The container platform for the next decade of AI and beyond

Chen Goldberg
GM & VP, Cloud Runtimes
Everywhere you look, there is an undeniable excitement about AI. We are thrilled, but not surprised, to see Google Cloud’s managed containers taking a pivotal role in this world-shaping transformation. We’re pleased to share announcements from across our container platform that will help you accelerate AI application development and increase AI workload efficiency so you can take full advantage of the promise of AI, while also helping you continue to drive your modernization efforts.
The opportunity: AI and containers
AI visionaries are pushing the boundaries of what’s possible, and platform builders are making those visions a scalable reality. The path to success builds on your existing expertise and infrastructure, not throwing away what you know. These new workloads demand a lot out of their platforms in the areas of:
-
Velocity: with leaders moving rapidly from talking about AI to deploying AI, time to market is more important than ever.
-
Scale: many of today’s systems were designed with specific scalability challenges in mind. Previous assumptions, no matter if you are a large model builder or looking to tune a small model for your specific business needs, have changed significantly.
-
Efficiency goals: AI’s inherent fluidity — such as shifting model sizes and evolving hardware needs — is changing how teams think about the cost and performance of both training and serving. Companies need to plan and measure at granular levels, tracking the cost per token instead of cost per VM. Teams that are able to measure and speak this new language are leading the market.
Containers serve the unique needs of AI
We’ve poured years of our insights and best practices into Google Cloud’s managed container platform and it has risen to the occasion of disruptive technology leaps of the past. And considering the aforementioned needs of AI workloads, the platform’s offerings — Cloud Run and Google Kubernetes Engine (GKE) — are ideally situated to meet the AI opportunity because they can:
-
Abstract infrastructure away: As infrastructure has changed, from compute to GPU time-sharing to TPUs, containers have allowed teams to take advantage of new capabilities on their existing platforms.
-
Orchestrate workloads: Much has changed from containers’ early days of being only used for running stateless workloads. Today, containers are optimized for a wide variety of workloads with complexity hidden from both users and platform builders. At Google, we use GKE for our own breakthrough AI products like Vertex AI, and to unlock the next generation of AI innovation with Deepmind.
-
Support extensibility: Kubernetes’ extensibility has been critical to its success, allowing a rich ecosystem to flourish, supporting user choice and enabling continued innovation. These characteristics now support the rapid pace of innovation and flexibility that users need in the AI era.
Cloud Run and GKE power Google products, as well as a growing roster of leading AI companies including Anthropic, Assembly AI, Cohere, and Salesforce that are choosing our container platform for its reliability, security, and scalability.
Our managed container platform provides three distinct approaches to help you move to implementation:
-
Solutions to get AI projects running quickly;
-
The ability to deploy customer AI workloads on GKE; and
-
Streamlined day-two operations across any of your enterprise deployments.
Cloud Run for an easy AI starting point
Cloud Run has always been a great solution for getting started quickly, offloading operational burden from your platform team and giving developers scalable, easy-to-deploy resources — without sacrificing enterprise-grade security or visibility.
Today, we are pleased to announce Cloud Run application canvas, designed to generate, modify and deploy Cloud Run applications. We’ve added integrations to services such as Vertex AI, simplifying the process of consuming Vertex AI generative APIs from Cloud Run services in just a few clicks. There are also integrations for Firestore, Memorystore, and Cloud SQL, as well as load balancing. And we’ve taken the experience one step further and integrated Gemini Cloud Assist, which provides AI assistance to help cloud teams design, operate, and optimize application lifecycles. Gemini in Cloud Run application canvas lets you describe the type of application you want to deploy with natural language, and Cloud Run will create or update those resources in a few minutes.
