Em uma malha de dados, uma plataforma de dados de autoatendimento permite que os usuários gerem valor a partir dos dados ao possibilitar que eles criem, compartilhem e usem produtos de dados de maneira autônoma. Para aproveitar ao máximo esses benefícios, recomendamos que sua plataforma de dados de autoatendimento ofereça os recursos descritos neste documento.
Este documento faz parte de uma série em que se descreve como implementar uma malha de dados no Google Cloud. Ele pressupõe que você leu e conhece os conceitos descritos em Criar uma malha de dados moderna e distribuída com o Google Cloud e Arquitetura e funções em malha de dados.
A série tem as seguintes partes:
- Arquitetura e funções em uma malha de dados
- Criar uma plataforma de dados de autoatendimento para uma malha de dados (este documento)
- Criar produtos de dados em uma malha de dados
- Descobrir e consumir produtos de dados em uma malha de dados
As equipes de plataforma de dados normalmente criam plataformas centrais de dados de autoatendimento, conforme descrito neste documento. Essa equipe cria as soluções e os componentes que as equipes do domínio (produtores e consumidores de dados) podem usar para criar e consumir produtos de dados. As equipes de domínio representam partes funcionais de uma malha de dados. Ao criar esses componentes, a equipe da plataforma de dados proporciona uma experiência tranquila de desenvolvimento e reduz a complexidade de criar, implantar e manter produtos de dados que são seguros e interoperáveis.
Em última análise, a equipe de plataforma de dados precisa permitir que as equipes de domínio se movam mais rapidamente. Elas ajudam a aumentar a eficiência das equipes do domínio, fornecendo a essas equipes um conjunto limitado de ferramentas que atendem às necessidades delas. Ao fornecer essas ferramentas, a equipe da plataforma de dados elimina o ônus de fazer com que a equipe de domínio crie e gere essas ferramentas por conta própria. As opções de ferramentas precisam ser personalizáveis de acordo com as diferentes necessidades, e não forçar uma maneira inflexível de trabalhar nas equipes do domínio de dados.
A equipe da plataforma de dados não deve se concentrar na criação de soluções personalizadas para orquestradores de pipeline de dados ou para sistemas de integração e implantação contínuas (CI/CD). Soluções como sistemas de CI/CD estão prontamente disponíveis como serviços de nuvem gerenciados, por exemplo, o Cloud Build. O uso de serviços de nuvem gerenciados pode reduzir as sobrecargas operacionais para a equipe da plataforma de dados e permitir que eles se concentrem nas necessidades específicas das equipes de domínio de dados como os usuários da plataforma. Com a sobrecarga operacional reduzida, a equipe da plataforma de dados pode se concentrar mais tempo para atender às necessidades específicas das equipes de domínio de dados.
Arquitetura
O diagrama a seguir ilustra os componentes da arquitetura de uma plataforma de dados de autoatendimento. O diagrama também mostra como esses componentes podem ajudar as equipes enquanto desenvolvem e consomem produtos de dados na malha de dados.

Conforme mostrado no diagrama anterior, a plataforma de dados de autoatendimento oferece os itens a seguir:
Soluções de plataforma: essas soluções consistem em componentes que podem ser compostos para provisionar projetos e recursos do Google Cloud, que os usuários selecionam e criam em diferentes combinações para atender aos requisitos específicos. Em vez de interagir diretamente com os componentes, os usuários da plataforma podem interagir com as soluções para ajudá-los a atingir uma meta específica. As equipes de domínio de dados precisam desenvolver soluções da plataforma que resolvam pontos problemáticos e áreas de atrito comuns que causam lentidão no desenvolvimento e consumo de produtos de dados. Por exemplo, as equipes de domínio de dados que se integram à malha de dados podem usar um modelo de infraestrutura como código (IaC, na sigla em inglês). O uso de modelos de IaC permite criar rapidamente um conjunto de projetos do Google Cloud com permissões padrão de gerenciamento de identidade e acesso (IAM), redes, políticas de segurança e APIs relevantes do Google Cloud ativadas para o desenvolvimento de produtos de dados. Recomendamos que cada solução seja acompanhada de documentação, como orientações de "como começar" e amostras de código. As soluções de plataforma de dados e os respectivos componentes precisam ser seguros e em conformidade por padrão.
