No Looker, as tabelas derivadas permanentes (PDTs, na sigla em inglês) são gravadas no esquema de raspadinha do banco de dados. O Looker persiste e recria uma PDT com base na sua estratégia de persistência. Quando uma PDT é acionada para recriar, por padrão, o Looker recria toda a tabela.
Se o discetário for compatível com PDTs incrementais, será possível anexar novos dados a ele, em vez de recriar um PDT inteiro:
Na primeira vez que você executa uma consulta em um PDT incremental, o Looker cria o PDT inteiro para conseguir os dados iniciais. Se a tabela for grande, o build inicial poderá levar um tempo significativo, assim como qualquer tabela grande. Depois que a tabela inicial for criada, os builds subsequentes serão incrementais e levarão menos tempo, se o PDT incremental estiver configurado estrategicamente.
Além disso, verifique se a tabela de origem PDT' incremental está otimizada para consultas baseadas em tempo. Especificamente, a coluna com base no tempo usada para a chave de incremento precisa ter uma estratégia de otimização, como particionamento, ordens de classificação, índices ou qualquer estratégia de otimização compatível com seu dialeto. O Optimize é altamente recomendado porque cada vez que a tabela incremental é atualizada, o Looker consulta a tabela de origem para determinar os valores mais recentes da coluna de tempo baseada para a chave de incremento. Se a tabela de origem não estiver otimizada para essas consultas, a consulta do Looker para os valores mais recentes poderá ser lenta e cara.
Se o dialeto for compatível com PDTs incrementais, será possível transformar os seguintes tipos em PDTs incrementais:
- Tabelas de agregação
- PDTs baseados em LookML (nativos)
PDTs baseados em SQL
Para PDTs baseados em SQL, a consulta da tabela precisa ser definida usando o parâmetro
sqla ser usado como PDT incremental. As PDTs baseadas em SQL definidas com o parâmetrosql_createoucreate_processnão podem ser criadas de modo incremental. Como você pode ver no Exemplo 1 desta página, o Looker usa um comando INSERT ou merge para criar os incrementos de um PDT incremental. A tabela derivada não pode ser definida usando instruções personalizadas de Linguagem de definição de dados (DDL), já que o Looker não poderia determinar quais instruções DDL seriam necessárias para criar um incremento preciso.
Como definir um PDT incremental
Use os parâmetros a seguir para transformar um PDT em um PDT incremental:
increment_key(obrigatório para transformar o PDT em um PDT incremental): define o período pelo qual novos registros precisam ser consultados.{% incrementcondition %}Filtro líquido (obrigatório para transformar uma PDT baseada em SQL em um PDT incremental. Não aplicável para PDTs baseados em LookML): conecta a chave de incremento à coluna de tempo do banco de dados em que a chave de incremento é baseada. Consulte a página de documentação doincrement_keypara ver mais informações.increment_offset(opcional): um número inteiro que define o número de períodos anteriores (com granularidade na chave de incremento e 3) que são recriados para cada build incremental. O parâmetroincrement_offseté útil no caso de dados atrasados, em que períodos anteriores podem ter novos dados que não foram incluídos quando o incremento correspondente foi originalmente criado e anexado ao PDT.
Consulte a página de documentação do parâmetro increment_key para ver exemplos de como criar PDTs incrementais com base em tabelas derivadas nativas permanentes, tabelas derivadas permanentes baseadas em SQL e tabelas agregadas.
Veja um exemplo simples de um arquivo de visualização que define um PDT incremental baseado em LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Ela será construída totalmente na primeira vez que uma consulta for executada nela. Depois disso, a PDT será recriada em incrementos de um dia (increment_key: departure_date), voltando três dias (increment_offset: 3).
A chave de incremento é baseada na dimensão departure_date, que é, na realidade, o cronograma date do grupo de dimensões departure. Consulte a página de documentação do parâmetro dimension_group para ter uma visão geral de como os grupos de dimensões funcionam. O grupo de dimensões e o período são definidos na visualização flights, que é o explore_source para esse PDT. Veja como o grupo de dimensões departure é definido no arquivo de visualização flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interação de parâmetros de incremento e estratégia de persistência
As configurações de increment_key e increment_offset de PDT' são independentes da estratégia de persistência do PDT'
- A estratégia de persistência incremental de PDT e 39; determina apenas quando o PDT incrementa. O builder de PDT não modifica o PDT incremental, a menos que a estratégia de persistência da tabela seja acionada ou a menos que o PDT seja acionado manualmente com a opção Recriar tabelas derivadas e execução em uma exploração.
- Quando o PDT aumenta, o builder de PDT determina quando os dados mais recentes foram adicionados à tabela de acordo com o incremento de tempo mais atual (o período definido pelo parâmetro
increment_key). Com base nisso, o builder de PDT trunca os dados para o início do incremento de tempo mais recente na tabela e, em seguida, cria o incremento mais recente. - Se a PDT tiver um parâmetro
increment_offset, o builder de PDT também vai recriar o número de períodos anteriores especificados no parâmetroincrement_offset. Os períodos anteriores começam no início do incremento de tempo mais atual (o período que é definido pelo parâmetroincrement_key).