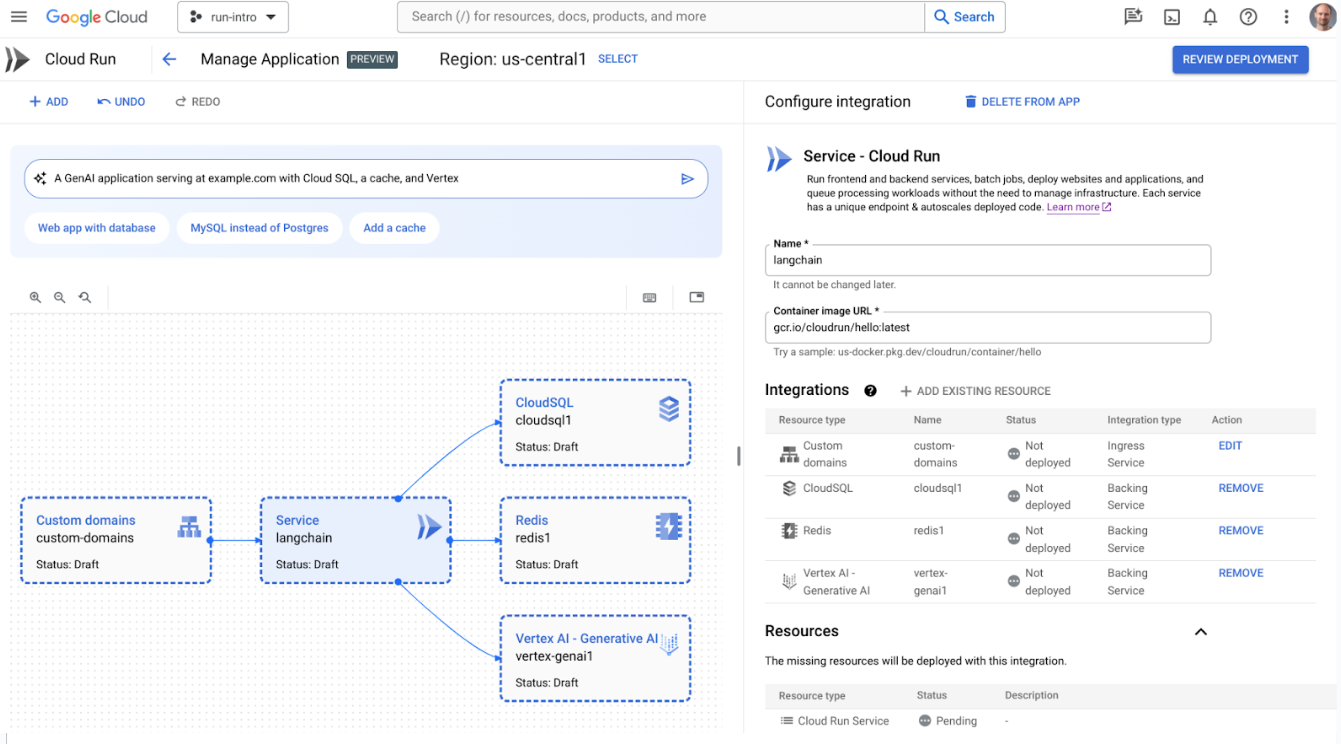
Cloud Run's application canvas showcasing a gen AI application
The velocity, scale, and efficiency you get from Cloud Run makes it a great option for building AI workloads. To help you get AI applications to market even faster, we’re pleased to announce Cloud Run support for integration with LangChain, a powerful open-source framework for building LLM-based applications. This support makes Cloud Run the easiest way to deploy and scale LangChain apps, with a developer-friendly experience.
“We researched alternatives, and Cloud Run is the easiest and fastest way to get your app running in production." - Nuno Campos, founding engineer, LangChain

Creating and deploying a LangChain application to Cloud Run
GKE for training and inference
For customers who value an open, portable, cloud-native, and customizable platform for their AI workloads, GKE is ideal. The tremendous growth in AI adoption continues to be reflected in how customers are using our products : Over the last year, the use of GPUs and TPUs on Google Kubernetes Engine has grown more than 900%.
To better meet the needs of customers transforming their businesses with AI, we've built innovations that let you train and serve the very largest AI workloads, cost effectively and seamlessly. Let's dive into each of those three: scale, cost efficiency, and ease of use.