Serviços comuns: esses serviços oferecem capacidade de descoberta, gerenciamento, compartilhamento e observabilidade de produtos de dados. Esses serviços facilitam a confiança dos consumidores em produtos de dados e são uma maneira eficaz para os produtores de dados alertarem os consumidores sobre problemas com os produtos deles.
As soluções e os serviços comuns da plataforma de dados podem incluir os itens a seguir:
- Modelos de IaC para configurar ambientes básicos de espaço de trabalho
de desenvolvimento de produtos de dados, incluindo:
- IAM
- Geração de registros e monitoramento
- Rede
- Proteções de segurança e conformidade
- Inclusão de tag de recurso para atribuição de faturamento
- Armazenamento, transformação e publicação de produtos de dados
- Registro, catalogação e inclusão de tag de metadados de produtos de dados
- Modelos de IaC que seguem proteções de segurança organizacional e práticas recomendadas e podem ser usados para implantar recursos do Google Cloud em espaços de trabalho de desenvolvimento de produtos de dados que já existem.
- modelos de pipeline de dados e aplicativos que podem ser usados para inicializar
novos projetos ou como referência para projetos atuais; Confira alguns exemplos desses modelos:
- Uso de bibliotecas e frameworks comuns
- Integração com ferramentas de geração de registros, monitoramento e observabilidade da plataforma
- Ferramentas de criação e teste
- Gerenciamento de configurações
- Empacotamento e pipelines de CI/CD para implantação
- Autenticação, implantação e gerenciamento de credenciais
- Serviços comuns para fornecer observabilidade e governança de produtos de dados, que podem incluir os itens a seguir:
- Verificações de tempo de atividade para mostrar o estado geral dos produtos de dados.
- Métricas personalizadas para fornecer indicadores úteis sobre produtos de dados.
- Suporte operacional pela equipe central, para que as equipes de consumidores de dados sejam alertadas sobre alterações nos produtos de dados que usam.
- Visões gerais dos produtos para mostrar o desempenho dos produtos de dados.
- Um catálogo de metadados para descobrir produtos de dados.
- Um conjunto de políticas computacionais definido de modo central que pode ser aplicado globalmente em toda a malha de dados.
- Um marketplace de dados para facilitar o compartilhamento de dados entre equipes de domínio.
O artigo Criar componentes e soluções de plataforma usando modelos de IaC discute as vantagens dos modelos de IaC para expor e implantar produtos de dados. Fornecer serviços comuns aborda por que é útil fornecer às equipes de domínio componentes de infraestrutura comuns criados e gerenciados pela equipe de plataforma de dados.
Criar componentes e soluções de plataforma usando modelos de IaC
O objetivo das equipes de plataforma de dados é configurar plataformas de dados de autoatendimento para extrair mais valor dos dados. Para desenvolver essas plataformas, elas criam e fornecem às equipes de domínio modelos de infraestrutura verificados, seguros e de autoatendimento. As equipes de domínio usam esses modelos para implantar os ambientes de desenvolvimento e consumo de dados. Os modelos de IaC ajudam as equipes de plataforma de dados a atingir essa meta e permitir o escalonamento. O uso de modelos de IaC verificados e confiáveis simplifica o processo de implantação de recursos para as equipes de domínio, permitindo que elas reutilizem pipelines de CI/CD que já existem. Com essa abordagem, as equipes de domínio começam a usar o produto rapidamente e se tornam produtivas na malha de dados.
Os modelos de IaC podem ser criados usando uma ferramenta de IaC. Embora haja várias ferramentas de IaC, incluindo Config Connector do Cloud, Pulumi, Chef e Ansible , este documento contém exemplos de ferramentas de IaC baseadas em Terraform. O Terraform é uma ferramenta de IaC de código aberto que permite que a equipe de plataforma de dados crie componentes e soluções de plataforma combináveis com eficiência para recursos do Google Cloud. Com o Terraform, a equipe de plataforma de dados escreve um código que especifica o estado final desejado e permite que a ferramenta descubra como alcançar esse estado. Essa abordagem declarativa permite que a equipe de plataforma de dados trate os recursos de infraestrutura como artefatos imutáveis para implantação em ambientes. Isso também ajuda a reduzir o risco de inconsistências que surgem entre os recursos implantados e o código declarado no controle de origem (conhecido como deslocamento de configuração). O deslocamento de configuração causado por alterações manuais e ad-hoc na infraestrutura dificulta a implantação segura e repetida de componentes de IaC em ambientes de produção.
