arquitetura do sistema.
As Unidades de Processamento de Tensor (TPUs) são circuitos integrados de aplicação específica (ASICs, na sigla em inglês) projetados pelo Google para acelerar as cargas de trabalho de machine learning. O Cloud TPU é um serviço do Google Cloud que disponibiliza TPUs como um recurso escalonável.
As TPUs são projetadas para executar operações de matriz rapidamente, tornando-as ideais para cargas de trabalho de machine learning. É possível executar cargas de trabalho de machine learning em TPUs usando frameworks como TensorFlow, Pytorch e JAX.
Termos do Cloud TPU
Se você ainda não conhece os Cloud TPUs, confira a página inicial da documentação da TPU. Confira nas seções abaixo os termos e conceitos relacionados usados neste documento.
Inferência em lote
Inferência em lote ou off-line refere-se a inferência fora dos pipelines de produção, normalmente em uma massa de entradas. A inferência em lote é usada para tarefas off-line, como rotulagem de dados, e para avaliação do modelo treinado. SLOs de latência não são uma prioridade para inferência em lote.
Ícone de TPU
Um chip de TPU contém um ou mais TensorCores. O número de TensorCores depende da versão do chip da TPU. Cada TensorCore consiste em uma ou mais unidades de multiplicação de matriz (MXUs, na sigla em inglês), uma unidade vetorial e uma unidade escalar.
Uma MXU é composta por acumuladores múltiplos de 128 x 128 em uma matriz sistólica. As MXUs fornecem a maior parte do poder de computação em um TensorCore. Cada MXU é capaz de realizar 16 mil operações de multiplicação e acumulação por ciclo. Todas as multiplicações recebem entradas bfloat16, mas todas as acumulações são realizadas no formato de número FP32.
A unidade de vetor é usada para computação geral, como ativações e softmax. A unidade escalar é usada para fluxo de controle, cálculo de endereços de memória e outras operações de manutenção.
cubo de TPU
Uma topologia 4x4x4. Isso é aplicável apenas a topologias 3D (a partir da versão v4 da TPU).
Inferência
Inferência é o processo de usar um modelo treinado para fazer previsões sobre novos dados. Ele é usado pelo processo de disponibilização.
Fatia múltipla versus fração única
Multislice é um grupo de frações que estende a conectividade da TPU para além das conexões de interconexão entre chips (ICI, na sigla em inglês) e aproveita a rede de data center (DCN, na sigla em inglês) para transmitir dados além de uma fração. Os dados dentro de cada fração ainda são transmitidos pelo ICI. Ao usar essa conectividade híbrida, o Multislice permite paralelismo entre fatias e permite usar um número maior de núcleos de TPU para um único job do que uma única fração pode acomodar.
As TPUs podem ser usadas para executar um job em uma única fração ou em várias frações. Consulte a Introdução ao recurso multislice para mais detalhes.
Resiliência de ICI do Cloud TPU
A resiliência de ICI ajuda a melhorar a tolerância a falhas de links ópticos e chaves de circuito óptico (OCS, na sigla em inglês) que conectam TPUs entre cubos. As conexões ICI dentro de um cubo usam elos de cobre que não são afetados. A resiliência da ICI permite que as conexões da ICI sejam roteadas em torno das falhas de OCS e ICI ópticas. Como resultado, ele melhora a disponibilidade de programação de fatias de TPU, com a compensação da degradação temporária no desempenho do ICI.
Semelhante ao Cloud TPU v4, a resiliência de ICI é ativada por padrão para frações v5p que têm um cubo ou maior:
- v5p-128 ao especificar o tipo de acelerador.
- 4x4x4 ao especificar a configuração do acelerador
Recurso na fila
Uma representação de recursos de TPU, usada para enfileirar e gerenciar uma solicitação para um ambiente de TPU de uma ou várias fatias. Consulte o Guia do usuário de Recursos na fila para mais informações.
Disponibilização
Exibição é o processo de implantação de um modelo de machine learning treinado em um ambiente de produção onde ele pode ser usado para fazer previsões ou tomar decisões. A latência e a disponibilidade no nível de serviço são importantes para a exibição.
Host único e vários hosts
Um host de TPU é uma VM executada em um computador físico conectado a um hardware de TPU. As cargas de trabalho de TPU podem usar um ou mais hosts.
Uma carga de trabalho de host único é limitada a uma VM de TPU. Uma carga de trabalho de vários hosts distribui o treinamento entre várias VMs de TPU.
Frações
Uma fração de pod é uma coleção de chips todos localizados dentro do mesmo pod de TPU conectado por interconexões entre chips (ICI) de alta velocidade. As frações são descritas em termos de chips ou TensorCores, dependendo da versão da TPU.
A forma do chip e a topologia do chip também se referem a formas de fatia.
SparseCore
O v5p inclui quatro SparseCores por chip, que são processadores do Dataflow que aceleram modelos que dependem de embeddings encontrados em modelos de recomendação.
Pod de TPU
Um pod de TPU é um conjunto contíguo de TPUs agrupadas em uma rede especializada. O número de chips de TPU em um pod de TPU depende da versão da TPU.
VM ou worker da TPU
Uma máquina virtual executando Linux que tem acesso às TPUs subjacentes. Uma VM de TPU também é conhecida como worker.
TensorCores
Os chips de TPU têm um ou dois TensorCores para executar a multiplicação de matrizes. Para mais informações sobre o TensorCores, consulte este artigo do ACM.
intelectual
Consulte VM da TPU.
Versões de TPU
A arquitetura exata de um chip de TPU depende da versão da TPU usada. Cada versão de TPU também oferece suporte a diferentes tamanhos e configurações de fatias. Para mais informações sobre a arquitetura do sistema e as configurações compatíveis, consulte as seguintes páginas:
Arquiteturas de VM do Cloud TPU
A forma como você interage com o host e a placa da TPU depende da arquitetura de VM da TPU usada: nós de TPU ou VMs de TPU.
Arquitetura da VM da TPU
A arquitetura da VM da TPU permite a conexão direta à VM conectada fisicamente ao dispositivo TPU usando SSH. Como você tem acesso raiz à VM, pode executar um código arbitrário. É possível acessar os registros de depuração do compilador e do ambiente de execução e as mensagens de erro.

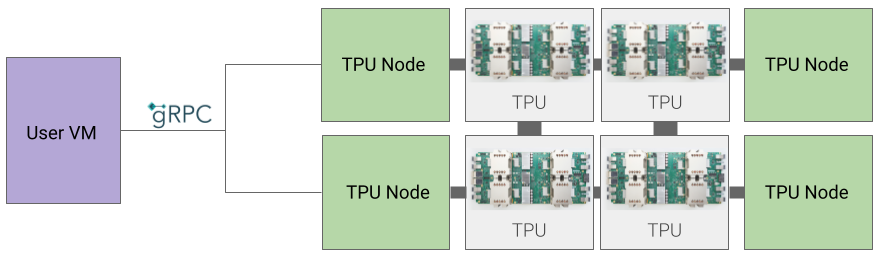
Arquitetura de nó da TPU
A arquitetura do nó da TPU consiste em uma VM de usuário que se comunica com o host da TPU pelo gRPC. Ao usar essa arquitetura, não é possível acessar diretamente o host da TPU, o que dificulta a depuração de erros de treinamento e de TPU.