Large-scale AI workloads
Many recent AI models demonstrate impressive capabilities, thanks in part to their very large size. As your AI models become larger, you need a platform that's built to handle training and serving massive AI models. We continue to push the limits of accelerator-optimized hardware to make GKE an ideal home for your large-scale AI models:
-
Cloud TPU v5p, which we announced in December and is now generally available, is our most powerful and scalable TPU accelerator to date. By leveraging TPU v5p on GKE, Google Cloud customer, Lightricks has achieved a remarkable 2.5X speedup in training their text-to-image and text-to-video models compared to TPU v4.
-
A3 Mega, which we announced today, is powered by NVIDIA's H100 GPUs and provides 2x more GPU to GPU networking bandwidth than A3, accelerating the time to train the largest AI models with GKE. A3 Mega will be generally available in the coming weeks.
Training the largest AI models often requires scaling far beyond a physical TPU. To enable continued scaling, last year we announced multi-slice training on GKE, which is generally available, enabling full-stack, cost-effective, large-scale training with near-linear scaling up to tens of thousands of TPU chips. We demonstrated this capability by training a single AI model using over 50,000 TPU v5e chips while maintaining near-ideal scaling performance.
Cost-efficient AI workloads
As AI models continue to grow, customers face many challenges to scaling in a cost effective way. For example, AI container images can be massive, causing cold start times to balloon. Keeping AI inference latency low requires overprovisioning to handle unpredictable load, but slow cold-start times require compensating by overprovisioning even more. All of this creates under-utilization and unnecessary costs.
GKE now supports container and model preloading, which accelerates workload cold start — enabling you to improve GPU utilization and save money while keeping AI inference latency low. When creating a GKE node pool, you can now preload a container image or model data in new nodes to achieve much faster workload deployment, autoscaling, and recovery from disruptions like maintenance events. Vertex AI's prediction service, which is built on GKE, found container preloading resulted in much faster container startup:
“Within Vertex AI's prediction service, some of our container images can be quite large. After we enabled GKE container image preloading, our 16GB container images were pulled up to 29x faster in our tests.” – Shawn Ma, Software Engineer, Vertex AI
For AI workloads that have highly variable demand such as low-volume inference or notebooks, a GPU may sit idle much of the time. To help you run more workloads on the same GPU, GKE now supports GPU sharing with NVIDIA Multi-Process Service (MPS). MPS enables concurrent processing on a single GPU, which can improve GPU efficiency for workloads with low GPU resource usage, reducing your costs.
To maximize the cost efficiency of AI accelerators during model training, it's important to minimize the time an application is waiting to fetch data. To achieve this, GKE supports GCS FUSE read caching, which is now generally available. GCS FUSE read caching uses a local directory as a cache to accelerate repeat reads for small and random I/Os, increasing GPU and TPU utilization by loading your data faster. This reduces the time to train a model and delivers up to 11x more throughput.
Ease of use for AI workloads
With GKE, we believe achieving AI scale and cost efficiency shouldn't be difficult. GKE makes obtaining GPUs for AI training workloads easy by using Dynamic Workload Scheduler, which has been transformative for customers like Two Sigma:
“Dynamic Workload Scheduler improved on-demand GPU obtainability by 80%, accelerating experiment iteration for our researchers. Leveraging the built-in Kueue and GKE integration, we were able to take advantage of new GPU capacity in Dynamic Workload Scheduler quickly and save months of development work.” – Alex Hays, Software Engineer, Two Sigma
For customers who want Kubernetes with a fully managed mode of operation, GKE Autopilot now supports NVIDIA H100 GPUs, TPUs, reservations, and Compute Engine committed use discounts (CUDs).
Traditionally, using a GPU required installing and maintaining the GPU driver on each node. However, GKE can now automatically install and maintain GPU drivers, making GPUs easier to use than ever before.
The enterprise platform for Day Two and beyond
Google Cloud’s managed container platform helps builders get started and scale up AI workloads. But while AI workloads are a strategic priority, there remains critical management and operations work in any enterprise environment. That’s why we continue to launch innovative capabilities that support all modern enterprise workloads.