Os modelos comuns de IaC para componentes da plataforma combináveis incluem o uso de módulos do Terraform para implantar recursos como um conjunto de dados do BigQuery, um bucket do Cloud Storage ou um banco de dados do Cloud SQL. Os módulos do Terraform podem ser combinados em soluções completas para implantar projetos completos do Cloud, incluindo recursos relevantes implantados usando os módulos compostos. Veja exemplos de módulos do Terraform nos blueprints do Terraform para o Google Cloud.
Cada módulo do Terraform precisa atender às políticas de segurança e conformidade da sua organização por padrão. Essas proteções e políticas também podem ser expressas como código e ser automatizadas com o uso de ferramentas automatizadas de verificação de conformidade, como a ferramenta de validação de políticas do Google Cloud.
Sua organização precisa testar continuamente os módulos do Terraform fornecidos pela plataforma, usando as mesmas proteções de conformidade automatizadas que ela usa para promover mudanças na produção.
Para tornar os componentes e as soluções de IaC detectáveis e consumíveis para as equipes de domínio com pouca experiência com o Terraform, recomendamos o uso de serviços como o catálogo de serviços. Os usuários com requisitos de personalização significativos precisam ter permissão para criar as próprias soluções de implantação com os mesmos modelos combináveis do Terraform usados pelas soluções já existentes.
Ao usar o Terraform, recomendamos que você siga as práticas recomendadas do Google Cloud, conforme descrito em Práticas recomendadas para usar o Terraform.
Para ilustrar como o Terraform pode ser usado para criar componentes da plataforma, as próximas seções mostram exemplos de como ele pode ser usado para expor interfaces de consumo e consumir um produto de dados.
Expor uma interface de consumo
Uma interface de consumo para um produto de dados é um conjunto de garantias sobre a qualidade dos dados e os parâmetros operacionais fornecidos pela equipe de domínio de dados para permitir que outras equipes descubram e usem os produtos de dados. Cada interface de consumo também contém um modelo de suporte do produto e uma documentação do produto. Um produto de dados pode ter diferentes tipos de interfaces de consumo, como APIs ou streams, conforme descrito em Criar produtos de dados em uma malha de dados. A interface de consumo mais comum pode ser um conjunto de dados autorizado do BigQuery, uma visualização autorizada ou uma função autorizada. Essa interface expõe uma tabela virtual de somente leitura, que é expressa como uma consulta na malha de dados. A interface não concede permissões de leitura para acesso direto aos dados subjacentes.
O Google fornece um exemplo de módulo do Terraform para criar visualizações autorizadas sem conceder às equipe permissões para os conjuntos de dados autorizados subjacentes. O código a seguir desse módulo do Terraform concede essas permissões do IAM na visualização autorizada dataset_id:
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
Se você precisa conceder aos usuários acesso a várias visualizações, conceder acesso a cada visualização autorizada pode ser demorado e mais difícil de manter. Em vez de criar várias visualizações autorizadas, use um conjunto de dados autorizado para autorizar automaticamente todas as visualizações criadas nesse conjunto.
Consumir um produto de dados
Na maioria dos casos de uso de análise, os padrões de consumo são determinados pelo aplicativo em que ocorre a utilização dos dados. O uso principal de um ambiente de consumo fornecido centralmente é para exploração de dados antes que eles sejam usados no aplicativo consumidor. Conforme abordado em Descobrir e consumir produtos em uma malha de dados, o SQL é o método mais usado para consultar produtos de dados. Por esse motivo, a plataforma precisa fornecer aos consumidores de dados um aplicativo SQL para análise detalhada dos dados.
Dependendo do caso de uso de análise, é possível usar o Terraform para implantar o ambiente de consumo para consumidores de dados. Por exemplo, a ciência de dados é um caso de uso comum para consumidores de dados. É possível usar o Terraform para implantar notebooks gerenciados pelo usuário da Vertex AI que serão usados como um ambiente de desenvolvimento de ciência de dados. Dos notebooks de ciência de dados, os consumidores de dados podem usar as próprias credenciais para fazer login na malha de dados e explorar os dados a que têm acesso e desenvolver modelos de ML com base nesses dados.
Para saber como usar o Terraform para implantar e ajudar a proteger um ambiente de notebook no Google Cloud, consulte Criar e implantar modelos de IA generativa e de machine learning em uma empresa.
