Dokumen ini menjelaskan beberapa arsitektur yang menyediakan ketersediaan tinggi (HA) untuk deployment PostgreSQL di Google Cloud. HA ukuran ketahanan sistem sebagai respon terhadap kegagalan infrastruktur yang mendasarinya. Dalam dokumen ini, HA mengacu pada ketersediaan cluster PostgreSQL dalam satu region cloud atau di antara beberapa region, bergantung pada arsitektur HA.
Dokumen ini ditujukan untuk administrator database, arsitek cloud, dan engineer DevOps yang ingin mempelajari cara meningkatkan keandalan tingkat data PostgreSQL dengan meningkatkan waktu operasi sistem secara keseluruhan. Dokumen ini membahas konsep yang relevan dengan menjalankan PostgreSQL pada Compute Engine. Dokumen ini tidak membahas penggunaan database terkelola seperti Cloud SQL untuk PostgreSQL dan AlloyDB untuk PostgreSQL.
Jika sistem atau aplikasi memerlukan status persisten untuk menangani permintaan atau transaksi, lapisan persisten data (tingkat data) harus tersedia agar berhasil menangani permintaan untuk kueri dan mutasi data. Periode nonaktif pada tingkat data mencegah sistem atau aplikasi melakukan tugas yang diperlukan.
Bergantung pada tujuan tingkat layanan (SLO) sistem Anda, Anda mungkin memerlukan arsitektur yang memberikan tingkat ketersediaan yang lebih tinggi. Terdapat lebih dari satu cara untuk mencapai HA, tetapi secara umum Anda menyediakan infrastruktur redundan yang dapat diakses dengan cepat oleh aplikasi Anda.
Dokumen ini membahas topik berikut:
- Definisi istilah yang terkait dengan konsep database dengan HA.
- Opsi untuk topologi PostgreSQL HA.
- Informasi kontekstual untuk pertimbangan setiap opsi arsitektur.
Terminologi
Istilah dan konsep berikut merupakan standar industri dan digunakan untuk memahami tujuan di luar dokumen ini.
- replikasi
-
Proses yang dilakukan untuk menulis transaksi (
INSERT,UPDATE, atauDELETE) dan perubahan skema (bahasa definisi data (DDL)) secara andal dicatat, di catat dalam log, lalu diterapkan secara berurutan ke semua node replikas database downstream pada arsitektur. - node utama
- Node yang memberikan pembacaan status terbaru dari data yang disimpan. Semua penulisan database harus diarahkan ke node utama.
- node replika (sekunder)
- Salinan online node database utama. Perubahan dapat direplikasi secara sinkron atau asinkron ke node replika dari node utama. Anda dapat membaca dari node replikasi dengan pemahaman bahwa data mungkin sedikit tertunda karena jeda replika.
- jeda replikasi
- Pengukuran, dalam nomor urut log (LSN), ID transaksi, atau waktu. Jeda replikasi menunjukkan perbedaan antara saat operasi perubahan diterapkan ke replika dibandingkan dengan saat diterapkan ke node utama.
- pengarsipan berkelanjutan
- Pencadangan inkremental pada database yang terus menyimpan transaksi berurutan ke dalam file.
- write-ahead log (WAL)
- Write-ahead log (WAL) adalah file log yang mencatat perubahan pada file data sebelum perubahan apa pun benar-benar dilakukan pada file. Jika terjadi error server, WAL adalah cara standar untuk membantu memastikan integritas data dan ketahanan operasi tulis Anda.
- Catatan WAL
- Data transaksi yang diterapkan pada database. Catatan WAL diformat dan disimpan sebagai serangkaian catatan yang menjelaskan perubahan tingkat halaman file data.
- Log Sequence Number (LSN)
- Transaksi membuat catatan WAL yang ditambahkan ke file WAL. Posisi tempat penyisipan terjadi disebut Log Sequence Number (LSN). Ini adalah bilangan bulat 64-bit, yang direpresentasikan sebagai dua angka heksadesimal yang dipisahkan dengan garis miring (XXXXXXXX/YYZZZZZZ). 'Z' mewakili posisi offset dalam file WAL.
- file segmen
- File yang berisi catatan WAL sebanyak mungkin, bergantung pada ukuran file yang Anda konfigurasi. File segmen memiliki nama file yang meningkat secara monoton dan ukuran file default 16 MB.
- replikasi sinkron
-
Bentuk replikasi yang server utama menunggu replika untuk
mengonfirmasi bahwa data telah ditulis ke log transaksi replika sebelum
mengonfirmasi commit ke klien. Saat menjalankan replikasi streaming, Anda
dapat menggunakan opsi PostgreSQL
synchronous_commit, yang membantu memastikan konsistensi antara server utama dan replika. - replikasi asinkron
- Bentuk replikasi yang server utama menunggu replika untuk mengonfirmasi bahwa data telah ditulis ke log transaksi replika sebelum mengonfirmasi commit ke klien. Replikasi asinkron memiliki latensi lebih rendah dibandingkan dengan replikasi sinkron. Namun, jika error utama dan transaksi yang di-commit tidak ditransfer ke replika, ada kemungkinan kehilangan data. Replikasi asinkron adalah mode default replikasi pada PostgreSQL, baik menggunakan pengiriman log berbasis file atau replikas streaming.
- pengiriman log berbasis file
- Metode replikasi di PostgreSQL yang mentransfer file segmen WAL dari server database utama ke replika. Layanan utama beroperasi dalam mode pengarsipan berkelanjutan, sementara setiap layanan standby beroperasi dalam mode pemulihan berkelanjutan untuk membaca file WAL. Jenis replikasi ini bersifat asinkron.
- replikasi streaming
- Metode replikasi yang replika terhubung ke replika utama dan terus menerima urutan perubahan yang berkelanjutan. Karena pembaruan masuk melalui aliran, metode ini membuat replika selalu terbaru dengan yang utama jika dibandingkan dengan replikasi pengiriman log. Meskipun replikasi bersifat asinkron secara default Anda dapat mengonfigurasi replikasi sinkron.
- replikasi streaming fisik
- Metode replikasi yang memindahkan perubahan ke replika. Metode ini menggunakan catatan WAL yang berisi perubahan data fisik dalam bentuk alamat blok disk dan perubahan byte per byte.
- replikasi streaming logis
- Metode replikasi yang menangkap perubahan berdasarkan identitas replikasinya (kunci utama) yang memungkinkan kontrol lebih besar atas cara data direplikasi dibandingkan dengan replikasi fisik. Karena pembatasan pada replikasi logis PostgreSQL, replikasi streaming logis memerlukan konfigurasi khusus untuk penyiapan HA. Panduan ini membahas replikasi fisik standar dan tidak membahas replikasi logis.