This starts with embedding AI directly into our cloud. Gemini Cloud Assist helps you boost Day-two operations by:
-
Optimizing costs: Gemini will help you identify and address dev/test environments left running, forgotten clusters from experiments, and clusters with excess resources.
-
Troubleshooting: get a natural language interpretation of the logs in Cloud Logging.
-
Synthetic Monitoring: using natural language, you can now describe the target and user journey flows that you'd like to test, and Gemini will generate a custom test script that you can deploy or configure further based on your needs.
And it’s not just Day-two operations, Gemini Cloud Assist can help you deploy three-tier architecture apps, understand Terraform scripts and more, drastically simplifying design and deployment.
While AI presents a thrilling new frontier, we have not lost focus on the crucial elements of a container platform that serves modern enterprises. We’ve continued to invest in foundational areas that ensure the stability, security, and compliance of your cloud-native applications and were excited to introduce the following preview launches:
-
GKE threat detection is powered by Security Command Center (SCC), and surfaces threats affecting your GKE clusters in near real-time by continuously monitoring GKE audit logs.
-
GKE compliance, a fully managed compliance service that automatically delivers end-to-end coverage from the cluster to the container, scanning for compliance against the most important benchmarks. Near-real-time insights are always available in a centralized dashboard and we produce compliance reports automatically for you.
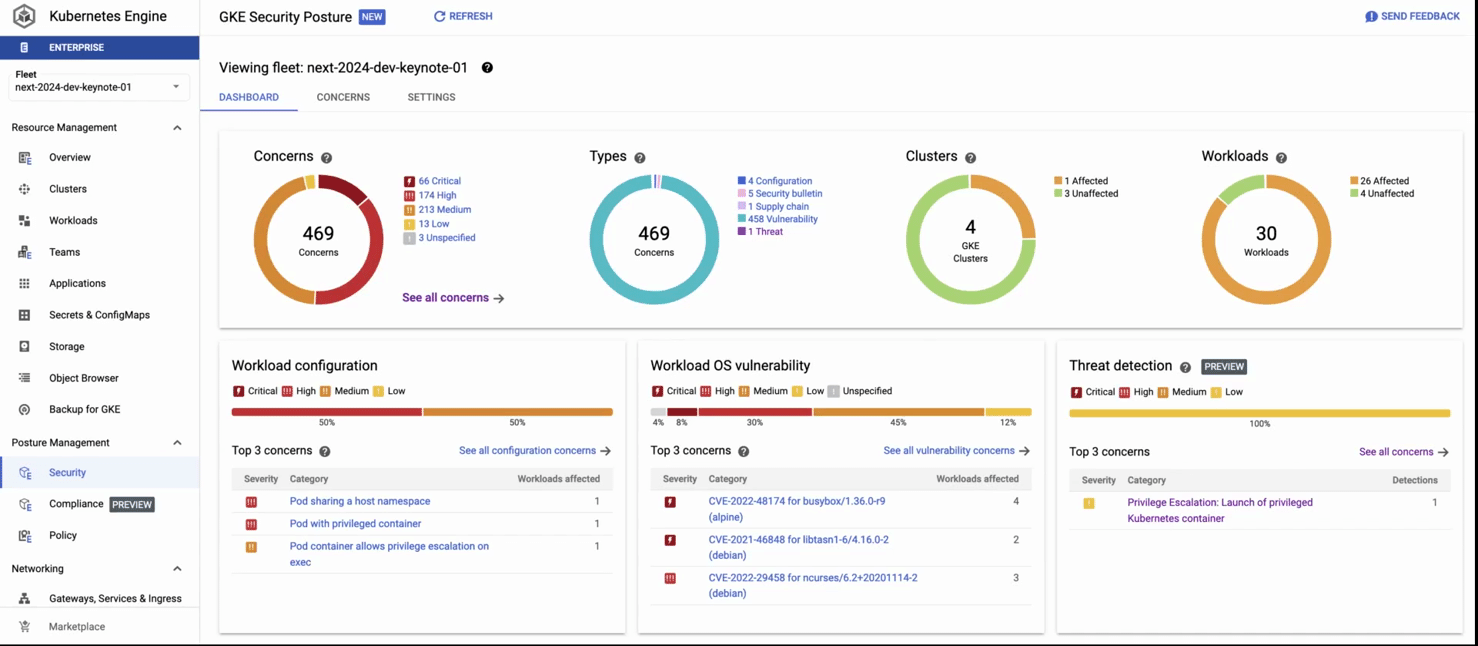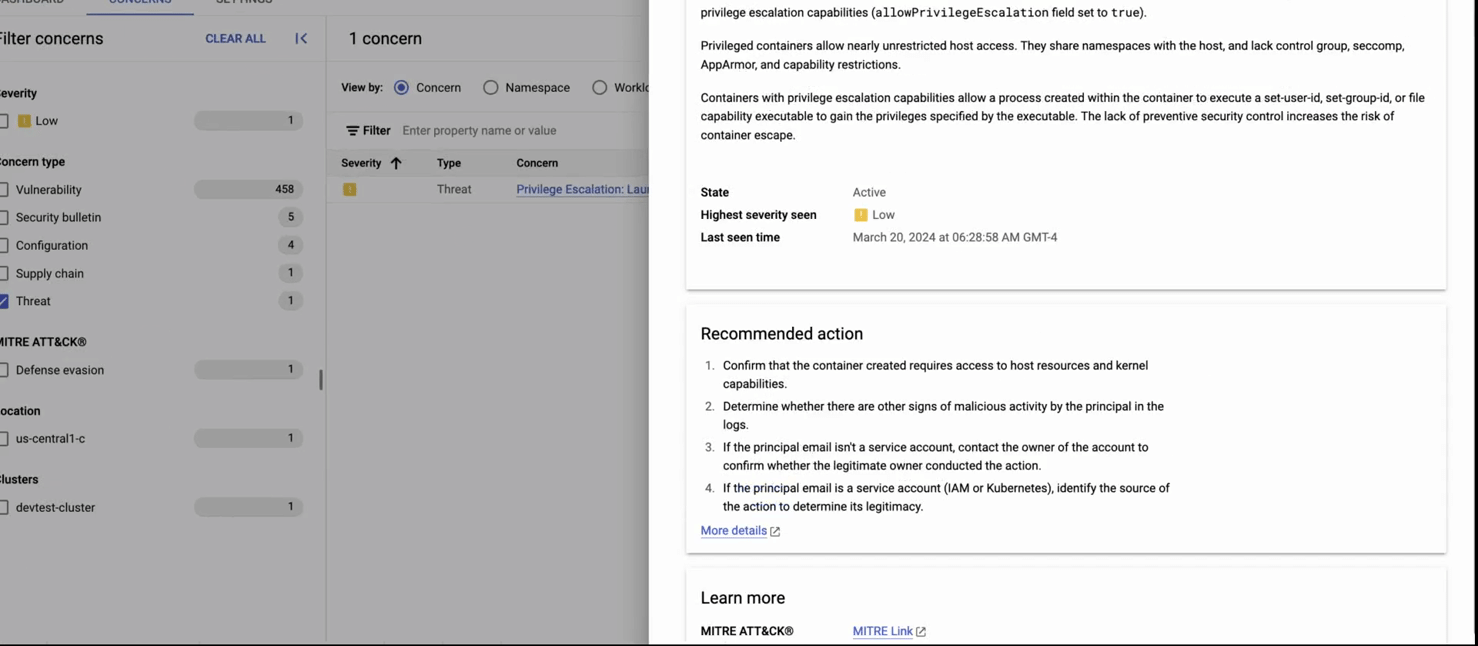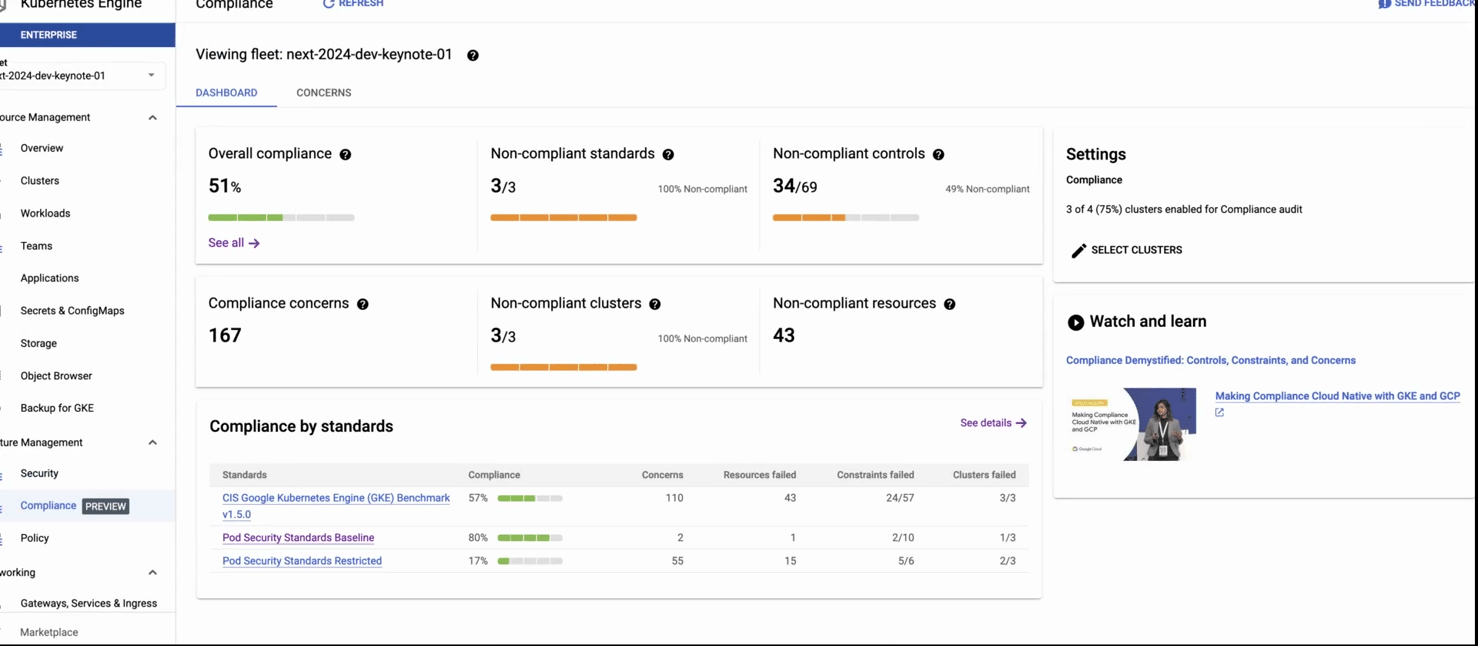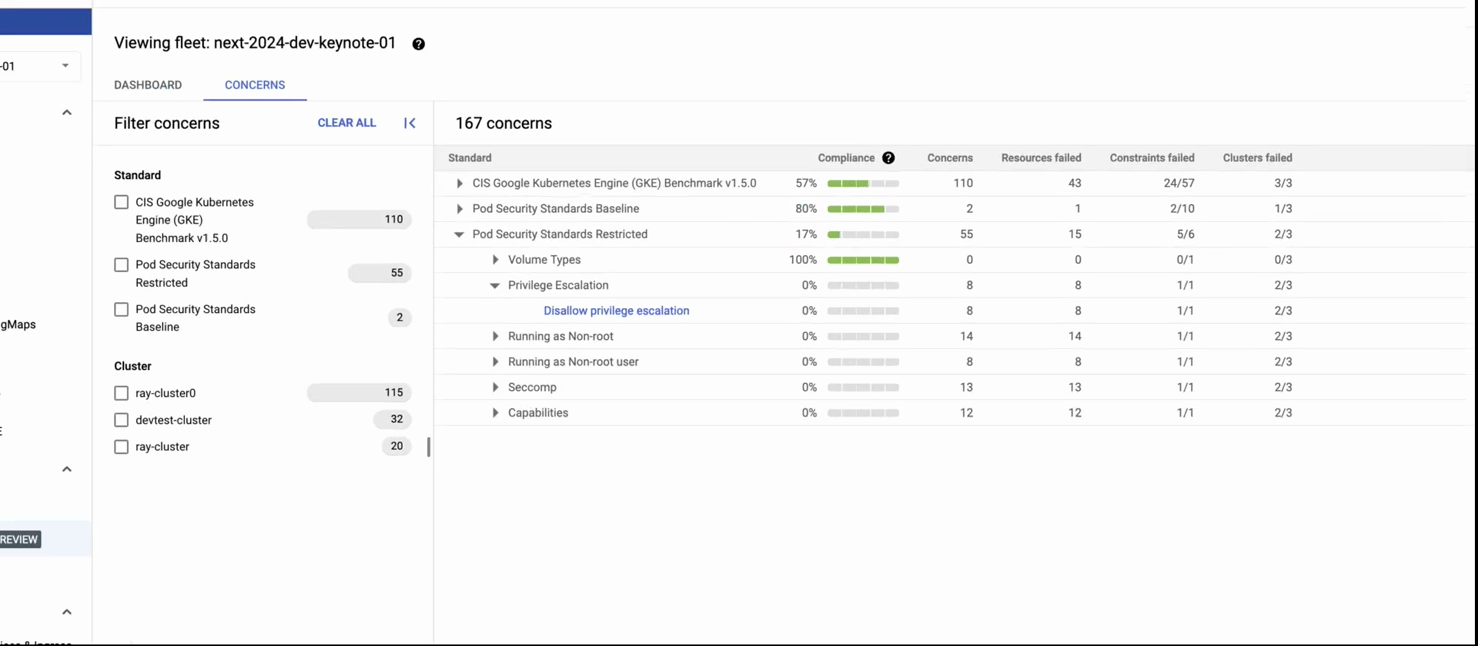
This recording shows: 1) the GKE security posture dashboard, 2) clicking on the threat detection panel, and 3) getting details about a detected threat (creation of a pod with privileged containers). In the second part of the recording, we 4)navigate to the compliance