Fornecer serviços comuns
Além dos componentes e soluções de autoatendimento da IaC, a equipe da plataforma de dados também pode assumir a propriedade da criação e operação dos serviços comuns da plataforma compartilhada usados por várias equipes do domínio de dados. Exemplos comuns de serviços de plataforma compartilhados incluem software de terceiros auto-hospedado como ferramentas de visualização de Business Intelligence ou um cluster do Kafka. No Google Cloud, a equipe de plataforma de dados pode decidir gerenciar recursos como coletores do Cloud Logging e Dataplex em nome das equipes de domínio de dados. O gerenciamento de recursos para as equipes de domínio de dados permite que a equipe de plataforma de dados facilite o gerenciamento centralizado de políticas e a auditoria em toda a organização.
As próximas seções mostram como usar o Dataplex para gerenciamento central e governança em uma malha de dados no Google Cloud, além da implementação de recursos de observabilidade de dados em uma malha de dados.
Dataplex para governança de dados
O Dataplex oferece uma plataforma de gerenciamento de dados que ajuda a criar domínios de dados independentes em uma malha de dados que abrange a organização. Com o Dataplex, você mantém controles centrais para administrar e monitorar os dados nos domínios.
Com o Dataplex, uma organização pode organizar logicamente os dados (fontes de dados compatíveis) e os artefatos relacionados, como código, notebooks e registros, em um lake do Dataplex que representa um domínio de dados. No diagrama a seguir, um domínio de vendas usa o Dataplex para organizar os recursos, incluindo métricas e registros de qualidade de dados, nas zonas do Dataplex.
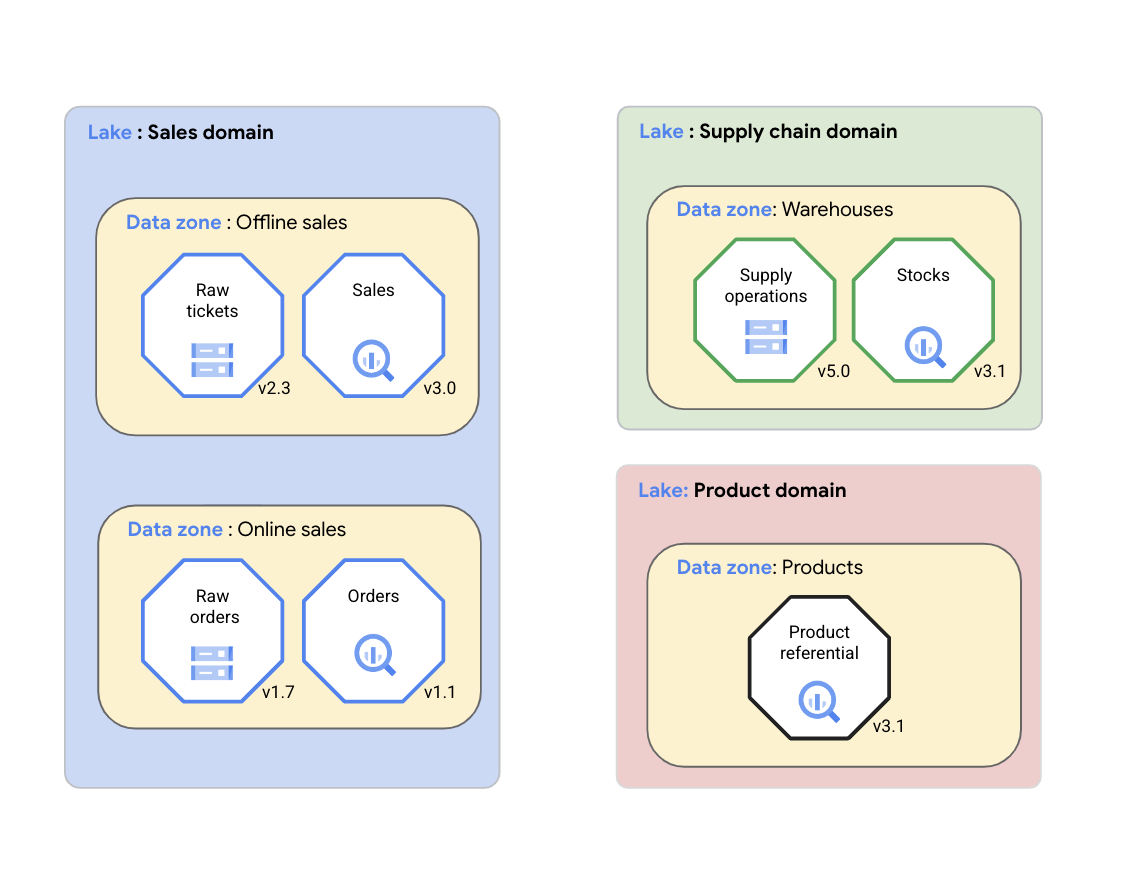
Conforme mostrado no diagrama anterior, o Dataplex pode ser usado para gerenciar dados de domínio nos seguintes recursos:
- O Dataplex permite que as equipes de domínio de dados gerenciem de maneira consistente os recursos de dados em um grupo lógico chamado Dataplex lake. A equipe de domínio de dados pode organizar seus recursos do Dataplex no mesmo lake do Dataplex sem mover dados fisicamente ou armazená-los em um único sistema de armazenamento. Os recursos do Dataplex podem se referir a buckets do Cloud Storage e conjuntos de dados do BigQuery armazenados em vários projetos do Cloud diferentes do projeto do Cloud que contém o Dataplex lake. Os recursos do Dataplex podem ser estruturados ou não e armazenados em um data lake ou data warehouse analítico. No diagrama, há data lakes para o domínio de vendas, domínio da cadeia de suprimentos e domínio do produto.