- waktu beroperasi
- Persentase waktu resource bekerja dan mampu mengirim respons atas suatu permintaan.
- deteksi kegagalan
- Proses mengidentifikasi bahwa telah terjadi kegagalan infrastruktur.
- failover
- Proses mempromosikan infrastruktur pencadangan atau standby (dalam hal ini, node replika) untuk menjadi infrastruktur utama. Selama failover, node replika menjadi node utama.
- beralih
- Proses menjalankan failover manual pada sistem produksi. Peralihan menguji sistemnya bekerja dengan baik, atau mengeluarkan node utama saat ini dari cluster untuk pemeliharaan.
- batas waktu pemulihan (RTO):
- Durasi real time yang telah berlalu untuk proses failover tingkat data selesai. RTO bergantung pada jumlah waktu yang dapat diterima dari perspektif bisnis.
- toleransi jumlah data yang hilang (RPO):
- Jumlah kehilangan data (dalam elapsed real time) untuk tingkat data yang akan dipertahankan sebagai akibat dari failover. RPO bergantung pada jumlah kehilangan data yang dapat diterima dari perspektif bisnis.
- pengganti
- Proses mengaktifkan kembali node utama sebelumnya setelah kondisi yang menyebabkan failover diatasi.
- pemulihan mandiri
- Kemampuan sistem untuk menyelesaikan masalah tanpa tindakan eksternal oleh operator manusia.
- partisi jaringan
- Kondisi saat dua node dalam arsitektur—misalnya node utama dan replika—tidak dapat berkomunikasi satu sama lain melalui jaringan.
- split brain
- Kondisi yang terjadi saat dua node secara bersamaan yakin bahwa keduanya adalah node utama.
- grup node
- Set resource komputasi yang menyediakan layanan. Dalam dokumen ini layanan tersebut adalah tingkatan persistensi data.
- saksi atau simpul kuorum
- Resource komputasi terpisah yang membantu grup node menentukan tindakan yang harus dilakukan saat kondisi split-brain terjadi.
- pemilihan utama atau pemimpin
- Proses yang digunakan oleh sekelompok node sadar, termasuk node saksi, menentukan node yang harus menjadi node utama.
Waktu yang tepat untuk mempertimbangkan arsitektur dengan HA
Arsitektur dengan HA memberikan perlindungan yang lebih baik terhadap periode nonaktif tingkat data jika dibandingkan dengan penyiapan database node tunggal. Untuk memilih opsi terbaik untuk kasus penggunaan bisnis, Anda perlu memahami toleransi Anda terhadap periode nonaktif dan konsekuensi masing-masing dari berbagai arsitektur.
Gunakan arsitektur HA ketika Anda ingin menyediakan peningkatan waktu beroperasi tingkat data untuk memenuhi persyaratan keandalan untuk workload dan layanan Anda. Jika lingkungan Anda menoleransi jumlah periode nonaktif, arsitektur HA mungkin menimbulkan biaya dan kompleksitas yang tidak diperlukan. Misalnya, lingkungan pengembangan atau pengujian jarang memerlukan ketersediaan tingkat database yang tinggi.
Pertimbangkan persyaratan Anda untuk ketersediaan tinggi (HA)
Berikut beberapa pertanyaan yang membantu Anda untuk memutuskan opsi PostgreSQL terbaik untuk bisnis Anda:
- Tingkat ketersediaan seperti apa yang ingin Anda capai? Apakah Anda memerlukan opsi yang memungkinkan layanan Anda terus berfungsi hanya selama satu zona atau kegagalan regional sepenuhnya? Beberapa opsi HA dibatasi pada satu region semntara yang lain dapat multi-region.
- Layanan atau pelanggan apa yang mengandalkan paket data Anda dan berapa biaya bagi bisnis Anda jika terjadi periode nonaktif pada tingkatan persistensi data? Jika layanan hanya melayani pelanggan internal yang sesekali memerlukan penggunaan sistem, layanan tersebut kemungkinan memiliki persyaratan ketersediaan yang lebih rendah dari layanan yang berinteraksi dengan pengguna akhir yang melayani pelanggan secara terus menerus.
- Berapa anggaran operasional Anda? Biaya adalah pertimbangan penting: untuk menyediakan HA kemungkinan besar dapat meningkatkan biaya infrastruktur dan penyimpanan.
- Seberapa otomatis proses yang diperlukan, dan seberapa lama Anda untuk menggagalkannya? (Apa RTO Anda?) Opsi HA berdasarkan seberapa cepat sistem dapat melakukan failover dan tersedia untuk pelanggan.
- Apakah Anda dapat kehilangan data karena hasil dari failover? (Apa RPO Anda?) Karena sifat topologi HA yang didistribusikan terdapat keseimbangan antara latensi commit dan resiko kehilangan data karena kegagalan.
Cara kerja HA
Pada bagian ini menjelaskan replikasi streaming dan streaming sinkron yang melandasi arsitektur HA PostgreSQL.
Replikasi streaming
Replikasi streaming adalah pendekatan replikasi yang mana replika terhubung ke replika utama dan terus menerima aliran data WAL. Dibandingkan dengan replikasi pengiriman log, replikasi streaming memungkinkan replika tetap lebih baru dengan replika utama. PostgreSQL menawarkan replikasi streaming bawaan yang dimulai dari versi 9. Banyak solusi HA PostgreSQL menggunakan replikasi streaming bawaan untuk menyediakan mekanisme bagi beberapa node replika PostgreSQL agar tetap sinkron dengan node utama. Beberapa opsi tersebut akan dibahas di bagian Arsitektur HA PostgreSQL nanti pada dokumen ini.
Setiap node replika memerlukan dedikasi resource komputasi dan penyimpanan. Infrastruktur node replikas tidak bergantung pada yang utama. Anda dapat menggunakan node replika sebagai hot standby untuk melayani kueri pelanggan hanya baca. Pendekatan ini memungkinkan load balancing kueri hanya baca diseluruh replika utama, salah satu atau beberapa replika.
Replikasi streaming secara default bersifat asinkron; replika utama tidak menunggu konfirmasi dari replika sebelum mengonfirmasi commit transaksi pada klien. Jika replika utama mengalami kegagalan setelah mengonfirmasi transaksi, tetapi sebelum replika menerima transaksi, replikasi asinkron dapat menyebabkan kehilangan data. Jika replika dipromosikan untuk menjadi primer baru, transaksi tersebut tidak akan ada.
