News and events
News and events
- See why Google was named Leader in Gartner® Magic Quadrant™ for AI InfrastructureRead the report to see why AI Hypercomputer is positioned furthest for execution and vision.
- Get the latest TPU newsSign up to our mailing list to be the first to hear about new TPU launches and events.
- Connect your developers with a global communityWe just passed 100,000 members in our Google Cloud x NVIDIA community — the best place for developers to connect, share, and learn from their peers.
The future of AI Infrastructure
The future of AI Infrastructure
AI Hypercomputer is an architecture combining purpose-built hardware, open software, and flexible consumption models. Each component is carefully integrated to work well together, improving your performance, cost, and developer productivity.

Smarter, faster training
Smarter, faster training
Build models in weeks, not months. Use Google’s training stack to speed up development and testing without sacrificing performance.

Train and tune LLMs faster
Develop LLMs 36% faster and squeeze up to 97% productivity (Goodput) out of every accelerator using TPU 8t together with software co-designed with Google DeepMind and integrated with open source frameworks - from Pathways to Pallas (training), Ray to Agent Sandbox (tuning). We also know that one size doesn't fit all, so we partner closely with NVIDIA to deliver the latest GPUs; Google Cloud will be will be among the first to deliver instances based on the next-generation NVIDIA Vera Rubin NVL72 when it becomes available later this year.
Train lightweight models smarter using proprietary data
Use Gemini Enterprise Agent Platform with BigQuery to train models on proprietary data 16X faster by combining your data estate, ML development and accelerators in one place. Both are powered by AI Hypercomputer, whether you use G4 VMs or Ironwood TPUs.
Build adaptive physical agents with MuJoCo-Warp
Run GPU-based simulations on DeepMind’s MuJoCo-Warp, up to 100X faster than standard MuJoCo. Then simulate impossible, risky, or expensive edge cases using synthetic media from Veo, Genie and Nano Banana, or ingest petabytes of real-world sensor data in BigQuery. Learn more about building physical agents on Google Cloud here.
Responsive, efficient inference
Responsive, efficient inference
Get validated model profiles plus fully-integrated Google and open software to boost application responsiveness with less complexity and waste.
Serve LLMs with near-zero latency
Use integrated inference technologies to deliver useful, responsive services to customers. Cut time-to-first-token by 71% with GKE Inference Gateway, serve up to 120k tokens per second using llm-d for disaggregated serving, and load models 5X faster using Rapid Cache and TPU 8i to keep your working memory exactly where it’s needed.
Serve pre-built visual, perception, and media models
Deploy classical ML models 70% faster using one of 200+ models available on Gemini Enterprise Agent Platform, using on your choice of TPU or GPU, including A5X VMs (NVIDIA Vera Rubin) and TPU 8i when they become available later this year.
Serve agents safely and cost-effectively
Serve swarms of agents securely in GKE Agent Sandbox, provisioning up to 300 sandboxes per second while instantly pausing and resuming as needed, so you never pay for agents sitting idle.
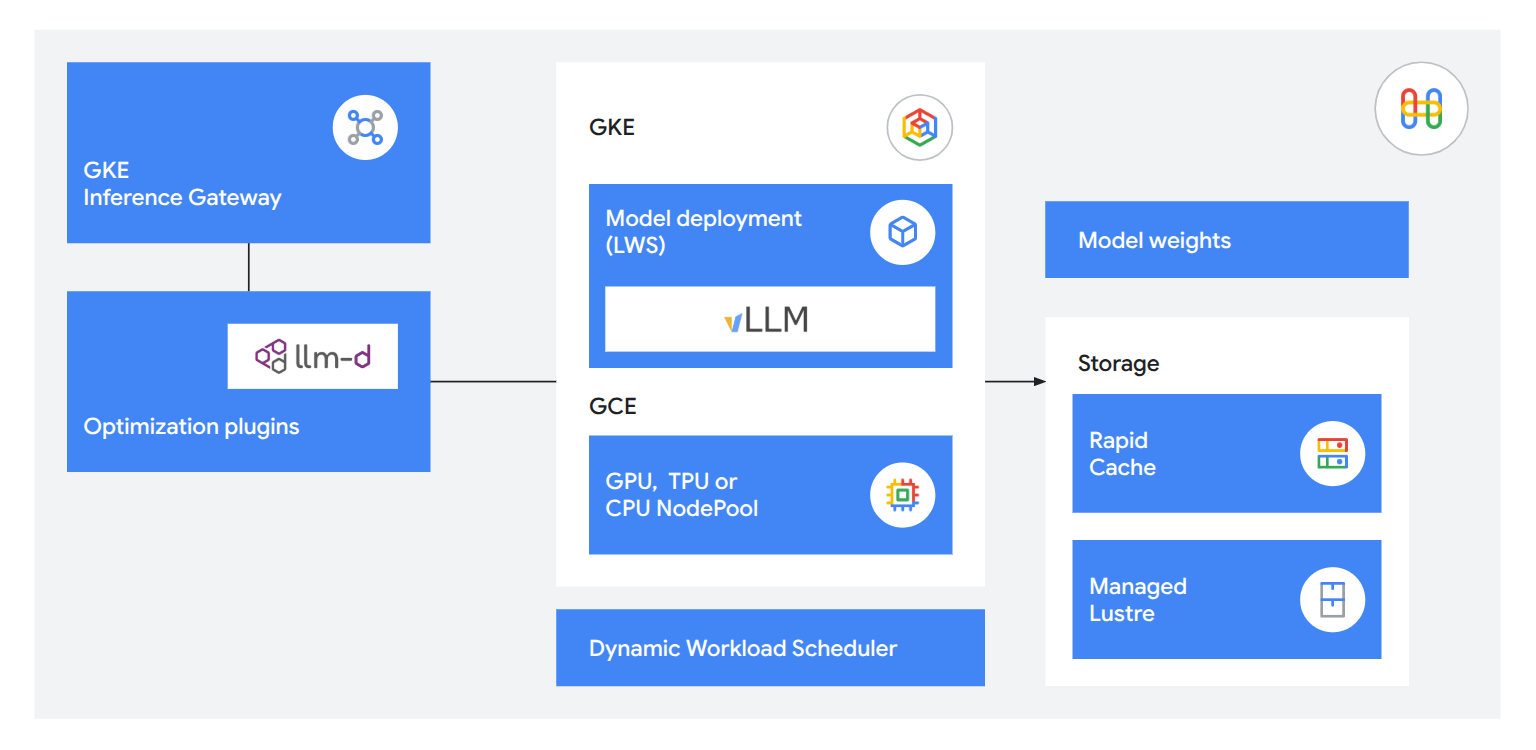
Flexible, open, reliable operations
Flexible, open, reliable operations
Use any framework or accelerator across hybrid and multicloud environments with automated cluster maintenance and management fit for exascale.

Switch between TPUs and GPUs without rewriting code
