How to scale AI training to up to tens of thousands of Cloud TPU chips with Multislice
Nisha Mariam Johnson
Product Manager
Andi Gavrilescu
Software Engineering Manager
The largest generative AI models are expected to surpass hundreds of billions of parameters and use trillions of training tokens. These models will require tens of EFLOPs (1018 FLOPs) of AI supercomputing to maintain training times of several weeks or less. Achieving that performance will require tens of thousands of accelerators working efficiently together. But most scaling solutions require sophisticated hand-coding and manual tuning, which result in brittle solutions and sublinear scaling performance.
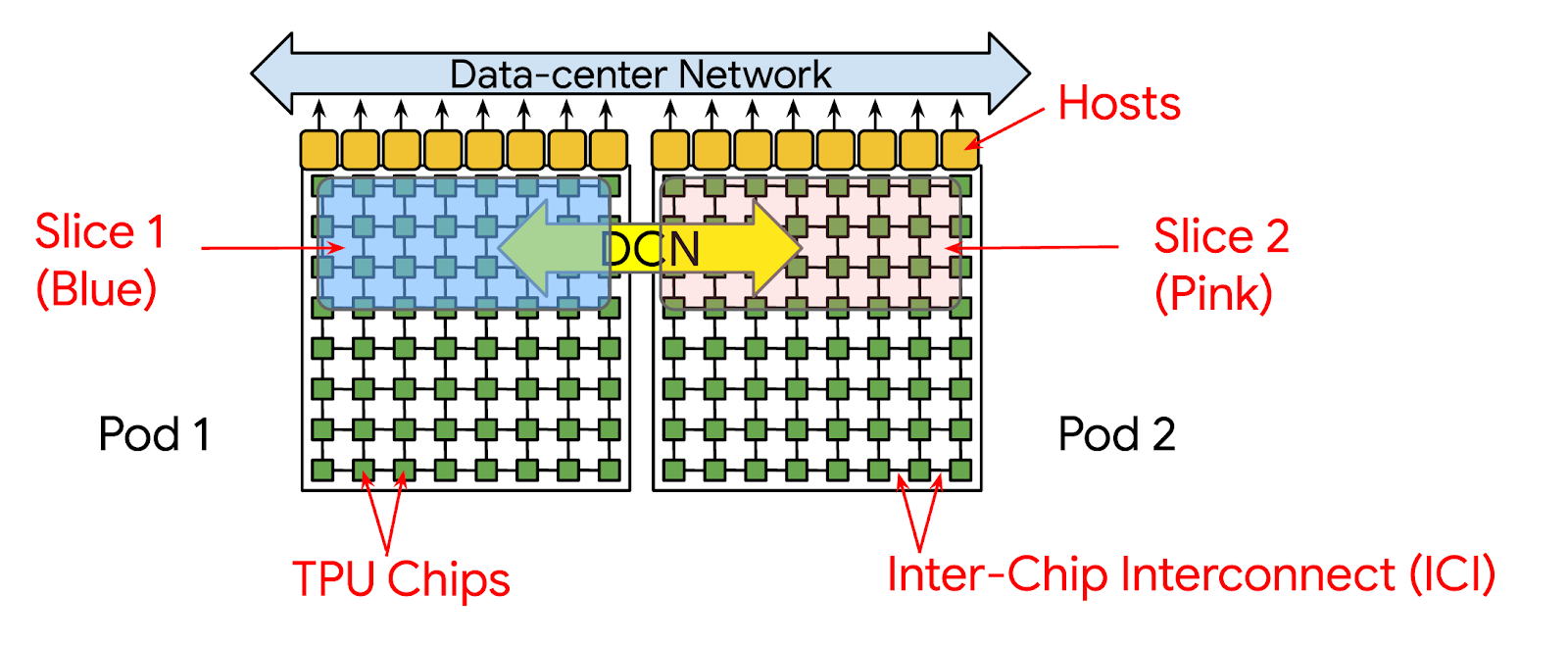
To address this challenge, this week at Google Cloud Next we announced Multislice, a full-stack large-scale training technology that enables easy, cost-effective and near-linear scaling up to tens of thousands of Cloud Tensor Processing Units (TPUs) chips. Historically, a training run could only use a single slice, a reservable collection of chips connected via inter-chip interconnect (ICI). This meant that a run could use no more than 3072 TPU v4 chips, which is currently the largest slice in the largest Cloud TPU system. With Multislice, a training run can scale beyond a single slice and use multiple slices over a number of pods by communicating over data center networking (DCN).
In summary, Multislice can offer the following benefits:
- Train massive models with near-linear scaling performance from single slice to multiple slices with up to tens of thousands of chips
- Enhance developer productivity with simple setup using few code changes
- Save time by leveraging automatic compiler optimizations
- Maximize cost-efficiencies via TPU v5e’s up to 2x higher performance-to-dollar for training LLMs versus TPU v4
- Access up to a 2x to 24x higher peak FLOPs budget versus systems with 8-chip ICI domains with the TPU v5e and TPU v4 respectively
“Google Cloud’s next generation of AI infrastructure including Multislice Cloud TPU v5e will bring incredible price performance benefits for our workloads and we look forward to building the next wave of AI on Google Cloud.”—Tom Brown, Co-Founder, Anthropic
How does Multislice work?
When deployed in Multislice configurations, TPU chips within each slice communicate through high-speed ICI. And, TPU chips across different slices communicate by transferring data over Google Cloud’s Jupiter data center network. For example, when using data parallelism, activations continue to be communicated over ICI, the same as in single slice operation, while gradients are reduced over DCN.
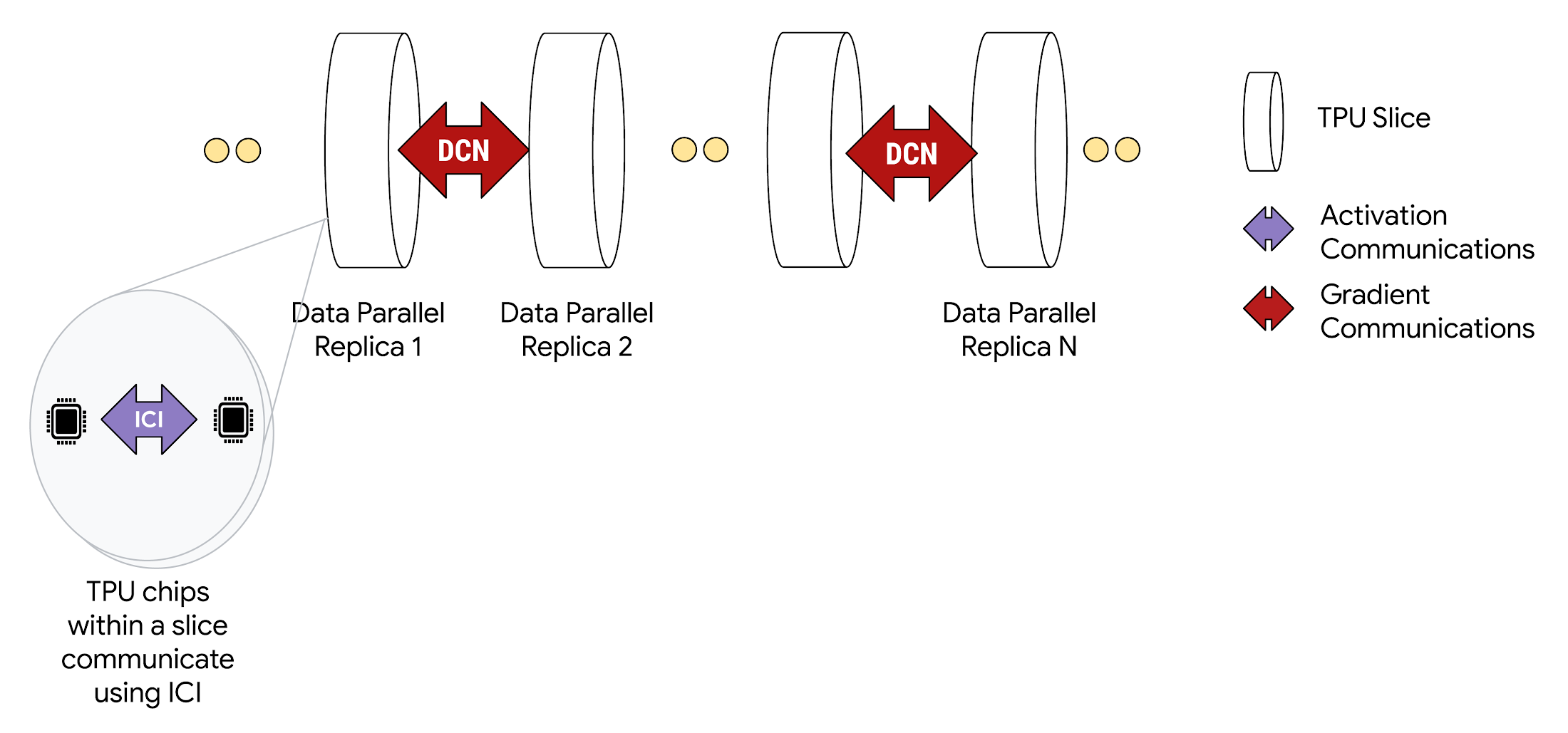
Multislice supports a variety of parallelism techniques to use multiple slices within a single pod or slices in multiple pods in the same training run. Simple data parallelism (DP) should suffice for most models, especially dense decoder or diffusion models, but for larger-scale models or data sizes, Multislice also supports Fully Sharded Data Parallelism (FSDP), model, and pipeline parallelism. Advanced optimizations and sharding strategies are discussed in more detail in the Multislice user guide.
Developers do not write code to implement inter-slice DCN communication. The XLA compiler generates that code and automatically overlaps communication with computation for maximum performance.
Achieve 2x or much higher system scale
Software scaling is limited by hardware. An accelerator system can only scale up to its FLOPs budget. Beyond that, performance is limited by communication bottlenecks. For scaling to be effective, the hardware system itself must support scaling. The Cloud TPU system’s large ICI domains help it achieve as high as 24x higher maximum FLOPs than traditional systems with 8-chip ICI domains, without hitting communication bottlenecks.
To understand the math better, start with the ICI domain. The largest number of chips connected by high-speed ICI is called the system’s ICI domain. The ICI domain for a TPU v4 pod is 3,072 chips and for a TPU v5e pod is 256 chips.
Let’s define P as the peak FLOPs a system can performantly scale to. A dense LLM using DP and FSDP needs a minimum batch size per ICI domain that’s approximately equal to the DCN arithmetic intensity. For these models, the DCN arithmetic intensity approximates to a ratio of per-chip FLOPs to DCN bandwidth per chip. Then, P becomes:
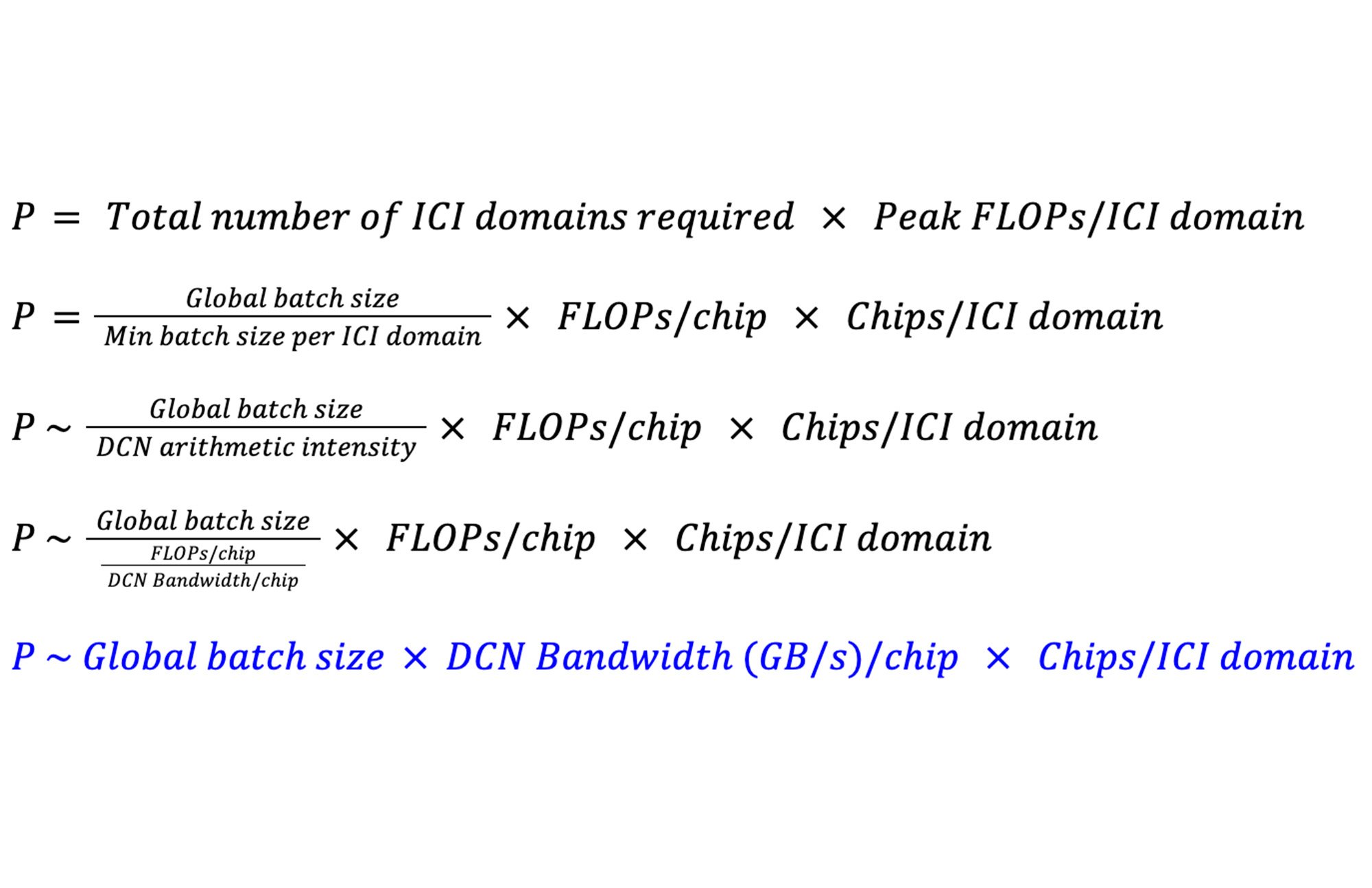
This shows that the maximum scale of a system, in total peak FLOPs, is impacted by the DCN bandwidth available per chip, the size of the ICI domain, and the global batch size.
To see the impact of ICI domain size on the maximum scale a system can enable without communication bottlenecks, let’s take a look at examples of different systems where a model is trained with a 32M global batch size:
As a baseline, assume that a system with an 8-chip ICI domain communicates across DCN at a rate of 400 Gbps/chip using traditional high-speed DCN technology:

Here, the highest total peak FLOPs this system can enable without performance degradation is P8 = 12.8 EFLOPs.
TPU pods have larger ICI domains that increase the arithmetic intensity per byte transferred over DCN. For the TPU v5e pods, with 256 chips per ICI domain and 25 Gbps/chip, P256 = 25.6 EFLOPs.

And, for TPU v4 pods, with 3072 chips per ICI domain and 25 Gbps/chip, P3072 = 307.2 EFLOPs.
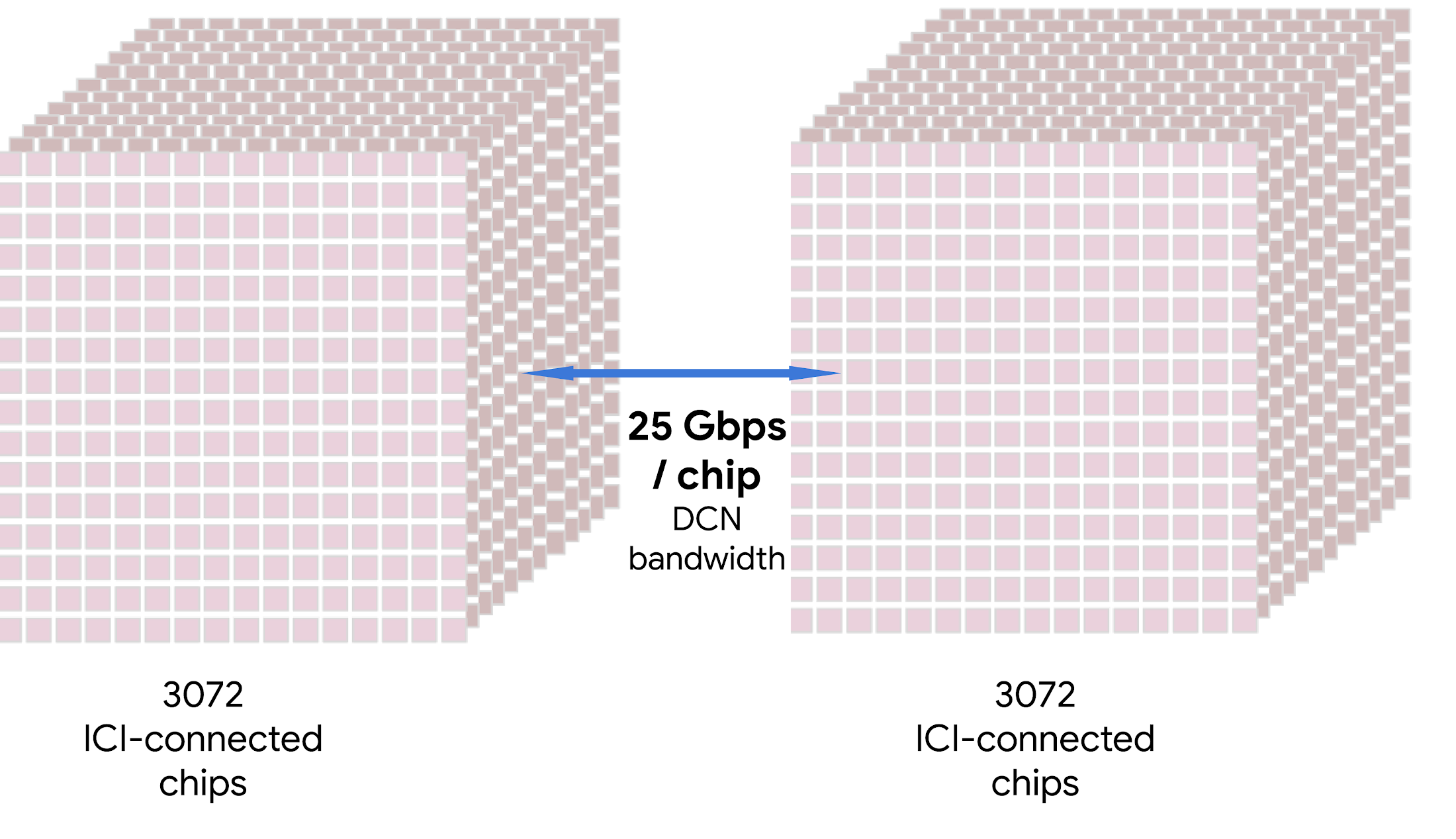
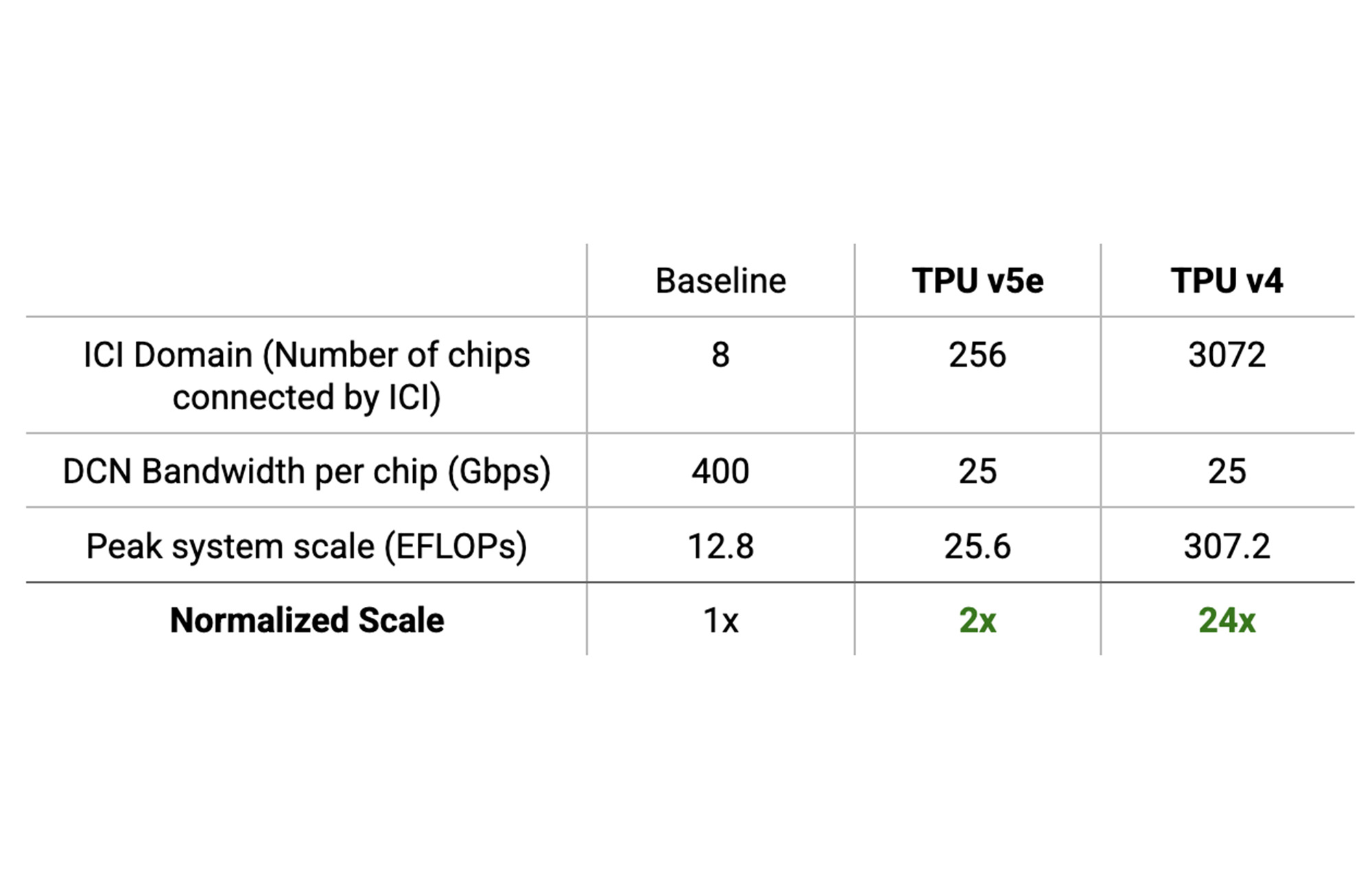
The TPU v5e system and the TPU v4 system enable up to 2x or 24x higher scale respectively compared to systems with 8-chip ICI domains and 400 Gbps of DCN bandwidth per chip.
“Google DeepMind and Research have had several successful training runs each using many thousands of TPU v5e chips including models for LLM use cases with excellent scaling efficiency — similar to TPU v4 generation — using Multislice scaling software.”—Jeff Dean, Chief Scientist, Google
Near-linear scaling up to tens of thousands of chips for TPU v5e
To compare Multislice performance to single-slice performance, we can use the metric Model FLOPs Utilization (MFU), defined as the ratio of the observed throughput (tokens-per-second) relative to the theoretical maximum throughput of a system operating at peak FLOPs.
A TPU training run that uses multiple slices with Multislice offers the same MFU rates as one using a single slice because of compiler optimizations. Some examples are:
Gradient reduction for FSDP that’s overlapped with backward propagation
Special hierarchical collectives that decompose traditional collectives based on communication topologies
In addition, unlike other accelerators, TPU chips can sustain their peak FLOPS without throttling, therefore achieving higher FLOPs and higher MFU rates.
Multislice can be used to train generative AI models with hundreds of billions of parameters with runs showing as high as 58.9% MFU on multibillion parameter models on TPU v4.
Weak scaling where the batch size was increased as more pods were used exhibits near-linear performance on GPT-3 175B trained on TPU v5e1:
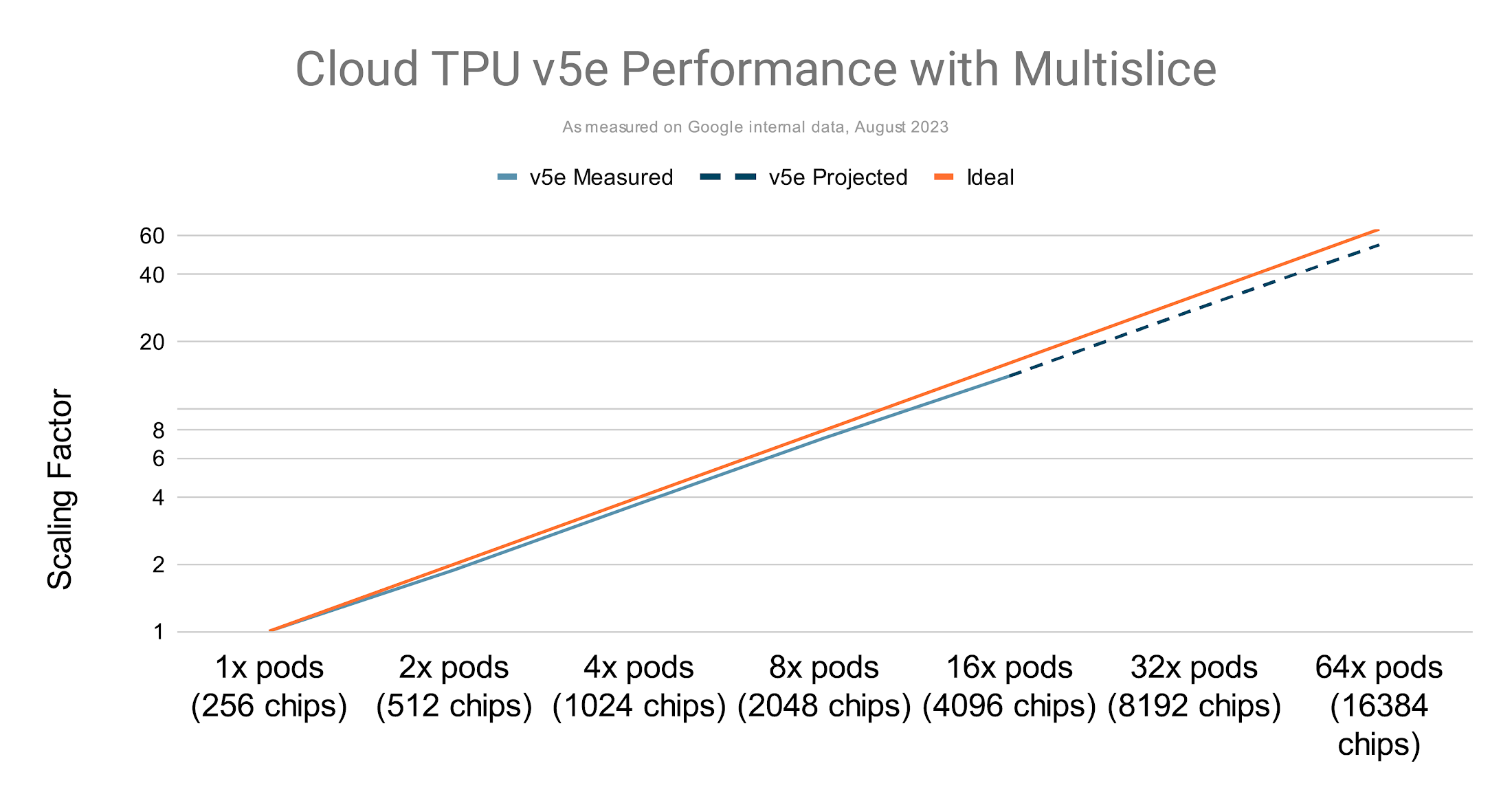
Multislice on Cloud TPUs is easy to use
Managing communication hierarchies for scaling technologies can be complex and reduce developer productivity. Multislice simplifies scaling with a throughput-optimized software stack that works well out-of-the-box. Users can focus on training AI models rather than managing complexity, which offers a good developer experience even at large scales. Integrations with familiar profiling and orchestration tools as those used for single-slice jobs reduce setup time further.
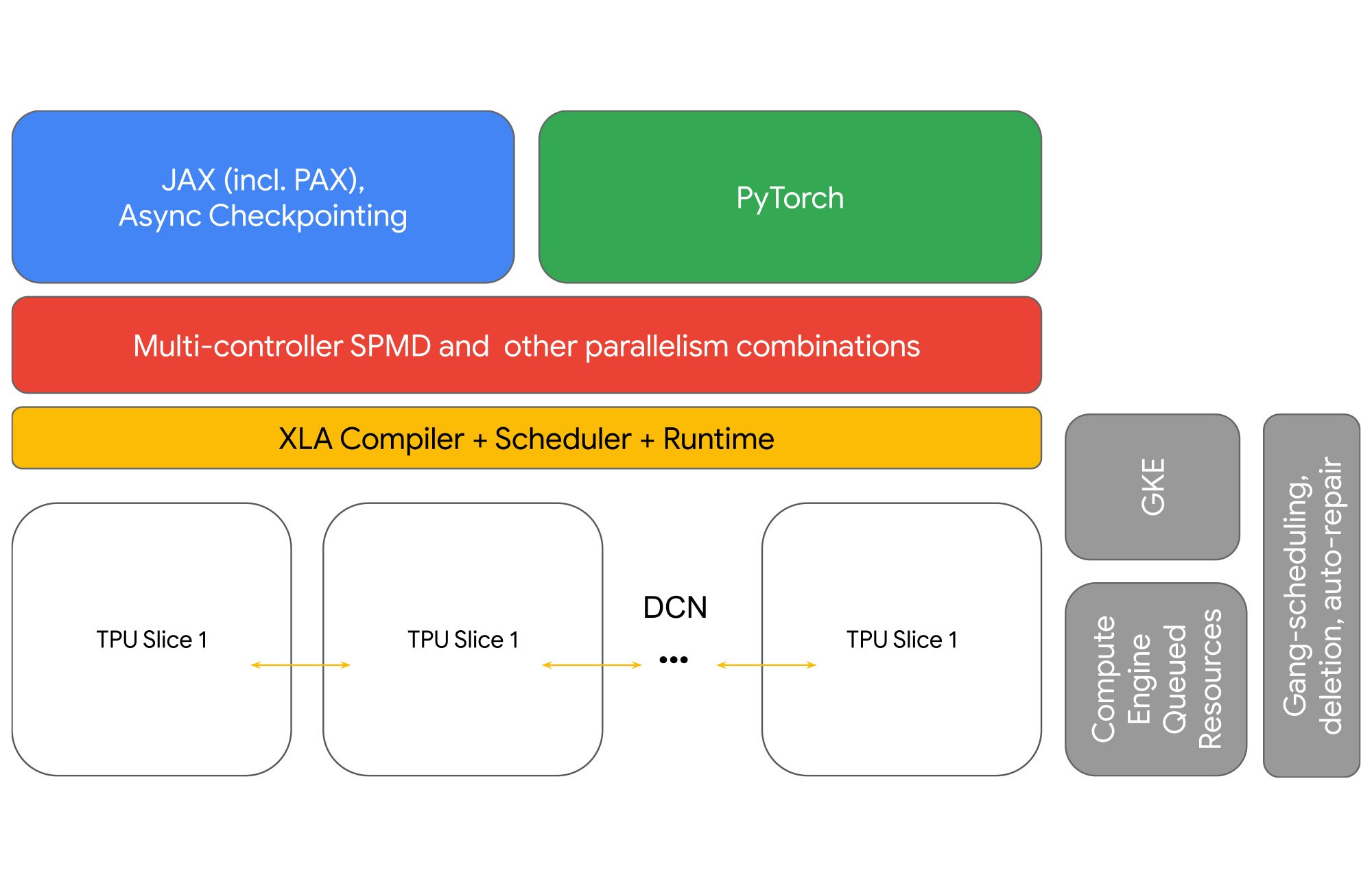
Using GSPMD, going from 2 to 2,000 slices is a simple matter of switching between tensor, data, and FSDP parallelisms by manipulating sharding axes. Consequently, we adapted the runtime and the rest of the infrastructure for Multislice workloads, and we introduced a new sharding dimension over DCN for JAX and PyTorch.
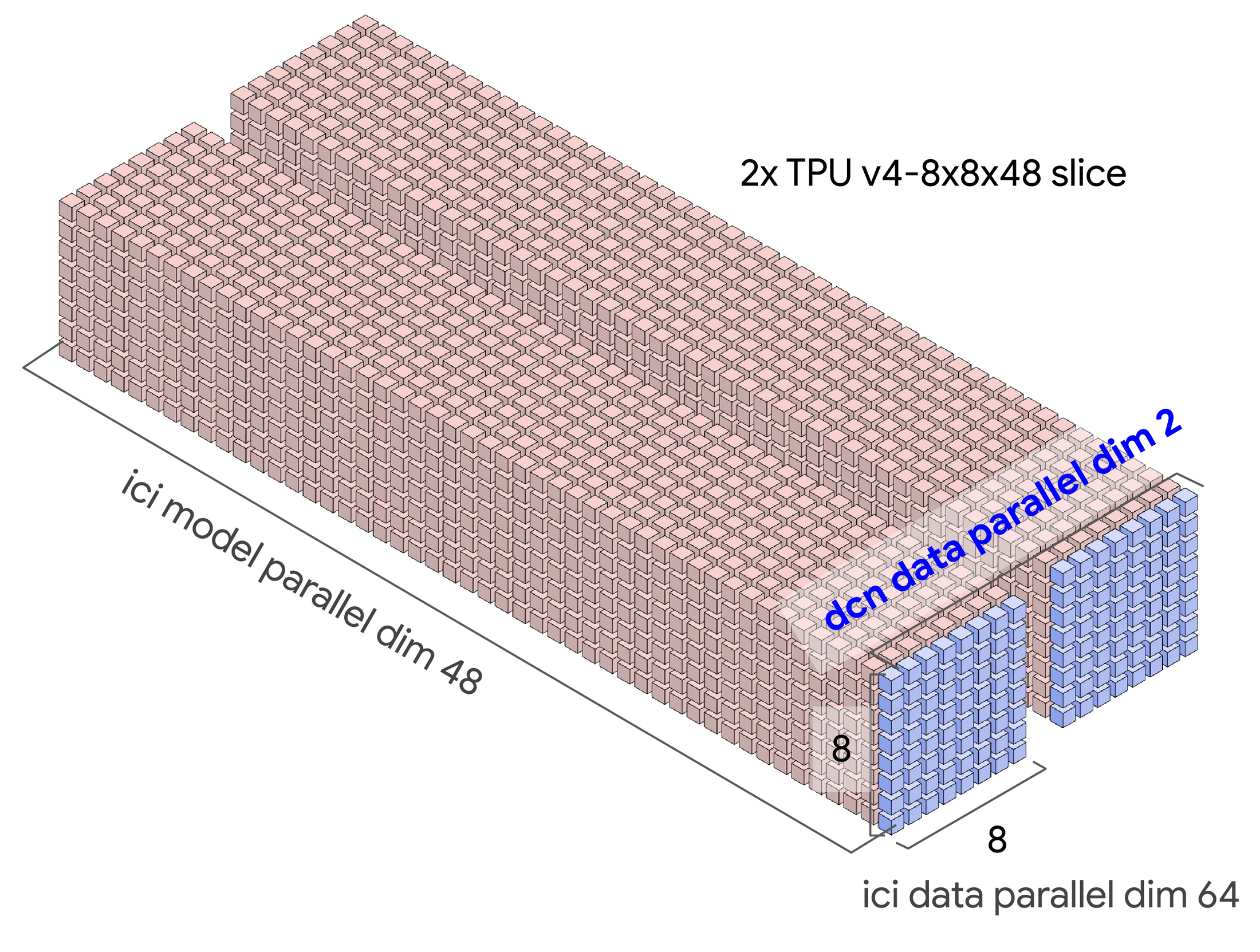
We use the GSPMD terminology, mesh, defined as a logical multi-dimensional organization of distributed devices that can be configured to assign model matrix dimensions across devices:
The table below shows an example for the configuration options for two slices with simple data parallelism with the DCN mapped to the data parallel axes:
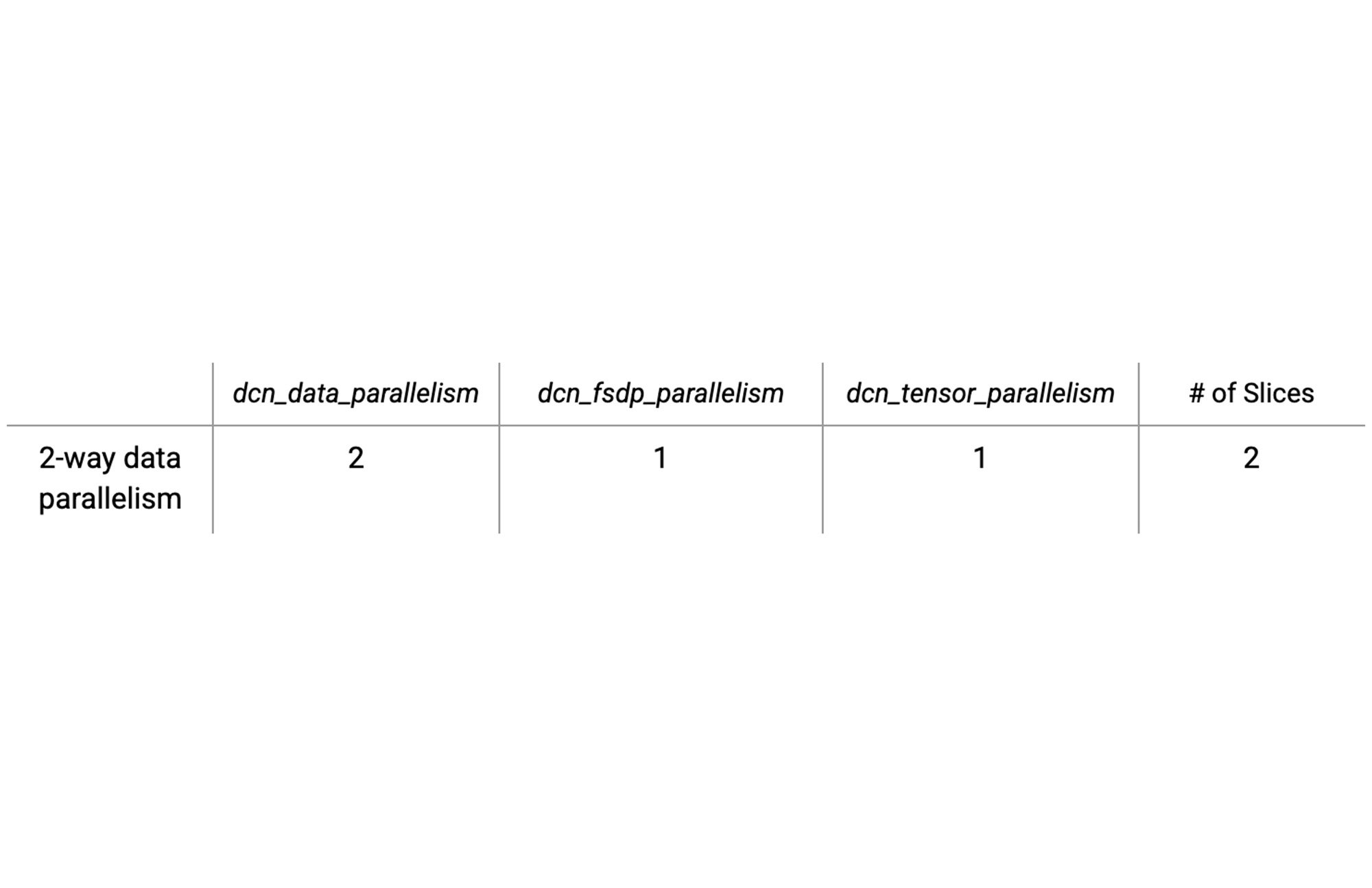
Computing values for these parallelism types is easy. Simply ensure that the products of the dcn and ici parallelism variables multiply to the total number of chips.
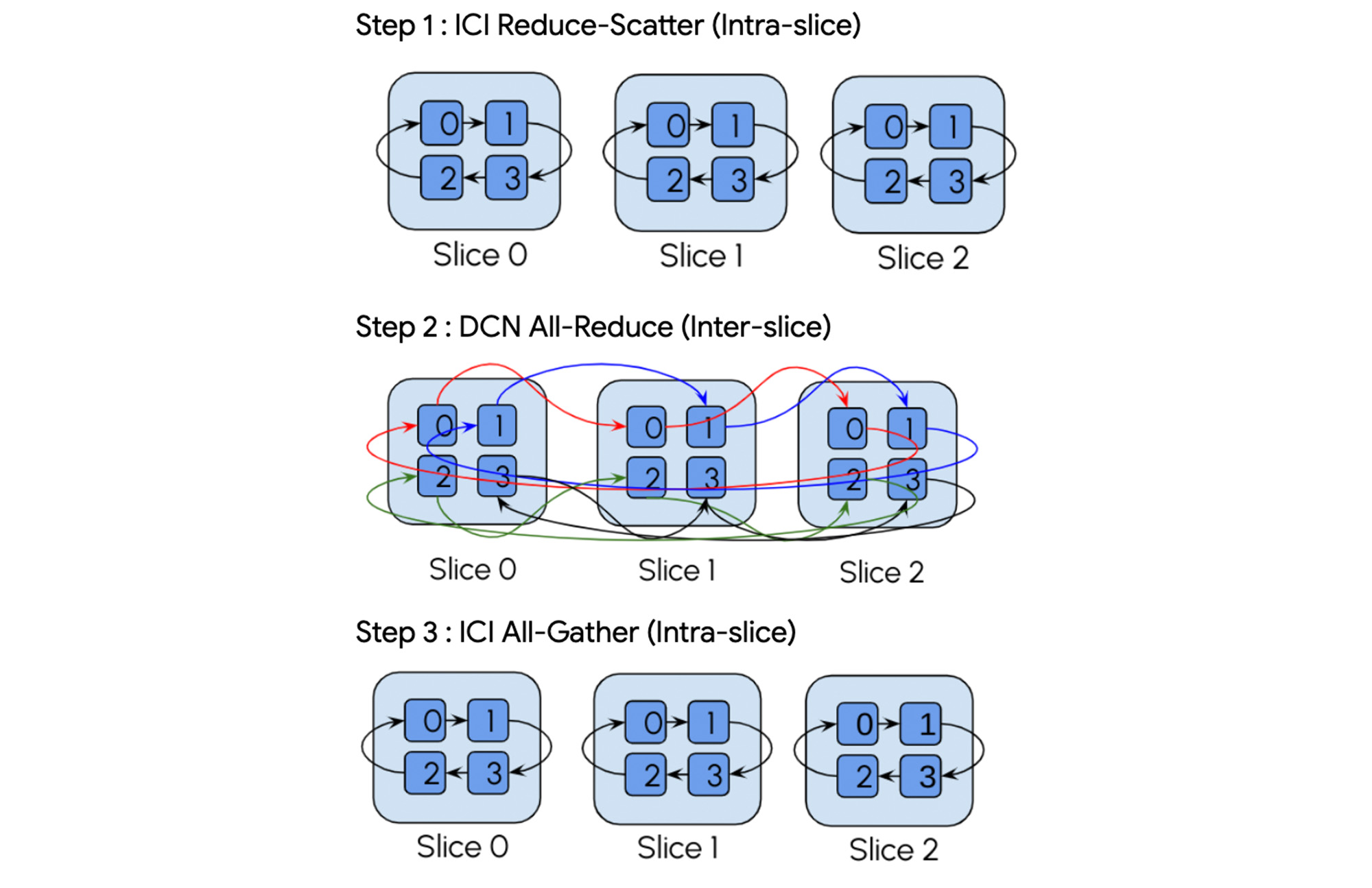
Additionally, because the XLA compiler understands the underlying hybrid DCN/ICI network topology it can automatically insert the appropriate hierarchical collectives and even convert single-slice operations into multi-slice hierarchical collectives to improve compute-communication overlap.
For example, take an all-reduce operation. The compiler automatically decomposes this into a three-step hierarchical collective:
“Multislice training has been a game-changer. It's made it easy to scale our ML workloads beyond a single densely-interconnected slice using data-center networking. JAX XLA made it easy to set up and delivered high performance out-of-the-box.”—Myle Ott, Co-founder, Character AI
Multislice supports JAX and PyTorch frameworks. For fast out-of-the box performance, in addition to compiler support for all models, we provide MaxText and PAX for LLMs, as open-sourced and well-tested examples written in pure Python and JAX that can be used as starter code. PAX is a framework for training large-scale models that allows for advanced and fully configurable experimentation and parallelization, and has demonstrated industry-leading MFU rates. MaxText is a more minimal framework intended for forking and adaptation. The only code change compared to single-slice code is the extra sharding dimension for DCN parallelism.
High performance networking
Multislice supports AllReduce, Broadcast, Reduce, AllGather and ReduceScatter collective communication operations over Google’s Jupiter data center network. As reported in August 2022, Jupiter reduces flow completion by 10%, improves throughput by 30%, uses 40% less power, incurs 30% less capex costs, and delivers 50x less downtime than previous generations of the Google data center network.3
Easy to manage
There are two options to manage the Multislice job: using Compute Engine Queued Resource CLIs and APIs or through Google Kubernetes Engine (GKE).
Special options allow for one-step deletion and creation of the collection of slices. And, fast recovery means jobs are restarted quickly even when individual slices are interrupted.
Reliable and fault tolerant
Your model training jobs restart automatically from the previous checkpoint even if individual slices fail. Using Multislice with GKE further improves the failure recovery experience — a single field-change in the yaml file implements automatic retry on encountering errors.
“Google Cloud’s TPU Multislice provided significant productivity and efficiency gains for us right out-of-the-box, enabling us to scale our language model training reliably. We recommend Multislice to anyone building large generative language AI models.”—Emad Mostaque, CEO, Stability AI
Get started
Multislice was designed to enable efficient large-scale AI model training. To scale AI workloads, hardware and software must work in concert. We have kept AI development productivity top of mind and are excited for you to try Multislice in preview on both Cloud TPU v4 as well as on the newly-announced Cloud TPU v5e.
Please contact your Google Cloud account representative to learn more and try Cloud TPU with Multislice using PAX and MaxText.1. Google internal data as of August, 2023
2. Google internal data as of August, 2023
3. Google internal data as of August, 2023



