Este documento é a segunda parte de uma série que discute a recuperação de desastres (DR) no Google Cloud. Esta parte fala sobre os serviços e produtos que podem ser usados como elementos básicos para seu plano de DR, tanto os do Google Cloud quanto os que funcionam em várias plataformas.
A série contém estas partes:
- Guia de planejamento de recuperação de desastres
- Elementos básicos da recuperação de desastres (este artigo)
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicativos
- Como arquitetar a recuperação de desastres para cargas de trabalho com restrição de localidade
- Casos de uso da recuperação de desastres: aplicativos de análise de dados com restrição de localidade
- Como arquitetar a recuperação de desastres para interrupções de infraestrutura em nuvem
O Google Cloud tem uma ampla variedade de produtos que podem ser usados como parte da arquitetura de recuperação de desastres. Esta seção aborda os recursos relacionados a DR dos produtos mais comumente usados como elementos básicos do Google Cloud DR.
Muitos desses serviços têm recursos de alta disponibilidade (HA, na sigla em inglês). A HA não se sobrepõe totalmente ao DR, mas muitos dos objetivos da HA também se aplicam a um plano de DR. Por exemplo, aproveitando os recursos de alta disponibilidade, é possível projetar arquiteturas que otimizem o tempo de atividade e que possam atenuar os efeitos de falhas em pequena escala, como a falha de uma VM. Para saber mais sobre a relação entre DR e HA, consulte o Guia de planejamento de recuperação de desastres.
As seções a seguir descrevem esses elementos básicos da DR do Google Cloud e como eles ajudam você a implementar suas metas de DR.
Computação e armazenamento
A tabela a seguir mostra um resumo dos recursos dos serviços de computação e armazenamento do Google Cloud que servem como elementos básicos para a DR:
| Produto | Recurso |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Para mais informações sobre como os recursos e o design desses e de outros produtos do Google Cloud podem influenciar sua estratégia de DR, consulte Como arquitetar a recuperação de desastres para interrupções de infraestrutura em nuvem: referência do produto.
Compute Engine
O Compute Engine fornece instâncias de máquina virtual (VM) e é o principal elemento do Google Cloud. Além de configurar, iniciar e monitorar instâncias do Compute Engine, você normalmente usa uma variedade de recursos relacionados para implementar um plano de DR.
Em cenários de DR, é possível impedir a exclusão acidental de VMs definindo a sinalização de proteção de exclusão. Isso é particularmente útil ao hospedar serviços com estado, como bancos de dados.
Para informações sobre como atender a valores baixos de RTO e RPO, consulte Como projetar sistemas resilientes.
Modelos de instância
Use modelos de instância do Compute Engine para salvar os detalhes de configuração da VM e, em seguida, criar instâncias com base nos modelos atuais. É possível usar o modelo para iniciar quantas instâncias forem necessárias, configuradas exatamente da maneira desejada, quando você precisar manter seu ambiente de destino de recuperação de desastres. Os modelos de instância são replicados globalmente para que você possa recriar a instância em qualquer lugar no Google Cloud com a mesma configuração.
Para saber mais, acesse os recursos a seguir:
Para detalhes sobre o uso de imagens do Compute Engine, consulte a seção Como balancear a configuração da imagem e a velocidade de implantação mais adiante neste documento.
Grupos de instâncias gerenciadas
Os grupos gerenciados de instâncias trabalham com o Cloud Load Balancing (discutido posteriormente neste documento) para distribuir o tráfego para grupos de instâncias configuradas de forma idêntica, que são copiadas entre as zonas. Os grupos de instâncias gerenciadas permitem o uso de recursos como escalonamento automático e recuperação automática, em que o grupo de instâncias gerenciadas pode excluir e recriar instâncias automaticamente.
