Recomendamos que você projete sua malha de dados para oferecer suporte a uma ampla variedade de casos de uso para consumo de dados. Os casos de uso de consumo de dados mais comuns em uma organização são descritos neste documento. O documento também discute quais informações de dados os consumidores precisam considerar ao determinar o produto de dados certo para o caso de uso e como eles descobrem e usam produtos de dados. A compreensão desses fatores pode ajudar as organizações a garantir que tenham as orientações e ferramentas certas para dar suporte aos consumidores de dados.
Este documento faz parte de uma série em que se descreve como implementar uma malha de dados no Google Cloud. Ele pressupõe que você leu e conhece os conceitos descritos em Arquitetura e funções em uma malha de dados e Criar uma malha de dados moderna e distribuída com o Google Cloud.
A série tem as seguintes partes:
- Arquitetura e funções em uma malha de dados
- Projetar uma plataforma de dados de autoatendimento para uma malha de dados
- Criar produtos de dados em uma malha de dados
- Descobrir e consumir produtos de dados em uma malha de dados (este documento)
O modelo de uma camada de consumo de dados, especificamente a maneira como os consumidores baseados em domínios de dados usam produtos de dados, depende dos requisitos dos consumidores de dados. Como pré-requisito, presume-se que os consumidores tenham um caso de uso em mente. Presume-se que eles identificaram os dados necessários e podem pesquisar no catálogo central de produtos de dados para encontrá-los. Se esses dados não estiverem no catálogo ou não estiverem no estado preferido (por exemplo, se a interface não for adequada ou os SLAs forem insuficientes), o consumidor precisará entrar em contato com o produtor de dados.
Como alternativa, o consumidor pode entrar em contato com o centro de excelência (COE, na sigla em inglês) para a malha de dados para receber conselhos sobre qual domínio é o mais adequado para produzir esse produto de dados. Os dados dos consumidores também podem perguntar como fazer essa solicitação. Se a organização for grande, haverá um processo para fazer solicitações de produtos de dados de maneira autônoma.
Os consumidores de dados usam produtos de dados pelos aplicativos que executam. O tipo de insight necessário impulsiona a escolha do design do aplicativo que consome dados. Ao desenvolver o design do aplicativo, o consumidor de dados também identifica o uso preferido de produtos de dados no aplicativo. Estabeleça a confiança necessária para ter a confiança e a confiabilidade desses dados. Os consumidores de dados podem estabelecer uma visualização sobre as interfaces de produto de dados e os SLAs exigidos pelo aplicativo.
Casos de uso de consumo de dados
Para que os consumidores de dados criem aplicativos de dados, as fontes podem ser um ou mais produtos de dados e, talvez, os dados do próprio domínio do consumidor de dados. Conforme descrito em Criar produtos de dados em uma malha de dados, produtos de dados analíticos podem ser feitos de produtos de dados baseados em vários repositórios de dados físicos.
O consumo de dados pode acontecer no mesmo domínio, mas os padrões de consumo mais comuns são os que procuram o produto de dados correto, independentemente do domínio, como a origem do aplicativo. Quando há o produto de dados correto em outro domínio, o padrão de consumo exige que você configure o mecanismo subsequente para acesso e uso dos dados entre domínios. O consumo de produtos de dados criados em domínios diferentes do domínio de consumo é discutido em Etapas de consumo de dados.
Arquitetura
O diagrama a seguir mostra um exemplo em que os consumidores usam produtos de dados por meio de uma variedade de interfaces, incluindo conjuntos de dados e APIs autorizados.
