Notícias e eventos
Notícias e eventos
- Saiba por que o Google foi nomeado líder no Magic Quadrant™ da Gartner® para infraestrutura de IALeia o relatório para saber por que o Hipercomputador de IA está posicionado mais longe em execução e visão.
- Receba as últimas notícias sobre TPUsInscreva-se na nossa lista de e-mails para ser o primeiro a saber sobre novos lançamentos e eventos de TPU.
- Conecte seus desenvolvedores a uma comunidade globalAcabamos de ultrapassar 100 mil membros na nossa comunidade Google Cloud x NVIDIA, o melhor lugar para desenvolvedores se conectarem, compartilharem e aprenderem com seus colegas.
O futuro da infraestrutura de IA
O futuro da infraestrutura de IA
O Hipercomputador de IA é uma arquitetura que combina hardware criado para fins específicos, software aberto e modelos de consumo flexíveis. Cada componente é cuidadosamente integrado para funcionar bem em conjunto, melhorando seu desempenho, custo e produtividade do desenvolvedor.

Treinamento mais rápido e inteligente
Treinamento mais rápido e inteligente
Crie modelos em semanas, não meses. Use a pilha de treinamento do Google para acelerar o desenvolvimento e os testes sem sacrificar o desempenho.

Treine e ajuste LLMs com mais rapidez
Desenvolva LLMs 36% mais rápido e aumente a produtividade em até 97% (Goodput) com cada acelerador usando a TPU 8t com software projetado em parceria com o Google DeepMind e integrado a frameworks de código aberto, do Pathways ao Pallas (treinamento) e do Ray ao Agent Sandbox (ajustes). Também sabemos que cada caso é um caso, por isso trabalhamos em parceria com a NVIDIA para oferecer as GPUs mais recentes. O Google Cloud será um dos primeiros a oferecer instâncias baseadas na NVIDIA Vera Rubin NVL72 de última geração quando ela estiver disponível ainda este ano.
Treine modelos leves de forma mais inteligente usando dados próprios
Use a Gemini Enterprise Agent Platform com o BigQuery para treinar modelos com dados próprios 16 vezes mais rápido combinando seu patrimônio de dados, desenvolvimento de ML e aceleradores em um só lugar. Ambos são alimentados pelo Hipercomputador de IA, seja usando VMs G4 ou TPUs Ironwood.
Crie agentes físicos adaptáveis com o MuJoCo-Warp
Execute simulações baseadas em GPU no MuJoCo-Warp do DeepMind, até 100 vezes mais rápido do que o MuJoCo padrão. Depois, simule casos extremos impossíveis, arriscados ou caros usando mídias sintéticas do Veo, Genie e Nano Banana ou ingira petabytes de dados de sensores do mundo real no BigQuery. Saiba mais sobre como criar agentes físicos no Google Cloud aqui.
Inferência responsiva e eficiente
Inferência responsiva e eficiente
Tenha perfis de modelos validados e software de código aberto e do Google totalmente integrado para aumentar a capacidade de resposta do aplicativo com menos complexidade e desperdício.
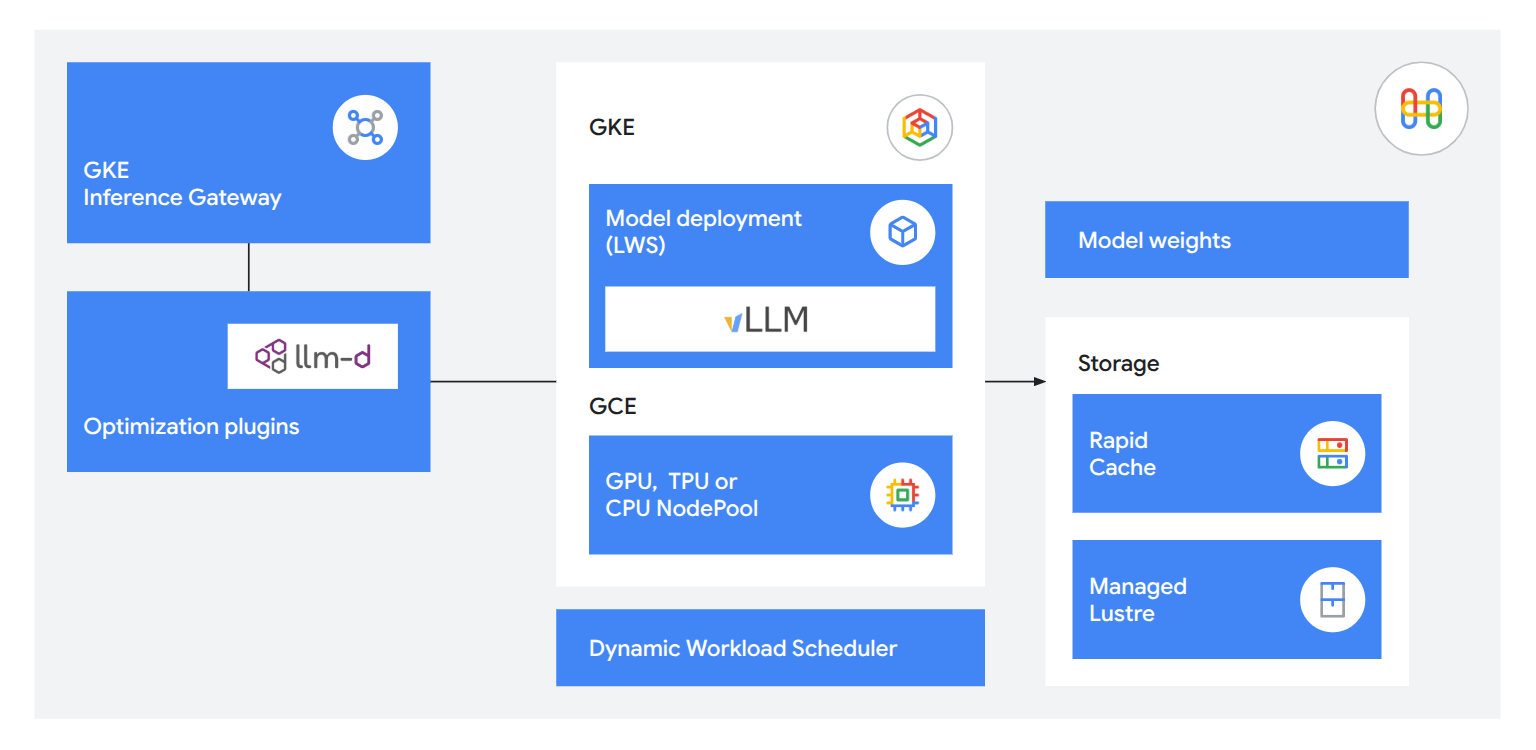
Disponibilize LLMs com quase zero de latência
Use tecnologias de inferência integradas para oferecer serviços úteis e responsivos aos clientes. Reduza o tempo até o primeiro token em 71% com o GKE Inference Gateway, disponibilize até 120 mil tokens por segundo usando o llm-d para disponibilização desagregada e carregue modelos 5 vezes mais rápido usando o Rapid Cache e a TPU 8i para manter sua memória de trabalho exatamente onde ela é necessária.
Disponibilize modelos visuais, de percepção e de mídia pré-criados
Implante modelos de ML clássicos 70% mais rápido usando um dos mais de 200 modelos disponíveis na Gemini Enterprise Agent Platform, usando a TPU ou GPU de sua preferência, incluindo VMs A5X (NVIDIA Vera Rubin) e TPU 8i quando estiverem disponíveis ainda este ano.
Disponibilize agentes com segurança e economia
Disponibilize enxurradas de agentes com segurança no GKE Agent Sandbox, provisionando até 300 sandboxes por segundo e pausando e retomando instantaneamente conforme necessário, para que você nunca pague por agentes inativos.
Operações flexíveis, abertas e confiáveis
Operações flexíveis, abertas e confiáveis
Use qualquer framework ou acelerador em ambientes híbridos e multicloud com manutenção e gerenciamento automatizados de clusters adequados para exaescala.

Alterne entre TPUs e GPUs sem reescrever o código
O TorchTPU elimina a curva de aprendizado da TPU para desenvolvedores ao oferecer suporte nativo ao PyTorch. Assim, é possível usar o melhor acelerador disponível sem precisar reescrever códigos complexos.
Implante a IA em qualquer ambiente e em praticamente qualquer escala
Com base no Kubernetes de código aberto, o GKE oferece portabilidade multicloud com escala empresarial, com suporte para até 130 mil nós e integração nativa com a Agent Platform e o Google Distributed Cloud para implantações híbridas.
Automatize a manutenção de clusters com ferramentas avançadas de diagnóstico e observabilidade
Todos os aceleradores no Hipercomputador de IA são compatíveis com os recursos do Cluster Director, incluindo um relatório de integridade pré-implantação, painéis de observabilidade de 360 graus e verificações de integridade sempre ativas.
Conecte cargas de trabalho multicloud em minutos, não semanas
Conecte serviços em várias nuvens sem conexões lentas usando o Cross-Cloud Network, uma rede de backbone confiável para mais de 65% das empresas da Fortune 100, que movimenta mais de 27 exabytes de dados por mês.
Tenha capacidade de acelerador do seu jeito
Nossos modelos de consumo flexíveis oferecem várias maneiras de programar e reduzir o custo dos aceleradores. Economize até 91% em jobs em lote ou tolerantes a falhas com VMs spot, até 50% em jobs com uma data de início flexível usando o Programador Dinâmico de Cargas de Trabalho e até 50% de desconto ao se inscrever nos descontos por compromisso de uso.
Sistemas prontos para agentes
Sistemas prontos para agentes
Aumente os limites de desempenho e use a energia de forma responsável ao escalonar na base de infraestrutura confiável do Google e dos laboratórios de IA de ponta
Reduza os riscos da sua estratégia de IA com uma base confiável
O Google Cloud oferece suporte a 9 dos 10 principais laboratórios de IA e a 70% das startups de IA financiadas. Ao implantar no Hipercomputador de IA, você usa data centers que processaram de forma confiável mais de 100 bilhões de tokens para quase 350 clientes apenas em dezembro de 2025.
Alcance a eficiência energética líder do setor
Os data centers do Google Cloud, incluindo o Hipercomputador de IA, oferecem eficiência energética líder do setor, com seis vezes mais capacidade computacional por unidade de eletricidade do que há cinco anos. Isso permite que nossa TPU de 8ª geração ofereça uma relação entre preço e desempenho 80% melhor e uma eficiência energética 20% maior do que a geração anterior.
Reduza seu impacto na rede e nas comunidades
Temos compromisso de pagar por 100% da energia usada pelos nossos data centers e por todos os novos custos de infraestrutura diretamente relacionados ao nosso crescimento. Seja nosso parceiro para garantir que, à medida que suas ambições de IA aumentam, as famílias e empresas locais não paguem a conta. Nos próximos anos, vamos financiar novas fontes de energia e infraestrutura para disponibilizar nossos modelos e continuar investindo em fontes de energia alternativas, como energia nuclear avançada, geotérmica e armazenamento de longa duração.
Proteja sua propriedade intelectual mais valiosa, do silício à borda
Nossa arquitetura Titanium com chips Titan personalizados oferece uma raiz de confiança de hardware verificável e segurança de confiança zero. Uma análise independente da cloudvulndb.org mostra que nossos sistemas têm até 70% menos vulnerabilidades críticas do que outras nuvens líderes.
Capacitando os principais inovadores do mundo










Saiba mais sobre o hipercomputador de IA
- IDC: The Business Value of AI Hypercomputer (O valor comercial do Hipercomputador de IA)Este relatório da IDC analisa o impacto real do Hipercomputador de IA para cargas de trabalho de IA. Leia o relatório completo para conferir dados do cliente que ilustram uma melhoria de 353% no ROI, equipes de TI 55% mais eficientes e 67% menos tempo de inatividade não planejado de aplicativos/cargas de trabalho.
Leitura de 5 minutos
Leia o relatório - O Google é líder no Magic Quadrant da Gartner® em serviços estratégicos de plataforma de nuvem.Pelo oitavo ano consecutivo, a Gartner® nomeou o Google como líder no Gartner Magic Quadrant™ para serviços estratégicos de plataforma de nuvem. Este ano, no entanto, marca um grande marco principal: o Google agora está posicionado em primeiro lugar em integridade de visão.
Leitura de 5 minutos
Confira os resultados - Google reconhecido como líder no relatório The Forrester Wave™: AI Infrastructure Solutions, do quarto trimestre de 2025O Google recebeu a maior pontuação de todos os fornecedores na categoria Oferta atual e a pontuação mais alta possível em 16 dos 19 critérios de avaliação, incluindo, entre outros: visão, arquitetura, treinamento, inferência, eficiência e segurança.
Leitura de 5 minutos
Confira os resultados
- Projetar e implantar sua primeira pilha de inferênciaConheça os componentes essenciais que formam uma solução de inferência no Google Cloud, como GKE, Cloud TPUs, TensorFlow, PyTorch, JAX ou Keras.
Curso de 2 horas
Fazer o curso - Usar o vLLM no GKE para disponibilizar a inferência do Gemma 3 27BNeste tutorial, você vai aprender a implantar e disponibilizar um modelo de linguagem grande (LLM) Gemma 3 27B com o framework de disponibilização vLLM. Você implanta o Gemma 3 em uma única instância de máquina virtual (VM) A4 no Google Kubernetes Engine (GKE).
Guia de 15 minutos
Faça o tutorial - Ajustar o Gemma 3 em um cluster do GKE A4Neste tutorial, você vai aprender a ajustar um modelo de linguagem grande (LLM) Gemma 3 em um cluster do GKE com vários nós e GPUs no Google Cloud. Esse cluster usa uma instância de máquina virtual (VM) A4, que tem 8 GPUs NVIDIA B200.
Guia de 15 minutos
Faça o tutorial
- Treinar o Qwen2 em um cluster Slurm A4Neste tutorial, você vai aprender a treinar um modelo de linguagem grande (LLM) em um cluster Slurm de vários nós e várias GPUs no Google Cloud. O modelo que você vai usar neste tutorial é baseado em um modelo Qwen2 de 1,5 bilhão de parâmetros. O cluster Slurm usa duas máquinas virtuais (VMs) a4-highgpu-8g, cada uma com 8 GPUs NVIDIA B200.
Guia de 15 minutos
Faça o tutorial - Disponibilizar o Qwen2-7B-Instruct com o vLLM em TPUsEste tutorial disponibiliza o modelo Qwen/Qwen2-7B-Instruct usando o framework de veiculação de TPU vLLM em uma VM de TPU v6e.
Guia de 15 minutos
Faça o tutorial
- Comece aquiConfira toda a documentação disponível do Hipercomputador de IA, incluindo arquitetura, implantação, gerenciamento, testes e orientações de otimização.Leia toda a documentação
- Recomendações de treinamentoConheça as opções de aceleradores, os modelos de consumo recomendados e os serviços de armazenamento a serem usados no pré-treinamento de modelos.
Leitura de 15 minutos
Leia a documentação - Recomendações de inferênciaConheça as opções de acelerador, os modelos de consumo recomendados e o serviço de armazenamento a ser usado para inferência.
Leitura de 15 minutos
Leia a documentação
Insights de analistas
- IDC: The Business Value of AI Hypercomputer (O valor comercial do Hipercomputador de IA)Este relatório da IDC analisa o impacto real do Hipercomputador de IA para cargas de trabalho de IA. Leia o relatório completo para conferir dados do cliente que ilustram uma melhoria de 353% no ROI, equipes de TI 55% mais eficientes e 67% menos tempo de inatividade não planejado de aplicativos/cargas de trabalho.
Leitura de 5 minutos
Leia o relatório - O Google é líder no Magic Quadrant da Gartner® em serviços estratégicos de plataforma de nuvem.Pelo oitavo ano consecutivo, a Gartner® nomeou o Google como líder no Gartner Magic Quadrant™ para serviços estratégicos de plataforma de nuvem. Este ano, no entanto, marca um grande marco principal: o Google agora está posicionado em primeiro lugar em integridade de visão.
Leitura de 5 minutos
Confira os resultados - Google reconhecido como líder no relatório The Forrester Wave™: AI Infrastructure Solutions, do quarto trimestre de 2025O Google recebeu a maior pontuação de todos os fornecedores na categoria Oferta atual e a pontuação mais alta possível em 16 dos 19 critérios de avaliação, incluindo, entre outros: visão, arquitetura, treinamento, inferência, eficiência e segurança.
Leitura de 5 minutos
Confira os resultados
Tutoriais
- Projetar e implantar sua primeira pilha de inferênciaConheça os componentes essenciais que formam uma solução de inferência no Google Cloud, como GKE, Cloud TPUs, TensorFlow, PyTorch, JAX ou Keras.
Curso de 2 horas
Fazer o curso - Usar o vLLM no GKE para disponibilizar a inferência do Gemma 3 27BNeste tutorial, você vai aprender a implantar e disponibilizar um modelo de linguagem grande (LLM) Gemma 3 27B com o framework de disponibilização vLLM. Você implanta o Gemma 3 em uma única instância de máquina virtual (VM) A4 no Google Kubernetes Engine (GKE).
Guia de 15 minutos
Faça o tutorial - Ajustar o Gemma 3 em um cluster do GKE A4Neste tutorial, você vai aprender a ajustar um modelo de linguagem grande (LLM) Gemma 3 em um cluster do GKE com vários nós e GPUs no Google Cloud. Esse cluster usa uma instância de máquina virtual (VM) A4, que tem 8 GPUs NVIDIA B200.
Guia de 15 minutos
Faça o tutorial
- Treinar o Qwen2 em um cluster Slurm A4Neste tutorial, você vai aprender a treinar um modelo de linguagem grande (LLM) em um cluster Slurm de vários nós e várias GPUs no Google Cloud. O modelo que você vai usar neste tutorial é baseado em um modelo Qwen2 de 1,5 bilhão de parâmetros. O cluster Slurm usa duas máquinas virtuais (VMs) a4-highgpu-8g, cada uma com 8 GPUs NVIDIA B200.
Guia de 15 minutos
Faça o tutorial - Disponibilizar o Qwen2-7B-Instruct com o vLLM em TPUsEste tutorial disponibiliza o modelo Qwen/Qwen2-7B-Instruct usando o framework de veiculação de TPU vLLM em uma VM de TPU v6e.
Guia de 15 minutos
Faça o tutorial
Documentação
- Comece aquiConfira toda a documentação disponível do Hipercomputador de IA, incluindo arquitetura, implantação, gerenciamento, testes e orientações de otimização.Leia toda a documentação
- Recomendações de treinamentoConheça as opções de aceleradores, os modelos de consumo recomendados e os serviços de armazenamento a serem usados no pré-treinamento de modelos.
Leitura de 15 minutos
Leia a documentação - Recomendações de inferênciaConheça as opções de acelerador, os modelos de consumo recomendados e o serviço de armazenamento a ser usado para inferência.
Leitura de 15 minutos
Leia a documentação



