Reservas
O Compute Engine permite a reserva de instâncias de VM em uma zona específica, usando tipos de máquina personalizados ou predefinidos, com ou sem GPUs ou SSDs locais. Para garantir a capacidade das cargas de trabalho críticas para DR, crie reservas nas zonas de destino de DR. Sem reservas, há a possibilidade de você não conseguir a capacidade sob demanda necessária para atender ao objetivo do tempo de recuperação. As reservas podem ser úteis em cenários de DR frio, morno ou quente. Elas permitem que você mantenha os recursos de recuperação disponíveis para o failover para atender às necessidades de RTO mais baixas, sem precisar configurá-los e implantá-los totalmente com antecedência.
Discos permanentes e snapshots
Os discos permanentes são dispositivos de armazenamento de rede duráveis que podem ser acessados por suas instâncias. Eles são independentes das instâncias, portanto, você pode separar e mover discos permanentes para manter os dados mesmo depois de excluir suas instâncias.
É possível fazer backups incrementais ou instantâneos das VMs do Compute Engine que você pode copiar nas regiões e usar para recriar discos permanentes no caso de um desastre. Além disso, é possível criar snapshots de discos permanentes para se proteger contra a perda de dados resultante de erros do usuário. Os snapshots são incrementais e levam apenas alguns minutos para serem criados, mesmo que os discos dos snapshots estejam anexados a instâncias em execução.
Os discos permanentes têm redundância incorporada para proteger os dados contra falhas de equipamentos e garantir a disponibilidade de dados por meio de eventos de manutenção de data center. Os discos permanentes são zonais ou regionais. Os discos permanentes regionais replicam gravações em duas zonas em uma região. No caso de uma interrupção zonal, uma instância de VM de backup pode forçar a anexação de um disco permanente regional na zona secundária. Para saber mais, consulte Opções de alta disponibilidade usando discos permanentes regionais.
Manutenção transparente
O Google realiza regularmente manutenção na infraestrutura corrigindo sistemas com o software mais recente, realizando testes de rotina e manutenção preventiva e trabalhando para garantir que a infraestrutura do Google seja a mais rápida e eficiente possível.
Por padrão, todas as instâncias do Compute Engine são configuradas de maneira que esses eventos de manutenção sejam transparentes para os seus aplicativos e as suas cargas de trabalho. Para mais informações, consulte Manutenção transparente.
Quando um evento de manutenção ocorre, o Compute Engine usa a migração em tempo real para migrar automaticamente as instâncias em execução para outro host na mesma zona A migração em tempo real permite que o Google realize a manutenção necessária para manter a infraestrutura protegida e confiável sem interromper nenhuma das suas VMs.
Ferramenta de importação de disco virtual
A ferramenta de importação de disco virtual permite importar formatos de arquivo, como VMDK, VHD e RAW, para criar novas máquinas virtuais do Compute Engine. Com essa ferramenta, é possível criar máquinas virtuais do Compute Engine com a mesma configuração das máquinas virtuais locais. Essa é uma boa abordagem quando não é possível configurar imagens do Compute Engine a partir dos binários de origem do software que já estão instalados em suas imagens.
Backups automatizados
É possível automatizar os backups das instâncias do Compute Engine usando tags. Por exemplo, é possível criar um modelo de plano de backup usando o serviço de backup e DR e aplicar o modelo automaticamente às instâncias do Compute Engine.
Para mais informações, consulte Proteger automaticamente novas instâncias do Compute Engine.
Cloud Storage
O Cloud Storage é um armazenamento de objetos ideal para armazenar arquivos de backup. Ele fornece diferentes classes de armazenamento, adequadas para casos de uso específicos, conforme descrito no diagrama a seguir.

Em cenários de DR, Nearline, Coldline e Archive Storage são de especial interesse. Essas classes de armazenamento reduzem o custo em comparação com o armazenamento padrão. No entanto, existem outros custos associados à recuperação de dados ou metadados armazenados nessas classes, assim como durações de armazenamento mínimas pelas quais é possível receber cobranças. O Nearline é projetado para cenários de backup em que o acesso é feito no máximo uma vez por mês, o que é ideal para permitir testes regulares de estresse de DR e manter os custos baixos.
