L'assegnazione di pseudonimi è una tecnica di anonimizzazione che sostituisce i valori dei dati sensibili con token generati in modo crittografico. L'assegnazione di pseudonimi è ampiamente impiegata in settori come quello finanziario e sanitario per contribuire a ridurre il rischio dei dati in uso, restringere l'ambito della conformità e ridurre al minimo l'esposizione dei dati sensibili ai sistemi, preservandone al contempo l'utilità e l'accuratezza.
Sensitive Data Protection supporta tre tecniche di pseudonimizzazione per la anonimizzazione e genera token applicando uno dei tre metodi di trasformazione cryptographic ai valori originali dei dati sensibili. Ogni valore sensibile originale viene poi sostituito con il token corrispondente. La pseudonimizzazione è a volte indicata come tokenizzazione o sostituzione con valori alternativi.
Le tecniche di pseudonimizzazione consentono l'utilizzo di token a senso unico o a doppio senso. Un token a senso unico è stato trasformato in modo irreversibile, mentre un token bidirezionale può essere invertito. Poiché il token viene creato utilizzando la crittografia simmetrica, la stessa chiave di crittografia che può generare nuovi token può anche invertirli. Per le situazioni in cui non è necessaria la reversibilità, puoi utilizzare token monodirezionali che utilizzano meccanismi di hashing sicuri.
È utile capire in che modo la pseudonimizzazione può contribuire a proteggere i dati sensibili, consentendo al contempo alle operazioni aziendali e ai flussi di lavoro di analisi di accedere facilmente ai dati di cui hanno bisogno e di utilizzarli. Questo argomento illustra il concetto di pseudonymization e i tre metodi crittografici per trasformare i dati supportati da Sensitive Data Protection.
Per istruzioni su come implementare questi metodi di pseudonimizzazione e per altri esempi di utilizzo di Sensitive Data Protection, consulta Anonimizzazione dei dati sensibili.
Metodi crittografici supportati in Sensitive Data Protection
Sensitive Data Protection supporta tre tecniche di pseudonimizzazione, tutte le quali impiegano chiavi di crittografia. Di seguito sono riportati i metodi disponibili:
- Crittografia deterministica con AES-SIV: un valore di input viene sostituito con un valore che è stato criptato utilizzando l'algoritmo di crittografia AES-SIV con una chiave crittografica, codificato utilizzando base64 e poi anteposto con un'annotazione sostitutiva, se specificata. Questo metodo produce un valore sottoposto ad hashing, pertanto non conserva il set di caratteri o la lunghezza del valore inserito. I valori sottoposti ad hashing e criptati possono essere identificati di nuovo utilizzando la chiave crittografica originale e l'intero valore di output, inclusa l'annotazione sostitutiva. Scopri di più sul formato dei valori tokenizzati mediante crittografia AES-SIV.
- Crittografia con protezione del formato:un valore di input viene sostituito con un valore che è stato criptato utilizzando l'algoritmo di crittografia FPE-FFX con una chiave crittografica e poi anteposto con un'annotazione sostitutiva, se specificata. Per impostazione predefinita, sia il set di caratteri sia la lunghezza del valore di input vengono conservati nel valore di output. I valori criptati possono essere identificati di nuovo utilizzando la chiave di crittografia originale e l'intero valore di output, inclusa l'annotazione sostitutiva. Per alcune considerazioni importanti sull'utilizzo di questo metodo di crittografia, consulta la sezione Crittografia con mantenimento del formato di seguito in questo argomento.
- Hashing crittografico:un valore di input viene sostituito con un valore che è stato criptato e sottoposto ad hashing utilizzando HMAC (Hash-based Message Authentication Code)-SHA (Secure Hash Algorithm)-256 sul valore di input con una chiave crittografica. L'output sottoposto ad hashing della trasformazione è sempre della stessa lunghezza e non può essere identificato di nuovo. Scopri di più sul formato dei valori tokenizzati mediante hashing cryptographic.
