La generalizzazione è il processo di selezione di un valore distintivo e di astrazione in un valore più generale e meno distintivo. La generalizzazione cerca di preservare l'utilità dei dati riducendo al contempo l'identificazione dei dati.
Ci possono essere molti livelli di generalizzazione a seconda del tipo di dati. Il livello di generalizzazione necessario è qualcosa che puoi misurare in un set di dati o in una popolazione reale utilizzando tecniche come quelle incluse nell'analisi del rischio di Sensitive Data Protection.
Una tecnica di generalizzazione comune supportata da Sensitive Data Protection è il bucket. Con i bucket, i record vengono raggruppati in bucket più piccoli nel tentativo di ridurre al minimo il rischio che un utente malintenzionato associ informazioni sensibili a informazioni identificative. Così facendo può conservare significato e utilità, ma oscurare anche i singoli valori con un numero insufficiente di partecipanti.
Scenario bucket 1
Considera questo scenario di bucketing numerico: un database archivia i punteggi di soddisfazione degli utenti, che vanno da 0 a 100. Il database ha un aspetto simile al seguente:
| user_id | score |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | ... |
Analizzando i dati, ti rendi conto che alcuni valori vengono utilizzati raramente dagli utenti. Infatti, esistono alcuni punteggi che corrispondono a un solo utente. Ad esempio, la maggior parte degli utenti sceglie 0, 25, 50, 75 o 100. Tuttavia, cinque utenti ne hanno scelti 95 e solo uno 92. Invece di conservare i dati non elaborati, potresti generalizzare questi valori in gruppi ed eliminare la presenza di gruppi con un numero di partecipanti insufficiente. A seconda di come vengono utilizzati i dati, generalizzare i dati in questo modo potrebbe aiutare a impedire la reidentificazione.
Puoi scegliere di rimuovere queste righe di dati outlier o provare a preservare la loro utilità utilizzando i bucket. Per questo esempio, raggruppiamo tutti i valori in base a quanto segue:
- Da 0 a 25: "Bassa"
- 26-75: "Medio"
- 76-100: "Alta"
Il bucket in Sensitive Data Protection è una delle tante trasformazioni primitive disponibili per l'anonimizzazione. La seguente configurazione JSON illustra come implementare questo scenario di bucket nell'API DLP. Questo JSON potrebbe essere incluso in una richiesta inviata al metodo content.deidentify:
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
Scenario bucket 2
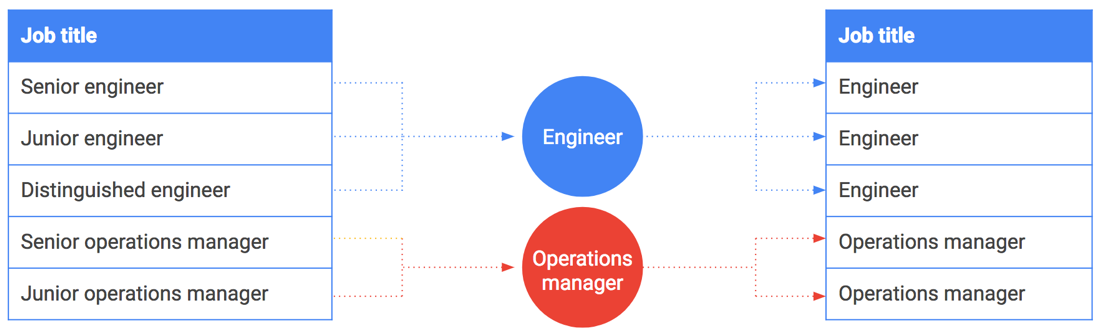
Il bucketing può essere utilizzato anche su stringhe o valori enumerati. Supponiamo che tu voglia condividere i dati sugli stipendi e includere le qualifiche. Tuttavia, alcune qualifiche, come CEO o ingegnere distinto, possono essere collegate a una sola persona o a un piccolo gruppo di persone. Tali qualifiche sono facilmente associabili ai dipendenti che le ricoprono.
Anche in questo caso il bucketing può essere utile. Anziché includere le qualifiche esatte, generalizzale e raggruppale. Ad esempio, "Senior Engineer", "Junior Engineer" e "Distinguited Engineer" vengono generalizzati e categorizzati semplicemente in "Engineer". La tabella seguente illustra la suddivisione in bucket di specifiche qualifiche in famiglie di ruoli.
Altri scenari
In questi esempi, abbiamo applicato la trasformazione ai dati strutturati. Il bucketing può essere utilizzato anche su esempi non strutturati, a condizione che il valore possa essere classificato con un infoType predefinito o personalizzato. Di seguito sono riportati alcuni scenari di esempio:
- Classifica le date e raggruppale in intervalli di anni
- Classifica i nomi e raggruppali in gruppi in base alla prima lettera (A-M, N-Z)
Risorse
Per scoprire di più sulla generalizzazione e sul bucketing, consulta Anonimizzazione dei dati sensibili nei contenuti testuali.
Per la documentazione relativa all'API, consulta:
- Metodo
projects.content.deidentify - Trasformazione di
BucketingConfig: raggruppa i valori in base a intervalli personalizzati. - Trasformazione di
FixedSizeBucketingConfig: raggruppa i valori in base a intervalli di dimensioni fissi.