Nearline, Coldline e Archive são otimizados para acesso pouco frequente, e o modelo de preços é projetado tendo isso em mente. Portanto, você é cobrado por períodos mínimos de armazenamento e há custos extras para recuperar dados ou metadados nessas classes antes da duração mínima de armazenamento da classe.
Para proteger os dados em um bucket do Cloud Storage contra exclusão acidental ou maliciosa, use o recurso de exclusão reversível para preservar objetos excluídos e substituídos por um período especificado e o recurso de retenção de objetos para impedir a exclusão ou atualização de objetos.
O Serviço de transferência do Cloud Storage permite importar dados do Amazon S3, do Azure Blob Storage ou de fontes de dados locais para o Cloud Storage. Em cenários de DR, é possível usar o Serviço de transferência do Cloud Storage para:
- Fazer backup de dados de outros provedores de armazenamento para um bucket do Cloud Storage.
- Mova os dados de um bucket em uma região birregional ou multirregional para um bucket em uma região para reduzir os custos de armazenamento de backups.
Filestore
As instâncias do Filestore são servidores de arquivos NFS totalmente gerenciados para uso com aplicativos executados em instâncias do Compute Engine ou clusters do GKE.
Os níveis básico e zonal do Filestore são recursos zonais e não oferecem suporte à replicação entre zonas, enquanto as instâncias do nível Enterprise são recursos regionais. Para aumentar a resiliência do seu ambiente do Filestore, recomendamos o uso de instâncias do nível Enterprise.
Google Kubernetes Engine
O GKE é um ambiente gerenciado e pronto para produção para implantar aplicativos em contêineres. Ele permite orquestrar sistemas de alta disponibilidade e inclui os seguintes recursos:
- Reparo automático de nós: se as verificações de integridade mostrarem falha consecutiva de um nó por um tempo de aproximadamente 10 minutos, o GKE iniciará um processo de reparação.
- Sondagens de ativação e prontidão. especifique uma sondagem de ativação, que informa periodicamente ao GKE que o pod está em execução. Se o pod falhar, a sondagem pode ser reiniciada.
- Clusters regionais e de várias zonas: é possível distribuir recursos do Kubernetes entre várias zonas dentro de uma região.
- O gateway de vários clusters permite configurar recursos de balanceamento de carga compartilhados em vários clusters do GKE em diferentes regiões.
- O Backup para GKE permite fazer backup e restaurar cargas de trabalho em clusters do GKE.
Rede e transferência de dados
A tabela a seguir oferece um resumo dos recursos dos serviços de transferência de dados e rede do Google Cloud que servem como elementos básicos para a DR:
| Produto | Recurso |
|---|---|
| Cloud Load Balancing |
|
Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
O Cloud Load Balancing oferece alta disponibilidade para os produtos de computação do Google Cloud, distribuindo o tráfego do usuário por várias instâncias dos seus aplicativos. Configure o Cloud Load Balancing com verificações de integridade que determinam se as instâncias estão disponíveis. Assim, o tráfego não é encaminhado para instâncias com falha.
O Cloud Load Balancing fornece um único endereço IP anycast para atender aos seus aplicativos. Seu aplicativo pode ter instâncias em execução em regiões diferentes (por exemplo, na Europa e nos EUA), e seus usuários finais são direcionados para o conjunto de instâncias mais próximo. Além de fornecer balanceamento de carga para serviços que estão expostos à Internet, é possível configurar o balanceamento de carga interno para seus serviços por trás de um endereço IP de balanceamento de carga particular. Esse endereço IP é acessível apenas para instâncias de VM internas da sua nuvem privada virtual (VPC).
Para mais informações, consulte a visão geral do Cloud Load Balancing.
Cloud Service Mesh
O Cloud Service Mesh é uma malha de serviço gerenciada pelo Google disponível no Google Cloud. O Cloud Service Mesh fornece telemetria detalhada para ajudar você a coletar insights detalhados sobre seus aplicativos. Ele oferece suporte a serviços executados em uma gama de infraestruturas de computação.
