campos usados para filtros na consulta "Explorar". Se uma consulta de exploração tiver uma dimensão ou medida que não esteja em uma tabela de agregação, o Looker não poderá usar a tabela de agregação e usará a tabela de base. Consulte a seção Fatores de campo nesta página para ver mais detalhes. A única exceção são as dimensões de período, porque os períodos de granularidade mais amplas podem ser derivados dos detalhes mais granulares. Para resolver isso, verifique se os campos da consulta "Explorar" estão incluídos na definição da tabela agregada. |
| A consulta contém os seguintes filtros que não foram incluídos como campos e não corresponderam exatamente aos filtros na tabela agregada. | Os filtros na consulta "Explorar" impedem que o Looker use a tabela de agregação. Para resolver esse problema, você tem duas opções:
|
| A consulta contém as medidas a seguir que não podem ser agrupadas. | A consulta contém um ou mais tipos de medidas que não são compatíveis com o reconhecimento agregado, como contagem distinta, mediana ou percentil. Para resolver isso, verifique o tipo de cada medida na consulta e se é um dos tipos de medidas compatíveis. Além disso, se você usar as funções Explorar com as junções, verifique se as medidas não foram convertidas em medidas distintas (agregações simétricas) usando mesclagens transmitidas. Consulte a seção Agregações simétricas para os Explorars com mesclagens nesta página para ver uma explicação. |
| Uma tabela de agregação diferente era a opção ideal para otimização. | Havia várias tabelas de agregação viáveis para a consulta, e o Looker encontrou uma tabela de agregação mais ideal para usar. Nesse caso, nenhuma ação será necessária. |
O Looker não fez nenhum agrupamento (devido a um parâmetro primary_key ou cancel_grouping_fields) e, portanto, a consulta não pode ser agregada. |
A consulta faz referência a uma dimensão que impede que ela tenha uma cláusula GROUP BY. Portanto, o Looker não pode usar nenhuma tabela agregada para a consulta.
Para resolver isso, verifique se os parâmetros primary_key das visualizações e o cancel_grouping_fields "Explorar" estão configurados corretamente. |
| A tabela agregada contém filtros que não estão na consulta. | A tabela agregada tem um filtro sem período, que não está na consulta. Para resolver isso, remova o filtro da tabela agregada. Consulte a seção Filtrar fatores nesta página para ver mais detalhes. |
Um campo é definido como somente filtro na consulta"Explorar", mas está listado no parâmetro dimensions da tabela agregada. |
O parâmetro dimensions da tabela agregada lista um campo definido apenas como um campo filter na consulta da exploração.Para resolver isso, remova o campo da lista dimensions da tabela agregada. Se este campo for necessário para a tabela agregada, adicione-o à lista filters na consulta da tabela agregada. |
| O otimizador não pode determinar por que a tabela agregada não foi usada. | Este comentário é reservado para casos isolados. Se essa consulta for usada com frequência, crie uma tabela agregada que corresponda exatamente à consulta "Explorar". É possível acessar facilmente o LookML da tabela a partir de uma exploração, conforme descrito na página de parâmetros aggregate_table. |
Considerações
Agregações simétricas para "explores" com mesclas
É importante observar que, em uma exploração que mescla várias tabelas de banco de dados, o Looker pode renderizar medidas do tipo SUM, COUNT e AVERAGE como SUM DISTINCT, COUNT DISTINCT e AVERAGE DISTINCT, respectivamente. O Looker faz isso para evitar erros de cálculo de fanout. Por exemplo, uma medida count é renderizada como um tipo de medida count_distinct. Isso evita erros de cálculo de fanout nas mesclagens e faz parte da funcionalidade de agregação simétrica do Looker. Consulte o artigo da Central de Ajuda sobre agregações simétricas para ver uma explicação sobre esse recurso do Looker.
A funcionalidade de agregação simétrica evita erros de cálculo, mas também pode impedir que as tabelas de agregação sejam usadas em determinados casos. Por isso, é importante entender.
Para os tipos de medição compatíveis com o reconhecimento agregado, isso se aplica a sum, count e average. O Looker renderizará esses tipos de medidas como DISTINCT se:
- A medida é a partir da visão de "um para todos" ou um para muitos.
- A medição é de qualquer visualização de uma mesclagem muitos para muitos.
Consulte a página de documentação do parâmetro relationship para ver uma explicação sobre esses tipos de mesclagem.
Se você descobrir que sua tabela agregada não está sendo usada por esse motivo, crie uma tabela agregada para corresponder exatamente a uma consulta "Explorar" e use esses tipos de medição para uma exploração com mesclagens. Consulte a seção Como criar tabelas agregadas que correspondem exatamente às consultas "Explorar" nesta página para mais informações.
Além disso, se você tiver um dialeto SQL compatível com os esboços do HyperLogLog, poderá adicionar o parâmetro allow_approximate_optimization: yes à medida. Quando uma medida de contagem é definida com allow_approximate_optimization: yes, o Looker pode usar a medida para reconhecimento agregado, mesmo que ela seja renderizada como uma contagem distinta.
Consulte a página de documentação do parâmetro allow_approximate_optimization para ver mais detalhes e uma lista de quais dialetos SQL são compatíveis com esboços do HyperLogLog.
Entender o suporte ao reconhecimento agregado
A capacidade de usar o reconhecimento agregado depende do dialeto do banco de dados que sua conexão do Looker está usando. Na versão mais recente do Looker, os seguintes dialetos são compatíveis com o reconhecimento agregado:
O SQL legado do Google BigQuery é compatível com o reconhecimento agregado, mas não com a integração de dados atualizados com os dados da tabela agregada.
Entender o suporte à criação incremental de tabelas de agregação
Para que o Looker ofereça suporte a tabelas de agregação incrementais no seu projeto do Looker, o dialeto do banco de dados também precisará torná-las compatíveis. A tabela a seguir mostra quais dialetos são compatíveis com tabelas agregadas e criando PDTs de maneira incremental na versão mais recente do Looker: