Halaman ini merupakan ringkasan konfigurasi ketersediaan tinggi (HA) untuk instance Cloud SQL. Untuk mengonfigurasi instance baru untuk HA, atau untuk mengaktifkan HA pada instance yang ada, lihat Mengaktifkan dan menonaktifkan ketersediaan tinggi pada instance.
Ringkasan konfigurasi HA
Tujuan konfigurasi HA adalah untuk mengurangi periode nonaktif saat zona atau instance menjadi tidak tersedia. Hal ini dapat terjadi selama pemadaman layanan berdasarkan zona, atau saat ada masalah hardware. Dengan ketersediaan tinggi (HA), data Anda akan tetap tersedia untuk aplikasi klien.
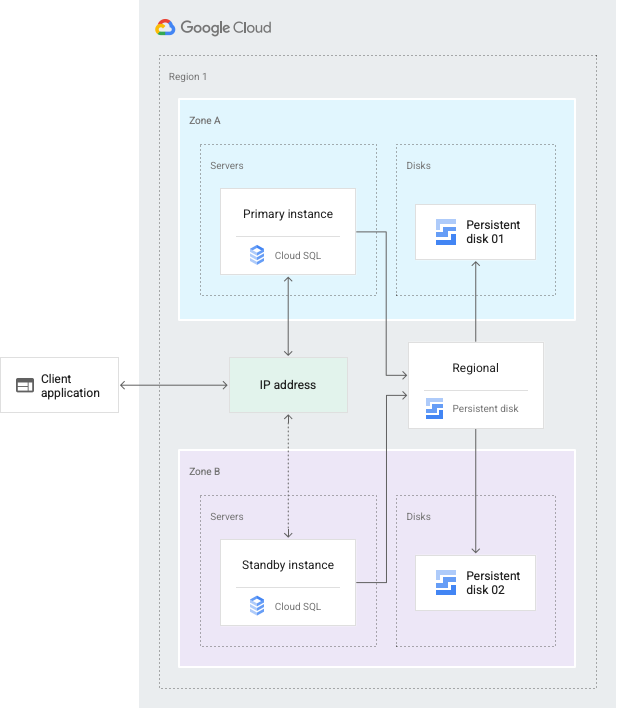
Konfigurasi HA menyediakan redundansi data. Instance Cloud SQL yang dikonfigurasi untuk HA juga disebut instance regionalserta memiliki zona primer dan sekunder dalam region yang dikonfigurasi*. Dalam instance regional, konfigurasi terdiri dari instance utama dan instance standby. Melalui replikasi sinkron ke persistent disk setiap zona, semua penulisan yang dibuat ke instance utama direplikasi ke disk di kedua zona sebelum transaksi dilaporkan sudah di-commit. Jika terjadi kegagalan instance atau zona, instance standby akan menjadi instance primer baru. Pengguna kemudian dialihkan ke instance primer baru. Proses ini disebut failover.
Setelah failover, instance yang menerima failover akan tetap menjadi instance primer, bahkan setelah instance aslinya kembali online. Setelah zona atau instance yang mengalami pemadaman tersedia lagi, instance primer yang asli akan dihilangkan dan dibuat ulang. Lalu menjadi instance standby baru. Jika nanti terjadi failover, instance baru akan beralih ke instance asli di zona asli.
Jika harus memiliki instance primer di zona yang mengalami pemadaman, Anda dapat melakukan failback. Langkah-langkah failback sama seperti failover, hanya berlawanan arah, untuk mengalihkan traffic kembali ke instance awal. Untuk melakukan failover, ikuti prosedur dalam Memulai failover.
Dukungan persistent disk regional untuk konfigurasi HA Cloud SQL yang memiliki setidaknya satu CPU khusus yang memiliki cakupan Perjanjian Tingkat Layanan (SLA) lengkap. Instance dengan konfigurasi HA dikenai biaya dua kali lebih besar dibandingkan instance mandiri. Harga ini sudah termasuk CPU, RAM, dan penyimpanan. Untuk informasi selengkapnya, lihat halaman harga.
* Untuk mengetahui informasi selengkapnya tentang pertimbangan khusus wilayah, lihat Geografi dan wilayah.
Replika baca
Jika ketersediaan menjadi pertimbangan untuk replika baca, Anda dapat mengaktifkan HA pada replika. Ketika Anda mempromosikan replika tersebut untuk menjadi instance primer, replika tersebut sudah disiapkan sebagai instance yang sangat tersedia
Selama pemadaman layanan di zona tertentu, traffic akan berhenti untuk membaca replika di zona tersebut. Setelah zona tersedia kembali, semua replika baca di zona tersebut melanjutkan replikasisi dari instance primer. Jika replika baca tidak berada di zona yang mengalami pemadaman, replika tersebut akan terhubung ke instance standby saat menjadi instance primer.
Sebagai praktik terbaik, sebaiknya Anda menempatkan beberapa replika baca Anda di zona yang berbeda dengan instance primer dan instance standby. Misalnya, jika Anda memiliki instance primer di zona A dan instance standby di zona B, masukkan replika baca di zona C untuk meningkatkan keandalan Anda. Praktik ini memastikan bahwa replika baca akan terus beroperasi meskipun zona untuk instance primer menurun. Anda juga harus menambahkan logika bisnis dalam aplikasi klien untuk mengirim operasi baca ke instance primer saat replika baca tidak tersedia.
Ringkasan failover
Jika instance yang dikonfigurasi dengan HA menjadi tidak responsif, Cloud SQL akan otomatis beralih ke sajian data dari instance standby. Untuk mengetahui apakah failover muncul, periksa histori failover log operasi Anda.
Pelajari lebih lanjut cara membuat kueri di Logs Explorer. Jika memerlukan informasi operasi yang lebih mendetail, tentang pengguna yang melakukan operasi, Anda harus mengaktifkan logging audit.
Klik tab untuk melihat pengaruh failover terhadap instance Anda.
Normal

