Cloud TPU v5e accelerates large-scale AI inference

Alex Spiridonov
Group Product Manager, AI Infrastructure
Gang Ji
Senior Software Engineering Manager
Google Cloud’s AI-optimized infrastructure makes it possible for businesses to train, fine-tune, and run inference on state-of-the-art AI models faster, at greater scale, and at lower cost. We are excited to announce the preview of inference on Cloud TPUs. The new Cloud TPU v5e enables high-performance and cost-effective inference for a broad range AI workloads, including the latest state-of-the-art large language models (LLMs) and generative AI models.
As new models are released and AI becomes more sophisticated, businesses require more powerful and cost efficient compute options. Google is an AI-first company, so our AI-optimized infrastructure is built to deliver the global scale and performance demanded by Google products like YouTube, Gmail, Google Maps, Google Play, and Android that serve billions of users — as well as our cloud customers.
LLM and generative AI breakthroughs require vast amounts of computation to train and serve AI models. We’ve custom-designed, built, and deployed Cloud TPU v5e to cost-efficiently meet this growing computational demand.
Cloud TPU v5e is a great choice for accelerating your AI inference workloads:
Cost Efficient: Up to 2.5x more performance per dollar and up to 1.7x lower latency for inference compared to TPU v4.
Scalable: Eight TPU shapes support the full range of LLM and generative AI model sizes, up to 2 trillion parameters.
Versatile: Robust AI framework and orchestration support.
In this blog, we’ll dive deeper into how you can leverage TPU v5e effectively for AI inference.
Up to 2.5x more performance per dollar and up to 1.7x lower latency for inference
Each TPU v5e chip provides up to 393 trillion int8 operations per second (TOPS), allowing complex models to make fast predictions. A TPU v5e pod consists of 256 chips networked over ultra-fast links. Each TPU v5e pod delivers up to 100 quadrillion int8 operations per second, or 100 PetaOps, of compute power.
We optimized the Cloud TPU inference software stack to take full advantage of this powerful hardware. The inference stack leverages XLA, Google’s AI compiler, which generates highly-efficient code for TPUs to maximize performance and efficiency.
The combined hardware and software optimizations, including int8 quantization, enable Cloud TPU v5e to achieve up to 2.5x greater inference performance per dollar than Cloud TPU v4 on state-of-the-art LLM and generative AI models, including Llama 2, GPT-3, and Stable Diffusion 2.1:
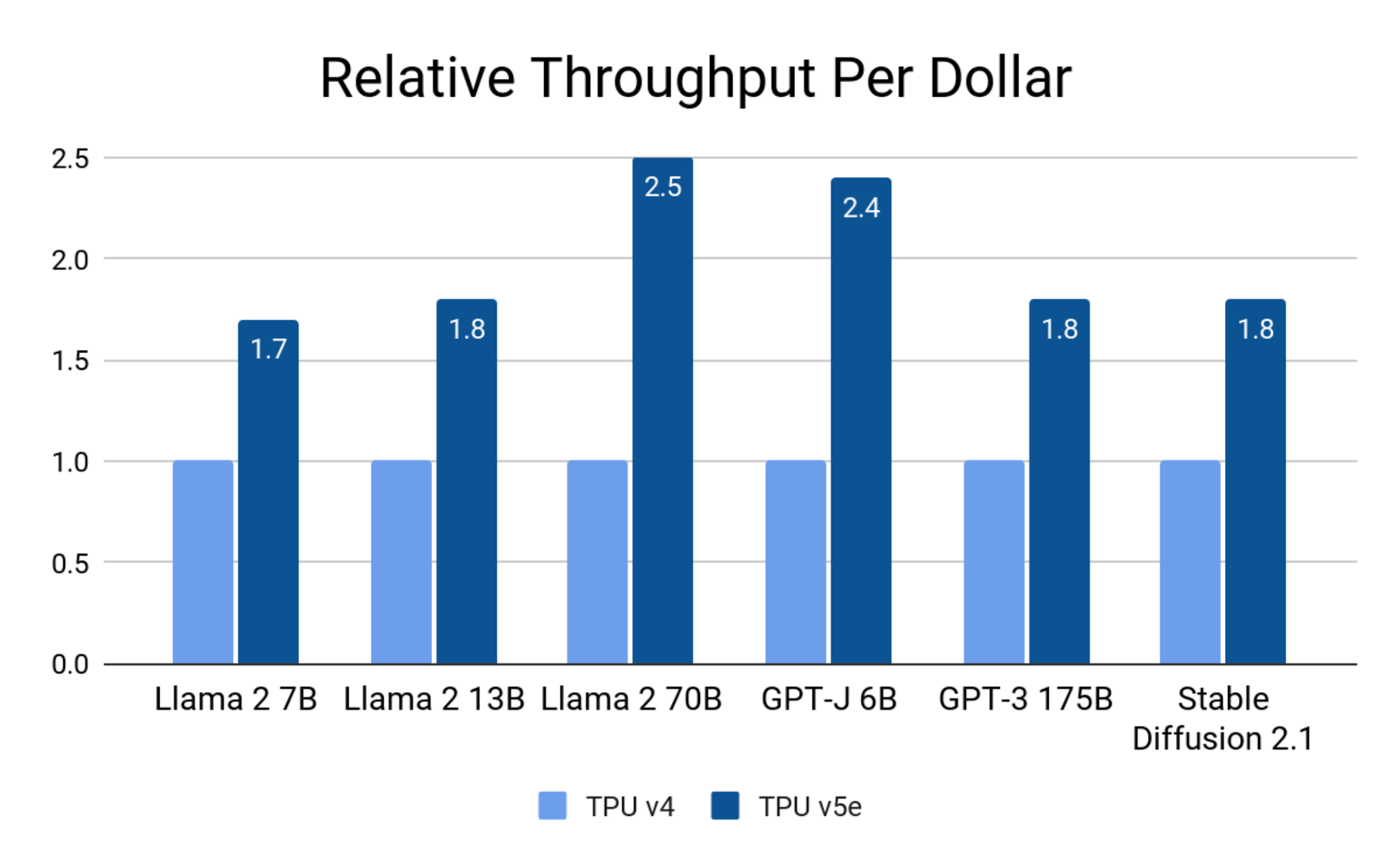
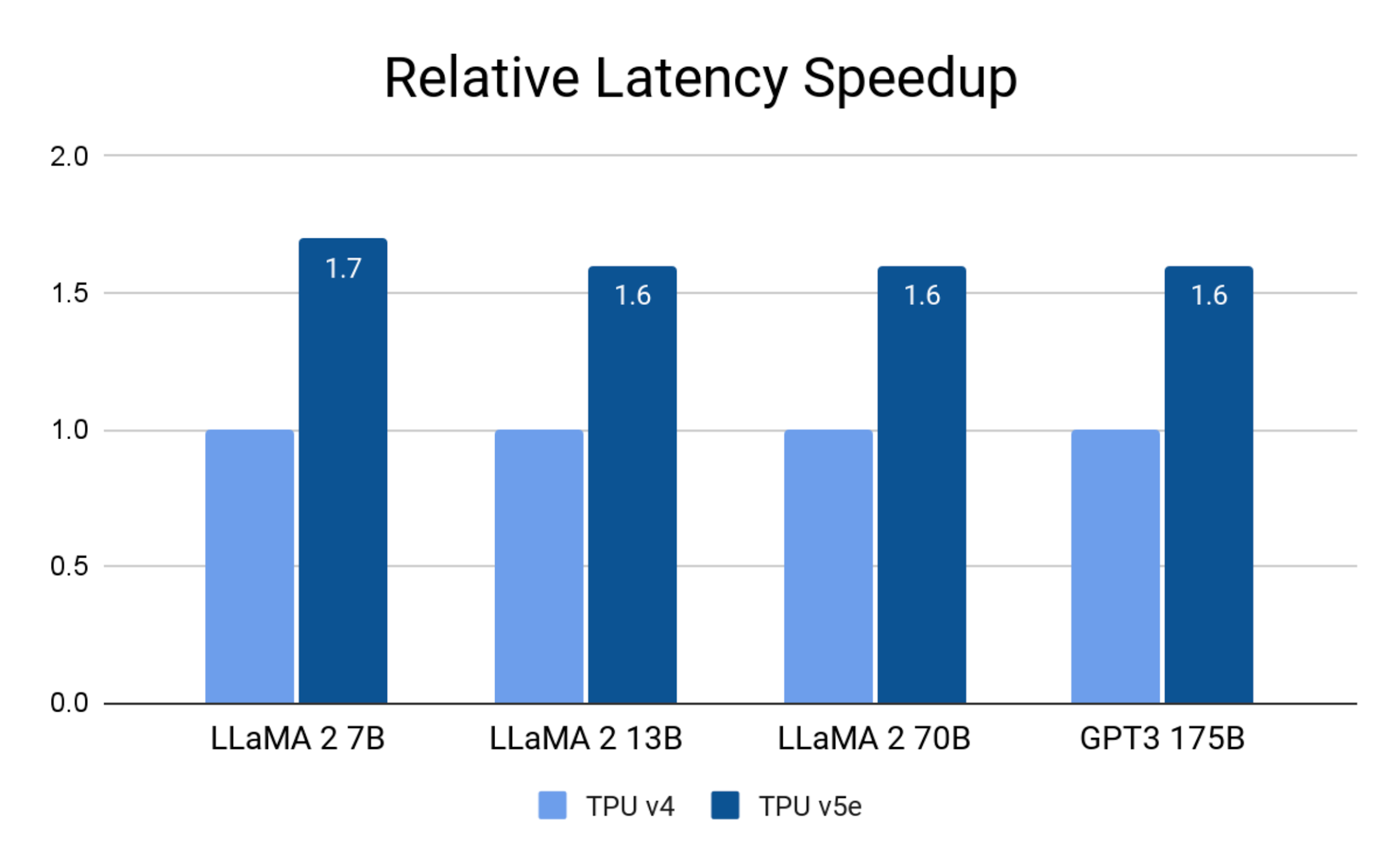
On latency, Cloud TPU v5e achieves up to 1.7x speedup compared to TPU v4:
Google Cloud customers have been running inference on Cloud TPU v5e, and some have seen even greater speedups on their particular workloads.