TorchTPU removes the TPU learning curve for developers by providing native PyTorch support, so you can use the best available accelerator without complex code rewrites.
Deploy AI in any environment at virtually any scale
Based on open source Kubernetes, GKE gives you multicloud portability with enterprise scale, supporting up to 130,000 nodes while integrating natively with Agent Platform and Google Distributed Cloud for hybrid deployments.
Automate cluster maintenance with advanced cluster diagnostics and observability tools
Every accelerator on AI Hypercomputer is supported by cluster director capabilities, including a pre-deployment bill of health, 360 degree observability dashboards and always-on health checks.
Connect multicloud workloads in minutes rather than weeks
Connect services across clouds without laggy connections using Cross-Cloud Network, a networking backbone trusted by over 65% of the Fortune 100 which moves over 27 exabytes of data per month.
Get accelerator capacity, your way
Our flexible consumption models give you multiple ways to schedule and reduce the cost of accelerators. Save up to 91% on batch or fault-tolerant jobs with Spot VMs, up to 50% on jobs with a flexible start date using Dynamic Workload Scheduler, and up to 50% off when you sign up for committed use discounts.
Agent-ready systems
Agent-ready systems
Push the limits of performance and use energy responsibly as you scale on the infrastructure foundation trusted by Google and frontier AI Labs
De-risk your AI roadmap on a trusted foundation
Google Cloud supports 9 out of 10 top AI labs and 70 percent of funded AI startups. By deploying on AI Hypercomputer, you’re using data centers that reliably processed over 100 billion tokens for nearly 350 customers in December 2025 alone.
Achieve industry leading energy-efficiency
Google Cloud’s data centers, including AI Hypercomputer, deliver industry-leading energy efficiency, with six times more computing power per unit of electricity than five years ago. This enables our 8th generation TPU to deliver 80% better price-performance and 20% more energy-efficiency than the previous generation.
Reduce your impact on the grid and communities
We are committed to paying for 100% of the power our data centers use and any new infrastructure costs directly driven by our growth. Partner with us to ensure that as your AI ambitions scale, local households and businesses don’t foot the bill. In the coming years, we will fund new power and infrastructure to serve our models, and continue investing in alternative energy sources like advanced nuclear, geothermal and long-duration storage.
Protect your most valuable IP from silicon to the edge
Our Titanium architecture’s custom Titan chips deliver a verifiable hardware root of trust and zero-trust security. Independent analysis from cloudvulndb.org shows that our systems experience up to 70% fewer critical vulnerabilities than other leading clouds.
Powering the world's leading innovators










Learn more about AI Hypercomputer
- IDC: The Business Value of AI HypercomputerThis IDC report explores the real customer impact of AI Hypercomputer for AI workloads. Read the full report to see customer data illustrating a 353% improvement in ROI, 55% more efficient IT teams, and 67% less application/workload unplanned downtime.
5-min read
Read the report - Google is a Leader in the Gartner® Magic Quadrant for Strategic Cloud Platform ServicesFor the eighth consecutive year, Gartner® has named Google a Leader in the Gartner Magic Quadrant™ for Strategic Cloud Platform Services. This year, however, marks a major milestone: Google is now positioned furthest for completeness of vision.