Replikasi streaming sinkron
Anda dapat mengonfigurasi replikasi streaming sebagai sinkron dengan memilih satu atau beberapa replika untuk menjadi standby sinkron. Jika Anda mengonfigurasi arsitektur untuk replikasi sinkron, replika utama tidak mengonfirmasi commit transaksi hingga replika mengonfirmasi persistensi transaksi. Replikasi streaming sinkron memberikan peningkatan ketahanan sebagai imbalan atas latensi transaksi yang lebih tinggi.
Opsi konfigurasi
synchronous_commit
juga memungkinkan Anda mengonfigurasi
tingkat ketahanan replika progresif berikut untuk transaksi:
local: replika standby sinkron tidak terlibat dalam konfirmasi commit. Primary mengonfirmasi commit transaksi setelah catatan WAL ditulis dan dihapus ke disk lokalnya. Commit transaksi di replika utama tidak melibatkan replika standby. Transaksi dapat hilang jika terjadi kegagalan pada primary.on[default]: replika standby sinkron menulis transaksi yang di-commit ke WAL sebelum mengirimkan konfirmasi ke yang utama. Penggunaan konfigurasionakan memastikan bahwa transaksi hanya dapat hilang jika replika standby utama dan semua replikasi sinkron mengalami kegagalan penyimpanan secara bersamaan. Karena replika hanya mengirim konfirmasi setelah menulis data WAL, klien yang membuat kueri replika tidak akan melihat perubahan sampai masing-masing catatan WAL diterapkan ke database replika.remote_write: replika standby sinkron mengonfirmasi penerimaan catatan WAL di tingkat OS, tetapi tidak menjamin bahwa catatan WAL ditulis ke disk. Karenaremote_writetidak menjamin bahwa WAL telah ditulis, transaksi dapat hilang jika terjadi kegagalan pada utama dan sekunder sebelum catatan ditulis.remote_writememiliki ketahanan yang lebih rendah daripada opsion.remote_apply: replika standby sinkron mengonfirmasi penerimaan transaksi dan aplikasi yang berhasil ke database sebelum mengonfirmasi commit transaksi ke klien. Penggunaan konfigurasiremote_applyakan memastikan transaksi dipertahankan pada replika dan hasil kueri klien segera menyertakan efek dari transaksi tersebut.remote_applymemberikan peningkatan ketahanan dan konsistensi dibandingkan denganondanremote_write.
Opsi konfigurasi synchronous_commit berfungsi dengan opsi konfigurasi synchronous_standby_names yang menentukan daftar server standby yang berpartisipasi dalam proses replikasi sinkron. Jika tidak ada nama standby sinkron yang ditentukan, commit transaksi tidak akan menunggu replikasi.
Arsitektur dengan HA PostgreSQL
Pada tingkat paling dasar, HA tingkat data terdiri dari hal-hal berikut:
- Mekanisme untuk mengidentifikasi apakah terjadi kegagalan node utama.
- Proses untuk melakukan failover saat node replika dipromosikan menjadi node utama.
- Proses untuk mengubah perutean kueri sehingga permintaan aplikasi mencapai node utama yang baru.
- Secara opsional, metode untuk kembali ke arsitektur asli menggunakan pre-failover utama dan node replika pada kapasitas aslinya.
Bagian berikut memberikan ringkasan arsitektur HA:
- Template Patroni
- Layanan dan ekstensi pg_auto_failover
- MIG stateful dan persistent disk regional
Solusi HA ini meminimalkan periode nonaktif jika ada gangguan infrastruktur atau zona. Saat memilih antara opsi ini, keseimbangan latensi commit, dan ketahanan berdasarkan kebutuhan bisnis Anda.
Aspek penting dari arsitektur HA adalah waktu dan upaya manual yang diperlukan untuk menyiapkan lingkungan standby baru bagi failover atau penggantian berikutnya. Jika tidak, sistem hanya dapat bertahan dari satu kegagalan, dan layanan tidak memiliki perlindungan dari pelanggaran SLA. Sebaiknya pilih arsitektur dengan HA yang dapat melakukan failover manual, atau peralihan, dengan infrastruktur produksi.
HA menggunakan template Patroni
Patroni adalah template software open source (berlisensi MIT), yang matang dan dikelola secara aktif yang menyediakan alat konfigurasi, deploy, dan operasi arsitektur HA PostgreSQL. Patroni menyediakan status cluster bersama dan konfigurasi arsitektur yang dipertahankan dalam penyimpanan konfigurasi terdistribusi (DCS). Opsi untuk mengimplementasikan DCS meliputi: etcd, Consul, Apache ZooKeeper, atau Kubernetes. Diagram berikut menunjukkan komponen utama cluster Patroni.
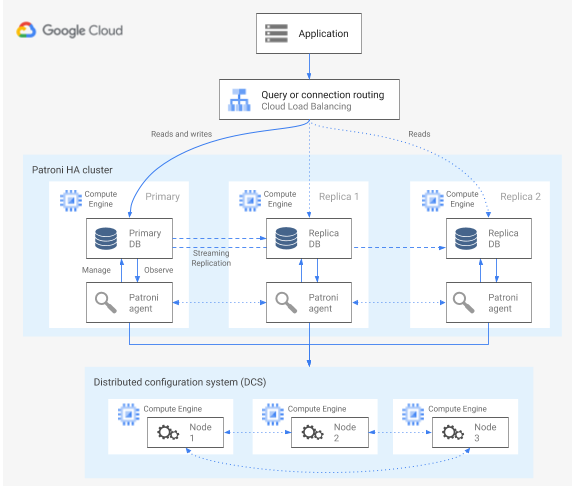
Gambar 1. Diagram komponen utama klaster Patroni.
Pada Gambar 1, load balancer berada di depan node PostgreSQL, dan DCS serta agen Pantroni beroperasi pada node PostgreSQL.
Patroni menjalankan proses agen pada setiap node PostgreSQL. Proses agen mengelola proses PostgreSQL dan konfigurasi node data. Agen Patroni berkoordinasi dengan node lain melalui DCS. Proses agen Patroni juga menampilkan REST API yang dapat Anda kueri untuk menentukan service health PostgreSQL dan konfigurasi pada setiap node.
Untuk menegaskan peran keanggotaan cluster-nya, node utama secara rutin memperbarui kunci pemimpin di DCS. Kunci pemimpin mencakup time to live (TTL). Jika TTL berlalu tanpa pembaruan, kunci pemimpin akan dikeluarkan dari DCS, dan pemilihan pemimpin mulai memilih kunci utama baru dari kumpulan kandidat.
Diagram berikut menunjukkan kluster kesehatan pada Node A berhasil memperbarui kunci pemimpin.