Questi metodi di pseudonimizzazione sono riassunti nella tabella seguente. Le righe della tabella sono spiegate di seguito.
| Crittografia deterministica con AES-SIV | Crittografia che preserva il formato | Hashing crittografico | |
|---|---|---|---|
| Tipo di crittografia | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Valori di input supportati | Deve contenere almeno 1 carattere; non sono previste limitazioni per l'insieme di caratteri. | Deve contenere almeno 2 caratteri e deve essere codificato in ASCII. | Deve essere una stringa o un valore intero. |
| Annotazione sostitutiva | Facoltativo. | Facoltativo. | N/D |
| Modifica del contesto | Facoltativo. | Facoltativo. | N/D |
| Carattere e lunghezza preservati | ✗ | ✓ | ✗ |
| Reversibile | ✓ | ✓ | ✗ |
| Integrità referenziale | ✓ | ✓ | ✓ |
- Tipo di crittografia: il tipo di crittografia utilizzata nella trasformazione di anonimizzazione.
- Valori di input supportati: requisiti minimi per i valori di input.
- Annotazione sostitutiva:un'annotazione specificata dall'utente che viene anteposta ai valori criptati per fornire il contesto agli utenti e informazioni da utilizzare per la protezione dei dati sensibili nella reidentificazione di un valore anonimizzato. Per la reidentificazione dei dati non strutturati è necessaria un'annotazione sostitutiva. È facoltativo quando si trasforma una colonna di dati strutturati o tabulari con un
RecordTransformation. - Modifica del contesto:un riferimento a un campo di dati che "modifica" il valore di input in modo che i valori di input identici possano essere anonimizzati in valori di output diversi. La modifica del contesto è facoltativa quando si trasforma una colonna di
dati strutturati o tabulari con un
RecordTransformation. Per scoprire di più, consulta la sezione Utilizzare le modifiche al contesto. - Carattere set e lunghezza conservati: indica se un valore anonimizzato è costituito dall'insieme di caratteri dello stesso valore originale e se la lunghezza del valore anonimizzato corrisponde a quella del valore originale.
- Reversibile:può essere identificato di nuovo utilizzando la chiave di crittografia, l'annotazione surrogata e qualsiasi modifica del contesto.
- Integrità referenziale: l'integrità referenziale consente ai record di mantenere la loro relazione tra loro anche dopo che i dati sono stati anonimizzati singolarmente. Se vengono utilizzate la stessa chiave di crittografia e lo stesso aggiustamento del contesto, una tabella di dati verrà sostituita con lo stesso modulo offuscato ogni volta che viene trasformata, il che garantisce che le connessioni tra i valori (e, con i dati strutturati, i record) vengano conservate, anche tra le tabelle.
Come funziona la tokenizzazione in Sensitive Data Protection
Il processo di base di tokenizzazione è lo stesso per tutti e tre i metodi supportati da Sensitive Data Protection.
Passaggio 1: Sensitive Data Protection seleziona i dati da tokenizzare. Il modo più comune per farlo è utilizzare un rilevatore di infoType integrato o personalizzato per trovare corrispondenze in base ai valori dei dati sensibili desiderati. Se esegui la scansione di dati strutturati (ad esempio una tabella BigQuery), puoi anche eseguire la tokenizzazione di intere colonne di dati utilizzando le trasformazioni di record.
Per ulteriori informazioni sulle due categorie di trasformazioni, ovvero le trasformazioni di infoType e di record, consulta Trasformazioni di anonimizzazione.
Passaggio 2: utilizzando una chiave crittografica, la funzionalità Sensitive Data Protection cripta ogni valore inserito. Puoi fornire questa chiave in tre modi:
- Eseguendo il wrapping utilizzando Cloud Key Management Service (Cloud KMS). Per la massima sicurezza, Cloud KMS è il metodo preferito.