dashboard where we see comprehensive compliance assessments for industry standards, then 5) we click on the concerns tab, where we see detailed reporting by each standard. 6) Finally we see details on the compliance constraints (checks) that failed (in this case, privilege escalation) and recommended remediation.
Let’s get to work
The urgency of the AI moment is permeating every aspect of technology, and data scientists, researchers, engineers, and developers are looking to platform builders to put the right resources in their hands. We’re ready to play our part in your success, delivering scalable, efficient, and secure container resources that fit seamlessly into your existing enterprise. We’re giving you three ways to get started:
-
For building your first AI application with Google Cloud, try Cloud Run and Vertex AI.
-
To learn how to serve an AI model, get started serving Gemma, Google's family of lightweight open models, using Hugging Face TGI, vLLM, or TensorRT-LLM.
-
If you’re ready to try GKE AI with a Retrieval Augmented Generation (RAG) pattern with an open model or AI ecosystem integrations such as Ray, try GKE Quick Start Solutions.
Google Cloud has been steadfast in its commitment to being the best place to run containerized workloads since the 2015 launch of Google Container Engine. 2024 marks a milestone for open source Kubernetes, which celebrates its 10th anniversary in June. We’d like to give kudos to the community that has powered its immense success. According to The Cloud Native Computing Foundation (CNCF), the project now boasts over 314,000 code commits, by over 74,000 contributors. The number of organizations contributing code has also grown from one to over 7,800 in the last 10 years. These contributions, as well as the enterprise scale, operational capability, and accessibility offered by Google Cloud’s managed container platform, have constantly expanded the usefulness of containers and Kubernetes for large numbers of organizations. We’re excited to work with you as you build for the next decade of AI and beyond!