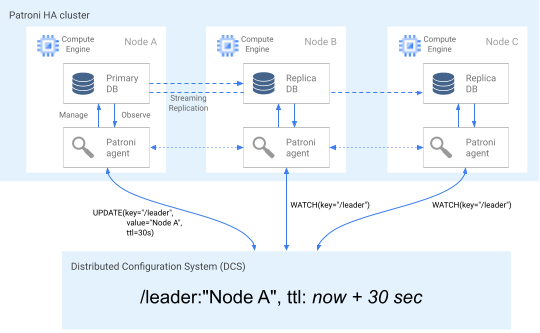
Gambar 2. Diagram klaster yang sehat.
Gambar 2 menunjukkan cluster yang sehat: lihat Node B dan Node C sementara Node A berhasil memperbarui kunci pemimpin.
Deteksi kegagalan
Agen Patroni terus melakukan telegraf kesehatannya dengan memperbarui kuncinya pada DCS. Pada saat yang sama, agen memvalidasi kondisi PostgreSQL; jika mendeteksi masalah, agen akan melindungi node sendiri dengan menonaktifkan dirinya sendiri, atau mendemosikan node menjadi replika. Seperti yang ditunjukkan pada diagram berikut, jika node yang diganggu adalah node utama, kunci pemimpin pada DCS akan berakhir, dan terjadi pemilihan pemimpin yang baru.
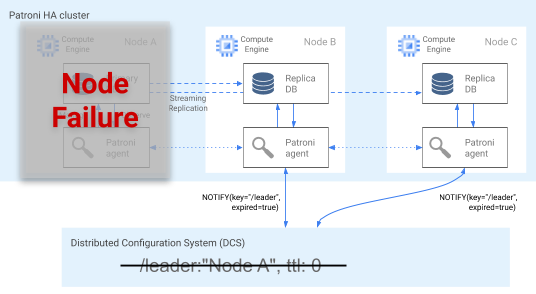
Gambar 3. Diagram cluster yang terganggu.
Gambar 3 menunjukkan cluster yang terganggu: node utama bawah belum memperbarui kunci pemimpin pada DCS, dan replika non pemimpin diberitahu bahwa kunci pemimpin telah berakhir.
Pada host Linux, Patroni juga menjalankan watchdog level OS pada node utama. Watchdog ini memproses pesan keep-alive dari proses agen Patroni. Jika proses tidak responsif, dan keep alive tidak terkirim, watchdog akan memulai ulang host. Watchdog membantu mencegah kondisi split brain saat node PostgreSQL terus berfungsi sebagai primer, namun kunci pemimpin di DCS telah berakhir karena kegagalan agen, dan primer (pemimpin) yang berbeda terpilih.
Proses failover
Jika kunci pemimpin berakhir masa berlakunya pada DCS, node replika kandidat memulai pemilihan pemimpin. Saat menemukan kunci pemimpin yang tidak ada, replika akan memeriksa posisi replikasinya dibandingkan dengan replika lainnya. Setiap replika menggunakan REST API untuk mendapatkan posisi log WAL pada node replika lainnya, seperti yang ditunjukkan pada diagram berikut.
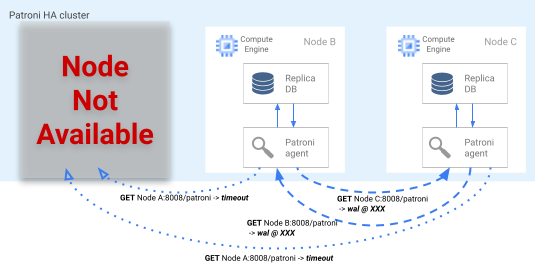
Gambar 4. Diagram proses failover Patroni.
Gambar 4 menunjukkan kueri posisi log WAL dan masing-masing hasil dari node replika aktif. Node A tidak tersedia, dan node B dan C yang responsif mengembalikan posisi WAL yang sama satu sama lain.
Node terbaru (atau node jika berada di posisi yang sama)
secara bersamaan mencoba mendapatkan kunci pemimpin pada DCS. Namun, hanya satu
node yang dapat membuat kunci pemimpin pada DCS. Node pertama yang berhasil membuat
kunci pemimpin adalah pemenang dari posisi teratas, seperti yang ditunjukkan dalam diagram
berikut. Atau, Anda dapat menetapkan kandidat failover pilihan dengan
menetapkan
tag failover_priority
dalam file konfigurasi.
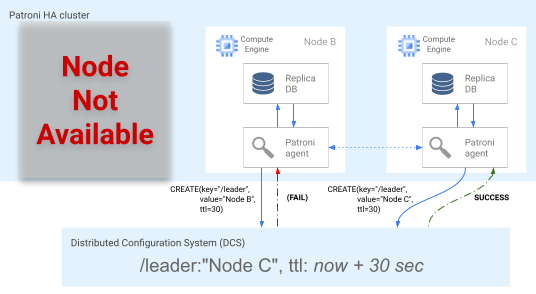
Gambar 5. Diagram perlombaan posisi teratas.
Gambar 5 menunjukkan posisi teratas: dua kandidat pemimpin mencoba mendapatkan kunci pemimpin, tetapi hanya satu dari dua node, Node C, yang berhasil menetapkan kunci pemimpin dan memenangkan perlombaan.
Setelah memenangkan pemilihan pemimpin, replika mempromosikan dirinya untuk menjadi utama baru. Mulai saat replika mempromosikan dirinya sendiri, node utama yang baru akan memperbarui kunci pemimpin di DCS untuk mempertahankan kunci pemimpin, dan node lainnya berfungsi sebagai replika.
Patroni juga menyediakan
alat kontrol patronictl
yang memungkinkan Anda menjalankan peralihan untuk menguji proses failover node.
Alat ini membantu operator menguji penyiapan HA mereka dalam produksi.
Pemilihan rute kueri
Proses agen Patroni yang berjalan di setiap node mengekspos endpoint REST API yang menunjukkan peran node saat ini baik yang utama atau pun yang replika.
| Endpoint REST | Kode pengembalian HTTP jika utama | Kode pengembalian HTTP jika replika |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Karena health check yang relevan mengubah responnya jika node tertentu mengubah perannya, health check load balancer dapat menggunakan endpoint untuk menginformasikan perutean traffic node utama dan replika. Project Patroni menyediakan konfigurasi template untuk load balancer seperti HAProxy . Load Balancer Jaringan passthrough internal dapat menggunakan health check yang sama untuk menyediakan kemampuan serupa.