- Com as zonas do Dataplex, a equipe de domínio pode organizar ainda mais os recursos de dados em subgrupos menores dentro do mesmo lake do Dataplex e adicionar estruturas que capturem aspectos importantes do subgrupo. Por exemplo, as zonas do Dataplex podem ser usadas para agrupar recursos de dados associados em um produto de dados. O agrupamento de recursos de dados em uma única zona do Dataplex permite que as equipes de domínio de dados gerenciem políticas de acesso e de governança de dados de maneira consistente em toda a zona como um único produto de dados. No diagrama, há zonas de dados para vendas off-line, vendas on-line, warehouses da cadeia de suprimentos e produtos.
Os lakes e as zonas do Dataplex permitem que uma organização unifique dados distribuídos e os organize com base no contexto de negócios. Esse acordo forma a base para atividades como o gerenciamento de metadados, a configuração de políticas de governança e o monitoramento da qualidade de dados. Essas atividades permitem que a organização gerencie os dados distribuídos em escala, como em uma malha de dados.
Observabilidade dos dados
Cada domínio de dados precisa implementar os próprios mecanismos de monitoramento e alerta, de preferência com uma abordagem padronizada. Cada domínio pode aplicar as práticas de monitoramento descritas em Conceitos no monitoramento de serviços, fazendo os ajustes necessários nos domínios de dados. A observabilidade é um assunto extenso e está fora do escopo deste documento. Esta seção aborda apenas os padrões que são úteis nas implementações de malha de dados.
Para produtos com vários consumidores de dados, fornecer a cada um deles informações oportunas sobre o status do produto pode se tornar um fardo operacional. Soluções básicas, como distribuições de e-mail gerenciadas manualmente, geralmente são propensas a erros. Elas podem ser úteis para notificar os consumidores sobre interrupções planejadas, próximos lançamentos de produtos e descontinuações, mas não fornecem reconhecimento operacional em tempo real.
Os serviços centrais podem desempenhar um papel importante no monitoramento da integridade e da qualidade dos produtos na malha de dados. Embora não seja um pré-requisito para uma implementação bem-sucedida da malha de dados, implementar recursos de observabilidade pode melhorar a satisfação dos produtores e consumidores de dados e reduzir os custos gerais de suporte e operacionais. O diagrama a seguir mostra uma arquitetura de observabilidade de malha de dados com base no Cloud Monitoring.

As próximas seções descrevem os componentes mostrados no diagrama, que são estes:
- Verificações de tempo de atividade para mostrar o estado geral dos produtos de dados.
- Métricas personalizadas para fornecer indicadores úteis sobre produtos de dados.
- Suporte operacional da equipe da plataforma de dados central para alertar os consumidores de dados sobre alterações nos produtos de dados que eles usam.
- Visões gerais dos produtos e painéis para mostrar o desempenho dos produtos de dados.