- Utilizzando una chiave temporanea, che la Protezione dei dati sensibili genera al momento dell'anonimizzazione e poi elimina. Una chiave transitoria mantiene l'integrità solo per richiesta API. Se hai bisogno di integrità o prevedi di identificare nuovamente questi dati, non utilizzare questo tipo di chiave.
- Direttamente in formato di testo non elaborato. (Non consigliato.)
Per maggiori dettagli, consulta la sezione Utilizzo delle chiavi di crittografia più avanti in questo argomento.
Passaggio 3 (hashing criptato e crittografia deterministica solo con AES-SIV): la Protezione dei dati sensibili codifica il valore criptato utilizzando base64. Con l'hashing criptato, questo valore codificato e criptato è il token e il procedura continua con il passaggio 6. Con la crittografia deterministica che utilizza AES-SIV, questo valore codificato e criptato è il valore sostitutivo, che è solo un componente del token. La procedura continua con il passaggio 4.
Passaggio 4 (crittografia deterministica e con mantenimento del formato solo con AES-SIV):
Sensitive Data Protection aggiunge un'annotazione surrogata facoltativa al valore
criptato. L'annotazione del surrogato consente di identificare i valori surrogati criptati anteponendoli a una stringa descrittiva che definisci. Ad esempio, senza un'annotazione potresti non essere in grado di distinguere un numero di telefono anonimizzato da un codice fiscale o da un altro numero di identificazione anonimizzato. Inoltre, per rieseguire l'identificazione dei valori nei dati non strutturati che sono stati anonimizzati utilizzando la crittografia con protezione del formato o la crittografia deterministica, devi specificare un'annotazione sostitutiva. Le annotazioni sostitutive non sono necessarie per trasformare una colonna di dati strutturati o tabulari con un RecordTransformation.
Passaggio 5 (crittografia deterministica e con mantenimento del formato con AES-SIV solo per i dati strutturati): la funzionalità Protezione dei dati sensibili può utilizzare il contesto facoltativo di un altro campo per "ottimizzare" il token generato. In questo modo puoi modificare l'ambito del token. Ad esempio, supponiamo che tu abbia un database di dati delle campagne di marketing che include indirizzi email e che tu voglia generare token univoci per lo stesso indirizzo email "modificato" dall'ID campagna. In questo modo, qualcuno potrebbe unire i dati dello stesso utente all'interno della stessa campagna, ma non tra campagne diverse. Se per creare il token viene utilizzata una modifica del contesto, questa modifica del contesto è necessaria anche per annullare le trasformazioni di anonimizzazione. Crittografia con protezione del formato e deterministica che utilizza contesti di supporto AES-SIV. Scopri di più sull'utilizzo delle modifiche al contesto.
Passaggio 6: Sensitive Data Protection sostituisce il valore originale con il valore anonimizzato.
Confronto dei valori tokenizzati
Questa sezione mostra l'aspetto di token tipici dopo la rimozione dell'identità
utilizzando ciascuno dei tre metodi descritti in questo argomento. Il valore di dati sensibili di esempio è un numero di telefono nordamericano (1-206-555-0123).
Crittografia deterministica con AES-SIV
Con la spersonalizzazione mediante crittografia deterministica e AES-SIV, un valore di input (e, facoltativamente, qualsiasi modifica del contesto specificata) viene criptato utilizzando AES-SIV con una chiave crittografica, codificato in base64 e, facoltativamente, anteposto con un'annotazione sostitutiva, se specificata. Questo metodo non conserva il set di caratteri (o "alfabeto") del valore di input. Per generare un output stampabile, il valore risultante viene codificato in base64.