Proses penggantian
Jika terjadi kegagalan node, cluster akan dibiarkan dalam performa menurun. Proses penggantian Patroni membantu memulihkan cluster dengan HA ke kondisi normal setelah terjadi kegagalan. Proses penggantian mengelola pengembalian cluster ke status awalnya yang secara otomatis menginisialisasi node yang terpengaruh sebagai replika cluster.
Misalnya, node mungkin memulai ulang karena terjadi kegagalan pada sistem operasi atau infrastruktur dasar. Jika node adalah node utama dan memerlukan waktu lebih lama dari TTL kunci pemimpin untuk dimulai ulang, pemilihan pemimpin akan dipicu dan node utama yang baru akan dipilih dan dipromosikan. Saat proses Patroni utama yang sudah lama dimulai, proses ini mendeteksi bahwa tidak ada kunci pemimpin yang secara otomatis mendemosikan dirinya menjadi replika, dan bergabung dengan cluster dalam kapasitas tersebut.
Jika terdapat kegagalan node yang tidak dapat dipulihkan, seperti kegagalan zona yang jarang terjadi, Anda perlu memulai node baru. Operator database dapat secara otomatis memulai node baru atau Anda dapat menggunakan stateful grup instance terkelola (MIG) regional dengan jumlah node minimum untuk proses secara otomatis. Setelah node baru dibuat, Patroni mendeteksi bahwa node baru tersebut merupakan bagian dari cluster yang ada dan secara otomatis melakukan inisialisasi node sebagai replika.
HA menggunakan ekstensi dan layanan pg_auto_failover
pg_auto_failover adalah ekstensi PostgreSQL open source (lisensi PostgreSQL) yang dikembangkan secara aktif. pg_auto_failover mengonfigurasi arsitektur HA dengan memperluas kemampuan PostgreSQL yang sudah ada. pg_auto_failover tidak memiliki dependensi apa pun selain PostgreSQL.
Untuk menggunakan ekstensi pg_auto_failover dengan arsitektur HA, Anda memerlukan setidaknya
tiga node, yang masing-masing menjalankan PostgreSQL dengan ekstensi diaktifkan. Salah satu
node dapat gagal tanpa memengaruhi waktu beroperasi grup database. Kumpulan
node yang dikelola oleh pg_auto_failover disebut formation. Diagram
berikut menunjukkan arsitektur pg_auto_failover.
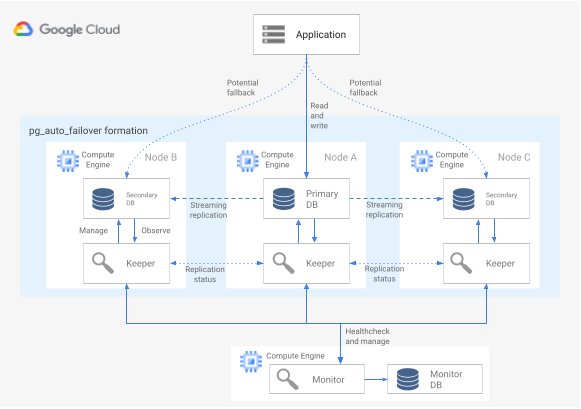
Gambar 6. Diagram arsitektur pg_auto_failover.
Gambar 6 menunjukkan arsitektur pg_auto_failover yang terdiri dari dua komponen utama: layanan Monitor dan agen Keeper. Baik Keeper dan Monitor terdapat dalam ekstensi pg_auto_failover.
Layanan Monitor
Layanan pg_auto_failover Monitor diimplementasikan sebagai ekstensi PostgreSQL; ketika layanan membuat node Monitor, layanan tersebut akan mulai instance PostgreSQL dengan ekstensi pg_auto_failover yang diaktifkan. Monitor mempertahankan status global untuk formasi, memperoleh status health check dari node data PostgreSQL anggota , dan mengorkestrasi grup menggunakan aturan yang ditetapkan dengan (FSM) mesin status terbatas. Sesuai dengan aturan FSM untuk transisi status, Monitor mengomunikasikan petunjuk pada node grup untuk tindakan seperti mempromosikan, mendemonstrasikan, dan mengubah konfigurasi.
Agen Keeper
Pada setiap node data pg_auto_failover data node, ekstensi memulai proses agen Keeper. Proses Keeper ini mengamati dan mengelola layanan PostgreSQL. Keeper mengirim status pembaruan ke node Monitor, dan menerima serta menjalankan tindakan yang dikirim Monitor sebagai respons.
Secara default, pg_auto_failover menyiapkan semua node data sekunder grup sebagai
replika sinkron. Jumlah replika sinkron yang diperlukan untuk commit
didasarkan pada konfigurasi number_sync_standby yang Anda tetapkan pada
Monitor.
Deteksi kegagalan
Agen Keeper pada node data utama dan sekunder terhubung secara berkala ke node Monitor untuk mengomunikasikan statusnya saat ini, dan memeriksa apakah ada tindakan yang akan dijalankan. Node Monitor juga terhubung ke node data untuk melakukan health check dengan menjalankan panggilan API protokol PostgreSQL (libpq), meniru aplikasi klien PostgreSQL pg_isready(). Jika kedua tindakan tersebut tidak berhasil setelah beberapa waktu (30 detik secara default), node Monitor akan menentukan bahwa terjadi kegagalan node data. Anda dapat mengubah setelan konfigurasi PostgreSQL untuk menyesuaikan waktu pemantauan dan jumlah percobaan ulang. Untuk informasi selengkapnya, lihat Failover dan fault tolerance.
Jika terjadi kegagalan node tunggal, salah satu hal berikut berlaku:
- Jika node data yang tidak responsif adalah node utama, Monitor akan memulai failover.
- Jika node data yang tidak responsif adalah node sekunder, Monitor akan menonaktifkan replikasi sinkron untuk node yang tidak responsif.
- Jika node yang gagal adalah node Monitor, failover otomatis tidak dapat dilakukan. Untuk menghindari titik tunggal kegagalan ini, Anda perlu untuk memastikan pemantauan dan pemulihan dari bencana (disaster recovery) yang tepat sudah diterapkan.
Diagram berikut menunjukkan skenario kegagalan dan status hasil formasi yang dijelaskan dalam daftar sebelumnya.
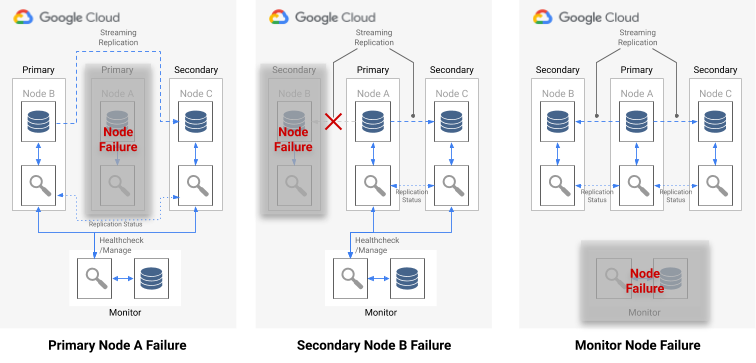
Gambar 7. Diagram skenario kegagalan pg_auto_failover.
