Questo argomento mostra come misurare k-anonymity di un set di dati utilizzando la protezione dei dati sensibili e come visualizzarla in Looker Studio. In questo modo, potrai anche comprendere meglio i rischi e valutare i compromessi in termini di utilità che potresti ottenere se oscurisci o anonimizzi i dati.
Sebbene l'argomento sia incentrato sulla visualizzazione della metrica di analisi del rischio di reidentificazione k-anonymity, puoi anche visualizzare la metrica l-diversity utilizzando gli stessi metodi.
Questo argomento presuppone che tu conosca già il concetto di k-anonymity e la sua utilità per valutare la riidentificabilità dei record all'interno di un set di dati. Sarà anche utile avere almeno un po' di familiarità con il calcolo di k-anonymity mediante Sensitive Data Protection e l'utilizzo di Looker Studio.
Introduzione
Le tecniche di anonimizzazione possono essere utili per proteggere la privacy dei tuoi soggetti durante l'elaborazione o l'utilizzo dei dati. Ma come fare a sapere se un set di dati è stato sufficientemente anonimizzato? E come fai a sapere se l'anonimizzazione ha comportato una perdita di dati eccessiva per il tuo caso d'uso? In altre parole, come puoi confrontare il rischio di reidentificazione con l'utilità dei dati per prendere decisioni basate sui dati?
Il calcolo del valore k-anonymity di un set di dati aiuta a rispondere a queste domande valutando la riidentificabilità dei record del set di dati. Sensitive Data Protection contiene funzionalità integrate per calcolare un valore k-anonymity su un set di dati basato su quasi-identificatori da te specificati. Ciò consente di valutare rapidamente se l'anonimizzazione di una determinata colonna o di una combinazione di colonne determina la creazione di un set di dati con maggiori o minori probabilità di essere reidentificato.
Set di dati di esempio
Di seguito sono riportate le prime righe di un grande set di dati di esempio.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Ai fini di questo tutorial, user_id non verrà esaminato, perché l'attenzione è concentrata
sui quasi-identificatori. In uno scenario reale, assicurati che user_id sia oscurato o token correttamente. La colonna score è di proprietà di questo set di dati ed è improbabile che un utente malintenzionato possa impararla in altri modi, pertanto non la includerai nell'analisi. Ti concentrerai sulle restanti colonne age e title, che un utente malintenzionato potrebbe potenzialmente venire a conoscenza di un individuo attraverso altre
fonti di dati. Le domande a cui stai cercando di rispondere per il set di dati sono:
- Quale effetto avranno i due quasi-identificatori (
ageetitle) sul rischio complessivo di reidentificazione dei dati anonimizzati? - In che modo l'applicazione della trasformazione di anonimizzazione influisce su questo rischio?
Vuoi assicurarti che la combinazione di age e title non venga mappata a un
piccolo numero di utenti. Ad esempio, supponiamo che ci sia un solo utente nel
set di dati il cui titolo è Programmatore I e che ha 69 anni. Un malintenzionato potrebbe essere in grado di eseguire un controllo incrociato delle informazioni con i dati demografici o altre informazioni disponibili, capire chi è la persona e conoscere il valore del suo punteggio.
Per ulteriori informazioni su questo fenomeno, consulta la sezione "ID entità e computing k-anonymity" nell'argomento concettuale Analisi del rischio.
Passaggio 1: calcola k-anonymity nel set di dati
Innanzitutto, utilizza Sensitive Data Protection per calcolare k-anonymity nel set di dati inviando il seguente JSON alla risorsa DlpJob. All'interno di questo JSON, imposti l'ID entità sulla colonna user_id e identifichi i due quasi-identificatori come colonne age e title. Stai anche indicando a Sensitive Data Protection di salvare i risultati in una nuova tabella BigQuery.
Input JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}
Una volta completato il job k-anonymity, Sensitive Data Protection invia i risultati
del job a una tabella BigQuery denominata
dlp-demo-2.dlp_testing.test_results.