Il token risultante, supponendo che sia stato specificato un infoType surrogato, è nel formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Il seguente diagramma annotato mostra un token di esempio, l'output di un'operazione di anonimizzazione che utilizza la crittografia deterministica con AES-SIV sul valore 1-206-555-0123. L'infoType surrogato facoltativo è stato impostato su
NAM_PHONE_NUMB:

- Annotazione sostitutiva
- InfoType surrogato (definito dall'utente)
- Lunghezza in caratteri del valore trasformato
- Valore sostitutivo (trasformato)
Se non specifichi un'annotazione sostitutiva, il token risultante è uguale al valore trasformato o al numero 4 nel diagramma annotato. Per reidentificare
i dati non strutturati, è necessario l'intero token, inclusa l'annotazione
surrogata. Quando si trasformano dati strutturati come una tabella, l'annotazione tramite surrogato è facoltativa. Sensitive Data Protection può eseguire sia la spersonalizzazione che la reidentificazione di un'intera colonna utilizzando un RecordTransformation senza un'annotazione tramite surrogato.
Crittografia con protezione del formato
Con l'anonimizzazione tramite crittografia con protezione del formato, un valore di input (e, facoltativamente, qualsiasi modifica del contesto specificata) viene criptato utilizzando la modalità FFX della crittografia con protezione del formato ("FPE-FFX") con una chiave crittografica, quindi facoltativamente anteposto a un'annotazione sostitutiva, se specificata.
A differenza degli altri metodi di tokenizzazione descritti in questo argomento, il valore surrogato di output ha la stessa lunghezza del valore di input e non viene codificato utilizzando base64. Devi definire l'insieme di caratteri, o "alfabeto", di cui è costituito il valore criptato. Esistono tre modi per specificare l'alfabeto da utilizzare in Sensitive Data Protection nel valore di output:
- Utilizza uno dei quattro valori enumerati che rappresentano i quattro alfabeti/set di caratteri più comuni.
- Utilizza un valore di radix, che specifica la dimensione dell'alfabeto. Se specifichi un valore di base minimo di
2, l'alfabeto sarà composto solo da0e1. Se specifichi il valore massimo di radix95, viene generato un alfabeto che include tutti i caratteri numerici, i caratteri alfa maiuscoli, i caratteri alfa minuscoli e i caratteri simbolici. - Crea un alfabeto elencando i caratteri esatti da utilizzare. Ad esempio,
se specifichi
1234567890-*, il valore sostitutivo sarà costituito solo da numeri, trattini e asterischi.
La tabella seguente elenca quattro set di caratteri comuni in base al valore enumerato di ciascuno (FfxCommonNativeAlphabet), al valore di base e all'elenco dei caratteri del set. L'ultima riga elenca il set di caratteri completo, che corrisponde al valore massimo della base.
| Nome dell'alfabeto/del set di caratteri | Radix | Elenco di caratteri |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
Il token risultante, supponendo che sia stato specificato un infoType surrogato, è nel formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Il seguente diagramma annotato è l'output di un'operazione di anonimizzazione di Sensitive Data Protection che utilizza la crittografia con protezione del formato sul valore 1-206-555-0123 utilizzando una base di 95. L'infoType surrogato facoltativo è stato impostato su NAM_PHONE_NUMB:
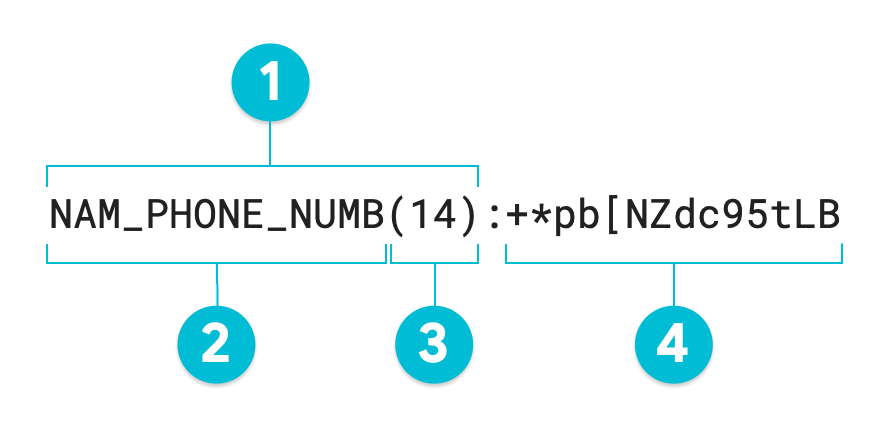
- Annotazione sostitutiva
- InfoType surrogato (definito dall'utente)
- Lunghezza in caratteri del valore trasformato
- Valore sostitutivo (trasformato): stessa lunghezza del valore di input
Se non specifichi un'annotazione sostitutiva, il token risultante è uguale al valore trasformato o al numero 4 nel diagramma annotato. Per reidentificare
i dati non strutturati, è necessario l'intero token, inclusa l'annotazione
surrogata. Quando si trasformano dati strutturati come una tabella, l'annotazione del sostituto è facoltativa. Sensitive Data Protection può eseguire sia la spersonalizzazione che la reidentificazione su un'intera colonna utilizzando un RecordTransformation senza un sostituto.