Proses failover
Setiap node database dalam grup memiliki opsi konfigurasi berikut yang menentukan proses failover:
replication_quorum: opsi boolean. Jikareplication_quorumditetapkan ketrue, kemudian node dianggap sebagai kandidat failover potensial.candidate_priority: nilai bilangan bulat antara 0 sampai 100.candidate_prioritymemiliki nilai default 50 yang dapat Anda ubah untuk memengaruhi prioritas failover. Node diprioritaskan sebagai kandidat failover berdasarkan nilaicandidate_priority. Node yang memiliki nilaicandidate_prioritylebih tinggi memiliki prioritas lebih tinggi. Proses failover mengharuskan setidaknya dua node memiliki prioritas kandidat bukan nol pada formasi pg_auto_failover.
Jika terjadi kegagalan pada node utama, node sekunder dianggap untuk
dipromosikan ke utama jika memiliki replikasi sinkron yang aktif dan jika node tersebut
merupakan anggota replication_quorum.
Node sekunder dipertimbangkan untuk dipromosikan sesuai dengan kriteria progresif berikut:
- Node dengan prioritas kandidat tertinggi
- Standby dengan posisi log WAL paling canggih yang dipublikasikan ke Monitor
- Pilihan acak sebagai tie-break terakhir
Kandidat failover adalah kandidat yang mengalami keterlambatan jika belum memublikasikan posisi LSN paling canggih pada WAL. Dalam skenario ini, orkestrasi pg_auto_failover mengatur langkah perantara dalam mekanisme failover: kandidat yang terlambat mengambil byte WAL yang hilang dari node standby yang memiliki posisi LSN paling canggih. Node standby kemudian dipromosikan. Postgres memungkinkan operasi ini karena replikasi beruntun memungkinkan standby apa pun bekerja sebagai node upstream untuk standby lain.
Pemilihan rute kueri
pg_auto_failure tidak menyediakan kemampuan perutean kueri sisi server apa pun.
Sebagai gantinya, pg_auto_failure mengandalkan pemilihan rute kueri sisi klien yang menggunakan libpq driver klien PostgreSQL resmi.
Saat Anda menentukan URI koneksi, driver dapat menerima beberapa host dalam
kata kunci host.
Library klien yang digunakan aplikasi Anda harus menggabungkan libpq atau mengimplementasikan kemampuan untuk menyediakan beberapa host bagi arsitektur guna mendukung failover yang sepenuhnya otomatis.
Proses penggantian dan peralihan
Saat proses Keeper memulai ulang node yang gagal atau memulai node pengganti baru, proses tersebut akan memeriksa node Monitor untuk menentukan tindakan berikutnya yang akan dilakukan. Jika node yang gagal dan dimulai ulang sebelumnya adalah node utama, dan Monitor telah memilih node utama baru sesuai dengan proses failover, Keeper akan menginisialisasi ulang node utamayang sudah lama sebagai replika sekunder.
pg_auto_failure menyediakan alat pg_autoctl, yang memungkinkan Anda menjalankan peralihan
untuk menguji proses failover node. Selain memungkinkan operator menguji penyiapan
HA mereka dalam produksi, alat ini membantu Anda memulihkan cluster dengan HA kembali ke
status responsif setelah failover.
HA menggunakan MIG stateful dan persistent disk regional
Bagian ini menjelaskan pendekatan HA yang menggunakan komponen Google Cloud berikut:
- persistent disk regional. Jika Anda menggunakan persistent disk regional, data direplikasi secara sinkron antara dua zona dalam satu region, sehingga Anda tidak perlu untuk menggunakan replikasi streaming. Namun, HA dibatasi tepat hingga dua zona dalam satu region.
- Grup instance terkelola stateful. Sepasang MIG stateful digunakan sebagai bagian dari bidang kontrol untuk menjaga satu node PostgreSQL utama tetap berjalan. Saat MIG stateful memulai instance baru, MIG dapat memasang persistent disk regional yang sudah ada. Pada suatu saat, hanya satu dari dua MIG yang akan memiliki instance yang sedang berjalan.
- Cloud Storage. Objek dalam bucket Cloud Storage berisi konfigurasi yang menunjukkan yang mana dari dua MIG yang menjalankan node database utama dan MIG mana yang instance failover harus dibuat.
- Health check dan autohealing MIG. Health check memantau kondisi instance. Jika node yang berjalan menjadi tidak responsif, health check akan memulai proses autohealing.
- Logging. Saat autohealing menghentikan node utama, entri dicatat di Logging. Entri log terkait diekspor ke topik sink Pub/Sub menggunakan filter.
- Cloud Run Functions berbasis peristiwa. Pesan Pub/Sub memicu fungsi Cloud Run. Fungsi Cloud Run menggunakan konfigurasi di Cloud Storage untuk menentukan tindakan yang harus diambil untuk setiap MIG stateful.
- Load Balancer jaringan passthrough internal. Load balancer menyediakan perutean ke instance yang berjalan dalam grup. Hal ini memastikan bahwa perubahan alamat IP instance yang disebabkan oleh pembuatan ulang instance diabstraksi dari klien.
Diagram berikut menunjukkan contoh HA yang menggunakan MIG stateful dan persis disk regional:

Gambar 8. Diagram HA yang menggunakan MIG stateful dan persistent disk regional.
Gambar 8 menunjukkan node Primary responsif yang melayani traffic klien. Klien terhubung dengan alamat IP statis Load Balancer jaringan passthrough. Load balancer merutekan permintaan klien ke VM yang berjalan sebagai bagian dari MIG. Volume data disimpan di persistent disk regional yang terpasang.
Untuk menerapkan pendekatan ini, buat image VM dengan PostgreSQL yang dimulai saat inisialisasi digunakan sebagai template instance MIG. Anda juga harus mengonfigurasi health check berbasis HTTP (seperti HAProxy atau pgDoctor) pada node. Health check berbasis HTTP membantu memastikan bahwa baik load balancer dan grup instance dapat menentukan kondisi node PostgreSQL.