Os exemplos de cenários a seguir ilustram como as PDTs incrementais são atualizadas, mostrando a interação de increment_key, increment_offset e a estratégia de persistência.
Exemplo 1
Este exemplo usa um PDT com as seguintes propriedades:
- Incrementar chave: data
- Incremento de incremento: 3
- Estratégia de persistência: acionada uma vez por mês no primeiro dia do mês
Veja como essa tabela será atualizada:
- Uma estratégia de persistência mensal significa que a tabela é criada automaticamente uma vez por mês. Isso significa que, em 1o de junho, por exemplo, a última linha na tabela será adicionada em 1o de maio.
- Como essa PDT tem uma chave de incremento com base na data, o builder de PDT será truncado no dia 1o de maio até o início do dia e recriará os dados de 1o de maio e até o dia atual, 1o de junho.
- Além disso, essa PDT tem um deslocamento de incremento de
3. Portanto, o builder de PDT também recria os dados dos três períodos anteriores (dias) antes de 1o de maio. O resultado é que os dados são reconstruídos para 28, 29, 30 de abril e até o dia atual de 1o de junho.
Em termos de SQL, este é o comando que o builder de PDT executará no dia 1o de junho para determinar as linhas do PDT existente que devem ser recriadas:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Este é o comando SQL que o builder de PDT executará em 1o de junho para criar o incremento mais recente:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Exemplo 2
Este exemplo usa um PDT com as seguintes propriedades:
- Estratégia de persistência: acionada uma vez por dia
- Incrementar chave: mês
- Aumento de incremento: 0
Veja como esta tabela será atualizada em 1o de junho:
- A estratégia de persistência diária significa que a tabela é criada automaticamente uma vez por dia. No dia 1o de junho, a última linha da tabela será adicionada em 31 de maio.
- Como a chave de incremento é baseada no mês, o builder de PDT será truncado de 31 de maio até o início do mês e recriará os dados de maio e até o dia atual, incluindo 1o de junho.
- Como essa PDT não tem deslocamento de incremento, nenhum período anterior é reconstruído.
Veja como esta tabela será atualizada em 2 de junho:
- No dia 2 de junho, a última linha da tabela será adicionada em 1o de junho.
- Como o builder de PDT será truncado no início do mês de junho, será recriado os dados a partir de 1o de junho e até o dia atual, os dados serão recriados somente para 1o de junho e 2 de junho.
- Como essa PDT não tem deslocamento de incremento, nenhum período anterior é reconstruído.
Exemplo 3
Este exemplo usa um PDT com as seguintes propriedades:
- Incrementar chave: mês
- Incremento de incremento: 3
- Estratégia de persistência: acionada uma vez por dia
Esse cenário ilustra uma configuração ruim de PDT incremental, já que é um PDT de acionamento diário com um deslocamento de três meses. Isso significa que pelo menos três meses de dados serão recriados todos os dias, o que seria um uso muito ineficiente de uma PDT incremental. No entanto, é um cenário interessante examinar como uma forma de entender como PDTs incrementais funcionam.
Veja como esta tabela será atualizada em 1o de junho:
- A estratégia de persistência diária significa que a tabela é criada automaticamente uma vez por dia. Por exemplo, em 1o de junho, a última linha da tabela será adicionada em 31 de maio.
- Como a chave de incremento é baseada no mês, o builder de PDT será truncado de 31 de maio até o início do mês e recriará os dados de maio e até o dia atual, incluindo 1o de junho.
- Além disso, essa PDT tem um deslocamento de incremento de
3. Isso significa que o builder de PDT também recria os dados dos três períodos anteriores (meses) antes de maio. Como resultado, os dados são recriados de fevereiro, março, abril e até o dia atual, 1o de junho.
Veja como esta tabela será atualizada em 2 de junho:
- No dia 2 de junho, a última linha da tabela será adicionada em 1o de junho.
- O builder de PDT truncará o mês até 1o de junho e recriará os dados do mês de junho, incluindo 2 de junho.
- Além disso, devido ao deslocamento de incremento, o builder de PDT recriará os dados dos três meses anteriores antes de junho. Por isso, os dados são reconstruídos de março, abril, maio e até o dia atual, 2 de junho.
Como testar um PDT incremental no modo de desenvolvimento
Antes de implantar um novo PDT incremental no seu ambiente de produção, é possível testar o PDT para confirmar se ele é criado e incrementado. Para testar um PDT incremental no modo de desenvolvimento, siga estas etapas:
- Crie uma exploração para o PDT:
include: "/views/e_faa_pdt.view"
explore: e_faa_pdt {}
Abra a guia "Explorar" para a PDT.