Hashing crittografico
Con la spersonalizzazione tramite hashing crittografico, un valore di input viene sottoposto ad hashing utilizzando HMAC-SHA-256 con una chiave crittografica e poi codificato utilizzando base64. Il valore anonimizzato ha sempre una lunghezza uniforme, a seconda delle dimensioni della chiave.
A differenza degli altri metodi di tokenizzazione discussi in questo argomento, l'hashing cryptographico crea un token unidirezionale. In altre parole, l'anonimizzazione tramite hashing cryptographico non può essere annullata.
Di seguito è riportato l'output di un'operazione di anonimizzazione che utilizza l'hashing cryptographic sul valore 1-206-555-0123. Questo output è una rappresentazione con codifica base64 del valore sottoposta ad hashing:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Utilizzo delle chiavi crittografiche
Esistono tre opzioni per le chiavi di crittografia che puoi utilizzare con i metodi di anonimizzazione crittografica in Sensitive Data Protection:
Chiave di crittografia con wrapping Cloud KMS: si tratta del tipo di chiave di crittografia più sicura disponibile per l'utilizzo con i metodi di anonimizzazione della Protezione dei dati sensibili. Una chiave con wrapping Cloud KMS è costituita da una chiave di crittografia di 128, 192 o 256 bit criptata con un'altra chiave. Fornisci la prima chiave di crittografia, che viene poi sottoposta a wrapping utilizzando una chiave di crittografia archiviata in Cloud Key Management Service. Questi tipi di chiavi vengono memorizzati in Cloud KMS per la reidentificazione successiva. Per ulteriori informazioni sulla creazione e sull'incapsulamento di una chiave ai fini dell'anonimizzazione e della reidentificazione, consulta la sezione Guida rapida: anonimizzazione e reidentificazione del testo sensibile.
Chiave di crittografia temporanea: una chiave di crittografia temporanea viene generata dalla Protezione dei dati sensibili al momento della anonimizzazione e poi eliminata. Per questo motivo, non utilizzare una chiave di crittografia temporanea con qualsiasi metodo di anonimizzazione crittografica che vuoi annullare. Le chiavi di crittografia temporanee mantengono l'integrità solo per richiesta API. Se hai bisogno di integrità in più di una richiesta API o prevedi di identificare nuovamente i tuoi dati, non utilizzare questo tipo di chiave.
Chiave di crittografia senza wrapping: una chiave senza wrapping è una chiave di crittografia con codifica base64 non elaborata di 128, 192 o 256 bit che fornisci all'interno della richiesta di anonimizzazione all'API DLP. Spetta a te conservare al sicuro questi tipi di chiavi di crittografia per la successiva reidentificazione. A causa del rischio di una fuga accidentale della chiave, questi tipi di chiavi non sono consigliati. Queste chiavi possono essere utili per i test, ma per i carichi di lavoro di produzione è consigliabile utilizzare una chiave di crittografia con wrapping Cloud KMS.