O Cloud Service Mesh também oferece suporte a recursos avançados de gerenciamento e roteamento de tráfego, como quebra de circuito e injeção de falha. Com a quebra de circuitos, é possível impor limites em solicitações a um determinado serviço. Quando os limites de quebra de circuito são alcançados, as solicitações são impedidas de chegar ao serviço, o que impede a degradação do serviço. Com a injeção de falhas, o Cloud Service Mesh pode apresentar atrasos ou cancelar uma fração de solicitações a um serviço. A injeção de falhas permite testar a capacidade do serviço de sobreviver a atrasos ou solicitações canceladas.
Para mais informações, consulte Visão geral do Cloud Service Mesh.
Cloud DNS
O Cloud DNS oferece uma maneira programática de gerenciar entradas de DNS como parte de um processo de recuperação automatizado. O Cloud DNS usa nossa rede global de servidores de nomes Anycast para disponibilizar zonas de DNS de locais redundantes do mundo todo, oferecendo alta disponibilidade e baixa latência aos usuários.
Se você gerenciar as entradas de DNS no local, poderá ativar as VMs no Google Cloud para resolver esses endereços usando o encaminhamento do Cloud DNS.
O Cloud DNS aceita políticas para configurar como ele responderá a solicitações de DNS. Por exemplo, é possível configurar políticas de roteamento de DNS para direcionar o tráfego com base em critérios específicos, como ativar o failover para uma configuração de backup a fim de fornecer alta disponibilidade ou rotear solicitações de DNS com base na localização geográfica delas.
Cloud Interconnect
O Cloud Interconnect fornece maneiras de mover informações de outras fontes para o Google Cloud. Falaremos sobre esse produto mais tarde em Como transferir dados de e para o Google Cloud.
Gerenciamento e monitoramento
A tabela a seguir mostra um resumo dos recursos nos serviços de gerenciamento e monitoramento do Google Cloud que servem como elementos básicos para a DR:
| Produto | Recurso |
|---|---|
| Painel de status do Cloud |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service para Prometheus |
|
Painel de status do Cloud
O Painel de status do Cloud mostra a disponibilidade atual dos serviços do Google Cloud. Veja o status na página e assine um feed RSS. Ele será atualizado sempre que houver notícias sobre um serviço.
Cloud Monitoring
O Cloud Monitoring coleta métricas, eventos e metadados do Google Cloud, da AWS, de sondagens de tempo de atividade hospedadas, de instrumentação de aplicativos e de vários outros componentes de aplicativos. Configure alertas para enviar notificações para ferramentas de terceiros, como o Slack ou o Pagerduty, para oferecer atualizações periódicas aos administradores.
O Cloud Monitoring permite criar verificações de tempo de atividade para endpoints disponíveis publicamente e para endpoints nas VPCs. Por exemplo, é possível monitorar URLs, instâncias do Compute Engine, revisões do Cloud Run e recursos de terceiros, como instâncias do Amazon Elastic Compute Cloud (EC2).
Google Cloud Managed Service para Prometheus
O Google Cloud Managed Service para Prometheus é uma solução de várias nuvens e entre projetos gerenciada pelo Google para métricas do Prometheus. Ele permite monitorar e receber alertas globalmente sobre as cargas de trabalho usando o Prometheus, sem precisar gerenciar e operar manualmente o Prometheus em grande escala.
Para mais informações, consulte Serviço gerenciado do Google Cloud para Prometheus.
Elementos básicos de DR em várias plataformas
Ao executar cargas de trabalho em mais de uma plataforma, uma maneira de reduzir a sobrecarga operacional é selecionar ferramentas que funcionam com todas as plataformas que você está usando. Nesta seção, discutimos algumas ferramentas e serviços que são independentes de plataforma e, portanto, compatíveis com cenários de DR entre várias plataformas.