Persistent disk regional
Untuk menyediakan perangkat block storage yang menyediakan replikasi data sinkron antara dua zona dalam satu region, Anda dapat menggunakan opsi penyimpanan persistent disk regional Compute Engine. Persistent disk regional dapat menyediakan elemen penyusun dasar bagi Anda untuk menerapkan opsi HA PostgreSQL yang tidak mengandalkan replikasi streaming bawaan PostgreSQL.
Jika instance VM node utama Anda tidak tersedia karena kegagalan infrastruktur atau pemadaman zona, Anda dapat memaksa persistent disk regional untuk dipasang ke instance VM di zona pencadangan Anda di region yang sama.
Untuk memasang persistent disk regional ke instance VM pada zona pencadangan, Anda dapat melakukan tindakan sebagai berikut:
- Mempertahankan instance VM mode cold standby di zona pencadangan. Instance VM standby VM merupakan instance VM yang dihentikan dan tidak memiliki Persistent Disk yang terpasang padanya tetapi merupakan instance VM yang identik dengan instance VM node utama. Jika terjadi kegagalan, VM mode cold standby akan dimulai dan persistent disk regional dipasang pada VM tersebut. Instance cold standby dan instance node utama memiliki data yang sama.
- Buat sepasang MIG stateful menggunakan template instance yang sama. MIG menyediakan health check dan layanan sebagai bagian dari bidang kontrol. Jika node utama gagal, instance failover akan dibuat di MIG target secara deklaratif. MIG target ditentukan melalui objek Cloud Storage. Konfigurasi per instance digunakan untuk memasangkan persistent disk regional.
Jika pemadaman layanan data segera diidentifikasi, operasi pemasangan paksa biasanya selesai dalam waktu kurang dari satu menit, sehingga RTO yang diukur dalam menit dapat dicapai.
Jika bisnis Anda dapat menoleransi peiode nonaktif tambahan yang diperlukan agar Anda dapat mendeteksi dan mengomunikasikan pemadaman data, dan Anda harus melakukan failover secara manual, Anda tidak perlu mengotomatiskan proses pemasangan paksa. Jika toleransi RTO lebih rendah, Anda dapat mengotomatiskan proses deteksi dan failover. Atau, Cloud SQL untuk PostgreSQL juga menyediakan implementasi yang terkelola sepenuhnya dari pendekatan HA ini.
Deteksi kegagalan dan proses failover
Pendekatan HA menggunakan kemampuan autohealing grup instance untuk memantau kondisi node menggunakan health check. Jika ada health check yang gagal, instance yang ada dianggap tidak responsif, dan instance akan dihentikan. Perhentian ini memulai proses failover menggunakan logging, Pub/Sub, dan fungsi Cloud Run yang dipicu.
Untuk memenuhi persyaratan bahwa VM ini selalu memasang disk regional, satu dari dua MIG akan dikonfigurasi oleh fungsi Cloud Run untuk membuat instance di salah satu dari dua zona tempat persistent disk regional tersedia. Jika terjadi kegagalan node, instance pengganti akan dimulai, sesuai dengan status yang dipertahankan di Cloud Storage, pada zona alternatif.

Gambar 9. Diagram kegagalan zona pada MIG.
Pada gambar 9, node utama sebelumnya di Zona A mengalami kegagalan dan fungsi Cloud Run telah mengonfigurasi MIG B untuk meluncurkan instance utama baru di Zona B. Mekanisme deteksi kegagalan secara otomatis dikonfigurasi untuk memantau keadaan node utama baru.
Pemilihan rute kueri
Load Balancer jaringan passthrough mengarahkan klien ke instance yang menjalankan layanan PostgreSQL. Load balancer menggunakan health check yang sama dengan grup instance untuk menentukan instance tersedia atau tidak untuk kueri layanan. Jika node tidak tersedia karena sedang dibuat ulang, koneksi akan gagal. Setelah instance dicadangkan health checks mulai diteruskan dan koneksi baru akan dirutekan ke node yang tersedia. Tidak ada node hanya baca dalam penyiapan ini karena hanya ada satu node yang berjalan.
Proses penggantian
Jika node database gagal dalam health check karena masalah hardware yang mendasarinya, node akan dibuat ulang pada instance dasar yang berbeda. Pada saat itu, arsitektur dikembalikan ke status aslinya tanpa langkah tambahan. Namun, jika terjadi kegagalan zona, penyiapan akan terus berjalan dalam keadaan yang menurun hingga zona pertama dipulihkan. Meskipun sangat tidak mungkin, jika terjadi kegagalan serentak pada kedua zona yang dikonfigurasi untuk replikasi Persistent Disk dan MIG stateful, instance PostgreSQL tidak dapat memulihkan–database yang tidak tersedia ke permintaan layanan selama pemadaman data.
Perbandingan antara opsi HA
Tabel berikut menunjukkan perbedaan opsi HA yang tersedia dari Patroni, pg_auto_failover, dan MIG stateful dengan persistent disk regional
Penyiapan dan arsitektur
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
|
Memerlukan arsitektur HA, penyiapan DCS, serta pemantauan dan pemberitahuan. Penyiapan agen pada node data yang relatif mudah. |
Tidak memerlukan dependensi eksternal apa pun selain PostgreSQL. Memerlukan node yang dedikasi sebagai pemantauan. Node monitor memerlukan HA dan DR untuk memastikan bahwa node monitor bukan merupakan titik tunggal kegagalan (SPOF). | Arsitektur secara eksklusif terdiri dari layanan Google Cloud. Anda hanya menjalankan satu node database aktif pada waktu bersamaan. |
Konfigurasi ketersediaan tinggi
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Sangat mudah mengonfigurasi: mendukung untuk replikasi asinkron dan sinkron serta memungkinkan Anda menentukan sinkron dan asinkron. Mencakup pengelolaan otomatis pada node sinkron. Memungkinkan beberapa penyiapan HA zona dan multi-region. DCS harus dapat diakses. | Mirip dengan Patroni: sangat mudah dikonfigurasi. Namun, karena pemantauan hanyatersedia untuk instance tunggal, semua jenis penyiapan perlu untuk mempertimbangkan akses ke node ini. | Dibatasi hingga dua zona dalam satu region dengan replikasi sinkron. |
Kemampuan untuk menangani partisi jaringan
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Pembatasan diri bersama dengan pemantauan level OS menyediakan perlindungan terhadap sistem split brain. Setiap kegagalan untuk terhubung ke DCS akan menyebabkan primer mendemosikan dirinya sendiri ke replika dan memicu failover untuk memastikan ketahanan yang melebihi ketersediaan. | Menggunakan kombinasi health check dari jaringan utama ke pemantauan dan replika untuk mendeteksi partisi jaringan, serta mendemosikan dirinya sendiri jika perlu. | Tidak berlaku: hanya ada satu node PostgreSQL yang aktif pada waktu bersamaan sehingga tidak ada partisi jaringan. |