AssemblyAI offers dozens of AI models to their customers for speech recognition and understanding with over 25 million inference calls on a daily basis.
“Cloud TPU v5e consistently delivered up to 4X greater performance per dollar than comparable solutions in the market for running inference on our production model. The Google Cloud software stack is optimized for peak performance and efficiency, taking full advantage of the TPU v5e hardware that was purpose-built for accelerating the most advanced AI and ML models. This powerful and versatile combination of hardware and software dramatically accelerated our time to solution: instead of spending weeks hand-tuning custom kernels, within hours we optimized our model to meet and exceed our inference performance targets.” – Domenic Donato, VP of Technology, AssemblyAI
Scale to the full range of LLM and Generative AI model sizes
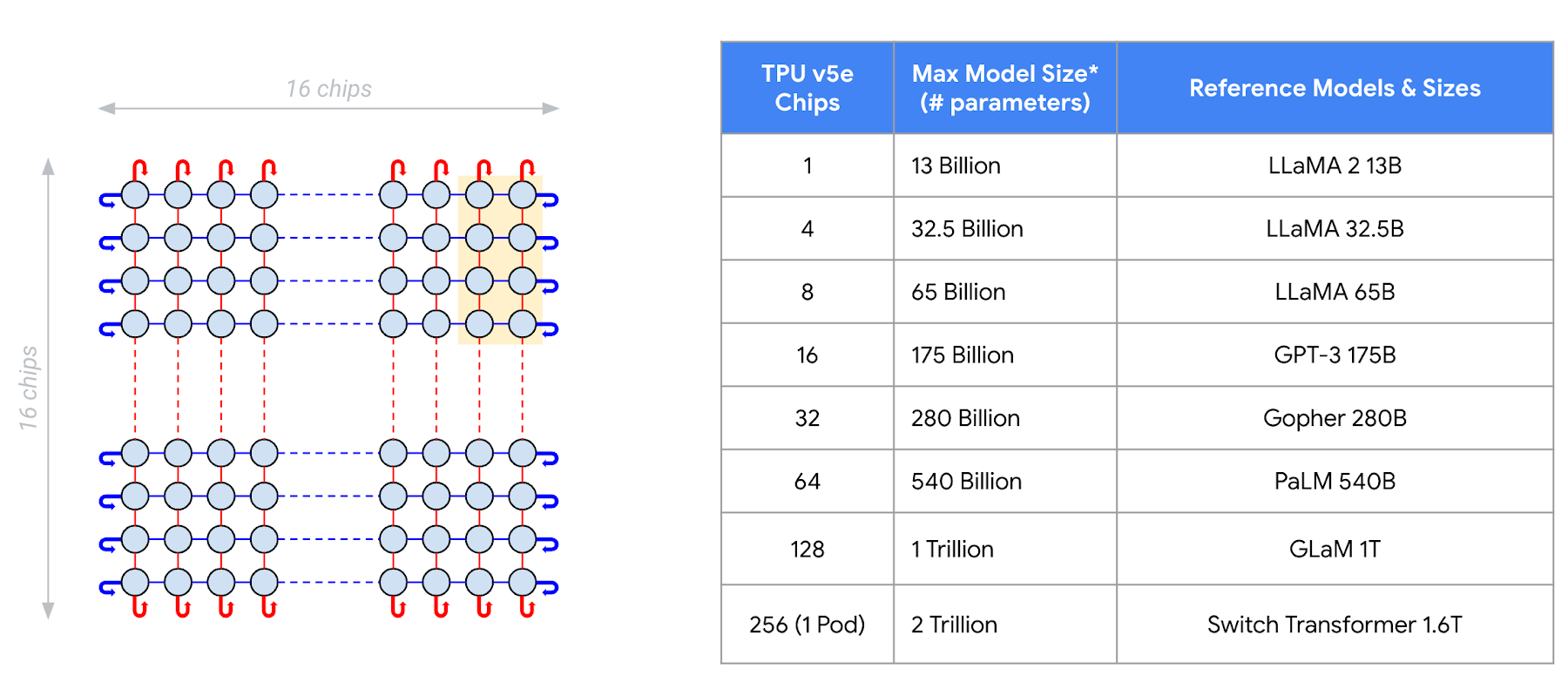