Infraestrutura como código
Ao definir sua infraestrutura usando código em vez de interfaces gráficas ou scripts, é possível adotar ferramentas de modelos declarativos e automatizar o provisionamento e a configuração da infraestrutura entre plataformas. Por exemplo, você pode usar o Terraform e o Infrastructure Manager para acionar a configuração da infraestrutura declarativa.
Ferramentas de gerenciamento de configurações
Para infraestruturas de DR grandes ou complexas, recomendamos ferramentas de gerenciamento de software independentes de plataforma, como Chef e Ansible. Essas ferramentas garantem que configurações reproduzíveis possam ser aplicadas, independentemente de onde sua carga de trabalho de computação esteja.
Ferramentas do orquestrador
Os contêineres também podem ser considerados um elemento básico de DR. Eles constituem uma maneira de agrupar serviços e introduzir consistência entre as plataformas.
Se você trabalha com contêineres, normalmente usa um orquestrador. Kubernetes serve para gerenciar contêineres dentro do Google Cloud (usando o GKE) e também oferece uma maneira de orquestrar cargas de trabalho baseadas em contêiner em várias plataformas. O Google Cloud, a AWS e o Microsoft Azure fornecem versões gerenciadas do Kubernetes.
Para distribuir o tráfego para clusters do Kubernetes em execução em diferentes plataformas de nuvem, você pode usar um serviço DNS que ofereça suporte a registros ponderados e incorpore a verificação de integridade.
Além disso, é necessário garantir que seja possível receber a imagem no ambiente de destino. Isso significa que você precisa acessar seu registro de imagem no caso de um desastre. Uma boa opção que também é independente de plataforma é o Artifact Registry.
Transferência de dados
A transferência de dados é um componente essencial para cenários de DR em várias plataformas. Você precisa projetar, implementar e testar seus cenários de DR em várias plataformas usando modelos realistas do que o cenário de transferência de dados de DR exige. Discutimos os cenários de transferência de dados na próxima seção.
Serviço de backup e DR
O serviço de backup e DR é uma solução de backup e DR para cargas de trabalho na nuvem. Ele ajuda a recuperar dados e retomar operações de negócios essenciais, além de oferecer suporte a vários produtos do Google Cloud, bancos de dados de terceiros e sistemas de armazenamento de dados.
Para mais informações, consulte Informações gerais do serviço de backup e DR.
Padrões para DR
Nesta seção, veremos alguns dos padrões mais comuns para arquiteturas de DR com base nos elementos essenciais discutidos anteriormente.
Como transferir dados para e do Google Cloud
Um aspecto importante do seu plano de DR é a rapidez com que os dados podem ser transferidos para e do Google Cloud. Isso é essencial se seu plano de DR é baseado na movimentação de dados do local para o Google Cloud ou de outro provedor de nuvem para o Google Cloud. Esta seção discute a rede e os serviços do Google Cloud que podem garantir uma boa capacidade.
Ao usar o Google Cloud como o local de recuperação para cargas de trabalho locais ou em outro ambiente em nuvem, considere os seguintes itens principais:
- Como você se conecta ao Google Cloud?
- Qual é a largura de banda entre você e o provedor de interconexão?
- Qual é a largura de banda fornecida pelo provedor diretamente ao Google Cloud?
- Quais outros dados serão transferidos por meio desse link?
Para mais informações sobre como transferir dados para o Google Cloud, consulte Migrar para o Google Cloud: transferir grandes conjuntos de dados.
Como balancear a configuração da imagem e a velocidade de implantação
Ao configurar uma imagem de máquina para implantar novas instâncias, pense no efeito que sua configuração terá na velocidade da implantação. Há um dilema entre a quantidade de pré-configuração da imagem, os custos de manutenção da imagem e a velocidade de implantação. Por exemplo, se uma imagem de máquina estiver minimamente configurada, as instâncias que a usam precisarão de mais tempo para serem iniciadas, porque precisam fazer o download e instalar dependências. Por outro lado, se a imagem de máquina estiver altamente configurada, as instâncias que a usam serão iniciadas mais rapidamente, mas você precisará atualizar a imagem com mais frequência. O tempo necessário para iniciar uma instância totalmente operacional tem uma correlação direta com seu RTO.