Passaggio 2: collega i risultati a Looker Studio
Poi collegherai la tabella BigQuery generata nel passaggio 1 a un nuovo report in Looker Studio.
Apri Looker Studio.
Fai clic su Crea > Report.
Nel riquadro Aggiungi dati al report in Connessione ai dati, fai clic su BigQuery. Potresti dover autorizzare Looker Studio ad accedere alle tabelle BigQuery.
Nel selettore di colonne, seleziona I miei progetti. Quindi scegli il progetto, il set di dati e la tabella. Al termine, fai clic su Aggiungi. Se viene visualizzato un avviso che indica che stai per aggiungere dati a questo report, fai clic su Aggiungi al report.
I risultati dell'analisi k-anonymity sono stati aggiunti al nuovo report di Looker Studio. Nel passaggio successivo creerai il grafico.
Passaggio 3: crea il grafico
Per inserire e configurare il grafico:
- In Looker Studio, se viene visualizzata una tabella di valori, selezionala e premi Canc per rimuoverla.
- Nel menu Inserisci, fai clic su Grafico combinato.
- Fai clic e traccia un rettangolo sul canvas nel punto in cui vuoi che venga visualizzato il grafico.
A questo punto, configura i dati del grafico nella scheda Dati in modo che il grafico mostri l'effetto della variazione degli intervalli di dimensioni e valori dei bucket:
- Cancella i campi sotto le seguenti intestazioni puntando a ciascun campo
e facendo clic sulla X , come mostrato qui:
- Dimensione Intervallo di date
- Dimensione
- Metrica
- Ordina
- Con tutti i campi cancellati, trascina il campo upper_endpoint dalla colonna Campi disponibili all'intestazione Dimensione.
- Trascina il campo upper_endpoint sull'intestazione Ordina, quindi seleziona Crescente.
- Trascina entrambi i campi bucket_size e bucket_value_count nell'intestazione Metrica.
- Posiziona il puntatore del mouse sull'icona a sinistra della metrica bucket_size per visualizzare l'icona Modifica.
Fai clic sull'icona Modifica
e poi:
- Nel campo Nome, digita
Unique row loss. - In Tipo, scegli Percentuale.
- In Calcolo confronto, scegli Percentuale del totale.
- In Calcolo progressivo, scegli Somma parziale.
- Nel campo Nome, digita
- Ripeti il passaggio precedente per la metrica bucket_value_count, ma digita
Unique quasi-identifier combination lossnel campo Nome.
Al termine, la colonna dovrebbe essere visualizzata come mostrato qui:
Infine, configura il grafico in modo che mostri entrambe le metriche:
- Fai clic sulla scheda Stile nel riquadro a destra della finestra.
- Sia per la Serie 1 che per la Serie 2, scegli Linea.
- Per visualizzare autonomamente il grafico finale, fai clic sul pulsante Visualizza nell'angolo in alto a destra della finestra.
Di seguito è riportato un grafico di esempio dopo aver completato i passaggi precedenti.