Failover

Pasca-Failover

Failback
Proses
Proses berikut akan terjadi:
Instance primer atau zona gagal.
Setiap detik, sistem heartbreak mendeteksi apakah instance primer responsif. Jika beberapa heartbreak tidak terdeteksi, failover akan dimulai.
Instance standby kini menyalurkan data setelah terhubung kembali.
Melalui alamat IP statis bersama dengan instance primer, instance standby kini menyalurkan data dari zona sekunder.
Persyaratan
Agar Cloud SQL mengizinkan failover, konfigurasi harus memenuhi persyaratan berikut:
- Instance primer harus dalam status operasi normal (tidak dihentikan, sedang berjalan, atau melakukan operasi instance Cloud SQL yang berjalan lama, seperti operasi pencadangan).
- Zona sekunder dan instance standby keduanya harus dalam status responsif. Jika instance standby tidak responsif, operasi failover akan diblokir. Setelah Cloud SQL memperbaiki instance standby dan zona sekunder tersedia, Cloud SQL akan mengizinkan failover.
Pencadangan dan pemulihan
Pencadangan otomatis sangat direkomendasikan untuk ketersediaan tinggi.
Opsi pemulihan untuk instance mandiri
Cloud SQL tidak memulihkan instance mandiri dari pemadaman layanan zona secara otomatis. Untuk memulihkan instance yang tidak dikonfigurasi untuk ketersediaan tinggi ke zona yang sehat, Anda harus memulihkan instance zona secara manual. Anda dapat memulihkan instance mandiri dari gangguan zonal secara manual menggunakan salah satu opsi berikut:
Lakukan pemulihan point-in-time pada instance ke instance baru yang Anda buat. Untuk menggunakan opsi ini, Anda harus mengaktifkan PITR di instance zona sebelum terjadinya gangguan zona. Log transaksi untuk instance harus disimpan di Cloud Storage. Jika log transaksi disimpan di disk, Anda dapat mengalihkannya ke Cloud Storage. Untuk menggunakan opsi ini, ikuti langkah-langkah di Melakukan PITR pada instance yang tidak tersedia.
Jika instance memiliki replika baca di zona lain, Anda dapat mempromosikan replika baca tersebut untuk menggantikan instance mandiri yang mengalami pemadaman layanan zona. Untuk menggunakan opsi ini, ikuti langkah-langkah di Mempromosikan replika
Untuk kedua opsi, pertimbangan berikut berlaku:
Beberapa transaksi terbaru yang di-commit pada instance utama mungkin tidak muncul di instance yang baru dipulihkan. Interval waktu saat transaksi mungkin hilang adalah toleransi durasi kehilangan data (RPO).
- Untuk pemulihan PITR, RPO biasanya lima menit atau kurang.
- Untuk promosi replika baca, RPO bervariasi berdasarkan beban kerja database. Untuk mengetahui informasi selengkapnya tentang cara memantau dan mengurangi jeda replikasi, lihat Jeda replikasi.
Setelah melakukan salah satu opsi pemulihan, Anda harus mengonfigurasi ulang klien instance yang mengalami gangguan zonal karena instance yang dipulihkan akan memiliki alamat IP dan nama koneksi yang berbeda.
Aplikasi dan instance
Tidak ada perbedaan dalam menangani instance non-HA dan HA, sehingga aplikasi Anda tidak perlu dikonfigurasi dengan cara tertentu. Saat terjadi failover, semua koneksi yang ada ke instance primer dan replika baca akan ditutup, dan diperlukan waktu sekitar 60 detik agar koneksi ke instance primer terhubung kembali. Aplikasi Anda terhubung kembali menggunakan string koneksi atau alamat IP yang sama, sehingga Anda tidak perlu mengupdate aplikasi setelah failover.
Untuk melihat lebih tepat cara aplikasi Anda terpengaruh oleh failover, mulai failover secara manual.
Periode nonaktif untuk pemeliharaan
Peristiwa pemeliharaan memengaruhi instance primer yang dikonfigurasi dengan HA dengan cara yang sama seperti instance lainnya. Anda dapat memperkirakan bahwa instance primer dapat mengalami gangguan dalam jangka waktu yang singkat. Untuk mengetahui informasi selengkapnya tentang pengaruh pemeliharaan terhadap instance HA, baca Cara kerja pemeliharaan. Untuk meminimalkan dampak terhadap layanan Anda, ubah setelan pemeliharaan untuk mengontrol kapan periode nonaktif terjadi.
Langkah berikutnya
- Mengaktifkan dan menonaktifkan ketersediaan tinggi pada instance.
- Mulai failover.
- Pelajari lebih lanjut cara mengelola koneksi database.
- Pelajari region dan zona lebih lanjut di Cloud SQL.