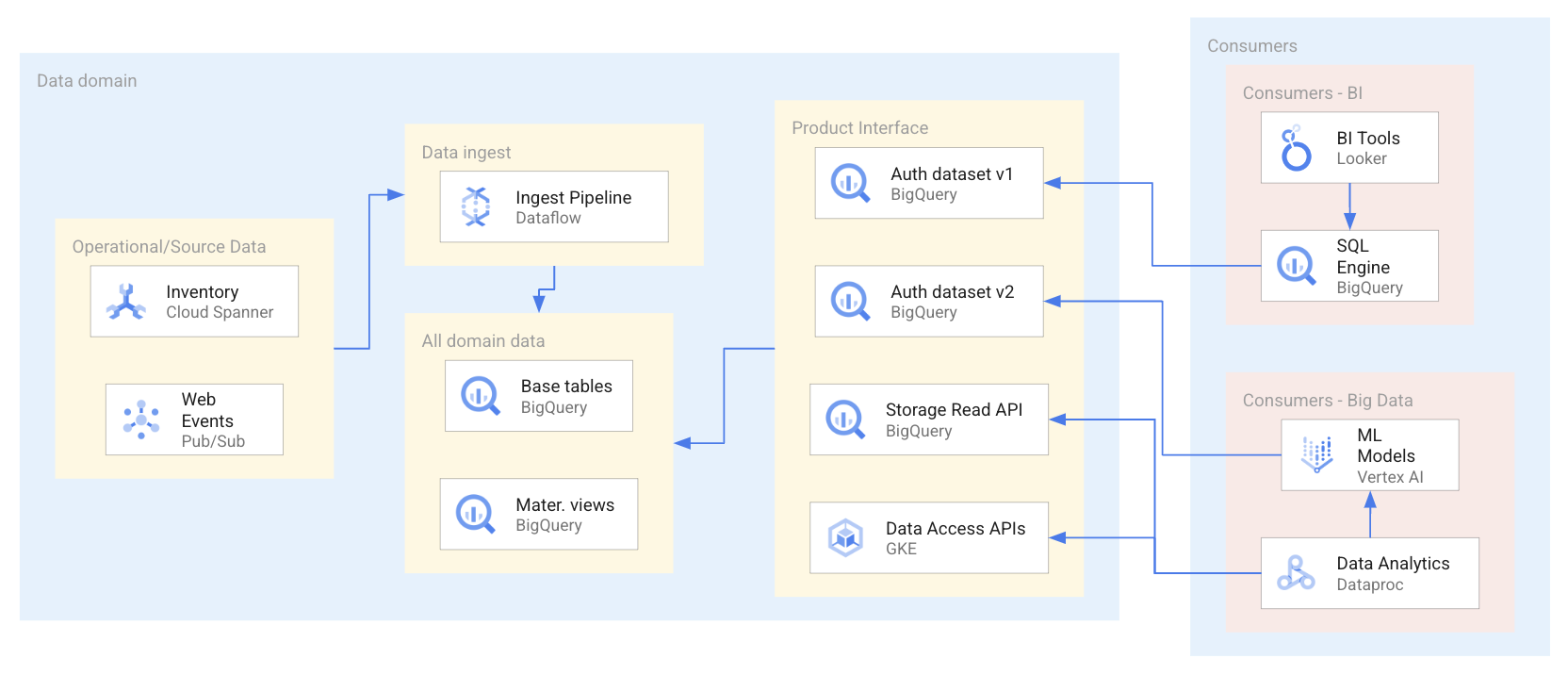
Como mostrado no diagrama anterior, o produtor de dados expôs quatro interfaces de produtos de dados: dois conjuntos de dados autorizados do BigQuery, um conjunto de dados do BigQuery exposto pela API de leitura do armazenamento do BigQuery e APIs de acesso a dados hospedados no Google Kubernetes Engine. Ao utilizar os produtos de dados, os consumidores de dados usam uma variedade de aplicativos que consultam ou acessam diretamente os recursos de dados nos produtos de dados. Nesse cenário, os consumidores de dados acessam os recursos de dados de duas maneiras diferentes, com base nos respectivos requisitos de acesso a dados específicos. Primeiro, o Looker usa o SQL do BigQuery para consultar um conjunto de dados autorizado. Na segunda maneira, o Dataproc acessa diretamente um conjunto de dados por meio da API BigQuery e, em seguida, processa esses dados ingeridos para treinar um modelo de machine learning (ML).
O uso de um aplicativo de consumo de dados nem sempre resulta em um relatório de Business Intelligence (BI) ou um painel de BI. O consumo de dados de um domínio também pode resultar em modelos de ML que enriquecem ainda mais produtos analíticos, são usados na análise de dados ou fazem parte de processos operacionais, por exemplo, detecção de fraude.
Veja alguns casos de uso típicos de consumo de produtos de dados:
- Relatórios de BI e análise de dados: neste caso, os aplicativos de dados são criados para consumir dados de vários produtos de dados. Por exemplo, os consumidores de dados da equipe de gestão de relacionamento com o cliente (CRM) precisam de acesso a dados de vários domínios, como vendas, clientes e finanças. O aplicativo de CRM desenvolvido por esses consumidores de dados pode precisar consultar uma visualização autorizada do BigQuery em um domínio e extrair dados de uma API Read do Cloud Storage em outro domínio. Para os consumidores de dados, os fatores de otimização que influenciam a interface de consumo preferido são os custos de computação e qualquer processamento de dados adicional necessário após consultar o produto de dados. Nos casos de uso de BI e de análise de dados, as visualizações autorizadas do BigQuery provavelmente são as mais usadas.