5-min read
See the results - Google named a Leader in The Forrester Wave™: AI Infrastructure Solutions, Q4 2025Google received the highest score of all vendors in the Current Offering category and received the highest possible score in 16 out of 19 evaluation criteria, including, but not limited to: Vision, Architecture, Training, Inferencing, Efficiency, and Security.
5-min read
See the results
- Design and deploy your first inference stackLearn the essential components that form an inference solution on Google Cloud, from GKE, Cloud TPUs, TensorFlow, PyTorch, JAX, and Keras.
2-hr course
Take the course - Use vLLM on GKE to serve Gemma 3 27B inferenceThis tutorial shows you how to deploy and serve a Gemma 3 27B large language model (LLM) with the vLLM serving framework. You deploy Gemma 3 on a single A4 virtual machine (VM) instance on Google Kubernetes Engine (GKE).
15-minute guide
Take the tutorial - Fine-tune Gemma 3 on an A4 GKE clusterThis tutorial shows you how to fine-tune a Gemma 3 large language model (LLM) on a multi-node, multi-GPU GKE cluster on Google Cloud. This cluster uses an A4 virtual machine (VM) instance which has 8 NVIDIA B200 GPUs.
15-minute guide
Take the tutorial
- Train Qwen2 on an A4 Slurm clusterThis tutorial shows you how to train a large language model (LLM) on a multi-node, multi-GPU Slurm cluster on Google Cloud. The model that you use in this tutorial is based on a Qwen2 1.5 billion parameter model. The Slurm cluster uses two a4-highgpu-8g virtual machines (VMs), which each have 8 NVIDIA B200 GPUs.
15-minute guide
Take the tutorial - Serve Qwen2-7B-Instruct with vLLM on TPUsThis tutorial serves the Qwen/Qwen2-7B-Instruct model using the vLLM TPU serving framework on a v6e TPU VM.
15-minute guide
Take the tutorial
- Start hereSee all available AI Hypercomputer documentation, including architecture, deployment, management, testing and optimization guidance.Read all documentation
- Training recommendationsLearn about your accelerator options, recommended consumption models, and storage services to use when pre-training models.
15-min read
Read the documentation - Inference recommendationsLearn about your accelerator options, recommended consumption models, and storage service to use for inference.
15-min read
Read the documentation
Analyst insights
- IDC: The Business Value of AI HypercomputerThis IDC report explores the real customer impact of AI Hypercomputer for AI workloads. Read the full report to see customer data illustrating a 353% improvement in ROI, 55% more efficient IT teams, and 67% less application/workload unplanned downtime.
5-min read
Read the report - Google is a Leader in the Gartner® Magic Quadrant for Strategic Cloud Platform ServicesFor the eighth consecutive year, Gartner® has named Google a Leader in the Gartner Magic Quadrant™ for Strategic Cloud Platform Services. This year, however, marks a major milestone: Google is now positioned furthest for completeness of vision.
5-min read
See the results - Google named a Leader in The Forrester Wave™: AI Infrastructure Solutions, Q4 2025Google received the highest score of all vendors in the Current Offering category and received the highest possible score in 16 out of 19 evaluation criteria, including, but not limited to: Vision, Architecture, Training, Inferencing, Efficiency, and Security.
5-min read
See the results
Tutorials
- Design and deploy your first inference stackLearn the essential components that form an inference solution on Google Cloud, from GKE, Cloud TPUs, TensorFlow, PyTorch, JAX, and Keras.
2-hr course
Take the course - Use vLLM on GKE to serve Gemma 3 27B inferenceThis tutorial shows you how to deploy and serve a Gemma 3 27B large language model (LLM) with the vLLM serving framework. You deploy Gemma 3 on a single A4 virtual machine (VM) instance on Google Kubernetes Engine (GKE).
15-minute guide
Take the tutorial - Fine-tune Gemma 3 on an A4 GKE clusterThis tutorial shows you how to fine-tune a Gemma 3 large language model (LLM) on a multi-node, multi-GPU GKE cluster on Google Cloud. This cluster uses an A4 virtual machine (VM) instance which has 8 NVIDIA B200 GPUs.
15-minute guide
Take the tutorial
- Train Qwen2 on an A4 Slurm clusterThis tutorial shows you how to train a large language model (LLM) on a multi-node, multi-GPU Slurm cluster on Google Cloud. The model that you use in this tutorial is based on a Qwen2 1.5 billion parameter model. The Slurm cluster uses two a4-highgpu-8g virtual machines (VMs), which each have 8 NVIDIA B200 GPUs.
15-minute guide
Take the tutorial - Serve Qwen2-7B-Instruct with vLLM on TPUsThis tutorial serves the Qwen/Qwen2-7B-Instruct model using the vLLM TPU serving framework on a v6e TPU VM.
15-minute guide
Take the tutorial
Documentation
- Start hereSee all available AI Hypercomputer documentation, including architecture, deployment, management, testing and optimization guidance.Read all documentation
- Training recommendationsLearn about your accelerator options, recommended consumption models, and storage services to use when pre-training models.
15-min read
Read the documentation - Inference recommendationsLearn about your accelerator options, recommended consumption models, and storage service to use for inference.
15-min read
Read the documentation



