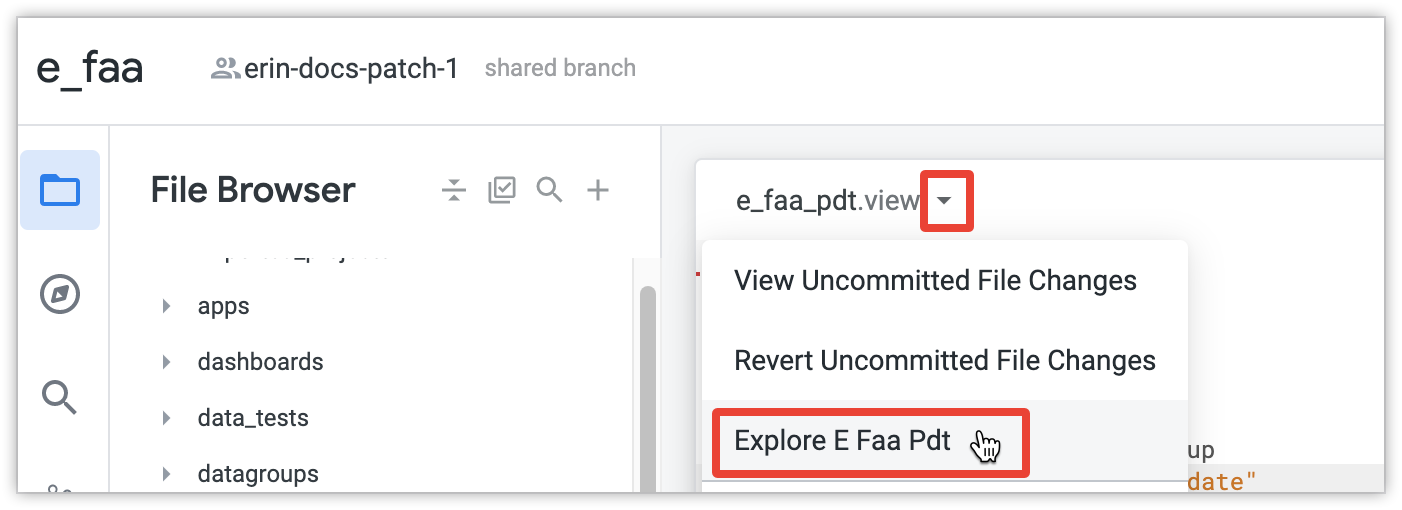
DICA: depois de incluir a visualização no seu arquivo de modelo e criar uma exploração, você pode navegar diretamente para a exploração pelo arquivo de visualização ou pelo arquivo de modelo do seu projeto LookML usando o menu de ações do arquivo na parte superior do arquivo LookML:
Em "Explorar", selecione algumas dimensões ou medidas e clique em Executar. O Looker criará todo o PDT. Se esta for a primeira consulta executada no PDT incremental, o builder de PDT criará todo o PDT para obter os dados iniciais. Se a tabela for grande, o build inicial poderá levar um tempo significativo, assim como qualquer tabela grande.
Verifique se a PDT inicial foi criada das seguintes maneiras:
- Se você tiver a permissão
see_logs, poderá verificar se a tabela foi criada procurando no Log de eventos PPD. Se o PDT não criar eventos no log de eventos de PDT, verifique as informações de status na parte superior do PDT Event Log Explore. Se ele selecionar "quot;from cache"," você pode selecionar Limpar cache & Refresh para receber informações mais recentes. - Caso contrário, observe os comentários na guia SQL da barra Dados de Explorar. A guia SQL mostra a consulta e as ações que serão realizadas quando você executar a consulta em "Explorar". Por exemplo, se os comentários na guia SQL indicarem
-- generate derived table e_incremental_pdt,
- Se você tiver a permissão
Depois de criar a versão inicial da PDT, solicite uma versão incremental da PDT usando a opção Rebuild Derived Tables & Run em "Explorar".
Use os mesmos métodos de antes para verificar se a PDT foi criada de modo incremental:
- Se você tiver a permissão
see_logs, poderá usar o LogT Event Log para ver os eventoscreate increment completedo PDT incremental. Se você não vir esse evento no log de eventos de PDT e o status da consulta for "quot;from cache"," selecione Limpar cache & atualizar para receber informações mais recentes. - Veja os comentários na guia SQL da barra Dados de Explorar. Nesse caso, os comentários vão indicar que a PDT foi incrementada. Por exemplo:
-- increment persistent derived table e_incremental_pdt to generation 2
- Se você tiver a permissão
Depois de verificar se o PDT está criado e incrementando corretamente, se você não quiser manter o Explorar dedicado para o PDT, poderá remover ou comentar os parâmetros
exploreeincludedo PDT do arquivo de modelo.
Depois que o PDT for criado no modo de desenvolvimento, a mesma tabela vai ser usada para produção depois de implantar as alterações, a menos que você faça mais alterações na definição da tabela. Consulte a seção Tabelas persistentes no modo de desenvolvimento da página de documentação Tabelas derivadas no Looker para mais informações.
Dialetos do banco de dados compatíveis com PDTs incrementais
Para que o Looker ofereça suporte a PDTs incrementais no seu projeto do Looker, o dialeto do banco de dados precisa ser compatível com comandos de linguagem de definição de dados (DDL) que permitem excluir e inserir linhas.
A tabela a seguir mostra quais dialetos são compatíveis com PDTs incrementais na versão mais recente do Looker: