Running AlphaFold batch inference with Vertex AI Pipelines

Jarek Kazmierczak
Solutions Architect
Renato Leite
Solutions Architect
Today, to accelerate research in the bio-pharma space, from the creation of treatments for diseases to the production of new synthetic biomaterials, we are announcing a new Vertex AI solution that demonstrates how to use Vertex AI Pipelines to run DeepMind’s AlphaFold protein structure predictions at scale.
Once a protein’s structure is determined and its role within the cell is understood, scientists can develop drugs that can modulate the protein function based on its role in the cell. DeepMind, an AI research organization within Alphabet, created the AlphaFold system to advance this area of research by helping data scientists and other researchers to accurately predict protein geometries at scale.
In 2020, in the Critical Assessment of Techniques for Protein Structure Prediction (CASP14) experiment, DeepMind presented a version of AlphaFold that predicted protein structures so accurately, experts declared the “protein-folding problem” solved. The next year, DeepMind open sourced the AlphaFold 2.0 system. Soon after, Google Cloud released a solution that integrated AlphaFold with Vertex AI Workbench to facilitate interactive experimentation. This made it easier for many data scientists to efficiently work with AlphaFold, and today’s announcement builds on that foundation.
Last week, AlphaFold took another significant step forward when DeepMind, in partnership with the European Bioinformatics Institute (EMBL-EBI), released predicted structures for nearly all cataloged proteins known to science. This release expands the AlphaFold database from nearly 1 million structures to over 200 million structures—and potentially increases our understanding of biology to a profound degree. Between this continued growth in the AlphaFold database and the efficiency of Vertex AI, we look forward to the discoveries researchers around the world will make.
In this article, we’ll explain how you can start experimenting with this solution, and we’ll also survey its benefits, which include offering lower costs through optimized selection of hardware, reproducibility through experiment tracking, lineage and metadata management, and faster run time through parallelization.
Background for running AlphaFold on Vertex AI
Generating a protein structure prediction is a computationally intensive task. It requires significant CPU and ML accelerator resources and can take hours or even days to compute. Running inference workflows at scale can be challenging—these challenges include optimizing inference elapsed time, optimizing hardware resource utilization, and managing experiments.Our new Vertex AI solution is meant to address these challenges.
To better understand how the solution addresses these challenges, let’s review the AlphaFold inference workflow:
Feature preprocessing. You use the input protein sequence (in the FASTA format) to search through genetic sequences across organisms and protein template databases using common open source tools. These tools include JackHMMER with MGnify and UniRef90, HHBlits with Uniclust30 and BFD, and HHSearch with PDB70. The outputs of the search (which consist of multiple sequence alignments (MSAs) and structural templates) and the input sequences are processed as inputs to an inference model. You can run the feature preprocessing steps only on a CPU platform. If you're using full-size databases, the process can take a few hours to complete.
Model inference. The AlphaFold structure prediction system includes a set of pretrained models, including models for predicting monomer structures, models for predicting multimer structures, and models that have been fine-tuned for CASP. At inference time, you independently run the five models of a given type (such as monomer models) on the same set of inputs. By default, one prediction is generated per model when folding monomer models, and five predictions are generated per model when folding multimers. This step of the inference workflow is computationally very intensive and requires GPU or TPU acceleration.
(Optional) Structure relaxation. In order to resolve any structural violations and clashes that are in the structure returned by the inference models, you can perform a structure relaxation step. In the AlphaFold system, you use the OpenMM molecular mechanics simulation package to perform a restrained energy minimization procedure. Relaxation is also very computationally intensive, and although you can run the step on a CPU-only platform, you can also accelerate the process by using GPUs.
The Vertex AI solution
The AlphaFold batch inference with the Vertex AI solution lets you efficiently run AlphaFold inference at scale by focusing on the following optimizations:
Optimizing inference workflow by parallelizing independent steps.
Optimizing hardware utilization (and as a result, costs) by running each step on the optimal hardware platform. As part of this optimization, the solution automatically provisions and deprovisions the compute resources required for a step.
Describing a robust and flexible experiment tracking approach that simplifies the process of running and analyzing hundreds of concurrent inference workflows.
The following diagram shows the architecture of the solution.
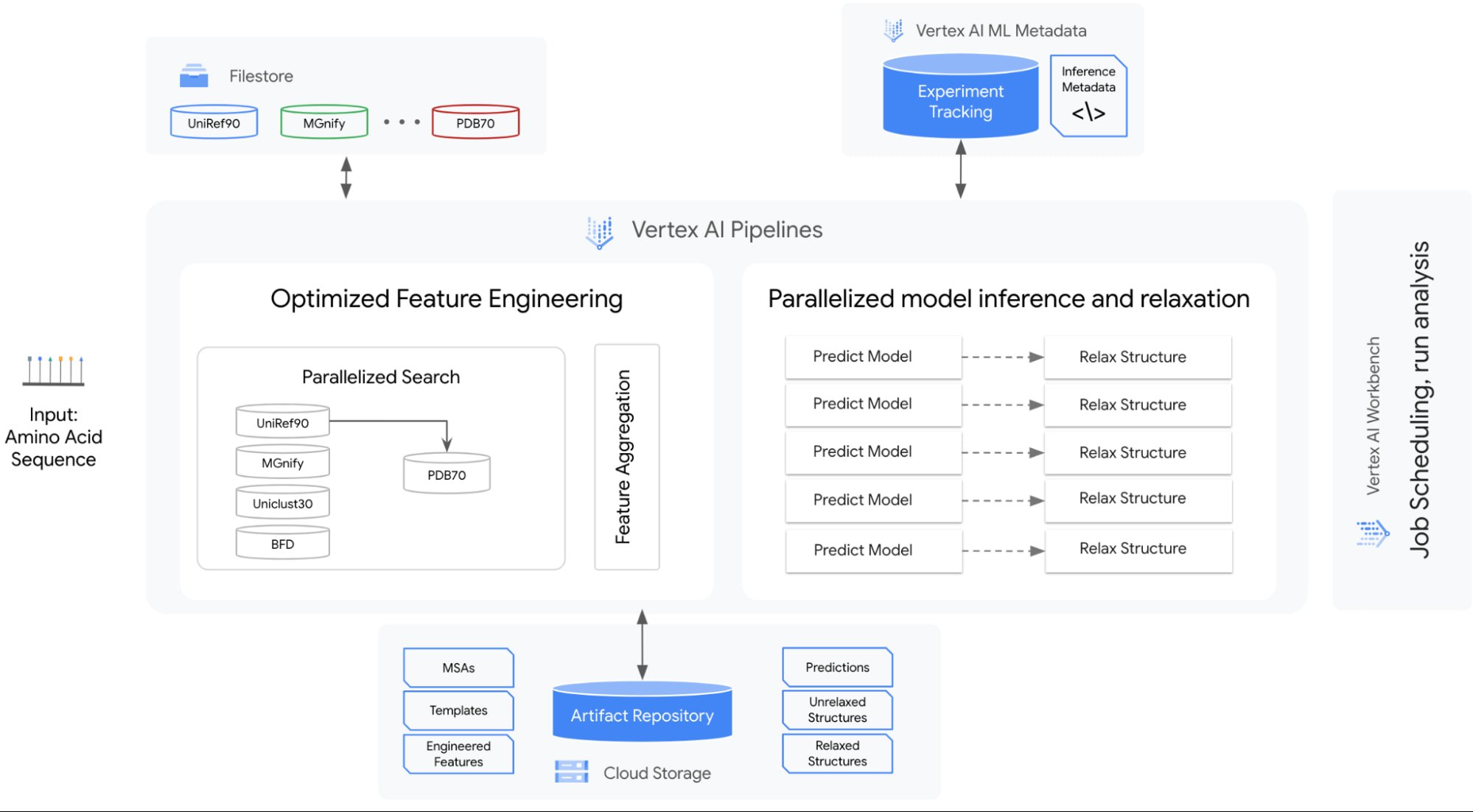
The solution encompasses the following:
A strategy for managing genetic databases. The solution includes high-performance, fully managed file storage. In this solution, Cloud Filestore is used to manage multiple versions of the databases and to provide high throughput and low-latency access.
An orchestrator to parallelize, orchestrate, and efficiently run steps in the workflow. Predictions, relaxations, and some feature engineering can be parallelized. In this solution, Vertex AI Pipelines is used as the orchestrator and runtime execution engine for the workflow steps.
Optimized hardware platform selection for each step. The prediction and relaxation steps run on GPUs, and feature engineering runs on CPUs. The prediction and relaxation steps can use multi-GPU node configurations. This is especially important for the prediction step because the memory usage is approximately quadratic with the number of residues. Therefore, predicting a large protein structure can exceed the memory of a single GPU device.
Metadata and artifact management. The solution includes management for running and analyzing experiments at scale. In this solution, Vertex AI Metadata is used to manage metadata and artifacts.
The basis of the solution is a set of reusable Vertex AI Pipelines components that encapsulate core steps in the AlphaFold inference workflow: feature preprocessing, prediction, and relaxation. In addition to those components, there are auxiliary components that break down the feature engineering step into tools, and helper components that aid in the organization and orchestration of the workflow.
The solution includes two sample pipelines: the universal pipeline and a monomer pipeline. The universal pipeline mirrors the settings and functionality of the inference script in the AlphaFold Github repository. It tracks elapsed time and optimizes compute resources utilization. The monomer pipeline further optimizes the workflow by making feature engineering more efficient. You can customize the pipeline by plugging in your own databases.
Next steps
To learn more and to try out this solution, check our GitHub repository, which contains the components and universal and monomer pipelines. The artifacts in the repository are designed so that you can customize them. In addition, you can integrate this solution into your upstream and downstream workflows for further analysis. To learn more about Vertex AI, visit our product page.
Acknowledgements
We would like to thank the following people for their collaboration: Shweta Maniar, Sampath Koppole, Mikhail Chrestkha, Jasper Wang, Alex Burdenko, Meera Lakhavani, Joan Kallogjeri, Dong Meng (NVIDIA), Mike Thomas (NVIDIA), and Jill Milton (NVIDIA).
Finally and most importantly, we would like to thank our Solution Manager Donna Schut for managing this solution from start to finish. This would not have been possible without Donna.