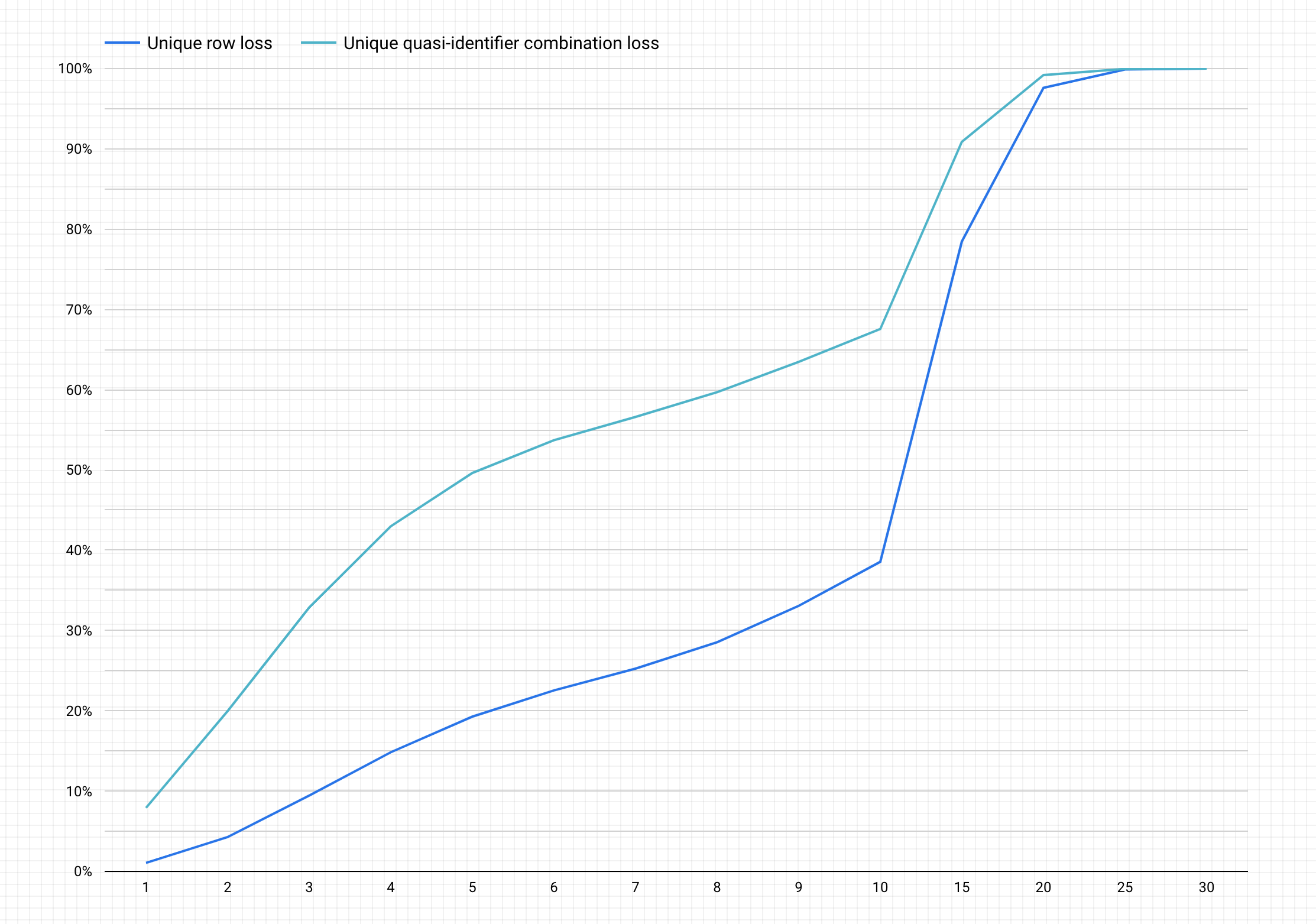
Interpretare il grafico
Il grafico generato traccia, sull'asse y, la percentuale potenziale di perdita di dati per le combinazioni di righe univoche e quasi-identificatori univoche per ottenere, sull'asse x, un valore di anonimizzazione k.
Valori k più elevati indicano un minore rischio di reidentificazione. Tuttavia, per ottenere valori di k-anonymity più elevati, devi rimuovere percentuali più elevate delle righe totali e combinazioni di quasi-identificatori unici più elevate, il che potrebbe diminuire l'utilità dei dati.
Fortunatamente, l'eliminazione dei dati non è la tua unica opzione per ridurre il rischio di reidentificazione. Altre tecniche di anonimizzazione possono raggiungere un migliore equilibrio tra perdita e utilità. Ad esempio, per affrontare il tipo di perdita di dati associata a valori di k-anonimato più elevati e a questo set di dati, potresti provare a bucket le età o i titoli delle mansioni in modo da ridurre l'unicità delle combinazioni di età/titolo di lavoro. Ad esempio, puoi provare a inserire fasce di età comprese tra 20-25, 25-30, 30-35 e così via. Per ulteriori informazioni su come eseguire questa operazione, consulta Generalizzazione e bucket e Anonimizzazione dei dati sensibili nei contenuti testuali.