Biaya
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Biaya tinggi karena bergantung pada DCS yang Anda pilih dan jumlah replika PostgreSQL. Arsitektur Patroni tidak menambahkan biaya yang signifikan. Namun, keseluruhan biaya dipengaruhi oleh infrastruktur yang mendasarinya, yang menggunakan beberapa instance komputasi untuk PostgreSQL dan DCS. Karena menggunakan beberapa replika dan cluster DCS terpisah, opsi ini dapat menjadi yang paling mahal. | Biaya sedang karena melibatkan pengoperasian node monitor dan setidaknya tiga node PostgreSQL (satu utama dan dua replika). | Biaya rendah karena hanya ada satu node PostgreSQL yang aktif berjalan pada waktu tertentu. Anda hanya membayar satu instance komputasi. |
Konfigurasi klien
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Transparan ke klien karena terhubung ke load balancer. | Library klien mengharuskan untuk mendukung beberapa definisi host dalam penyiapan karena library klien sulit ditangani dengan load balancer. | Transparan ke klien karena terhubung ke load balancer. |
Skalabilitas
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Fleksibilitas tinggi dalam mengonfigurasi untuk mendapatkan kompromi skalabilitas dan ketersediaan. Penskalaan operasi baca dapat dilakukan dengan menambahkan lebih banyak replika. | Mirip dengan Patroni: Penskalaan operasi baca dapat dilakukan dengan menambahkan lebih banyak replika. | Skalabilitas terbatas karena hanya memiliki satu node PostgreSQL yang aktif pada satu waktu. |
Otomatisasi inisialisasi node PostgreSQL, pengelolaan konfigurasi
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
Menyediakan alat untuk mengelola konfigurasi PostgreSQL (patronictl
edit-config) dan otomatis menginisialisasi node baru atau node yang dimulai ulang
dalam kluster. Anda dapat menginisialisasi node menggunakan
pg_basebackup atau alat lainnya seperti barman.
|
Secara otomatis menginisialisasi node, tetapi dibatasi hanya untuk menggunakan
pg_basebackup saat menginisialisasi node replika baru.
Pengelolaan konfigurasi terbatas pada konfigurasi terkait pg_auto_failover.
|
Grup instance stateful dengan disk bersama menghilangkan yang dibutuhkan untuk inisialisasi node PostgreSQL. Karena terdapat hanya satu node yang berjalan, manajemen konfigurasi berada pada satu node. |
Kemampuan penyesuaian dan banyak fitur
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
|
Menyediakan antarmuka hook untuk memungkinkan pengguna menentukan tindakan dipanggil pada langkah-langkah utama, seperti saat demosi atau promosi. Kemampuan konfigurasi yang memiliki banyak fitur seperti dukungan untuk berbagai jenis DCS , berbagai cara untuk melakukan inisialisasi replika, dan berbagai cara untuk menyediakan konfigurasi PostgreSQL. Memungkinkan Anda menyiapkan cluster standby yang memungkinkan cluster replika menurun untuk memudahkan migrasi antar-cluster. |
Terbatas karena ini merupakan proyek yang relatif baru. | Tidak berlaku. |
Jatuh tempo
| Patroni | pg_auto_failover | MIG stateful dengan persistent disk regional |
|---|---|---|
| Project ini sudah tersedia sejak tahun 2015 dan digunakan dalam produksi oleh perusahaan besar seperti Zalando dan GitLab. | Project yang relatif baru yang diumumkan pada awal 2019. | Sepenuhnya terdiri dari produk Google Cloud yang tersedia secara umum. |
Praktik Terbaik untuk Pemeliharaan dan Pemantauan
Memelihara dan memantau cluster HA PostgreSQL Anda sangat penting untuk memastikan ketersediaan tinggi, integritas data, dan performa yang optimal. Bagian berikut memberikan beberapa praktik terbaik untuk memantau dan mengelola cluster HA PostgreSQL.
Melakukan pencadangan dan pengujian pemulihan secara rutin
Cadangkan database PostgreSQL Anda secara rutin dan uji proses pemulihan. Tindakan ini membantu memastikan integritas data dan meminimalkan periode nonaktif jika terjadi penghentian layanan. Uji proses pemulihan untuk memvalidasi pencadangan dan mengidentifikasi potensi masalah sebelum pemadaman terjadi.
Memantau server PostgreSQL dan jeda replikasi
Pantau server PostgreSQL Anda untuk memverifikasi bahwa server tersebut berjalan. Pantau
jeda replikasi antara node utama dan replika. Keterlambatan yang berlebihan dapat menyebabkan
inkonsistensi data dan peningkatan kehilangan data jika terjadi failover. Siapkan pemberitahuan untuk peningkatan latensi yang signifikan dan selidiki akar masalahnya dengan segera.
Menggunakan tampilan seperti pg_stat_replication dan pg_replication_slots dapat membantu
Anda memantau jeda replikasi.
Mengimplementasikan penggabungan koneksi
Penggabungan koneksi dapat membantu Anda mengelola koneksi database secara efisien. Penggabungan koneksi membantu mengurangi overhead pembuatan koneksi baru, yang meningkatkan performa aplikasi dan stabilitas server database. Alat seperti PGBouncer dan Pgpool-II dapat menyediakan penggabungan koneksi untuk PostgreSQL.
Mengimplementasikan pemantauan komprehensif
Untuk mendapatkan insight tentang cluster HA PostgreSQL, buat sistem pemantauan yang andal sebagai berikut:
- Pantau metrik PostgreSQL dan sistem utama, seperti penggunaan CPU, penggunaan memori, I/O disk, aktivitas jaringan, dan koneksi aktif.
- Kumpulkan log PostgreSQL, termasuk log server, log WAL, dan log autovacuum, untuk analisis mendalam dan pemecahan masalah.
- Gunakan alat dan dasbor pemantauan untuk memvisualisasikan metrik dan log guna mengidentifikasi masalah dengan cepat.
- Integrasikan metrik dan log dengan sistem pemberitahuan untuk notifikasi proaktif tentang potensi masalah.
Untuk informasi selengkapnya tentang cara memantau instance Compute Engine, lihat ringkasan Cloud Monitoring.
Langkah selanjutnya
- Baca konfigurasi ketersediaan tinggi Cloud SQL.
- Pelajari tentang Opsi ketersediaan tinggi menggunakan persistent disk regional lebih lanjut.
- Baca tentang Patroni.
- Baca tentang pg_auto_failover.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis: Alex Cârciu | Solutions Architect