Per scoprire di più sulle opzioni disponibili quando si utilizzano le chiavi di crittografia, consulta
CryptoKey
nella documentazione di riferimento dell'API DLP.
Utilizzare le modifiche contestuali
Per impostazione predefinita, tutti i metodi di trasformazione crittografica della spersonalizzazione hanno integrità referenziale, indipendentemente dal fatto che i token di output siano unidirezionali o bidirezionali. In altre parole, data la stessa chiave crittografica, un valore di input viene sempre trasformato nello stesso valore criptato. Nelle situazioni in cui potrebbero verificarsi dati o pattern di dati ripetitivi, il rischio di reidentificazione aumenta. Per fare in modo che lo stesso valore di input venga sempre trasformato in un valore criptato diverso, puoi specificare una modifica del contesto univoca.
Specifica un aggiustamento del contesto (chiamato semplicemente
context
nell'API DLP) quando trasformi i dati tabulari, poiché l'aggiustamento è
in pratica un puntatore a una colonna di dati, ad esempio un identificatore.
La protezione dei dati sensibili utilizza il valore nel campo specificato dalla modifica del contesto durante la crittografia del valore di input. Per assicurarti che il valore criptato sia sempre un valore univoco, specifica una colonna per la modifica contenente identificatori univoci.
Considera questo semplice esempio. La seguente tabella mostra diversi record medici, alcuni dei quali includono ID paziente duplicati.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
Se indichi a Sensitive Data Protection di anonimizzare gli ID paziente nella tabella, per impostazione predefinita anonimizza gli ID paziente ripetuti con gli stessi valori, come mostrato nella tabella seguente. Ad esempio, entrambe le istanze dell'ID paziente "43789" vengono anonimizzate in "47222". La colonna patient_id mostra i valori dei token dopo la pseudonimizzazione utilizzando FPE-FFX e non include le annotazioni surrogate. Per saperne di più, consulta la sezione Crittografia con protezione del formato.
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
Ciò significa che l'ambito dell'integrità referenziale si estende all'intero set di dati.
Per restringere l'ambito in modo da evitare questo comportamento, specifica una modifica del contesto. Puoi specificare qualsiasi colonna come modifica del contesto, ma per garantire che ogni valore anonimizzato sia univoco, specifica una colonna per la quale ogni valore sia univoco.
Supponiamo che tu voglia verificare se lo stesso paziente viene visualizzato per un valore icd10_codes
, ma non se viene visualizzato in valori icd10_codes diversi. Per farlo, devi specificare la colonna icd10_codes come modifica del contesto.
Questa è la tabella dopo l'anonimizzazione della colonna patient_id utilizzando la colonna icd10_codes come modifica del contesto:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
Tieni presente che il quarto e il quinto valore patient_id anonimizzati (29460) sono uguali perché non solo i valori patient_id originali erano identici, ma anche i valori icd10_codes di entrambe le righe erano identici. Poiché dovevi eseguire un'analisi con ID paziente coerenti nell'ambito del valore icd10_codes, questo comportamento è quello che stai cercando.
Per interrompere completamente l'integrità referenziale tra i valori patient_id e i valori icd10_codes, puoi utilizzare la colonna record_id come modifica del contesto:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
Tieni presente che ogni valore patient_id anonimizzato nella tabella ora è univoco.
Per scoprire come utilizzare le modifiche contestuali nell'API DLP, prendi nota dell'utilizzo di context nei seguenti argomenti di riferimento dei metodi di trasformazione:
- Crittografia con protezione del formato:
CryptoReplaceFfxFpeConfig - Crittografia deterministica con AES-SIV:
CryptoDeterministicConfig - Spostamento della data:
DateShiftConfig
Passaggi successivi
Consulta gli esempi di codice che mostrano come tokenizzare i dati sensibili.
Scopri come anonimizzare i dati utilizzando l'API DLP.