LLMs and generative AI models continue to grow in size and computational cost. The largest models require the combined compute and memory of hundreds of hardware accelerators. Cloud TPU v5e enables inference for a wide range of model sizes. A single v5e chip can run models with up to 13B parameters. From there, you can scale up to hundreds of chips and run models with up to 2 trillion parameters.
Gridspace leverages Google Cloud TPU infrastructure to power its full-stack conversational AI platform – building and integrating real-time conversational ASR, LLMs, semantic search, and neural TTS.
“We’re a huge fan of Google Cloud TPUs. Our benchmarks are demonstrating a 5X increase in the speed of AI models when training and running on Google Cloud TPU v5e. We are also seeing a 6x improvement in the scale of our inference metrics. We've scaled our AI models to billions of conversations per year across financial services, capital markets, and healthcare with Google Cloud’s AI infrastructure. Our Grace bots are powered by models trained using Cloud TPUs and served at scale on GKE with support for PCI, HITRUST, and SOC 2 compliance.” – Wonkyum Lee, Head of Machine Learning, Gridspace
Robust AI framework and orchestration support
Leading AI frameworks, including PyTorch, JAX, and TensorFlow, provide robust support for inference on Cloud TPU v5e. This means you can now train and serve models end-to-end on Cloud TPUs: what you train is what you serve.
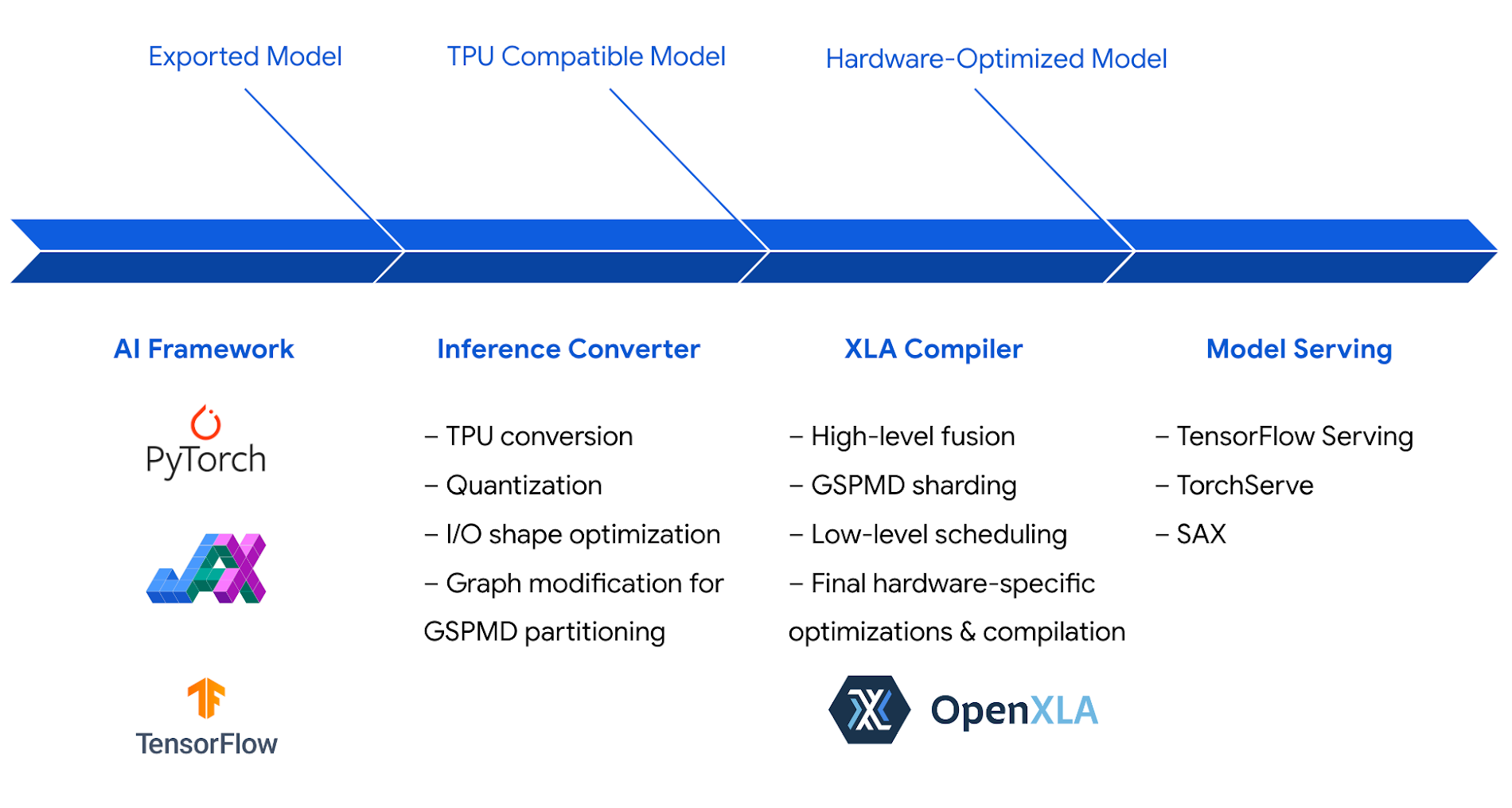
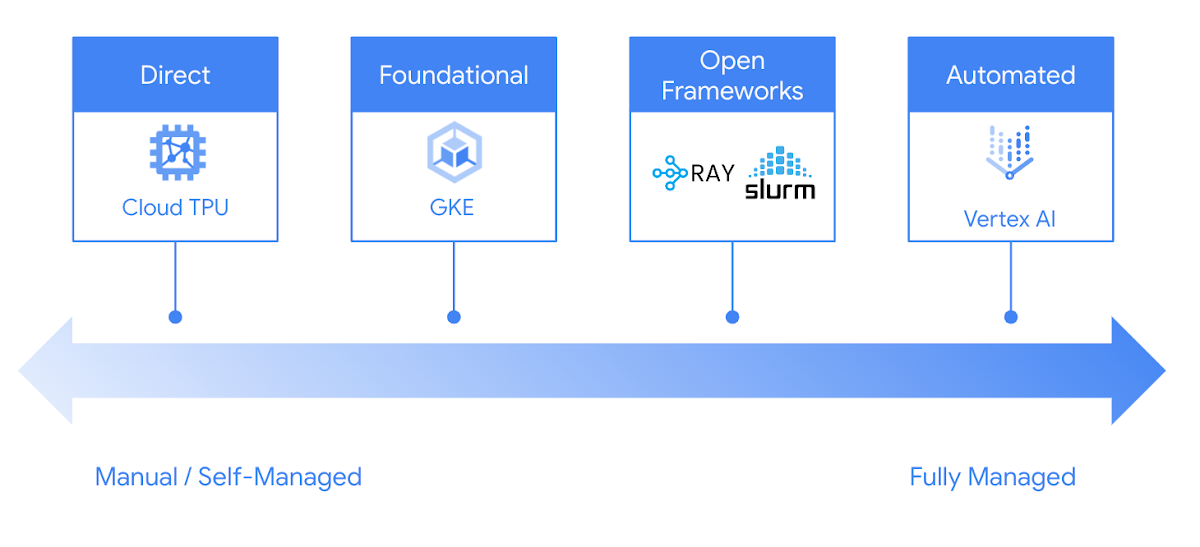
Google Cloud offers you many choices to run inference on Cloud TPUs easily and reliably. From GKE and Vertex AI, to popular open-source frameworks such as Ray and Slurm, you can leverage Google Cloud TPUs in your preferred way to fit your development process.
Try Cloud TPU v5e for inference today
Cloud TPU v5e provides a high-performance, cost-efficient, scalable, and reliable inference platform for LLMs and generative AI models. Leading AI companies are leveraging the power of Cloud TPU v5e to serve AI models at scale:

To get started with inference on Cloud TPU, reach out to your Google Cloud account manager or contact Google Cloud sales.