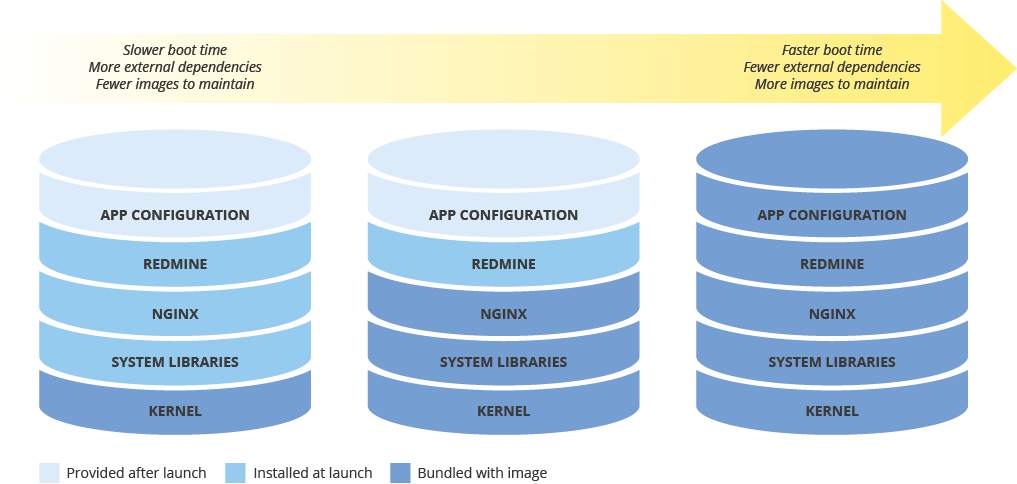
Como manter a consistência da imagem de máquina em ambientes híbridos
Se você implementar uma solução híbrida (do local para nuvem ou de nuvem para nuvem), precisará encontrar uma maneira de manter a consistência da VM nos ambientes de produção.
Caso seja necessário usar uma imagem totalmente configurada, use um software como o Packer, que pode criar imagens de máquina idênticas para diversas plataformas. É possível usar os mesmos scripts com arquivos de configuração específicos da plataforma. No caso do Packer, é possível colocar o arquivo de configuração no controle de versão para acompanhar qual versão é implementada na produção.
Outra opção é usar ferramentas de gerenciamento de configuração, como Chef, Puppet, Ansible ou Saltstack, para configurar instâncias com maior granularidade, criando imagens de base, imagens minimamente configuradas ou imagens totalmente configuradas conforme necessário.
Também é possível converter e importar manualmente as imagens existentes, como Amazon AMIs, imagens de Virtualbox e imagens de disco RAW, para o Compute Engine.
Como implementar o armazenamento em níveis
O padrão de armazenamento em níveis é normalmente usado para backups em que o backup mais recente fica em um armazenamento mais rápido e, lentamente, você migra os backups mais antigos para um armazenamento mais barato (mas mais lento). Ao aplicar esse padrão, você migra backups entre buckets de diferentes classes de armazenamento, geralmente da classe padrão para classes de armazenamento mais baratas, como Nearline e Coldline.
Para implementar esse padrão, use o Gerenciamento do ciclo de vida de objetos. Por exemplo, é possível mudar automaticamente a classe de armazenamento de objetos mais antigos do que um determinado período para Coldline.
A seguir
- Leia sobre a Geografia e regiões do Google Cloud.
Leia outros artigos nesta série de DR:
- Guia de planejamento de recuperação de desastres
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicativos
- Como arquitetar a recuperação de desastres para cargas de trabalho com restrição de localidade
- Casos de uso da recuperação de desastres: aplicativos de análise de dados com restrição de localidade
- Como arquitetar a recuperação de desastres para interrupções de infraestrutura em nuvem
Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.
Colaboradores
Autores:
- Grace Mollison | Líder de soluções
- Marco Ferrari | Arquiteto de soluções do Cloud