Verificações de tempo de atividade
Os produtos de dados podem criar aplicativos personalizados simples que implementam verificações de tempo de atividade. Essas verificações podem servir como indicadores de alto nível do estado geral do produto. Por exemplo, se a equipe de produto de dados descobre uma queda repentina na qualidade dos dados do produto, a equipe pode marcá-lo como não íntegro. As verificações de tempo de atividade que estão próximas ao tempo real são especialmente importantes para consumidores de dados que têm produtos derivados que dependem da disponibilidade constante dos dados no produto de dados de upstream. Os produtores de dados precisam criar verificações de tempo de atividade para incluir a verificação de dependências de upstream, fornecendo assim uma imagem precisa da integridade dos produtos aos consumidores de dados.
Os consumidores de dados podem incluir verificações de tempo de atividade do produto no processamento. Por exemplo, um job de composição que gera um relatório com base nos dados fornecidos por um produto de dados pode, como primeira etapa, validar se o produto está no estado "em execução". Recomendamos que seu aplicativo de verificação de tempo de atividade retorne um payload estruturado no corpo da mensagem da resposta HTTP. Esse payload estruturado precisa indicar se há algum problema, a causa raiz do problema em formato legível por humanos e, se possível, o tempo estimado para restaurar o serviço. Esse payload estruturado também pode fornecer informações mais refinadas sobre o estado do produto. Por exemplo, ele pode conter as informações de integridade sobre cada uma das visualizações no conjunto de dados autorizado exposto como um produto.
Métricas personalizadas
Produtos de dados podem ter várias métricas personalizadas para medir a utilidade. As equipes de produtores de dados podem publicar essas métricas personalizadas nos respectivos projetos do Cloud específicos ao domínio. Para criar uma experiência de monitoramento unificada em todos os produtos de dados, um projeto central de monitoramento de malha de dados pode receber acesso a esses projetos específicos do domínio.
Cada tipo de interface de consumo do produto de dados tem métricas diferentes para medir a utilidade delas. As métricas também podem ser específicas do domínio da empresa. Por exemplo, as métricas das tabelas do BigQuery expostas por visualizações ou pela API Storage Read podem ser estas:
- O número de linhas.
- Atualização de dados (expressa como o número de segundos antes do tempo de medição).
- O índice de qualidade de dados.
- Os dados disponíveis. Essa métrica pode indicar que os dados estão disponíveis para consulta. Uma alternativa é usar as verificações de tempo de atividade mencionadas anteriormente neste documento.
Essas métricas podem ser visualizadas como indicadores de nível de serviço (SLI) de um produto específico.
Para fluxos de dados (implementados como tópicos do Pub/Sub), essa lista pode ser as métricas do Pub/Sub padrão, que estão disponíveis via tópicos.
Suporte operacional pela equipe de plataforma de dados central
A equipe de plataforma de dados central pode expor painéis personalizados para exibir diferentes níveis de detalhes aos consumidores de dados. Um painel de status simples que lista os produtos na malha de dados e o status de tempo de atividade desses produtos pode ajudar a responder a várias solicitações de usuários finais.
A equipe central também pode servir como um hub de distribuição de notificações para notificar os consumidores de dados sobre vários eventos nos produtos de dados que eles usam. Normalmente, esse hub é feito com a criação de políticas de alertas. Centralizar essa função pode reduzir o trabalho que precisa ser feito por cada equipe de produtores de dados. A criação dessas políticas não exige conhecimento dos domínios de dados e deve ajudar a evitar gargalos no consumo de dados.
Um estado final ideal para monitoramento de malha de dados é que o modelo de tag de produto de dados exponha os SLIs e os objetivos de nível de serviço (SLOs) aos quais o produto é compatível quando o produto é disponibilizado. A equipe central pode implantar automaticamente o alerta correspondente usando o monitoramento de serviços com a API Monitoring.
Visão geral dos produtos
Como parte do acordo de governança central, as quatro funções em uma malha de dados podem definir os critérios para criar visões gerais de produtos de dados. Essas visões gerais podem se tornar uma medida objetiva da performance do produto de dados.
Muitas das variáveis usadas para calcular as visões gerais são a porcentagem de tempo em que os produtos de dados estão atingindo o SLO. Podem ser critérios úteis a porcentagem de tempo de atividade, os índices médios de qualidade de dados e a porcentagem de produtos com atualização de dados que não está abaixo de um limite. Para calcular essas métricas automaticamente usando a Linguagem de consulta do Monitoring (MQL, na sigla em inglês), as métricas personalizadas e os resultados das verificações de tempo de atividade do projeto de monitoramento central precisam ser suficientes.
A seguir
- Saiba mais sobre o BigQuery.
- Conheça o Dataplex.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.