- Casos de uso e treinamento de modelos de ciência de dados: neste caso, a equipe de consumidor de dados está usando os produtos de dados de outros domínios para aprimorar o próprio produto de dados de análise, como um modelo de ML. Ao usar o Google Cloud sem servidor para Apache Spark Google Cloud ,o Google Cloud oferece recursos de pré-processamento e engenharia de atributos para ativar o enriquecimento de dados antes de executar tarefas de ML. As principais considerações são a disponibilidade de quantidades suficientes de dados de treinamento a um custo razoável e a confiança de que os dados de treinamento são os dados apropriados. Para manter os custos baixos, as interfaces de consumo preferidas provavelmente serão APIs de leitura direta. É possível para uma equipe que consome dados criar um modelo de ML como um produto de dados e, por sua vez, essa equipe que consome dados também se torna uma nova equipe de produção de dados.
- Processos de operador:o consumo é uma parte do processo operacional no domínio que consome dados. Por exemplo, um consumidor de dados em uma equipe que lida com fraudes pode estar usando dados de transações provenientes de fontes de dados operacionais no domínio do comerciante. Ao usar um método de integração de dados, como a captura de dados alterados, esses dados de transação são interceptados quase em tempo real. Use o Pub/Sub para definir um esquema para esses dados e expor essas informações como eventos. Nesse caso, as interfaces apropriadas seriam dados expostos como tópicos do Pub/Sub.
Etapas do consumo de dados
Os produtores de dados documentam o produto de dados deles no catálogo central, incluindo orientações sobre como consumir os dados. Para uma organização com vários domínios, essa abordagem de documentação cria uma arquitetura diferente do pipeline ELT/ETL tradicional, criado centralmente, em que os processadores criam saídas sem os limites dos domínios de negócios. Os consumidores de dados em uma malha de dados precisam ter uma camada de descoberta e de consumo bem projetada para criar um ciclo de vida de consumo de dados. A camada precisa incluir o seguinte:
Etapa 1: descobrir produtos de dados usando a pesquisa declarativa e a análise de especificações de produtos de dados: os consumidores de dados podem pesquisar qualquer produto de dados que os produtores registraram no catálogo central. Para todos os produtos de dados, a tag de produto de dados especifica como fazer solicitações de acesso a dados e o modo de consumir dados da interface de produto de dados necessária. Os campos nas tags de produtos de dados podem ser pesquisados usando um aplicativo de pesquisa. As interfaces de produtos de dados implementam URIs de dados, o que significa que os dados não precisam ser movidos para uma zona de consumo separada para atender aos consumidores. Quando os dados em tempo real não são necessários, os consumidores consultam produtos de dados e criam relatórios com os resultados gerados.
Etapa 2: analisar dados usando acesso interativo e prototipagem: os consumidores de dados usam ferramentas interativas, como o BigQuery Studio e os Notebooks do Jupyter para interpretar e testar os dados com o objetivo de refinar as consultas necessárias para uso em produção. As consultas interativas permitem que os consumidores de dados explorem novas dimensões de dados e melhorem a precisão dos insights gerados em cenários de produção.
Etapa 3: com o produto de dados consumido por meio de um aplicativo, com acesso e produção programáticos:
- Relatórios de BI. Os relatórios e painéis em lote e quase em tempo real são o grupo mais comum de casos de uso analíticos exigidos por consumidores de dados. Os relatórios podem exigir acesso a produtos de dados diferentes para ajudar a facilitar a tomada de decisões. Por exemplo, uma plataforma de dados do cliente exige a consulta programática de pedidos e produtos de dados de CRM de maneira programada. Os resultados dessa abordagem fornecem uma visão holística do cliente para os usuários comerciais que consomem os dados.
- Modelo de IA/ML para previsão em lote e em tempo real. Os cientistas de dados usam princípios comuns de MLOps para criar e atender modelos de ML que consomem produtos de dados disponibilizados pelas equipes de produtos de dados. Os modelos de ML oferecem recursos de inferência em tempo real para casos de uso transacionais, como a detecção de fraudes. Da mesma forma, com a análise exploratória de dados, os consumidores de dados podem enriquecer os dados de origem. Por exemplo, a análise exploratória de dados de campanhas de vendas e marketing mostra segmentos de clientes demográficos em que as vendas precisam ser mais altas e, portanto, as campanhas precisam ser exibidas.
A seguir
- Consulte uma implementação de referência da arquitetura da malha de dados.
- Saiba mais sobre o BigQuery.
- Leia mais sobre a Vertex AI.
- Saiba mais sobre ciência de dados no Dataproc.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.